Mettez en pratique vos compétences dans la console Google Cloud
Points de contrôle
Launch Vertex AI Workbench instance
Vérifier ma progression
/ 50
Clone a course repo within your JupyterLab interface
Vérifier ma progression
/ 50
Instructions et exigences de configuration de l'atelier
Protégez votre compte et votre progression. Utilisez toujours une fenêtre de navigation privée et les identifiants de l'atelier pour exécuter cet atelier.
Visualisations avancées avec TensorFlow Data Validation
Ce contenu n'est pas encore optimisé pour les appareils mobiles.
Pour une expérience optimale, veuillez accéder à notre site sur un ordinateur de bureau en utilisant un lien envoyé par e-mail.
Présentation
Cet atelier vous explique comment utiliser TensorFlow Data Validation (TFDV) pour examiner et visualiser votre ensemble de données. Ceci inclut l'examen des statistiques descriptives, l'inférence d'un schéma, la recherche et la correction d'anomalies, ainsi que la détection de dérives et de biais dans votre ensemble de données. Il est essentiel de comprendre les caractéristiques de votre ensemble de données, y compris la façon dont il peut évoluer dans votre pipeline de production au fil du temps. De même, il est important de rechercher des anomalies dans vos données, et de comparer vos ensembles de données d'entraînement, d'évaluation et de mise en service pour vous assurer de leur cohérence.
Objectifs de l'atelier
Vous allez découvrir comment :
installer TFDV ;
calculer et visualiser des statistiques ;
inférer un schéma ;
rechercher des erreurs dans les données d'évaluation ;
rechercher et corriger les anomalies de l'évaluation ;
rechercher les dérives et les écarts ;
figer le schéma.
Configurer l'environnement de votre atelier
Démarrer l'atelier
Pour chaque atelier, nous vous attribuons un nouveau projet Google Cloud et un nouvel ensemble de ressources pour une durée déterminée, sans frais.
Connectez-vous à Google Skills dans une fenêtre de navigation privée.
Vérifiez le temps imparti pour l'atelier (par exemple : 01:15:00) : vous devez pouvoir le terminer dans ce délai.
Une fois l'atelier lancé, vous ne pouvez pas le mettre en pause. Si nécessaire, vous pourrez le redémarrer, mais vous devrez tout reprendre depuis le début.
Lorsque vous êtes prêt, cliquez sur Démarrer l'atelier.
Notez vos identifiants pour l'atelier (Nom d'utilisateur et Mot de passe). Ils vous serviront à vous connecter à la console Google Cloud.
Cliquez sur Ouvrir la console Google.
Cliquez sur Utiliser un autre compte, puis copiez-collez les identifiants de cet atelier lorsque vous y êtes invité.
Si vous utilisez d'autres identifiants, des messages d'erreur s'afficheront ou des frais seront appliqués.
Acceptez les conditions d'utilisation et ignorez la page concernant les ressources de récupération des données.
Tâche 1 : Lancer une instance Vertex AI Workbench
Dans le menu de navigation () de la console Google Cloud, sélectionnez Vertex AI.
Cliquez sur Activer toutes les API recommandées.
Dans le menu de navigation, cliquez sur Workbench.
En haut de la page "Workbench", vérifiez que vous vous trouvez dans la vue Instances.
Cliquez sur Créer.
Configurez l'instance :
Nom : lab-workbench
Région : définissez la région sur
Zone : définissez la zone sur
Options avancées (facultatif) : si nécessaire, cliquez sur "Options avancées" pour une personnalisation plus avancée (par exemple, type de machine, taille du disque).
Cliquez sur Créer.
La création de l'instance prend quelques minutes. Une coche verte apparaît à côté de son nom quand elle est prête.
Cliquez sur Ouvrir JupyterLab à côté du nom de l'instance pour lancer l'interface JupyterLab. Un nouvel onglet s'ouvre alors dans votre navigateur.
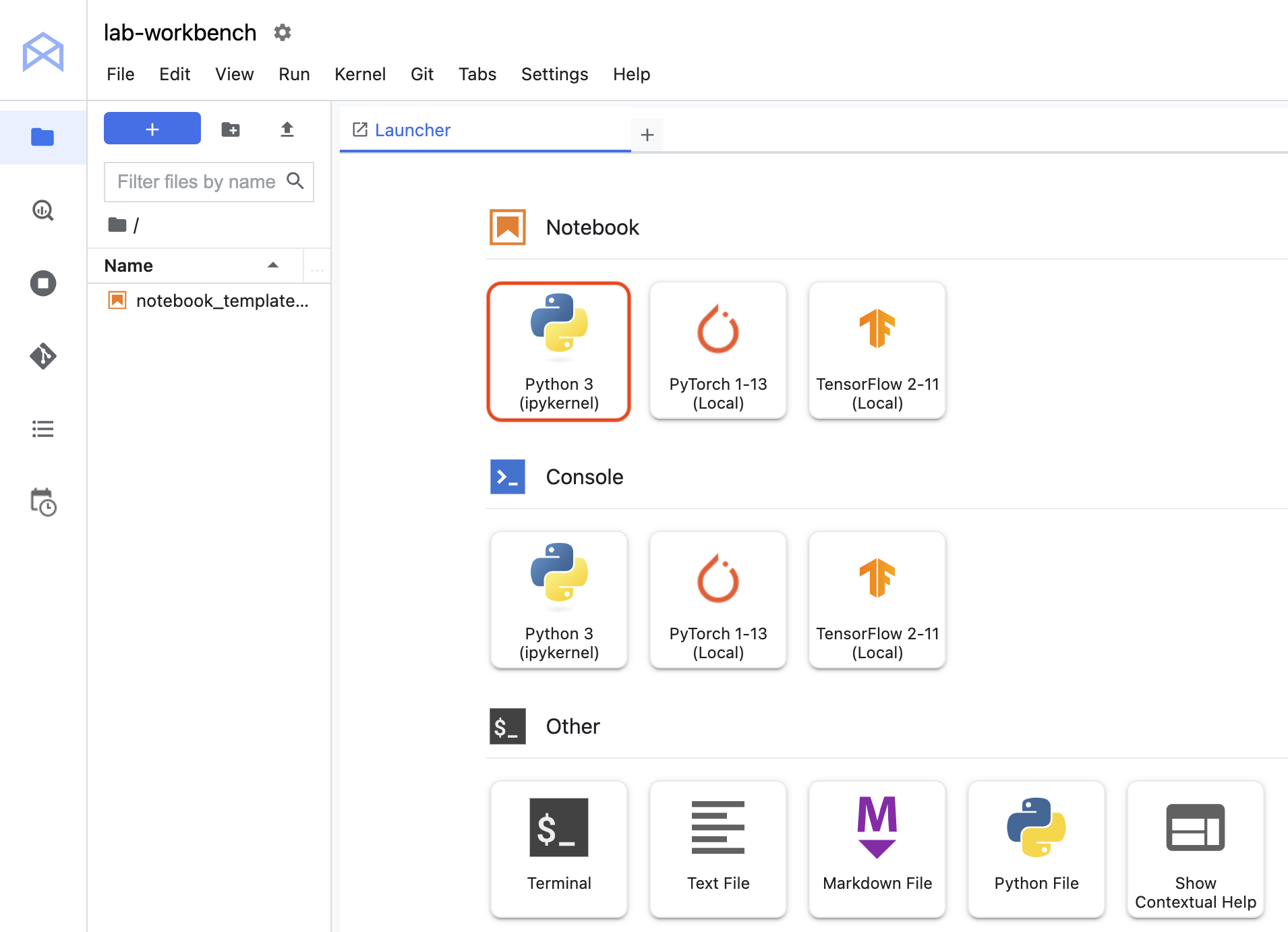
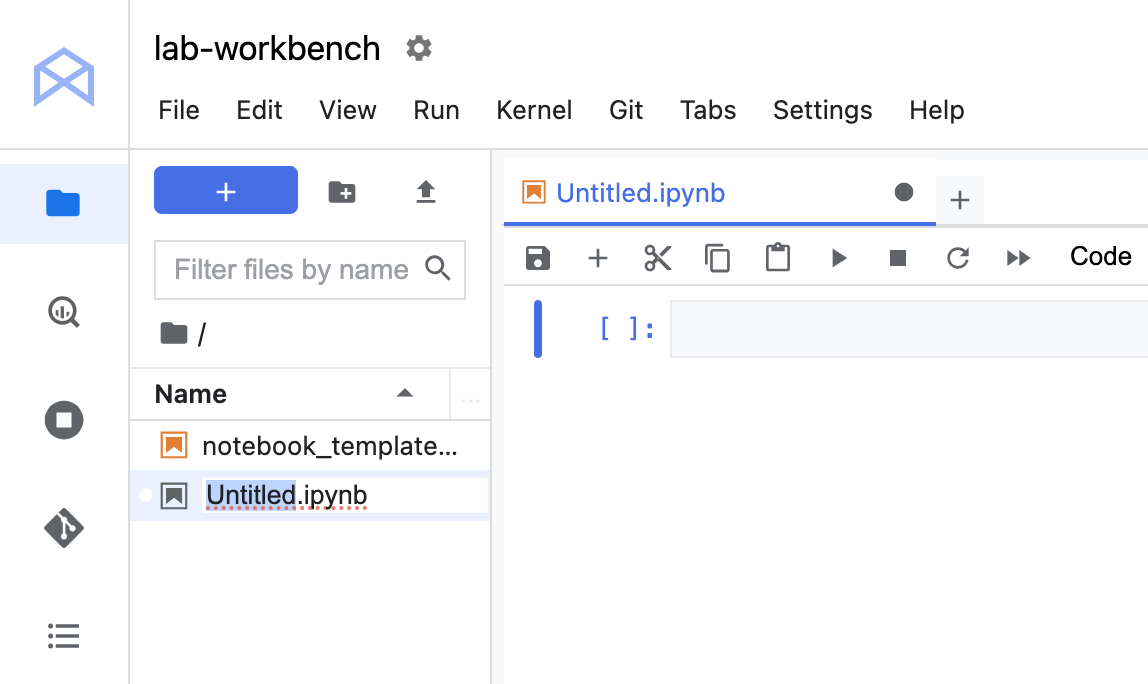
Cliquez sur l'icône Python 3 pour lancer un nouveau notebook Python.
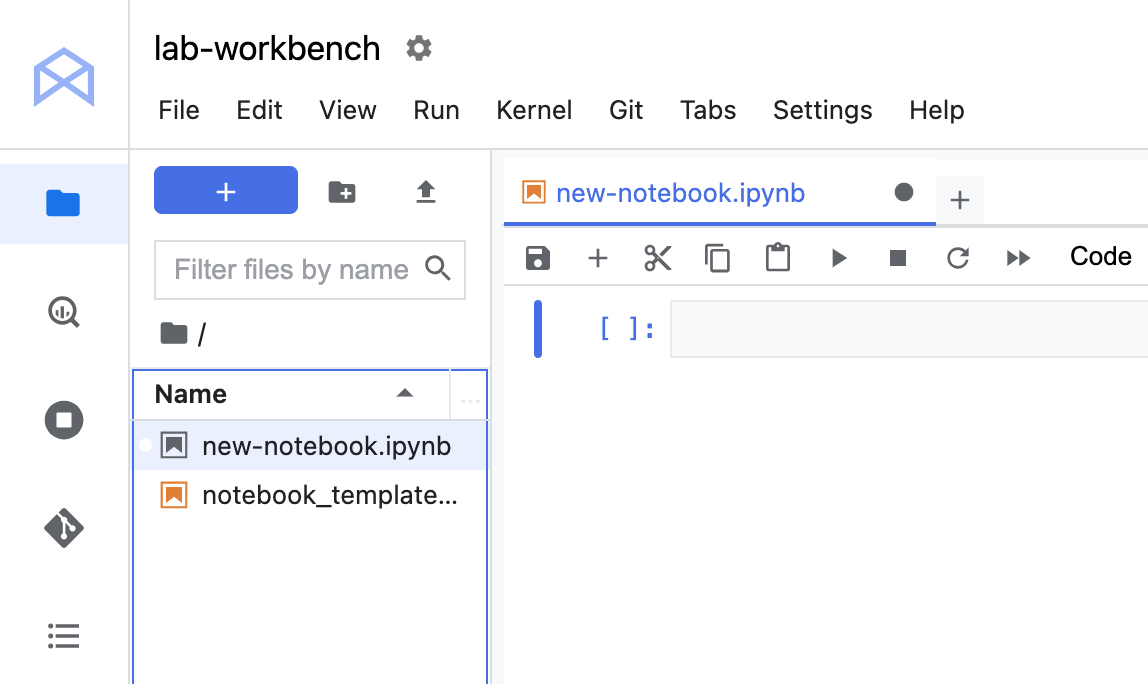
Effectuez un clic droit sur le fichier Untitled.ipynb dans la barre de menu et sélectionnez Renommer le notebook pour lui attribuer un nom significatif.
Votre environnement est configuré. Vous êtes maintenant prêt à utiliser votre notebook Vertex AI Workbench.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Lancer une instance Vertex AI Workbench
Tâche 2 : Cloner un dépôt du cours dans votre interface JupyterLab
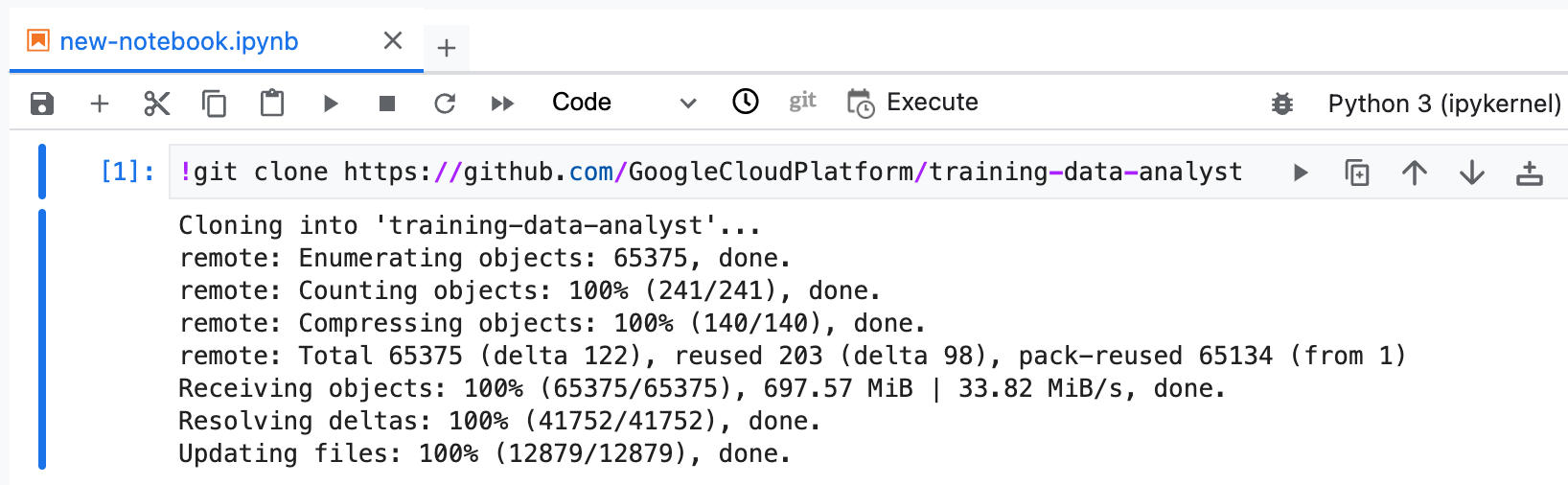
Le dépôt GitHub contient le fichier de l'atelier et les fichiers de solution du cours.
Copiez et exécutez le code suivant dans la première cellule de votre notebook pour cloner le dépôt training-data-analyst.
Vérifiez que vous avez bien cloné le dépôt. Double-cliquez sur le répertoire training-data-analyst et assurez-vous que vous pouvez voir son contenu.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Cloner un dépôt du cours dans votre interface JupyterLab
Tâche 3 : Créer des visualisations avancées avec TensorFlow Data Validation
Dans l'interface du notebook, accédez à training-data-analyst > courses > machine_learning > deepdive2 > production_ml > labs, puis ouvrez tfdv_advanced_taxi.ipynb.
Dans la boîte de dialogue Select Kernel (Sélectionner le kernel), sélectionnez Python 3 dans la liste des kernels disponibles.
Dans l'interface du notebook, cliquez sur Modifier > Supprimer tous les éléments de sortie.
Lisez attentivement les instructions du notebook et complétez le code sur les lignes contenant la mention #TODO.
Conseil : Pour exécuter la cellule actuellement sélectionnée, cliquez dessus et appuyez sur MAJ+ENTRÉE. Vous trouverez les autres commandes de cellule dans l'interface du notebook, sous Exécuter.
Des conseils ont parfois été ajoutés pour vous aider à effectuer des tâches. Mettez le texte en surbrillance pour lire les conseils (texte en blanc).
Si vous avez besoin d'une aide supplémentaire, reportez-vous à la solution complète. Pour cela, accédez à training-data-analyst > courses > machine_learning > deepdive2 > production_ml > solutions et ouvrez tfdv_advanced_taxi.ipynb.
Terminer l'atelier
Une fois l'atelier terminé, cliquez sur End Lab (Terminer l'atelier). Qwiklabs supprime les ressources que vous avez utilisées, puis efface le compte.
Si vous le souhaitez, vous pouvez noter l'atelier. Sélectionnez le nombre d'étoiles correspondant à votre note, saisissez un commentaire, puis cliquez sur Submit (Envoyer).
Le nombre d'étoiles que vous pouvez attribuer à un atelier correspond à votre degré de satisfaction :
1 étoile = très mécontent(e)
2 étoiles = insatisfait(e)
3 étoiles = ni insatisfait(e), ni satisfait(e)
4 étoiles = satisfait(e)
5 étoiles = très satisfait(e)
Si vous ne souhaitez pas donner votre avis, vous pouvez fermer la boîte de dialogue.
Pour soumettre des commentaires, suggestions ou corrections, veuillez utiliser l'onglet Support (Assistance).
Copyright 2026 Google LLC Tous droits réservés. Google et le logo Google sont des marques de Google LLC. Tous les autres noms de société et de produit peuvent être des marques des sociétés auxquelles ils sont associés.
Les ateliers créent un projet Google Cloud et des ressources pour une durée déterminée.
Les ateliers doivent être effectués dans le délai imparti et ne peuvent pas être mis en pause. Si vous quittez l'atelier, vous devrez le recommencer depuis le début.
En haut à gauche de l'écran, cliquez sur Démarrer l'atelier pour commencer.
Utilisez la navigation privée
Copiez le nom d'utilisateur et le mot de passe fournis pour l'atelier
Cliquez sur Ouvrir la console en navigation privée
Connectez-vous à la console
Connectez-vous à l'aide des identifiants qui vous ont été attribués pour l'atelier. L'utilisation d'autres identifiants peut entraîner des erreurs ou des frais.
Acceptez les conditions d'utilisation et ignorez la page concernant les ressources de récupération des données.
Ne cliquez pas sur Terminer l'atelier, à moins que vous n'ayez terminé l'atelier ou que vous ne vouliez le recommencer, car cela effacera votre travail et supprimera le projet.
Ce contenu n'est pas disponible pour le moment
Nous vous préviendrons par e-mail lorsqu'il sera disponible
Parfait !
Nous vous contacterons par e-mail s'il devient disponible
Un atelier à la fois
Confirmez pour mettre fin à tous les ateliers existants et démarrer celui-ci
Utilisez la navigation privée pour effectuer l'atelier
Le meilleur moyen d'exécuter cet atelier consiste à utiliser une fenêtre de navigation privée. Vous éviterez ainsi les conflits entre votre compte personnel et le compte temporaire de participant, qui pourraient entraîner des frais supplémentaires facturés sur votre compte personnel.
Cet atelier vous explique comment utiliser TensorFlow Data Validation (TFDV) pour examiner et visualiser votre ensemble de données. Ceci inclut l'examen des statistiques descriptives, l'inférence d'un schéma, la recherche et la correction d'anomalies, ainsi que la détection de dérives et d'écarts dans votre ensemble de données. Il est essentiel de comprendre les caractéristiques de votre ensemble de données, y compris la façon dont il peut évoluer dans votre pipeline de production au fil du temps. De même, il est important de rechercher les éventuelles anomalies dans vos données, et de comparer vos ensembles de données d'entraînement, d'évaluation et de mise en service pour vous assurer de leur cohérence.
Durée :
0 min de configuration
·
Accessible pendant 120 min
·
Terminé après 120 min

 ) de la console Google Cloud, sélectionnez Vertex AI.
) de la console Google Cloud, sélectionnez Vertex AI. Créer.
Créer.