

始める前に
- ラボでは、Google Cloud プロジェクトとリソースを一定の時間利用します
- ラボには時間制限があり、一時停止機能はありません。ラボを終了した場合は、最初からやり直す必要があります。
- 画面左上の [ラボを開始] をクリックして開始します
Create the view file for SQL derived table
/ 30
Add measures to answer business questions
/ 40
Update a SQL derived table to generate dynamic values using templated filters
/ 30


Looker は Google Cloud で利用できる最新のデータ プラットフォームで、インタラクティブにデータを分析して可視化できます。Looker を使用すると、詳細なデータ分析、さまざまなデータソース間での分析情報の統合、実用的なデータドリブン ワークフローの構築、独自のデータ アプリケーションの作成を行うことができます。
このラボでは、動的な値を生成して複数のユースケースに対応するために SQL 派生テーブルを作成および更新する方法を学びます。
LookML に関する知識が必要です。このラボを開始する前に、「Understanding LookML in Looker」を修了することをおすすめします。
こちらの説明をお読みください。ラボの時間は制限されており、一時停止することはできません。タイマーは、Google Cloud のリソースを利用できる時間を示しており、[ラボを開始] をクリックするとスタートします。
このハンズオンラボでは、シミュレーションやデモ環境ではなく、実際のクラウド環境を使ってご自身でラボのアクティビティを行うことができます。そのため、ラボの受講中に Google Cloud にログインおよびアクセスするための、新しい一時的な認証情報が提供されます。
このラボを完了するためには、下記が必要です。
準備ができたら、[ラボを開始] をクリックします。
[ラボの詳細] ペインに、このラボで使用する一時的な認証情報が表示されます。
ラボの料金をお支払いいただく必要がある場合は、表示されるポップアップでお支払い方法を選択してください。
[ラボの詳細] ペインに表示されているラボの認証情報を確認してください(このラボの Looker インスタンスにログインする際に使用します)。
[Open Looker] をクリックします。
提供されたユーザー名とパスワードを、[Email] フィールドと [Password] フィールドに入力します。
ユーザー名:
パスワード:
[Log In] をクリックします。
正常にログインすると、このラボで使用する Looker インスタンスが表示されます。
LookML で派生テーブルを定義するには、SQL クエリを使用して SQL の派生テーブルを定義するか、Explore クエリを使用してネイティブ派生テーブルを定義します。SQL の派生テーブルを使用することで、SQL 開発者が理解しやすくなり、Looker で派生テーブルを簡単に使い始めることができます。
このタスクでは、顧客の行動に関する次のような複数の問いに柔軟に対応できる user_facts という SQL 派生テーブルを作成します。
[Develop] タブをクリックし、[SQL Runner] をクリックします。
[SQL Query] ウィンドウで、次のクエリを追加します。
この例では、user_id を選択し、そのユーザーのライフタイム注文数をカウントした後、価格を合計してユーザーのライフタイム収益を算出するクエリが必要です。また、created_at 列の最小値と最大値をそれぞれ初回注文日と最終注文日として判別します。
GROUP BY 句を使用して結果を user_id でグループ化します。クエリが適切に機能していることを確かめるには一部のレコードを確認すればよいので、返される結果を LIMIT 句を使用して限定します。
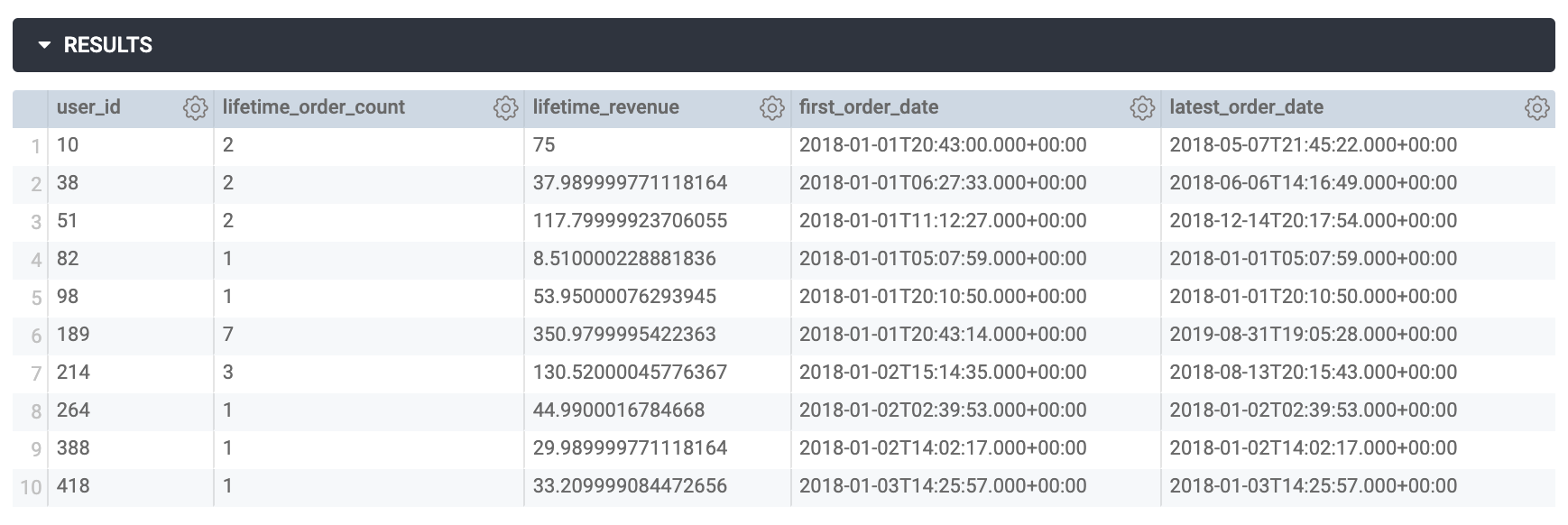
この例では、ユーザー ID、ライフタイム注文数、ユーザーから得られたライフタイム収益、初回と最終の注文日が返されていることがわかります。
このテスト中に返されるデータの量を減らすために、LIMIT 句を使用していることに注目してください。この後のステップで SQL の派生テーブルに対する新しいビューファイルを作成するときには、LIMIT 句を削除します。
ページ右上の [Run] の横にある設定アイコン(
[Project] で qwiklabs-ecommerce を選択します。
[View Name] に「user_facts」と入力します。
[Add] をクリックします。
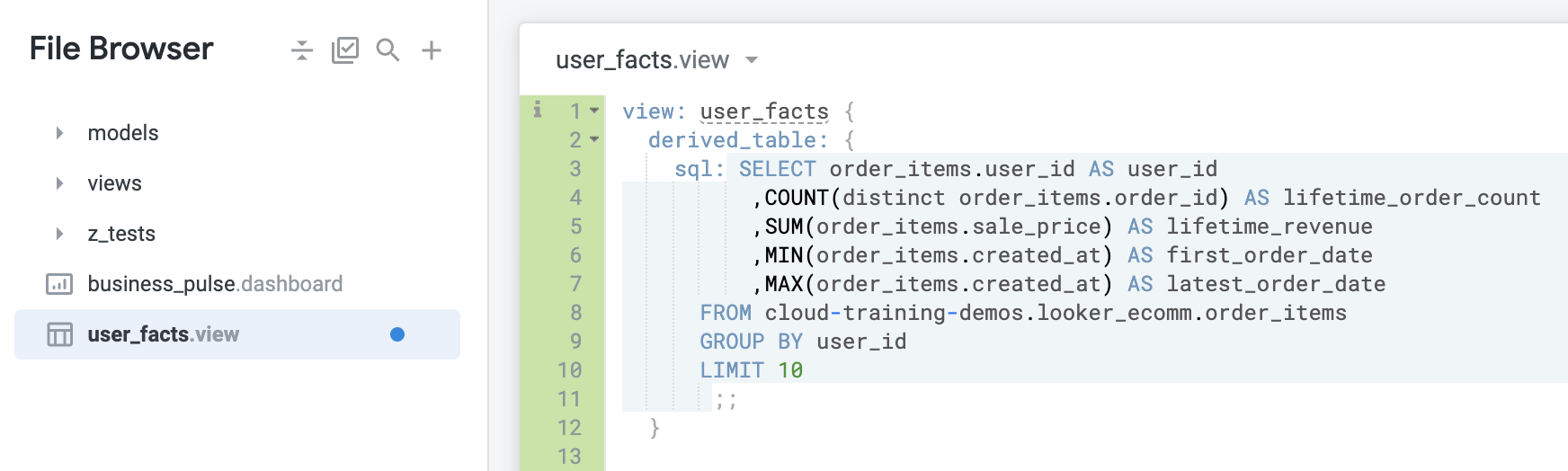
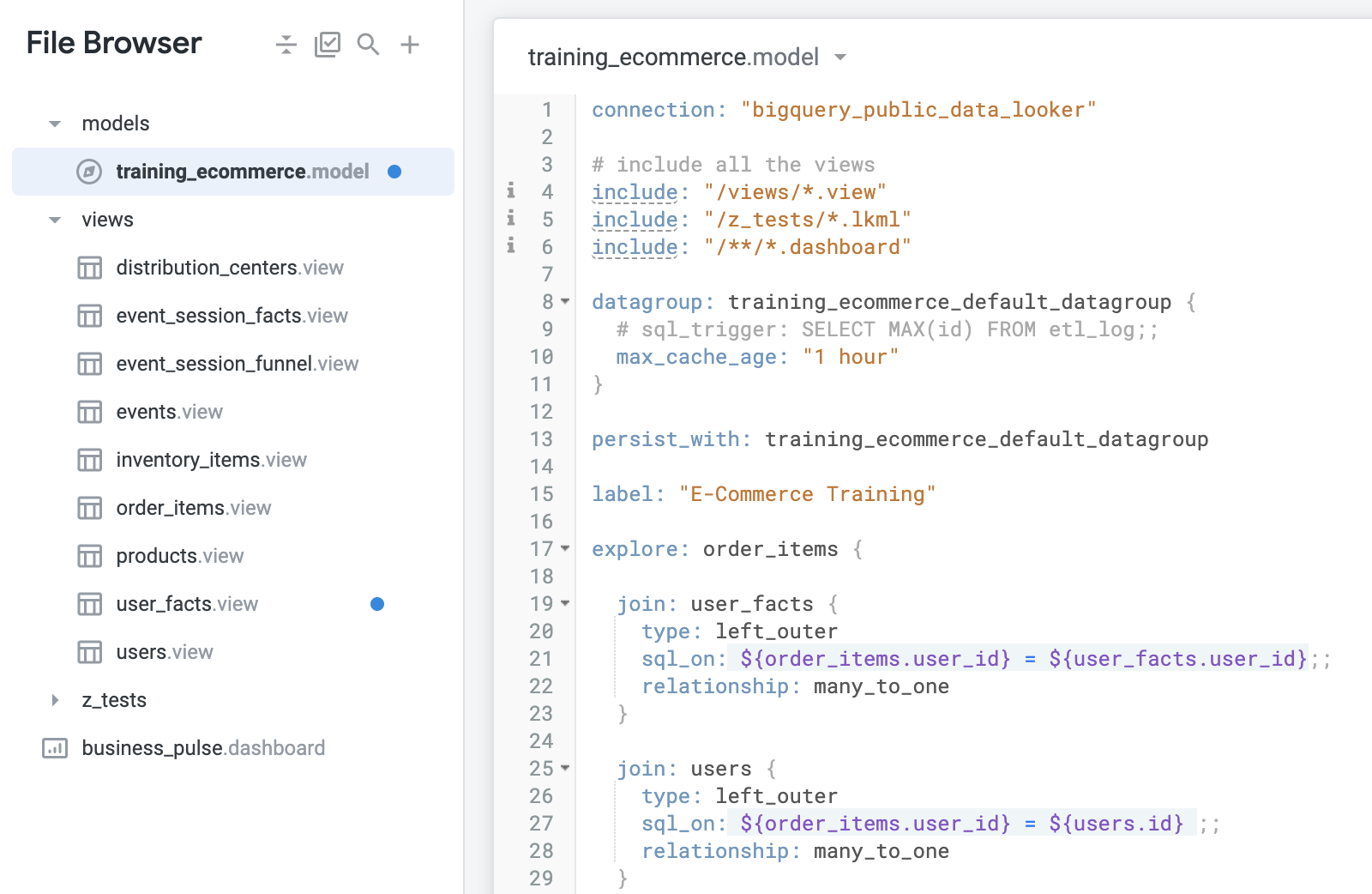
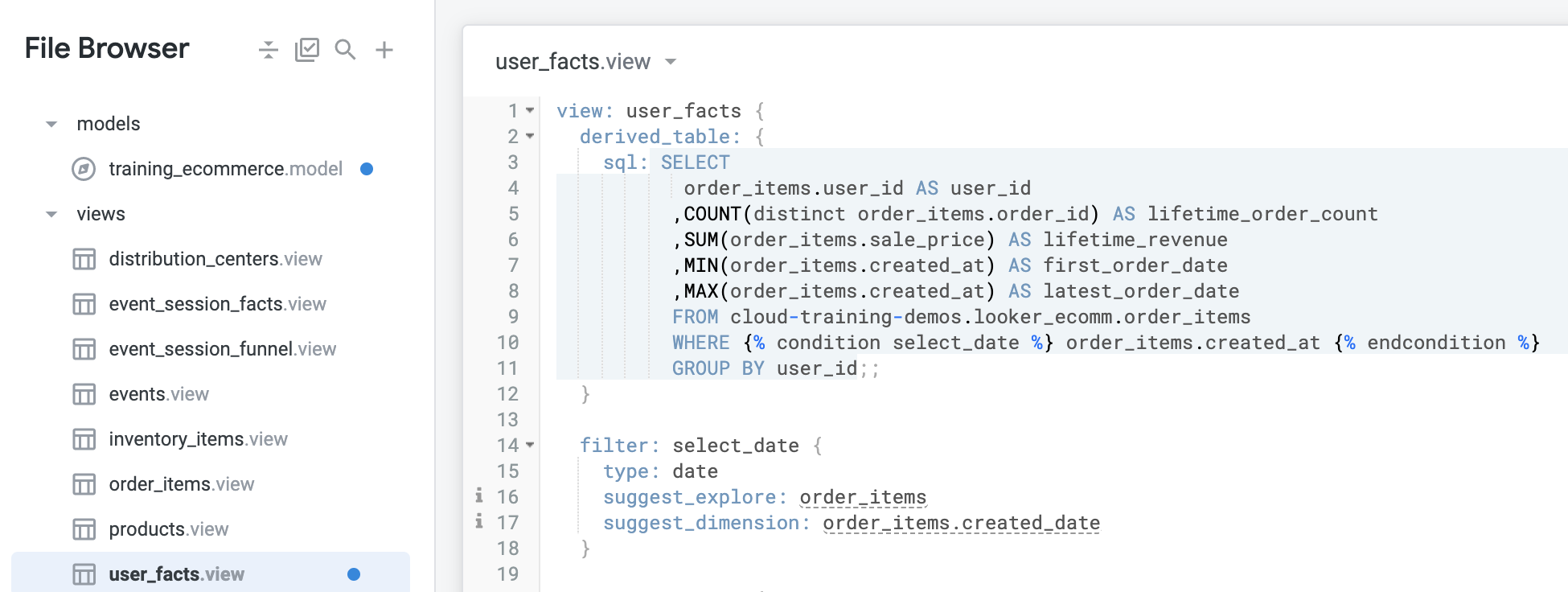
Looker の IDE にリダイレクトされるので、そこで SQL 派生テーブル用に新たに作成したビューファイルを確認します。SQL Runner に入力したクエリに基づいて SQL 派生テーブルのビューファイルが Looker で自動生成されていることがわかります。ビューファイルの最初の 12 行を以下に示します。
Looker におけるファイルは次のようになります。
新しい user_facts ビューが views フォルダの外に作成されていることに注目してください。ビューファイルはプロジェクト内で整理することをおすすめします。
[views] の横にある矢印をクリックして、ビューの一覧を表示します。
user_facts.view をクリックして、views フォルダの下にドラッグします。
user_facts.view をクリックして、SQL 派生テーブルのビューファイルを参照します。
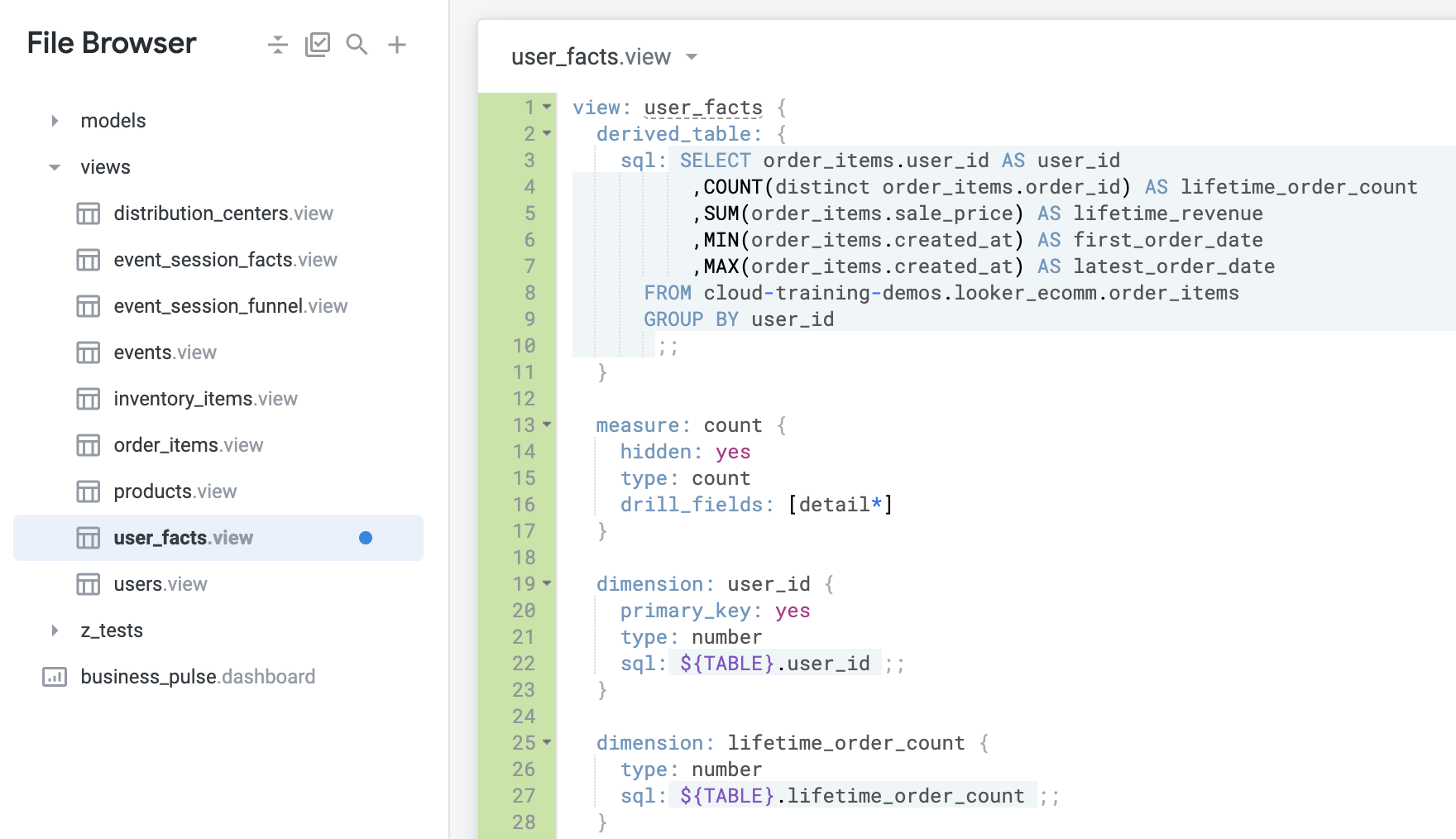
Looker によって、SQL クエリの SELECT 句の各列に、1 つのディメンションと 1 つの新しいカウントのメジャーが自動で作成されます。この後のステップでは、ビューファイルを変更して不要になった LIMIT 句を削除し、新しいカウント メジャーを非表示にして、ビューに主キーを追加します。
LIMIT 10 のコード行を削除します。前述のとおり、count メジャーが派生テーブルで使用されるディメンションとともに自動で生成されます。同じ数値を提供する count が別のビューにすでにある場合、この自動生成の count メジャーは必要ないことがあります。
この例では、自動生成の count メジャーは注文 ID をカウントしていますが、注文のカウントは order_items ビューにすでに存在します。
hidden: yes パラメータを使用して、count メジャーを削除または非表示にできます。このカウントが別のカウントと同じである場合、検証用にメジャーを残しながらユーザーには公開しないようにする場合は、メジャーを非表示にすることをおすすめします。
type: count の前に新しい行を追加し、以下を挿入します。最後のベスト プラクティスは、新しいビューに必ず主キーを指定することです。
この例では、primary_key: yes パラメータを user_id ディメンションに追加できます。user_id は、個々の注文の詳細情報を提供するこのビューを整理するための中心となる ID です。
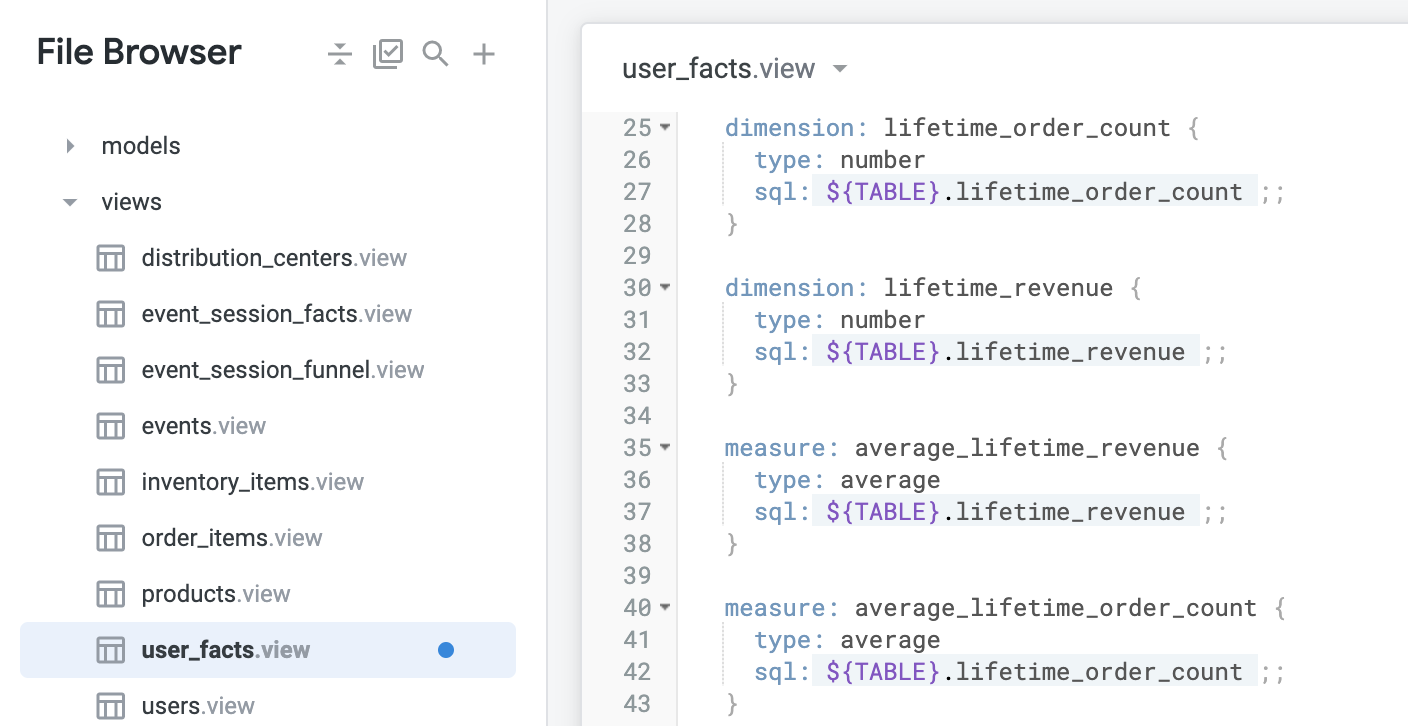
type: number の前に新しい行を追加し、以下を挿入します。これで、新しいビューである user_facts が完成し、ディメンションとメジャーの新規作成とモデルファイル内の Explore への結合、Git ワークフローの完了と本番環境への変更内容の送信を行う準備ができました。これを基盤にして以降のセクションを続けていきます。
Looker におけるファイルは次のようになります。
[LookML を検証] をクリックしてから、[Commit Changes & Push] をクリックします。
commit メッセージを追加して、[Commit] をクリックします。
最後に、[本番環境にデプロイ] をクリックします。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
このセクションでは、最初に示した顧客の行動に関する問い「米国の各州におけるすべての顧客の平均ライフタイム収益と平均ライフタイム注文数は?」に答えるための 2 つの指標を追加します。
average_lifetime_revenue と average_lifetime_order_count の 2 つのメジャーを追加します。このセクションでは、新しい派生テーブルを確認してテストします。まず、モデルファイル内の order_items Explore の定義に結合した後、Order Items Explore を使用して、変更内容を本番環境に push した場合にビジネス ユーザーに表示される内容を確認します。
同じページで、model フォルダ内の training_ecommerce.model ファイルをクリックして、その内容を変更します。
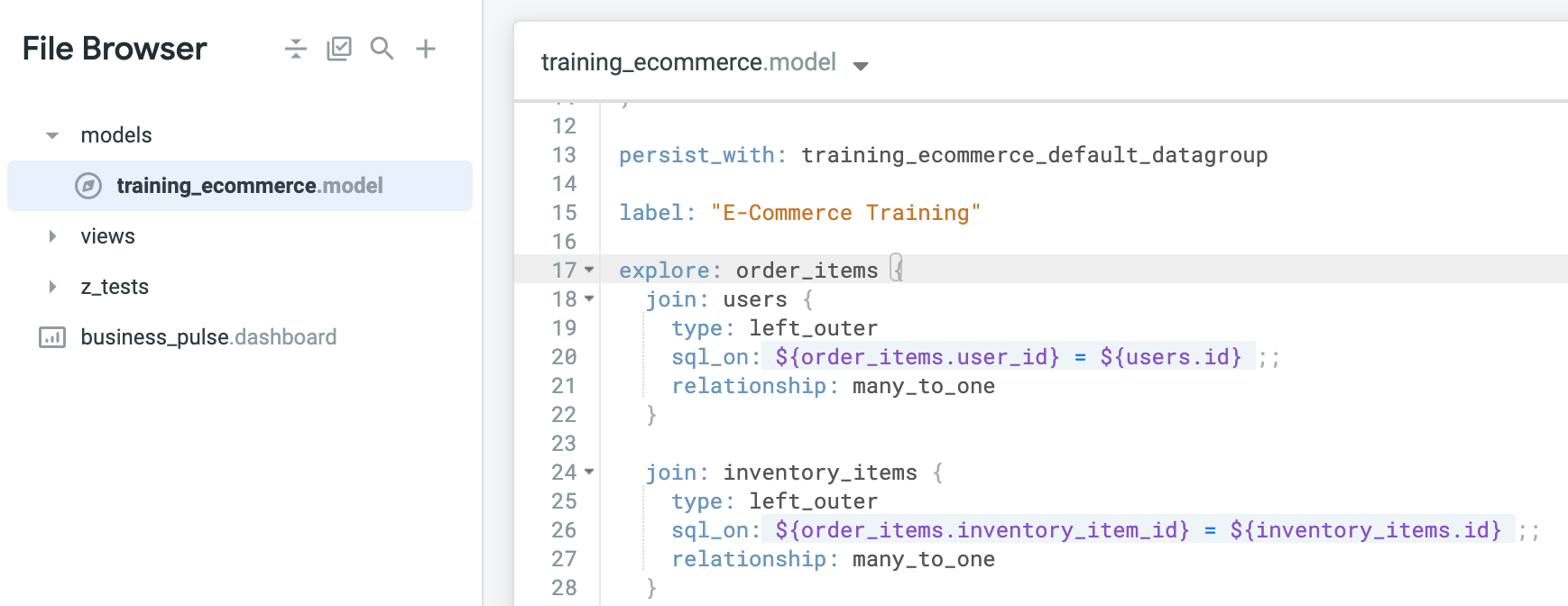
explore: order_items の定義を見つけます。たとえば users ビューの結合など、いくつかの結合がすでに定義されています。
explore: order_items 定義で、users 用の既存の結合の上に、次のように指定して order_details 用の新しい結合を追加します。sql_on パラメータによって、user_id が結合フィールドとして特定されています。relationship パラメータによって、order_items には user_id のインスタンスが複数存在する場合がありますが、user_facts は注文ごとに要約行が 1 つになるように編成されており、各 user_id のインスタンスが 1 つのみになることが示されています。
Looker におけるビューは次のようになります。
ビューを Explore に結合したので、Order Items の Explore ページに移動します。
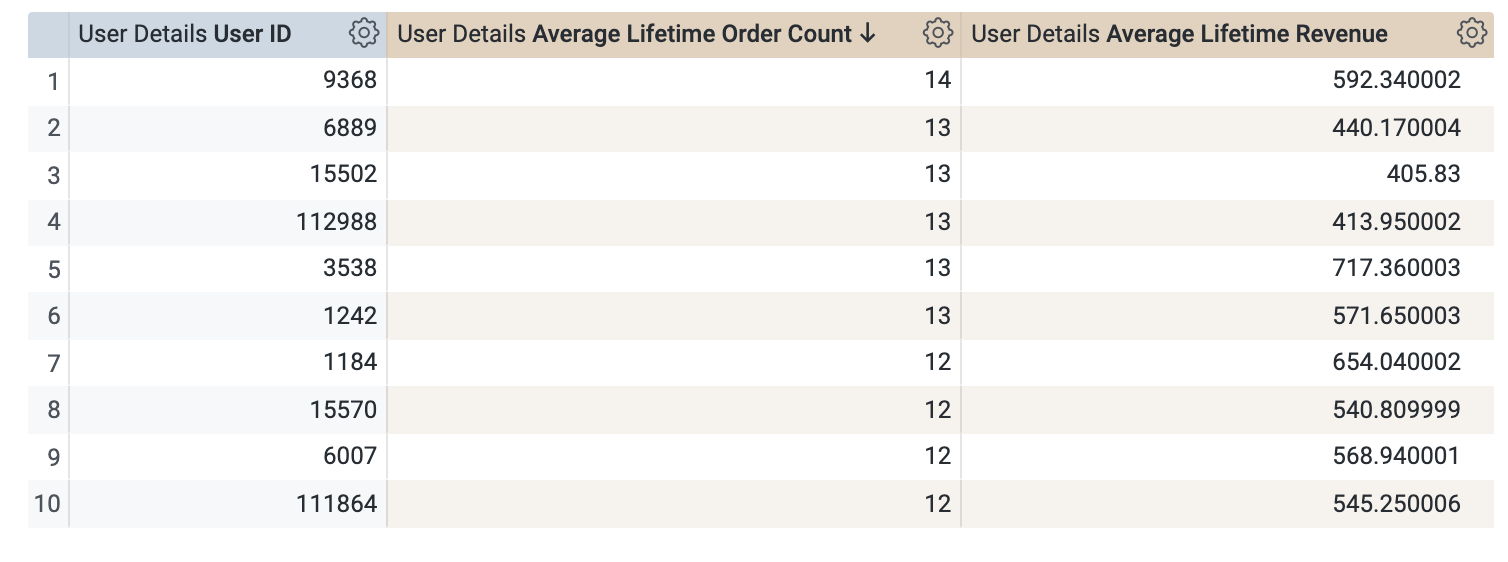
User Facts ビューで、User ID ディメンションと Average Lifetime Order Count メジャーおよび Average Lifetime Revenue メジャーを選択します。
[Row Limit] を 100 に設定します。
[Run] をクリックします。結果は次のようになります。
次に、User ID ディメンションを削除し、Users ビューから State ディメンションを追加します。
Country ディメンションをクリックし、フィルタを追加します。
USA を選択します。
同じメジャーを使用して、ユーザーと州ごとの平均ライフタイム収益と平均ライフタイム注文数の値を計算できるようになりました。
[LookML を検証] をクリックしてから、[Commit Changes & Push] をクリックします。
commit メッセージを追加して、[Commit] をクリックします。
最後に、[本番環境にデプロイ] をクリックします。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
前のラボで説明したように、テンプレート フィルタはパラメータと同じ論理パターンに従います。テンプレート フィルタではエンドユーザーが複数のフィルタ演算子から選択できる点が大きな違いです。数値データ型の場合、「次と等しい」、「次より大きい」、「次の範囲内」などがあります。
テンプレート フィルタでは、値はハードコードされていません。値はユーザーが入力し、その値が生成される SQL クエリに渡されます。ただし、フィルタ定義で Explore とディメンションを指定すると、オプションのプルダウン メニューを表示できます。
このセクションでは、ユーザーが選択した期間に基づいてすべての値を再計算するように、最初のセクションの SQL 派生テーブルの定義を変更します。
Looker IDE で user_facts ビューに戻ります。
まず、SQL 派生テーブルの定義を次のように変更して条件付き WHERE 句を含めます。
derived_table 定義の下に新しいフィルタを追加します。ビューファイルの最初の 18 行は次のようになります。
次に、Order Items Explore の動的な SQL 派生テーブルのテストとして、前のタスクのクエリを繰り返し、フィルタを追加すると値が変化することを確認します。
Order Items Explore に戻ります。
User Facts ビューで Average Lifetime Order Count メジャーと Average Lifetime Revenue メジャーを選択します。
Users ビューで State ディメンションを選択します。
User Facts ビューで [Select Date] という新しいフィルタ専用フィールドの横にあるフィルタ アイコンをクリックします。
UI の上部にある最初のフィルタの値は [is in the past] が選択されたままにします。
2 番目のフィルタの値として [complete years] を選択し、空の値ボックスに「1」を追加します。
Users ビューから Country のフィルタを追加し、USA に設定します。
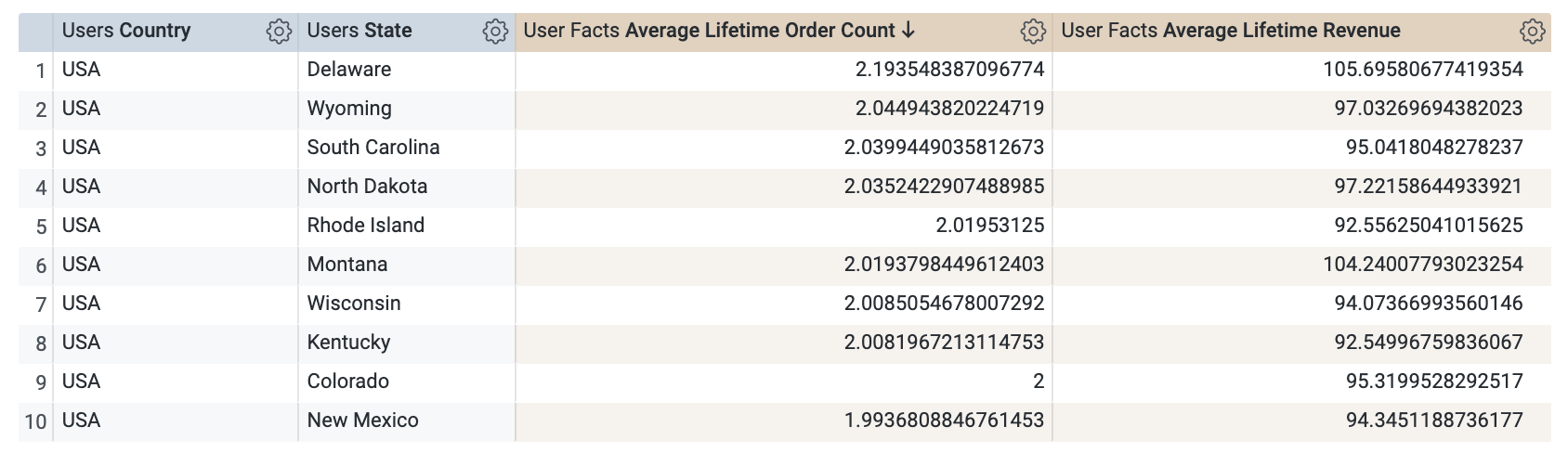
[Run] をクリックして、結果を確認します。
州または国ごとの過去 1 年間の平均ライフタイム注文数と平均ライフタイム収益が表示されます。
[SQL] タブをクリックして SQL を確認します。
この時点で、フィルタの値を変えて、テンプレート フィルタが値に応じてどのように変化するかを [SQL] タブで確認できます。
user_facts ビューに戻ります。
[LookML を検証] をクリックしてから、[Commit Changes & Push] をクリックします。
commit メッセージを追加して、[Commit] をクリックします。
最後に、[本番環境にデプロイ] をクリックします。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
このラボでは、SQL 派生テーブルを作成し、Liquid でテンプレート フィルタを使用して動的な値を生成し、動的な SQL 派生テーブルを活用して複雑な問いに答えました。
Google Cloud トレーニングと認定資格を通して、Google Cloud 技術を最大限に活用できるようになります。必要な技術スキルとベスト プラクティスについて取り扱うクラスでは、学習を継続的に進めることができます。トレーニングは基礎レベルから上級レベルまであり、オンデマンド、ライブ、バーチャル参加など、多忙なスケジュールにも対応できるオプションが用意されています。認定資格を取得することで、Google Cloud テクノロジーに関するスキルと知識を証明できます。
マニュアルの最終更新日: 2024 年 4 月 24 日
ラボの最終テスト日: 2024 年 4 月 24 日
Copyright 2026 Google LLC. All rights reserved. Google および Google のロゴは Google LLC の商標です。その他すべての企業名および商品名はそれぞれ各社の商標または登録商標です。



このコンテンツは現在ご利用いただけません
利用可能になりましたら、メールでお知らせいたします

ありがとうございます。
利用可能になりましたら、メールでご連絡いたします

1 回に 1 つのラボ
既存のラボをすべて終了して、このラボを開始することを確認してください