

![Cloud Shell の [エディタを開く] ボタン](https://cdn.qwiklabs.com/hZYBOz6ymTpCcrjxYiyPK2gVdwvdXxHVm77O5rBeFfs%3D)

始める前に
- ラボでは、Google Cloud プロジェクトとリソースを一定の時間利用します
- ラボには時間制限があり、一時停止機能はありません。ラボを終了した場合は、最初からやり直す必要があります。
- 画面左上の [ラボを開始] をクリックして開始します

Cloud Natural Language API を使用すると、テキストからエンティティを抽出して感情分析や構文解析を行い、分析したテキストをカテゴリに分類できます。このラボでは、テキスト分類を中心に演習を行います。700 以上のカテゴリが登録されたデータベースを使用するこの API 機能により、大規模なテキスト データセットの分類が容易になります。
各ラボでは、新しい Google Cloud プロジェクトとリソースセットを一定時間無料で利用できます。
Qwiklabs にシークレット ウィンドウでログインします。
ラボのアクセス時間(例: 1:15:00)に注意し、時間内に完了できるようにしてください。
一時停止機能はありません。必要な場合はやり直せますが、最初からになります。
準備ができたら、[ラボを開始] をクリックします。
ラボの認証情報(ユーザー名とパスワード)をメモしておきます。この情報は、Google Cloud Console にログインする際に使用します。
[Google Console を開く] をクリックします。
[別のアカウントを使用] をクリックし、このラボの認証情報をコピーしてプロンプトに貼り付けます。
他の認証情報を使用すると、エラーが発生したり、料金の請求が発生したりします。
利用規約に同意し、再設定用のリソースページをスキップします。
Google Cloud Shell は、開発ツールと一緒に読み込まれる仮想マシンです。5 GB の永続ホーム ディレクトリが用意されており、Google Cloud で稼働します。
Google Cloud Shell を使用すると、コマンドラインで Google Cloud リソースにアクセスできます。
Google Cloud コンソールで、右上のツールバーにある [Cloud Shell をアクティブにする] ボタンをクリックします。
[続行] をクリックします。
環境がプロビジョニングされ、接続されるまでしばらく待ちます。接続した時点で認証が完了しており、プロジェクトに各自のプロジェクト ID が設定されます。次に例を示します。
gcloud は Google Cloud のコマンドライン ツールです。このツールは、Cloud Shell にプリインストールされており、タブ補完がサポートされています。
出力:
出力例:
出力:
出力例:
画面左上のナビゲーション メニュー アイコン(
[API とサービス] > [有効な API とサービス] を選択します。
[+ API とサービスの有効化] をクリックします。
次に、検索ボックスで「language」を検索します。[Cloud Natural Language API] をクリックします。
API が有効になっていない場合は、[有効にする] ボタンが表示されます。[有効にする] をクリックして、Cloud Natural Language API を有効にします。
API が有効になっている場合は、[Cloud Natural Language API] タイルに [管理] ボタンが表示されます。
curl を使用して Natural Language API にリクエストを送信するため、リクエスト URL に渡す API キーを生成する必要があります。
API キーを作成するには、コンソールのナビゲーション メニューをクリックし、[API とサービス] > [認証情報] をクリックします。
[+ 認証情報を作成] をクリックします。
プルダウン メニューで [API キー] を選択します。
生成された API キーをコピーし、[閉じる] をクリックします。
API キーが準備できたので、リクエストごとに API キーの値を挿入しなくて済むようにするために、環境変数にキーを保存します。
<your_api_key> の部分は、コピーしたキーに置き換えてください。Natural Language API の classifyText メソッドを使用すると、1 つの API 呼び出しでテキストデータをカテゴリに分類できます。このメソッドは、テキスト ドキュメントに適用されるコンテンツ カテゴリのリストを返します。返されるカテゴリの具体性には幅があり、/Computers & Electronics のように大まかなカテゴリもあれば、/Computers & Electronics/Programming/Java (Programming Language) のように非常に具体的なカテゴリもあります。700 以上あるカテゴリ候補の全リストはコンテンツ カテゴリ ガイドでご確認ください。
ここでは、最初に 1 つの記事を分類し、同じ手法で大規模なニュース コーパスを整理していく方法について説明します。取り上げるのは、The New York Times の料理セクションの記事にあった、次の見出しと説明です。
A Smoky Lobster Salad With a Tapa Twist. This spin on the Spanish pulpo a la gallega skips the octopus, but keeps the sea salt, olive oil, pimentón and boiled potatoes.(タパスをアレンジしたスモーキー ロブスター サラダ。スペイン料理、プルポ・ア・ラ・ガジェガ(ガリシア風タコ)をヒントにしたこの一品には、タコは使いませんが、岩塩、オリーブオイル、ピメントン、ゆでジャガイモを使います。)
request.json ファイルを作成します。Cloud Shell コードエディタ以外のコマンドライン エディタ(nano、vim、emacs)を使用してもかまいません。request.json という名前の新しいファイルを作成し、以下を追加します。curl コマンドを使って Natural Language API の classifyText メソッドに送信します。レスポンスを確認します。
出力:
このテキストに対し、次の 2 つのカテゴリが API から返されます。
/Food & Drink/Cooking & Recipes/Food & Drink/Food/Meat & Seafoodテキストには、これがレシピであることもシーフードが含まれることもはっきりとは書かれていませんが、この API を使えば分類することができます。1 つの記事を分類することでもこの機能の優れた点がわかりますが、本当の利点は、次のように大規模なテキストデータを扱うことで見えてきます。
BBC のニュース記事を集めたこちらの一般公開データセットを使って、classifyText メソッドで大量のテキストを含むデータセットをわかりやすく整理していきましょう。このデータセットには、2004 年から 2005 年までの間に書かれた 5 つの分野(ビジネス、エンターテインメント、政治、スポーツ、テクノロジー)の記事が 2,225 件含まれています。一般公開されている Google Cloud Storage バケットの中には、これらの記事のサブセットがあります。記事は 1 件ずつ 1 つの .txt ファイルになっています。
データを調べて Natural Language API に送信するために、Cloud Storage から各テキスト ファイルを読み取り、classifyText エンドポイントに送信し、その結果を BigQuery テーブルに保存する Python スクリプトを作成します。BigQuery は、大規模なデータセットの保存や分析を容易にする Google Cloud のビッグデータ ウェアハウス ツールです。
作業するテキストの種類を確認するため、次のコマンドを実行して 1 つの記事を表示してみます。
次に、データを保存する BigQuery テーブルを作成します。
Natural Language API にテキストを送信する前に、各記事のテキストとカテゴリの保存場所を用意する必要があります。
Google Cloud コンソールでナビゲーション メニュー(
BigQuery の起動画面が表示されたら、[完了] をクリックします。
左側のパネルでプロジェクト名の横にある [アクションを表示] アイコン(![[アクションを表示] アイコン](https://cdn.qwiklabs.com/2ufrDePg5inKfodUoT2Kib4oE7II7emYn%2BypCC85FjQ%3D)
[データセット ID] に「news_classification_dataset」と入力します。
[データセットを作成] をクリックします。
データセット名の横にあるアクションを表示アイコンをクリックし、[テーブルを作成] をクリックします。以下の設定で新しいテーブルを作成します。
現在、テーブルは空の状態です。次のステップで、Cloud Storage から記事を読み取り、それを Natural Language API に送信して分類し、結果を BigQuery に保存していきます。
ニュースデータを Natural Language API に送信するスクリプトを作成する前に、サービス アカウントを作成する必要があります。このアカウントは、Python スクリプトから Natural Language API と BigQuery に対して認証を行う際に使用されます。
<your_project_name> は、ラボの [ラボの詳細] パネルに表示される GCP プロジェクト ID に置き換えてください。これで、Natural Language API にテキストデータを送信する準備が整いました。
データを送信するために、Google Cloud 用の Python モジュールを使用して Python スクリプトを作成します。さまざまなクラウド クライアント ライブラリが多数存在し、どの言語からでも同じことができます。
classify-text.py という名前のファイルを作成し、ファイルの中に以下をコピーします。YOUR-PROJECT は GCP プロジェクト ID に置き換えてください。これで、記事を分類して BigQuery にインポートする準備が整いました。
スクリプトが完了するまで 2 分ほどかかりますので、その間に処理内容について説明します。
python3 classify-text.py の実行時にエラーが発生した場合、Cloud Shell が切断される可能性があります。この問題を解決するために、次のコマンドを実行して環境変数をエクスポートし、python3 classify-text.py コマンドを再実行してください。
export PROJECT=(GCP プロジェクト ID)export GOOGLE_APPLICATION_CREDENTIALS=key.jsonGoogle では、google-cloud という Python クライアント ライブラリを使用して、Cloud Storage、Natural Language API、BigQuery にアクセスしています。まず、サービスごとにクライアントが作成され、BigQuery テーブルに参照が作成されます。一般公開されているバケットに含まれる各 BBC データセット ファイルへの参照は、files です。これらのファイルを順番に処理し、記事を文字列としてダウンロードし、それぞれを classify_text 関数の Natural Language API に送信します。Natural Language API からカテゴリが返されたすべての記事について、記事とそのカテゴリデータが rows_for_bq リストに保存されます。各記事の分類が完了すると、insert_rows() によって BigQuery にデータが挿入されます。
スクリプトの実行が完了したら、記事データが BigQuery に保存されたことを確認します。
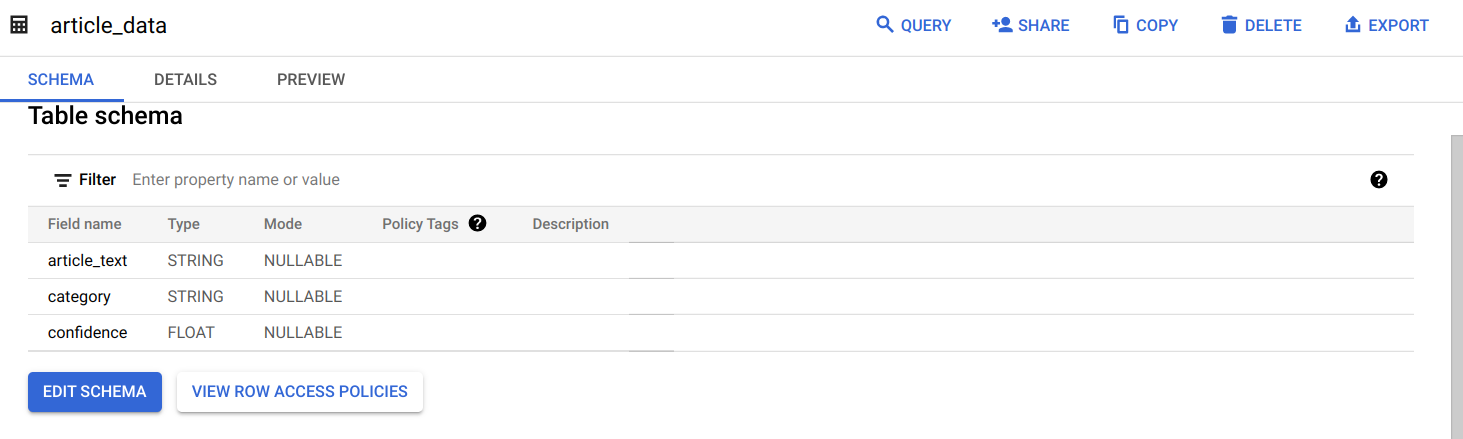
article_data テーブルに移動して、[クエリ] > [新しいタブ] をクリックします。クエリが完了すると、データが表示されます。右にスクロールして、カテゴリ列を表示します。
カテゴリ列には、Natural Language API から記事に対して返された最初のカテゴリの名前が含まれ、confidence には、API による記事の分類の信頼性を示す 0〜1 の値が含まれています。次のステップでは、データに対してより複雑なクエリを実行する方法について説明します。
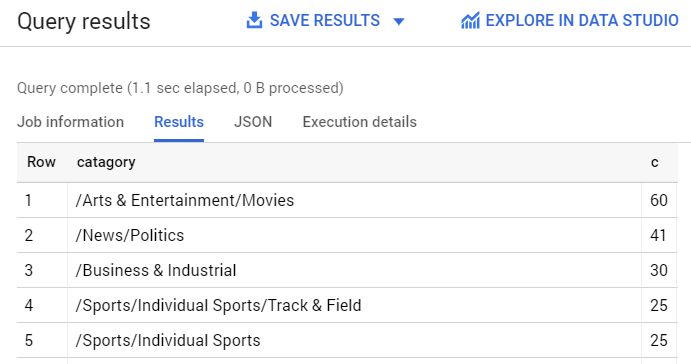
まず、データセットで最も多かったカテゴリを確認します。
BigQuery コンソールで、[+ クエリを新規作成] をクリックします。
次のクエリを入力します。
クエリの結果として、次のような内容が表示されます。
/Arts & Entertainment/Music & Audio/Classical Music のように大まかなカテゴリの記事が返されるようにする場合は、次のクエリを実行します。その他のクエリ方法について詳しくは、BigQuery のドキュメントをご確認ください。BigQuery は多数の可視化ツールとも統合されています。分類したニュースデータを可視化したい場合は、BigQuery のデータポータル クイックスタートをご参照ください。
このラボでは、Natural Language API のテキスト分類メソッドを使ってニュース記事を分類する方法を学習しました。最初に 1 つの記事を分類する方法を学び、その後、大規模なニュース データセットを NL API で分類して BigQuery で分析する方法を学びました。
classifyText リクエストの作成と curl を使用した API の呼び出しCopyright 2026 Google LLC All rights reserved. Google および Google のロゴは、Google LLC の商標です。その他すべての社名および製品名は、それぞれ該当する企業の商標である可能性があります。



このコンテンツは現在ご利用いただけません
利用可能になりましたら、メールでお知らせいたします

ありがとうございます。
利用可能になりましたら、メールでご連絡いたします

1 回に 1 つのラボ
既存のラボをすべて終了して、このラボを開始することを確認してください