概要
BigQuery は、Google が提供する低コスト、NoOps のフルマネージド分析データベースです。BigQuery では、インフラストラクチャを所有して管理したりデータベース管理者を置いたりすることなく、テラバイト単位の大規模なデータでクエリを実行できます。また、SQL が採用されており、従量課金制というメリットもあります。このような特長を活かし、有用な情報を得るためのデータ分析に専念できます。
ここでは、ecommerce データセットを使用します。このデータセットには、Google Merchandise Store に関する数百万件の Google アナリティクス レコードが含まれており、BigQuery に読み込まれています。このデータセットのコピーを使用して、フィールドや行からどのような分析情報が得られるのかを確認します。
このラボでは、パーティション分割データセットに対してクエリを実行するほか、独自のデータセット パーティションの作成によってクエリのパフォーマンスを高め、コストを削減します。
設定と要件
各ラボでは、新しい Google Cloud プロジェクトとリソースセットを一定時間無料で利用できます。
-
シークレット ウィンドウを使用して Google Skills にログインします。
-
ラボのアクセス時間(例: 1:15:00)に注意し、時間内に完了できるようにしてください。
一時停止機能はありません。必要な場合はやり直せますが、最初からになります。
-
準備ができたら、[ラボを開始] をクリックします。
-
ラボの認証情報(ユーザー名とパスワード)をメモしておきます。この情報は、Google Cloud コンソールにログインする際に使用します。
-
[Google コンソールを開く] をクリックします。
-
[別のアカウントを使用] をクリックし、このラボの認証情報をコピーしてプロンプトに貼り付けます。
他の認証情報を使用すると、エラーや料金が発生します。
-
利用規約に同意し、再設定用のリソースページをスキップします。
BigQuery コンソールを開く
- Google Cloud コンソールで、ナビゲーション メニュー > [BigQuery] を選択します。
[Cloud Console の BigQuery へようこそ] メッセージ ボックスが開きます。このメッセージ ボックスにはクイックスタート ガイドへのリンクと、UI の更新情報が表示されます。
- [完了] をクリックします。
タスク 1. 新しいデータセットを作成する
まず、テーブルを保存するためのデータセットを作成します。
- 左側のペインで、[エクスプローラ] セクションのプロジェクト名(
qwiklabs-gcp-... で始まる)の横にある「アクションを表示」アイコンをクリックした後、[データセットを作成] をクリックします。
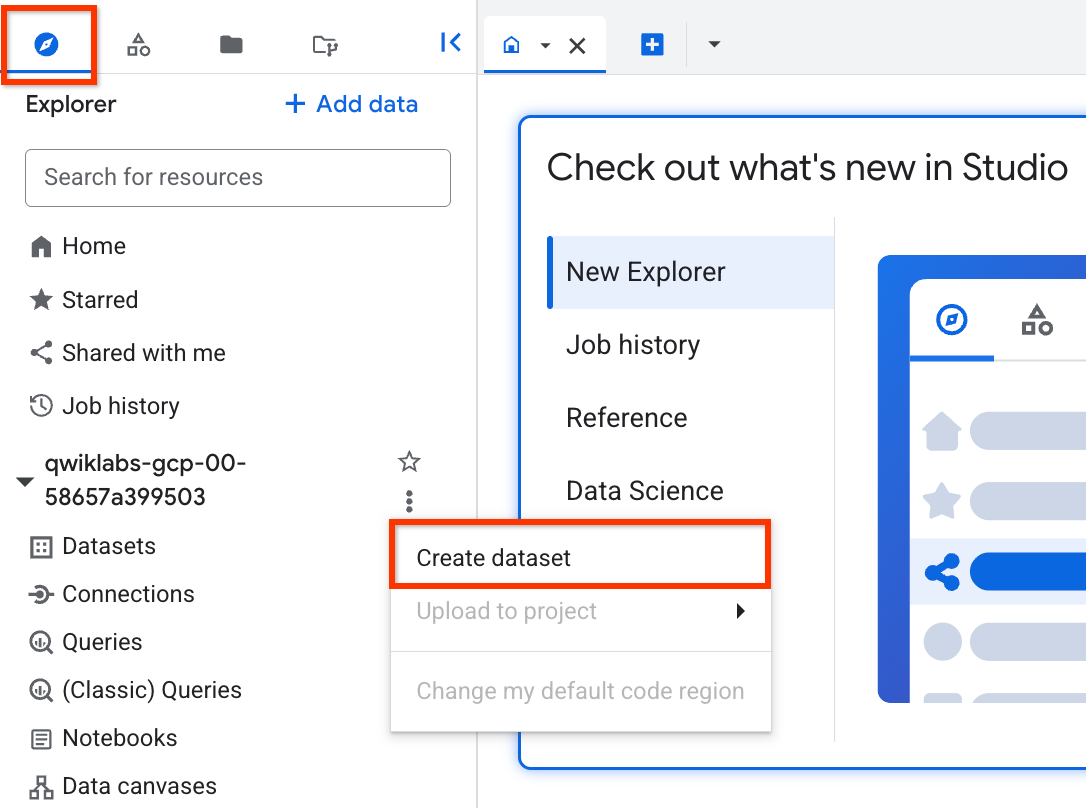
- [データセット ID] に「
ecommerce」と入力します。その他のオプションはデフォルト値のままにします([データのロケーション]、[デフォルトのテーブルの有効期限])。[データセットを作成] をクリックします。
タスク 2. 日付パーティションを持つテーブルを作成する
パーティション分割テーブルは、パーティションと呼ばれるセグメントに分割されたテーブルです。このテーブルを使用すると、データの管理や照会が簡単になります。大きなテーブルを小さなパーティションに分割することで、クエリのパフォーマンスを高めたり、クエリによって読み取られるバイト数を減らしてコストを抑えたりすることができます。
ここでは、新しいテーブルを作成し、日付またはタイムスタンプの列をパーティションとしてバインドします。その前に、分割されていないテーブルのデータを調べてみましょう。
ウェブページ分析データで 2017 年の訪問者のサンプルをクエリする
-
クエリエディタに以下のクエリを追加します。実行する前に、処理されるデータの総量を確認します。これは、クエリ バリデータ ツールのアイコンの横に「このクエリを実行すると、1.74 GB が処理されます」のように表示されます。
#standardSQL
SELECT DISTINCT
fullVisitorId,
date,
city,
pageTitle
FROM `data-to-insights.ecommerce.all_sessions_raw`
WHERE date = '20170708'
LIMIT 5
- [実行] をクリックします。
このクエリは 5 件の結果を返します。
ウェブページ分析データで 2018 年の訪問者のサンプルをクエリする
次に、このクエリを変更して 2018 年の訪問者を調べてみましょう。
-
クエリエディタに以下のクエリを追加します。
#standardSQL
SELECT DISTINCT
fullVisitorId,
date,
city,
pageTitle
FROM `data-to-insights.ecommerce.all_sessions_raw`
WHERE date = '20180708'
LIMIT 5
クエリ結果に処理されるデータの量が表示されます。
- [実行] をクリックします。
返される結果が 0 件でも、やはり 1.74 GB のデータが処理されているのが分かります。なぜでしょう。それは、クエリエンジンがデータセット内のすべてのレコードをスキャンして、WHERE 句の日付に一致しているかどうかを確認する必要があるためです。レコードの日付をひとつひとつ '20180708' という条件と比較しなければなりません。
なお、よく誤解されていますが、LIMIT 5 を指定しても処理されるデータの総量が減ることはありません。
日付パーティション分割テーブルの一般的なユースケース
行を WHERE 条件と比較するために毎回データセット全体をスキャンするのは、無駄の多い作業です。以下のように、特定の期間のレコードのみを対象とする場合は特に当てはまります。
- 昨年のすべてのトランザクション
- 過去 7 日間のすべてのユーザー インタラクション
- 先月販売したすべての商品
今度は、前のクエリのようにデータセット全体をスキャンして日付フィールドでフィルタする代わりに、日付パーティション分割テーブルを作成します。これにより、クエリに関係のないパーティションのレコードは一切スキャンする必要がなくなります。
日付に基づいた新しいパーティション分割テーブルを作成する
- [+](SQL クエリ)をクリックして、以下のクエリを追加して [実行] をクリックします。
#standardSQL
CREATE OR REPLACE TABLE ecommerce.partition_by_day
PARTITION BY date_formatted
OPTIONS(
description="a table partitioned by date"
) AS
SELECT DISTINCT
PARSE_DATE("%Y%m%d", date) AS date_formatted,
fullvisitorId
FROM `data-to-insights.ecommerce.all_sessions_raw`
このクエリには、PARTITION BY <フィールド> という新しいオプションがあります。パーティション分割に使用できるオプションは DATE と TIMESTAMP の 2 つです。ここでは、文字列として保存されている日付フィールドをパーティション分割に適した DATE 型に変換するために、PARSE_DATE 関数を使用しています。
-
ecommerce データセットをクリックし、新しい partiton_by_day テーブルを選択します。
- [詳細] タブをクリックします。
次のようになっていることを確認します。
- パーティション分割の基準: Day
- パーティション分割の場所: date_formatted
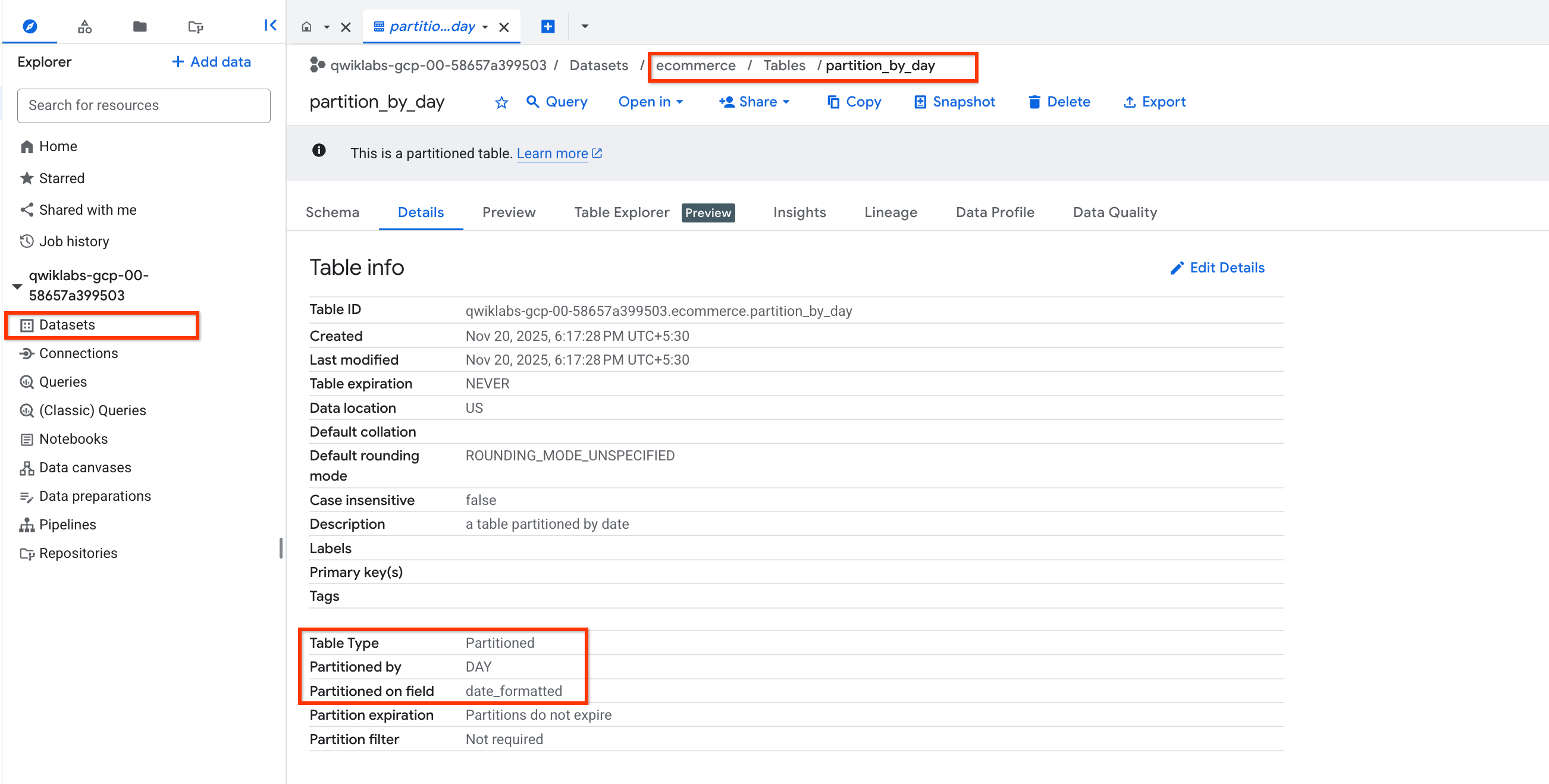
注: Qwiklabs アカウントのパーティション分割テーブル内のパーティションは、日付列の値から 60 日後に自動的に期限切れになります。課金を有効にした個人の GCP アカウントでは、期限切れにならないパーティション分割テーブルを作成できます。
このラボの以降のクエリは、すでに作成されているパーティション分割テーブルに対して実行します。
タスク 3. パーティション分割テーブルを使用して処理されたデータを表示する
- 以下のクエリを実行します。処理される合計バイト数を確認してください。
#standardSQL
SELECT *
FROM `data-to-insights.ecommerce.partition_by_day`
WHERE date_formatted = '2016-08-01'
処理されるバイト数が約 25 KB(0.025 MB)になりました。これは、前のクエリに比べるとごくわずかです。
- 次に、以下のクエリを実行します。処理される合計バイト数に注目してください。
#standardSQL
SELECT *
FROM `data-to-insights.ecommerce.partition_by_day`
WHERE date_formatted = '2018-07-08'
「このクエリを実行すると、0 B が処理されます」と表示されます。
処理されるバイト数が 0 バイトになるのはなぜでしょうか。
タスク 4. 自動的に期限切れになるパーティション分割テーブルを作成する
自動的に期限切れになるパーティション分割テーブルは、データ プライバシーに関する法令を遵守するために使用されます。ストレージの不必要な浪費を防ぐために使用することもできます(本番環境ではコストの節約になります)。データのローリング ウィンドウを作成するには、使い終わったパーティションが自動的に消去されるように有効期限を追加します。
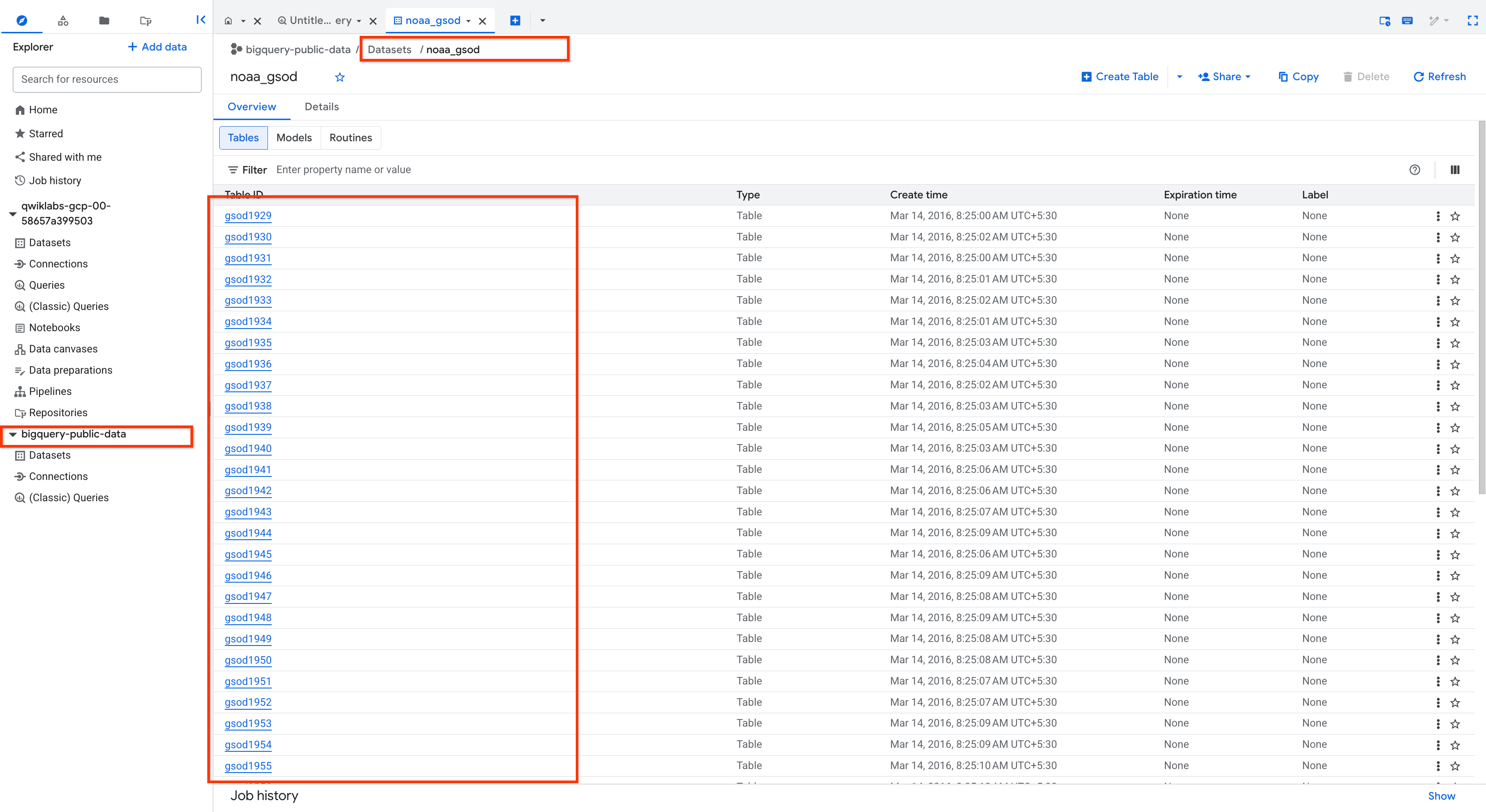
公開されている NOAA 気象データのテーブルを調べる
-
左側のメニューの [エクスプローラ] で [+ 追加] をクリックし、[名前を指定してプロジェクトにスターを付ける] > [プロジェクト名を入力] を選択します。
-
「bigquery-public-data」と入力して [スターを付ける] をクリックします。
-
bigquery-public-data を展開して、noaa_gsod を見つけます。
-
noaa_gsod データセットのテーブルのリストをスクロールします(手動でシャーディングされ、パーティション分割されていません)。
- まず、以下のクエリをクエリエディタにコピーして貼り付けます。
#standardSQL
SELECT
DATE(CAST(year AS INT64), CAST(mo AS INT64), CAST(da AS INT64)) AS date,
(SELECT ANY_VALUE(name) FROM `bigquery-public-data.noaa_gsod.stations` AS stations
WHERE stations.usaf = stn) AS station_name, -- 観測所は複数の名称を持つ場合がある
prcp
FROM `bigquery-public-data.noaa_gsod.gsod*` AS weather
WHERE prcp < 99.9 -- 不明な値を除去する
AND length(_TABLE_SUFFIX) = 4 AND CAST(_TABLE_SUFFIX AS int64) >= 2018
AND prcp > 0 -- 降水量のない観測所/日付を除去する
AND CAST(_TABLE_SUFFIX AS int64) >= 2018
ORDER BY date DESC -- 直近の降雨または降雪はどこか
LIMIT 10
TABLE_SUFFIX フィルタで参照されるテーブルの数を制限するために、FROM 句でテーブル ワイルドカード * が使用されています。
LIMIT 10 が追加されていますが、まだパーティションがないため、スキャンされるデータの総量(約 457.5 MB)は減りません。
-
[実行] をクリックします。
-
日付の形式が正しいこと、降水量フィールドの値が 0 でないことを確認します。
タスク 5. 実習: パーティション分割テーブルを作成する
クエリは次のようになります。
#standardSQL
CREATE OR REPLACE TABLE ecommerce.days_with_rain
PARTITION BY date
OPTIONS (
partition_expiration_days=60,
description="weather stations with precipitation, partitioned by day"
) AS
SELECT
DATE(CAST(year AS INT64), CAST(mo AS INT64), CAST(da AS INT64)) AS date,
(SELECT ANY_VALUE(name) FROM `bigquery-public-data.noaa_gsod.stations` AS stations
WHERE stations.usaf = stn) AS station_name, -- Stations may have multiple names
prcp
FROM `bigquery-public-data.noaa_gsod.gsod*` AS weather
WHERE prcp < 99.9 -- Filter unknown values
AND length(_TABLE_SUFFIX) = 4 AND CAST(_TABLE_SUFFIX AS int64) >= 2018
AND prcp > 0 -- Filter
AND CAST(_TABLE_SUFFIX AS int64) >= 2018
データ パーティションの有効期限が機能していることを確認する
- 60 日前より古いデータが保存されていないことを確認するために、DATE_DIFF クエリを実行してパーティションの経過日数を取得します。パーティションは 60 日後に期限切れになるように設定されています。
以下のクエリは、非常に降水量の多い和歌山市にある NOAA の気象観測所の平均降水量を追跡します。
- 次のクエリを追加して実行します。
#standardSQL
# 月の平均降水量
SELECT
AVG(prcp) AS average,
station_name,
date,
CURRENT_DATE() AS today,
DATE_DIFF(CURRENT_DATE(), date, DAY) AS partition_age,
EXTRACT(MONTH FROM date) AS month
FROM ecommerce.days_with_rain
WHERE station_name = 'WAKAYAMA' #日本
GROUP BY station_name, date, today, month, partition_age
ORDER BY date DESC; # 直近の日付順
タスク 6. partition_age が 60 日以下であることを確認する
-
ORDER BY 句を更新して、パーティションを古い順に表示します。
-
次のクエリを追加して実行します。
#standardSQL
# 月の平均降水量
SELECT
AVG(prcp) AS average,
station_name,
date,
CURRENT_DATE() AS today,
DATE_DIFF(CURRENT_DATE(), date, DAY) AS partition_age,
EXTRACT(MONTH FROM date) AS month
FROM ecommerce.days_with_rain
WHERE station_name = 'WAKAYAMA' #日本
GROUP BY station_name, date, today, month, partition_age
ORDER BY partition_age DESC
注: 気象データとパーティションは継続的に更新されるため、今後このクエリを再実行したときには結果は変わります。
お疲れさまでした
ここでは、BigQuery で分割テーブルを作成してクエリを実行しました。
ラボを終了する
ラボが完了したら、[ラボを終了] をクリックします。ラボで使用したリソースが Google Cloud Skills Boost から削除され、アカウントの情報も消去されます。
ラボの評価を求めるダイアログが表示されたら、星の数を選択してコメントを入力し、[送信] をクリックします。
星の数は、それぞれ次の評価を表します。
- 星 1 つ = 非常に不満
- 星 2 つ = 不満
- 星 3 つ = どちらともいえない
- 星 4 つ = 満足
- 星 5 つ = 非常に満足
フィードバックを送信しない場合は、ダイアログ ボックスを閉じてください。
フィードバックやご提案の送信、修正が必要な箇所をご報告いただく際は、[サポート] タブをご利用ください。
Copyright 2026 Google LLC All rights reserved. Google および Google のロゴは、Google LLC の商標です。その他すべての社名および製品名は、それぞれ該当する企業の商標である可能性があります。






