Mettez en pratique vos compétences dans la console Google Cloud
Instructions et exigences de configuration de l'atelier
Protégez votre compte et votre progression. Utilisez toujours une fenêtre de navigation privée et les identifiants de l'atelier pour exécuter cet atelier.
Créer des tables partitionnées par date dans BigQuery v1.5
Ce contenu n'est pas encore optimisé pour les appareils mobiles.
Pour une expérience optimale, veuillez accéder à notre site sur un ordinateur de bureau en utilisant un lien envoyé par e-mail.
Aperçu
BigQuery est la base de données d'analyse NoOps, économique et entièrement gérée de Google. Avec BigQuery, vous pouvez interroger plusieurs téraoctets de données sans avoir à gérer d'infrastructure ni faire appel à un administrateur de base de données. Basé sur le langage SQL et le modèle de paiement à l'usage, BigQuery vous permet de vous concentrer sur l'analyse des données pour en dégager des informations pertinentes.
Vous allez utiliser un ensemble de données d'e-commerce comprenant des millions d'enregistrements Google Analytics pour le Google Merchandise Store, chargé dans BigQuery. Pour cet atelier, vous disposez d'une copie de cet ensemble de données, et vous allez explorer les champs et les lignes qu'il contient afin d'obtenir des renseignements.
Dans cet atelier, vous allez interroger des ensembles de données partitionnés et créer vos propres partitions d'ensemble de données pour améliorer les performances des requêtes et réduire les coûts.
Préparation
Pour chaque atelier, nous vous attribuons un nouveau projet Google Cloud et un nouvel ensemble de ressources pour une durée déterminée, sans frais.
Connectez-vous à Google Skills dans une fenêtre de navigation privée.
Vérifiez le temps imparti pour l'atelier (par exemple : 01:15:00) : vous devez pouvoir le terminer dans ce délai.
Une fois l'atelier lancé, vous ne pourrez pas le mettre sur pause. Si nécessaire, vous pourrez le redémarrer, mais vous devrez tout reprendre depuis le début.
Lorsque vous êtes prêt, cliquez sur Démarrer l'atelier.
Notez vos identifiants pour l'atelier (Nom d'utilisateur et Mot de passe). Ils vous serviront à vous connecter à la console Google Cloud.
Cliquez sur Ouvrir la console Google.
Cliquez sur Utiliser un autre compte, puis copiez-collez les identifiants de cet atelier lorsque vous y êtes invité.
Si vous utilisez d'autres identifiants, des messages d'erreur s'afficheront ou des frais seront facturés.
Acceptez les conditions d'utilisation et ignorez la page concernant les ressources de récupération des données.
Ouvrir la console BigQuery
Dans la console Google Cloud, sélectionnez le menu de navigation > BigQuery.
Le message Bienvenue sur BigQuery dans la console Cloud s'affiche. Il contient un lien vers le guide de démarrage rapide et liste les mises à jour de l'interface utilisateur.
Cliquez sur Done (OK).
Tâche 1 : Créer un ensemble de données
Commencez par créer un ensemble de données dans lequel stocker vos tables.
Dans le volet de gauche, dans la section Explorateur, cliquez sur l'icône Afficher les actions à côté du nom de votre projet (qui commence par qwiklabs-gcp-...), puis sur CRÉER UN ENSEMBLE DE DONNÉES.
Définissez le champ ID de l'ensemble de données sur ecommerce. Laissez les valeurs par défaut des autres options, "Emplacement des données" et "Expiration de la table par défaut". Cliquez sur CRÉER UN ENSEMBLE DE DONNÉES.
Tâche 2 : Créer des tables partitionnées par date
Une table partitionnée est une table divisée en segments, appelés partitions, qui facilitent la gestion et l'interrogation des données. Diviser une grande table en partitions plus petites permet d'améliorer les performances des requêtes et de maîtriser les coûts en réduisant le nombre d'octets traités par une requête.
Vous allez maintenant créer une table et lui associer une colonne de date ou d'horodatage en tant que partition. Auparavant, examinons les données de la table non partitionnée.
Interroger des données analytiques de page Web pour un échantillon de visiteurs en 2017
Dans l'éditeur de requête, ajoutez la requête ci-dessous. Avant de l'exécuter, notez la quantité totale de données à traiter, comme indiqué à côté de l'icône de l'outil de validation des requêtes : "This query will process 1.74 GB when run" (Cette requête traitera 1,74 Go lors de son exécution).
#standardSQL
SELECT DISTINCT
fullVisitorId,
date,
city,
pageTitle
FROM `data-to-insights.ecommerce.all_sessions_raw`
WHERE date = '20170708'
LIMIT 5
Cliquez sur EXÉCUTER.
La requête renvoie cinq résultats.
Interroger des données analytiques de page Web pour un échantillon de visiteurs en 2018
Modifions à présent la requête pour qu'elle s'intéresse aux visiteurs en 2018.
Dans l'éditeur de requête, ajoutez la requête ci-dessous :
#standardSQL
SELECT DISTINCT
fullVisitorId,
date,
city,
pageTitle
FROM `data-to-insights.ecommerce.all_sessions_raw`
WHERE date = '20180708'
LIMIT 5
Les résultats de la requête vous indiquent la quantité de données qui sera traitée par cette requête.
Cliquez sur EXÉCUTER.
Notez que la requête traite toujours 1,74 Go de données, même si elle ne renvoie aucun résultat. Pourquoi ? Le moteur de requêtes doit analyser tous les enregistrements de l'ensemble de données pour vérifier s'ils respectent la condition de correspondance de date dans la clause WHERE. Il doit examiner chaque enregistrement afin de comparer sa date à la condition "20180708".
De plus, contrairement à l'idée reçue, la clause LIMIT 5 (Limite 5) ne réduit pas la quantité totale de données traitée.
Cas d'utilisation courants des tables partitionnées par date
L'analyse systématique de l'ensemble de données complet afin de comparer les lignes à une condition WHERE est inefficace, surtout si seuls les enregistrements concernant une période spécifique vous intéressent, par exemple :
toutes les transactions de l'année passée ;
toutes les interactions des visiteurs au cours des sept derniers jours ;
tous les produits vendus au cours du mois écoulé.
Au lieu d'analyser l'ensemble de données complet et de le filtrer selon un champ de date comme pour les requêtes précédentes, nous allons à présent configurer une table partitionnée par date. Cela permettra d'ignorer complètement les enregistrements de certaines partitions s'ils sont sans rapport avec la requête.
Créer une table partitionnée en fonction de la date
Cliquez sur "+" (Requête SQL), puis ajoutez la requête ci-dessous et cliquez sur EXÉCUTER :
#standardSQL
CREATE OR REPLACE TABLE ecommerce.partition_by_day
PARTITION BY date_formatted
OPTIONS(
description="a table partitioned by date"
) AS
SELECT DISTINCT
PARSE_DATE("%Y%m%d", date) AS date_formatted,
fullvisitorId
FROM `data-to-insights.ecommerce.all_sessions_raw`
Dans cette requête, notez la nouvelle option - PARTITION BY (Partitionner par) suivie d'un champ. Les deux options de partition disponibles sont DATE et TIMESTAMP (Horodatage). La fonction PARSE_DATE est utilisée pour le champ de date (stocké en tant que chaîne) pour l'associer au type de DATE correct en vue du partitionnement.
Cliquez sur l'ensemble de données ecommerce, puis sélectionnez la nouvelle table partition_by_day (partition_par_jour) :
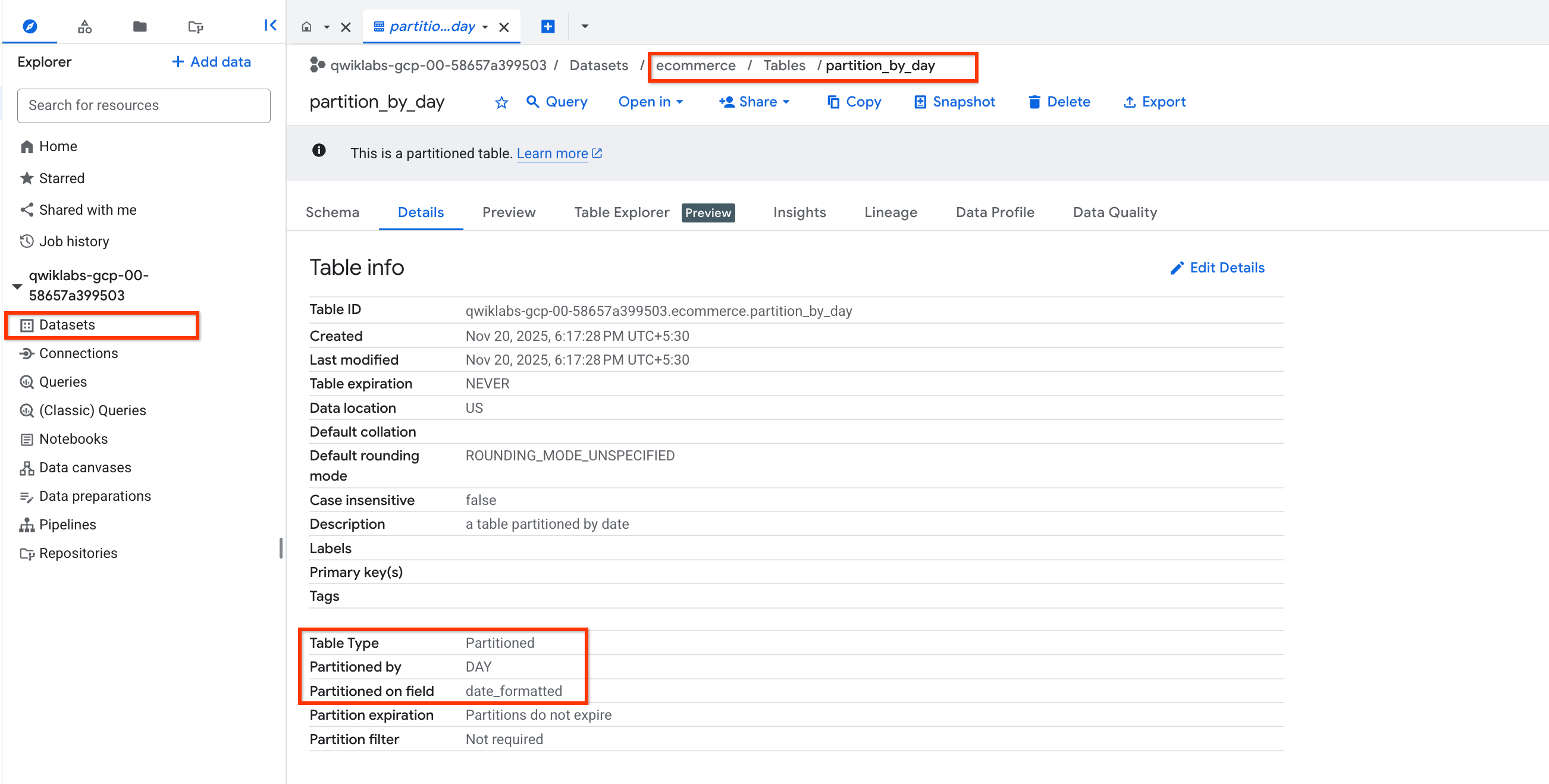
Cliquez sur l'onglet Détails.
Vérifiez que les données suivantes apparaissent :
Partitionnée par : jour
Partitioning on: date_formatted (Partitionnement le : date_formatée)
Remarque : Les partitions au sein des tables partitionnées liées à votre compte Qwiklabs expireront automatiquement au bout de 60 jours à compter de la valeur indiquée dans votre colonne de date. Les tables partitionnées que vous créerez avec votre compte GCP personnel avec facturation activée n'expireront pas.
Dans le cadre de cet atelier, les requêtes restantes seront exécutées sur des tables partitionnées qui ont déjà été créées.
Tâche 3 : Afficher les données traitées à l'aide d'une table partitionnée
Exécutez la requête suivante, et notez la quantité totale d'octets à traiter :
#standardSQL
SELECT *
FROM `data-to-insights.ecommerce.partition_by_day`
WHERE date_formatted = '2016-08-01'
Cette fois, environ 25 Ko ou 0,025 Mo sont traités, ce qui représente une petite fraction de la quantité de données analysée par la requête précédente.
À présent, exécutez la requête suivante, et notez la quantité totale d'octets à traiter :
#standardSQL
SELECT *
FROM `data-to-insights.ecommerce.partition_by_day`
WHERE date_formatted = '2018-07-08'
Le message suivant doit s'afficher : This query will process 0 B when run (Cette requête traitera 0 octet lors de son exécution).
Pourquoi la quantité d'octets traitée est-elle nulle ?
Tâche 4 : Créer une table partitionnée à expiration automatique
Les tables partitionnées à expiration automatique sont utilisées pour assurer la conformité avec les règles de confidentialité des données. Elles permettent aussi d'éviter tout stockage superflu (facturé dans un environnement de production). Si vous souhaitez créer une période glissante de données, ajoutez une date d'expiration pour que la partition disparaisse une fois que vous avez fini de l'utiliser.
Explorer les tables de données météorologiques mises à disposition par l'Agence américaine d'observation océanique et atmosphérique (NOAA)
Dans le menu de gauche, sous Explorateur, cliquez sur + AJOUTER, puis sélectionnez Ajouter un projet aux favoris en saisissant son nom et saisissez le nom du projet.
Saisissez bigquery-public-data et cliquez sur Ajouter aux favoris.
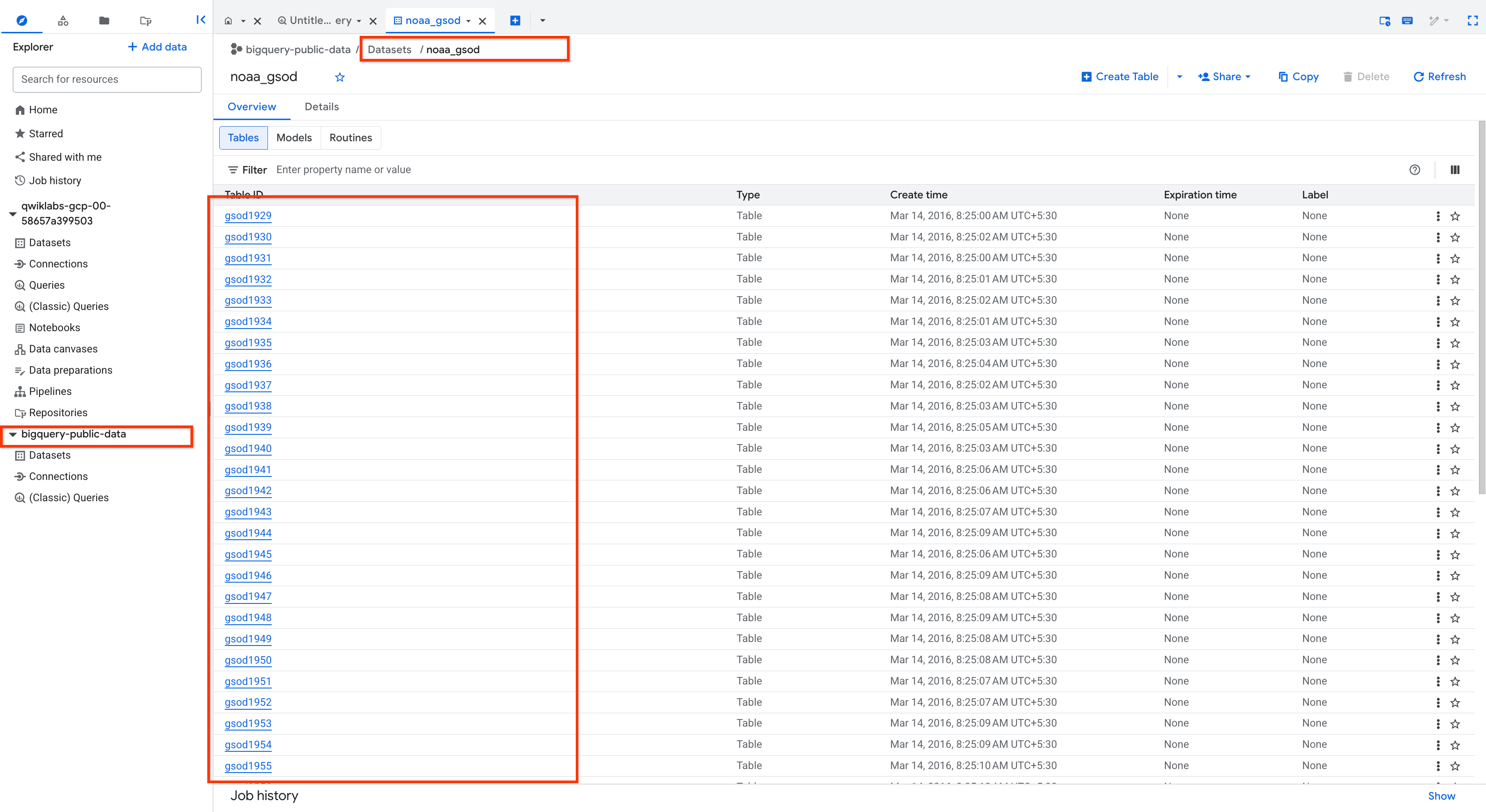
Développez bigquery-public-data et recherchez noaa_gsod.
Faites défiler les tables dans l'ensemble de données noaa_gsod (elles sont segmentées manuellement et non partitionnées).
Tout d'abord, copiez et collez la requête ci-dessous dans l'éditeur de requête :
#standardSQL
SELECT
DATE(CAST(year AS INT64), CAST(mo AS INT64), CAST(da AS INT64)) AS date,
(SELECT ANY_VALUE(name) FROM `bigquery-public-data.noaa_gsod.stations` AS stations
WHERE stations.usaf = stn) AS station_name, -- Stations may have multiple names
prcp
FROM `bigquery-public-data.noaa_gsod.gsod*` AS weather
WHERE prcp < 99.9 -- Filter unknown values
AND length(_TABLE_SUFFIX) = 4 AND CAST(_TABLE_SUFFIX AS int64) >= 2018
AND prcp > 0 -- Filter stations/days with no precipitation
AND CAST(_TABLE_SUFFIX AS int64) >= 2018
ORDER BY date DESC -- Where has it rained/snowed recently
LIMIT 10
Notez que le caractère générique de table * est utilisé dans la clause FROM (À partir de) pour limiter la quantité de tables traitées par le filtre TABLE_SUFFIX.
Notez que bien qu'une clause LIMIT 10 (Limite 10) ait été ajoutée, la quantité totale de données analysées reste la même (environ 457,5 Mo) étant donné qu'aucune partition n'a encore été créée.
Cliquez sur EXÉCUTER.
Vérifiez que le format de date est correct et que le champ des précipitations indique des valeurs non nulles.
Tâche 5 : À vous de créer une table partitionnée
Modifiez la requête précédente afin de créer une table correspondant aux spécifications ci-dessous :
Nom de la table : ecommerce.days_with_rain
Utilisez le champ de date comme clause PARTITION BY
Pour OPTIONS, spécifiez partition_expiration_days = 60
Ajoutez la description de la table = "weather stations with precipitation, partitioned by day"
Votre requête doit se présenter comme suit :
#standardSQL
CREATE OR REPLACE TABLE ecommerce.days_with_rain
PARTITION BY date
OPTIONS (
partition_expiration_days=60,
description="weather stations with precipitation, partitioned by day"
) AS
SELECT
DATE(CAST(year AS INT64), CAST(mo AS INT64), CAST(da AS INT64)) AS date,
(SELECT ANY_VALUE(name) FROM `bigquery-public-data.noaa_gsod.stations` AS stations
WHERE stations.usaf = stn) AS station_name, -- Stations may have multiple names
prcp
FROM `bigquery-public-data.noaa_gsod.gsod*` AS weather
WHERE prcp < 99.9 -- Filter unknown values
AND length(_TABLE_SUFFIX) = 4 AND CAST(_TABLE_SUFFIX AS int64) >= 2018
AND prcp > 0 -- Filter
AND CAST(_TABLE_SUFFIX AS int64) >= 2018
Vérifier que l'expiration de la partition de données fonctionne
Pour vérifier que vous ne stockez que des données datant de 60 jours ou moins, exécutez la requête DATE_DIFF pour obtenir l'âge de vos partitions, qui sont configurées pour expirer au bout de 60 jours.
Voici une requête qui enregistre les précipitations moyennes pour la station météorologique de la NOAA à Wakayama, au Japon, connue pour ses précipitations abondantes.
Ajoutez cette requête, puis exécutez-la :
#standardSQL
# avg monthly precipitation
SELECT
AVG(prcp) AS average,
station_name,
date,
CURRENT_DATE() AS today,
DATE_DIFF(CURRENT_DATE(), date, DAY) AS partition_age,
EXTRACT(MONTH FROM date) AS month
FROM ecommerce.days_with_rain
WHERE station_name = 'WAKAYAMA' #Japan
GROUP BY station_name, date, today, month, partition_age
ORDER BY date DESC; # most recent days first
Tâche 6 : Vérifier que la partition la plus ancienne (partition_age) date de 60 jours ou moins
Mettez à jour la clause ORDER BY (Classer par) pour afficher les partitions les plus anciennes en premier.
Ajoutez cette requête, puis exécutez-la :
#standardSQL
# avg monthly precipitation
SELECT
AVG(prcp) AS average,
station_name,
date,
CURRENT_DATE() AS today,
DATE_DIFF(CURRENT_DATE(), date, DAY) AS partition_age,
EXTRACT(MONTH FROM date) AS month
FROM ecommerce.days_with_rain
WHERE station_name = 'WAKAYAMA' #Japan
GROUP BY station_name, date, today, month, partition_age
ORDER BY partition_age DESC
Remarque : Vos résultats varieront si vous réexécutez la requête ultérieurement, puisque les données météorologiques, ainsi que vos partitions, sont mises à jour en permanence.
Félicitations !
Vous avez créé et interrogé des tables partitionnées dans BigQuery.
Terminer l'atelier
Une fois l'atelier terminé, cliquez sur Terminer l'atelier. Google Cloud Skills Boost supprime les ressources que vous avez utilisées, puis efface le compte.
Si vous le souhaitez, vous pouvez noter l'atelier. Sélectionnez un nombre d'étoiles, saisissez un commentaire, puis cliquez sur Envoyer.
Le nombre d'étoiles correspond à votre degré de satisfaction :
1 étoile = très insatisfait(e)
2 étoiles = insatisfait(e)
3 étoiles = ni insatisfait(e), ni satisfait(e)
4 étoiles = satisfait(e)
5 étoiles = très satisfait(e)
Si vous ne souhaitez pas donner votre avis, vous pouvez fermer la boîte de dialogue.
Pour soumettre des commentaires, suggestions ou corrections, veuillez accéder à l'onglet Assistance.
Copyright 2026 Google LLC Tous droits réservés. Google et le logo Google sont des marques de Google LLC. Tous les autres noms de société et de produit peuvent être des marques des sociétés auxquelles ils sont associés.
Les ateliers créent un projet Google Cloud et des ressources pour une durée déterminée.
Les ateliers doivent être effectués dans le délai imparti et ne peuvent pas être mis en pause. Si vous quittez l'atelier, vous devrez le recommencer depuis le début.
En haut à gauche de l'écran, cliquez sur Démarrer l'atelier pour commencer.
Utilisez la navigation privée
Copiez le nom d'utilisateur et le mot de passe fournis pour l'atelier
Cliquez sur Ouvrir la console en navigation privée
Connectez-vous à la console
Connectez-vous à l'aide des identifiants qui vous ont été attribués pour l'atelier. L'utilisation d'autres identifiants peut entraîner des erreurs ou des frais.
Acceptez les conditions d'utilisation et ignorez la page concernant les ressources de récupération des données.
Ne cliquez pas sur Terminer l'atelier, à moins que vous n'ayez terminé l'atelier ou que vous ne vouliez le recommencer, car cela effacera votre travail et supprimera le projet.
Ce contenu n'est pas disponible pour le moment
Nous vous préviendrons par e-mail lorsqu'il sera disponible
Parfait !
Nous vous contacterons par e-mail s'il devient disponible
Un atelier à la fois
Confirmez pour mettre fin à tous les ateliers existants et démarrer celui-ci
Utilisez la navigation privée pour effectuer l'atelier
Le meilleur moyen d'exécuter cet atelier consiste à utiliser une fenêtre de navigation privée. Vous éviterez ainsi les conflits entre votre compte personnel et le compte temporaire de participant, qui pourraient entraîner des frais supplémentaires facturés sur votre compte personnel.
Cet atelier explique comment interroger des ensembles de données partitionnés et créer vos propres partitions d'ensemble de données pour améliorer les performances des requêtes, et réduire ainsi les coûts.
Durée :
0 min de configuration
·
Accessible pendant 90 min
·
Terminé après 60 min