Este contenido aún no está optimizado para dispositivos móviles.
Para obtener la mejor experiencia, visítanos en una computadora de escritorio con un vínculo que te enviaremos por correo electrónico.
Descripción general
BigQuery es la base de datos estadísticos de Google de bajo costo, NoOps y completamente administrada. Con BigQuery, puede consultar muchos terabytes de datos sin tener que administrar ninguna infraestructura y sin la necesidad de un administrador de base de datos. BigQuery usa SQL y puede aprovechar el modelo prepago. Además, le permite enfocarse en el análisis de datos para buscar estadísticas valiosas.
BigQuery Machine Learning (BQML, producto en versión Beta) es una nueva función de BigQuery en la que los analistas de datos pueden crear, entrenar, evaluar y predecir con modelos de aprendizaje automático y programación mínima.
En este lab, explorará millones de viajes de taxis amarillos de la ciudad de Nueva York disponibles en un conjunto de datos públicos de BigQuery. Luego, creará un modelo de aprendizaje automático en BigQuery a fin de predecir la tarifa del viaje en función de los datos de su modelo. Por último, evaluará el rendimiento de su modelo y hará predicciones.
Objetivos
En este lab, aprenderá a realizar las siguientes tareas:
Usar BigQuery para buscar conjuntos de datos públicos
Consultar y explorar el conjunto de datos públicos de taxis
Crear un conjunto de datos de entrenamiento y evaluación para usarlos en la predicción por lotes
Crear un modelo de previsión (regresión lineal) en BQML
Evaluar el rendimiento de su modelo de aprendizaje automático
En cada lab, recibirá un proyecto de Google Cloud y un conjunto de recursos nuevos por tiempo limitado y sin costo adicional.
Accede a Qwiklabs desde una ventana de incógnito.
Ten en cuenta el tiempo de acceso del lab (por ejemplo, 1:15:00) y asegúrate de finalizarlo en el plazo asignado.
No existe una función de pausa. Si lo necesita, puede reiniciar el lab, pero deberá hacerlo desde el comienzo.
Cuando esté listo, haga clic en Comenzar lab.
Anote las credenciales del lab (el nombre de usuario y la contraseña). Las usarás para acceder a la consola de Google Cloud.
Haga clic en Abrir Google Console.
Haga clic en Usar otra cuenta, copie las credenciales para este lab y péguelas en el mensaje emergente que aparece.
Si usa otras credenciales, se generarán errores o incurrirá en cargos.
Acepta las condiciones y omite la página de recursos de recuperación.
Abra BigQuery en Console
En la consola de Google Cloud, seleccione elmenú de navegación > BigQuery.
Se abrirá el cuadro de mensaje Te damos la bienvenida a BigQuery en la consola de Cloud, Contiene un vínculo a la guía de inicio rápido y enumera las actualizaciones de la IU.
Haga clic en Listo.
Explore los datos de taxis de NYC
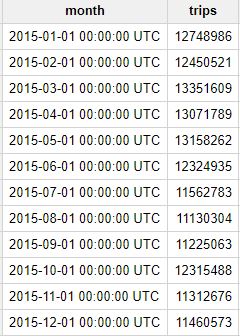
Pregunta: ¿Cuántos viajes por mes hicieron los taxis amarillos en 2015?
Agregue la siguiente consulta en el campo Editor de consultas.
#standardSQL
SELECT
TIMESTAMP_TRUNC(pickup_datetime,
MONTH) month,
COUNT(*) trips
FROM
`bigquery-public-data.new_york.tlc_yellow_trips_2015`
GROUP BY
1
ORDER BY
1
Luego, haga clic en Ejecutar.
Este es el resultado:
Pregunta: ¿Cuál fue la velocidad promedio de los viajes de taxis amarillos en 2015?
Reemplace la consulta anterior por lo siguiente y, luego, haga clic en Ejecutar:
#standardSQL
SELECT
EXTRACT(HOUR
FROM
pickup_datetime) hour,
ROUND(AVG(trip_distance / TIMESTAMP_DIFF(dropoff_datetime,
pickup_datetime,
SECOND))*3600, 1) speed
FROM
`bigquery-public-data.new_york.tlc_yellow_trips_2015`
WHERE
trip_distance > 0
AND fare_amount/trip_distance BETWEEN 2
AND 10
AND dropoff_datetime > pickup_datetime
GROUP BY
1
ORDER BY
1
Este es el resultado:
Durante el día, la velocidad promedio es de aproximadamente 11 a 12 mph; pero, a las 5:00 a.m., la velocidad promedio casi se duplica a 21 mph. Por intuición, esto tiene sentido, ya que probablemente haya menos tráfico en la carretera a las 5 a.m.
Identifique un objetivo
Ahora creará un modelo de aprendizaje automático en BigQuery para predecir el precio de un viaje en taxi en la ciudad de Nueva York basándose en el conjunto de datos históricos y los datos de viajes. Predecir la tarifa antes de acceder al servicio puede resultar muy útil para la planificación de viajes, tanto para el pasajero como para la agencia de taxis.
Seleccione atributos y cree su conjunto de datos de entrenamiento
El conjunto de datos de taxis amarillos de la ciudad de Nueva York es un conjunto de datos públicos que proporciona la ciudad y que se cargó en BigQuery para que realice análisis. Explore la lista completa de campos aquí y, luego, obtenga una vista previa del conjunto de datos en busca de atributos útiles que ayudarán a que un modelo de aprendizaje automático comprenda la relación entre los datos sobre viajes históricos en taxi y el precio de la tarifa.
Su equipo decide probar si estos campos representan buenas entradas para su modelo de previsión de tarifas:
Importe de peaje
Importe de tarifa
Hora del día
Dirección de partida
Dirección de destino
Cantidad de pasajeros
Reemplace la consulta por los siguientes valores:
#standardSQL
WITH params AS (
SELECT
1 AS TRAIN,
2 AS EVAL
),
daynames AS
(SELECT ['Sun', 'Mon', 'Tues', 'Wed', 'Thurs', 'Fri', 'Sat'] AS daysofweek),
taxitrips AS (
SELECT
(tolls_amount + fare_amount) AS total_fare,
daysofweek[ORDINAL(EXTRACT(DAYOFWEEK FROM pickup_datetime))] AS dayofweek,
EXTRACT(HOUR FROM pickup_datetime) AS hourofday,
pickup_longitude AS pickuplon,
pickup_latitude AS pickuplat,
dropoff_longitude AS dropofflon,
dropoff_latitude AS dropofflat,
passenger_count AS passengers
FROM
`nyc-tlc.yellow.trips`, daynames, params
WHERE
trip_distance > 0 AND fare_amount > 0
AND MOD(ABS(FARM_FINGERPRINT(CAST(pickup_datetime AS STRING))),1000) = params.TRAIN
)
SELECT *
FROM taxitrips
Observe algunos puntos sobre la consulta:
La parte principal de la consulta se encuentra en la parte inferior: (SELECT * from taxitrips).
taxitrips hace la mayor parte de la extracción del conjunto de datos de NYC. La variable SELECT contiene su etiqueta y atributos de entrenamiento.
La variable WHERE quita los datos sobre los que no desea entrenar.
WHERE también incluye una cláusula de muestra para seleccionar solo 1/1,000 de los datos.
Definimos una variable llamada TRAIN a fin de compilar un conjunto independiente EVAL rápidamente.
Luego, haga clic en Ejecutar.
Resultados de muestra:
¿Cuál es la etiqueta (respuesta correcta)?
total_fare es la etiqueta (lo que predeciremos). Usted creó este campo a partir de tolls_amount y fare_amount, por lo que puede ignorar las propinas de los clientes como parte del modelo, ya que estas son a discreción.
Cree un conjunto de datos de BigQuery para almacenar modelos
A continuación, cree un nuevo conjunto de datos de BigQuery que también almacenará sus modelos de AA.
En el panel izquierdo, haga clic en el nombre de su proyecto y, luego, en Crear conjunto de datos.
En el diálogo Crear conjunto de datos, realice lo siguiente:
En ID de conjunto de datos, escriba taxi.
Deje los demás valores en su configuración predeterminada.
Haga clic en Crear conjunto de datos.
Seleccione un tipo de modelo de BQML y especifique las opciones
Ahora que ya seleccionó sus atributos iniciales, está listo para crear su primer modelo de AA en BigQuery.
Hay dos tipos de modelos para elegir:
Modelo
Tipo de modelo
Tipo de datos de etiqueta
Ejemplo
Previsión
linear_reg
Valor numérico (generalmente un número entero o punto flotante)
Previsión de cifras de ventas para el próximo año según los datos históricos de ventas
Clasificación
logistic_reg
0 o 1 para clasificación binaria
Clasificación de un correo electrónico como spam o no spam según el contexto
Clasificación multiclase
logistic_reg
Estos modelos pueden usarse para predecir varios valores posibles; por ejemplo, si una entrada tiene un valor bajo, medio o alto. Las etiquetas pueden tener hasta 50 valores únicos.
Clasificación de un correo electrónico como spam, de prioridad normal o de importancia alta
Nota: Existen muchos tipos de modelos adicionales que se usan en el aprendizaje automático (como las redes neuronales y los árboles de decisión) y que están disponibles en bibliotecas como TensorFlow. En este momento, BQML es compatible con los dos modelos mencionados anteriormente.
¿Qué tipo de modelo debería elegir? Dado que está prediciendo un valor numérico (tarifa de taxi), debe usar regresión lineal.
Ingrese la siguiente consulta para crear un modelo y especificar opciones del modelo. Para ello, reemplace -- paste the previous training dataset query here por la consulta de conjuntos de datos de entrenamiento que creó anteriormente (omita la línea #standardSQL):
CREATE or REPLACE MODEL taxi.taxifare_model
OPTIONS
(model_type='linear_reg', labels=['total_fare']) AS
-- paste the previous training dataset query here
Luego, haga clic en Ejecutar para entrenar su modelo.
Espere a que el modelo se entrene (de 5 a 10 minutos).
Luego del entrenamiento del modelo, verá el resultado This statement created a new model named <Project-ID>:taxi.taxifare_model, lo que indica que su modelo se entrenó correctamente.
Revise su conjunto de datos de taxis y confirme que ahora aparece taxifare_model.
A continuación, evaluará el rendimiento del modelo en comparación con nuevos datos de evaluación no vistos.
Evalúe el rendimiento del modelo de clasificación
Seleccione sus criterios de rendimiento
Para los modelos de regresión lineal, debe usar una métrica de pérdidas como raíz cuadrada del error cuadrático medio. Debe continuar entrenando y mejorando el modelo hasta que tenga la RMSE más bajo.
En BQML, mean_squared_error es simplemente un campo para consultas cuando se evalúa su modelo entrenado de AA. Simplemente agregue un SQRT() para obtener la RMSE.
Ahora que el entrenamiento se completó, puede evaluar qué tan bien se desempeña el modelo con esta consulta mediante ML.EVALUATE:
#standardSQL
SELECT
SQRT(mean_squared_error) AS rmse
FROM
ML.EVALUATE(MODEL taxi.taxifare_model,
(
WITH params AS (
SELECT
1 AS TRAIN,
2 AS EVAL
),
daynames AS
(SELECT ['Sun', 'Mon', 'Tues', 'Wed', 'Thurs', 'Fri', 'Sat'] AS daysofweek),
taxitrips AS (
SELECT
(tolls_amount + fare_amount) AS total_fare,
daysofweek[ORDINAL(EXTRACT(DAYOFWEEK FROM pickup_datetime))] AS dayofweek,
EXTRACT(HOUR FROM pickup_datetime) AS hourofday,
pickup_longitude AS pickuplon,
pickup_latitude AS pickuplat,
dropoff_longitude AS dropofflon,
dropoff_latitude AS dropofflat,
passenger_count AS passengers
FROM
`nyc-tlc.yellow.trips`, daynames, params
WHERE
trip_distance > 0 AND fare_amount > 0
AND MOD(ABS(FARM_FINGERPRINT(CAST(pickup_datetime AS STRING))),1000) = params.EVAL
)
SELECT *
FROM taxitrips
))
Ahora está evaluando el modelo con un conjunto distinto de viajes de taxi con su filtro params.EVAL.
Después de que el modelo se ejecute, revise los resultados (el valor de la RMSE de su modelo variará ligeramente).
Fila
RMSE
1
9.477056435999074
Luego de evaluar su modelo, obtiene una RMSE de USD 9.47. Conocer si esta métrica de pérdidas es aceptable o no a fin de llevar su modelo a producción depende totalmente de sus criterios de comparativas, que se configuran antes del comienzo del entrenamiento de modelos. Las comparativas implican establecer un nivel mínimo de exactitud y rendimiento aceptable.
Compare la pérdida de entrenamiento y de evaluación
Debe asegurarse de no sobreajustar su modelo a sus datos. Si lo hace, el rendimiento de su modelo será peor con los datos nuevos no vistos. Puede comparar la pérdida de entrenamiento con la pérdida de evaluación si utiliza ML.TRAINING_INFO.
SELECT * FROM ML.TRAINING_INFO(model `taxi.taxifare_model`);
De este modo, se seleccionará toda la información de cada iteración del entrenamiento del modelo. Incluirá el número de iteración del entrenamiento, la pérdida de entrenamiento y la pérdida de evaluación.
Para comparar la pérdida de entrenamiento y de evaluación, exploremos la diferencia en las curvas de pérdida de manera visual. Haga clic en EXPLORAR DATOS > Explorar con Data Studio en Cloud Console de BigQuery. Luego, se abrirá Data Studio con los datos de su consulta conectados como fuente de entrada.
Cuando se le solicite, seleccione el botón GET STARTED.
Seleccione AUTHORIZE cuando se le pregunte si Google Data Studio puede acceder a sus datos.
Nota: Si aparece el mensaje Oops… Not able to connect to your data, haga clic en Back. Haga clic en Save en el Explorador de Data Studio.
Haga clic en GET STARTED y acepte las Condiciones del Servicio. Haga clic en Accept.
Seleccione No, thanks en todas las preferencias y haga clic en Done.
Actualice la pestaña para cargar los datos.
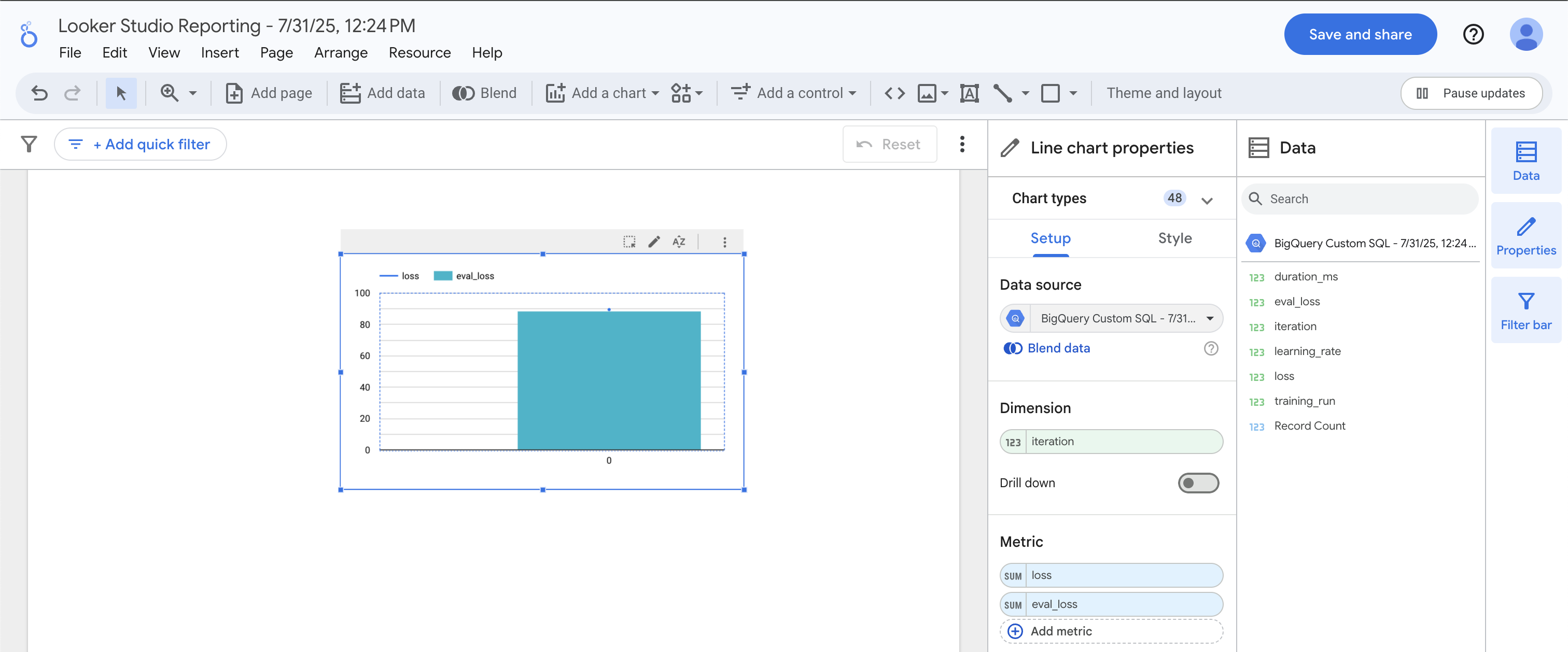
En Data Studio, haga clic en el ícono de Combo Chart.
En Dimension, arrastre iteration. En Metric, arrastre loss y eval_loss. Debería obtener un gráfico que incluye un gráfico de líneas superpuesto sobre un gráfico de barras.
La pérdida de entrenamiento coincide casi exactamente con la pérdida de evaluación, lo cual indica que no estamos sobreajustando el modelo. ¡Excelente! Pasemos a la predicción.
Prediga el importe de las tarifas de taxis
A continuación, escribirá una consulta para usar su nuevo modelo a fin de hacer predicciones:
#standardSQL
SELECT
*
FROM
ml.PREDICT(MODEL `taxi.taxifare_model`,
(
WITH params AS (
SELECT
1 AS TRAIN,
2 AS EVAL
),
daynames AS
(SELECT ['Sun', 'Mon', 'Tues', 'Wed', 'Thurs', 'Fri', 'Sat'] AS daysofweek),
taxitrips AS (
SELECT
(tolls_amount + fare_amount) AS total_fare,
daysofweek[ORDINAL(EXTRACT(DAYOFWEEK FROM pickup_datetime))] AS dayofweek,
EXTRACT(HOUR FROM pickup_datetime) AS hourofday,
pickup_longitude AS pickuplon,
pickup_latitude AS pickuplat,
dropoff_longitude AS dropofflon,
dropoff_latitude AS dropofflat,
passenger_count AS passengers
FROM
`nyc-tlc.yellow.trips`, daynames, params
WHERE
trip_distance > 0 AND fare_amount > 0
AND MOD(ABS(FARM_FINGERPRINT(CAST(pickup_datetime AS STRING))),1000) = params.EVAL
)
SELECT *
FROM taxitrips
));
Ahora verá las predicciones del modelo para tarifas de taxi junto con las tarifas reales y otros atributos de esos viajes.
Información adicional
Sugerencia: Agregue warm_start = true a las opciones de su modelo si vuelve a entrenar datos nuevos en un modelo existente para lograr tiempos de entrenamiento más rápidos. Tenga en cuenta que no puede cambiar las columnas de atributos (esto requeriría un nuevo modelo).
Otros conjuntos de datos para explorar
Puede usar el siguiente vínculo para incorporar el proyecto bigquery-public-data si desea explorar la creación de modelos en otros conjuntos de datos como la previsión de tarifas para viajes de taxi en Chicago:
Compiló correctamente un modelo de AA en BigQuery para prever la tarifa de taxis de la ciudad de Nueva York.
Finalice su lab
Cuando haya completado el lab, haga clic en Finalizar lab. Google Cloud Skills Boost quitará los recursos que usó y limpiará la cuenta.
Tendrá la oportunidad de calificar su experiencia en el lab. Seleccione la cantidad de estrellas que corresponda, ingrese un comentario y haga clic en Enviar.
La cantidad de estrellas indica lo siguiente:
1 estrella = Muy insatisfecho
2 estrellas = Insatisfecho
3 estrellas = Neutral
4 estrellas = Satisfecho
5 estrellas = Muy satisfecho
Puede cerrar el cuadro de diálogo si no desea proporcionar comentarios.
Para enviar comentarios, sugerencias o correcciones, use la pestaña Asistencia.
Copyright 2026 Google LLC. Todos los derechos reservados. Google y el logotipo de Google son marcas de Google LLC. El resto de los nombres de productos y empresas pueden ser marcas de las respectivas empresas a las que están asociados.
Los labs crean un proyecto de Google Cloud y recursos por un tiempo determinado
.
Los labs tienen un límite de tiempo y no tienen la función de pausa. Si finalizas el lab, deberás reiniciarlo desde el principio.
En la parte superior izquierda de la pantalla, haz clic en Comenzar lab para empezar
Usa la navegación privada
Copia el nombre de usuario y la contraseña proporcionados para el lab
Haz clic en Abrir la consola en modo privado
Accede a la consola
Accede con tus credenciales del lab. Si usas otras credenciales, se generarán errores o se incurrirá en cargos.
Acepta las condiciones y omite la página de recursos de recuperación
No hagas clic en Finalizar lab, a menos que lo hayas terminado o quieras reiniciarlo, ya que se borrará tu trabajo y se quitará el proyecto
Este contenido no está disponible en este momento
Te enviaremos una notificación por correo electrónico cuando esté disponible
¡Genial!
Nos comunicaremos contigo por correo electrónico si está disponible
Un lab a la vez
Confirma para finalizar todos los labs existentes y comenzar este
Usa la navegación privada para ejecutar el lab
Usar una ventana de incógnito o de navegación privada es la mejor forma de ejecutar
este lab. Así evitarás cualquier conflicto entre tu cuenta personal
y la cuenta de estudiante, lo que podría generar cargos adicionales en
tu cuenta personal.
En este lab, explorará millones de viajes de taxis amarillos de la ciudad de Nueva York disponibles en un conjunto de datos públicos de BigQuery, creará un modelo de AA en BigQuery para predecir la tarifa y evaluará el rendimiento de su modelo para hacer predicciones.
Duración:
0 min de configuración
·
Acceso por 60 min
·
60 min para completar