Este contenido aún no está optimizado para dispositivos móviles.
Para obtener la mejor experiencia, visítanos en una computadora de escritorio con un vínculo que te enviaremos por correo electrónico.
Descripción general
En este lab, aprenderás a hacer lo siguiente:
Escribir una canalización que agrupe el tráfico del sitio por usuario
Escribir una canalización que agrupe el tráfico del sitio por minuto
Implementar sistemas de ventanas en datos de series temporales
Requisitos
Conocimientos básicos sobre Java
Configuración y requisitos
En cada lab, recibirás un proyecto de Google Cloud y un conjunto de recursos nuevos por tiempo limitado y sin costo adicional.
Accede a Google Skills en una ventana de incógnito.
Ten en cuenta el tiempo de acceso del lab (por ejemplo, 1:15:00) y asegúrate de finalizarlo en el plazo asignado.
No existe una función de pausa. Si lo necesitas, puedes reiniciar el lab, pero deberás hacerlo desde el comienzo.
Cuando tengas todo listo, haz clic en Comenzar lab.
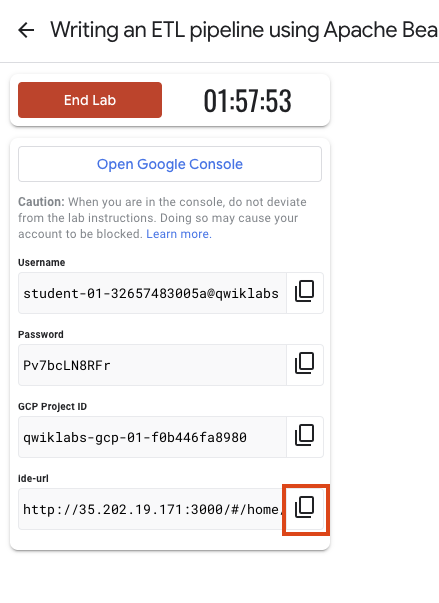
Anota las credenciales del lab (el nombre de usuario y la contraseña). Las usarás para acceder a la consola de Google Cloud.
Haz clic en Abrir la consola de Google.
Haz clic en Usar otra cuenta, copia las credenciales para este lab y pégalas en el mensaje emergente que aparece.
Si usas otras credenciales, se generarán errores o incurrirás en cargos.
Acepta las condiciones y omite la página de recursos de recuperación.
Verifica los permisos del proyecto
Antes de comenzar a trabajar en Google Cloud, asegúrate de que tu proyecto tenga los permisos correctos en Identity and Access Management (IAM).
En la consola de Google Cloud, en el Menú de navegación (), selecciona IAM y administración > IAM.
Confirma que aparezca la cuenta de servicio predeterminada de Compute {número-del-proyecto}-compute@developer.gserviceaccount.com, y que tenga asignado el rol Editor. El prefijo de la cuenta es el número del proyecto, que puedes encontrar en el menú de navegación > Descripción general de Cloud > Panel.
Nota: Si la cuenta no aparece en IAM o no tiene asignado el rol Editor, sigue los pasos que se indican a continuación para asignar el rol necesario.
En la consola de Google Cloud, en el menú de navegación, haz clic en Descripción general de Cloud > Panel.
Copia el número del proyecto (p. ej., 729328892908).
En el Menú de navegación, selecciona IAM y administración > IAM.
En la parte superior de la tabla de funciones, debajo de Ver por principales, haz clic en Otorgar acceso.
Reemplaza {número-del-proyecto} por el número de tu proyecto.
En Rol, selecciona Proyecto (o Básico) > Editor.
Haz clic en Guardar.
Activa Google Cloud Shell
Google Cloud Shell es una máquina virtual que cuenta con herramientas para desarrolladores. Ofrece un directorio principal persistente de 5 GB y se ejecuta en Google Cloud.
Google Cloud Shell proporciona acceso de línea de comandos a tus recursos de Google Cloud.
En la consola de Cloud, en la barra de herramientas superior derecha, haz clic en el botón Abrir Cloud Shell.
Haz clic en Continuar.
El aprovisionamiento y la conexión al entorno demorarán unos minutos. Cuando te conectes, habrás completado la autenticación, y el proyecto estará configurado con tu PROJECT_ID. Por ejemplo:
gcloud es la herramienta de línea de comandos de Google Cloud. Viene preinstalada en Cloud Shell y es compatible con el completado de línea de comando.
Puedes solicitar el nombre de la cuenta activa con este comando:
Para los fines de este lab, usará principalmente un IDE web de Theia alojado en Google Compute Engine. El IDE tiene el repositorio de labs clonado previamente. Se ofrece compatibilidad con servidores de lenguaje Java y una terminal para el acceso programático a las APIs de Google Cloud con la herramienta de línea de comandos de gcloud, similar a Cloud Shell.
Para acceder al IDE de Theia, copia y pega en una pestaña nueva el vínculo que se muestra en Google Skills.
Nota: Es posible que debas esperar entre 3 y 5 minutos para que se aprovisione por completo el entorno, incluso después de que aparezca la URL. Hasta ese momento, se mostrará un error en el navegador.
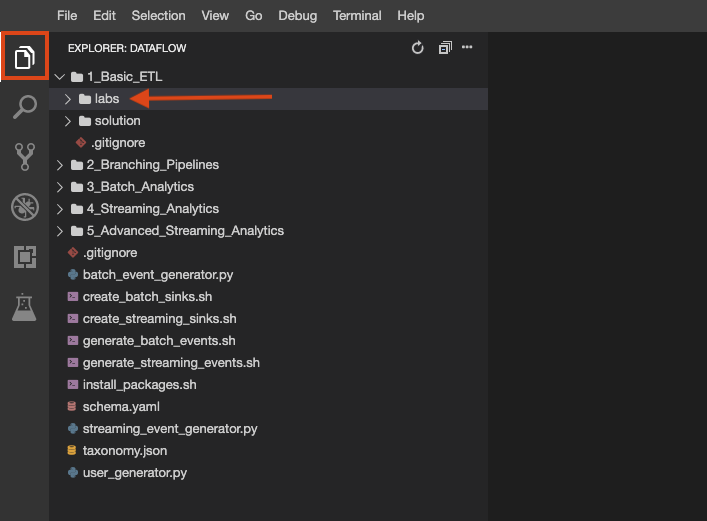
El repositorio del lab se clonó en tu entorno. Cada lab se divide en una carpeta labs con un código que debes completar y una carpeta solution con un ejemplo viable que puedes consultar como referencia si no sabes cómo continuar.
Haz clic en el botón File Explorer para ver lo siguiente:
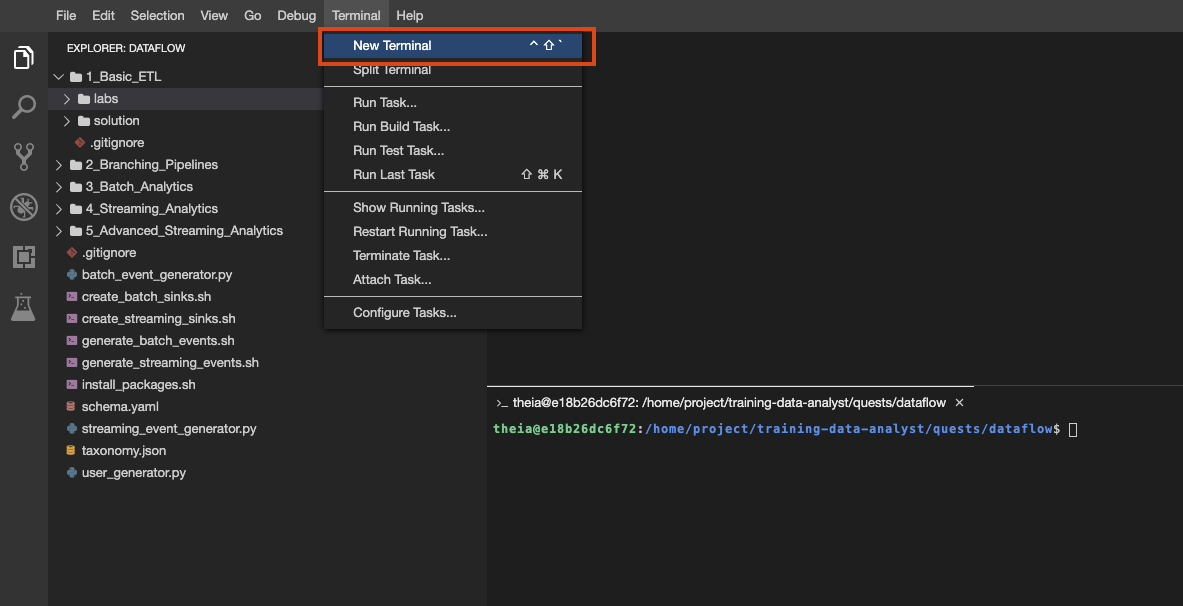
También puedes crear varias terminales en este entorno, como lo harías con Cloud Shell:
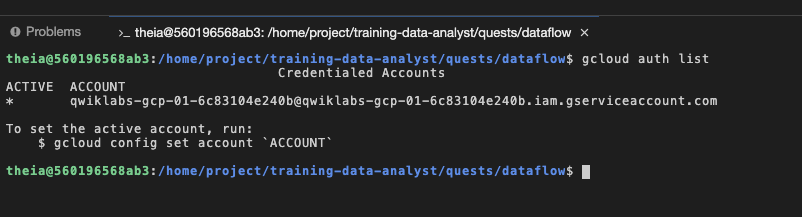
Para verificarlo, ejecuta gcloud auth list en la terminal con la que accediste como cuenta de servicio proporcionada, que tiene exactamente los mismos permisos que tu cuenta de usuario del lab:
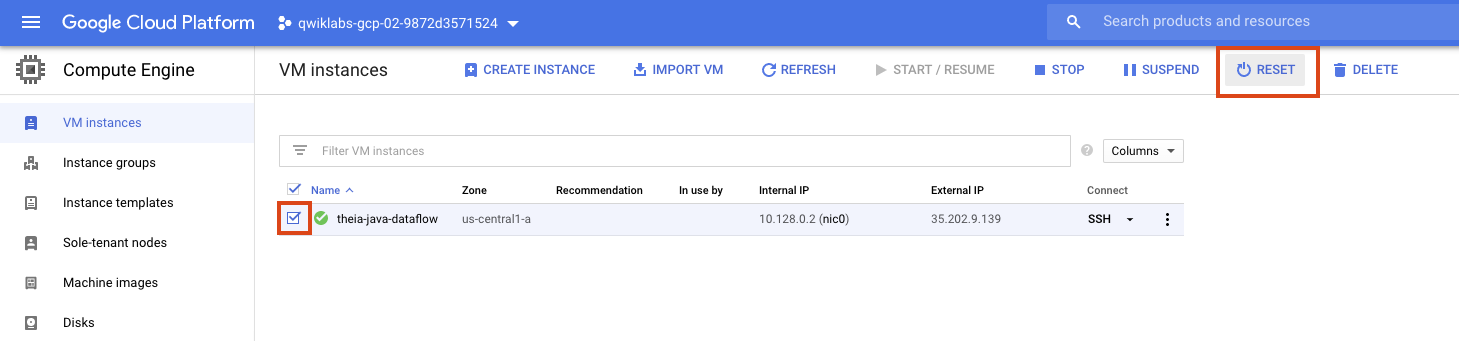
Si en algún momento tu entorno deja de funcionar, intenta restablecer la VM en la que se aloja el IDE desde la consola de GCE de la siguiente manera:
Parte 1: Agrupa el tráfico del sitio por usuario
En esta parte del lab, escribirás una canalización que realizará las siguientes acciones:
Leer el tráfico del día desde un archivo de Cloud Storage
Convertir cada evento en un objeto CommonLog
Sumar la cantidad de hits de cada usuario único, agrupando cada objeto por ID de usuario y combinando los valores para obtener la cantidad total de hits para ese usuario específico
Realizar agregaciones adicionales en cada usuario
Escribir los datos resultantes en BigQuery
Tarea 1. Genera datos sintéticos
Al igual que en los labs anteriores, el primer paso es generar datos para que la canalización los procese. Abre el entorno del lab y genera los datos como lo hiciste anteriormente:
Abre el lab adecuado
Si aún no lo has hecho, crea una terminal nueva en tu entorno de IDE y, luego, copia y pega el siguiente comando:
# Change directory into the lab
cd 3_Batch_Analytics/labs
# Download dependencies
mvn clean dependency:resolve
export BASE_DIR=$(pwd)
Configura el entorno de datos
# Crear buckets de GCS y un conjunto de datos de BQ
cd $BASE_DIR/../..
source create_batch_sinks.sh
# Generar evento de Dataflow
source generate_batch_events.sh
# Cambiar al directorio que contiene la versión de práctica del código
cd $BASE_DIR
La secuencia de comandos crea un archivo llamado events.json que contiene líneas similares a las siguientes:
Luego, copia este archivo automáticamente en tu bucket de Google Cloud Storage, en gs://my-project-id/events.json.
Navega a Google Cloud Storage y confirma que tu bucket de almacenamiento contenga un archivo llamado events.json.
Haz clic en Revisar mi progreso para verificar el objetivo.
Generar datos sintéticos
Tarea 2: Suma las páginas vistas por usuario
Abre BatchUserTrafficPipeline.java en tu IDE, que puedes encontrar en 3_Batch_Analytics/labs/src/main/java/com/mypackage/pipeline.
Esta canalización ya contiene el código necesario para aceptar las opciones de la línea de comandos de la ruta de entrada y el nombre de la tabla de salida, así como el código para leer en los eventos de Google Cloud Storage, analizarlos y escribir resultados en BigQuery. Sin embargo, faltan algunas partes importantes.
El siguiente paso en la canalización es agregar los eventos por cada user_id único y contar las páginas vistas de cada uno. Una manera sencilla de hacerlo en Rows o en objetos con un esquema de Beam es usar la transformación Group.byFieldNames() y, luego, realizar algunas agregaciones en el grupo resultante. Por ejemplo:
Esto mostrará una PCollection de filas con dos campos, “key” y “values”. El campo “key” en sí es una Row con el esquema <userID:STRING, address:STRING>, que representa cada combinación única de userID y address. El campo “values” es del tipo ITERABLE[ROW[MyObject]], que contiene todos los objetos de ese grupo único.
FieldName
FieldType
key
ROW{userId:STRING, streetAddress:STRING}
values
ITERABLE[ROW[Purchase]]
Esto es muy útil cuando se pueden realizar cálculos agregados en esta agrupación y nombrar los campos resultantes de la siguiente manera:
Las transformaciones Sum y Count son perfectas para este uso. Sum y Count son ejemplos de transformaciones Combine que pueden actuar sobre grupos de datos.
Nota: En este ejemplo, puedes realizar agregaciones en cualquiera de los campos de Count.combineFn() o, incluso, en el campo de comodín *, ya que esta transformación simplemente cuenta cuántos elementos hay en el grupo completo.
El siguiente paso de la canalización es agregar los eventos por user_id, sumar las páginas vistas y, además, calcular agregaciones adicionales en num_bytes, por ejemplo, el total de bytes del usuario.
Para completar esta tarea, agrega otra transformación a la canalización que agrupe los eventos por user_id y, luego, realiza las agregaciones relevantes. Ten en cuenta la entrada, las clases CombineFn que usarás y los nombres que asignarás a los campos de salida.
Tarea 3: Compacta el esquema
En este punto, la transformación nueva debería mostrar una PCollection con el esquema <Key,Value>, tal como se mencionó anteriormente. Si ejecutas tu canalización tal como está, se escribirá en BigQuery como dos RECORDS anidados, pese a que, básicamente, solo haya una fila de valores en cada uno.
Para evitar esto, agrega una transformación Select de la siguiente manera:
Esta transformación conservará los nombres de campo relevantes en el nuevo esquema compactado y quitará “key” y “value”.
Para completar esta tarea, agrega una transformación Select para compactar el esquema de tu nueva fila.
Nota: Recuerda cambiar la sugerencia del objeto en BigQueryIO.<CommonLog>write() a <Row> si aún no las hecho.
Tarea 4: Ejecuta tu canalización
Regresa a Cloud Shell y ejecuta el siguiente comando para ejecutar tu canalización con el servicio de Dataflow. Si tienes problemas, puedes ejecutarla con DirectRunner o consultar la solución.
Haz clic en Revisar mi progreso para verificar el objetivo.
Agregar tráfico del sitio por usuario y ejecutar la canalización
Tarea 5: Verifica los resultados en BigQuery
Para completar esta tarea, espera unos minutos hasta que se complete la canalización. Luego, navega a BigQuery y consulta la tabla user_traffic.
Si te interesa, puedes marcar como comentario el paso de transformación Select y volver a ejecutar la canalización para ver el esquema resultante de BigQuery.
Parte 2: Agrupa el tráfico del sitio por minuto
En esta parte del lab, crearás una nueva canalización llamada BatchMinuteTraffic. BatchMinuteTraffic amplía los principios básicos del análisis por lotes que se usan en BatchUserTraffic y, en lugar de agrupar el tráfico por usuarios en todo el lote, lo agrupa cuando ocurren los eventos.
En el IDE, abre el archivo BatchMinuteTrafficPipeline.java dentro de 3_Batch_Analytics/labs/src/main/java/com/mypackage/pipeline.
Tarea 1: Agrega marcas de tiempo a cada elemento
Una fuente no delimitada proporciona una marca de tiempo para cada elemento. Según la fuente no delimitada, es posible que debas configurar cómo se extrae la marca de tiempo del flujo de datos sin procesar.
Sin embargo, las fuentes delimitadas (p. ej., un archivo de TextIO, como el que se usa en esta canalización) no proporcionan marcas de tiempo.
Puedes analizar el campo de marca de tiempo desde cada registro y usar la transformación WithTimestamps para adjuntar las marcas de tiempo a cada elemento en tu PCollection.
Para completar esta tarea, agrega una transformación a la canalización que agregue marcas de tiempo a cada elemento de la canalización.
Tarea 2: Agrupa elementos en ventanas de un minuto
Un sistema de ventanas subdivide una PCollection de acuerdo con las marcas de tiempo de sus elementos individuales. Las transformaciones que agregan varios elementos, como GroupByKey y Combine, funcionan de forma implícita por ventana, es decir, procesan cada PCollection como una sucesión de ventanas múltiples y finitas, aunque toda la colección en sí puede ser de un tamaño ilimitado.
Puedes definir diferentes tipos de ventanas para dividir los elementos de tu PCollection. Beam proporciona varias funciones de ventanas, incluidas las siguientes:
Ventanas de tiempo fijo
Ventanas de tiempo variable
Ventanas por sesión
Ventana global única
Ventanas basadas en el calendario (no compatibles con el SDK de Beam para Python)
En este lab, utilizarás ventanas de tiempo fijo. Una ventana de tiempo fijo representa un intervalo de tiempo que no se superpone y de duración coherente en el flujo de datos. Considera ventanas con una duración de cinco minutos: todos los elementos de tu PCollection no delimitada con valores de marca de tiempo desde 0:00:00 hasta (sin incluir) 0:05:00 pertenecen a la primera ventana. Los elementos con valores de marca de tiempo desde 0:05:00 hasta (sin incluir) 0:10:00 pertenecen a la segunda ventana, y así sucesivamente.
Implementa un período de tiempo fijo con una duración de un segundo como se indica a continuación:
A continuación, la canalización debe calcular la cantidad de eventos que ocurrieron en cada ventana. En la canalización de BatchUserTraffic, se usaba una transformación Sum para sumar por clave. Sin embargo, a diferencia de esa canalización, en este caso los elementos tienen ventanas y el cálculo deseado debe respetar los límites de esas ventanas.
A pesar de esta nueva restricción, la transformación Combine aún es apropiada. Esto se debe a que este tipo de transformaciones respetan automáticamente los límites de las ventanas.
Consulta la documentación sobre Count para aprender a agregar una transformación nueva que cuente la cantidad de elementos por ventana.
A partir de Beam 2.22, la mejor opción para contar elementos de filas en el sistema de ventanas es usar Combine.globally(Count.<T>combineFn()).withoutDefaults() (es decir, no usar todo SQL, que analizaremos más adelante en el siguiente lab). Esta transformación dará como resultado el tipo PCollection<Long> que, como verás, ya no usa esquemas de Beam.
Para completar esta tarea, agrega una transformación que cuente todos los elementos en cada ventana. Recuerda consultar la solución si no puedes avanzar.
Tarea 4: Vuelve a convertir los elementos en filas y agrega una marca de tiempo
Para escribir en BigQuery, cada elemento debe volver a convertirse en un objeto Row con un campo llamado “pageviews” y un campo adicional llamado “minute”. La idea es usar el límite de cada ventana como un campo y la cantidad combinada de páginas vistas como el otro.
Hasta ahora, los elementos siempre se han ajustado a un esquema de Beam cuando pasan de ser una cadena JSON a ser un objeto CommonLog y, a veces, cuando se revierten a un objeto Row. Se dedujo el esquema original del POJO de CommonLog a través de la anotación @DefaultSchema(JavaFieldSchema.class) y, luego, se especificaron los campos agregados o borrados en las transformaciones de las canalizaciones. Sin embargo, en este punto de la canalización, según el resultado de la transformación Count, cada elemento es del tipo Long. Por lo tanto, se debe crear un objeto Row nuevo desde cero.
Los esquemas se pueden crear y registrar de forma manual como se describe a continuación. Este código se agregaría fuera del método main(), de manera similar a la definición del objeto CommonLog:
// Define the schema for the records.
Schema appSchema =
Schema
.builder()
.addInt32Field("appId")
.addStringField("description")
.addDateTimeField("rowtime")
.build();
Los objetos Row posteriores de este esquema se pueden crear en una PTransform en función de entradas como una Long. Este es un ejemplo:
Por lo general, Beam requerirá una indicación del esquema nuevo en la PTransform si la transformación crea una fila nueva en lugar de mutar una anterior:
Otro problema en este punto es que la transformación Count solo proporciona elementos de tipo Long que ya no llevan ningún tipo de información de marca de tiempo.
Sin embargo, esta información sí está presente, aunque no de forma tan clara. Los ejecutores de Apache Beam saben de forma predeterminada cómo proporcionar el valor para varios parámetros adicionales, incluidas las marcas de tiempo de eventos, las ventanas y las opciones de canalización. Consulta la documentación de parámetros de DoFn de Apache para obtener una lista completa.
Para completar esta tarea, escribe una función ParDo que acepte elementos de tipo Long y emita elementos de tipo Row con el tipo de esquema pageViewsSchema, que se te proporcionó anteriormente y que tiene un parámetro de entrada adicional de tipo IntervalWindow. Utiliza este parámetro adicional para crear una instancia de Instant. Luego, usa esta instancia para derivar una representación de cadena para el campo de minutos":"
@ProcessElement
public void processElement(@Element T l, OutputReceiver<T> r, IntervalWindow window) {
Instant i = Instant.ofEpochMilli(window.start().getMillis());
...
r.output(...);
}
Tarea 5: Ejecuta la canalización
Cuando completes la programación, ejecuta la canalización con el comando que aparece más abajo. Ten en cuenta que, mientras pruebas tu código, será mucho más rápido cambiar la variable de entorno RUNNER a DirectRunner, que ejecutará la canalización de manera local.
Haz clic en Revisar mi progreso para verificar el objetivo.
Agrupar el tráfico del sitio por minuto y ejecutar la canalización
Tarea 6: Verifica los resultados
Para completar esta tarea, espera unos minutos para que se ejecute la canalización y, luego, navega a BigQuery y consulta la tabla minute_traffic.
Finaliza el lab
Cuando hayas completado el lab, haz clic en Finalizar lab. Google Skills quitará los recursos que usaste y limpiará la cuenta.
Tendrás la oportunidad de calificar tu experiencia en el lab. Selecciona la cantidad de estrellas que corresponda, ingresa un comentario y haz clic en Enviar.
La cantidad de estrellas indica lo siguiente:
1 estrella = Muy insatisfecho
2 estrellas = Insatisfecho
3 estrellas = Ni satisfecho ni insatisfecho
4 estrellas = Satisfecho
5 estrellas = Muy satisfecho
Puedes cerrar el cuadro de diálogo si no deseas proporcionar comentarios.
Para enviar comentarios, sugerencias o correcciones, usa la pestaña Asistencia.
Copyright 2026 Google LLC. Todos los derechos reservados. Google y el logotipo de Google son marcas de Google LLC. El resto de los nombres de productos y empresas pueden ser marcas de las respectivas empresas a las que están asociados.
Los labs crean un proyecto de Google Cloud y recursos por un tiempo determinado
.
Los labs tienen un límite de tiempo y no tienen la función de pausa. Si finalizas el lab, deberás reiniciarlo desde el principio.
En la parte superior izquierda de la pantalla, haz clic en Comenzar lab para empezar
Usa la navegación privada
Copia el nombre de usuario y la contraseña proporcionados para el lab
Haz clic en Abrir la consola en modo privado
Accede a la consola
Accede con tus credenciales del lab. Si usas otras credenciales, se generarán errores o se incurrirá en cargos.
Acepta las condiciones y omite la página de recursos de recuperación
No hagas clic en Finalizar lab, a menos que lo hayas terminado o quieras reiniciarlo, ya que se borrará tu trabajo y se quitará el proyecto
Este contenido no está disponible en este momento
Te enviaremos una notificación por correo electrónico cuando esté disponible
¡Genial!
Nos comunicaremos contigo por correo electrónico si está disponible
Un lab a la vez
Confirma para finalizar todos los labs existentes y comenzar este
Usa la navegación privada para ejecutar el lab
Usar una ventana de incógnito o de navegación privada es la mejor forma de ejecutar
este lab. Así evitarás cualquier conflicto entre tu cuenta personal
y la cuenta de estudiante, lo que podría generar cargos adicionales en
tu cuenta personal.
En este lab, escribirás una canalización que agrupe el tráfico del sitio por usuario y otra que agrupe el tráfico del sitio por minuto.
Duración:
1 min de configuración
·
Acceso por 120 min
·
120 min para completar

 ), selecciona IAM y administración > IAM.
), selecciona IAM y administración > IAM.