

Before you begin
- Labs create a Google Cloud project and resources for a fixed time
- Labs have a time limit and no pause feature. If you end the lab, you'll have to restart from the beginning.
- On the top left of your screen, click Start lab to begin
Customize native derived tables using derived columns
/ 50
Customize native derived tables using filters
/ 50
Customize native derived tables using derived columns
/ 50
Customize native derived tables using filters
/ 50

Looker 是 Google Cloud 的新型資料平台,提供互動式分析功能,並可用圖表呈現資料。您能使用 Looker 深入分析資料、整合各種資料來源的洞察資訊、設定可做為行動依據的資料導向工作流程,以及建立自訂資料應用程式。
在本實驗室中,您將瞭解如何運用原生衍生資料表回答複雜問題、處理進階用途,以及使用內建參數自訂原生衍生資料表。
您將學習下列內容:
為獲得最大學習效益,您必須熟悉 LookML,並建議先完成「瞭解 Looker 中的 LookML」技能徽章課程,再開始學習本實驗室的內容。
請詳閱以下操作說明。實驗室活動會計時,且中途無法暫停。點選「Start Lab」後就會開始計時,顯示可使用 Google Cloud 資源的時間。
您將在真正的雲端環境中完成實作實驗室活動,而不是在模擬或示範環境。為達此目的,我們會提供新的暫時憑證,讓您用來在研究室活動期間登入及存取 Google Cloud。
如要完成這個研究室活動,請先確認:
準備就緒後,請點選「Start Lab」。
「Lab Details」窗格會顯示本實驗室中必須使用的暫時憑證。
如果實驗室會產生費用,畫面中會出現選擇付款方式的彈出式視窗。
請在「Lab Details」窗格查看實驗室憑證,您之後會使用此憑證登入實驗室的 Looker 執行個體。
點選「Open Looker」。
分別在「Email」和「Password」欄位,輸入提供的使用者名稱和密碼。
使用者名稱:
密碼:
點選「Log In」。
成功登入後,您就會在本實驗室看到 Looker 執行個體。
原生衍生資料表與手動編寫的 SQL 查詢功能相同,但以原生 LookML 語言表示。
為什麼要使用原生衍生資料表?想想您在上一個實驗室中建立的 user_facts SQL 衍生資料表。您已將訂單 ID 的 COUNT 設為 lifetime_order_count,並將 sale_price 的 SUM 設為 lifetime_revenue。如果您還沒發現,這些匯總資料已以測量指標的形式存在於模型中!order_items 檢視畫面已包含 order_count 和 total_sales。
原生衍生資料表之所以實用,是因為它體現了 LookML「可重複使用」這項核心原則,也就是說您可以沿用現有的維度、測量指標,甚至是探索和彙整邏輯。這能大幅減少使用「硬式編碼」參照資料庫;長期下來,模型會更容易維護。
在本節中,您將建立名為 brand_order_facts 的原生衍生資料表,其中包含可依總收益為品牌排序的衍生資料欄,並可使用動態日期範圍和/或使用者輸入內容進行篩選。您也會建立新的維度,將資料列標示為前 5 大品牌或非前 5 大品牌 (也就是將排名第 6 以上的所有品牌歸為「6) Other」這個品牌名稱)。
首先,在 Looker 使用者介面左下方,按一下切換鈕進入「開發模式」。
在 Looker 導覽選單中,按一下「探索」。
在「E-Commerce Training」底下,按一下「Order Items」。
在「Inventory Items」檢視畫面下方,按一下「Product Brand」維度。
在「Order Items」檢視畫面下方,按一下「Total Revenue」測量指標。
按一下「執行」。
按一下頁面右上角「執行」旁的設定齒輪圖示 (
切換至「衍生資料表」,按一下方塊中的 LookML 程式碼,然後複製到剪貼簿。
前往 Looker IDE (依序點選「開發」>「qwiklabs-ecommerce」),按一下檔案瀏覽器旁的加號 (+) 圖示,然後選擇「建立檢視表」。
將新的檢視表命名為 brand_order_facts,然後按一下「建立」。
按一下「brand_order_facts.view」,然後拖曳至「views」資料夾底下。
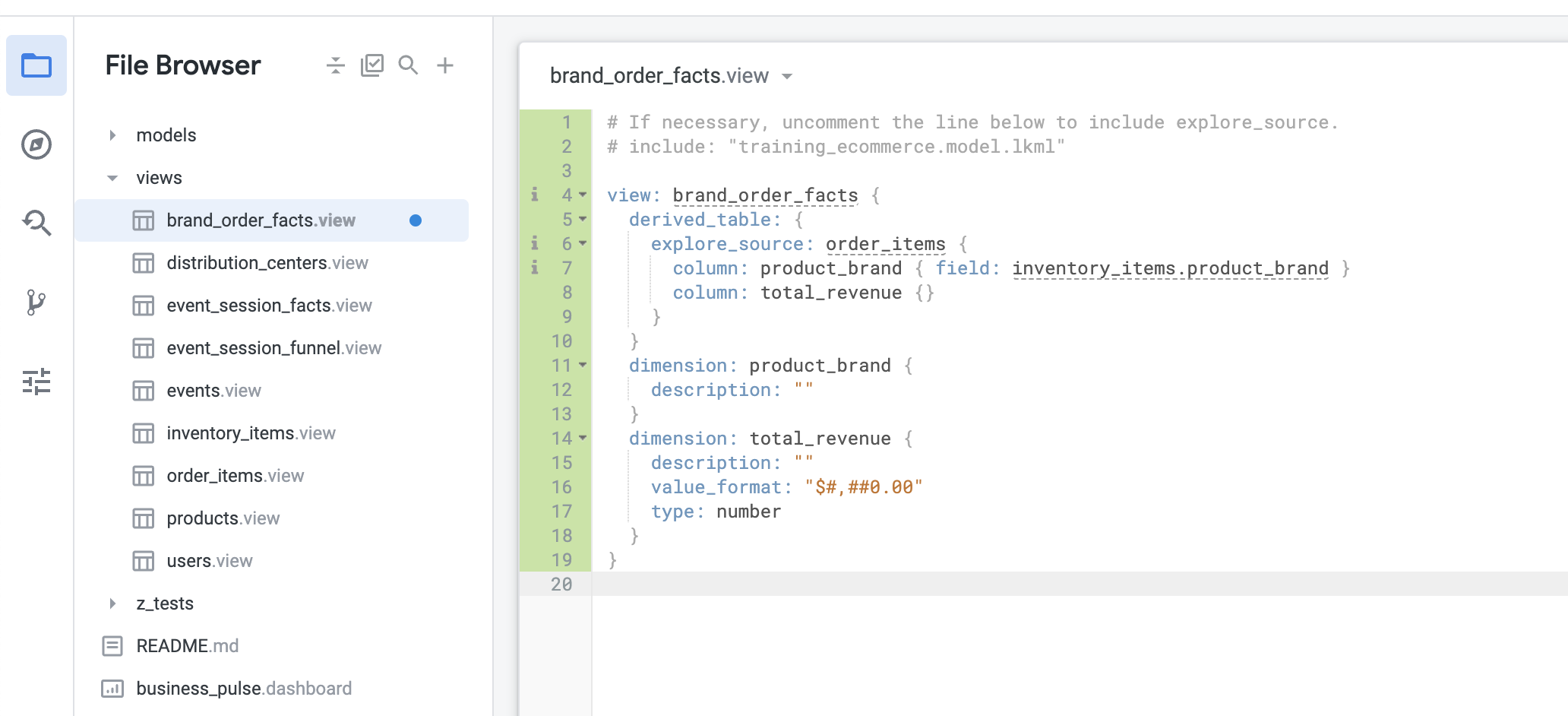
清除所有自動產生的範例程式碼,然後貼上從「探索」複製的程式碼。別忘了將自動產生的檢視表名稱修正為 brand_order_facts。您會看見類似下方的畫面:
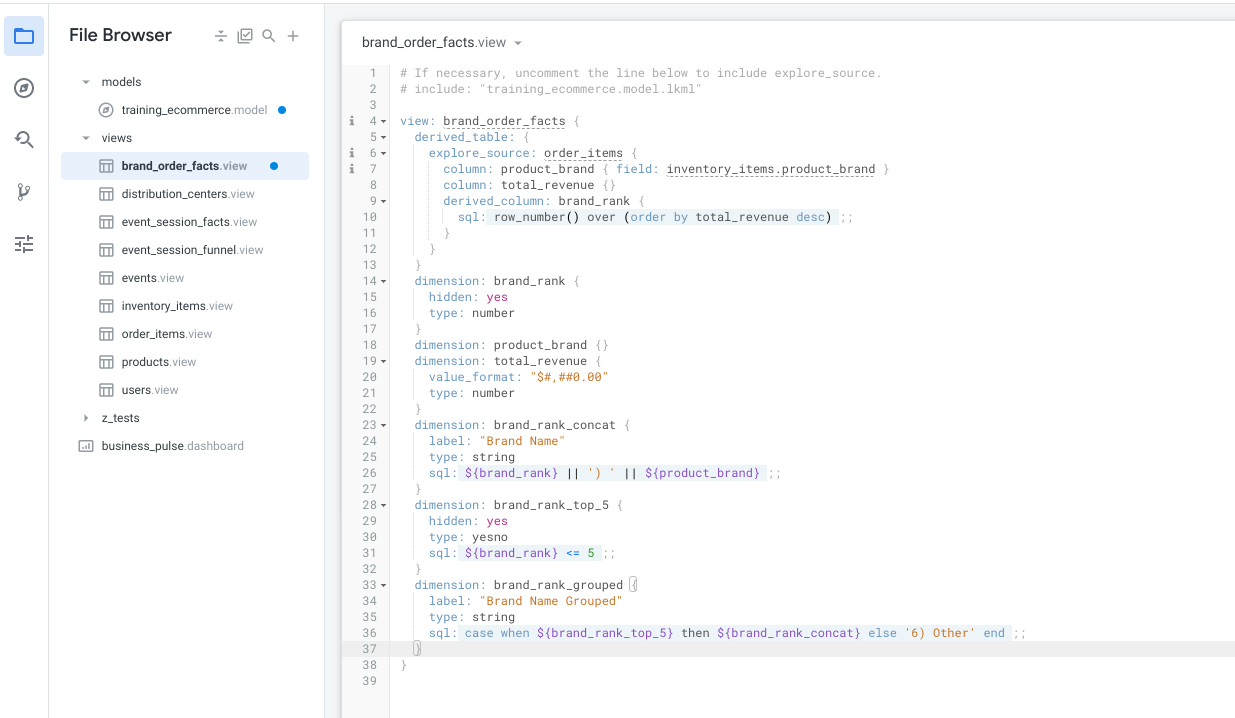
現在您已具備原生衍生資料表的基礎概念,接下來的工作是為品牌排名,在大多數 SQL 方言中,這項作業可透過 ROW_NUMBER() 函式完成。
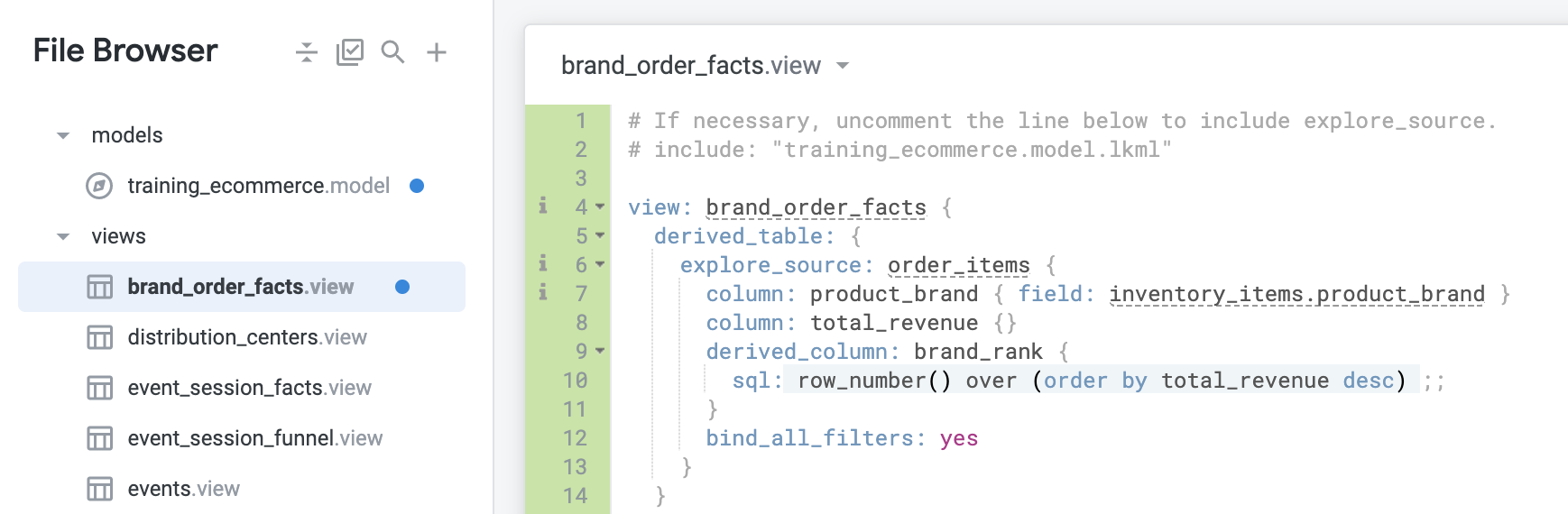
如要達成這個目標,您需要在原生衍生資料表的 explore_source 中加入 derived_column。在原生衍生資料表中,您可以使用 derived_column 指定「尚未存在」於 explore_source 參數所指定「探索」中的資料欄。在本例中,您會將其命名為 brand_rank。
column: total_revenue {} 定義下方,開始定義 brand_rank 衍生欄:每當您建立衍生資料欄時,也需要為該資料欄新增維度。這與一般資料庫資料表中的資料欄相同,資料欄必須以維度形式在 LookML 中呈現。您是否有發現,自動產生的維度沒有 SQL 參數?這是因為如果沒有為維度指定 SQL,Looker 會假設維度應指向基礎資料中名稱完全相同的資料欄。如果需要,這項捷徑可用於專案的其他區域,但一般來說,盡可能明確指定是較好的做法。在這種情況下,您至少應指定類型。否則 Looker 會預設為字串,這不是您要的結果。
product_brand 維度正上方,新增下列程式碼:新的檢視畫面應如下所示:
按一下「儲存變更」。
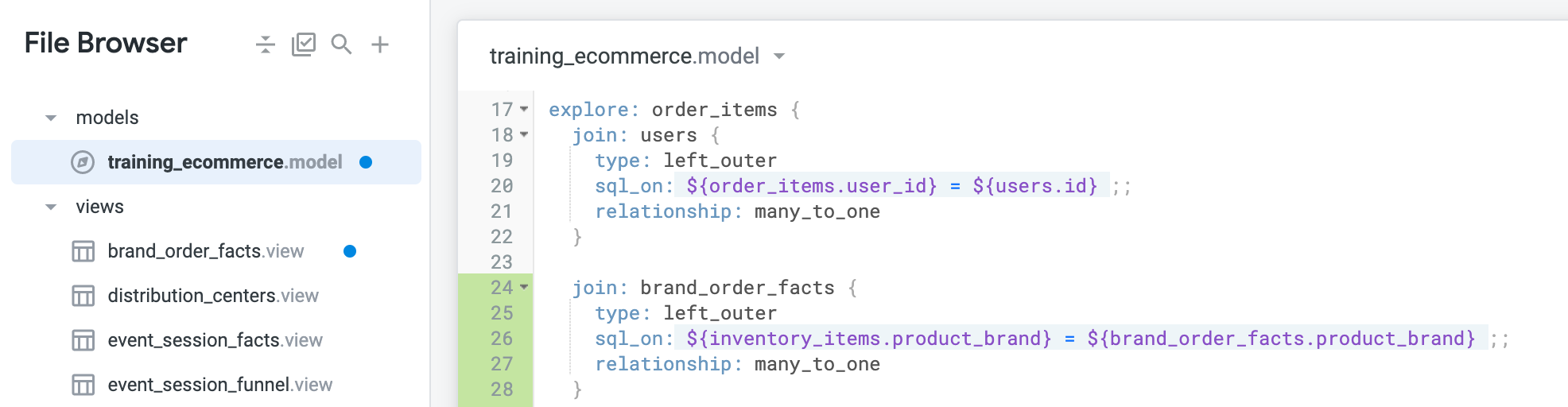
在同一頁面中,點按「model」資料夾內的 training_ecommerce.model 檔案修改內容。
找到 explore: order_items 定義。
在 explore: order_items 定義中,用下列指令新增 brand_order_facts 彙整:
按一下「儲存變更」。
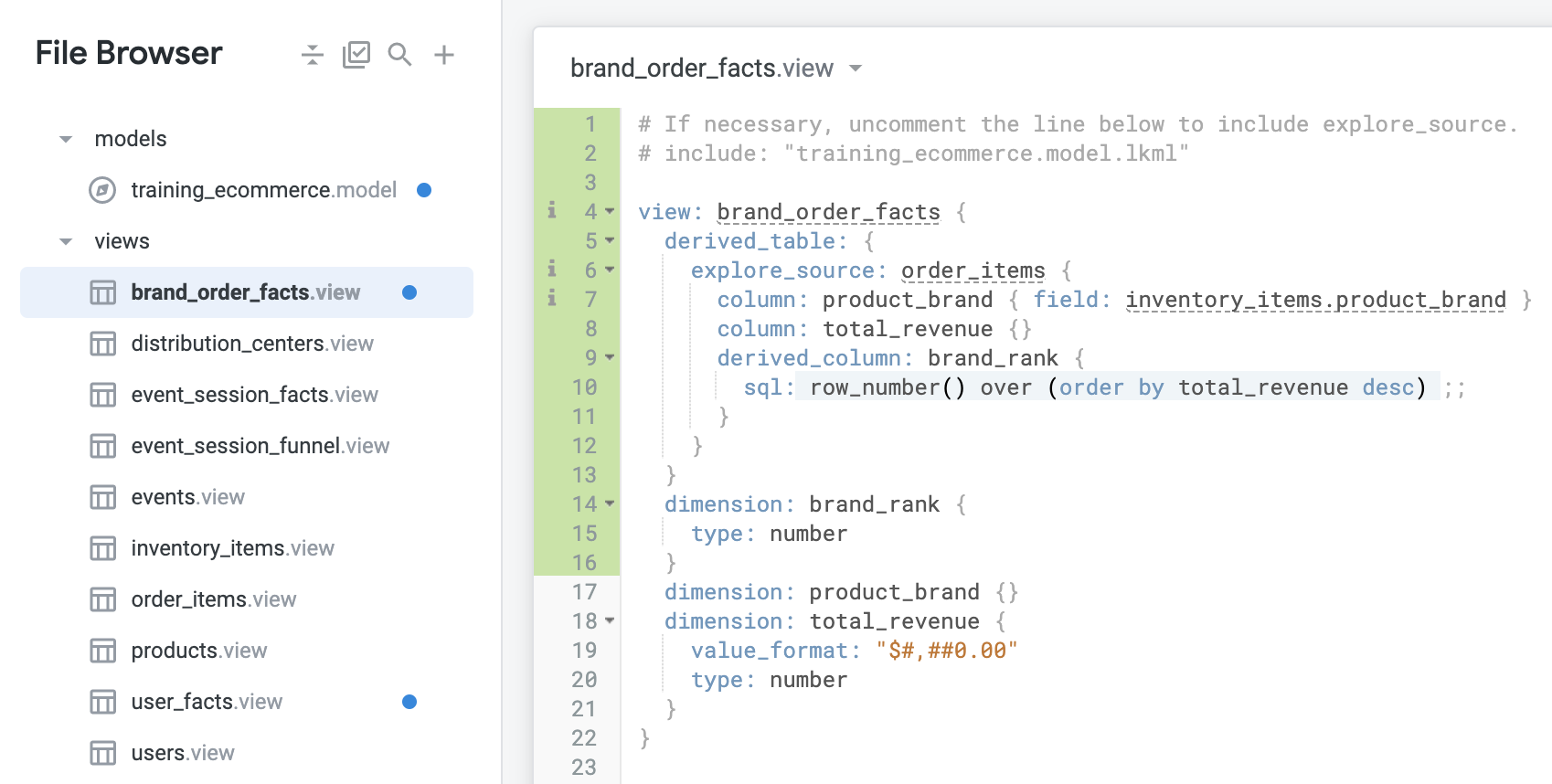
模型檔案應如下所示:
現在您已將 brand_order_facts 檢視畫面加入「探索」,請前往「Order Items」的「探索」頁面。
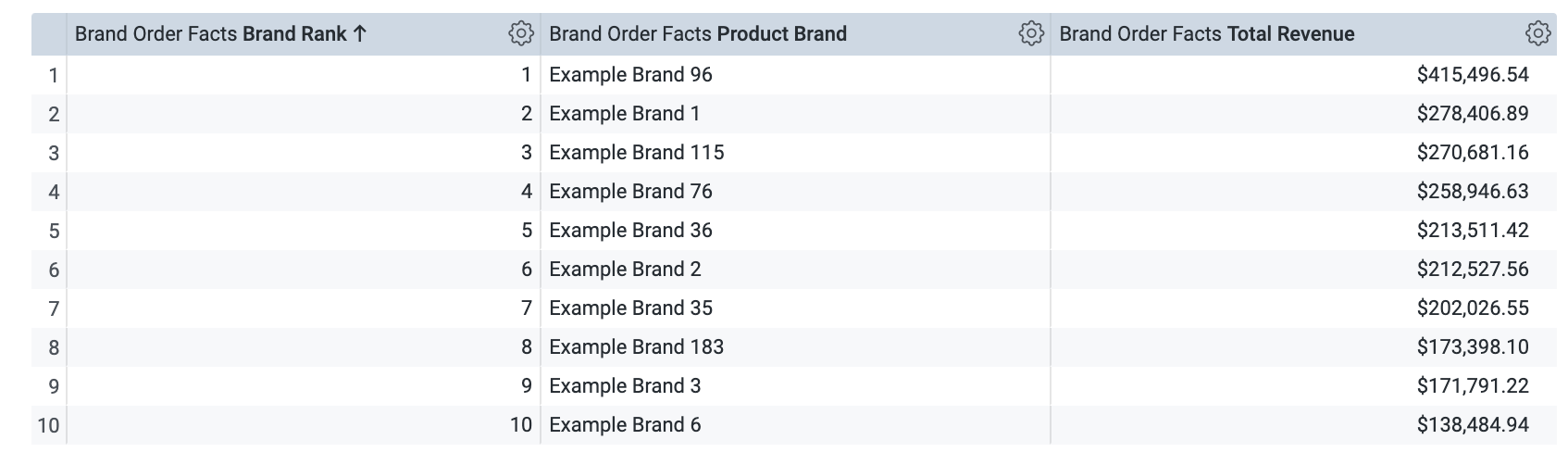
在「Brand Order Facts」檢視畫面下方,選取「Brand Rank」、「Product Brand」和「Total Revenue」維度。
將「資料列限制」設為 10。
按一下「執行」。結果應大致如下:
到目前為止都很順利!但如果企業使用者希望品牌名稱顯示為「1) Example Brand」,而不只是「Example Brand」,該怎麼做?要如何達成這個目標?在這種情況下,您可以建立維度,串連其他兩個維度值。
返回 brand_order_facts 檢視畫面。
建立另一個名為 brand_rank_concat 的維度,串連品牌排名和產品品牌:
brand_rank,因為企業使用者可能只會在新的 brand_rank_concat 中尋找排名編號,而不想使用個別欄位:brand_rank_concat 新增標籤,讓使用者更容易使用。使用「Brand Name」標籤:最後一個步驟是將所有排名第 6 以上的品牌歸入「Other」分類。為此,您首先要建立「stepping-stone」維度,評估品牌的排名是否在前 5 名內。
brand_rank_top_5 的新維度,並採用下列參數:brand_rank_grouped 的新維度,並使用下列程式碼將 brand_rank_top_5 併入其中:您應該會看見類似下方的檢視畫面:
前往「Order Items」的「探索」頁面。
在「Brand Order Facts」檢視畫面下方,選取「Brand Name Grouped」維度。
在「Order Items」檢視畫面下方,選取「Total Revenue」測量指標。將「資料列限制」設為 10。
按一下「執行」。
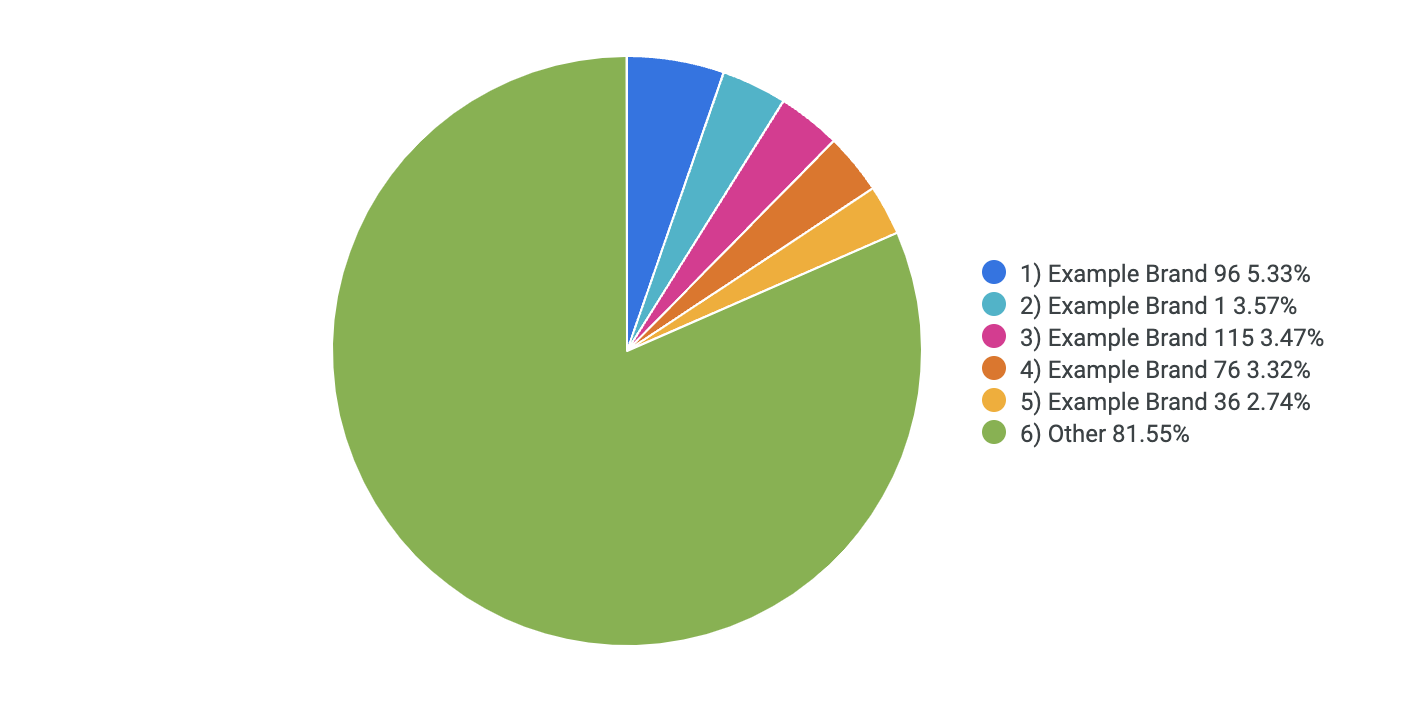
確認「Brand Name Grouped」欄依序排列,然後在「圖表」分頁中,按一下「圓餅圖」。
確認圖表類似下圖:
按一下頁面右上角「執行」旁的設定齒輪圖示 (
將 Look 圖表命名為:Ranked Brand Revenue。
按一下「儲存」。
返回 brand_order_facts 檢視畫面。
依序點按「驗證 LookML」>「修訂變更並推送」。
新增修訂版本訊息,然後點按「修訂」。
最後,點按「部署至正式環境」。
太好了!希望這有助於您瞭解,將用途或所需邏輯分解為個別基本維度,然後合併或建構這些維度,以回答特定業務問題,是多麼實用。在最佳做法 LookML 開發中,有許多類似的隱藏「stepping-stone」維度和測量指標非常常見。
點選「Check my progress」,確認上述工作已完成。
假設商家只關心最近 365 天內的訂單,也許這些前 5 大品牌在幾年前非常受歡迎,但由於趨勢不同,過去一年內的排名可能有所變動。
在本節中,您將瞭解如何在 LookML 中,為原生衍生資料表使用不同類型的篩選器。篩選器可用於對衍生資料表套用篩選條件,與篩選後的測量指標類似。系統會新增 WHERE 或 HAVING 子句。
首先,返回 brand_order_facts 檢視畫面。
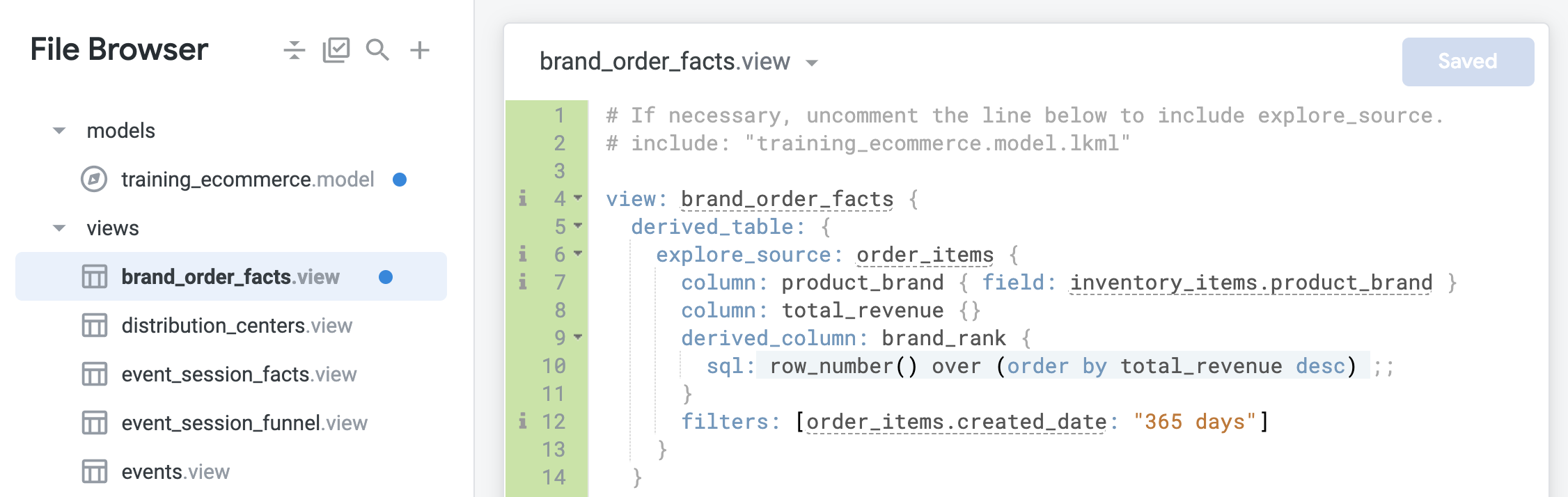
在 derived_column 定義下方,新增篩選器,將原生衍生資料表限制為過去 365 天內建立的訂單:
返回「Order Items Explore」。
在「Brand Order Facts」檢視畫面下方,選取「Brand Name Grouped」。
在「Order Items」檢視畫面下方,選取「Total Revenue」測量指標。
按一下「執行」。
點按「資料」列的「SQL」分頁標籤,即可查看查詢中如何使用篩選器。
由於您已對「Ordered Items Created Date」新增篩選器,只查看過去 365 天內的訂單,因此 WHERE 條件只會在所謂的「外部查詢」中產生。這是任何維度篩選器的預設行為;您無法要求篩選器進入衍生資料表的通用資料表運算式,或讓外部 WHERE「向下滲透」至內部查詢。這時,在 NDT 本身中新增篩選器就派上用場了。
如果商家覺得只限制過去 365 天的訂單資料太過嚴格,該怎麼辦?有時使用者可能想分析過去兩年的排名。使用 filters: [order_items.created_date: "365 days"],您會將時間範圍硬式編碼。
這時,bind_filters 參數就比單純的篩選器更有用。您可以指出要從外部探索「向下流動」至原生衍生資料表內部查詢的欄位 (from_field),以及應對應至哪個原生衍生資料表欄位 (to_field)。在絕大多數情況下,這兩者應該相同。
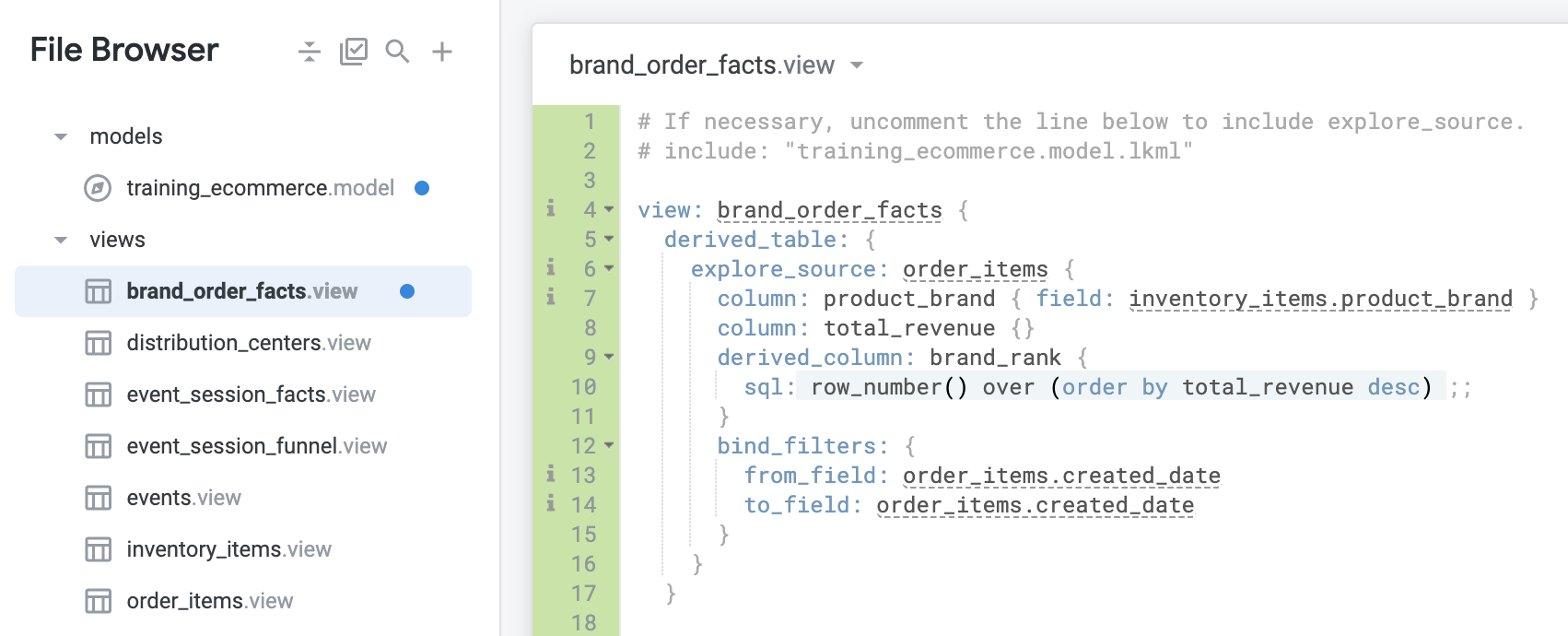
explore_source 的 bind_filters 子參數會將探索查詢中的特定篩選器傳遞至原生衍生資料表子查詢:
to_field 是原生衍生資料表中的欄位,篩選器會套用至該欄位。to_field 必須是基礎 explore_source 的欄位。from_field 會指定要從哪個探索欄位取得篩選器。返回 brand_order_facts 檢視畫面。
如要使用繫結篩選器,請先移除您在前一節建立的衍生資料表定義中的靜態日期篩選器。
接著,在 derived_column 定義下方新增下列 bind_filters 範本:
在這種情況下,您會想抓取 from_field: order_items.created_date 篩選器,並讓它影響或套用至 to_field: order_items.created_date。
返回「Order Items Explore」。
在「Brand Order Facts」檢視畫面下方,選取「Brand Name Grouped」。
在「Order Items」檢視畫面下方,選取「Total Revenue」測量指標。
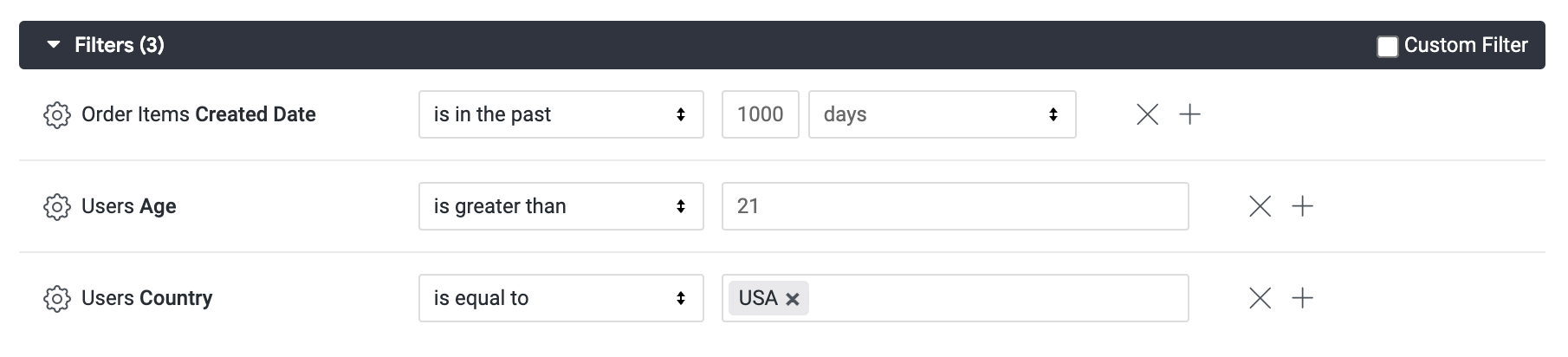
同樣在「Order Items」檢視畫面中,選取「Created Date」維度,然後選取「Date」欄位,並點選「Date」旁的篩選按鈕。
在篩選器定義中,將篩選器指定為:is in the past 1000 days。為方便示範,您使用 1000 天,確保篩選條件不會過於嚴格,且會擷取過去 3 年的資料。
按一下「執行」。
如您所見,這種做法有彈性多了!如果篩選過去 3 季建立的訂單,原生衍生資料表就會相應計算過去 3 季的排名。如果依特定日期範圍內建立的訂單進行篩選,原生衍生資料表也會在 WHERE 條件中使用相同的日期範圍。
現在,在「Users」欄位下方,選取「Country」和「Age」,然後為這些項目新增篩選器;將篩選器設為 Country is equal to USA 和 Age is greater than 21。
按一下「執行」。
請注意,衍生資料表的 WHERE 條件不受影響。如果企業使用者除了「Ordered Items Created Date」以外,還有其他條件,該怎麼辦?如果他們只想查看美國或男性顧客的訂單排名,該怎麼辦?
您當然可以繼續新增 bind_filters,但請看看「Order Items Explore」中有多少欄位。為所有項目新增 bind_filters 需耗費大量時間。這時,另一個參數 bind_all_filters 就非常實用。
點選「Check my progress」,確認上述工作已完成。
如要將篩選器從「探索」傳遞至原生衍生資料表子查詢,最簡單的方法是在原生衍生資料表的 explore_source 參數中指定 bind_all_filters: yes。這會將「探索」的所有執行階段篩選器傳遞至原生衍生資料表子查詢。
如要在其他探索中使用原生衍生資料表,請改用 bind_filters 參數,如上一節所述。
首先,請移除您在前一節建立的衍生資料表定義中的 bind_filter。
在 derived_column 定義下方新增 bind_all_filters: yes 定義,即可將每個篩選器繫結至自身,而不只是將 order_created_date 繫結至自身:
返回「Order Items Explore」。
在「Brand Order Facts」檢視畫面下方,選取「Brand Name Grouped」。
在「Order Items」檢視畫面下方,選取「Total Revenue」測量指標。
同樣在「Order Items」檢視畫面下方,找到「Created Date」維度,然後點按「Date」旁的篩選按鈕。
在篩選器定義中,將篩選器指定為:is in the past 365 days。
在「Users」檢視畫面中,針對「Country」和「Age」新增篩選器,並將其設為 Country is equal to USA 和 Age is greater than 21。
按一下「執行」。
按一下「SQL」分頁標籤。請注意,衍生資料表的 WHERE 條件現在會動態更新!
雖然 bind_all_filters 很實用,但只有在您將原生衍生資料表加入 explore_source 時,這個參數才會生效。換句話說,您只能在這裡使用這個檢視區塊,因為您已將 brand_order_facts 彙整回與 explore_source order_items 相同的探索。
原因為何?因為 bind_all_filters 表示 Looker 必須知道如何為整個探索中的任何欄位產生 WHERE 條件。如果原生衍生資料表使用 order_items 的 explore_source,但您將其彙整至其他探索,該探索可能會彙整任意數量的檢視區塊和欄位,而這些檢視區塊和欄位在 order_items 中不存在,因此在 order_items 中沒有任何意義。Looker 無法使用這些其他欄位篩選衍生資料表。
您已瞭解 bind_all_filters 的運作方式,現在請試用幾個不同的探索篩選器,看看這些篩選器如何影響原生衍生資料表的編譯方式。
依序點按「驗證 LookML」>「修訂變更並推送」。
新增修訂版本訊息,然後點按「修訂」。
最後,點按「部署至正式環境」。
在本實驗室中,您使用原生衍生資料表回答複雜問題,並使用衍生資料欄解決進階用途案例,然後更新這些資料表,使用內建篩選器參數產生動態值。您也瞭解了企業使用者如何運用自訂原生衍生資料表,解答複雜的問題。
協助您瞭解如何充分運用 Google Cloud 的技術。我們的課程會介紹專業技能和最佳做法,讓您可以快速掌握要領並持續進修。我們提供從基本到進階等級的訓練課程,並有隨選、線上和虛擬課程等選項,方便您抽空參加。認證可協助您驗證及證明自己在 Google Cloud 技術方面的技能和專業知識。
使用手冊上次更新日期:2024 年 3 月 4 日
實驗室上次測試日期:2024 年 3 月 4 日
Copyright 2026 Google LLC 保留所有權利。Google 和 Google 標誌是 Google LLC 的商標,其他公司和產品名稱則有可能是其關聯公司的商標。



This content is not currently available
We will notify you via email when it becomes available

Great!
We will contact you via email if it becomes available

One lab at a time
Confirm to end all existing labs and start this one
Complete this quick step to start your lab.