Neste laboratório, muitos dos conceitos apresentados em um contexto de lote serão usados e aplicados no contexto de streaming para criar um pipeline semelhante ao batch_minute_traffic_pipeline, que opera em tempo real. O pipeline final primeiro vai ler as mensagens JSON do Pub/Sub e analisá-las antes da ramificação. Uma ramificação grava alguns dados brutos no BigQuery e registra o tempo de processamento e de eventos. As outras ramificações agrupam em janelas e agregam os dados, além de gravar os resultados no BigQuery.
Objetivos
Ler os dados de uma fonte de streaming
Gravar os dados em um coletor de streaming.
Dividir os dados em janelas em um contexto de streaming
Verificar os efeitos de atrasos de modo experimental
Você vai criar o seguinte pipeline:
Para cada laboratório, você recebe um novo projeto do Google Cloud e um conjunto de recursos por um determinado período e sem custos financeiros.
Faça login no Qwiklabs em uma janela anônima.
Confira o tempo de acesso do laboratório (por exemplo, 1:15:00) e finalize todas as atividades nesse prazo.
Não é possível pausar o laboratório. Você pode reiniciar o desafio, mas vai precisar refazer todas as etapas.
Quando tudo estiver pronto, clique em Começar o laboratório.
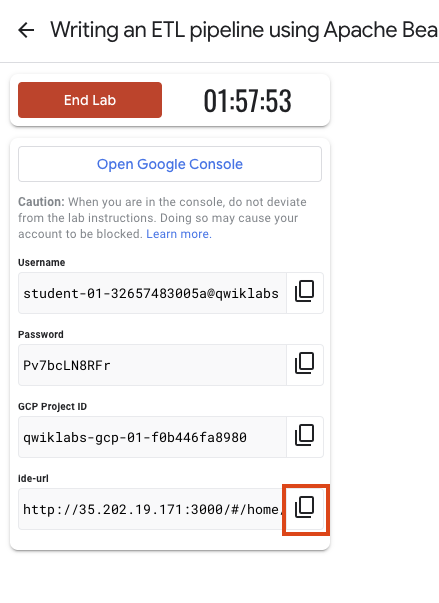
Anote as credenciais (Nome de usuário e Senha). É com elas que você vai fazer login no Console do Google Cloud.
Clique em Abrir Console do Google.
Clique em Usar outra conta, depois copie e cole as credenciais deste laboratório nos locais indicados.
Se você usar outras credenciais, vai receber mensagens de erro ou cobranças.
Aceite os termos e pule a página de recursos de recuperação.
Ative o Google Cloud Shell
O Google Cloud Shell é uma máquina virtual com ferramentas de desenvolvimento. Ele tem um diretório principal permanente de 5 GB e é executado no Google Cloud.
O Cloud Shell oferece acesso de linha de comando aos recursos do Google Cloud.
No console do Cloud, clique no botão "Abrir o Cloud Shell" na barra de ferramentas superior direita.
Clique em Continuar.
O provisionamento e a conexão do ambiente podem demorar um pouco. Quando você estiver conectado, já estará autenticado, e o projeto estará definido com seu PROJECT_ID. Exemplo:
A gcloud é a ferramenta de linha de comando do Google Cloud. Ela vem pré-instalada no Cloud Shell e aceita preenchimento com tabulação.
Para listar o nome da conta ativa, use este comando:
Antes de começar a trabalhar no Google Cloud, veja se o projeto tem as permissões corretas no Identity and Access Management (IAM).
No console do Google Cloud, em Menu de navegação (), selecione IAM e administrador > IAM.
Confira se a conta de serviço padrão do Compute {project-number}-compute@developer.gserviceaccount.com está na lista e recebeu o papel de editor. O prefixo da conta é o número do projeto, que está no Menu de navegação > Visão geral do Cloud > Painel.
Observação: se a conta não estiver no IAM ou não tiver o papel de editor, siga as etapas abaixo.
No console do Google Cloud, em Menu de navegação, clique em Visão geral do Cloud > Painel.
Copie o número do projeto, por exemplo, 729328892908.
Em Menu de navegação, clique em IAM e administrador > IAM.
Clique em Permitir acesso, logo abaixo de Visualizar por principais na parte de cima da tabela de papéis.
Substitua {project-number} pelo número do seu projeto.
Em Papel, selecione Projeto (ou Básico) > Editor.
Clique em Save.
Como configurar o ambiente de desenvolvimento integrado
Neste laboratório, você vai usar principalmente a versão da Web do ambiente de desenvolvimento integrado Theia. Ele é hospedado no Google Compute Engine e contém o repositório do laboratório pré-clonado. Além disso, o Theia oferece suporte de servidor à linguagem Java e um terminal para acesso programático às APIs do Google Cloud com a ferramenta de linha de comando gcloud, similar ao Cloud Shell.
Para acessar o ambiente de desenvolvimento integrado Theia, copie e cole o link exibido no Qwiklabs em uma nova guia.
OBSERVAÇÃO: mesmo depois que o URL aparecer, talvez você precise esperar de três a cinco minutos para o ambiente ser totalmente provisionado. Até isso acontecer, uma mensagem de erro será exibida no navegador.
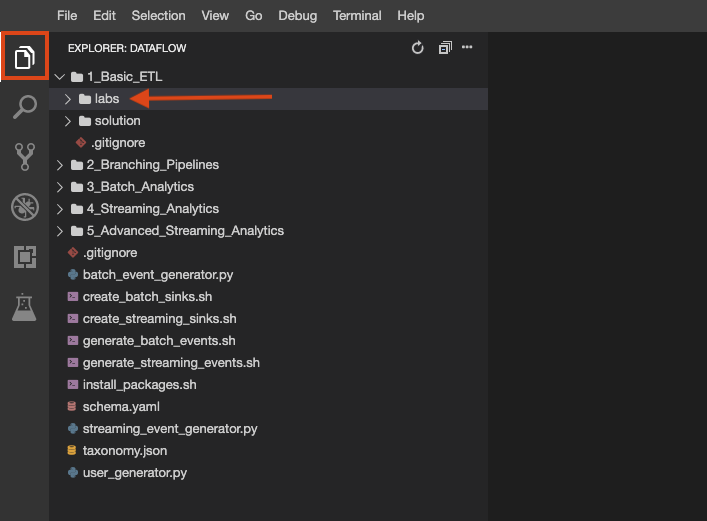
O repositório do laboratório foi clonado para seu ambiente. Cada laboratório é dividido em uma pasta labs com códigos que você vai concluir e uma pasta solution com um exemplo totalmente funcional para consulta, caso você enfrente dificuldades. Clique no botão File explorer para conferir:
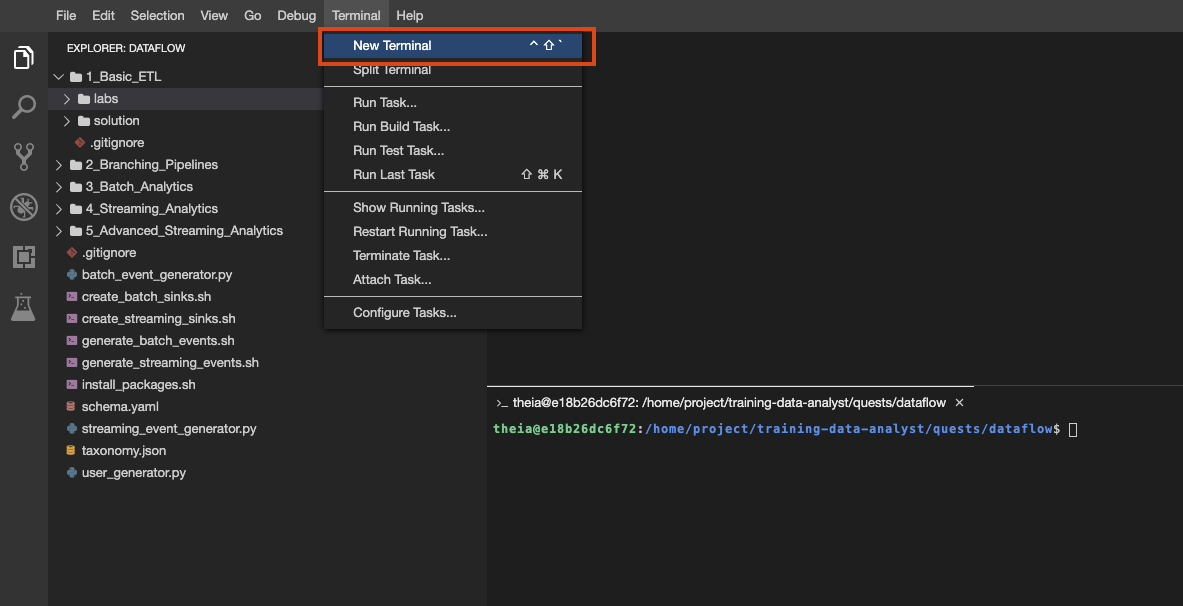
Também é possível criar vários terminais nesse ambiente, como você faria com o Cloud Shell:
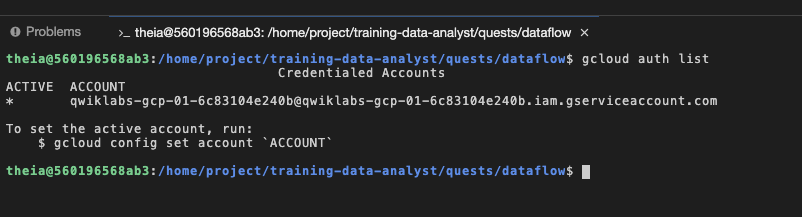
Outra opção de visualização é executar gcloud auth list no terminal em que você fez login com uma conta de serviço fornecida. Ela tem as mesmas permissões que a sua conta de usuário do laboratório:
Se em algum momento o ambiente parar de funcionar, tente redefinir a VM que hospeda o ambiente de desenvolvimento integrado no Console do GCE, conforme este exemplo:
Abrir o laboratório apropriado
Crie um novo terminal no ambiente de desenvolvimento integrado, caso ainda não tenha feito isso. Depois copie e cole este comando:
# Change directory into the lab
cd 5_Streaming_Analytics/labs
# Download dependencies
mvn clean dependency:resolve
export BASE_DIR=$(pwd)
Configurar o ambiente de dados
# Create GCS buckets, BQ dataset, and Pubsub Topic
cd $BASE_DIR/../..
source create_streaming_sinks.sh
# Change to the directory containing the practice version of the code
cd $BASE_DIR
Clique em Verificar meu progresso para ver o objetivo.
Configure o ambiente de dados
Tarefa 1: como ler uma fonte de streaming
Você usou TextIO.read() para leitura do Google Cloud Storage nos laboratórios anteriores. Neste laboratório, em vez do Google Cloud Storage, você usa o Pub/Sub. O Pub/Sub é um serviço de mensagens em tempo real totalmente gerenciado. Ele permite que os editores enviem mensagens a um "tópico", em que os assinantes podem se inscrever com uma "assinatura".
O pipeline que você criou se inscreve em um tópico chamado my_topic, recém-criado via script create_streaming_sinks.sh. Em uma situação de produção, é normal que a equipe de publicação crie esse tópico. Confira na seção Pub/Sub do console.
Para ler o Pub/Sub usando os conectores de E/S do Apache Beam, abra o arquivo StreamingMinuteTrafficPipeline.java e adicione uma transformação ao pipeline com a função PubsubIO.readStrings(). Essa função retorna uma instância de PubsubIO.Read, que tem um método para especificar o tópico de origem e o atributo de carimbo de data/hora. Já existe uma opção de linha de comando para o nome do tópico do Pub/Sub. Defina o atributo de carimbo de data/hora como "data/hora" que corresponde ao que será adicionado a cada mensagem do Pub/Sub. Pule esta etapa se o tempo da publicação da mensagem for suficiente.
Observação: o horário da publicação é o momento em que o serviço Pub/Sub recebe a mensagem pela primeira vez. Pode haver uma diferença entre o horário real do evento e o da publicação em alguns sistemas (por exemplo, dados atrasados). Se isso for considerado, o código do cliente que publica a mensagem precisa definir um atributo de metadados de "carimbo de data/hora" na mensagem e fornecer o carimbo de data/hora do evento real. O Pub/Sub não vai extrair de forma nativa o carimbo de data/hora do evento incorporado ao payload.
É possível verificar o código do cliente que gera as mensagens que você vai usar no GitHub.
Adicione uma transformação que leia o tópico do Pub/Sub especificado pelo parâmetro de linha de comando input_topic para concluir esta tarefa. Em seguida, use o DoFn fornecido, JsonToCommonLog, para converter cada string JSON em uma instância CommonLog. Colete os resultados dessa transformação em uma PCollection de instâncias do CommonLog.
Tarefa 2: agrupar os dados
No laboratório anterior que não é SQL, você implementou janelas de tempo fixo para agrupar eventos por tempo do evento em janelas de tamanho fixo de exclusão mútua. Faça o mesmo com as entradas de streaming aqui. Se tiver dificuldades, consulte o código do laboratório anterior ou a solução.
Agrupar em janelas de um minuto
Acrescente uma janela de tempo fixo com a duração de um minuto da seguinte forma:
Para concluir essa tarefa, adicione uma transformação ao pipeline que aceite a PCollection de dados CommonLog e agrupe os elementos em janelas de segundos de duração window_duration usando window_duration como parâmetro de linha de comando.
Tarefa 3: agregar os dados
No laboratório anterior, você usou a transformação Contagem para contar o número de eventos por janela. Faça o mesmo aqui.
Contar eventos por janela
Conte o número de eventos de uma janela não global usando um código assim:
Conforme já feito, é necessário converter novamente o valor <Long> para um valor <Row> e extrair o carimbo de data/hora da seguinte forma:
@ProcessElement
public void processElement(@Element T l, OutputReceiver<T> r, IntervalWindow window) {
Instant i = Instant.ofEpochMilli(window.end().getMillis());
Row row = Row.withSchema(appSchema)
.addValues(.......)
.build()
...
r.output(...);
}
Indique o esquema para serialização da seguinte forma:
apply().setRowSchema(appSchema)
Para concluir essa tarefa, transmita a PCollection em janela como entrada para uma transformação que faça a contagem do número de eventos por janela.
Adicione mais uma transformação para converter os resultados em uma PCollection de Rows com o esquema pageviewsSchema fornecido.
Tarefa 4: gravar no BigQuery
Este pipeline faz gravações no BigQuery em duas ramificações separadas. A primeira ramificação grava os dados agregados no BigQuery. A segunda ramificação, que já foi criada para você, grava alguns metadados sobre cada evento bruto, incluindo os carimbos de data/hora do evento e do carimbo de data/hora do processamento. Ambos gravam dados direto no BigQuery usando inserções por streaming.
Gravar dados agregados no BigQuery
Como a gravação no BigQuery foi abordada em laboratórios anteriores, o mecanismo básico não será detalhado aqui.
A tarefa usa o código fornecido.
Para concluir essa tarefa, siga estas etapas:
Crie um novo parâmetro de linha de comando chamado aggregateTableName para a tabela que vai abrigar os dados agregados.
Adicione uma transformação, como mostrado nas etapas anteriores, que grava no BigQuery e usa .useBeamSchema().
Observação: em contexto de streaming, BigQueryIO.write() não é compatível com WriteDisposition do WRITE_TRUNCATE em que a tabela é descartada e recriada. Neste exemplo, use WRITE_APPEND.
Nos casos de uso de streaming de uploads em lote periódicos a cada dois minutos que estão funcionando bem, é possível especificar esse comportamento com .withMethod() e também definir a frequência com .withTriggeringFrequency(org.joda.time.Duration).
Observação: ainda não há dados sendo criados e ingeridos pelo pipeline. Portanto, ele será executado, mas não vai processar nada. Você vai incluir os dados na próxima etapa.
Clique em Verificar meu progresso para ver o objetivo.
Execute o pipeline
Tarefa 6: gerar uma entrada de streaming sem atraso
Como este é um pipeline de streaming, ele é inscrito na origem do streaming e aguarda a entrada. No momento, não há nada. Nesta seção, você vai gerar dados sem atraso. Os dados reais quase sempre têm atraso. No entanto, esta seção é instrutiva, e o objetivo é que você entenda as entradas de streaming sem atraso.
O código desta Quest inclui um script para publicar eventos JSON usando o Pub/Sub.
Para concluir a tarefa e começar a publicar mensagens, abra um novo terminal ao lado do atual e execute o script a seguir. Ele só vai parar de publicar mensagens quando for encerrado. Confirme se a pasta é a training-data-analyst/quests/dataflow.
bash generate_streaming_events.sh
Clique em Verificar meu progresso para conferir o objetivo.
Gere uma entrada de streaming sem atraso
Analisar os resultados
Aguarde o preenchimento de dados por alguns minutos e acesse o BigQuery para consultar a tabela "logs.minute_traffic" seguindo algo parecido com isto:
SELECT minute, pageviews
FROM `logs.windowed_traffic`
ORDER BY minute ASC
O número de visualizações de páginas terá passado de 100 visualizações por minuto.
Você pode usar a ferramenta de linha de comando do BigQuery para confirmar rapidamente que os resultados estão sendo gravados:
bq head logs.raw
bq head logs.windowed_traffic
Agora insira a seguinte consulta:
SELECT
UNIX_MILLIS(event_timestamp) - min_millis.min_event_millis AS event_millis,
UNIX_MILLIS(processing_timestamp) - min_millis.min_event_millis AS processing_millis,
user_id,
-- adicionado como rótulo único para verificarmos todos os pontos
CAST(UNIX_MILLIS(event_timestamp) - min_millis.min_event_millis AS STRING) AS label
FROM
`logs.raw`
CROSS JOIN (
SELECT
MIN(UNIX_MILLIS(event_timestamp)) AS min_event_millis
FROM
`logs.raw`) min_millis
WHERE
event_timestamp IS NOT NULL
ORDER BY
event_millis ASC
Esta consulta ilustra a lacuna entre o tempo de evento e o tempo de processamento. No entanto, pode ser difícil ver o panorama geral se analisarmos apenas os dados tabulares brutos. Usaremos o Data Studio, uma visualização leve de dados e um mecanismo de BI.
Na IU do BigQuery, clique no botão Explorar dados e selecione Explorar com o Data Studio.
Uma nova janela é aberta.
No painel à direita dessa janela, selecione o tipo de gráfico de dispersão.
Defina os seguintes valores na coluna Dados do painel à direita:
Dimensão: rótulo
Métrica X: event_millis
Métrica Y: processing_millis
O gráfico será transformado em um gráfico de dispersão, em que todos os pontos estão na diagonal. Isso ocorre porque, nos dados de streaming que estão sendo gerados, os eventos são processados logo após a geração, sem atraso. Se você iniciou o script de geração de dados rapidamente, ou seja, antes da ativação do job do Dataflow, verá algo parecido com um taco de hóquei, porque algumas mensagens na fila do Pub/Sub foram processadas quase de uma vez.
Mas, no mundo real, o atraso é algo com que os pipelines precisam lidar.
Tarefa 7: incluir o atraso na entrada de streaming
O script de evento de streaming é capaz de gerar eventos com atraso simulado.
Isso representa cenários em que há um atraso entre o momento em que os eventos são gerados e publicados no Pub/Sub. Por exemplo, quando um cliente de dispositivo móvel entra no modo off-line porque um usuário não tem o serviço, mas todos os eventos são coletados no dispositivo e publicados de uma vez quando o aparelho retorna ao modo on-line.
Gerar entrada de streaming com atraso
Primeiro, feche a janela do Data Studio.
Em seguida, para ativar o atraso, volte para a janela do terminal do ambiente de desenvolvimento integrado.
Interrompa o script em execução usando CTRL+C no terminal.
Por último, execute este comando:
bash generate_streaming_events.sh true
Analisar os resultados
Volte à interface do BigQuery, execute a consulta outra vez e recrie a visualização do Data Studio.
Os novos dados que chegam e são mostrados do lado direito do gráfico não são mais perfeitos. Alguns vão aparecer acima da diagonal, indicando que foram processados após a ocorrência dos eventos.
Tipo de gráfico: dispersão
Dimensão: rótulo
Métrica X: event_millis
Métrica Y: processing_millis
Finalize o laboratório
Clique em Terminar o laboratório após a conclusão. O Google Cloud Ensina remove os recursos usados e limpa a conta por você.
Você vai poder avaliar sua experiência no laboratório. Basta selecionar o número de estrelas, digitar um comentário e clicar em Enviar.
O número de estrelas indica o seguinte:
1 estrela = muito insatisfeito
2 estrelas = insatisfeito
3 estrelas = neutro
4 estrelas = satisfeito
5 estrelas = muito satisfeito
Feche a caixa de diálogo se não quiser enviar feedback.
Para enviar seu feedback, fazer sugestões ou correções, use a guia Suporte.
Copyright 2020 Google LLC. Todos os direitos reservados. Google e o logotipo do Google são marcas registradas da Google LLC. Todos os outros nomes de produtos e empresas podem ser marcas registradas das respectivas empresas a que estão associados.
Os laboratórios criam um projeto e recursos do Google Cloud por um período fixo
Os laboratórios têm um limite de tempo e não têm o recurso de pausa. Se você encerrar o laboratório, vai precisar recomeçar do início.
No canto superior esquerdo da tela, clique em Começar o laboratório
Usar a navegação anônima
Copie o nome de usuário e a senha fornecidos para o laboratório
Clique em Abrir console no modo anônimo
Fazer login no console
Faça login usando suas credenciais do laboratório. Usar outras credenciais pode causar erros ou gerar cobranças.
Aceite os termos e pule a página de recursos de recuperação
Não clique em Terminar o laboratório a menos que você tenha concluído ou queira recomeçar, porque isso vai apagar seu trabalho e remover o projeto
Este conteúdo não está disponível no momento
Você vai receber uma notificação por e-mail quando ele estiver disponível
Ótimo!
Vamos entrar em contato por e-mail se ele ficar disponível
Um laboratório por vez
Confirme para encerrar todos os laboratórios atuais e iniciar este
Use a navegação anônima para executar o laboratório
Para executar este laboratório, use o modo de navegação anônima ou uma janela anônima do navegador. Isso evita conflitos entre sua conta pessoal e a conta de estudante, o que poderia causar cobranças extras na sua conta pessoal.
Neste laboratório, você vai ler dados de uma fonte de streaming, realizar as mesmas agregações que fez antes e gravar os resultados no formato de streaming no BigQuery. Você também vai testar a diferença no tempo de processamento e tempo de eventos com dados atrasados.
Duração:
Configuração: 0 minutos
·
Tempo de acesso: 120 minutos
·
Tempo para conclusão: 120 minutos



 ), selecione IAM e administrador > IAM.
), selecione IAM e administrador > IAM.