Mettez en pratique vos compétences dans la console Google Cloud
Instructions et exigences de configuration de l'atelier
Protégez votre compte et votre progression. Utilisez toujours une fenêtre de navigation privée et les identifiants de l'atelier pour exécuter cet atelier.
Prédire le prix d'une course en taxi à l'aide d'un modèle de prévision BigQuery ML v1.5
Ce contenu n'est pas encore optimisé pour les appareils mobiles.
Pour une expérience optimale, veuillez accéder à notre site sur un ordinateur de bureau en utilisant un lien envoyé par e-mail.
Présentation
BigQuery est la base de données d'analyse à faible coût de Google, entièrement gérée et qui ne nécessite aucune opération (NoOps). Grâce à BigQuery, vous pouvez interroger plusieurs téraoctets de données sans avoir à gérer d'infrastructure ni faire appel à un administrateur de base de données. Basé sur le langage SQL et le modèle de facturation à l'utilisation, BigQuery BigQuery vous permet de vous concentrer sur l'analyse des données pour en dégager des informations pertinentes.
BigQuery dispose d'une nouvelle fonctionnalité appelée BigQuery Machine Learning (ou BQML, disponible en version bêta), qui permet aux analystes de données de créer, d'entraîner et d'évaluer des modèles de machine learning en vue de prédire des résultats, et ce avec très peu de code.
Dans cet atelier, vous allez analyser des millions de courses effectuées par les taxis jaunes de New York à partir d'un ensemble de données public BigQuery. Vous allez ensuite créer un modèle de machine learning dans BigQuery pour prédire le prix de la course à partir des données traitées par le modèle. Pour finir, vous allez évaluer les performances du modèle et réaliser des prédictions.
Objectifs
Dans cet atelier, vous allez apprendre à réaliser les opérations suivantes :
Utiliser BigQuery pour rechercher des ensembles de données publics
Interroger et examiner l'ensemble de données public relatif aux taxis
Créer un ensemble de données d'entraînement et d'évaluation pour la prédiction par lot
Créer un modèle de prévision (de type régression linéaire) dans BQML
Évaluer les performances de votre modèle de machine learning
Pour chaque atelier, nous vous attribuons un nouveau projet Google Cloud et un nouvel ensemble de ressources pour une durée déterminée, sans frais.
Connectez-vous à Qwiklabs dans une fenêtre de navigation privée.
Vérifiez le temps imparti pour l'atelier (par exemple : 01:15:00) : vous devez pouvoir le terminer dans ce délai.
Une fois l'atelier lancé, vous ne pouvez pas le mettre en pause. Si nécessaire, vous pourrez le redémarrer, mais vous devrez tout reprendre depuis le début.
Lorsque vous êtes prêt, cliquez sur Démarrer l'atelier.
Notez vos identifiants pour l'atelier (Nom d'utilisateur et Mot de passe). Ils vous serviront à vous connecter à Google Cloud Console.
Cliquez sur Ouvrir la console Google.
Cliquez sur Utiliser un autre compte, puis copiez-collez les identifiants de cet atelier lorsque vous y êtes invité.
Si vous utilisez d'autres identifiants, des messages d'erreur s'afficheront ou des frais seront appliqués.
Acceptez les conditions d'utilisation et ignorez la page concernant les ressources de récupération des données.
Ouvrir la console BigQuery
Dans la console Google Cloud, sélectionnez le menu de navigation > BigQuery.
Le message Bienvenue sur BigQuery dans la console Cloud s'affiche. Il contient un lien vers le guide de démarrage rapide et liste les mises à jour de l'interface utilisateur.
Cliquez sur Done (OK).
Examiner les données relatives aux taxis new-yorkais
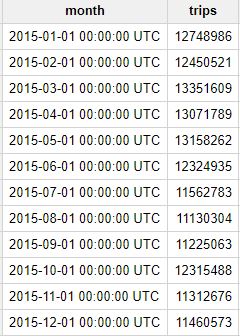
Question : Combien de courses les taxis jaunes ont-ils effectuées chaque mois en 2015 ?
Ajoutez la requête suivante dans le champ Query editor (Éditeur de requête).
#standardSQL
SELECT
TIMESTAMP_TRUNC(pickup_datetime,
MONTH) month,
COUNT(*) trips
FROM
`bigquery-public-data.new_york.tlc_yellow_trips_2015`
GROUP BY
1
ORDER BY
1
Ensuite, cliquez sur Run (Exécuter).
Vous obtenez le résultat suivant :
Question : Quelle était la vitesse moyenne des taxis jaunes en 2015 ?
Remplacez la requête précédente par celle qui suit, puis cliquez sur Run (Exécuter) :
#standardSQL
SELECT
EXTRACT(HOUR
FROM
pickup_datetime) hour,
ROUND(AVG(trip_distance / TIMESTAMP_DIFF(dropoff_datetime,
pickup_datetime,
SECOND))*3600, 1) speed
FROM
`bigquery-public-data.new_york.tlc_yellow_trips_2015`
WHERE
trip_distance > 0
AND fare_amount/trip_distance BETWEEN 2
AND 10
AND dropoff_datetime > pickup_datetime
GROUP BY
1
ORDER BY
1
Vous obtenez le résultat suivant :
En journée, la vitesse moyenne est d'environ 18 km/h. Elle atteint 34 km/h à 5 h du matin, soit près du double. Cela semble logique, car la circulation est sans doute plus fluide à cette heure-là.
Identifier un objectif
Vous allez maintenant créer un modèle de machine learning dans BigQuery afin de prédire le prix d'une course à New York en vous basant sur un ensemble de données contenant l'historique des courses et les informations associées. Cela peut s'avérer très utile en termes de planification des trajets, pour le chauffeur comme pour l'agence de taxis.
Sélectionner des caractéristiques et créer l'ensemble de données d'entraînement
L'ensemble de données concernant les taxis jaunes new-yorkais est un ensemble de données public fourni par la ville. Il a été chargé dans BigQuery afin que vous puissiez l'examiner. Après avoir parcouru la liste complète des champs sur cette page, prévisualisez l'ensemble de données pour identifier les caractéristiques utiles qui permettront à votre modèle de machine learning de déterminer le lien entre les données concernant l'historique des courses en taxi et le prix de la course.
Votre équipe veut savoir si les champs suivants conviennent pour établir le modèle de prévision du prix d'une course :
Tarif des péages
Prix de la course
Heure de la journée
Adresse de départ
Adresse d'arrivée
Nombre de passagers
Remplacez la requête par le code suivant :
#standardSQL
WITH params AS (
SELECT
1 AS TRAIN,
2 AS EVAL
),
daynames AS
(SELECT ['Sun', 'Mon', 'Tues', 'Wed', 'Thurs', 'Fri', 'Sat'] AS daysofweek),
taxitrips AS (
SELECT
(tolls_amount + fare_amount) AS total_fare,
daysofweek[ORDINAL(EXTRACT(DAYOFWEEK FROM pickup_datetime))] AS dayofweek,
EXTRACT(HOUR FROM pickup_datetime) AS hourofday,
pickup_longitude AS pickuplon,
pickup_latitude AS pickuplat,
dropoff_longitude AS dropofflon,
dropoff_latitude AS dropofflat,
passenger_count AS passengers
FROM
`nyc-tlc.yellow.trips`, daynames, params
WHERE
trip_distance > 0 AND fare_amount > 0
AND MOD(ABS(FARM_FINGERPRINT(CAST(pickup_datetime AS STRING))),1000) = params.TRAIN
)
SELECT *
FROM taxitrips
Informations importantes concernant la requête :
La partie principale de la requête se trouve à la fin : "SELECT * from taxitrips".
L'essentiel de l'extraction depuis l'ensemble de données relatif aux taxis new-yorkais s'effectue grâce à taxitrips. La partie "SELECT" contient les caractéristiques d'entraînement et l'étiquette que vous avez définies.
La partie "WHERE" permet d'exclure certaines données de l'entraînement.
La partie "WHERE" inclut également une clause d'échantillonnage permettant de ne sélectionner que 1/1 000e des données.
Nous définissons une variable d'entraînement ("TRAIN") pour pouvoir créer rapidement un ensemble d'évaluation ("EVAL") indépendant.
Ensuite, cliquez sur Run (Exécuter).
Exemple de résultats :
Quelle est l'étiquette (la réponse correcte) ?
L'étiquette correspond à total_fare (montant total), ce que nous allons prédire. Ce champ découle de tolls_amount (tarif des péages) et de fare_amount (prix de la course). Vous pouvez donc ignorer les pourboires des clients dans le modèle étant donné qu'ils ne sont pas obligatoires.
Créer un ensemble de données BigQuery pour y stocker vos modèles
Créons maintenant un autre ensemble de données BigQuery dans lequel stocker vos modèles de ML.
Dans le volet de gauche, cliquez sur le nom de votre projet, puis sur Create Dataset (Créer un ensemble de données).
Dans la boîte de dialogue Create dataset (Créer un ensemble de données) :
Dans le champ Dataset ID (ID de l'ensemble de données), saisissez taxi.
Conservez les valeurs par défaut dans les autres champs.
Cliquez sur Create dataset (Créer un ensemble de données).
Sélectionner un type de modèle BQML et définir les options correspondantes
Maintenant que vous avez sélectionné les caractéristiques de base, vous pouvez créer votre premier modèle de ML dans BigQuery.
Vous avez le choix entre deux types de modèles :
Modèle
Type de modèle
Type de données de l'étiquette
Exemple
Prévision
linear_reg (régression linéaire)
Valeur numérique (nombre entier ou à virgule flottante)
Prévisions de ventes pour l'année prochaine d'après l'historique des données de ventes
Classification
logistic_reg (régression logistique)
0 ou 1 (classification binaire)
Classification ou non d'un e-mail dans la catégorie spam selon le contexte
Classification à classes multiples
logistic_reg (régression logistique)
Ces modèles permettent de prédire plusieurs valeurs possibles (par exemple, si une entrée est une "valeur faible", une "valeur moyenne" ou une "valeur élevée"). Chaque étiquette peut contenir jusqu'à 50 valeurs uniques.
Classification d'un e-mail dans la catégorie de spam, de priorité normale ou d'importance élevée
Remarque : Il existe de nombreux autres types de modèles pour le machine learning (comme les réseaux de neurones et les arbres de décision). Ces modèles sont disponibles dans des bibliothèques telles que TensorFlow. Pour l'instant, BQML n'accepte que les deux types de modèles mentionnés ci-dessus.
Quel type de modèle choisir ? La prédiction portant ici sur une valeur numérique (le prix de la course), vous allez utiliser la régression linéaire.
Saisissez la requête suivante afin de créer un modèle et d'en définir les options, en remplaçant -- paste the previous training dataset query here par la requête de l'ensemble de données d'entraînement créée plus tôt (supprimez la ligne #standardSQL) :
CREATE or REPLACE MODEL taxi.taxifare_model
OPTIONS
(model_type='linear_reg', labels=['total_fare']) AS
-- paste the previous training dataset query here
Cliquez ensuite sur Run (Exécuter) pour entraîner le modèle.
Attendez que le modèle soit entraîné (5 à 10 minutes).
Une fois votre modèle entraîné, le résultat suivant s'affiche : This statement created a new model named <Project-ID>:taxi.taxifare_model (Cette instruction a créé un modèle nommé "<Project-ID>:taxi.taxifare_model"). Cela indique que votre modèle a bien été entraîné.
Vérifiez que le code taxifare_model apparaît bien dans l'ensemble de données portant sur les taxis.
L'étape suivante consiste à évaluer les performances du modèle à partir de nouvelles données d'évaluation.
Évaluer les performances du modèle de classification
Sélectionner vos critères de performance
Pour les modèles de type régression linéaire, vous devez utiliser une statistique de perte, à savoir la racine carrée de l'erreur quadratique moyenne (RMSE). L'objectif est de continuer à entraîner le modèle et à l'améliorer de manière que ce chiffre soit le plus bas possible.
Dans BQML, mean_squared_error désigne simplement un champ interrogeable lors de l'évaluation du modèle de ML entraîné. Pour obtenir la valeur RMSE, il suffit d'ajouter "SQRT()".
Une fois l'entraînement terminé, la fonction ML.EVALUATE vous permet d'évaluer les performances du modèle à l'aide de cette requête :
#standardSQL
SELECT
SQRT(mean_squared_error) AS rmse
FROM
ML.EVALUATE(MODEL taxi.taxifare_model,
(
WITH params AS (
SELECT
1 AS TRAIN,
2 AS EVAL
),
daynames AS
(SELECT ['Sun', 'Mon', 'Tues', 'Wed', 'Thurs', 'Fri', 'Sat'] AS daysofweek),
taxitrips AS (
SELECT
(tolls_amount + fare_amount) AS total_fare,
daysofweek[ORDINAL(EXTRACT(DAYOFWEEK FROM pickup_datetime))] AS dayofweek,
EXTRACT(HOUR FROM pickup_datetime) AS hourofday,
pickup_longitude AS pickuplon,
pickup_latitude AS pickuplat,
dropoff_longitude AS dropofflon,
dropoff_latitude AS dropofflat,
passenger_count AS passengers
FROM
`nyc-tlc.yellow.trips`, daynames, params
WHERE
trip_distance > 0 AND fare_amount > 0
AND MOD(ABS(FARM_FINGERPRINT(CAST(pickup_datetime AS STRING))),1000) = params.EVAL
)
SELECT *
FROM taxitrips
))
Vous évaluez désormais le modèle par rapport à différentes courses de taxi avec votre filtre params.EVAL.
Examinez les résultats après l'exécution du modèle. Il est normal que la valeur RMSE varie légèrement.
Ligne
"rmse"
1
9,477056435999074
Suite à l'évaluation du modèle, vous obtenez une RMSE de 9,47 $. Cette statistique de perte peut s'avérer acceptable ou non pour produire ensuite le modèle. Tout dépend des critères d'analyse comparative définis en amont de la phase d'entraînement qui permettent de fixer un niveau minimal acceptable en termes de performances et de justesse du modèle.
Comparer les pertes d'entraînement et d'évaluation
Vous devez vous assurer que votre modèle n'est pas surajusté. En cas de surapprentissage, votre modèle ne donnerait pas les résultats escomptés avec d'autres données. Vous pouvez comparer les pertes d'entraînement et d'évaluation, à l'aide de ML.TRAINING_INFO.
SELECT * FROM ML.TRAINING_INFO(model `taxi.taxifare_model`);
Toutes les informations de chacune des itérations de l'entraînement du modèle seront alors sélectionnées, telles que le nombre d'itérations d'entraînement, la perte d'entraînement et la perte d'évaluation.
Pour comparer ces deux pertes, nous allons examiner les différences visuelles au niveau des courbes de fonction de perte. Cliquez sur EXPLORE DATA > Explore with Data Studio (Explorer les données > Explorer avec Data Studio) dans Cloud Console pour BigQuery. Data Studio s'affiche avec les données de votre requête associées en tant que source de données.
Lorsque vous y êtes invité, sélectionnez le bouton GET STARTED (Commencer).
Sélectionnez AUTHORIZE (Autoriser) pour autoriser Google Data Studio à accéder à vos données.
Remarque : Si le message Oops… Not able to connect to your data (Petit problème… Connexion aux données impossible) vous est renvoyé, cliquez sur Back (Retour). Cliquez sur Save (Enregistrer) dans l'explorateur Data Studio.
Cliquez sur GET STARTED (Commencer), puis prenez connaissance des conditions d'utilisation. Cliquez sur Accept (Accepter).
Sélectionnez No, thanks (Non, merci) pour la totalité des préférences, puis cliquez sur Done (OK).
Actualisez l'onglet pour charger les données.
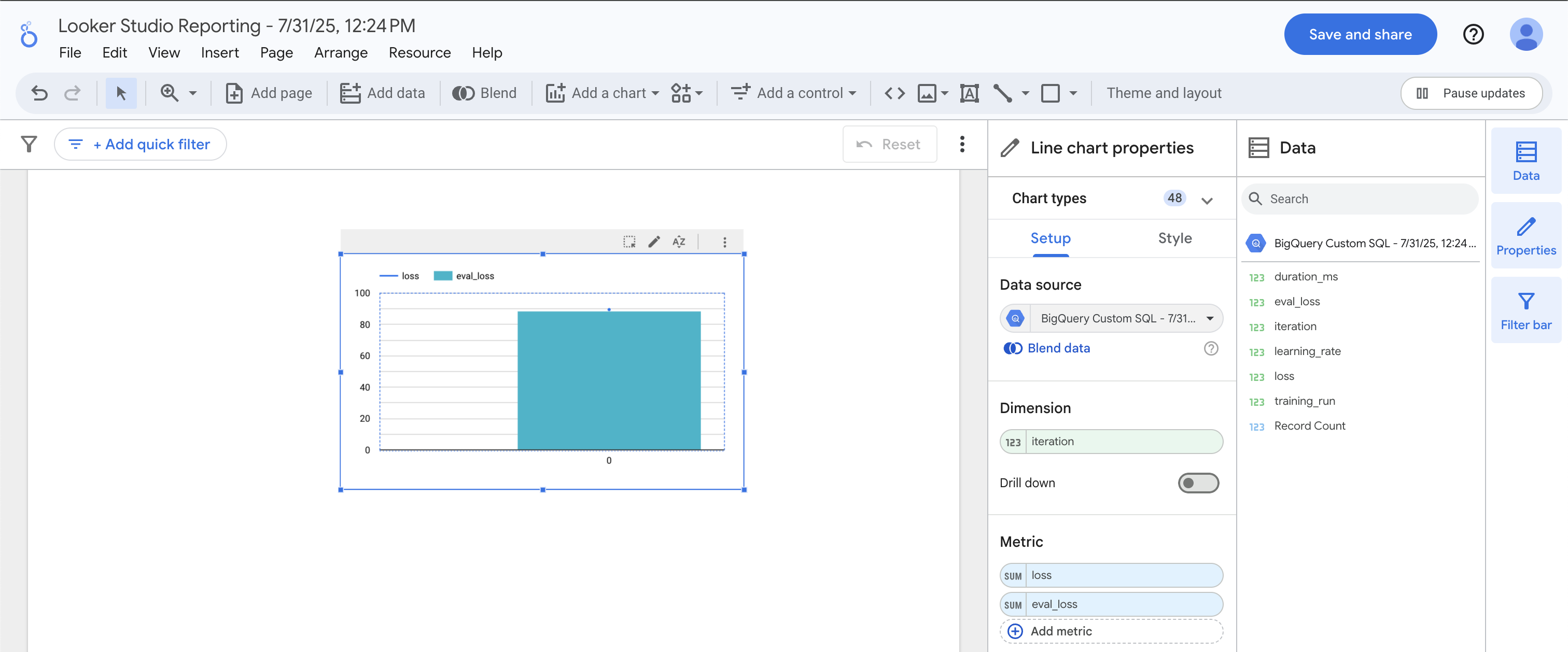
Une fois dans Data Studio, cliquez sur l'icône Combo Chart (Graphique combiné).
Sous Dimension, faites glisser la valeur iteration. Sous Metric (Métrique), faites glisser les valeurs loss et eval_loss. Le graphique que vous obtenez doit montrer deux types de graphiques superposés : en courbes et à barres.
Les pertes d'entraînement et d'évaluation correspondent presque parfaitement, ce qui signifie que notre modèle ne constitue pas un cas de surapprentissage. Parfait ! Passons maintenant à la prédiction.
Prédire le prix d'une course en taxi
Vous allez maintenant créer une requête afin de réaliser des prédictions à l'aide du nouveau modèle :
#standardSQL
SELECT
*
FROM
ml.PREDICT(MODEL `taxi.taxifare_model`,
(
WITH params AS (
SELECT
1 AS TRAIN,
2 AS EVAL
),
daynames AS
(SELECT ['Sun', 'Mon', 'Tues', 'Wed', 'Thurs', 'Fri', 'Sat'] AS daysofweek),
taxitrips AS (
SELECT
(tolls_amount + fare_amount) AS total_fare,
daysofweek[ORDINAL(EXTRACT(DAYOFWEEK FROM pickup_datetime))] AS dayofweek,
EXTRACT(HOUR FROM pickup_datetime) AS hourofday,
pickup_longitude AS pickuplon,
pickup_latitude AS pickuplat,
dropoff_longitude AS dropofflon,
dropoff_latitude AS dropofflat,
passenger_count AS passengers
FROM
`nyc-tlc.yellow.trips`, daynames, params
WHERE
trip_distance > 0 AND fare_amount > 0
AND MOD(ABS(FARM_FINGERPRINT(CAST(pickup_datetime AS STRING))),1000) = params.EVAL
)
SELECT *
FROM taxitrips
));
Les prédictions concernant le prix des courses s'affichent, avec les prix réels et d'autres caractéristiques liées à ces trajets.
Informations supplémentaires
Conseil : Si vous relancez l'entraînement d'un modèle existant avec de nouvelles données, gagnez du temps en ajoutant warm_start = true à ses options. Par contre, il est impossible de modifier les colonnes de caractéristiques. Cette opération nécessiterait un nouveau modèle.
Autres ensembles de données à examiner
Cliquez sur le lien ci-dessous pour accéder au projet bigquery-public-data et découvrir la modélisation d'autres ensembles de données, par exemple pour prédire le montant d'une course en taxi à Chicago :
Vous avez créé un modèle de ML dans BigQuery permettant de prédire le prix d'une course en taxi à New York.
Terminer l'atelier
Une fois l'atelier terminé, cliquez sur Terminer l'atelier. Google Cloud Skills Boost supprime les ressources que vous avez utilisées, puis efface le compte.
Si vous le souhaitez, vous pouvez noter l'atelier. Sélectionnez un nombre d'étoiles, saisissez un commentaire, puis cliquez sur Envoyer.
Le nombre d'étoiles correspond à votre degré de satisfaction :
1 étoile = très insatisfait(e)
2 étoiles = insatisfait(e)
3 étoiles = ni insatisfait(e), ni satisfait(e)
4 étoiles = satisfait(e)
5 étoiles = très satisfait(e)
Si vous ne souhaitez pas donner votre avis, vous pouvez fermer la boîte de dialogue.
Pour soumettre des commentaires, suggestions ou corrections, veuillez accéder à l'onglet Assistance.
Copyright 2026 Google LLC Tous droits réservés. Google et le logo Google sont des marques de Google LLC. Tous les autres noms de société et de produit peuvent être des marques des sociétés auxquelles ils sont associés.
Les ateliers créent un projet Google Cloud et des ressources pour une durée déterminée.
Les ateliers doivent être effectués dans le délai imparti et ne peuvent pas être mis en pause. Si vous quittez l'atelier, vous devrez le recommencer depuis le début.
En haut à gauche de l'écran, cliquez sur Démarrer l'atelier pour commencer.
Utilisez la navigation privée
Copiez le nom d'utilisateur et le mot de passe fournis pour l'atelier
Cliquez sur Ouvrir la console en navigation privée
Connectez-vous à la console
Connectez-vous à l'aide des identifiants qui vous ont été attribués pour l'atelier. L'utilisation d'autres identifiants peut entraîner des erreurs ou des frais.
Acceptez les conditions d'utilisation et ignorez la page concernant les ressources de récupération des données.
Ne cliquez pas sur Terminer l'atelier, à moins que vous n'ayez terminé l'atelier ou que vous ne vouliez le recommencer, car cela effacera votre travail et supprimera le projet.
Ce contenu n'est pas disponible pour le moment
Nous vous préviendrons par e-mail lorsqu'il sera disponible
Parfait !
Nous vous contacterons par e-mail s'il devient disponible
Un atelier à la fois
Confirmez pour mettre fin à tous les ateliers existants et démarrer celui-ci
Utilisez la navigation privée pour effectuer l'atelier
Le meilleur moyen d'exécuter cet atelier consiste à utiliser une fenêtre de navigation privée. Vous éviterez ainsi les conflits entre votre compte personnel et le compte temporaire de participant, qui pourraient entraîner des frais supplémentaires facturés sur votre compte personnel.
Dans cet atelier, vous allez analyser des millions de courses effectuées par les taxis jaunes de New York, à partir d'un ensemble de données public BigQuery. Vous allez ensuite créer un modèle de ML dans BigQuery afin de prédire le prix de la course, puis vous évaluerez les performances du modèle créé.
Durée :
0 min de configuration
·
Accessible pendant 60 min
·
Terminé après 60 min