



始める前に
- ラボでは、Google Cloud プロジェクトとリソースを一定の時間利用します
- ラボには時間制限があり、一時停止機能はありません。ラボを終了した場合は、最初からやり直す必要があります。
- 画面左上の [ラボを開始] をクリックして開始します

BigQuery は、Google が低料金で提供する NoOps のフルマネージド分析データベースです。インフラストラクチャを所有して管理したり、データベース管理者を配置したりすることなく、テラバイト単位の大規模なデータでクエリを実行できます。BigQuery は SQL を採用しており、従量課金制モデルで利用できます。このような利点を活かし、ユーザーは有用な情報を得るためのデータの分析に専念することができます。
BigQuery の新機能である BigQuery ML(BQML、ベータ版)を使用すれば、最小限のコーディングで機械学習モデルの作成、トレーニング、評価、予測が可能になります。
このラボでは、BigQuery の一般公開データセットに含まれる数百万件に及ぶニューヨーク市内のタクシー賃走データを探索します。その後、機械学習モデルを BigQuery 内に作成し、モデル入力に基づいてタクシー運賃を予測します。最後に、モデルの性能を評価して予測を行います。
このラボでは、次のタスクの実行方法について学びます。
BigQuery を使用して一般公開データセットを見つける
タクシーの一般公開データセットでクエリを実行して探索する
バッチ予測に使用するトレーニングと評価のデータセットを作成する
予測(線形回帰)モデルを BQML に作成する
機械学習モデルの性能を評価する
各ラボでは、新しい Google Cloud プロジェクトとリソースセットを一定時間無料で利用できます。
Qwiklabs にシークレット ウィンドウでログインします。
ラボのアクセス時間(例: 1:15:00)に注意し、時間内に完了できるようにしてください。
一時停止機能はありません。必要な場合はやり直せますが、最初からになります。
準備ができたら、[ラボを開始] をクリックします。
ラボの認証情報(ユーザー名とパスワード)をメモしておきます。この情報は、Google Cloud Console にログインする際に使用します。
[Google Console を開く] をクリックします。
[別のアカウントを使用] をクリックし、このラボの認証情報をコピーしてプロンプトに貼り付けます。
他の認証情報を使用すると、エラーが発生したり、料金の請求が発生したりします。
利用規約に同意し、再設定用のリソースページをスキップします。
[Cloud Console の BigQuery へようこそ] メッセージ ボックスが開きます。このメッセージ ボックスにはクイックスタート ガイドへのリンクと、UI の更新情報が表示されます。
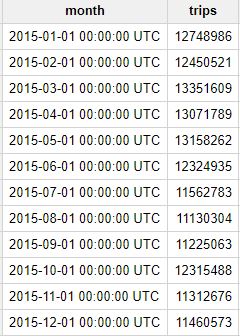
質問: 2015 年のイエロー タクシーの毎月の賃走回数は?
[クエリエディタ] フィールドに以下のクエリを追加します。
#standardSQL
SELECT
TIMESTAMP_TRUNC(pickup_datetime,
MONTH) month,
COUNT(*) trips
FROM
`bigquery-public-data.new_york.tlc_yellow_trips_2015`
GROUP BY
1
ORDER BY
1
[実行] をクリックします。
結果:
質問: 2015 年のイエロー タクシーの平均速度は?
前のクエリを以下に置き換え、[実行] をクリックします。
#standardSQL
SELECT
EXTRACT(HOUR
FROM
pickup_datetime) hour,
ROUND(AVG(trip_distance / TIMESTAMP_DIFF(dropoff_datetime,
pickup_datetime,
SECOND))*3600, 1) speed
FROM
`bigquery-public-data.new_york.tlc_yellow_trips_2015`
WHERE
trip_distance > 0
AND fare_amount/trip_distance BETWEEN 2
AND 10
AND dropoff_datetime > pickup_datetime
GROUP BY
1
ORDER BY
1
結果:
日中の平均速度はおよそ時速 11~12 マイルですが、午前 5 時の平均速度はほぼ倍の時速 21 マイルになっています。午前 5 時は交通量が少ないはずなので、これは直感的に理解できます。
次に、機械学習モデルを BigQuery に作成し、過去の賃走データセットに基づいてニューヨーク市のタクシー運賃を予測します。乗車前に運賃を予測できれば、乗客とタクシー会社の双方が、より効率的に乗車と配車の計画を立てられるようになります。
ニューヨーク市のイエロー タクシーのデータセットは、市が提供する一般公開データセットです。これは BigQuery に読み込まれ、自由に探索できるようになっています。フィールドの全一覧をこちらで確認してから、データセットをプレビューし、機械学習モデルが過去のタクシー賃走と運賃の関係を理解するのに役立つ特徴を見つけます。
以下のフィールドが運賃予測モデルに適した入力であるかどうかをテストします。
クエリを以下に置き換えます。
#standardSQL
WITH params AS (
SELECT
1 AS TRAIN,
2 AS EVAL
),
daynames AS
(SELECT ['Sun', 'Mon', 'Tues', 'Wed', 'Thurs', 'Fri', 'Sat'] AS daysofweek),
taxitrips AS (
SELECT
(tolls_amount + fare_amount) AS total_fare,
daysofweek[ORDINAL(EXTRACT(DAYOFWEEK FROM pickup_datetime))] AS dayofweek,
EXTRACT(HOUR FROM pickup_datetime) AS hourofday,
pickup_longitude AS pickuplon,
pickup_latitude AS pickuplat,
dropoff_longitude AS dropofflon,
dropoff_latitude AS dropofflat,
passenger_count AS passengers
FROM
`nyc-tlc.yellow.trips`, daynames, params
WHERE
trip_distance > 0 AND fare_amount > 0
AND MOD(ABS(FARM_FINGERPRINT(CAST(pickup_datetime AS STRING))),1000) = params.TRAIN
)
SELECT *
FROM taxitrips
このクエリについて、以下の点に注意します。
taxitrips がニューヨーク市のデータセットの抽出の大部分を担い、SELECT にトレーニングの特徴とラベルが含まれます。[実行] をクリックします。
結果の例を以下に示します。
どれがラベル(正解)ですか。
total_fare がラベル(予測するもの)です。このフィールドは tolls_amount と fare_amount から作成しています。チップは任意であるため、モデルでは無視できます。
次に、新しい BigQuery データセットを作成し、ML モデルを格納します。
[データセットを作成] ダイアログで、次の操作を行います。
[データセット ID] に「taxi」と入力します。
その他の値はデフォルトのままにします。
[データセットを作成] をクリックします。
最初に使用する特徴を選択したので、ML モデルを BigQuery に作成する準備ができました。
モデルタイプは次の 2 つから選択します。
| モデル | モデルタイプ | ラベルのデータ型 | 例 |
|---|---|---|---|
| 予測 | linear_reg | 数値(通常は整数または浮動小数点数) | 過去の売り上げデータから翌年の売り上げを予測。 |
| 分類 | logistic_reg | 0 または 1 のバイナリ分類 | コンテキストに応じて、メールを迷惑メールまたは迷惑メール以外に分類。 |
| マルチクラス分類 | logistic_reg | このモデルは、可能性のある複数の値を予測するために使用できます。たとえば、入力が低値、中間値、高値かどうかの判定に使用します。ラベルには、最大 50 個の一意の値を指定できます。 | メールを迷惑メール、標準の優先度、または高い優先度に分類。 |
注: 機械学習で使用されているモデルタイプは他にも多数あります(ニューラル ネットワークやディシジョン ツリーなど)。これらは TensorFlow などのライブラリで利用可能です。BQML は現時点で上記の 2 つをサポートしています。
この場合はどのモデルタイプを選択すればいいでしょうか。数値(タクシー運賃)を予測するため、線形回帰を使用します。
以下のクエリを入力してモデルを作成し、モデルのオプションを指定します。-- paste the previous training dataset query here は、事前に作成したトレーニング データセットのクエリに置き換えます(#standardSQL の行は省きます)。
CREATE or REPLACE MODEL taxi.taxifare_model
OPTIONS
(model_type='linear_reg', labels=['total_fare']) AS
-- paste the previous training dataset query here
次に、[実行] をクリックしてモデルのトレーニングを行います。
モデルのトレーニングが終わるのを待ちます(5~10 分)。
モデルのトレーニングが終わると、「このステートメントで新しいモデル <Project-ID>:taxi.taxifare_model が作成されました」という結果が表示されます。これはモデルのトレーニングが正常に終了したことを示します。
taxi データセット内に taxifare_model があることを確認します。
次に、未知の評価データに対してモデルの性能を評価します。
線形回帰モデルには、二乗平均平方根誤差(RMSE)などの損失指標を使用します。RMSE が下がるまでトレーニングを続け、モデルを改善していきます。
BQML の mean_squared_error は、トレーニングを行った ML モデルを評価するときにクエリ可能なフィールドです。RMSE を取得するには SQRT() を追加します。
トレーニングが完了したので、ML.EVALUATE を使用してこのクエリに対するモデルの性能を評価します。
#standardSQL
SELECT
SQRT(mean_squared_error) AS rmse
FROM
ML.EVALUATE(MODEL taxi.taxifare_model,
(
WITH params AS (
SELECT
1 AS TRAIN,
2 AS EVAL
),
daynames AS
(SELECT ['Sun', 'Mon', 'Tues', 'Wed', 'Thurs', 'Fri', 'Sat'] AS daysofweek),
taxitrips AS (
SELECT
(tolls_amount + fare_amount) AS total_fare,
daysofweek[ORDINAL(EXTRACT(DAYOFWEEK FROM pickup_datetime))] AS dayofweek,
EXTRACT(HOUR FROM pickup_datetime) AS hourofday,
pickup_longitude AS pickuplon,
pickup_latitude AS pickuplat,
dropoff_longitude AS dropofflon,
dropoff_latitude AS dropofflat,
passenger_count AS passengers
FROM
`nyc-tlc.yellow.trips`, daynames, params
WHERE
trip_distance > 0 AND fare_amount > 0
AND MOD(ABS(FARM_FINGERPRINT(CAST(pickup_datetime AS STRING))),1000) = params.EVAL
)
SELECT *
FROM taxitrips
))
params.EVAL フィルタで、異なるタクシー賃走データセットに対してモデルを評価します。
モデルの実行後、モデルの結果を確認します(モデルの実際の RMSE 値はわずかに異なる場合があります)。
| 行 | rmse |
|---|---|
| 1 | 9.477056435999074 |
モデルを評価したら、RMSE が $9.47 になりました。この損失指標で、このモデルを本番環境用に使用してもいいかどうかは、モデルのトレーニング開始前に設定するベンチマーク基準によって異なります。ベンチマークとは、許容できる最低レベルのモデルの性能と精度を確立するための基準です。
モデルがデータに過剰適合していないことを確認する必要があります。モデルが過剰適合すると、未知のデータに対する性能が低下します。ML.TRAINING_INFO を使用すると、トレーニングの損失と評価の損失を比較できます。
SELECT * FROM ML.TRAINING_INFO(model `taxi.taxifare_model`);
この SELECT 文では、モデル トレーニングを反復するたびにすべての情報が選択されます。この情報には、トレーニングの反復回数、トレーニングの損失、評価の損失などが含まれます。
トレーニングの損失と評価の損失を比較するために、損失曲線を視覚化して差異を調査します。Cloud Console の BigQuery で、[データを探索] > [データポータルで調べる] をクリックします。データポータルが開き、入力元として接続されたクエリからのデータが表示されます。
プロンプトが表示されたら、[使ってみる] ボタンを選択します。
Google データポータルにデータへのアクセスを許可するかどうかを尋ねられたら、[承認] を選択します。
[使ってみる] をクリックして利用規約を承認します。[同意する] をクリックします。
[設定] ですべて [いいえ] を選択して [完了] をクリックします。
タブを更新してデータを読み込みます。
データポータルで、Combo chart のアイコンをクリックします。
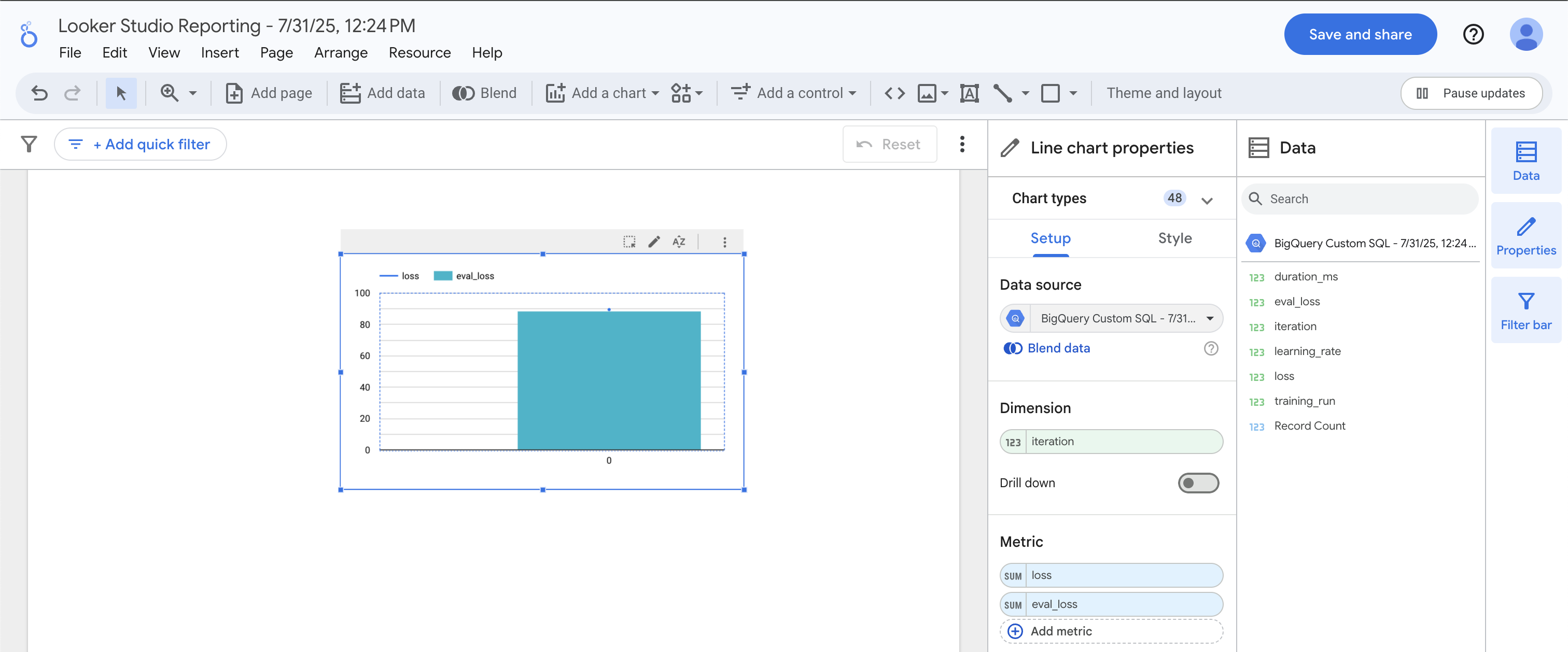
[Dimension] の下に iteration をドラッグします。[Metric] の下に loss と eval_loss をドラッグします。棒グラフの上に折れ線グラフが重なって表示されます。
トレーニングの損失は、評価の損失とほぼ一致しています。これは、モデルに過剰適合していないことを示しています。正しく適合できたので、予測に進みます。
次に、新しいモデルを使用して予測を行うためのクエリを作成します。
#standardSQL
SELECT
*
FROM
ml.PREDICT(MODEL `taxi.taxifare_model`,
(
WITH params AS (
SELECT
1 AS TRAIN,
2 AS EVAL
),
daynames AS
(SELECT ['Sun', 'Mon', 'Tues', 'Wed', 'Thurs', 'Fri', 'Sat'] AS daysofweek),
taxitrips AS (
SELECT
(tolls_amount + fare_amount) AS total_fare,
daysofweek[ORDINAL(EXTRACT(DAYOFWEEK FROM pickup_datetime))] AS dayofweek,
EXTRACT(HOUR FROM pickup_datetime) AS hourofday,
pickup_longitude AS pickuplon,
pickup_latitude AS pickuplat,
dropoff_longitude AS dropofflon,
dropoff_latitude AS dropofflat,
passenger_count AS passengers
FROM
`nyc-tlc.yellow.trips`, daynames, params
WHERE
trip_distance > 0 AND fare_amount > 0
AND MOD(ABS(FARM_FINGERPRINT(CAST(pickup_datetime AS STRING))),1000) = params.EVAL
)
SELECT *
FROM taxitrips
));
タクシー運賃に対するモデルの予測が、その賃走の実際の運賃とその他の特徴とともに表示されます。
ヒント: 新しいデータで既存のモデルの再トレーニングを行う場合、warm_start = true をモデルのオプションに追加するとトレーニング時間を短縮できます。特徴の列を変更することはできません(変更すると、新しいモデルが必要になります)。
シカゴのタクシー運賃を予測する場合など、他のデータセットに対してモデルを作成するには、以下のリンクを使用して、bigquery-public-data プロジェクトを開始します。
これで、ニューヨーク市のタクシー運賃を予測する ML モデルを BigQuery に作成できました。
ラボが完了したら、[ラボを終了] をクリックします。ラボで使用したリソースが Google Cloud Skills Boost から削除され、アカウントの情報も消去されます。
ラボの評価を求めるダイアログが表示されたら、星の数を選択してコメントを入力し、[送信] をクリックします。
星の数は、それぞれ次の評価を表します。
フィードバックを送信しない場合は、ダイアログ ボックスを閉じてください。
フィードバックやご提案の送信、修正が必要な箇所をご報告いただく際は、[サポート] タブをご利用ください。
Copyright 2026 Google LLC All rights reserved. Google および Google のロゴは、Google LLC の商標です。その他すべての社名および製品名は、それぞれ該当する企業の商標である可能性があります。



このコンテンツは現在ご利用いただけません
利用可能になりましたら、メールでお知らせいたします

ありがとうございます。
利用可能になりましたら、メールでご連絡いたします

1 回に 1 つのラボ
既存のラボをすべて終了して、このラボを開始することを確認してください