![Compute Engine のデフォルトのサービス アカウント名と編集者のステータスがハイライト表示された [権限] タブページ](https://cdn.qwiklabs.com/1nytD9OUuNUV9undyjUWeOS7LJmekReBDmkUjveCjcU%3D)


![[ターミナル] メニューでハイライト表示されている [新しいターミナル] オプション](https://cdn.qwiklabs.com/o3Hxy07QcEZ%2FwAucqGRJPFyRJWB0negMcYJph7S%2FDh4%3D)
![[VM インスタンス] ページで、リセットボタンと VM インスタンス名の両方がハイライト表示されている](https://cdn.qwiklabs.com/jDH1qGTOJ%2B1Hy2nxOPm1DPmO1JgUCjOmBvwycVWgqEk%3D)

始める前に
- ラボでは、Google Cloud プロジェクトとリソースを一定の時間利用します
- ラボには時間制限があり、一時停止機能はありません。ラボを終了した場合は、最初からやり直す必要があります。
- 画面左上の [ラボを開始] をクリックして開始します
Generate synthetic data
/ 10
Aggregating site traffic by user and run your pipeline
/ 10
Aggregating site traffic by minute and run the pipeline
/ 10

このラボの内容:
Java に関する基本的な知識。
各ラボでは、新しい Google Cloud プロジェクトとリソースセットを一定時間無料で利用できます。
シークレット ウィンドウを使用して Google Skills にログインします。
ラボのアクセス時間(例: 1:15:00)に注意し、時間内に完了できるようにしてください。
一時停止機能はありません。必要な場合はやり直せますが、最初からになります。
準備ができたら、[ラボを開始] をクリックします。
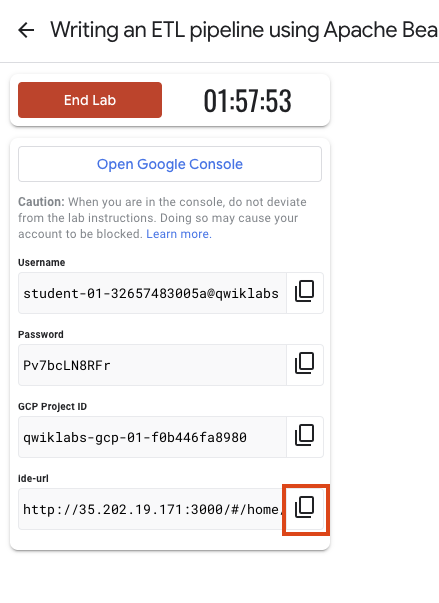
ラボの認証情報(ユーザー名とパスワード)をメモしておきます。この情報は、Google Cloud コンソールにログインする際に使用します。
[Google コンソールを開く] をクリックします。
[別のアカウントを使用] をクリックし、このラボの認証情報をコピーしてプロンプトに貼り付けます。 他の認証情報を使用すると、エラーや料金が発生します。
利用規約に同意し、再設定用のリソースページをスキップします。
Google Cloud で作業を開始する前に、Identity and Access Management(IAM)内で適切な権限がプロジェクトに付与されていることを確認する必要があります。
Google Cloud コンソールのナビゲーション メニュー(
Compute Engine のデフォルトのサービス アカウント {project-number}-compute@developer.gserviceaccount.com が存在し、編集者のロールが割り当てられていることを確認します。アカウントの接頭辞はプロジェクト番号で、ナビゲーション メニュー > [Cloud の概要] > [ダッシュボード] から確認できます。
編集者のロールがない場合は、以下の手順に沿って必要なロールを割り当てます。729328892908)をコピーします。{project-number} はプロジェクト番号に置き換えてください。Google Cloud Shell は、開発ツールと一緒に読み込まれる仮想マシンです。5 GB の永続ホーム ディレクトリが用意されており、Google Cloud で稼働します。
Google Cloud Shell を使用すると、コマンドラインで Google Cloud リソースにアクセスできます。
Google Cloud コンソールで、右上のツールバーにある [Cloud Shell をアクティブにする] ボタンをクリックします。
[続行] をクリックします。
環境がプロビジョニングされ、接続されるまでしばらく待ちます。接続した時点で認証が完了しており、プロジェクトに各自のプロジェクト ID が設定されます。次に例を示します。
gcloud は Google Cloud のコマンドライン ツールです。このツールは、Cloud Shell にプリインストールされており、タブ補完がサポートされています。
出力:
出力例:
出力:
出力例:
このラボでは、Google Compute Engine でホストされる Theia Web IDE を主に使用します。これには、事前にクローンが作成されたラボリポジトリが含まれます。Java 言語サーバーがサポートされているとともに、Cloud Shell に似た仕組みで、gcloud コマンドライン ツールを通じて Google Cloud API へのプログラムによるアクセスが可能なターミナルも使用できます。
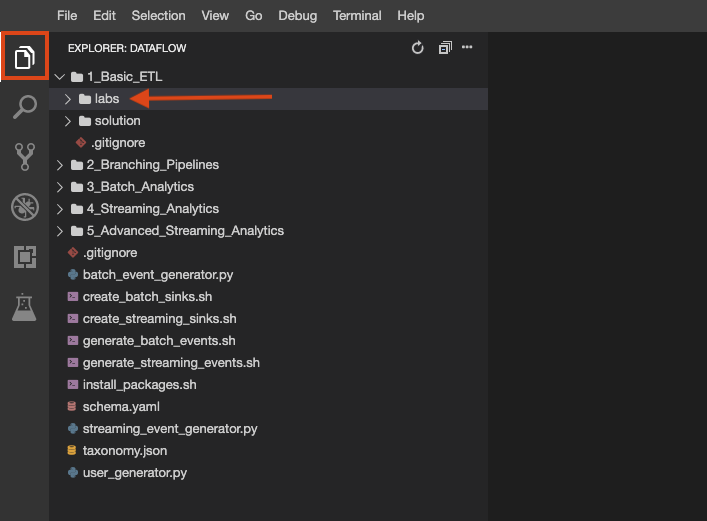
ラボリポジトリのクローンが環境に作成されました。各ラボは、完成させるコードが格納される labs フォルダと、ヒントが必要な場合に完全に機能するサンプルを参照できる solution フォルダに分けられています。
ファイル エクスプローラ ボタンをクリックして確認します。Cloud Shell で行うように、この環境で複数のターミナルを作成することも可能です。
提供されたサービス アカウント(ラボのユーザー アカウントとまったく同じ権限がある)でログインしたターミナルで gcloud auth list を実行すれば、以下を確認できます。
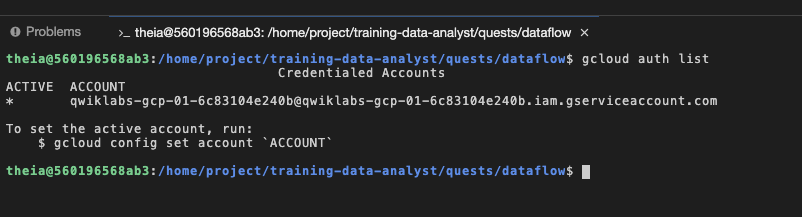
環境が機能しなくなった場合は、IDE をホストしている VM を GCE コンソールから次のようにリセットしてみてください。
ラボのこのパートでは、次のようなパイプラインを作成します。
CommonLog オブジェクトに変換する。以前のラボと同様に、最初のステップはパイプラインで処理するデータを生成することです。ラボ環境を開いて、以前と同じようにデータを生成します。
このスクリプトにより、次のような行が含まれている events.json というファイルが作成されます。
このファイルは gs://my-project-id/events.json の Google Cloud Storage バケットに自動的にコピーされます。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
BatchUserTrafficPipeline.java を開きます。これは 3_Batch_Analytics/labs/src/main/java/com/mypackage/pipeline にあります。このパイプラインには、入力パスと出力テーブル名のコマンドライン オプションを受け入れるために必要なコードと、Google Cloud Storage からイベントを読み取り、それらのイベントを解析して、結果を BigQuery に書き込むコードがすでに含まれています。ただし、いくつかの重要な部分が欠けています。
user_id 別にイベントを集計し、それぞれのページビューをカウントします。Beam スキーマを使用して Row やオブジェクトに対してこの操作を行う簡単な方法は、Group.byFieldNames() 変換を使用し、結果のグループに対していくつかの集計を実行することです。次に例を示します。これは「key」と「value」の 2 つのフィールドを含む行の PCollection を返します。「key」フィールド自体は、userID と address の一意の組み合わせをすべて表すスキーマ <userID:STRING, address:STRING> のある Row です。「values」フィールドは、ITERABLE[ROW[MyObject]] 型で、その一意のグループ内のすべてのオブジェクトが含まれます。
| FieldName | FieldType |
|---|---|
| key | ROW{userId:STRING, streetAddress:STRING} |
| values | ITERABLE[ROW[Purchase]] |
これは複数形の「values」ではなく、「key」「value」の Row を返します。
| FieldName | FieldType |
|---|---|
| key | ROW{userId:STRING} |
| value | ROW{numPurchases: INT64, totalSpendCents: INT64, largestPurchases: INT64} |
このような用途には Sum 変換と Count 変換が最適です。Sum と Count は、データのグループに作用する Combine 変換の例です。
Count.combineFn() フィールド、またはワイルドカード フィールド * を集計できます。これは、この変換が単にグループ全体に含まれる要素の数を数えているだけだからです。このタスクを完了するには、イベントを user_id でグループ化し、関連する集計を実行する別の変換をパイプラインに追加します。入力、使用する CombineFns、出力フィールドの命名方法にご注意ください。
この時点で、すでに述べたように、新しい変換はスキーマ <Key,Value> のある PCollection を返します。パイプラインをそのまま実行すると、本来それぞれ 1 行の値しかない場合でも、2 つのネストされた RECORDS として BigQuery に書き込まれます。
Select 変換を追加することで回避できます。これにより、新しいフラット化されたスキーマで関連するフィールド名が保持され、「key」と「value」が削除されます。
Select 変換を追加して、新しい行のスキーマをフラット化します。注: BigQueryIO.<CommonLog>write() のオブジェクト ヒントを <Row> に変更していない場合は、忘れずに変更してください。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
このタスクを完了するには、パイプラインが完了するまで数分待ってから、BigQuery に移動して user_traffic テーブルに対してクエリを実行します。
興味がある場合は、Select 変換ステップをコメントアウトしてパイプラインを再実行し、結果の BigQuery スキーマを確認してください。
ラボのこのパートでは、BatchMinuteTraffic という新しいパイプラインを作成します。BatchMinuteTraffic は、BatchUserTraffic で使用されている基本的なバッチ分析原則を拡張し、バッチ全体でユーザー別に集計するのではなく、イベントが発生した時間ごとに集計します。
3_Batch_Analytics/labs/src/main/java/com/mypackage/pipeline 内のファイル BatchMinuteTrafficPipeline.java を開きます。制限なしソースから各要素のタイムスタンプが提供されます。制限なしソースによっては、元データ ストリームからタイムスタンプを抽出する方法を構成する必要があるかもしれません。
ただし、有限ソース(このパイプラインで使用される TextIO からのファイルなど)はタイムスタンプを提供しません。
ウィンドウ処理では、PCollection を個々の要素のタイムスタンプに基づいて細分化します。複数の要素を集計する変換である GroupByKey や Combine などは、暗黙的にウィンドウ単位で動作します。各 PCollection は、全体のサイズが無限のこともありますが、複数の有限ウィンドウが連続的につながったものとして処理されます。
PCollection の要素を分割するために、さまざまな種類のウィンドウを定義できます。Beam では、次のようないくつかのウィンドウ処理関数が用意されています。
このラボでは、固定時間ウィンドウを使用します。固定時間ウィンドウは、データ ストリームの間隔に重複がない一貫した継続期間を表します。5 分間のウィンドウについて考えてみます。制限なし PCollection で、タイムスタンプ値が 0:00:00 から 0:05:00 まで(0:05:00 は含まれない)のすべての要素が最初のウィンドウに属し、タイムスタンプ値が 0:05:00 から 0:10:00 まで(0:10:00 は含まれない)の要素は 2 番目のウィンドウに属します。その後に関しても同様です。
他の種類のウィンドウ処理について詳しくは、Apache Beam ドキュメントのウィンドウ関数に関するセクションをご覧ください。
次に、パイプラインで各ウィンドウ内に発生したイベントの数を計算する必要があります。BatchUserTraffic パイプラインでは、キーごとの合計に Sum 変換を使用しました。しかし、今回はそのパイプラインとは違い、要素がウィンドウ処理されており、目的の計算でウィンドウ境界を考慮する必要があります。
この新たな制約にもかかわらず、やはり Combine 変換が適切です。これは、Combine 変換がウィンドウ境界を自動的に考慮するためです。
Beam 2.22 の時点では、ウィンドウ処理中に行の要素をカウントする最適な方法は、Combine.globally(Count.<T>combineFn()).withoutDefaults() を使用することです(つまり、全面的に SQL を使用するわけではありません。これについては次のラボで詳しく説明します)。この変換は PCollection<Long> 型を出力しますが、これには Beam スキーマが使用されていないことがわかります。
BigQuery に書き込むには、各要素を「pageviews」というフィールドと「minute」という追加フィールドを含む Row オブジェクトに変換し直す必要があります。これは、各ウィンドウの境界を 1 つのフィールドとして、ページビューの合計数をもう 1 つのフィールドとして使用するという考え方です。
これまでのところ、要素は JSON String から CommonLog オブジェクトに変換されると常に Beam スキーマに準拠しており、場合によっては Row オブジェクトに戻っています。元のスキーマは @DefaultSchema(JavaFieldSchema.class) アノテーションを介して CommonLog POJO から推論され、その後追加 / 削除されたフィールドはパイプライン変換で指定されました。ただし、パイプラインのこの時点では、Count 変換の出力のとおり、すべての要素は Long 型になります。したがって、新しい Row オブジェクトをゼロから作成する必要があります。
CommonLog オブジェクト定義と同様に、main() メソッドの外側に追加されます。Row オブジェクトは、次のような Long などの入力に基づいて、PTransform で作成できます。スキーマの作成と推論の詳細については、Apache の Beam SQL チュートリアルをご覧ください。
もう一つの問題は、現時点では、Count 変換がタイムスタンプ情報を持たない Long 型の要素しか提供しないということです。
ただし、実際には、それほど明白な方法によってではありませんが、それらの要素はタイムスタンプ情報を持ちます。Apache Beam ランナーは、イベント タイムスタンプ、ウィンドウ、パイプライン オプションなど、多くの追加パラメータの値を提供する方法をデフォルトで認識しています。完全なリストについては、Apache の DoFn パラメータのドキュメントをご覧ください。
pageViewsSchema を使用して Row 型の要素を出力する ParDo 関数を作成します。この関数には、IntervalWindow 型の追加の入力パラメータが含まれています。この追加パラメータを使用して Instant のインスタンスを作成し、これを使用して分フィールド「:」の文字列表現を導き出します。[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
minute_traffic テーブルに対してクエリを実行します。ラボが完了したら、[ラボを終了] をクリックします。ラボで使用したリソースが Google Skills から削除され、アカウントの情報も消去されます。
ラボの評価を求めるダイアログが表示されたら、星の数を選択してコメントを入力し、[送信] をクリックします。
星の数は、それぞれ次の評価を表します。
フィードバックを送信しない場合は、ダイアログ ボックスを閉じてください。
フィードバックやご提案の送信、修正が必要な箇所をご報告いただく際は、[サポート] タブをご利用ください。
Copyright 2026 Google LLC All rights reserved. Google および Google のロゴは、Google LLC の商標です。その他すべての社名および製品名は、それぞれ該当する企業の商標である可能性があります。



このコンテンツは現在ご利用いただけません
利用可能になりましたら、メールでお知らせいたします

ありがとうございます。
利用可能になりましたら、メールでご連絡いたします

1 回に 1 つのラボ
既存のラボをすべて終了して、このラボを開始することを確認してください