Mettez en pratique vos compétences dans la console Google Cloud
Points de contrôle
Generate synthetic data
Vérifier ma progression
/ 10
Aggregating site traffic by user and run your pipeline
Vérifier ma progression
/ 10
Aggregating site traffic by minute and run the pipeline
Vérifier ma progression
/ 10
Instructions et exigences de configuration de l'atelier
Protégez votre compte et votre progression. Utilisez toujours une fenêtre de navigation privée et les identifiants de l'atelier pour exécuter cet atelier.
Traitement de données sans serveur avec Dataflow : pipelines d'analyse par lot avec Dataflow (Java)
Ce contenu n'est pas encore optimisé pour les appareils mobiles.
Pour une expérience optimale, veuillez accéder à notre site sur un ordinateur de bureau en utilisant un lien envoyé par e-mail.
Présentation
Au cours de cet atelier, vous allez :
Écrire un pipeline qui agrège le trafic du site par utilisateur
Écrire un pipeline qui agrège le trafic du site par minute
Implémenter le fenêtrage sur des données de séries temporelles
Prérequis
Connaître les bases de Java
Préparation
Pour chaque atelier, nous vous attribuons un nouveau projet Google Cloud et un nouvel ensemble de ressources pour une durée déterminée, sans frais.
Connectez-vous à Google Skills dans une fenêtre de navigation privée.
Vérifiez le temps imparti pour l'atelier (par exemple : 01:15:00) : vous devez pouvoir le terminer dans ce délai.
Une fois l'atelier lancé, vous ne pourrez pas le mettre sur pause. Si nécessaire, vous pourrez le redémarrer, mais vous devrez tout reprendre depuis le début.
Lorsque vous êtes prêt, cliquez sur Démarrer l'atelier.
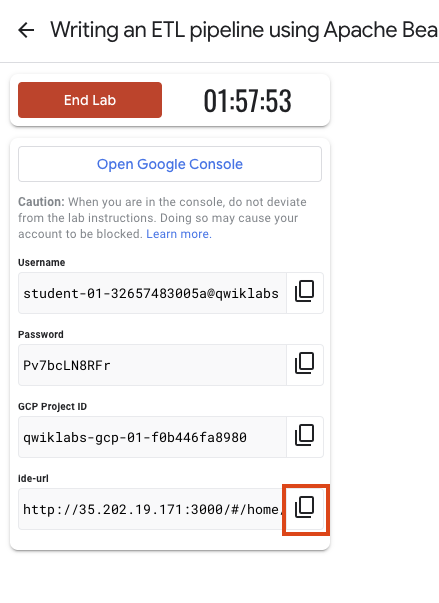
Notez vos identifiants pour l'atelier (Nom d'utilisateur et Mot de passe). Ils vous serviront à vous connecter à la console Google Cloud.
Cliquez sur Ouvrir la console Google.
Cliquez sur Utiliser un autre compte, puis copiez-collez les identifiants de cet atelier lorsque vous y êtes invité.
Si vous utilisez d'autres identifiants, des messages d'erreur s'afficheront ou des frais seront facturés.
Acceptez les conditions d'utilisation et ignorez la page concernant les ressources de récupération des données.
Vérifier les autorisations du projet
Avant de commencer à travailler dans Google Cloud, vous devez vous assurer de disposer des autorisations adéquates pour votre projet dans IAM (Identity and Access Management).
Dans la console Google Cloud, accédez au menu de navigation (), puis sélectionnez IAM et administration > IAM.
Vérifiez que le compte de service Compute par défaut {project-number}-compute@developer.gserviceaccount.com existe et qu'il est associé au rôle editor (éditeur). Le préfixe du compte correspond au numéro du projet, disponible sur cette page : Menu de navigation > Présentation du cloud > Tableau de bord.
Remarque : Si le compte n'est pas disponible dans IAM ou n'est pas associé au rôle editor (éditeur), procédez comme suit pour lui attribuer le rôle approprié.
Dans la console Google Cloud, accédez au menu de navigation et cliquez sur Présentation du cloud > Tableau de bord.
Copiez le numéro du projet (par exemple, 729328892908).
Dans le menu de navigation, sélectionnez IAM et administration > IAM.
Sous Afficher par compte principal, en haut de la table des rôles, cliquez sur Accorder l'accès.
Dans le champ Nouveaux comptes principaux, saisissez :
Remplacez {project-number} par le numéro de votre projet.
Dans le champ Rôle, sélectionnez Projet (ou Basique) > Éditeur.
Cliquez sur Enregistrer.
Activer Google Cloud Shell
Google Cloud Shell est une machine virtuelle qui contient de nombreux outils pour les développeurs. Elle comprend un répertoire d'accueil persistant de 5 Go et s'exécute sur Google Cloud.
Google Cloud Shell vous permet d'accéder à vos ressources Google Cloud grâce à une ligne de commande.
Dans la barre d'outils située en haut à droite dans la console Cloud, cliquez sur le bouton "Ouvrir Cloud Shell".
Cliquez sur Continuer.
Le provisionnement et la connexion à l'environnement prennent quelques instants. Une fois connecté, vous êtes en principe authentifié et le projet est défini sur votre ID_PROJET. Par exemple :
gcloud est l'outil de ligne de commande pour Google Cloud. Il est préinstallé sur Cloud Shell et permet la complétion par tabulation.
Vous pouvez lister les noms des comptes actifs à l'aide de cette commande :
Vous pouvez lister les ID de projet à l'aide de cette commande :
gcloud config list project
Résultat :
[core]
project =
Exemple de résultat :
[core]
project = qwiklabs-gcp-44776a13dea667a6
Remarque : Pour consulter la documentation complète sur gcloud, accédez au guide de présentation de la gcloud CLI.
Configurer votre IDE
Dans cet atelier, vous utiliserez principalement un IDE Web Theia hébergé sur Google Compute Engine. Le dépôt de l'atelier y est précloné. L'IDE prend en charge les serveurs au langage Java et comprend un terminal permettant l'accès programmatique aux API Google Cloud avec l'outil de ligne de commande gcloud, comme avec Cloud Shell.
Pour accéder à votre IDE Theia, copiez le lien affiché dans Google Skills et collez-le dans un nouvel onglet.
Remarque : Le provisionnement complet de l'environnement peut prendre entre trois et cinq minutes, même après l'affichage de l'URL. En attendant, le navigateur indiquera une erreur.
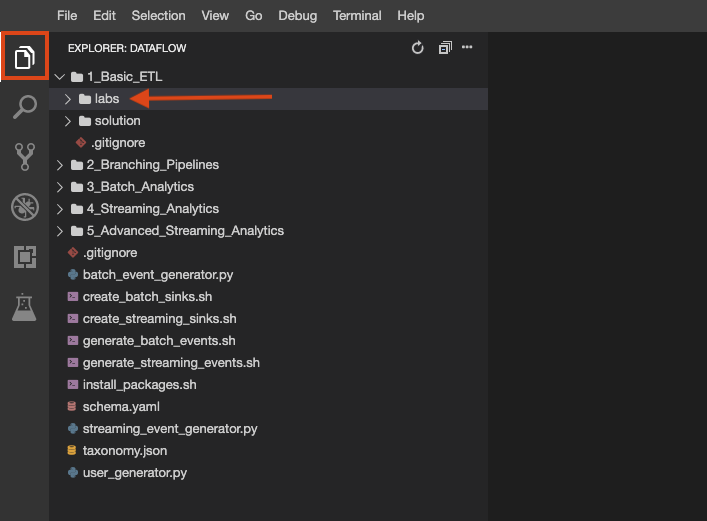
Le dépôt de l'atelier a été cloné dans votre environnement. Chaque atelier est divisé en deux dossiers : le premier, intitulé labs, contient du code que vous devez compléter, tandis que le second, nommé solution, comporte un exemple opérationnel que vous pouvez consulter si vous rencontrez des difficultés.
Cliquez sur le bouton Explorateur de fichiers pour y accéder :
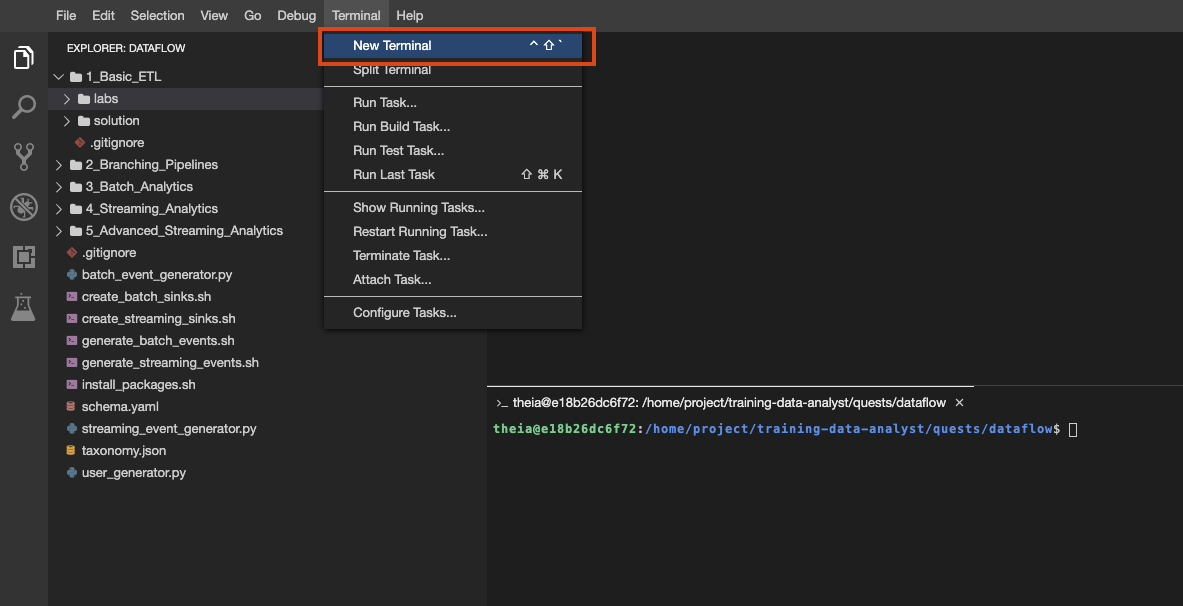
Vous pouvez également créer plusieurs terminaux dans cet environnement, comme vous le feriez avec Cloud Shell :
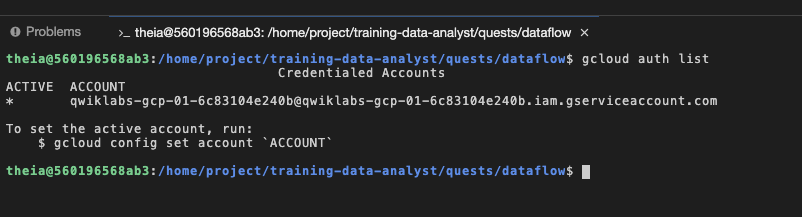
Vous pouvez exécuter la commande gcloud auth list dans le terminal pour vérifier que vous êtes connecté avec un compte de service fourni et que vous disposez donc des mêmes autorisations qu'avec votre compte utilisateur pour l'atelier :
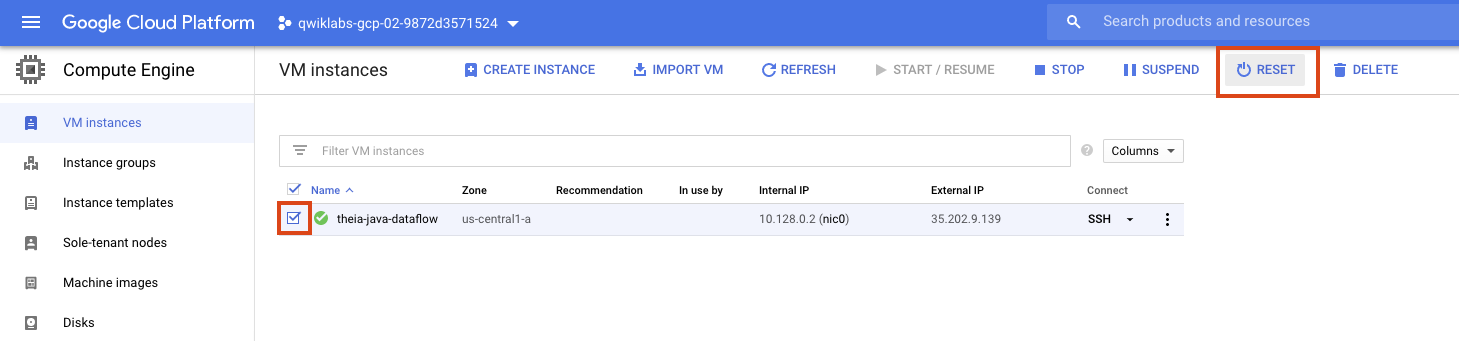
Si votre environnement cesse de fonctionner, vous pouvez essayer de réinitialiser la VM hébergeant votre IDE depuis la console GCE. Pour cela, procédez comme suit :
Partie 1 : Agréger le trafic du site par utilisateur
Dans cette partie de l'atelier, vous allez écrire un pipeline qui :
Lit le trafic de la journée à partir d'un fichier stocké dans Cloud Storage.
Convertit chaque événement en un objet CommonLog.
Additionne le nombre de hits pour chaque utilisateur unique en regroupant les objets par ID utilisateur et en combinant les valeurs pour obtenir le nombre total de hits pour cet utilisateur.
Effectue des agrégations supplémentaires sur chaque utilisateur.
Écrit les données résultantes dans BigQuery.
Tâche 1 : Générer des données synthétiques
Comme dans les ateliers précédents, la première étape consiste à générer les données que le pipeline va traiter. Vous allez ouvrir l'environnement de l'atelier et générer les données comme précédemment :
Ouvrir l'atelier approprié
Si ce n'est pas déjà fait, créez un terminal dans votre environnement IDE, puis copiez et collez la commande suivante :
# Change directory into the lab
cd 3_Batch_Analytics/labs
# Download dependencies
mvn clean dependency:resolve
export BASE_DIR=$(pwd)
Configurer l'environnement de données
# Create GCS buckets and BQ dataset
cd $BASE_DIR/../..
source create_batch_sinks.sh
# Generate event dataflow
source generate_batch_events.sh
# Change to the directory containing the practice version of the code
cd $BASE_DIR
Le script crée un fichier nommé events.json contenant des lignes semblables à ce qui suit :
Il copie ensuite automatiquement ce fichier dans votre bucket Google Cloud Storage à l'emplacement gs://my-project-id/events.json.
Accédez à Google Cloud Storage et vérifiez que votre bucket de stockage contient bien un fichier nommé "events.json".
Cliquez sur Vérifier ma progression pour valider l'objectif.
Générer des données synthétiques
Tâche 2 : Compter les pages vues par utilisateur
Ouvrez le fichier BatchUserTrafficPipeline.java dans votre IDE. Vous le trouverez dans 3_Batch_Analytics/labs/src/main/java/com/mypackage/pipeline.
Ce pipeline contient déjà le code nécessaire pour accepter les options de ligne de commande (chemin d'entrée, nom de table de sortie) ainsi que le code permettant de lire les événements depuis Google Cloud Storage, de les analyser et d'écrire les résultats dans BigQuery. Cependant, il manque certaines étapes clés.
L'étape suivante du pipeline consiste à agréger les événements par user_id unique et à compter les pages vues pour chaque utilisateur. Une façon simple de réaliser cela sur des objets Row ou des objets disposant d'un schéma Beam consiste à utiliser la transformation Group.byFieldNames(), puis à effectuer des agrégations sur le groupe obtenu. Exemple :
Cette instruction renvoie une PCollection de lignes avec deux champs, "key" et "values". Le champ "key" est lui-même un objet Row dont le schéma est <userID:STRING, address:STRING>, qui représente chaque combinaison unique de userID et address. Le champ "values" est de type ITERABLE[ROW[MyObject]] et contient tous les objets de ce groupe unique.
Nom du champ
Type du champ
key
ROW{userId:STRING, streetAddress:STRING}
values
ITERABLE[ROW[Purchase]]
Cette approche est particulièrement utile lorsque vous pouvez effectuer des calculs d'agrégation sur ce regroupement et nommer les champs résultants, comme suit :
Les transformations Sum et Count sont parfaites pour ce type d'opération. Sum et Count sont des exemples de transformations Combine qui s'appliquent sur des groupes de données.
Remarque : Dans cet exemple, vous pourriez effectuer l'agrégation sur n'importe quel champ pour Count.combineFn(), ou même sur le champ de caractère générique *, car cette transformation compte simplement le nombre d'éléments dans l'ensemble du groupe.
L'étape suivante du pipeline consiste à agréger les événements par user_id, à additionner les pages vues (pageviews) et à calculer d'autres agrégations sur num_bytes, par exemple le nombre total d'octets par utilisateur.
Pour effectuer cette tâche, ajoutez une autre transformation au pipeline qui regroupe les événements par user_id, puis effectue les agrégations appropriées. Tenez compte des données d'entrée, des CombineFns à utiliser et du nommage des champs de sortie.
Tâche 3 : Aplatir le schéma
À ce stade, votre nouvelle transformation renvoie une PCollection dont le schéma est <Key,Value>, comme nous l'avons déjà mentionné. Si vous exécutez le pipeline tel quel, le résultat sera écrit dans BigQuery sous forme de deux enregistrements imbriqués (RECORDS), alors que chacun de ces enregistrements ne contient qu'une seule ligne de valeurs.
Pour éviter cela, vous pouvez ajouter une transformation Select comme suit :
Cela permet de conserver les noms de champs utiles dans le nouveau schéma aplati et de supprimer "key" et "value".
Pour effectuer cette tâche, ajoutez une transformation Select afin d'aplatir le schéma de votre nouvelle ligne.
Remarque : N'oubliez pas de remplacer le type d'objet indiqué dans BigQueryIO.<CommonLog>write() par <Row> si vous ne l'avez pas encore fait.
Tâche 4 : Exécuter le pipeline
Revenez dans Cloud Shell et exécutez la commande suivante pour exécuter votre pipeline à l'aide du service Dataflow. Si vous rencontrez des difficultés, vous pouvez l'exécuter avec DirectRunner ou consulter la solution.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Agréger le trafic du site par utilisateur et exécuter votre pipeline
Tâche 5 : Vérifier les résultats dans BigQuery
Pour effectuer cette tâche, attendez quelques minutes que le pipeline se termine, puis accédez à BigQuery et interrogez la table user_traffic.
Si vous êtes curieux, mettez en commentaire l'étape de transformation Select et réexécutez le pipeline pour observer le schéma BigQuery résultant.
Partie 2 : Agréger le trafic du site par minute
Dans cette partie de l'atelier, vous allez créer un pipeline appelé "BatchMinuteTraffic". BatchMinuteTraffic s'appuie sur les principes de base de l'analyse par lots vus dans BatchUserTraffic. Cependant, au lieu d'agréger les données par utilisateur sur l'ensemble du lot, il agrège les événements en fonction du moment où ils se sont produits.
Dans l'IDE, ouvrez le fichier BatchMinuteTrafficPipeline.java qui se trouve dans 3_Batch_Analytics/labs/src/main/java/com/mypackage/pipeline.
Tâche 1 : Ajouter des codes temporels à chaque élément
Une source illimitée associe un code temporel à chaque élément. Selon la source illimitée utilisée, vous devrez peut-être configurer la façon dont ce code temporel est extrait du flux de données brutes.
En revanche, les sources limitées (comme un fichier de TextIO, utilisé dans ce pipeline) n'attribuent pas de codes temporels.
Vous pouvez analyser le champ de code temporel de chaque enregistrement et utiliser la transformation WithTimestamps pour associer ces codes temporels à chaque élément de la PCollection.
Pour réaliser cette tâche, ajoutez une transformation dans le pipeline qui attribue des codes temporels à chaque élément du pipeline.
Tâche 2 : Implémenter un fenêtrage d'une minute
Le fenêtrage subdivise une PCollection en fonction du code temporel de ses éléments individuels. Les transformations qui agrègent plusieurs éléments, telles que GroupByKey et Combine, fonctionnent implicitement par fenêtre. Elles traitent chaque PCollection comme une succession de fenêtres finies, même si la collection globale peut être de taille illimitée.
Vous pouvez définir différents types de fenêtres pour diviser les éléments de votre PCollection. Beam propose plusieurs types de fenêtrage, y compris :
Fenêtres fixes
Fenêtres glissantes
Fenêtres par session
Fenêtre globale unique
Fenêtres basées sur un calendrier (non prises en charge par le SDK Beam pour Python)
Dans cet atelier, vous allez utiliser des fenêtres fixes. Une fenêtre fixe représente un intervalle de temps sans chevauchement et de durée constante dans le flux de données. Par exemple, avec des fenêtres de cinq minutes, tous les éléments de la PCollection illimitée dont le code temporel est compris entre 0:00:00 (inclus) et 0:05:00 (exclu) appartiennent à la première fenêtre. Ceux dont le code temporel est compris entre 0:05:00 (inclus) et 0:10:00 (exclu) appartiennent à la deuxième fenêtre, et ainsi de suite.
Pour implémenter une fenêtre fixe d'une minute, procédez comme suit :
Ensuite, le pipeline doit calculer le nombre d'événements qui se sont produits dans chaque fenêtre. Dans le pipeline BatchUserTraffic, on utilisait une transformation Sum pour additionner les valeurs par clé. Ici, contrairement à ce pipeline, les éléments ont été fenêtrés et le calcul doit respecter les limites des fenêtres.
Malgré cette contrainte, la transformation Combine reste adaptée. En effet, les transformations Combine respectent automatiquement les limites des fenêtres.
Consultez la documentation sur Count pour savoir comment ajouter une transformation qui compte le nombre d'éléments par fenêtre.
Depuis Beam 2.22, la meilleure méthode pour compter les éléments des lignes lors du fenêtrage consiste à utiliser Combine.globally(Count.<T>combineFn()).withoutDefaults() (c'est-à-dire sans utiliser les requêtes SQL classiques, ce que nous aborderons plus en détail dans le prochain atelier). Cette transformation génère une sortie de type PCollection<Long> qui, comme vous pouvez le constater, n'utilise plus les schémas Beam.
Pour effectuer cette tâche, ajoutez une transformation qui compte tous les éléments de chaque fenêtre. N'hésitez pas à consulter la solution si vous rencontrez des difficultés.
Tâche 4 : Reconvertir les éléments en objets Row et ajouter un code temporel
Pour écrire dans BigQuery, chaque élément doit être reconverti en un objet Row comportant un champ "pageviews" et un autre champ appelé "minute". L'idée est d'utiliser la limite de chaque fenêtre comme premier champ et le nombre total de pages vues comme second champ.
Jusqu'à présent, les éléments ont toujours respecté un schéma Beam, que ce soit après leur conversion d'une chaîne JSON en objet CommonLog, ou lorsqu'ils étaient reconvertis en objets Row. Le schéma d'origine a été inféré du POJO CommonLog grâce à l'annotation @DefaultSchema(JavaFieldSchema.class), et tous les champs ajoutés ou supprimés par la suite ont été spécifiés dans les transformations du pipeline. Cependant, à ce stade du pipeline, comme le montre la sortie de la transformation Count, chaque élément est de type Long. Il faut donc créer un objet Row manuellement.
Vous pouvez créer et enregistrer des schémas manuellement comme suit. Ce code doit être ajouté en dehors de la méthode main(), comme la définition de l'objet CommonLog :
// Define the schema for the records.
Schema appSchema =
Schema
.builder()
.addInt32Field("appId")
.addStringField("description")
.addDateTimeField("rowtime")
.build();
Les objets Row correspondant à ce schéma peuvent ensuite être créés dans une PTransform, éventuellement à partir d'entrées telles qu'un Long, par exemple :
En général, Beam requiert de spécifier le nouveau schéma dans la PTransform si la transformation crée un objet Row au lieu de modifier un objet Row existant :
À ce stade, un autre problème se pose : la transformation Count ne fournit que des éléments de type Long qui ne contiennent plus aucune information de code temporel.
En réalité, ces informations existent toujours, mais pas de manière évidente. Par défaut, les exécuteurs Apache Beam savent comment fournir la valeur de plusieurs paramètres supplémentaires, y compris les codes temporels d'événements, les fenêtres et les options de pipeline. Pour obtenir la liste complète, consultez la documentation d'Apache sur les paramètres DoFn.
Pour effectuer cette tâche, écrivez une fonction ParDo qui accepte des éléments de type Long et produit des éléments de type Row conformes au type de schéma pageViewsSchema fourni. Cette fonction doit également comporter un paramètre d'entrée supplémentaire de type IntervalWindow. Utilisez ce paramètre supplémentaire pour créer une instance d'Instant, puis utilisez cette instance pour obtenir une représentation sous forme de chaîne du champ "minute" :
@ProcessElement
public void processElement(@Element T l, OutputReceiver<T> r, IntervalWindow window) {
Instant i = Instant.ofEpochMilli(window.start().getMillis());
...
r.output(...);
}
Tâche 5 : Exécuter le pipeline
Une fois que vous avez terminé de coder, exécutez le pipeline à l'aide de la commande ci-dessous. N'oubliez pas que, pour tester votre code, il sera beaucoup plus rapide de remplacer la variable d'environnement RUNNER par DirectRunner, qui exécute le pipeline localement.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Agréger le trafic du site par minute et exécuter le pipeline
Tâche 6 : Vérifier les résultats
Pour effectuer cette tâche, attendez quelques minutes que le pipeline s'exécute, puis accédez à BigQuery et interrogez la table minute_traffic.
Terminer l'atelier
Une fois l'atelier terminé, cliquez sur Terminer l'atelier. Google Skills supprime les ressources que vous avez utilisées, puis efface le compte.
Si vous le souhaitez, vous pouvez noter l'atelier. Sélectionnez un nombre d'étoiles, saisissez un commentaire, puis cliquez sur Envoyer.
Voici à quoi correspond le nombre d'étoiles que vous pouvez attribuer à un atelier :
1 étoile = très insatisfait(e)
2 étoiles = insatisfait(e)
3 étoiles = ni insatisfait(e), ni satisfait(e)
4 étoiles = satisfait(e)
5 étoiles = très satisfait(e)
Si vous ne souhaitez pas donner votre avis, vous pouvez fermer la boîte de dialogue.
Pour soumettre des commentaires, suggestions ou corrections, veuillez accéder à l'onglet Assistance.
Copyright 2026 Google LLC Tous droits réservés. Google et le logo Google sont des marques de Google LLC. Tous les autres noms de société et de produit peuvent être des marques des sociétés auxquelles ils sont associés.
Les ateliers créent un projet Google Cloud et des ressources pour une durée déterminée.
Les ateliers doivent être effectués dans le délai imparti et ne peuvent pas être mis en pause. Si vous quittez l'atelier, vous devrez le recommencer depuis le début.
En haut à gauche de l'écran, cliquez sur Démarrer l'atelier pour commencer.
Utilisez la navigation privée
Copiez le nom d'utilisateur et le mot de passe fournis pour l'atelier
Cliquez sur Ouvrir la console en navigation privée
Connectez-vous à la console
Connectez-vous à l'aide des identifiants qui vous ont été attribués pour l'atelier. L'utilisation d'autres identifiants peut entraîner des erreurs ou des frais.
Acceptez les conditions d'utilisation et ignorez la page concernant les ressources de récupération des données.
Ne cliquez pas sur Terminer l'atelier, à moins que vous n'ayez terminé l'atelier ou que vous ne vouliez le recommencer, car cela effacera votre travail et supprimera le projet.
Ce contenu n'est pas disponible pour le moment
Nous vous préviendrons par e-mail lorsqu'il sera disponible
Parfait !
Nous vous contacterons par e-mail s'il devient disponible
Un atelier à la fois
Confirmez pour mettre fin à tous les ateliers existants et démarrer celui-ci
Utilisez la navigation privée pour effectuer l'atelier
Le meilleur moyen d'exécuter cet atelier consiste à utiliser une fenêtre de navigation privée. Vous éviterez ainsi les conflits entre votre compte personnel et le compte temporaire de participant, qui pourraient entraîner des frais supplémentaires facturés sur votre compte personnel.
Dans cet atelier, vous allez écrire un pipeline qui agrège le trafic du site par utilisateur et un pipeline qui agrège le trafic du site par minute.
Durée :
1 min de configuration
·
Accessible pendant 120 min
·
Terminé après 120 min

 ), puis sélectionnez IAM et administration > IAM.
), puis sélectionnez IAM et administration > IAM.