
Before you begin
- Labs create a Google Cloud project and resources for a fixed time
- Labs have a time limit and no pause feature. If you end the lab, you'll have to restart from the beginning.
- On the top left of your screen, click Start lab to begin
Enable the Document AI API
/ 10
Create and test a general form processor
/ 20
Authenticate API requests and Download the sample form
/ 20
Call the Document AI API using curl
/ 20
Test a Document AI form processor using the Python client libraries
/ 10
Run the Document AI Python code
/ 20
Enable the Document AI API
/ 10
Create and test a general form processor
/ 20
Authenticate API requests and Download the sample form
/ 20
Call the Document AI API using curl
/ 20
Test a Document AI form processor using the Python client libraries
/ 10
Run the Document AI Python code
/ 20

Document AI API 是文件解讀解決方案,可擷取文件和電子郵件等非結構化資料,方便您解讀、分析和使用。本實驗室使用的一般表單處理器,可從簡單的文件中擷取鍵/值組合。
在本實驗室,您將瞭解如何使用 Document AI 建立文件剖析器、透過 Google Cloud 控制台和指令列提交文件進行處理,以及使用 Python 發出同步 API 呼叫。
您將瞭解如何執行下列工作:
請詳閱以下操作說明。實驗室活動會計時,且中途無法暫停。點選「Start Lab」後就會開始計時,顯示可使用 Google Cloud 資源的時間。
您將在真正的雲端環境完成實作實驗室活動,而不是模擬或示範環境。為此,我們會提供新的暫時憑證,供您在實驗室活動期間登入及存取 Google Cloud。
為了順利完成這個實驗室,請先確認:
按一下「Start Lab」按鈕。如果實驗室會產生費用,請在開啟的對話方塊中選取付款方式。右側的「Lab setup and access」面板會顯示下列項目:
請注意,實驗室計時器位於頁面頂端附近,會顯示剩餘時間。
按一下「Open Google Cloud console」。如果使用 Chrome 瀏覽器,也可以按一下滑鼠右鍵,選取「在無痕視窗中開啟連結」。
接著,實驗室會啟動相關資源,並開啟另一個分頁,顯示「登入」頁面。
提示:您可以在不同的視窗並排開啟分頁。
如有必要,請將下方的 Username 貼到「登入」對話方塊。
您也可以在「Lab setup and access」面板找到「Username」。
點選「下一步」。
複製下方的 Password,並貼到「歡迎使用」對話方塊。
您也可以在「Lab setup and access」面板找到「Password」。
點選「下一步」。
繼續點按後續頁面:
Google Cloud 控制台稍後會在這個分頁開啟。

Cloud Shell 是搭載多項開發工具的虛擬機器,提供永久的 5 GB 主目錄,而且在 Google Cloud 中運作。Cloud Shell 提供指令列存取權,方便您使用 Google Cloud 資源。
點按 Google Cloud 控制台頂端的「啟用 Cloud Shell」圖示 
系統顯示視窗時,請按照下列步驟操作:
連線建立完成即代表已通過驗證,而且專案已設為您的 Project_ID:
gcloud 是 Google Cloud 的指令列工具,已預先安裝於 Cloud Shell,並支援 Tab 鍵自動完成功能。
輸出內容:
輸出內容:
gcloud 的完整說明,請前往 Google Cloud 參閱 gcloud CLI 總覽指南。
在這項工作中,您將啟用 Document AI API,然後建立及測試一般表單處理器。一般表單處理器能處理任何類型的文件,並將文件中可辨識的所有文字內容擷取出來。這類處理器支援數種語言,不僅能處理印刷、手寫和以任意方向書寫的文字,還可解讀各項表單資料元素間的關係,方便您從含有文字標籤的表單欄位擷取鍵/值組合。
您必須先啟用 API,才能使用 Document AI。
依序點選「導覽選單」圖示 
搜尋「Cloud Document AI API」,然後點選「啟用」按鈕,即可在 Google Cloud 專案中使用這個 API。
如果先前已啟用 Cloud Document AI API,畫面上會顯示「管理」按鈕,表示您可繼續完成後續的實驗室活動。
點選「Check my progress」,確認目標已達成。
接著,您將使用 Document AI 表單剖析器建立 Document AI 處理器。
前往控制台,依序點選「導覽選單」圖示
點選「探索處理器」。
點選「Form Parser」 (一般處理器的一種)。
將處理器名稱設為 form-parser,然後從清單中選取「US (美國)」。
點選「建立」,即可建立 form-parser 處理器。
系統會建立處理器,並返回處理器詳細資料頁面,當中會顯示處理器 ID、狀態和預測端點。
curl 對 API 發出 POST 呼叫。在這項工作中,您將從 Cloud Storage 下載範例表單。下一個工作需要上傳這份表單,因此請先將表單下載到本機電腦。
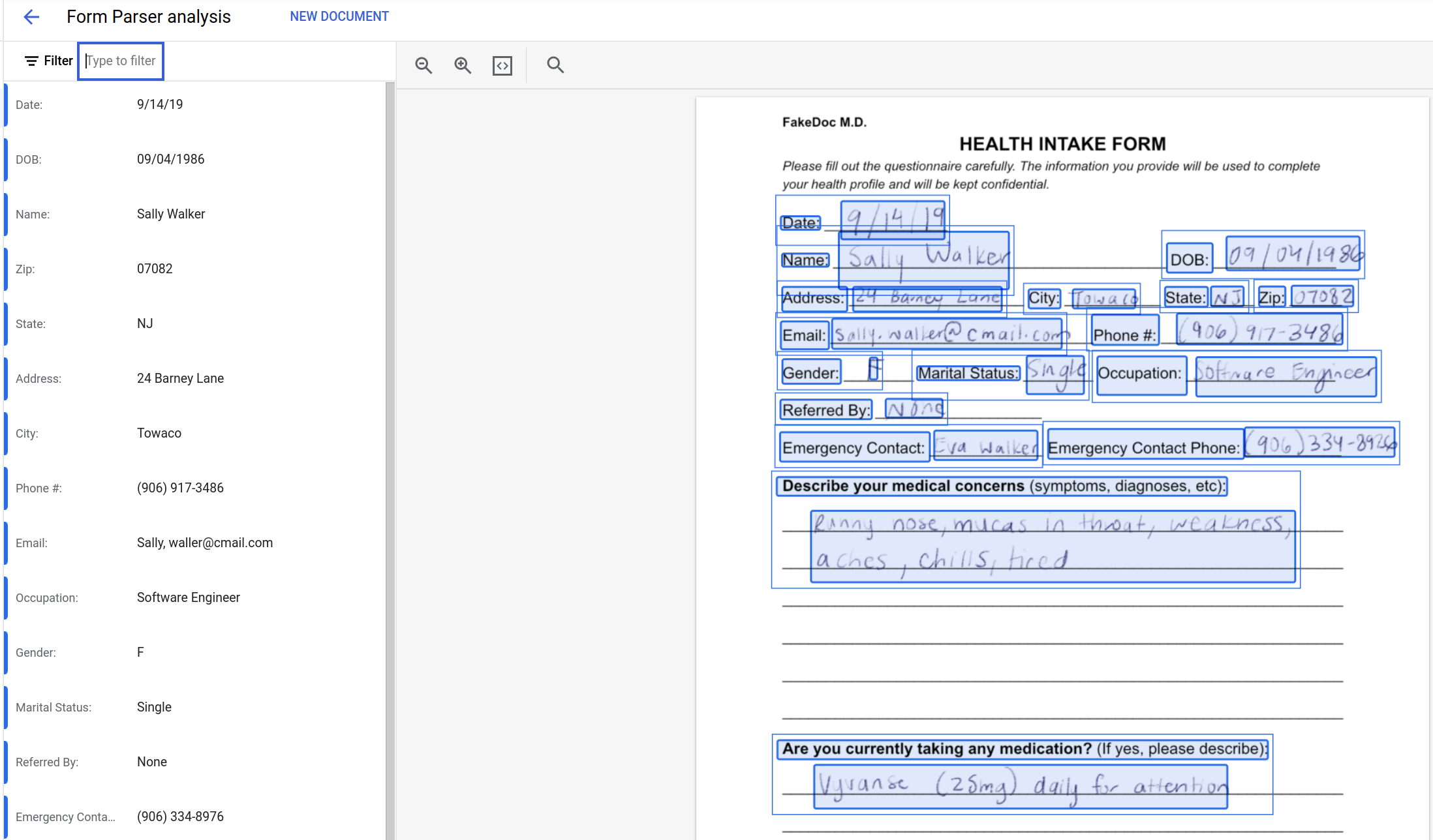
檔案應該會直接下載到本機;如果在瀏覽器中開啟,請使用瀏覽器的檔案控制項下載檔案。form.pdf 檔案是一份健康資料登記表,內含手寫範例資料。
接著,您要將下載的範例表單上傳至 form-parser 處理器。系統會分析檔案,並在控制台顯示結果。
進度列會顯示分析程序的完成程度,完成後就會顯示結果。您會看到一般處理器已擷取表單中的資料,並轉換為一組鍵/值組合。
控制台會顯示從來源文件剖析出的鍵/值組合。左側窗格會列出資料,右側窗格則會以藍色矩形標示資料在已剖析文件中的原始位置。檢查輸出內容,並比對結果與來源資料。
在這項工作中,您將從指令列發出 API 呼叫,測試 Document AI 一般表單處理器。
點選「Check my progress」,確認目標已達成。
在本節中,您將設定實驗室執行個體,以使用 Document AI API。
您將在名為 document-ai-dev 的實驗室 VM 中完成其餘實驗室工作。
依序點選「導覽選單」圖示
點選 VM 執行個體「document-ai-dev」的「SSH」連結。
這個步驟需使用您在工作 1 建立的 Document AI 處理器 ID。如果剛才未記下,請在 Cloud 控制台分頁執行下列操作:
)。[your processor id] 預留位置文字改成自己的處理器 ID:本實驗室的後續步驟都會用到這個 SSH 工作階段。
您必須提供有效的憑證,才能向 Document AI API 發出要求。在這項工作中,您將建立服務帳戶,並將授予該服務帳戶的權限限制為實驗室所需的權限,然後為該帳戶產生憑證,用於驗證 Document AI API 要求。
key.json 的 JSON 檔案:GOOGLE_APPLICATION_CREDENTIALS 環境變數並指向憑證檔案,程式庫會使用這個變數尋找您的憑證:GOOGLE_APPLICATION_CREDENTIALS 環境變數已設為先前建立的 JSON 憑證檔案完整路徑:gcloud 指令列工具會使用這個環境變數,指定執行指令時要使用的憑證。如要進一步瞭解這種驗證方式,請參閱應用程式預設憑證指南。
現在您可以下載範例表單,然後以 Base64 編碼再提交至 Document AI API。
點選「Check my progress」,確認目標已達成。
在這項工作中,您將使用 curl 呼叫同步 Document AI API 端點,處理範例文件。
curl 提交表單以供處理。結果會儲存在 output.json 檔案:output.json 檔案包含 API 呼叫結果:GOOGLE_APPLICATION_CREDENTIALS 環境變數設為指向先前建立的憑證 JSON 檔案。IAM 政策可能需要幾分鐘才會生效,如果收到錯誤訊息,請稍後再試。
Cloud IAM 服務帳戶的存取權杖會即時產生,並透過 Authorization: HTTP 標頭傳遞至 API。回應包含 JSON 格式的資料,該資料會儲存至 output.json 檔案。
接著來看看從範例表單擷取的資訊。
輸出內容會列出在上傳文件中偵測到的所有文字。
輸出內容會列出文件中偵測到的所有表單欄位的物件資料。您可以使用每個表單的 textAnchor.startIndex 和 textAnchor.endIndex 值,在 document.text 欄位中找出偵測到的表單名稱。下一項工作會用到的 Python 指令碼,可為您完成這項對應作業。
JSON 檔案相當大,因為其中包含以 Base64 編碼的來源文件,以及所有偵測到的文字和文件屬性。如要查看 JSON 檔案,可以用文字編輯器開啟,或使用 jq 等 JSON 查詢工具。
使用 Python Document AI 用戶端程式庫,對 Document AI API 發出同步呼叫。
現在,您要使用同步端點處理文件。使用非同步 API,即可一次處理大量文件。如要進一步瞭解如何使用 Document AI API,請參閱這份指南。
如要直接執行 Python 指令碼,必須提供適當憑證,才能使用已設定正確權限的服務帳戶,對 API 發出呼叫。如要進一步瞭解如何設定這種驗證方式,請參閱「以服務帳戶進行驗證」說明文件。
現在要將 Python Google Cloud 用戶端程式庫安裝至 VM 執行個體。
如果出現「Do you want to continue? (Y/n)」這個提示訊息,請輸入 Y。
輸出內容應該會指出程式庫已安裝成功。
請花點時間檢查範例檔案中的 Python 程式碼。您可以使用 vi 或 nano 等編輯器,在 SSH 工作階段中查看程式碼,也可以使用前一節的指令,將範例程式碼複製到 Cloud Shell,然後使用程式碼編輯器查看原始碼。
process_document 函式可對 Document AI 處理器發出同步呼叫。這個函式會建立 Document AI API 用戶端物件。API 呼叫所需的處理器名稱會透過 project_id、location 和 processor_id 這些參數建立,接著會讀取要處理的文件,並以 mime_type 結構儲存該文件。
隨後會將處理器名稱和文件傳遞至 Document AI API 用戶端物件,並發出同步 API 呼叫。如果要求順利完成,處理器將傳回文件物件,當中的屬性包含 Document AI 處理器偵測到的資料。
process_document 函式,並將回應儲存在 document 變數中。.text 屬性,其中包含在文件中偵測到的所有文字,並使用表單剖析器偵測到的每個表單欄位的文字錨點資料,來顯示表單資訊。點選「Check my progress」,確認目標已達成。
執行程式碼範例,並處理與先前相同的檔案。
synchronous_doc_ai.py Python 程式:您會看到以下這段文字輸出內容:
第一段文字是單一文字元素,包含文件中的所有文字。這段文字無法辨識表單型資料,因此 Date 和 Name 等項目會混雜在原始文字值中。
接著,程式碼會使用 form-parser 從文件結構推論出的表單資料,輸出結構更完整的資料檢視畫面。這項結構化輸出內容也包含表單欄位名稱和值的可信度分數。這個部分輸出的內容,會更清楚呈現表單欄位名稱與值的對應關係,例如 Date 和 Name 表單欄位與正確值的連結。
點選「Check my progress」,確認目標已達成。
您已成功透過 Document AI API,使用一般表單處理器從文件中擷取資料。在本實驗室中,您使用控制台和指令列建立並測試了 Document AI 處理器,並透過 Python 發出 Document AI 同步 API 呼叫。
協助您瞭解如何充分運用 Google Cloud 的技術。我們的課程會介紹專業技能和最佳做法,讓您可以快速掌握要領並持續進修。我們提供從基本到進階等級的訓練課程,並有隨選、線上和虛擬課程等選項,方便您抽空參加。認證可協助您驗證及證明自己在 Google Cloud 技術方面的技能和專業知識。
使用手冊上次更新日期:2026 年 3 月 10 日
實驗室上次測試日期:2026 年 3 月 10 日
Copyright 2026 Google LLC 保留所有權利。Google 和 Google 標誌是 Google LLC 的商標,其他公司和產品名稱則有可能是其關聯公司的商標。



This content is not currently available
We will notify you via email when it becomes available

Great!
We will contact you via email if it becomes available

One lab at a time
Confirm to end all existing labs and start this one
Complete this quick step to start your lab.