
![Compute Engine のデフォルトのサービス アカウント名と編集者のステータスがハイライト表示された [権限] タブページ](https://cdn.qwiklabs.com/1nytD9OUuNUV9undyjUWeOS7LJmekReBDmkUjveCjcU%3D)
![[ターミナル] メニューでハイライト表示されている [新しいターミナル] オプション](https://cdn.qwiklabs.com/o3Hxy07QcEZ%2FwAucqGRJPFyRJWB0negMcYJph7S%2FDh4%3D)
![[VM インスタンス] ページで、リセットボタンと VM インスタンス名の両方がハイライト表示されている](https://cdn.qwiklabs.com/jDH1qGTOJ%2B1Hy2nxOPm1DPmO1JgUCjOmBvwycVWgqEk%3D)

始める前に
- ラボでは、Google Cloud プロジェクトとリソースを一定の時間利用します
- ラボには時間制限があり、一時停止機能はありません。ラボを終了した場合は、最初からやり直す必要があります。
- 画面左上の [ラボを開始] をクリックして開始します
Prepare Environment
/ 15
Run your pipeline
/ 15
Test your pipeline
/ 15

このラボの内容:
前回のラボの最後に、リアルタイム型パイプラインが直面する課題の一つを紹介しました。それはイベントが発生したタイミングと処理されたタイミングの間に生じる時間差で、ラグとも呼ばれます。このラボでは、パイプラインの作成時に、ラグへの対処方法を体系的に指定できるようにする Apache Beam のコンセプトをいくつか紹介します。
しかし、ストリーミング環境のパイプラインで発生しうる問題は、ラグだけではありません。システムの外部からの入力の場合、何かしら不正な形式である可能性が常にあります。このラボでは、そうした入力に対処するための手法についても紹介します。
このラボで作成する最終的なパイプラインは、以下の画像のようなものになります。ブランチが含まれていることに注意してください。
各ラボでは、新しい Google Cloud プロジェクトとリソースセットを一定時間無料で利用できます。
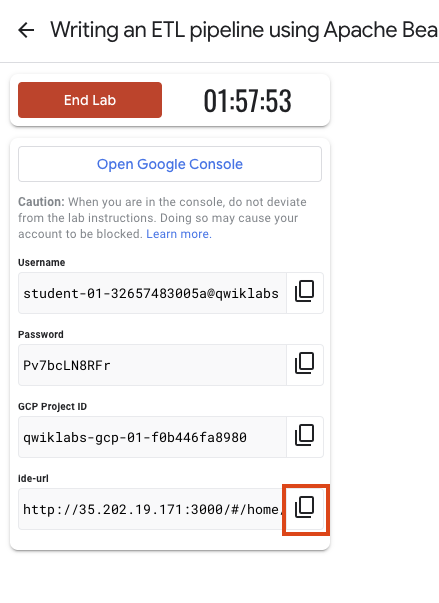
Qwiklabs にシークレット ウィンドウでログインします。
ラボのアクセス時間(例: 1:15:00)に注意し、時間内に完了できるようにしてください。
一時停止機能はありません。必要な場合はやり直せますが、最初からになります。
準備ができたら、[ラボを開始] をクリックします。
ラボの認証情報(ユーザー名とパスワード)をメモしておきます。この情報は、Google Cloud Console にログインする際に使用します。
[Google Console を開く] をクリックします。
[別のアカウントを使用] をクリックし、このラボの認証情報をコピーしてプロンプトに貼り付けます。
他の認証情報を使用すると、エラーが発生したり、料金の請求が発生したりします。
利用規約に同意し、再設定用のリソースページをスキップします。
Google Cloud で作業を開始する前に、Identity and Access Management(IAM)内で適切な権限がプロジェクトに付与されていることを確認する必要があります。
Google Cloud コンソールのナビゲーション メニュー(
Compute Engine のデフォルトのサービス アカウント {project-number}-compute@developer.gserviceaccount.com が存在し、編集者のロールが割り当てられていることを確認します。アカウントの接頭辞はプロジェクト番号で、ナビゲーション メニュー > [Cloud の概要] > [ダッシュボード] から確認できます。
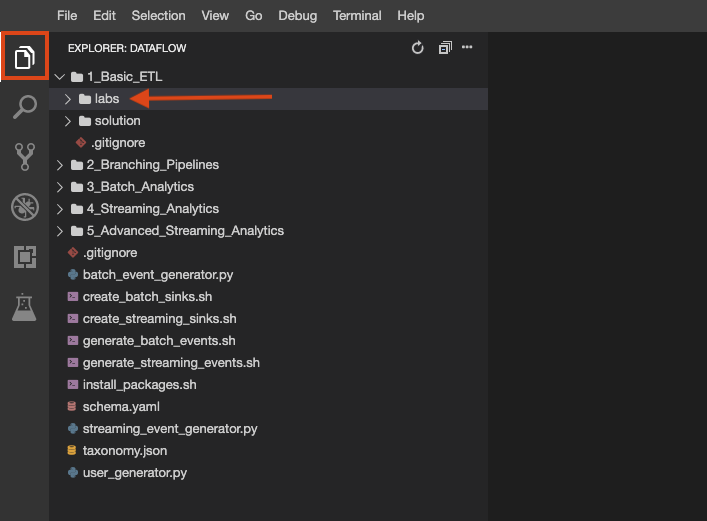
編集者のロールがない場合は、以下の手順に沿って必要なロールを割り当てます。729328892908)をコピーします。{project-number} はプロジェクト番号に置き換えてください。このラボでは、Google Compute Engine でホストされる Theia Web IDE を主に使用します。これには、事前にクローンが作成されたラボリポジトリが含まれます。Java 言語サーバーがサポートされているとともに、Cloud Shell に似た仕組みで、gcloud コマンドライン ツールを通じて Google Cloud API へのプログラムによるアクセスが可能なターミナルも使用できます。
ラボリポジトリのクローンが環境に作成されました。各ラボは、完成させるコードが格納される labs フォルダと、ヒントが必要な場合に完全に機能するサンプルを参照できる solution フォルダに分けられています。
ファイル エクスプローラ ボタンをクリックして確認します。Cloud Shell で行うように、この環境で複数のターミナルを作成することも可能です。
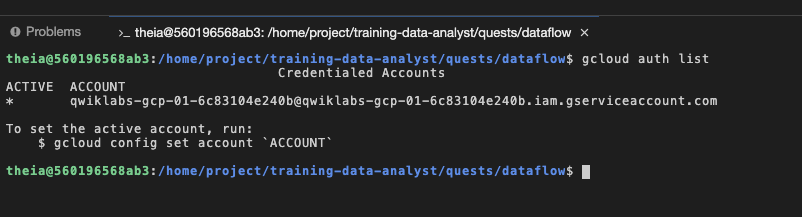
提供されたサービス アカウント(ラボのユーザー アカウントとまったく同じ権限がある)でログインしたターミナルで gcloud auth list を実行すれば、以下を確認できます。
環境が機能しなくなった場合は、IDE をホストしている VM を GCE コンソールから次のようにリセットしてみてください。
これまでのラボでは、イベント時間ごとの要素を固定幅のウィンドウに分割する場合、以下のようなコードで記述していました。
ただ、前回の非 SQL ラボの最後に見たように、データ ストリームでラグが発生するのは珍しいことではありません。ウィンドウ処理に(処理時間ではなく)イベント時間を使用する場合は、ラグが問題となります。イベント時間のある特定の時点ですべてのイベントが届いているかどうか、確実にはわからないからです。
そのため、結果を出力するには、パイプラインがこの点に関して判断を下す必要がありました。そこで使用されたのが、ウォーターマークというコンセプトです。ウォーターマークは、イベント時間のある時点までに、すべてのデータがパイプラインに届いていると見なすタイミングをシステムがヒューリスティックに基づいて判断するという考え方です。ウォーターマークがウィンドウの枠を超えたら、それ以後は、そのウィンドウ内のタイムスタンプで届いた要素は、遅延データと見なされ、単にドロップされます。デフォルトのウィンドウ処理では、システムがすべてのデータが揃ったと確信を持って判断した場合に、可能な限り完全な単一の結果が出力されます。
Apache Beam では、数多くのヒューリスティックを使用して、何をウォーターマークにするかを経験則から導き出しますが、それでもヒューリスティックであることに変わりはありません。さらに重要なのは、こうしたヒューリスティックは汎用的なものであり、すべてのユースケースに適しているわけではないということです。パイプラインの設計担当者は、汎用的なヒューリスティックを使用する代わりに、以下の質問をじっくりと検討して妥当なトレードオフを判断する必要があります。
こうした疑問への答えに基づいて、Apache Beam の形式手法に従って、妥当なトレードオフを実現するコードを記述できます。
許容遅延を使用すると、ウィンドウの状態が維持される期間を制御できます。ウォーターマークが許容遅延の期限に達すると、すべての状態がドロップされます。すべての永続状態を期限まで維持できればよいのですが、現実にはそうはいきません。無限データソースに対処する場合、特定のウィンドウの状態を無期限に維持するのは実用的ではありません。ディスク容量を使い切ってしまうからです。
そのため、実際にデータを順不同で処理するあらゆるシステムで、処理対象のウィンドウの存続期間を制限するなんらかの方法が必要になります。その簡単明瞭な方法の一つが、システム内で許容遅延の範囲を定義することです。たとえば、処理対象の特定のレコードに遅延の限度を設け(ウォーターマークを基準とする)、その限度を超えて届いたデータは単にドロップするというようにします。各データに許容遅延の限度を設定すると、ウィンドウの状態を維持するべき期間も正確に定義できます(ウィンドウの終了時間に設定された遅延範囲をウォーターマークが超過するまで)。
以前のラボと同様に、最初のステップはパイプラインで処理するデータを生成することです。ラボ環境を開いて、以前と同じようにデータを生成します。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
7_Advanced_Streaming_Analytics/labs/src/main/java/com/mypackage/pipeline にある StreamingMinuteTrafficPipeline.java を開きます。Apache Beam では、以下の例のように withAllowedLateness() メソッドを使用して許容遅延を設定します。
.withAllowedLateness() の呼び出しを追加し、適切なコマンドライン パラメータから構築した有効な Duration に渡します。妥当な値を決め、適切な単位が反映されるようコマンドラインを更新します。パイプラインの設計者は、暫定的な結果を出力するタイミングを自ら決定することもできます。たとえば、ウィンドウの終了時間に設定されたウォーターマークには達していないものの、想定データの 75% がすでに到着している場合を考えてみましょう。多くの場合、このようなサンプルは典型的な例として、エンドユーザーに紹介する価値が十分にあります。
Trigger は、処理時間中のどの時点で具体的な結果が出力されるかを決定するものです。ウィンドウの各出力は、ウィンドウのペインと呼ばれます。トリガーの条件が満たされると、トリガーによりペインが出力されます。Apache Beam では、トリガーの条件として、ウォーターマークの進行状況、処理時間の進行状況(どのくらいのデータが実際に届いたかにかかわらず均一に進行)、要素数のカウント(一定量のデータが新規に届いたときなど)、データ依存トリガー(ファイルの末尾に達したときなど)といったものがあります。
トリガーの条件によっては、特定のペインが何度も発生する可能性があります。そのため、出力結果を累積する方法も指定する必要があります。Apache Beam は現在、2 つの累積モードをサポートしています。一つは結果を全部まとめて累積するモードで、もう一つはペインが最後に発生してから新たに結果に含まれた部分のみを返すモードです。
Window 変換を使用して PCollection のウィンドウ関数を設定するときに、トリガーも指定できます。
次のようにメソッド「.triggering()」を Window.into() 変換の結果に対して呼び出すことで、PCollection のトリガーを設定します。Window.triggering() はトリガーを引数として受け取ります。Apache Beam では、以下のようにいくつものトリガーが用意されています。
以下のコードサンプルでは PCollection に時間ベースのトリガーを設定しています。このトリガーは、ウィンドウ内で最初の要素が処理されて 1 分後に結果を出力します。コードサンプルの最終行にある .discardingFiredPanes() は、ウィンドウの蓄積モードを設定します。
Window.triggering() の呼び出しを追加し、有効な Trigger を渡します。トリガーを設計する際には、このユースケースを念頭に、データが 1 分間のウィンドウ内で処理されることと、データが遅れて届くこともあるという点に留意してください。トリガーの例が必要な方は、こちらのソリューションをご覧ください。
Trigger の設定方法によっては、今回のパイプラインをすぐに実行して以前のラボから取得したパイプラインと比較した際に、新しいパイプラインの方が結果表示が早いと思われるかもしれません。また、ヒューリスティックがストリーミング動作をうまく予想できず、許容遅延の設定がより適切であれば、今回のパイプラインから得た結果の方が正確な場合もあります。
ただ、今回のパイプラインは遅延に対する堅牢性が高まりましたが、不正な形式のデータに対しては依然として脆弱です。今回のパイプラインを実行してパブリッシュしたメッセージに CommonLog に解析できる適切な JSON 形式以外の文字列が含まれていた場合は、パイプラインでエラーが発生します。こうしたエラーは、Cloud Logging のようなツールを使用すると簡単に確認できますが、事前に定義した場所に保存して後で調べられるようにパイプラインをうまく設計することもできます。
このセクションでは、モジュール性と堅牢性の両方を高めるコンポーネントをパイプラインに追加します。
不正な形式のデータに対する堅牢性を高めるには、パイプラインがこの種のデータをフィルタリングして、違う方法で処理できるようブランチを組み込む方法が必要です。パイプラインにブランチを組み込む方法の一つは、すでにご紹介しています。それは、多重変換用の入力である PCollection を 1 つ作成することです。
この形式のブランチは高性能ですが、ユースケースによっては処理が非効率になることもあります。たとえば、同じ PCollection に対して 2 種類のサブセットを作成したいとします。複数変換の方法では、サブセットごとにフィルタ変換を 1 つ作成して、その両方を元の PCollection に適用します。しかし、これでは各要素を 2 回処理することになります。
パイプラインにブランチを生成するには、入力の PCollection を 1 回処理する間に単一の変換で複数の出力を生成するという別の方法もあります。このタスクでは、複数の出力を生成する変換を作成します。最初の出力は適切な形式のデータから得た結果であり、もう一つの出力は元の入力ストリームから得た不正な形式の要素です。
PCollection を 1 つだけ作成しながら複数の結果を出力するために、Apache Beam は PCollectionTuple と呼ばれるクラスを使用します。PCollectionTuple は、異なる型を含む PCollection の不変タプルであり、TupleTag を「キー」とします。
2 種類の PCollection を使用して PCollectionTuple をインスタンス化する例を以下に示します。その後、これらの PCollection は PCollectionTuple.get() メソッドを使用して取得されます。
PTransform のコンテキストでこのメソッドを使用するには、以下の例にあるようなコードを記述します。この例では、要素の内容に基づいて TupleTag を要素に割り当てています。
TupleTag 定数をクラスの冒頭で宣言します。そして、PCollectionTuple を返し、未解析の要素に片方のタグを付与して解析済みの要素にもう片方のタグを付与するように、JsonToCommonLog 変換を変更します。if / then / else ブロックの代わりに、try / catch ステートメントを使用します。変換はネスト構造にして、1 つの複雑な変換で複数のシンプルな変換を実行することができます(1 つ以上の ParDo や Combine、GroupByKey、その他の複合変換など)。これらの変換は複合変換と呼ばれます。1 つの複合変換内で複数の変換をネストすると、コードのモジュール性を高めて、わかりやすくできます。
PTransform クラスのサブクラスを作成し、実際の処理ロジックを指定するために expand() メソッドをオーバーライドします。PTransform クラスの型パラメータについては、変換が入力として受け取り、出力として生成する PCollection 型を渡します。次のコードサンプルは、文字列の PCollection を入力として受け付け、整数型の PCollection を出力する PTransform の宣言方法を示したものです。
#TODO: JsonToRow
PTransform サブクラス内では、expand() メソッドをオーバーライドする必要があります。expand() メソッドでは、PTransform の処理ロジックを追加します。expand() メソッドのオーバーライドでは、適切なタイプの入力「PCollection」をパラメータとして受け付け、出力「PCollection」を戻り値として指定する必要があります。PCollection に対して PCollection.apply() を使用し、複合変換のインスタンスを渡します。JsonToCommonLog 変換を複合変換に変えます。この処理によって、CommonLog のインスタンスを想定している現在の書き込み変換に問題が発生します。複合変換の結果を新規の PCollectionTuple に保存してから、.get() を使用して書き込み変換が想定している PCollection を取得します。不正な形式のデータを生成しているアップストリームの問題を解決するためには、不正な形式のデータを分析できることが重要です。そのためには、どこかにその具体的なデータを出力する必要があります。このタスクでは、Google Cloud Storage に不正な形式のデータを書き込みます。このような方法を、デッドレター ストレージの使用と呼びます。
これまでのラボでは、TextIO.write() を使用して制限付きソース(バッチ)を Cloud Storage に直接書き込んできましたが、制限なしソース(ストリーミング)からの書き込みでは、この手法に少し手を加える必要があります。
まずは、書き込み変換のアップストリームです。Trigger を使用して、処理時間のどのタイミングで書き込むかを指定する必要があります。これを指定せずにデフォルトのままにしておくと、書き込みは行われません。デフォルトでは、すべてのイベントがグローバル ウィンドウに属しています。この場合、データセット全体の内容を実行時に把握できるため、一括して操作するときはデフォルトのままでかまいません。一方、制限なしソースの場合、データセット全体のサイズが不明であるため、グローバル ウィンドウのペインが発生することはなく、したがって完了することもありません。
Trigge を使用しているため、Window も使用する必要があります。ただし、必ずしもウィンドウの変更が必要になるとは限りません。これまでのラボとタスクでは、ウィンドウ処理変換を使用して、グローバル ウィンドウをイベント時間で期間が固定されたウィンドウに置き換えてきました。この場合、どの要素をグループ化するかよりも、結果が有用な形かつ実用的な速度で出力されることの方が重要です。
以下の例では、ウィンドウは処理時間 10 秒ごとにグローバル ウィンドウのペインを出力しますが、新規イベントのみを書き込みます。
Trigger を設定したら、書き込みを実行するように TextIO.write() の呼び出しを変更します。ウィンドウ処理変換のダウンストリームに書き込む際は、withWindowedWrites() の呼び出しをチェーンして、書き込みが並列処理されるように複数のシャードを指定します。
PCollectionTuple に対して .get() を使用して新規の変換を作成し、不正な形式のデータを取得します。トリガーに関する知識と判断力を働かせて、このトリガーに対して適切な起動条件を設定しましょう。このクエストのコードには、JSON イベントを Pub/Sub でパブリッシュするためのスクリプトが含まれています。
training-data-analyst/quests/dataflow フォルダが作業ディレクトリになっていることを確認します。true フラグはストリームに遅延イベントを追加します。[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
Google Cloud コンソールのタイトルバーにある [検索] フィールドに「Pub/Sub」と入力し、[プロダクトとページ] セクションの [Pub/Sub] をクリックします。
[トピック] をクリックし、トピック「my_topic」をクリックします。
[メッセージ] タブ > [メッセージをパブリッシュ] ボタンの順にクリックします。
後続のページで、パブリッシュするメッセージを入力します。
CommonLog JSON 仕様に対して完璧に適合しない限り、メッセージは短時間のうちにデッドレター Cloud Storage バケットに到着します。パイプラインのモニタリング ウィンドウに戻り、未解析メッセージの処理を行っているブランチ内のノードをクリックすることで、パイプラインを通るパスをトレースできます。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
ラボが完了したら、[ラボを終了] をクリックします。ラボで使用したリソースが Google Cloud Skills Boost から削除され、アカウントの情報も消去されます。
ラボの評価を求めるダイアログが表示されたら、星の数を選択してコメントを入力し、[送信] をクリックします。
星の数は、それぞれ次の評価を表します。
フィードバックを送信しない場合は、ダイアログ ボックスを閉じてください。
フィードバックやご提案の送信、修正が必要な箇所をご報告いただく際は、[サポート] タブをご利用ください。
Copyright 2026 Google LLC All rights reserved. Google および Google のロゴは、Google LLC の商標です。その他すべての社名および製品名は、それぞれ該当する企業の商標である可能性があります。



このコンテンツは現在ご利用いただけません
利用可能になりましたら、メールでお知らせいたします

ありがとうございます。
利用可能になりましたら、メールでご連絡いたします

1 回に 1 つのラボ
既存のラボをすべて終了して、このラボを開始することを確認してください