GSP935

Présentation
Looker est une plate-forme de données moderne intégrée à Google Cloud. Elle vous permet d'analyser et de visualiser vos données de manière interactive. Vous pouvez utiliser Looker pour effectuer des analyses de données approfondies, intégrer des insights provenant de différentes sources de données, mettre en place des workflows exploitables basés sur les données et créer des applications de données personnalisées.
Dans cet atelier, vous allez apprendre à exploiter les tables dérivées natives pour répondre à des questions complexes, traiter des cas d'utilisation avancés et les personnaliser à l'aide de paramètres intégrés.
Points abordés
Vous allez apprendre à effectuer les tâches suivantes :
- Créer des tables dérivées natives pour répondre à des questions complexes à l'aide de colonnes dérivées
- Mettre à jour une table dérivée native pour générer des valeurs dynamiques à l'aide de paramètres de filtre intégrés
- Comprendre comment les utilisateurs professionnels exploitent les tables dérivées natives personnalisées pour répondre à des questions complexes
Prérequis :
Pour profiter pleinement de cette formation, vous devez maîtriser LookML. Nous vous recommandons de suivre le cours ouvrant droit à un badge de compétence Comprendre LookML dans Looker avant de commencer cet atelier.
Préparation
Avant de cliquer sur le bouton "Démarrer l'atelier"
Lisez ces instructions. Les ateliers sont minutés, et vous ne pouvez pas les mettre en pause. Le minuteur, qui démarre lorsque vous cliquez sur Démarrer l'atelier, indique combien de temps les ressources Google Cloud resteront accessibles.
Cet atelier pratique vous permet de suivre vous-même les activités dans un véritable environnement cloud, et non dans un environnement de simulation ou de démonstration. Nous vous fournissons des identifiants temporaires pour vous connecter à Google Cloud le temps de l'atelier.
Pour réaliser cet atelier :
- vous devez avoir accès à un navigateur Internet standard (nous vous recommandons d'utiliser Chrome) ;
Remarque : Ouvrez une fenêtre de navigateur en mode incognito/navigation privée pour effectuer cet atelier. Vous éviterez ainsi les conflits entre votre compte personnel et le compte temporaire de participant, qui pourraient entraîner des frais supplémentaires facturés sur votre compte personnel.
- vous disposez d'un temps limité ; n'oubliez pas qu'une fois l'atelier commencé, vous ne pouvez pas le mettre en pause.
Remarque : Si vous possédez déjà votre propre compte ou projet Google Cloud, veillez à ne pas l'utiliser pour réaliser cet atelier afin d'éviter que des frais supplémentaires ne vous soient facturés.
Démarrer votre atelier et vous connecter à Looker
-
Lorsque vous êtes prêt, cliquez sur Démarrer l'atelier.
Le volet "Détails concernant l'atelier" s'affiche avec les identifiants temporaires que vous devez utiliser pour cet atelier.
Si l'atelier est payant, un pop-up s'affiche pour vous permettre de sélectionner un mode de paiement.
Notez les identifiants qui vous ont été attribués pour cet atelier dans le volet "Détails concernant l'atelier". Ils vous serviront à vous connecter à l'instance Looker de cet atelier.
Remarque : Si vous utilisez d'autres identifiants, des messages d'erreur s'afficheront ou des frais seront appliqués.
-
Cliquez sur Ouvrir Looker.
-
Saisissez le nom d'utilisateur et le mot de passe fournis dans les champs Adresse e-mail et Mot de passe.
Nom d'utilisateur :
{{{looker.developer_username | Username}}}
Mot de passe :
{{{looker.developer_password | Password}}}
Important : Vous devez utiliser les identifiants fournis dans le volet "Détails concernant l'atelier" sur cette page. Ne saisissez pas vos identifiants Google Cloud Skills Boost. Si vous possédez un compte Looker personnel, ne l'utilisez pas pour cet atelier.
-
Cliquez sur Connexion.
Une fois la connexion établie, l'instance Looker de cet atelier s'affichera.
Tâche 1 : Personnaliser des tables dérivées natives à l'aide de colonnes dérivées
Les tables dérivées natives sont des tables dérivées qui remplissent la même fonction qu'une requête SQL rédigée, mais qui sont exprimées nativement dans le langage LookML.
Pourquoi utiliser des tables dérivées natives ? Repensez à la table dérivée SQL user_facts que vous avez créée dans l'atelier précédent. Vous avez appliqué COUNT sur les ID de commande avec lifetime_order_count et SUM sur sale_price avec lifetime_revenue. Si vous ne l'aviez pas encore remarqué, ces agrégations existent déjà dans votre modèle en tant que mesures. Votre vue order_items comporte déjà order_count et total_sales.
Les tables dérivées natives sont intéressantes, car elles incarnent le principe fondamental de réutilisabilité de LookML. Elles vous permettent d'hériter de dimensions, de mesures et même d'explorations et de logiques de jointure existantes. Votre modèle est ainsi beaucoup plus facile à gérer sur le long terme, car vous réduisez au minimum le nombre de références de base de données codées en dur.
Dans cette section, vous allez créer une table dérivée native nommée brand_order_facts qui contient une colonne dérivée permettant de classer les marques par revenu total et qui peut être filtrée à l'aide d'une plage de dates dynamique et/ou d'entrées utilisateur. Vous allez également créer des dimensions qui indiqueront si les lignes font partie des cinq premières marques ou non (c'est-à-dire que toutes les marques classées à partir de la sixième position seront regroupées sous le nom de marque 6) Other).
Créer une table dérivée native qui classe les cinq premières marques par total des ventes
-
Tout d'abord, en bas à gauche de l'interface utilisateur de Looker, cliquez sur le bouton d'activation pour passer en mode Développement.
-
Dans le menu de navigation Looker, cliquez sur Explorer.
-
Sous E-Commerce Training (Formation e-commerce), cliquez sur Order Items (Articles de la commande).
-
Dans la vue Inventory Items (Éléments d'inventaire), cliquez sur la dimension Product Brand (Marque du produit).
-
Dans la vue Order Items (Articles de la commande), cliquez sur la mesure Total Revenue (Revenu total).
-
Cliquez sur Exécuter.
-
Cliquez sur l'icône de paramètres en forme de roue dentée ( ) à côté de Exécuter (en haut à droite de la page), puis sélectionnez Afficher le code LookML.
) à côté de Exécuter (en haut à droite de la page), puis sélectionnez Afficher le code LookML.
-
Accédez à l'onglet Table dérivée, cliquez sur le code LookML dans la zone, puis copiez-le dans le presse-papiers.
-
Accédez à l'IDE Looker (Développer > qwiklabs-ecommerce), cliquez sur l'icône Plus (+) à côté de l'explorateur de fichiers, puis sélectionnez Créer une vue.
-
Nommez la nouvelle vue brand_order_facts, puis cliquez sur Créer.
-
Cliquez sur brand_order_facts.view et faites glisser dans le dossier views.
-
Effacez l'intégralité de l'exemple de code généré automatiquement, puis collez le code copié à partir de l'exploration. N'oubliez pas de remplacer le nom de vue généré automatiquement par brand_order_facts. Votre vue doit se présenter comme suit :
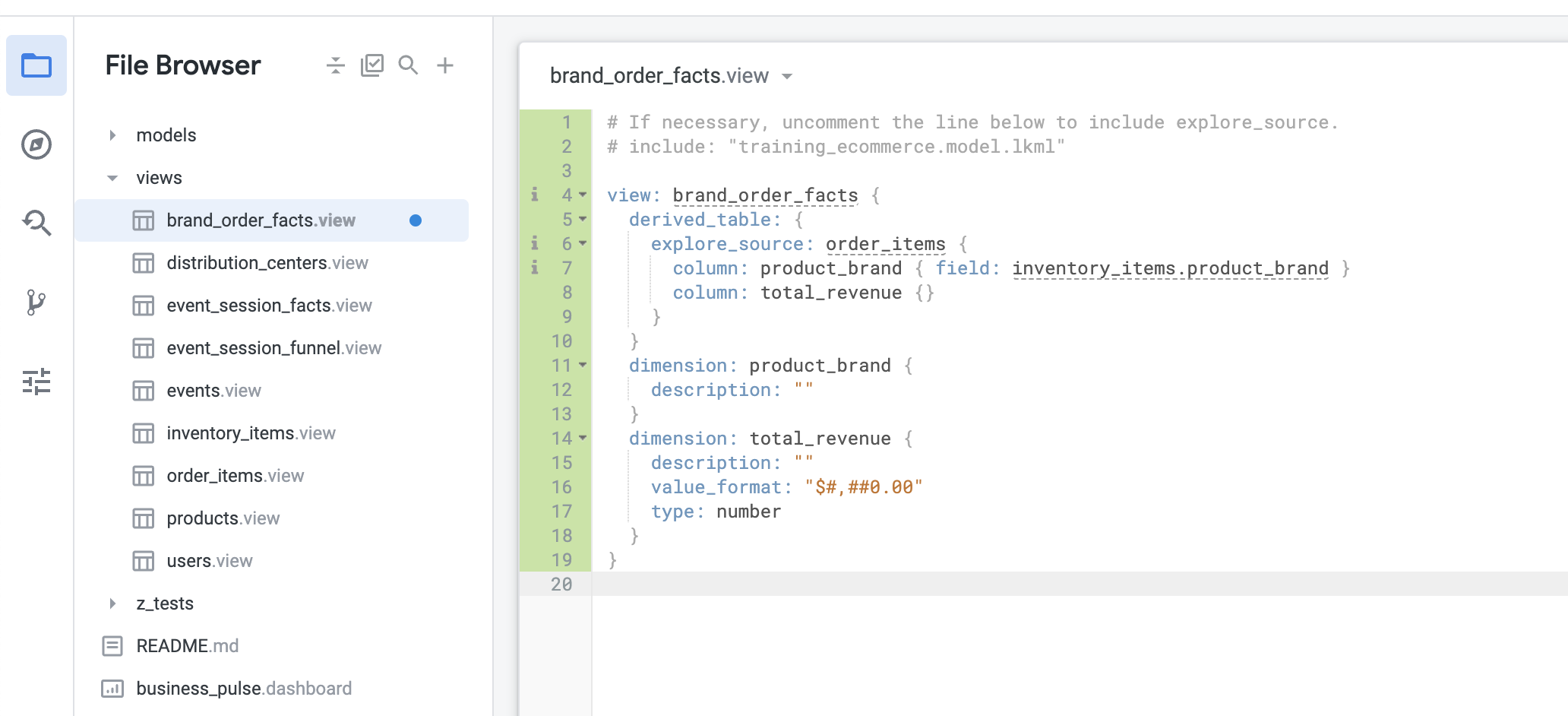
- Cliquez sur Enregistrer les modifications.
Ajouter une colonne dérivée de classement des marques
Vous avez posé les bases de votre table dérivée native. La tâche suivante consiste à classer les marques. Dans la plupart des dialectes SQL, la fonction ROW_NUMBER() permet d'y parvenir.
Pour ce faire, vous devez ajouter derived_column à explore_source pour votre table dérivée native. Dans une table dérivée native, vous pouvez utiliser derived_column pour spécifier une colonne qui n'existe pas encore dans l'exploration indiquée par le paramètre explore_source. Dans cet exemple, vous appellerez la colonne brand_rank.
- Sous la définition
column: total_revenue {}, commencez par établir la colonne dérivée brand_rank :
derived_column: brand_rank {}
- Ensuite, dans les accolades, ajoutez le paramètre SQL suivant :
derived_column: brand_rank {
sql: row_number() over (order by total_revenue desc) ;;
}
Chaque fois que vous créez une colonne dérivée, vous devez également ajouter une dimension associée. C'est le même fonctionnement que pour une colonne de votre table de base de données habituelle : la colonne doit être représentée dans LookML en tant que dimension. Avez-vous remarqué que les dimensions générées automatiquement n'ont pas de paramètre SQL ? En effet, lorsque vous ne spécifiez pas de code SQL pour une dimension, Looker suppose qu'il doit pointer vers une colonne des données sous-jacentes portant exactement le même nom que la dimension. Ce raccourci peut être utile dans d'autres parties de votre projet si cela vous convient, bien qu'il soit généralement préférable d'être explicite dans la mesure du possible. Dans ce cas, vous devez au moins fournir le type. Si vous ne le faites pas, Looker utilise le type chaîne par défaut, ce qui n'est pas souhaitable ici.
- En dehors de la définition derived_table, juste au-dessus de la dimension
product_brand, ajoutez le code suivant :
dimension: brand_rank {
type: number
}
Votre nouvelle vue doit se présenter comme suit :
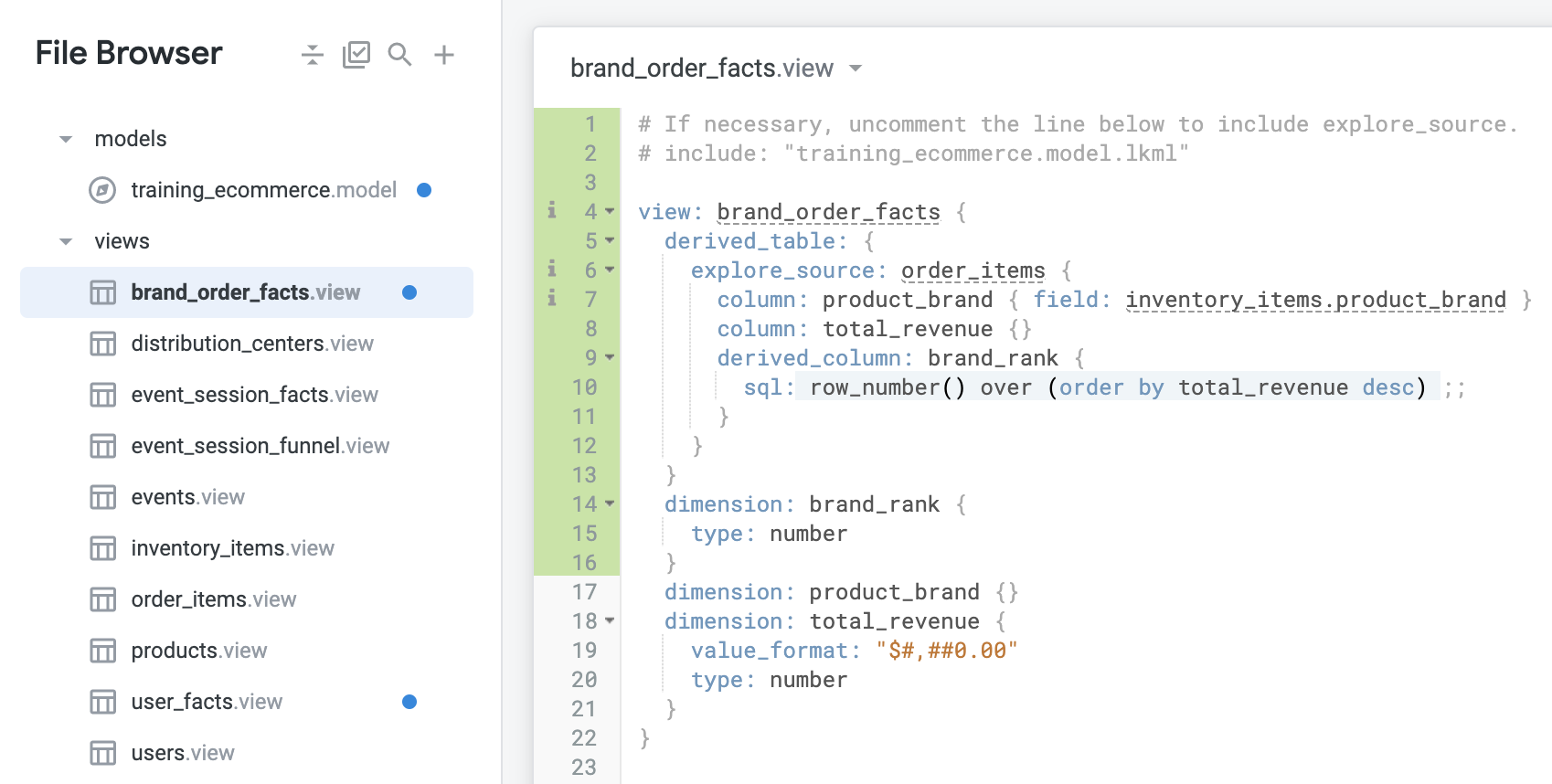
-
Cliquez sur Enregistrer les modifications.
-
Ensuite, sur la même page, cliquez sur le fichier training_ecommerce.model dans le dossier model pour modifier son contenu.
-
Recherchez la définition explore: order_items.
-
Dans la définition explore: order_items, ajoutez une nouvelle jointure pour brand_order_facts en spécifiant ce qui suit :
join: brand_order_facts {
type: left_outer
sql_on: ${inventory_items.product_brand} = ${brand_order_facts.product_brand} ;;
relationship: many_to_one
}
-
Cliquez sur Enregistrer les modifications.
-
Votre fichier de modèle doit maintenant se présenter comme suit :
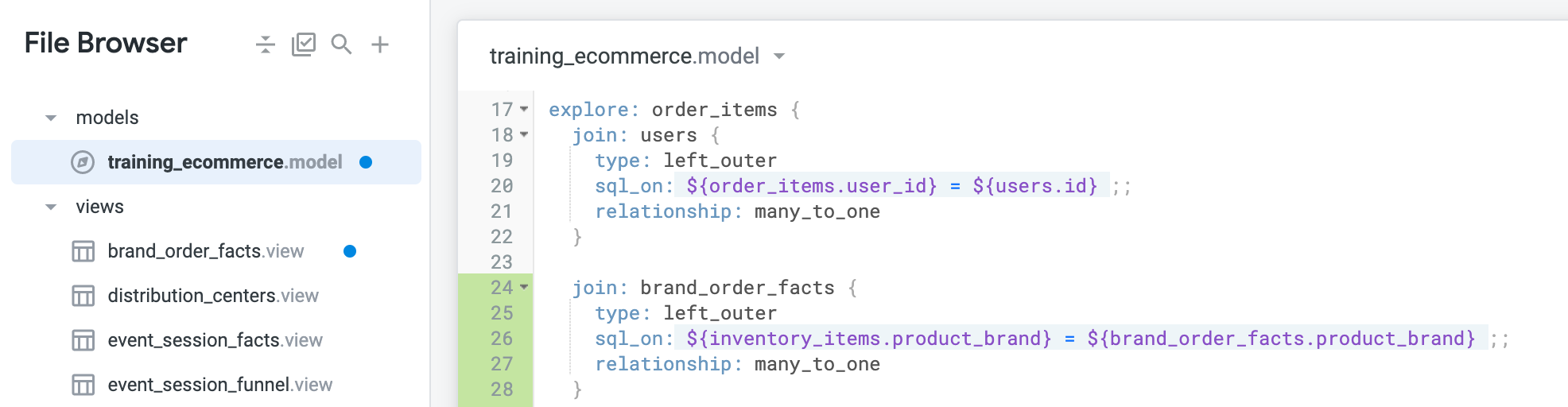
-
Maintenant que vous avez joint la vue brand_order_facts à l'exploration, accédez à la page "Exploration" pour Order Items.
-
Dans la vue Brand Order Facts (Faits sur les commandes des marques), sélectionnez les dimensions Brand Rank (Classement de la marque), Product Brand et Total Revenue.
-
Définissez la limite de lignes sur 10.
-
Cliquez sur Exécuter. Le résultat doit se présenter comme suit :
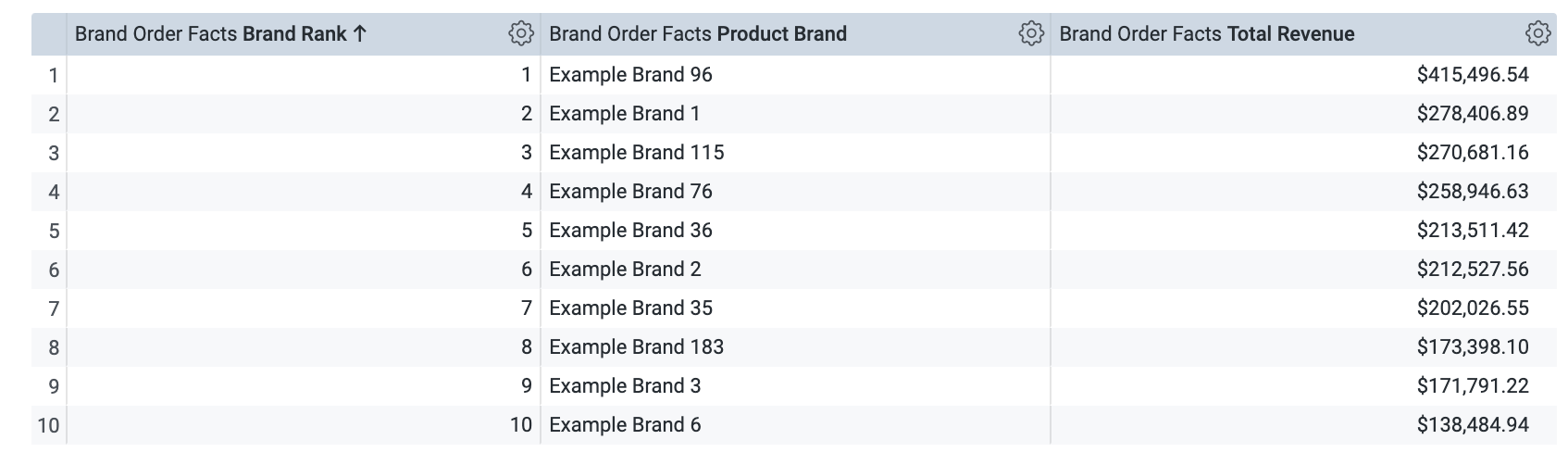
Jusque-là, tout va bien. Mais que faire si vos utilisateurs professionnels souhaitent voir les noms des marques affichés au format "1) Example Brand", et pas uniquement "Example Brand" ? Comment procéder ? Dans ce cas, vous pouvez créer une dimension qui concatène deux autres valeurs de dimension.
-
Revenez à la vue brand_order_facts.
-
Créez une autre dimension appelée brand_rank_concat, qui concatène le classement de la marque et la marque du produit :
dimension: brand_rank_concat {
type: string
sql: ${brand_rank} || ') ' || ${product_brand} ;;
}
- Masquez
brand_rank, car les utilisateurs professionnels préféreront probablement utiliser le numéro de classement dans notre nouvelle vue brand_rank_concat plutôt qu'un champ distinct :
dimension: brand_rank {
hidden: yes
type: number
}
- Ajoutez un libellé à
brand_rank_concat pour plus de convivialité. Utilisez le libellé "Brand Name" :
dimension: brand_rank_concat {
label: "Brand Name"
type: string
sql: ${brand_rank} || ') ' || ${product_brand} ;;
}
À la dernière étape, vous devrez regrouper toutes les marques classées à partir de la sixième position dans la catégorie "Other". Pour ce faire, vous allez d'abord créer une dimension "intermédiaire" qui vérifie si une marque est classée ou non parmi les cinq premières.
- Dans la vue brand_order_facts, créez une dimension nommée
brand_rank_top_5 avec les paramètres suivants :
dimension: brand_rank_top_5 {
hidden: yes
type: yesno
sql: ${brand_rank} <= 5 ;;
}
- Créez ensuite une dimension nommée
brand_rank_grouped et intégrez-y brand_rank_top_5 avec le code suivant :
dimension: brand_rank_grouped {
label: "Brand Name Grouped"
type: string
sql: case when ${brand_rank_top_5} then ${brand_rank_concat} else '6) Other' end ;;
}
- Cliquez sur Enregistrer les modifications.
La vue doit désormais se présenter comme suit :
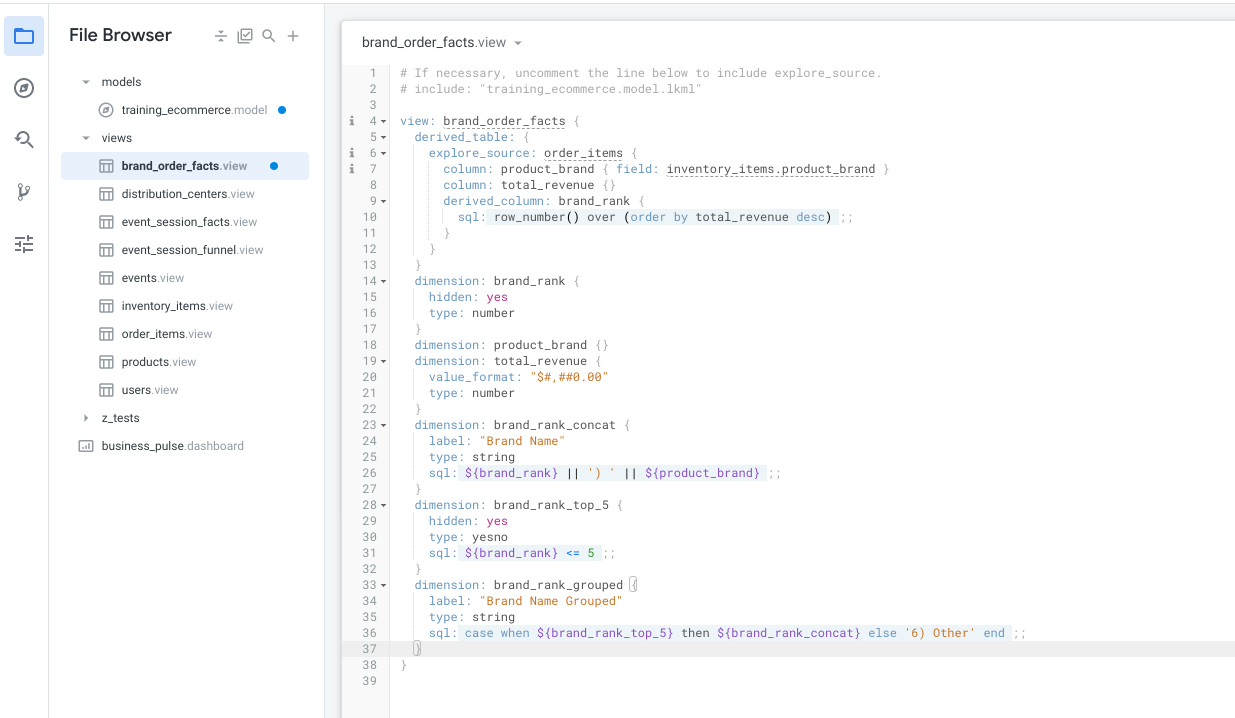
-
Revenez à la page "Exploration" pour Order Items.
-
Dans la vue Brand Order Facts, sélectionnez la dimension Brand Name Grouped (Nom de la marque, groupé).
Dans la vue Order Items, sélectionnez la mesure Total Revenue. Définissez la limite de lignes sur 10.
-
Cliquez sur Exécuter.
-
Assurez-vous que la colonne Brand Name Grouped est classée de la première à la dernière marque, puis dans l'onglet "Visualisation", cliquez sur Graphique à secteurs.
-
Vérifiez que la visualisation ressemble à ce qui suit :
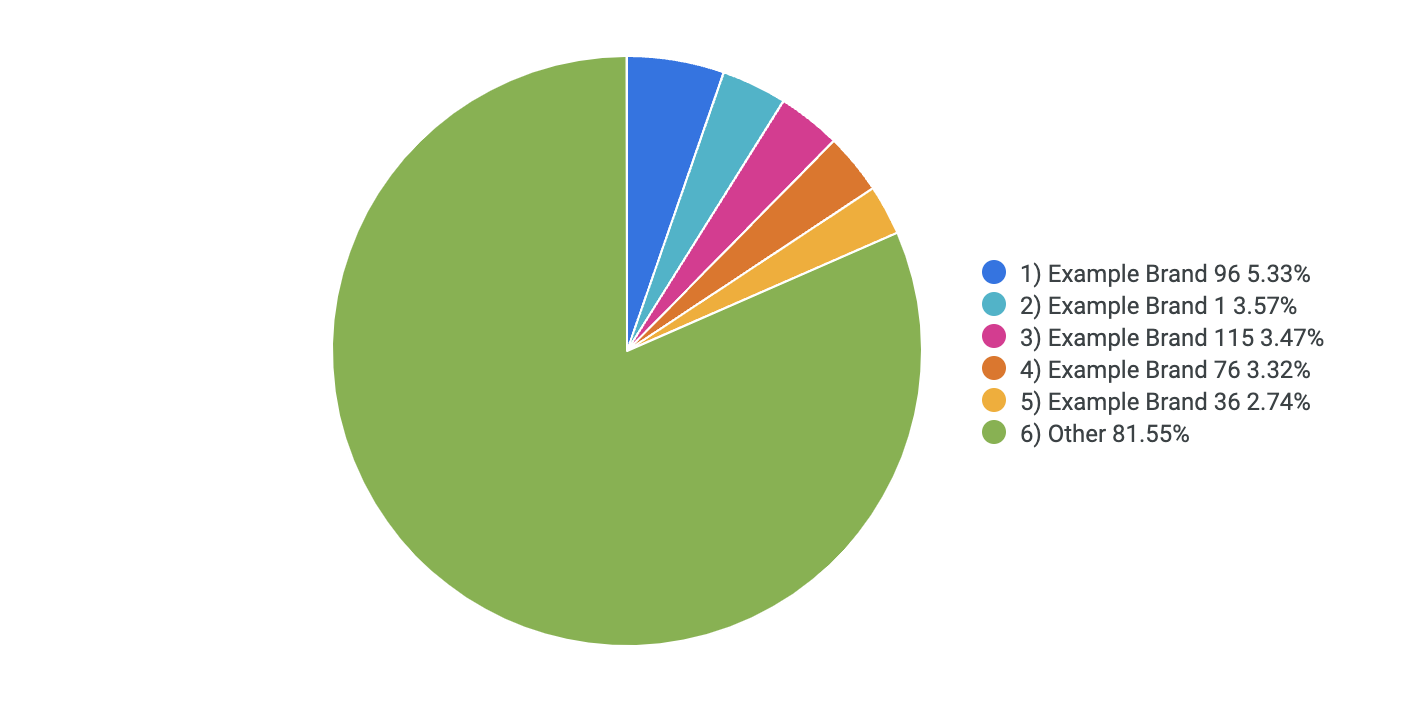
-
Cliquez sur l'icône de paramètres en forme de roue dentée () à côté de Exécuter (en haut à droite de la page), puis sélectionnez Enregistrer > En tant que Look.
-
Nommez votre Look Ranked Brand Revenue.
-
Cliquez sur Enregistrer.
-
Revenez à la vue brand_order_facts.
Valider les modifications et les déployer en production
-
Cliquez sur Valider le LookML, puis sur Valider les modifications et envoyer.
-
Ajoutez un message de commit, puis cliquez sur Valider.
-
Enfin, cliquez sur Déployer en production.
Parfait ! Nous espérons que cet atelier vous aide à comprendre à quel point il peut être utile de décomposer un cas d'utilisation ou une logique souhaitée en dimensions de base distinctes, que vous pouvez ensuite combiner ou développer pour répondre à des questions métier spécifiques. Selon les bonnes pratiques de développement LookML, il est très courant d'avoir de nombreuses dimensions et mesures "intermédiaires" cachées comme celles-ci.
Cliquez sur Vérifier ma progression pour vérifier que vous avez correctement effectué la tâche ci-dessus. Personnaliser des tables dérivées natives à l'aide de colonnes dérivées
Tâche 2 : Personnaliser des tables dérivées natives à l'aide de filtres
Imaginons à présent que l'entreprise ne s'intéresse qu'aux commandes récentes, passées au cours des 365 derniers jours. Il est possible que certaines des cinq premières marques aient été très populaires il y a quelques années en raison de tendances différentes, mais que leur classement ait changé au cours de l'année écoulée.
Dans cette section, vous allez découvrir les différents types de filtres à utiliser pour votre table dérivée native dans LookML. Les filtres peuvent être appliqués à la table dérivée, comme avec une mesure filtrée. Ce filtrage ajoute une clause WHERE ou HAVING.
Ajouter un filtre de date statique
-
Commencez par revenir à la vue brand_order_facts.
-
Sous la définition derived_column, ajoutez un filtre pour limiter la table dérivée native aux commandes créées au cours des 365 derniers jours :
filters: [order_items.created_date: "365 days"]
- Cliquez sur Enregistrer les modifications. Votre fichier doit maintenant se présenter comme suit :
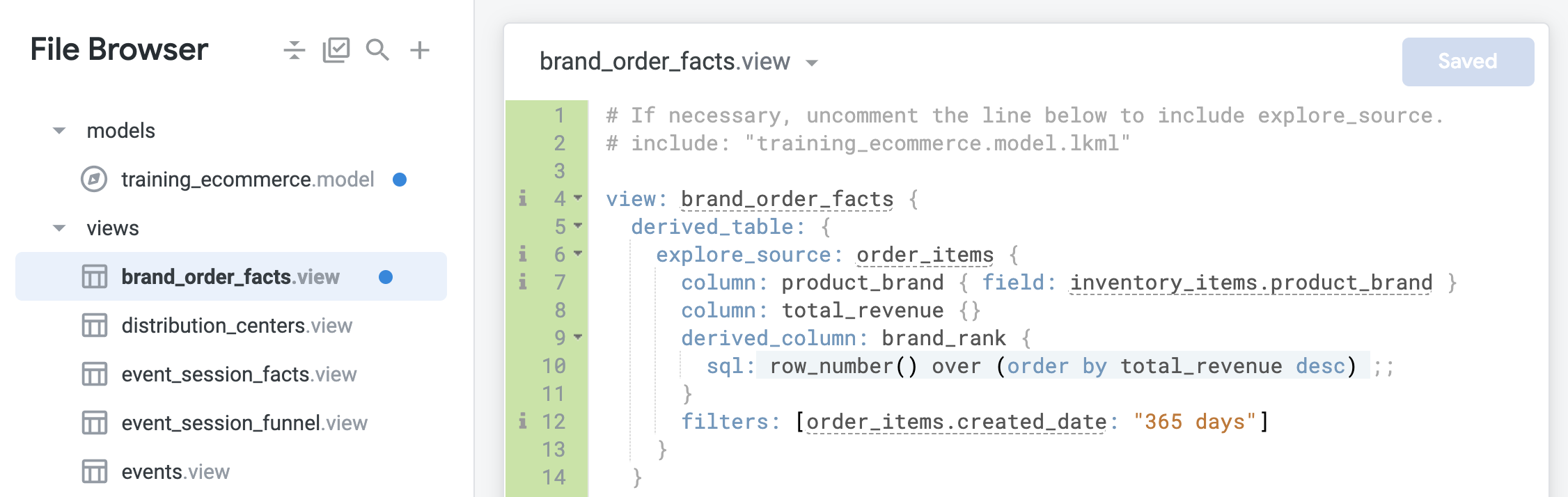
-
Revenez à l'exploration Order Items.
-
Dans la vue Brand Order Facts, sélectionnez Brand Name Grouped.
-
Dans la vue Order Items, sélectionnez la mesure Total Revenue.
-
Cliquez sur Exécuter.
-
Dans la barre Données, cliquez sur l'onglet SQL pour voir comment le filtre est utilisé dans la requête.
Puisque vous avez ajouté un filtre sur la date de création des articles commandés pour n'examiner que les commandes passées au cours des 365 derniers jours, la condition WHERE n'est générée que dans ce que l'on appelle la requête externe. Il s'agit du comportement par défaut de tout filtre de dimension. Vous ne pouvez pas lui demander d'entrer dans l'expression de table courante pour la table dérivée, ni de faire "ruisseler" la clause WHERE externe vers la requête interne. C'est là qu'il est utile d'ajouter un filtre à la NDT elle-même.
Ajouter un filtre de liaison
Que se passe-t-il si l'entreprise trouve trop rigide de limiter les données aux commandes des 365 derniers jours ? Les utilisateurs souhaiteront peut-être parfois analyser les classements des deux dernières années. Avec filters: [order_items.created_date: "365 days"], vous codez en dur la période.
Le paramètre bind_filters peut alors devenir plus utile que les simples filtres. Vous pouvez indiquer le champ de l'exploration externe que vous souhaitez faire "ruisseler" vers la requête interne de la table dérivée native (from_field) et le champ de la table dérivée native auquel il doit être mappé (to_field). La plupart du temps, les deux champs doivent être identiques.
Le sous-paramètre bind_filters de explore_source transmet un filtre spécifique de la requête d'exploration à la sous-requête de la table dérivée native :
-
to_field correspond au champ de la table dérivée native auquel le filtre est appliqué. Le champ to_field doit être un champ de la source explore_source sous-jacente.
-
from_field spécifie le champ de l'exploration à partir de laquelle obtenir le filtre, si l'utilisateur indique un filtre lors de l'exécution.
-
Revenez à la vue brand_order_facts.
-
Pour utiliser le filtre de liaison, commencez par supprimer le filtre de date statique de la définition de table dérivée que vous avez créée dans la section précédente.
-
Ensuite, ajoutez le modèle bind_filters suivant dans la définition derived_column :
bind_filters: {
from_field: # The field the end user interacts with via the filters area
to_field: # The field which should be filtered inside the NDT
}
Dans ce cas, vous voulez prendre le filtre from_field: order_items.created_date, et le faire influer ou s'appliquer sur to_field: order_items.created_date.
- Ajoutez le code suivant pour les champs de filtre de liaison :
bind_filters: {
from_field: order_items.created_date
to_field: order_items.created_date
}
Remarque : Cela équivaut à ajouter un filtre basé sur un modèle à la table dérivée SQL. Comme vous l'avez vu dans l'atelier précédent, un filtre basé sur un modèle a été ajouté à une table dérivée SQL. Les utilisateurs peuvent ainsi choisir une date et voir les valeurs se mettre à jour en fonction de cette date.
- Cliquez sur Enregistrer les modifications. Votre fichier doit se présenter comme suit :
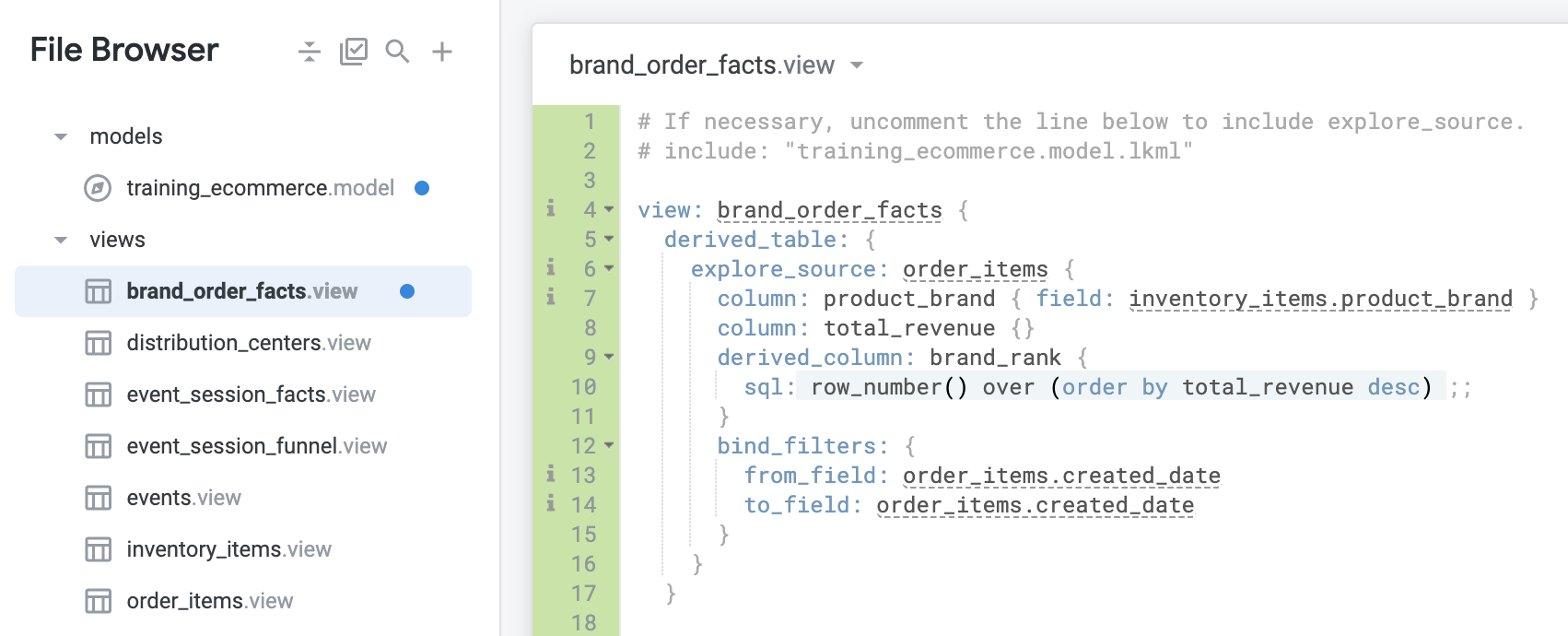
-
Revenez à l'exploration Order Items.
-
Dans la vue Brand Order Facts, sélectionnez Brand Name Grouped.
-
Dans la vue Order Items, sélectionnez la mesure Total Revenue.
-
Toujours dans la vue Order Items, dans la dimension Created Date (Date de création), sélectionnez le champ Date, puis le bouton de filtre à côté de Date.
-
Dans la définition du filtre, spécifiez ce qui suit : is in the past 1000 days. À des fins de démonstration, utilisez 1 000 jours pour vous assurer que le filtre n'est pas trop restrictif et qu'il capture les trois dernières années.
-
Cliquez sur Exécuter.

- Dans la barre Données, cliquez sur l'onglet SQL pour voir comment le filtre est utilisé dans la requête. Notez que le code SQL généré met désormais à jour de manière dynamique la condition WHERE dans l'expression de table courante pour la table dérivée, ainsi que la condition WHERE externe.
Comme vous pouvez le constater, cette méthode est beaucoup plus flexible. Si vous filtrez les données sur les commandes créées au cours des trois derniers trimestres, la table dérivée native calcule les classements en conséquence. Si vous filtrez les données sur les commandes créées dans une plage de dates spécifique, la table dérivée native utilise cette même plage de dates dans sa condition WHERE.
-
Maintenant, dans le champ Users (Utilisateurs), sélectionnez Country (Pays) et Age (Âge), puis ajoutez un filtre pour chacun d'eux : Country is equal to USA et Age is greater than 21.
-
Cliquez sur Exécuter.
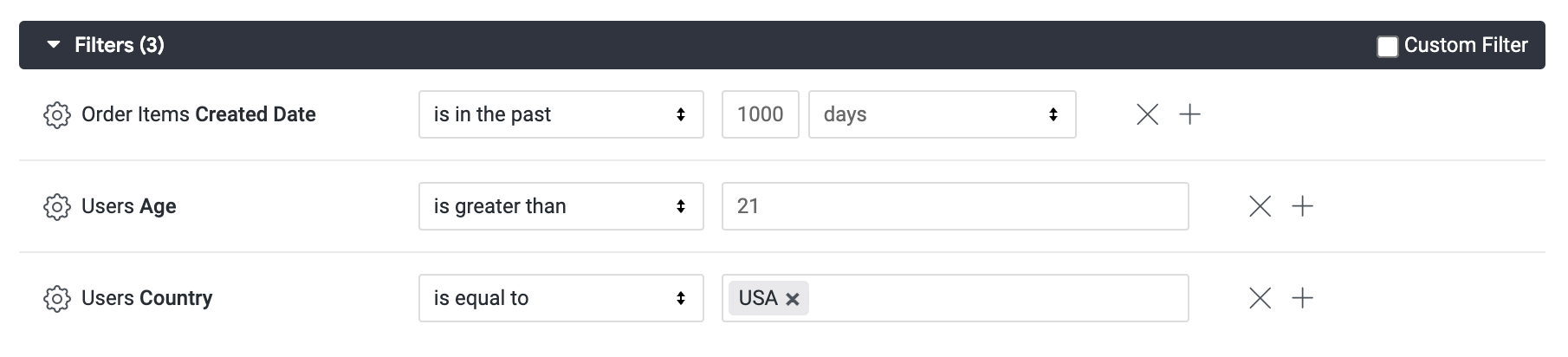
- Enfin, cliquez sur l'onglet SQL.
Notez que la condition WHERE de la table dérivée n'est pas affectée. Que se passe-t-il si les utilisateurs professionnels ont d'autres critères que la date de création des articles commandés ? S'ils ne souhaitent voir que le classement des commandes passées par des clients aux États-Unis ou par des clients de genre masculin ?
Vous pourriez continuer à ajouter des filtres bind_filters, mais regardez le nombre de champs dont vous disposez dans l'exploration "Order Items". Ajouter des filtres bind_filters pour chacun d'eux prendrait une éternité. C'est là qu'un autre paramètre peut s'avérer extrêmement utile : bind_all_filters.
Cliquez sur Vérifier ma progression pour vérifier que vous avez correctement effectué la tâche ci-dessus. Personnaliser des tables dérivées natives à l'aide de filtres
Utiliser bind_all_filters
Le moyen le plus simple de transmettre des filtres d'une exploration à une sous-requête de table dérivée native consiste à spécifier bind_all_filters: yes dans le paramètre explore_source de la table dérivée native. Vous transmettez ainsi tous les filtres d'exécution d'une exploration à la sous-requête de la table dérivée native.
Si vous souhaitez utiliser la table dérivée native dans une autre exploration, appliquez plutôt le paramètre bind_filters, comme décrit dans la section précédente.
-
Commencez par supprimer le filtre bind_filter dans la définition de table dérivée que vous avez créée dans la section précédente.
-
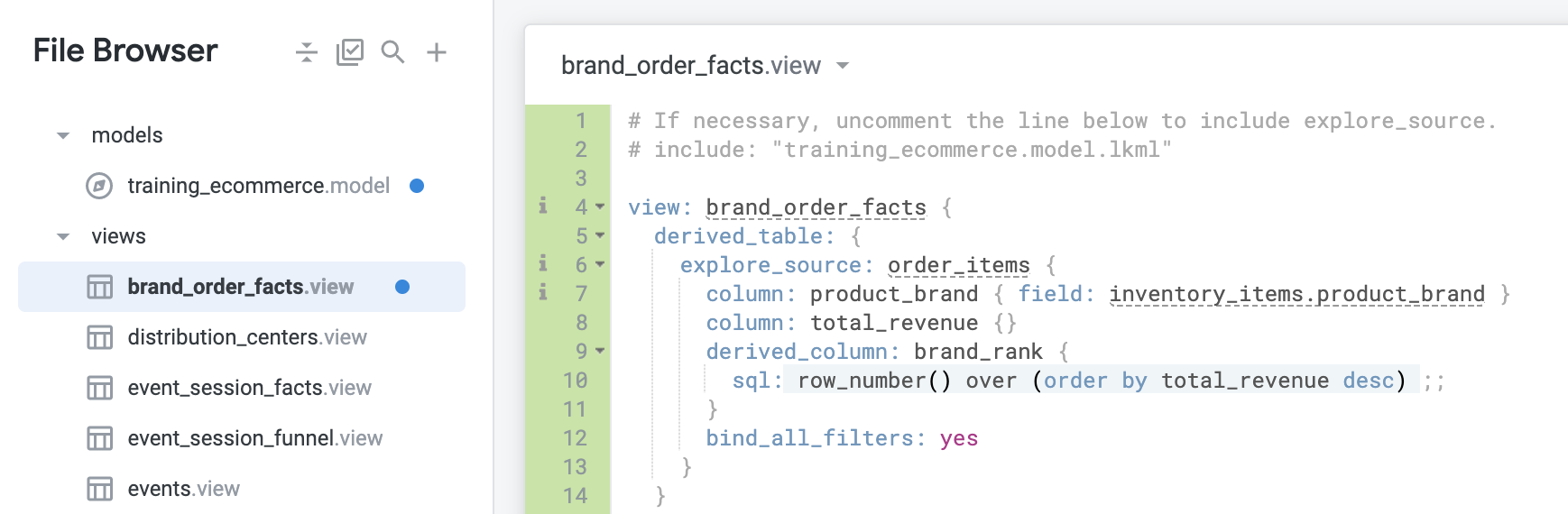
Ajoutez la définition bind_all_filters: yes sous la définition derived_column pour lier non seulement order_created_date à lui-même, mais aussi chaque filtre à lui-même :
bind_all_filters: yes
- Cliquez sur Enregistrer les modifications. Votre fichier doit se présenter comme suit :
-
Revenez à l'exploration Order Items.
-
Dans la vue Brand Order Facts, sélectionnez Brand Name Grouped.
-
Dans la vue Order Items, sélectionnez la mesure Total Revenue.
-
Toujours dans la vue Order Items, recherchez la dimension Created Date, puis cliquez sur le bouton de filtre à côté de Date.
-
Dans la définition du filtre, spécifiez ce qui suit : is in the past 365 days.
-
Dans la vue Users, ajoutez un filtre sur Country et Age : Country is equal to USA et Age is greater than 21.
-
Cliquez sur Exécuter.
-
Cliquez sur l'onglet SQL. Notez que la condition WHERE de la table dérivée est désormais mise à jour de manière dynamique.
Bien que bind_all_filters soit une excellente méthode, elle ne fonctionne que lorsque vous avez joint la table dérivée native à sa source explore_source. En d'autres termes, vous ne pouvez l'utiliser ici que parce que vous avez joint brand_order_facts à la même exploration que explore_source, order_items.
Pourquoi ? Car bind_all_filters signifie que Looker doit savoir comment générer une condition WHERE pour n'importe quel champ dans l'ensemble de l'exploration. Si votre table dérivée native utilise une source explore_source de order_items, mais que vous la joignez à une autre exploration, cette autre exploration peut comporter un nombre quelconque de vues et de champs joints qui n'existent pas dans order_items et qui, par conséquent, n'auraient aucun sens dans le contexte de order_items. Looker ne saurait pas comment filtrer la table dérivée avec ces autres champs.
Maintenant que vous avez vu bind_all_filters en action, testez différents filtres d'exploration et voyez leur impact sur la compilation de la table dérivée native.
- Revenez à la vue brand_order_facts.
Valider les modifications et les déployer en production
-
Cliquez sur Valider le LookML, puis sur Valider les modifications et envoyer.
-
Ajoutez un message de commit, puis cliquez sur Valider.
-
Enfin, cliquez sur Déployer en production.
Félicitations !
Dans cet atelier, vous avez utilisé des tables dérivées natives pour répondre à des questions complexes et traiter des cas d'utilisation avancés à l'aide de colonnes dérivées. Vous les avez ensuite mises à jour pour générer des valeurs dynamiques à l'aide de paramètres de filtre intégrés. Vous avez également appris comment les utilisateurs professionnels exploitent les tables dérivées natives personnalisées pour répondre à des questions complexes.
Étapes suivantes et informations supplémentaires
Formations et certifications Google Cloud
Les formations et certifications Google Cloud vous aident à tirer pleinement parti des technologies Google Cloud. Nos cours portent sur les compétences techniques et les bonnes pratiques à suivre pour être rapidement opérationnel et poursuivre votre apprentissage. Nous proposons des formations pour tous les niveaux, à la demande, en salle et à distance, pour nous adapter aux emplois du temps de chacun. Les certifications vous permettent de valider et de démontrer vos compétences et votre expérience en matière de technologies Google Cloud.
Dernière mise à jour du manuel : 4 mars 2024
Dernier test de l'atelier : 4 mars 2024
Copyright 2026 Google LLC. Tous droits réservés. Google et le logo Google sont des marques de Google LLC. Tous les autres noms d'entreprises et de produits peuvent être des marques des entreprises auxquelles ils sont associés.





