




始める前に
- ラボでは、Google Cloud プロジェクトとリソースを一定の時間利用します
- ラボには時間制限があり、一時停止機能はありません。ラボを終了した場合は、最初からやり直す必要があります。
- 画面左上の [ラボを開始] をクリックして開始します
Create a Cloud Storage Bucket
/ 50
Create a dataset
/ 50
Create a Cloud Storage Bucket
/ 50
Create a dataset
/ 50
Vertex AI AutoML を使用すると、ML の専門知識が限られている開発者でも、高品質な画像認識モデルをトレーニングできます。AutoML UI に画像をアップロードすると、Google Cloud ですぐに利用できるモデルをトレーニングして、使いやすい REST API を介して予測を生成することが可能です。
このラボでは、Cloud Storage に画像をアップロードして、さまざまな種類の雲(積雲、積乱雲など)を見分けられるようにカスタムモデルをトレーニングします。
このラボでは、次のことを行います。
こちらの手順をお読みください。ラボの時間は記録されており、一時停止することはできません。[ラボを開始] をクリックするとスタートするタイマーは、Google Cloud のリソースを利用できる時間を示しています。
このハンズオンラボでは、シミュレーションやデモ環境ではなく、実際のクラウド環境を使ってご自身でラボのアクティビティを行うことができます。そのため、ラボの受講中に Google Cloud にログインおよびアクセスするための、新しい一時的な認証情報が提供されます。
このラボを完了するためには、下記が必要です。
これは、このラボの間だけ有効な一時的なアカウントです。以下の点に注意してください。
 )をクリックしてサービスのリストを確認します。
)をクリックしてサービスのリストを確認します。Cloud Shell は、開発ツールが組み込まれた仮想マシンです。5 GB の永続ホーム ディレクトリを提供し、Google Cloud 上で実行されます。Cloud Shell を使用すると、コマンドラインで Google Cloud リソースにアクセスできます。gcloud は Google Cloud のコマンドライン ツールで、Cloud Shell にプリインストールされており、Tab キーによる入力補完がサポートされています。
Google Cloud Console のナビゲーション パネルで、「Cloud Shell をアクティブにする」アイコン(
[次へ] をクリックします。
環境がプロビジョニングされ、接続されるまでしばらく待ちます。接続の際に認証も行われ、プロジェクトは現在のプロジェクト ID に設定されます。次に例を示します。
有効なアカウント名前を一覧表示する:
(出力)
(出力例)
プロジェクト ID を一覧表示する:
(出力)
(出力例)
[進行状況を確認] をクリックして、目標に沿って進行していることを確認します。
雲の画像を分類するようにモデルをトレーニングするには、さまざまな種類の雲に関連付けられた画像の特徴をモデルが理解できるように、ラベル付けしたトレーニング データを用意する必要があります。この例のモデルは、3 種類の雲(巻雲、積雲、積乱雲)を分類できるように学習します。 AutoML を使用するには、トレーニング画像を Cloud Storage に保存する必要があります。
Cloud Shell で次のコマンドを実行します。
トレーニング画像は Cloud Storage バケットで一般公開されています。
各フォルダ内の個々の画像ファイルをクリックすると、雲の種類ごとにモデルをトレーニングするための写真を表示できます。
トレーニング データは Cloud Storage に格納されました。次は AutoML からそのデータにアクセスする方法が必要となります。そこで、トレーニング画像の URL と、その画像に対応するラベルが各行に含まれる CSV ファイルを作成します。 この CSV ファイルはすでに用意してありますので、先ほどのバケット名を使用して更新してください。
コマンドが完了したら、Storage ブラウザの上部にある [更新] ボタンをクリックします。バケットに data.csv ファイルが表示されることを確認します。
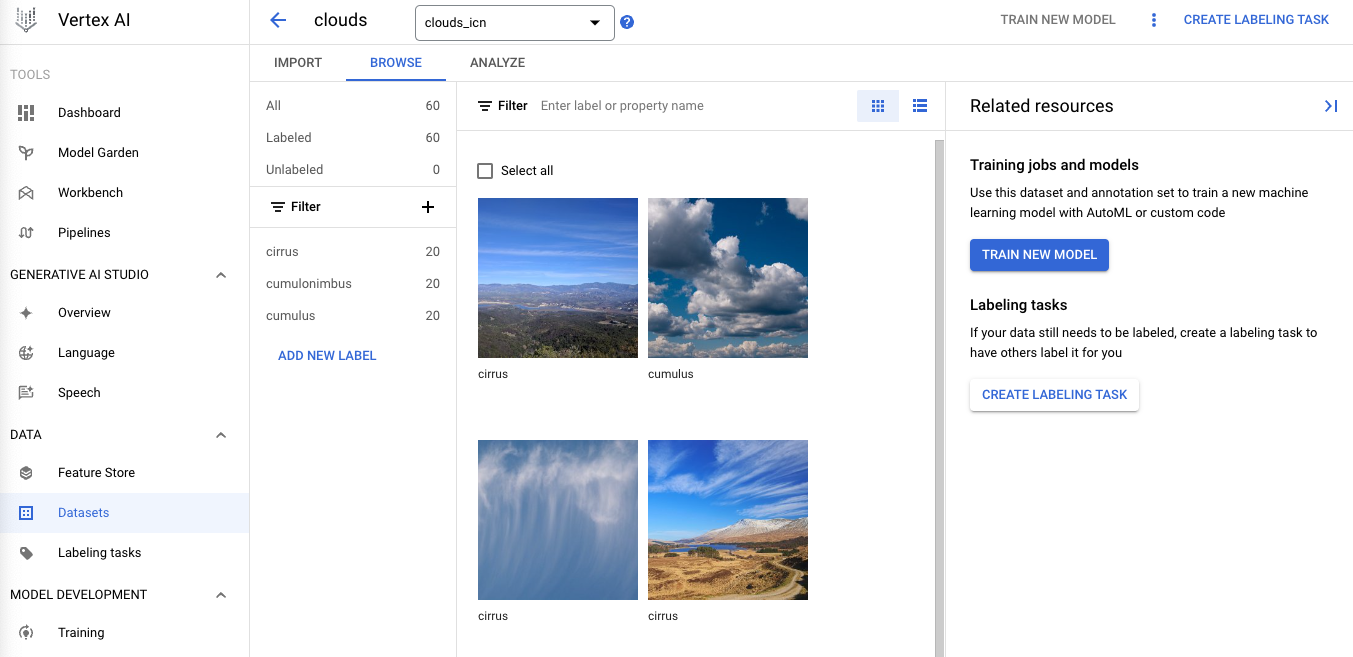
Vertex AI データセット タブを開きます。ページは以下のようになります。
コンソールの上部で、[+ 作成] をクリックします。
[データセット名] に「clouds」と入力します。
[画像分類(単一ラベル)] を選択します。
[作成] をクリックします。
[インポート ファイルを Cloud Storage から選択] を選択し、先ほどアップロードしたファイルの URL にファイル名を追加します(your-bucket-name/data.csv)。
Google Cloud コンソールに戻って data.csv ファイルをクリックし、URI フィールドに移動するとこのリンクを簡単に取得できます。
画像のインポートには、2~5 分ほどかかります。インポートが完了すると、データセット内のすべての画像を含むページが表示されます。
[進行状況を確認] をクリックして、目標に沿って進行していることを確認します。
インポートが完了すると、アップロードした画像を確認するための [参照] タブにリダイレクトされます。
左側のメニューからさまざまなラベルでフィルタして(積雲をクリックするなど)、トレーニング画像を確認してみてください。
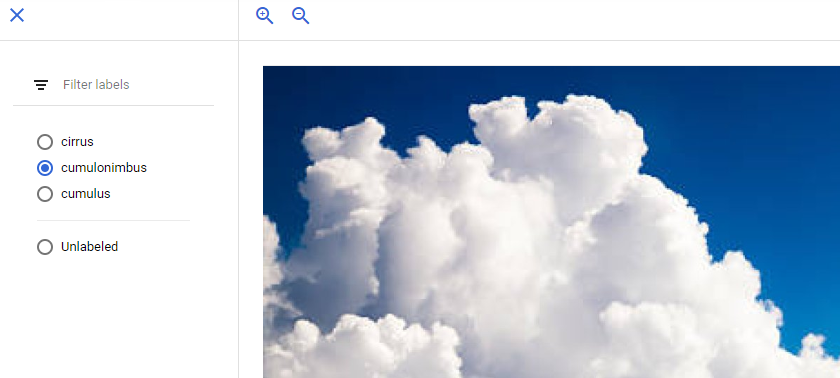
ラベルが間違っている画像があった場合は、画像をクリックしてラベルを切り替えてください。
モデルのトレーニングを開始する準備が整いました。AutoML ではモデルのトレーニングが自動的に行われるため、モデルコードを記述する必要はありません。
モデルをトレーニングするには、[新しいモデルをトレーニング] をクリックします。
[トレーニング方法] タブで、[続行] をクリックします。
[モデルの詳細] タブで、[続行] をクリックします。
[トレーニング オプション] タブで、[続行] をクリックします。
[説明可能性] タブで、[続行] をクリックします。
[コンピューティングと料金] タブで、ノード時間を 8 に設定します。
予測を生成する方法はいくつかあります。 このラボでは、UI を使用して画像をアップロードします。 このモデルが 2 つの画像をどのように分類するかを確認できます(1 つ目の画像は巻雲、2 つ目の画像は積乱雲です)。
Cloud Shell デバイスに戻ります。
これらの画像をローカルマシンにダウンロードします。
予想される出力:
このラボで扱うトピックに関する短いクイズに答えて、AutoML の理解度をテストしてください。
ラボで得た知識を使って、予測を立てます。
このモデルが画像中の雲の種類を予測できるかどうかを確認してください。
CLOUD1-JSON を入力ファイルとして設定します。このモデルが画像中の雲の種類を予測できるかどうか確認しましょう。
CLOUD2-JSON を入力ファイルとして設定します。ウェブ UI を介して、独自のカスタム機械学習モデルをトレーニングし、そのモデルを使って予測を生成する方法を学びました。これで、独自の画像データセットでモデルをトレーニングするために必要な知識をすべて習得できました。
ラボでの学習が完了したら、[ラボを終了] をクリックします。ラボで使用したリソースが Qwiklabs から削除され、アカウントの情報も消去されます。
ラボの評価を求めるダイアログが表示されたら、星の数を選択してコメントを入力し、[送信] をクリックします。
星の数は、それぞれ次の評価を表します。
フィードバックを送信しない場合は、ダイアログ ボックスを閉じてください。
フィードバック、ご提案、修正が必要な箇所については、[サポート] タブからお知らせください。



このコンテンツは現在ご利用いただけません
利用可能になりましたら、メールでお知らせいたします

ありがとうございます。
利用可能になりましたら、メールでご連絡いたします

1 回に 1 つのラボ
既存のラボをすべて終了して、このラボを開始することを確認してください
ラボを開始するには、この簡単な手順を完了してください。