

![Compute Engine のデフォルトのサービス アカウント名と編集者のステータスがハイライト表示された [権限] タブページ](https://cdn.qwiklabs.com/1nytD9OUuNUV9undyjUWeOS7LJmekReBDmkUjveCjcU%3D)
![[ターミナル] メニューでハイライト表示されている [新しいターミナル] オプション](https://cdn.qwiklabs.com/o3Hxy07QcEZ%2FwAucqGRJPFyRJWB0negMcYJph7S%2FDh4%3D)
![[VM インスタンス] ページで、リセットボタンと VM インスタンス名の両方がハイライト表示されている](https://cdn.qwiklabs.com/jDH1qGTOJ%2B1Hy2nxOPm1DPmO1JgUCjOmBvwycVWgqEk%3D)
![[スキーマ] タブページのログスキーマ](https://cdn.qwiklabs.com/O2VOb%2B%2F1UgevR8rQO7O1VARFRcB2fhqq%2BM4sedd7F8g%3D)

始める前に
- ラボでは、Google Cloud プロジェクトとリソースを一定の時間利用します
- ラボには時間制限があり、一時停止機能はありません。ラボを終了した場合は、最初からやり直す必要があります。
- 画面左上の [ラボを開始] をクリックして開始します
Setup the data environment
/ 15
Run your pipeline from the command line
/ 10

このラボでは、次の作業を行います。
<Row> オブジェクトとして処理するJava に関する基本的な知識
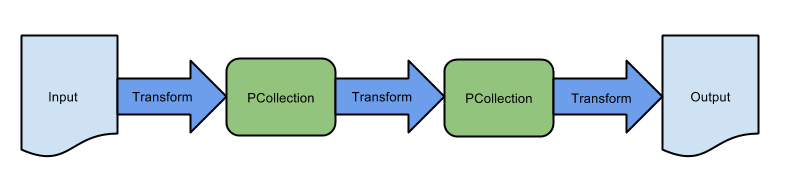
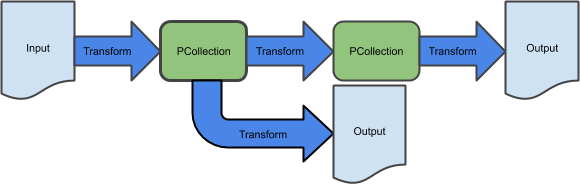
前のラボでは、基本的な抽出、変換、読み込みの連続的なパイプラインを作成し、対応する Dataflow テンプレートを使用して Google Cloud Storage のバッチ データ ストレージを取り込みました。このパイプラインは、以下に示す変換のシーケンスで構成されています。
しかし多くの場合、パイプラインはこのように単純な構造ではありません。このラボでは、より高度な連続的でないパイプラインを構築します。
今回のユースケースではリソース消費量を最適化します。プロダクトによってリソースの利用状況は異なります。また、一つの企業内でもすべてのデータが同じように使われるわけではなく、たとえば分析ワークロードで定期的にクエリされるデータもあれば、復元にのみ使用されるデータもあります。
このラボでは、最初のラボで作成したパイプラインのリソース消費量を最適化するために、アナリストが使用するデータのみを BigQuery に保存し、他のデータは低コストで耐久性の高いストレージ サービスである Google Cloud Storage の Coldline Storage にアーカイブします。
各ラボでは、新しい Google Cloud プロジェクトとリソースセットを一定時間無料で利用できます。
シークレット ウィンドウを使用して Google Skills にログインします。
ラボのアクセス時間(例: 1:15:00)に注意し、時間内に完了できるようにしてください。
一時停止機能はありません。必要な場合はやり直せますが、最初からになります。
準備ができたら、[ラボを開始] をクリックします。
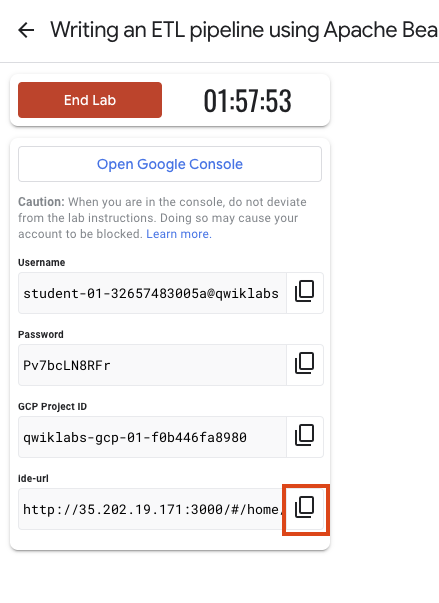
ラボの認証情報(ユーザー名とパスワード)をメモしておきます。この情報は、Google Cloud コンソールにログインする際に使用します。
[Google コンソールを開く] をクリックします。
[別のアカウントを使用] をクリックし、このラボの認証情報をコピーしてプロンプトに貼り付けます。 他の認証情報を使用すると、エラーや料金が発生します。
利用規約に同意し、再設定用のリソースページをスキップします。
Google Cloud Shell は、開発ツールと一緒に読み込まれる仮想マシンです。5 GB の永続ホーム ディレクトリが用意されており、Google Cloud で稼働します。
Google Cloud Shell を使用すると、コマンドラインで Google Cloud リソースにアクセスできます。
Google Cloud コンソールで、右上のツールバーにある [Cloud Shell をアクティブにする] ボタンをクリックします。
[続行] をクリックします。
環境がプロビジョニングされ、接続されるまでしばらく待ちます。接続した時点で認証が完了しており、プロジェクトに各自のプロジェクト ID が設定されます。次に例を示します。
gcloud は Google Cloud のコマンドライン ツールです。このツールは、Cloud Shell にプリインストールされており、タブ補完がサポートされています。
出力:
出力例:
出力:
出力例:
Google Cloud で作業を開始する前に、Identity and Access Management(IAM)内で適切な権限がプロジェクトに付与されていることを確認する必要があります。
Google Cloud コンソールのナビゲーション メニュー(
Compute Engine のデフォルトのサービス アカウント {project-number}-compute@developer.gserviceaccount.com が存在し、編集者のロールが割り当てられていることを確認します。アカウントの接頭辞はプロジェクト番号で、ナビゲーション メニュー > [Cloud の概要] > [ダッシュボード] から確認できます。
編集者のロールがない場合は、以下の手順に沿って必要なロールを割り当てます。729328892908)をコピーします。{project-number} はプロジェクト番号に置き換えてください。このラボでは、Google Compute Engine でホストされる Theia Web IDE を主に使用します。これには、事前にクローンが作成されたラボリポジトリが含まれます。Java 言語サーバーがサポートされているとともに、Cloud Shell に似た仕組みで、gcloud コマンドライン ツールを通じて Google Cloud API へのプログラムによるアクセスが可能なターミナルも使用できます。
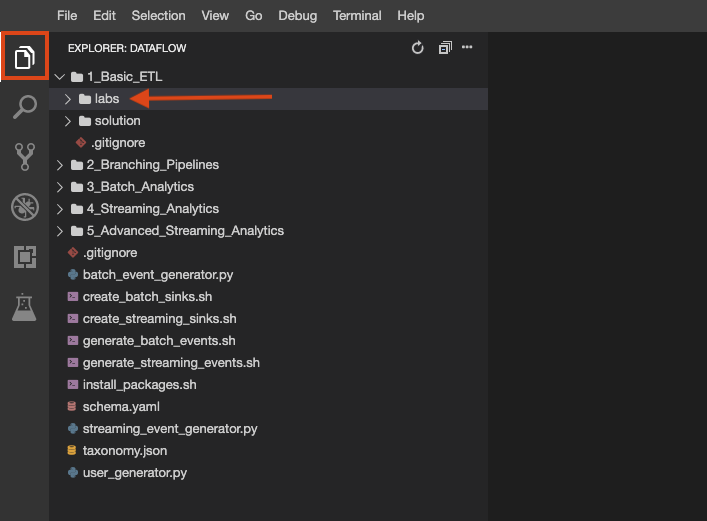
ラボリポジトリのクローンが環境に作成されました。各ラボは、完成させるコードが格納される labs フォルダと、ヒントが必要な場合に完全に機能するサンプルを参照できる solution フォルダに分けられています。
ファイル エクスプローラ ボタンをクリックして確認します。Cloud Shell で行うように、この環境で複数のターミナルを作成することも可能です。
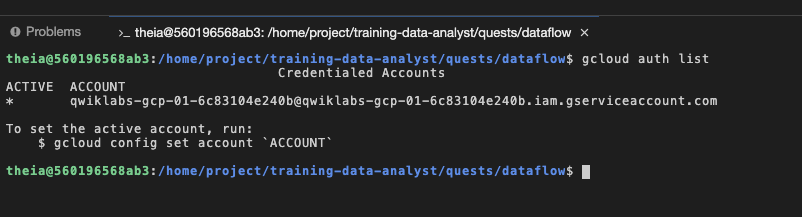
提供されたサービス アカウント(ラボのユーザー アカウントとまったく同じ権限がある)でログインしたターミナルで gcloud auth list を実行すれば、以下を確認できます。
環境が機能しなくなった場合は、IDE をホストしている VM を GCE コンソールから次のようにリセットしてみてください。
このラボでは、Google Cloud Storage と BigQuery の両方にデータを書き込む、分岐するパイプラインを作成します。分岐するパイプラインを作成する方法の一つは、2 つの異なる変換を同じ PCollection に適用することにより、2 つの異なる PCollection を作成することです。
このセクションや後のセクションでヒントが必要な場合は、ソリューションを参照してください。
このタスクを完了するには、Cloud Storage に書き込むブランチを追加して既存のパイプラインを変更します。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
2_Branching_Pipelines/labs/src/main/java/com/mypackage/pipeline にある MyPipeline.java を開きます。<CommonLog> に変換される前に、TextIO.write() を使用して Cloud Storage への書き込みを行う新しい分岐変換を追加することで、このコードを変更します。このセクションや後のセクションでヒントが必要な場合は、training-data-analyst ファイルをご覧ください。
スキーマは、プログラミング言語の特定の種類に依存しない Beam レコードの型システムを提供します。複数の Java クラスのすべてに同じスキーマが含まれている可能性があり(プロトコル バッファ クラスや POJO クラスなど)、Beam によってこれらの型をシームレスに変換できます。スキーマを使えば、さまざまなプログラミング言語 API で簡単に型を推測できます。
スキーマを含む PCollection では、Beam がスキーマ行のエンコードとデコードの方法を認識するため、コーダーを指定する必要がありません。Beam はスキーマタイプのエンコードに特別なコーダーを使用します。スキーマ API を導入する前に、Beam がパイプラインのすべてのオブジェクトをエンコードする方法を認識している必要があります。
この時点では、すべてのデータが 2 回保存されるため、新しいパイプラインでもリソースの消費量は減りません。リソース消費量を改善するには、重複するデータの量を減らす必要があります。Google Cloud Storage バケットの使用目的は、アーカイブおよびバックアップ ストレージとしての機能なので、すべてのデータを保存する必要があります。一方、BigQuery にはすべてのデータを送る必要はありません。
たとえば、データ アナリストが頻繁に確認する対象が、ウェブサイトでユーザーがアクセスするリソースや、地域と時間に応じたアクセス パターンの違いである場合、必要なフィールドはごく一部です。
各オブジェクトを変換して一部のフィールドのみを返す DoFn を作成することもできますが、Apache Beam にはスキーマを含む PCollection 用にさまざまなリレーショナル変換が用意されています。各レコードは名前付きフィールドで構成されているので、SQL 式での集計と同様に、フィールドを名前で参照するシンプルでわかりやすい集計が可能になります。
Select および DropFields 変換はこのうちの 2 つです。
重要: これらの各例は、PCollection<MyClass> ではなく PCollection<Row> を返します。Row クラスはあらゆるスキーマに対応できる、汎用スキーマ化されたオブジェクトと考えることができます。スキーマを含む PCollection を行の PCollection にキャストできます。
上の 2 つの変換はフィールドを削除するため、どちらも完全な CommonLog オブジェクトを返しません。その結果、Row を返す変換に戻ります。新しい名前付きスキーマを作成するか、中間の POJO スキーマを登録することもできますが、当面は Row を使用する方が簡単です。
重要: すでにメソッド チェーンで BigQueryIO.<CommonLog>write() メソッドを追加している場合は、新しいタイプなので <Row> に変更する必要があります。
Apache Beam にはフィルタリングの方法が数多くあります。前のタスクでスキーマ変換を使用した方法を説明しました。この実装では、各要素の一部を除外した結果、スキーマと残りのフィールドのサブセットを含む新しい Row オブジェクトが返されました。以下の例のように、簡単にすべての要素を除外できます。
パイプラインには現在、入力のパスや BigQuery のテーブルの場所など、多くのパラメータがハードコードされています。Cloud Storage の任意の JSON ファイルを読み取ることができれば、パイプラインがさらに便利になります。この機能を追加するには、一連のコマンドライン パラメータへの追加が必要です。
現在パイプラインでは PipelineOptionsFactory を使用して Options というカスタムクラスのインスタンスが生成されていますが、このクラスは PipelineOptions クラスと何も変わらないので、実質的には PipelineOptions のインスタンスです。
PipelineOptions クラスは、次の形式のコマンドライン引数を処理します。
ただし、ごく一部の定義済みパラメータに限られます。get- 関数はこちらで確認できます。
カスタム パラメータを追加するには、2 つの手順を行います。
PipelineOptionsFactory でインターフェースを登録し、PipelineOptions オブジェクトの作成時にインターフェースを渡します。PipelineOptionsFactory でインターフェースを登録する場合、--help でカスタム オプション インターフェースを検索し、--help コマンドの出力に追加できます。PipelineOptionsFactory は、カスタム オプションが他のすべての登録済みオプションと互換であることも検証します。次のコード例は、PipelineOptionsFactory でカスタム オプション インターフェースを登録する方法を示しています。
お気づきかもしれませんが、前回のラボで作成した BigQuery テーブルには、すべてのフィールドを REQUIRED とする次のようなスキーマがありました。
パイプラインの実行自体とこれを反映するスキーマで構成される BigQuery テーブルの両方に対して、データが存在しない NULLABLE フィールドを持つ Apache Beam スキーマを作成することをおすすめします。
Javax 表記をクラス定義に追加できます。これは次のように Apache Beam スキーマに組み込まれます。
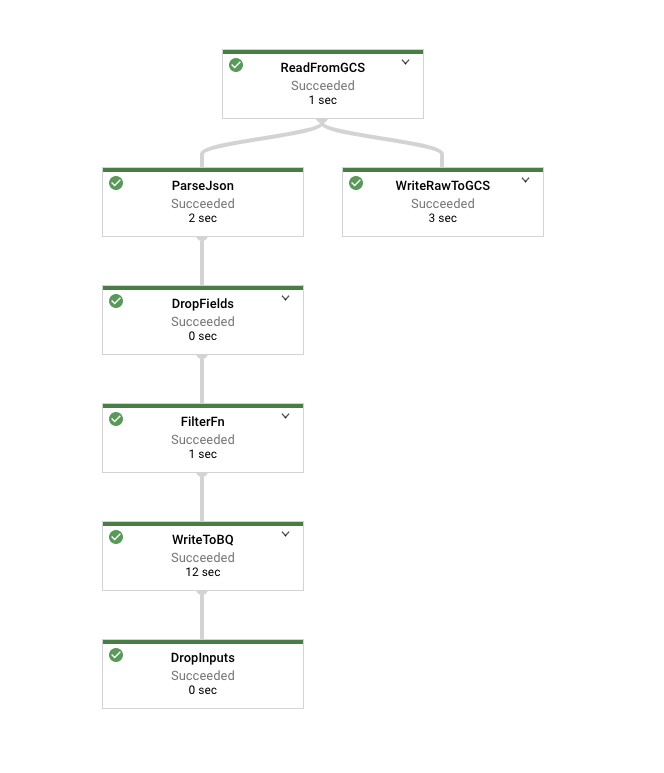
lat および lon フィールドを null 可能としてマークします。Filter 関数を表すノード(上の図では FilterFn)をクリックします。右側に表示されたパネルで、入力として追加された要素が出力として書き込まれた要素よりも多いことが確認できます。
次に Cloud Storage への書き込みを表すノードをクリックします。すべての要素が書き込まれているので、この数字は Filter 関数への入力の要素数と一致しているはずです。
パイプラインが終了したら、テーブルに対してクエリを実行して BigQuery の結果を確認します。テーブル内のレコード数は Filter 関数で出力された要素の数と一致しているはずです。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
ラボが完了したら、[ラボを終了] をクリックします。ラボで使用したリソースが Google Skills から削除され、アカウントの情報も消去されます。
ラボの評価を求めるダイアログが表示されたら、星の数を選択してコメントを入力し、[送信] をクリックします。
星の数は、それぞれ次の評価を表します。
フィードバックを送信しない場合は、ダイアログ ボックスを閉じてください。
フィードバックやご提案の送信、修正が必要な箇所をご報告いただく際は、[サポート] タブをご利用ください。
Copyright 2026 Google LLC All rights reserved. Google および Google のロゴは、Google LLC の商標です。その他すべての社名および製品名は、それぞれ該当する企業の商標である可能性があります。



このコンテンツは現在ご利用いただけません
利用可能になりましたら、メールでお知らせいたします

ありがとうございます。
利用可能になりましたら、メールでご連絡いたします

1 回に 1 つのラボ
既存のラボをすべて終了して、このラボを開始することを確認してください