![[プロジェクト情報]、[API]、[リソース]、[トレース]、[課金]、[Error Reporting] のタイルなどが表示されたプロジェクト ダッシュボード](https://cdn.qwiklabs.com/dxfeoOcn1ObyC0BYyoqqqSi4rO%2FeMdbWPFjoK6C0YYk%3D)


![[ラボの詳細] パネルに複数のプロジェクトのクルデンシャルがリストされている](https://cdn.qwiklabs.com/YSYl63KqoOqGgz9Cj%2FqISbU6l9STKjwTXQEmXbdiTeE%3D)

始める前に
- ラボでは、Google Cloud プロジェクトとリソースを一定の時間利用します
- ラボには時間制限があり、一時停止機能はありません。ラボを終了した場合は、最初からやり直す必要があります。
- 画面左上の [ラボを開始] をクリックして開始します
Configure the resource projects
/ 25
Create and configure Monitoring groups
/ 25
Create and test an uptime check
/ 25
Create a custom dashboard
/ 25

Cloud Monitoring では、単一の指標スコープから複数のプロジェクトをモニタリングできるようになっています。この演習では、まず、3 つの Google Cloud プロジェクトを作成します。そのうちの 2 つにモニタリング対象のリソースを追加し、3 つ目のプロジェクトを使用して指標スコープをホストします。そして、2 つのリソース プロジェクトを指標スコープに関連付けて、稼働時間チェックを作成し、一元化されたダッシュボードを構築します。
各ラボでは、新しい Google Cloud プロジェクトとリソースセットを一定時間無料で利用できます。
[ラボを開始] ボタンをクリックします。ラボの料金をお支払いいただく必要がある場合は、表示されるポップアップでお支払い方法を選択してください。 左側の [ラボの詳細] パネルには、以下が表示されます。
[Google Cloud コンソールを開く] をクリックします(Chrome ブラウザを使用している場合は、右クリックして [シークレット ウィンドウで開く] を選択します)。
ラボでリソースが起動し、別のタブで [ログイン] ページが表示されます。
ヒント: タブをそれぞれ別のウィンドウで開き、並べて表示しておきましょう。
必要に応じて、下のユーザー名をコピーして、[ログイン] ダイアログに貼り付けます。
[ラボの詳細] パネルでもユーザー名を確認できます。
[次へ] をクリックします。
以下のパスワードをコピーして、[ようこそ] ダイアログに貼り付けます。
[ラボの詳細] パネルでもパスワードを確認できます。
[次へ] をクリックします。
その後次のように進みます。
その後、このタブで Google Cloud コンソールが開きます。

最初のログイン手順を完了すると、プロジェクト ダッシュボードが表示されます。
Google Cloud Shell は、開発ツールと一緒に読み込まれる仮想マシンです。5 GB の永続ホーム ディレクトリが用意されており、Google Cloud で稼働します。
Google Cloud Shell を使用すると、コマンドラインで Google Cloud リソースにアクセスできます。
Google Cloud コンソールで、右上のツールバーにある [Cloud Shell をアクティブにする] ボタンをクリックします。
[続行] をクリックします。
環境がプロビジョニングされ、接続されるまでしばらく待ちます。接続した時点で認証が完了しており、プロジェクトに各自のプロジェクト ID が設定されます。次に例を示します。
gcloud は Google Cloud のコマンドライン ツールです。このツールは、Cloud Shell にプリインストールされており、タブ補完がサポートされています。
出力:
出力例:
出力:
出力例:
ラボ環境には事前に 3 つのプロジェクトが作成されており、それぞれのプロジェクト ID がラボ ステップ ページの左上隅に表示されます。
最初のプロジェクト(ID 1)はスコーピング プロジェクトになります。プロジェクト ID 2 と ID 3 はモニタリング対象 / リソース プロジェクトになります。Google 推奨のベスト プラクティスに従って、指標スコープをホストするために使用するプロジェクトは、モニタリング対象リソースを実際に収容しているプロジェクトとは違うものにします。
このタスクでは、次のことを実行します。
まず、モニタリングするリソースをいくつか構築しましょう。
コンピュータ上にテキスト ドキュメントを開いて、3 つのプロジェクト ID を書き留めます。
この演習では、以後これらの名前でプロジェクト ID を参照します。
[Google Cloud コンソール] ページで、インターフェースの左上隅近くにあるプロジェクト プルダウンを使用して、Worker 1 プロジェクトに切り替えます。このプロジェクトは、先のステップ 1 でテキスト ファイルを開いて ID に Worker 1 というラベルを付けたプロジェクトです。
Google Cloud コンソールのナビゲーション メニュー(
初回起動時には、初期化に 1 分ほどかかることがあります。
新しいインスタンスを作成するには、[インスタンスを作成] をクリックします。
新しいインスタンスの作成時に構成できるパラメータは多数ありますが、このラボでは以下を使用します。
| 項目 | 値 | その他の情報 |
|---|---|---|
| 名前 | worker-1-server | VM インスタンスの名前 |
| リージョン | リージョンの詳細については、Compute Engine ガイドのリージョンとゾーンをご覧ください。 | |
| ゾーン | 注: 後で必要になるので、選択したゾーンを控えておいてください。ゾーンについて詳しくは、Compute Engine ガイドのリージョンとゾーンをご覧ください。 | |
| シリーズ | E2 | シリーズの名前 |
| マシンタイプ | vCPU 2 個 | これは(e2-medium)2 CPU、4 GB RAM のインスタンスです。マイクロ インスタンス タイプから 32 コア、208 GB RAM のインスタンス タイプまで、選択できるマシンタイプは複数あります。詳しくは、Compute Engine ガイドのマシン ファミリーについてをご覧ください。注: 新しいプロジェクトにはデフォルトのリソース割り当てが適用されるため、CPU コアの数が制限される場合があります。このラボ以外のプロジェクトで作業を行う際は、より多くの CPU コアをリクエストできます。 |
| ブートディスク | 新しい 10 GB のバランス永続ディスク OS イメージ: Debian GNU/Linux 12(bookworm) | Debian、Ubuntu、CoreOS から、Red Hat Enterprise Linux や Windows Server などのプレミアム イメージまで、選択できるイメージは複数あります。詳しくは、オペレーティング システムのドキュメントをご覧ください。 |
| ファイアウォール | HTTP トラフィックを許可する | 後でインストールするウェブサーバーにアクセスするために、このオプションを選択します。注: これによって、ポート 80 で HTTP トラフィックを許可するファイアウォール ルールが自動的に作成されます。 |
[作成] をクリックします。
VM worker-1-server が作成されるまでに約 1 分を要します。worker-1-server が作成されると、[VM インスタンス] ページの VM インスタンス リストに表示されます。
SSH を使用して VM に接続するには、インスタンス名 worker-1-server の右側にある [SSH] をクリックします。
これによって、ブラウザから直接 SSH クライアントを起動できます。プロンプトが表示されたら、[承認] をクリックします。
ここでは、VM を接続するために、世界的に広く利用されているウェブサーバーである NGINX ウェブサーバーをインストールします。
OS を更新します。
想定される出力:
NGINX をインストールします。
想定される出力:
NGINX が実行されていることを確認します。
想定される出力:
ウェブページを表示するために、Cloud コンソールに戻って該当するマシンの行の [外部 IP] をクリックするか、新しいブラウザ ウィンドウまたはタブで [外部 IP] の値を http://EXTERNAL_IP/ に追加します。
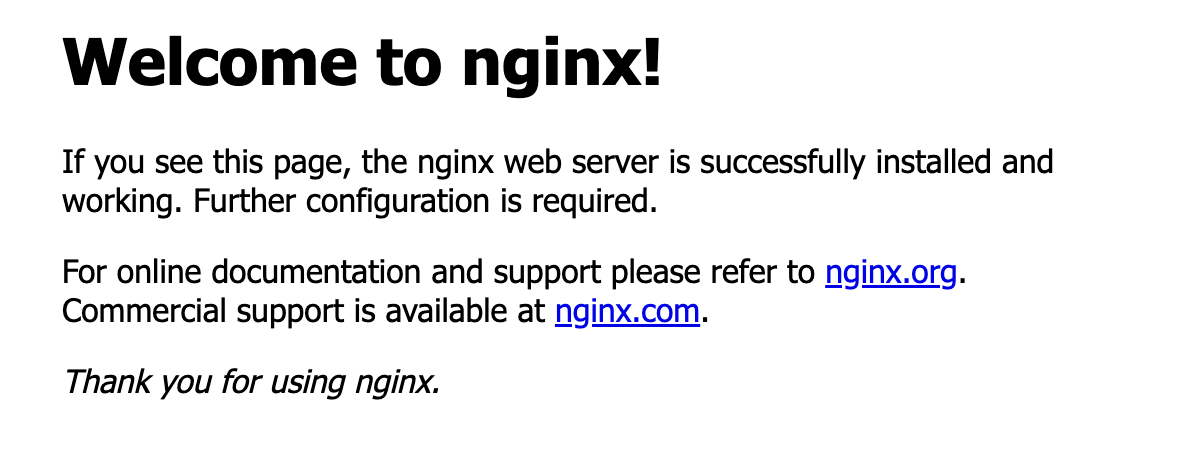
サイトが安全な接続に対応していないというメッセージが表示された場合は、[サイトへ移動] をクリックします。デフォルトのウェブページが開きます。
プロジェクト プルダウンを使用して、Worker 2 プロジェクトに切り替えます。
Worker 2 で同様のステップを実行します。
プロジェクト プルダウンを使用して、Worker 1 プロジェクトに戻ります。
ナビゲーション メニューを使用して、新しい [Compute Engine] > [VM インスタンス] を表示します。
外部 IP をコピーして新しいブラウザタブに貼り付けます。新しい Worker 1 ウェブサーバーが表示されることを確認します。
ステップ 1 で作成したテキスト ファイルに、新しいエントリとして worker-1-server を追加し、その横に先ほどコピーした外部 IP を貼り付けます。
プロジェクト プルダウンを使用して、Worker 2 プロジェクトに切り替えます。引き続き [VM インスタンス] ページが表示されているはずです。再度以下を実行します。
外部 IP 値をコピーします。このラボの進捗状況を確認するには、下の [進行状況を確認] をクリックします。チェックマークが表示されればタスクは正常に完了しています。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
モニタリングを行うホスト プロジェクトと、モニタリングの対象となるプロジェクトやプロジェクトとの関係を、さまざまな方法で構成できます。
一般に、複数のプロジェクトを一元的にモニタリングするアプローチを取る場合は、モニタリング プロジェクトにモニタリング関連のリソースと構成以外は何も含めないことをおすすめします。ここではまさにそのアプローチを取ります。
このタスクでは、次のことを実行します。
プロジェクト プルダウンを使用して、Monitoring Project に切り替えます。
Google Cloud コンソールのナビゲーション メニュー(
[設定] をクリックします。
[Metric Scope] をクリックし、[プロジェクトを追加] をクリックします。
[プロジェクトを選択] をクリックし、Worker 1 プロジェクトと Worker 2 プロジェクトを選択します。
[Add projects] をクリックします。
[ダッシュボード] ページに切り替えます。
[VM インスタンス] をクリックします。ダッシュボードを数分かけてじっくり確認します。
[ダッシュボード] をクリックし、使用可能な他のダッシュボード、特に [インフラストラクチャの概要] を数分かけてじっくり確認します。
Cloud Monitoring を使用すると、一連のリソースを単一のグループとしてまとめてモニタリングできます。グループは、アラート ポリシーやダッシュボードなどにリンクできます。指標スコープごとに、最大 500 個のグループと最大 6 個のサブグループ レイヤに対応できます。ラベル、リージョン、アプリケーションなどさまざまな基準を使用して、グループを作成できます。
各ウェブサーバーに component=frontend というラベルを追加して、外部に公開されるサーバーをトラッキングできるようにします。このようにすると、外部に公開されるサーバーを同じグループに簡単に追加できます。
このタスクでは、次のことを実行します。
Google Cloud コンソールのナビゲーション メニュー(
プロジェクト プルダウンを使用して、Worker 1 プロジェクトに切り替えます。
ナビゲーション メニューを使用して、[Compute Engine] > [VM インスタンス] に移動します。
リンクをクリックして、worker-1-server 設定に移動します。
[編集] ボタンをクリックします。
[ラベルを管理] ボタンをクリックします。
[+ ラベルを追加] ボタンをクリックし、キーを component、値を frontend としてラベルを作成します。
[+ ラベルを追加] ボタンをクリックし、キーを stage、値を dev としてラベルを作成します。
[保存] をクリックします。
構成の変更を保存します。
プロジェクト プルダウンを使用して、Worker 2 プロジェクトに切り替えます。
以下の同様のタスクを実行します。
component、値を frontend としてラベルを作成します。stage、値を test としてラベルを作成します。(test 値に留意してください)プロジェクト プルダウンを使用して、Monitoring Project に切り替えます。
ナビゲーション メニュー(
左側のメニューで、[グループ] に移動します。
[+ Create Group] リンクを使用して、新しいモニタリング グループを作成します。
グループに「Frontend Servers」という名前を付けます。
基準に以下を使用します。
| 設定 | 値 |
|---|---|
| Type | タグ |
| タグ | component |
| Operator | Equals |
| Value | frontend |
ページ右側の [Resources Selected] に、現在選択されている 2 つの VM インスタンスが表示されていることを確認します。表示されていない場合は、基準を再度確認してください。
グループを作成します。
ページを更新し、1 分ほど待つと、2 つの VM の指標とグラフがいくつか表示されます。
Frontend Servers グループで、[サブグループ] セクションに移動し、[サブグループを作成] をクリックします。
サブグループを以下の設定で構成します。
| 設定 | 値 |
|---|---|
| 名前 | Frontend Dev |
| 基準 1 | |
| 種類 | タグ |
| タグ | component |
| Operator | Equals |
| Value | frontend |
| 設定 | 値 |
|---|---|
| 基準 2 | |
| 種類 | タグ |
| タグ | stage |
| 演算子 | 等しい |
| 値 | dev |
2 つ目の基準に対して [完了] をクリックし、[Combine criteria operator] で [AND] を選択して結合します。
[作成] をクリックします。
[グループ] ホームページに戻ります。Frontend Servers グループを開くと、サブグループを表示できるようになりました。その仕組みに留意してください。また、クリック可能なリンクも表示され、これをクリックすると、グループに含まれているリソースタイプに関する情報がいくつか表示されます。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
Google Cloud 稼働時間チェックは、外部に公開されている HTTP、HTTPS、TCP といったアプリケーションの有効性をテストします。そのために、世界の複数の場所から前述のアプリケーションにアクセスします。出力されるレポートには、稼働時間、レイテンシ、ステータスに関する情報が記載されています。稼働時間チェックは、アラート ポリシーとダッシュボードでも使用できます。
このタスクでは、次のことを実行します。
稼働時間チェックの対象となるリソースのうち、同種のものをグループにまとめると、複数のサーバーをチェックできる単一の稼働時間チェックを簡単に作成できます。
Monitoring Project の [Monitoring] セクションで、[稼働時間チェック] をクリックします。
ページ上部で、[+ 稼働時間チェックを作成] のリンクをたどります。
新しい稼働時間チェックを以下の設定で構成します(まだ [保存] は押さないでください)。
| 設定 | 値 |
|---|---|
| Protocol | HTTP |
| リソースの種類 | Instance |
| 対象 | Group |
| Group | Frontend Servers |
| Path | / |
| Check Frequency | 1 minute |
他のオプションをデフォルトのままにして、[続行] をクリックします。
[回答の検証] セクションで、[続行] をクリックします。
必要に応じて、[アラートと通知] セクションで、[通知チャンネル] プルダウンをクリックし、[通知チャンネルを管理] を使用して、メールアドレスを有効な通知オプションとして追加します。アラートはデフォルトで有効になりますが、これ以外に誰かに通知する方法はありません。
[続行] をクリックします。
[タイトル] に Frontend Servers Uptime と設定します。
[テスト] をクリックし、200 レスポンスを検証します。
稼働時間チェックを作成します。
稼働時間チェックのリストで、新たに作成した Frontend Servers Uptime をクリックして、そのダッシュボードを表示します。
数分待ってから更新します。チェック結果に関する情報がダッシュボードに表示されます。グラフとデータをじっくり確認します。
[構成] ボックスのページ右側で、Check ID 値をコピーして、メモ テキスト ファイルに貼り付けます。frontend-servers-uptime という値が貼り付けられるはずです。
作成した稼働時間チェックは正常に機能していますが、もしエラーがあったとしたらどうなるでしょうか?実際にエラーをトリガーして、その結果生成される稼働時間チェックとアラートの動作を詳しく見ていきましょう。
先に進む前に、稼働時間チェックのダッシュボードに数分間分のデータが表示されていることを確認します。
ナビゲーション メニューを使用して、[Cloud の概要] > [ダッシュボード] ページに移動します。
プロジェクト プルダウンを使用して、Worker 1 プロジェクトに切り替えます。
ナビゲーション メニューを使用して、[Compute Engine] > [VM インスタンス] に移動します。
worker-1-server の横にあるチェックボックスをオンにし、実行を停止します。
VM インスタンスのページを更新し、サーバーの稼働が停止するまで待ちます。
プロジェクト プルダウンを使用して、Monitoring Project に切り替えます。
ナビゲーション メニュー(
[稼働時間チェックのレイテンシ] と [合格したチェック] グラフを確認します。エラーの表示が始まるまで少し時間がかかることがあります。
[Monitoring] > [Metrics Explorer] に移動します。
[指標を選択] プルダウンをクリックし、[VM インスタンス] > [Uptime_check] > [Check passed] を選択して、[適用] をクリックします。注意事項に目を通し、Check passed 指標を確認したら、「uptime_check」を検索してみてください。他にも検討したくなるような指標がいくつか表示されるはずです。
[フィルタを追加] をクリックします。
| 設定 | 値 |
|---|---|
| 指標ラベル | checked_resource_id |
| 値 | プルダウンから選択 |
少し時間をかけて結果を確認します。
ナビゲーション メニューの [ログ エクスプローラ] をクリックします。
[クエリを表示] を有効にし、その内容を削除します。[すべてのログ名] をクリックします。uptime_checks ログを見つけて追加し、[適用] を選択します。[クエリを実行] をクリックします。
いずれかのログエントリを開いて確認します。どのような有益な情報が提供されますか?
その同じエントリで、labels セクションに移動し、check_id を見つけます。テキスト形式のメモ ドキュメントを開いて、そこに記録した id と比較します。両者は一致するはずです。
ナビゲーション メニュー(
発生したアラートを確認します。通知チャンネルとして自分自身を追加していた場合は、メールを確認してください。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
Google Cloud システムの稼働担当者が、システムのステータスを調べてみたいと思うときがいつかやってきます。それは単なる好奇心かもしれませんし、キャパシティ プランニングや、アラートに応えてのことかもしれません。
いずれにせよ、データをアイテムや値のリストではなくグラフ形式で表すると、トレンド、異常、値の上下を発見しやすくなる傾向があります。このタスクでは、デベロッパーがフロントエンド サーバーで起きていることをトラッキングできるよう、その手段の一つとしてグラフを追加します。
このタスクでは、次のことを実行します。
デベロッパー ウェブサーバーで何が起きているかに関心があるなら、そのサーバーだけを対象としたグラフをダッシュボードに表示するようにすると効果的です。このセクションでは、稼働時間チェックのサマリーグラフを表示するダッシュボードを作成します。
Google Cloud コンソールのナビゲーション メニュー(
プロジェクト プルダウンを使用して、Worker 1 プロジェクトに切り替えます。
ナビゲーション メニューを使用して、[Compute Engine] > [VM インスタンス] に移動します。
worker-1-server の横にあるチェックボックスをオンにし、実行を開始します。
プロジェクト プルダウンを使用して、Monitoring Project に切り替えます。
ナビゲーション メニュー(
ページ上部にある [カスタム ダッシュボードを作成します] をクリックします。
[新しいダッシュボード名] に「Developer's Frontend」と入力します。
[ウィジェットを追加] をクリックし、[線] をクリックします。
| 設定 | 値 |
|---|---|
| ウィジェットのタイトル | Dev Server Uptime |
| 指標を選択 | [VM インスタンス] > [Uptime_check] > [check_passed] |
[適用] をクリックします。
グラフに表示される値を確認します。worker-1-server がコアとなる開発サーバーです。そのチェック レスポンス行のいずれかから checked_resource_id 値をメモします。次のステップでこの値をリストから選択する必要があります。
[フィルタを追加] をクリックします。
| 設定 | 値 |
|---|---|
| リソースラベル | instance_id |
| 値 | プルダウンから選択 |
[集計] で [整列指定子を構成] を選択し、[アライメント関数] を [true のカウント] に設定します。
プラスアイコン(クエリ要素を追加)をクリックし、[最小間隔] の期間を「5 分」に設定します。
[適用] をクリックします。
開発サーバー内で起きていることに関する重要な情報にはもう一つ、CPU 負荷があります。総じて、NGINX サーバー自体で何が起きているかを把握することは素晴らしいことですが、ロギングとモニタリングのエージェントをインストールしなければ、まだそれはできません。
ダッシュボードに別のグラフを追加します。[ウィジェットを追加] をクリックし、[線] をクリックします。
[指標を選択] で、[VM インスタンス] > [インスタンス] > [cpu utilization] を検索または選択します。
[適用] をクリックします。
[フィルタを追加] をクリックします。
| 設定 | 値 |
|---|---|
| 指標ラベル | instance_name |
| 値 | worker-1-server |
[適用] をクリックします。
Cloud Shell は、負荷テストのトラフィックを生成するためのプラットフォームとして常に正しく機能するとは限りません。悪意のある何かをユーザーが実行しようとしていると判断して、ユーザーのセッションを終了する場合があるからです。そのため代わりに、もう一つのウェブサーバーを使用して負荷を生成します。ナビゲーション メニューを開き、[Compute Engine] を右クリックして、リンクを新しいタブまたはウィンドウに開きます。
プロジェクト プルダウンを使用して、Worker 2 プロジェクトに切り替えます。
worker-2-server に SSH 接続します。
サーバーのパッケージ データベースを更新し、apache2-utils をインストールします。Apache Bench は、次のように HTTP 負荷をすばやく簡単に生成できるツールです。
「Do you want to continue? [Y/n]」と表示されたら、「Y」と入力します。
worker-1-server 外部 IP を見つけ、その IP を使用して以下の URL 環境変数を構成します。「http://」を省略しないでください。[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
他のプロジェクトを一元的にモニタリングできるプロジェクトの設定方法を理解し、モニタリング対象リソース グループ、稼働時間チェック、カスタム ダッシュボードを作成できるようになりました。これでまた一歩前進しました。これで完了となります。
ラボが完了したら、[ラボを終了] をクリックします。ラボで使用したリソースが Google Skills から削除され、アカウントの情報も消去されます。
ラボの評価を求めるダイアログが表示されたら、星の数を選択してコメントを入力し、[送信] をクリックします。
星の数は、それぞれ次の評価を表します。
フィードバックを送信しない場合は、ダイアログ ボックスを閉じてください。
フィードバックやご提案の送信、修正が必要な箇所をご報告いただく際は、[サポート] タブをご利用ください。
Copyright 2026 Google LLC All rights reserved. Google および Google のロゴは、Google LLC の商標です。その他すべての社名および製品名は、それぞれ該当する企業の商標である可能性があります。



このコンテンツは現在ご利用いただけません
利用可能になりましたら、メールでお知らせいたします

ありがとうございます。
利用可能になりましたら、メールでご連絡いたします

1 回に 1 つのラボ
既存のラボをすべて終了して、このラボを開始することを確認してください