![Compute Engine のデフォルトのサービス アカウント名と編集者のステータスがハイライト表示された [権限] タブページ](https://cdn.qwiklabs.com/1nytD9OUuNUV9undyjUWeOS7LJmekReBDmkUjveCjcU%3D)



始める前に
- ラボでは、Google Cloud プロジェクトとリソースを一定の時間利用します
- ラボには時間制限があり、一時停止機能はありません。ラボを終了した場合は、最初からやり直す必要があります。
- 画面左上の [ラボを開始] をクリックして開始します
Download a code repository
/ 5
Create a BigQuery Dataset
/ 5
Simulate traffic sensor data into Pub/Sub
/ 5
Launch Dataflow Pipeline
/ 5
Create an alert
/ 5
Download a code repository
/ 5
Create a BigQuery Dataset
/ 5
Simulate traffic sensor data into Pub/Sub
/ 5
Launch Dataflow Pipeline
/ 5
Create an alert
/ 5
このラボでは、Pub/Sub 経由で取り込み可能なトラフィック センサーのシミュレーション データから、Dataflow を使用してトラフィック イベントを収集し、実際に利用できる平均値を生成します。また、後で分析するために元データを BigQuery に保存します。この過程で、Dataflow パイプラインを起動、モニタリング、最適化する方法について学習します。
このラボでは、次のタスクを行います。
各ラボでは、新しい Google Cloud プロジェクトとリソースセットを一定時間無料で利用できます。
Qwiklabs にシークレット ウィンドウでログインします。
ラボのアクセス時間(例: 1:15:00)に注意し、時間内に完了できるようにしてください。
一時停止機能はありません。必要な場合はやり直せますが、最初からになります。
準備ができたら、[ラボを開始] をクリックします。
ラボの認証情報(ユーザー名とパスワード)をメモしておきます。この情報は、Google Cloud Console にログインする際に使用します。
[Google Console を開く] をクリックします。
[別のアカウントを使用] をクリックし、このラボの認証情報をコピーしてプロンプトに貼り付けます。
他の認証情報を使用すると、エラーが発生したり、料金の請求が発生したりします。
利用規約に同意し、再設定用のリソースページをスキップします。
Google Cloud で作業を開始する前に、Identity and Access Management(IAM)内で適切な権限がプロジェクトに付与されていることを確認する必要があります。
Google Cloud コンソールのナビゲーション メニュー(
Compute Engine のデフォルトのサービス アカウント {project-number}-compute@developer.gserviceaccount.com が存在し、編集者のロールが割り当てられていることを確認します。アカウントの接頭辞はプロジェクト番号で、ナビゲーション メニュー > [Cloud の概要] > [ダッシュボード] から確認できます。
編集者のロールがない場合は、以下の手順に沿って必要なロールを割り当てます。729328892908)をコピーします。{project-number} はプロジェクト番号に置き換えてください。トレーニング用 VM からセンサー シミュレータを実行します。ラボ 1 では、Pub/Sub コンポーネントを手動でセットアップしました。このラボでは、それらのプロセスの一部が自動化されています。
Cloud コンソールのナビゲーション メニュー(
training-vm という名前のインスタンスがある行を確認します。
右端の [接続] の下にある [SSH] をクリックしてターミナル ウィンドウを開きます。
このラボでは、training-vm 上で CLI コマンドを入力します。
training-vm によってバックグラウンドでソフトウェアのインストールが行われます。
list(ls)コマンドの出力結果が次の画像のように表示された場合、設定は完了しています。完全なリストが表示されない場合は、数分待ってからもう一度実行してください。
このスクリプトにより、DEVSHELL_PROJECT_ID 環境変数と BUCKET 環境変数が設定されます。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
後で作成される Dataflow パイプラインによって、BigQuery データセットのテーブルに書き込みが行われます。
[Cloud Console の BigQuery へようこそ] メッセージ ボックスが開きます。このメッセージ ボックスにはクイックスタート ガイドへのリンクと、UI の更新情報が表示されます。
データセットを作成するには、プロジェクト ID の横にある「アクションを表示」アイコンをクリックし、[データセットを作成] を選択します。
次に、[データセット ID] を「demos」にします。他のオプションはすべてデフォルト値のままにして [データセットを作成] をクリックします。
プロジェクト ID と同じ名前のバケットがすでに存在します。
Cloud コンソールのナビゲーション メニュー(
次の値を確認します。
|
プロパティ |
値 (値を入力、または指定されたオプションを選択) |
|
名前 |
|
|
Default storage class |
Regional |
|
場所 |
|
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
このコマンドを実行すると、1 時間分のデータが 1 分で送信されます。現在のターミナルでスクリプトの実行を継続します。
training-vm の SSH ターミナルの右上にある歯車アイコン(
新しいターミナル セッションには、必要な環境変数が設定されていません。そこで、次のコマンドを実行して環境変数を設定します。
training-vm の新しい SSH ターミナルで次のように入力します。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
4 つ目の options はオプションの引数です。options 引数については、このラボで後述します。
|
project id |
|
|
bucket name |
|
|
classname |
|
|
options |
|
classname は、4 つの Java ファイルから選択できます。それぞれが Pub/Sub からトラフィック データを読み取り、異なる集計と計算を実行します。
このスクリプトは何を実行するのでしょうか。
ファイルを閉じて続行します。アプリケーションの実行中にこのソースコードを簡単に参照できるように、ブラウザの新しいタブを開いて、GitHub の AverageSpeeds.java を表示します。
ブラウザでこのタブを開いたままにしておきます。このラボの後のステップでソースコードを参照します。
このスクリプトでは、Maven を使用して Java で Dataflow ストリーミング パイプラインを構築しています。
正常に完了した例:
この Dataflow パイプラインは、Pub/Sub トピックからメッセージを読み取り、入力メッセージの JSON を解析し、1 つの主出力を生成して BigQuery に書き込みます。
)で、[すべてのプロダクトを表示] > [分析] > [Dataflow] をクリックし、ジョブをクリックして進行状況をモニタリングします。例:
./run_oncloud.sh $DEVSHELL_PROJECT_ID $BUCKET AverageSpeeds を再度実行します。パイプラインが実行されたら、ナビゲーション メニュー(
[トピックの名前] の行で sandiego というトピックを探します。
ナビゲーション メニュー(
ブラウザの GitHub を表示しているタブのコード(AverageSpeeds.java)と、Dataflow ジョブのページに表示されているパイプラインのグラフを比較します。
グラフでパイプライン ステップ [GetMessages] を見つけ、AverageSpeeds.java ファイルでそれに対応するコードを特定します。これは、Pub/Sub トピックから読み取りを行うパイプライン ステップで、読み取られた Pub/Sub メッセージに対応する文字列のコレクションを作成します。
グラフでパイプライン ステップ [BySensor] と [AvgBySensor] を見つけ、AverageSpeeds.java ファイルでそれに対応するコード スニペットを特定します。[BySensor] ではウィンドウ内のすべてのイベントがセンサー ID ごとにグループ化され、[AvgBySensor] ではそれらの各グループの平均速度が計算されます。
グラフとコードでパイプライン ステップ [ToBQRow] を確認します。このステップでは、前のステップで計算された平均とレーン情報を含む「行」の作成のみを行います。
パイプライン グラフとソースコードの両方で [BigQueryIO.Write] を確認します。このステップでは、パイプラインの行を BigQuery テーブルに書き込みます。書き込み処理として [WriteDisposition.WRITE_APPEND] を選択しているため、新しいレコードがテーブルの末尾に追加されます。
ナビゲーション メニュー(
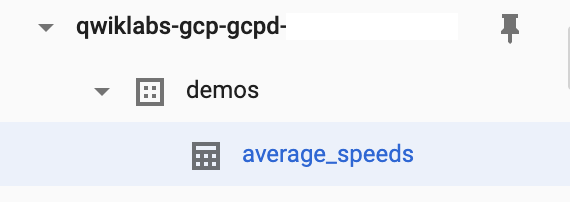
プロジェクト名と作成した demos データセットを確認します。データセット名 demos の左側にある小さい矢印が有効になり、それをクリックすると average_speeds テーブルが表示されます。
average_speeds テーブルが BigQuery に表示されるまでには数分かかります。
例:
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
Dataflow パイプラインをモニタリングして改善する際は、パイプラインで 1 秒あたりに処理される要素の数、システムラグ、その時点で処理済みのデータ要素数を特定するのが一般的です。このアクティビティでは、処理された要素と時間に関する情報を Cloud コンソールで確認していきます。
Cloud コンソールのナビゲーション メニュー(
グラフで [GetMessages] パイプライン ノードを選択し、右側でステップの指標を確認します。
)で、[BigQuery] > [スタジオ] をクリックします。次のクエリは、10 分前に存在していた average_speeds テーブルから一部の行を返します。
クエリで行をリクエストしても、指定した過去の時点でテーブルが存在しなかった場合は、次のエラー メッセージが表示されます。
Invalid snapshot time 1633691170651 for Table PROJECT:DATASET.TABLE__
このエラーが表示された場合は、時間の値を小さくしてタイムトラベルの範囲を狭くしてください。
着信 Pub/Sub メッセージのバックログを処理するために、Dataflow でワーカー数がどのようにスケールされるかを確認します。
Cloud コンソールのナビゲーション メニュー(
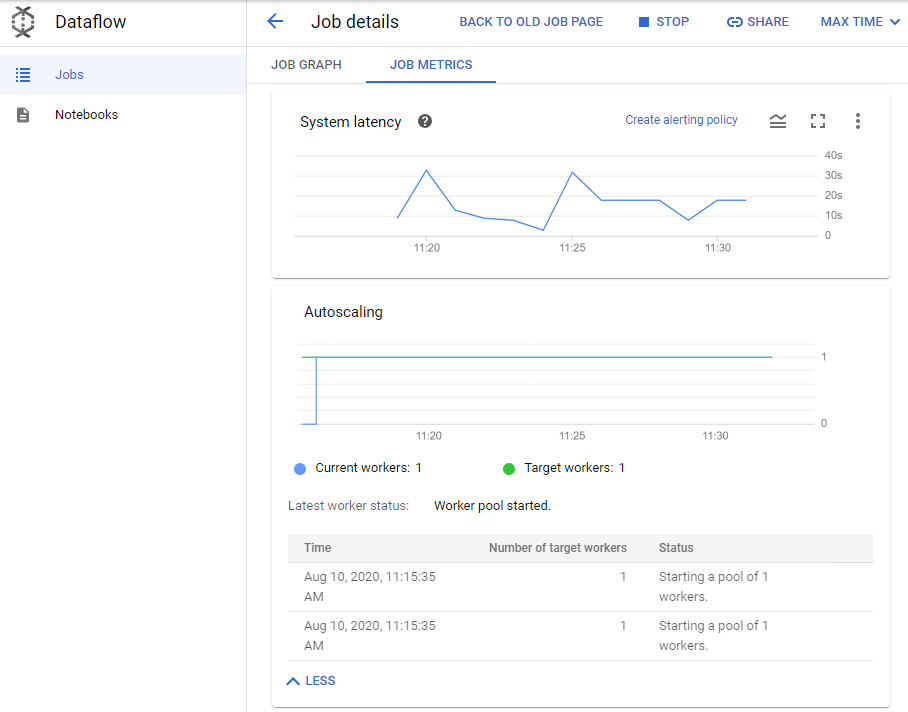
ジョブペインで [自動スケーリング] をクリックします。Pub/Sub トピックのメッセージを処理するために使用されているワーカー数を確認します。
[その他の履歴] をクリックし、パイプライン実行中のさまざまな時点で使用されたワーカー数を確認します。
ラボの始めに開始されたトラフィック センサー シミュレータからのデータによって、1 秒あたり何百ものメッセージが Pub/Sub トピックに作成されます。そのため、Dataflow はパイプラインのシステムラグを最適なレベルに保つ目的でワーカー数を増やします。
[その他の履歴] の [ワーカープール] で、Dataflow がワーカー数をどのように変更したかを確認できます。[ステータス] 列には変更の理由が示されています。
センサーデータのスクリプトを実行している training-vm の SSH ターミナルに戻ります。
[INFO: Publishing] というメッセージが表示される場合は、スクリプトがまだ実行されています。Ctrl+C キーを押してスクリプトを停止してから、スクリプトを再び開始するコマンドを実行します。
新しい SSH ターミナルを開きます。新しいセッションでは割り当ては未使用の状態です。
Cloud コンソールのナビゲーション メニュー(
training-vm という名前のインスタンスがある行を確認します。
右端の [接続] の下で [SSH] をクリックして、新しいターミナル ウィンドウを開きます。
training-vm の SSH ターミナルで、次のコマンドを入力して環境変数を作成します。
Cloud Monitoring を Dataflow に統合すると、ユーザーは System Lag(ストリーミング ジョブの場合)、Job Status(失敗または成功)、Element Counts、User Counters などの Dataflow ジョブ指標に Cloud Monitoring 内からアクセスできるようになります。
下記は、一般的な Dataflow 指標の一部です。
| 指標 | 機能 |
|---|---|
| Job status | ジョブ ステータス(失敗または成功)。30 秒ごと、および更新のたびに列挙型としてレポートされます。 |
| Elapsed time | ジョブの経過時間(秒単位で計測)。30 秒ごとにレポートされます。 |
| System lag | パイプライン全体での最大ラグ。数秒でレポートされます。 |
| Current vCPU count | ジョブで現在使用されている仮想 CPU の数。値が変化すると更新されます。 |
| Estimated byte count | PCollection ごとの処理バイト数。 |
Cloud Monitoring は、Google Cloud における別個のサービスです。そのため、ご使用のラボのアカウントでこのサービスを初期設定するために、いくつかのセットアップが必要になります。
Google Cloud コンソールのナビゲーション メニュー(
左側のパネルで [Metrics Explorer] をクリックします。
Metrics Explorer で [指標を選択] をクリックします。
[Dataflow Job] > [Job] を選択すると、使用可能な Dataflow 関連の指標が表示されます。[Data watermark lag] を選択して [適用] をクリックします。
Cloud Monitoring のページ右側にグラフが描画されます。
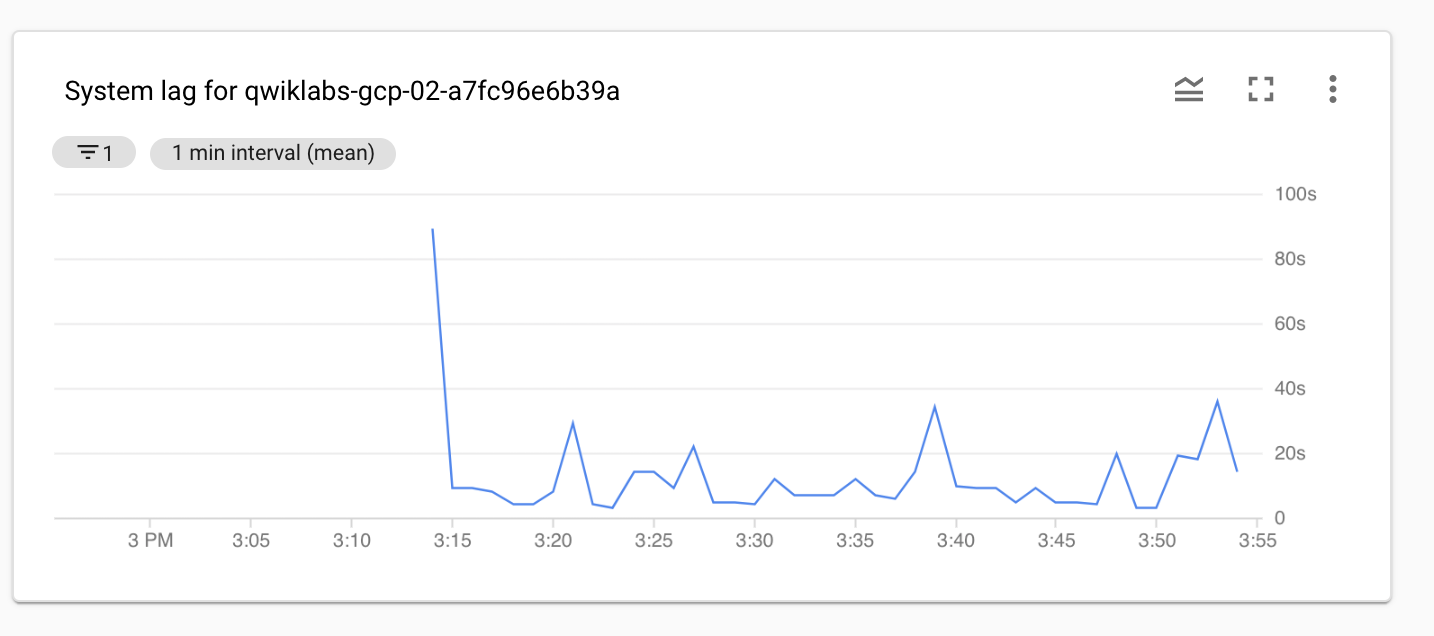
指標にある [リセット] をクリックして [Data watermark lag] 指標を削除します。新しい Dataflow 指標 [System lag] を選択します。
注: Dataflow から Monitoring に提供される指標の一覧は、Google Cloud の指標に関するドキュメントで確認できます。ページ上で Dataflow を検索してください。上で確認した指標は、パイプラインのパフォーマンス インジケータとして役立ちます。
Data watermark lag: パイプラインで処理が完了した、直近のデータ項目の経過時間(イベント タイムスタンプ以降の時間)。 System lag: 処理待ち状態になっていたデータ項目の現時点での最長時間(秒単位)。特定の指標が、指定されているしきい値を超えたとき(たとえばこのラボのストリーミング パイプラインのシステムラグが事前定義済みの値より大きくなったとき)に通知を受け取るには、Monitoring のアラート機能を利用します。
Cloud コンソールのナビゲーション メニュー(
[+ Create policy] をクリックします。
[指標を選択] プルダウンをクリックします。 [Active] チェックボックスをオフにします。
リソースと指標名のフィルタに「Dataflow Job」と入力し、[Dataflow Job] > [Job] をクリックします。[System lag] を選択して [適用] をクリックします。
[ローリング ウィンドウ] を [1 分] に設定します。[Next] をクリックします。
[トリガーの構成] をクリックします。
[しきい値の位置] で [しきい値より上] を選択し、[しきい値] に「5」と入力して [Next] をクリックします。
[通知チャンネル] ページが新しいタブで開きます。
ページを下方向にスクロールし、[Email] で [Add New] をクリックします。
[Create Email Channel] ダイアログ ボックスで、[Email address] にラボのユーザー名を入力し、[Display name] を入力します。
[Save] をクリックします。
[通知ポリシーの作成] タブに戻ります。
[通知チャンネル] をもう一度クリックし、更新アイコンをクリックして、前のステップで入力した表示名が表示されている状態にします。
使用する表示名を選択し、[OK] をクリックします。
[アラート ポリシー名] を「MyAlertPolicy」に設定します。
[Next] をクリックします。
アラートを確認して [ポリシーを作成] をクリックします。
[Monitoring] で [アラート] をクリックし、[Policies] ペインを表示します。
指標のしきい値の条件によってアラートがトリガーされるたびに、インシデントおよび対応するイベントが Monitoring で作成されます。また、アラートの通知メカニズム(メール、SMS など)を指定した場合は、通知を受け取ることができます。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
Cloud Monitoring ダッシュボードを使用すると、適切な Dataflow 関連のグラフを含むダッシュボードを簡単に作成できます。
Cloud コンソールのナビゲーション メニュー(
[カスタム ダッシュボードを作成します] をクリックします。
新しいダッシュボード名の項目に「My Dashboard」と入力します。
[ウィジェットを追加] をクリックし、[線] グラフをクリックします。
[指標を選択] にあるプルダウンをクリックします。
[Dataflow Job] > [Job] > [System lag] を選択して [適用] をクリックします。
[フィルタ] パネルで、[フィルタを追加] をクリックします。
[リソースラベル] で [project_id] を選択し、[値] で
[適用] をクリックします。
例:
必要に応じて、トピックでの Pub/Sub パブリッシュ レートやサブスクリプション バックログ(Dataflow 自動スケーラーに対するシグナル)などのグラフをダッシュボードに追加できます。
ラボが完了したら、[ラボを終了] をクリックします。ラボで使用したリソースが Google Cloud Skills Boost から削除され、アカウントの情報も消去されます。
ラボの評価を求めるダイアログが表示されたら、星の数を選択してコメントを入力し、[送信] をクリックします。
星の数は、それぞれ次の評価を表します。
フィードバックを送信しない場合は、ダイアログ ボックスを閉じてください。
フィードバックやご提案の送信、修正が必要な箇所をご報告いただく際は、[サポート] タブをご利用ください。
Copyright 2026 Google LLC All rights reserved. Google および Google のロゴは、Google LLC の商標です。その他すべての社名および製品名は、それぞれ該当する企業の商標である可能性があります。



このコンテンツは現在ご利用いただけません
利用可能になりましたら、メールでお知らせいたします

ありがとうございます。
利用可能になりましたら、メールでご連絡いたします

1 回に 1 つのラボ
既存のラボをすべて終了して、このラボを開始することを確認してください
ラボを開始するには、この簡単な手順を完了してください。