![Compute Engine のデフォルトのサービス アカウント名と編集者のステータスがハイライト表示された [権限] タブページ](https://cdn.qwiklabs.com/1nytD9OUuNUV9undyjUWeOS7LJmekReBDmkUjveCjcU%3D)
![all-sessions_raw_dataprep-2 dataset のサンプルを読み込んだ [Transformer] ビュー](https://cdn.qwiklabs.com/XvknvNGV4DFB2vDqo%2BhlqURR%2BC5zNvsA2pE7lfw1Cec%3D)
![all-sessions_raw_dataprep-2 dataset のサンプルを読み込んだ [Transformer] ビュー](https://cdn.qwiklabs.com/9L1l%2FNknuj40nXW1EGNMVz%2FWr%2BplV4anLgNWJfZvHj4%3D)
![[Column Details] オプション](https://cdn.qwiklabs.com/Gddqosl4E0xkae7pSJSI2kePjp%2BV9J7RoAgyg3gyru4%3D)
![timeOnSite 列の [概要] タブ](https://cdn.qwiklabs.com/OQeZsCroQLukI8sQgySErq4zDIWQ94XFuHMAjo5V24g%3D)
![メニューの [String] オプション](https://cdn.qwiklabs.com/m%2FnSrZIMLfP9NOEimu9Svqmgajog6U2c9zfLH%2FuK%2Fs4%3D)
![transactionID の詳細を表示した [概要] タブ](https://cdn.qwiklabs.com/HRA3rYFBI7c%2BgiT4j87W8qD%2BzMkXpdDzCfNwrtz9f6Q%3D)
![[Delete rows] オプションが選択されている状態の [Suggestions] パネル](https://cdn.qwiklabs.com/mNDpRfHOA8BomAEY1QYHj3waBulnEZk7%2BSyq0vN%2BGG0%3D)
![一致した行を保持したままで v2ProductCategory 列内の「Apparel」を含む行を取得するようフィルタを適用した [Filter rows] パネル](https://cdn.qwiklabs.com/ohup2bmk4ksUUS49y2ygHEUYnGD9I70JZVMUh5EaDYA%3D)
![[Preview] タブに表示されているクエリ結果](https://cdn.qwiklabs.com/mLqGzoZF790G2E%2Fb0C0%2F9Q%2B7LVZmgDfL9MNccmpw86g%3D)

始める前に
- ラボでは、Google Cloud プロジェクトとリソースを一定の時間利用します
- ラボには時間制限があり、一時停止機能はありません。ラボを終了した場合は、最初からやり直す必要があります。
- 画面左上の [ラボを開始] をクリックして開始します
Cloud Dataprep by Trifacta は、分析を目的として、データの視覚的な探索、クリーニング、準備を行うためのインテリジェント データ サービスで、構造化データと非構造化データの両方に対応しています。このラボでは、Cloud Dataprep の UI を実際に使用して、定期的に実行されて結果が BigQuery に出力される e コマース用の変換パイプラインを作成します。
ここで使用する e コマースのデータセットは、Google Merchandise Store に関する数百万件の Google アナリティクスのレコードを含み、BigQuery に読み込まれています。このラボでは、このデータセットのコピーを使用し、利用できるフィールドや行を詳しく確認して分析情報を取得します。
このラボでは、次のタスクの実行方法について学びます。
各ラボでは、新しい Google Cloud プロジェクトとリソースセットを一定時間無料で利用できます。
Qwiklabs にシークレット ウィンドウでログインします。
ラボのアクセス時間(例: 1:15:00)に注意し、時間内に完了できるようにしてください。
一時停止機能はありません。必要な場合はやり直せますが、最初からになります。
準備ができたら、[ラボを開始] をクリックします。
ラボの認証情報(ユーザー名とパスワード)をメモしておきます。この情報は、Google Cloud Console にログインする際に使用します。
[Google Console を開く] をクリックします。
[別のアカウントを使用] をクリックし、このラボの認証情報をコピーしてプロンプトに貼り付けます。
他の認証情報を使用すると、エラーが発生したり、料金の請求が発生したりします。
利用規約に同意し、再設定用のリソースページをスキップします。
Google Cloud で作業を開始する前に、Identity and Access Management(IAM)内で適切な権限がプロジェクトに付与されていることを確認する必要があります。
Google Cloud コンソールのナビゲーション メニュー(
Compute Engine のデフォルトのサービス アカウント {project-number}-compute@developer.gserviceaccount.com が存在し、編集者のロールが割り当てられていることを確認します。アカウントの接頭辞はプロジェクト番号で、ナビゲーション メニュー > [Cloud の概要] > [ダッシュボード] から確認できます。
編集者のロールがない場合は、以下の手順に沿って必要なロールを割り当てます。729328892908)をコピーします。{project-number} はプロジェクト番号に置き換えてください。[Cloud Console の BigQuery へようこそ] メッセージ ボックスが開きます。このメッセージ ボックスにはクイックスタート ガイドへのリンクと、UI の更新情報が表示されます。
このラボでは主に Cloud Dataprep を使用しますが、BigQuery も必要です。BigQuery は、パイプラインへのデータセット取り込み用のエンドポイント、およびパイプライン完了時の出力先として使用します。
このタスクでは、新しいパイプラインの出力テーブルを格納する新しい BigQuery データセットを作成します。
左側のペインで、プロジェクト ID の横にある [アクションを表示](
[データセットを作成する] ダイアログで、次の操作を行います。
[データセットを作成] をクリックします。
次の SQL クエリをコピーして [クエリエディタ] テキスト フィールドに貼り付けます。
一般公開されている e コマースの元データセットの一部がプロジェクトのデータセットにコピーされ、Cloud Dataprep で探索やクリーニングができるようになります。
このタスクでは、Google および Trifacta の利用規約に同意し、Trifacta がプロジェクト データにアクセスすることを許可します。
Google Cloud Platform のコンソールに移動し、ラボのプロジェクトが選択されていることを確認します。
ナビゲーション メニュー(
Google および Trifacta の利用規約を選択し、[同意する] をクリックします。
[Trifacta とアカウント情報を共有しますか?] ダイアログで、チェックボックスをオンにして [同意して続行] をクリックします。
[許可] をクリックして、Trifacta にプロジェクト データへのアクセスを許可します。この承認プロセスには数分かかる場合があります。
[Google でログイン] ウィンドウが表示されたら、Qwiklab アカウントを選択し、[許可] をクリックします。チェックボックスをオンにして、必要な場合は [同意する] をクリックします。
ストレージ バケットにはデフォルトの場所を使用するため、[続行] をクリックします。
Cloud Dataprep のホームページが表示されます。表示されない場合は、[ホーム] をクリックします。
このタスクでは、Cloud Dataprep を BigQuery データソースに接続します。
Cloud Dataprep のページで次の操作を行います。
[Create a new flow] をクリックします。
ページの上部にある [Untitled Flow] をクリックします。
[Rename] ダイアログで次のように指定します。
[OK] をクリックします。
[+] アイコンをクリックしてデータセットを追加します。
[Add datasets to flow] ダイアログで、左下にある [Import datasets] をクリックします。
左側のペインで [BigQuery] をクリックします。
e コマースのデータセットが読み込まれたら、それをクリックします。
データセットを作成するには Create dataset アイコン(![[Create dataset] アイコン](https://cdn.qwiklabs.com/SVBIVNk8vcwfKB4BKiyA6ywrizKBLzqJsXvVdw5gjY4%3D)
[Import & Add to Flow] をクリックします。
データソースが自動的に更新されます。
このタスクでは、Cloud Dataprep でデータセットのサンプルを読み込んで探索します。
右側のパネルで [Edit Recipe] をクリックします。
[The Transformer] ダイアログで、必要に応じて [Don't show me any helpers] をクリックします。
[Transformer] ビューにデータセットのサンプルが読み込まれます。この処理には数分かかる場合があります。
以下の各問題に解答してください。
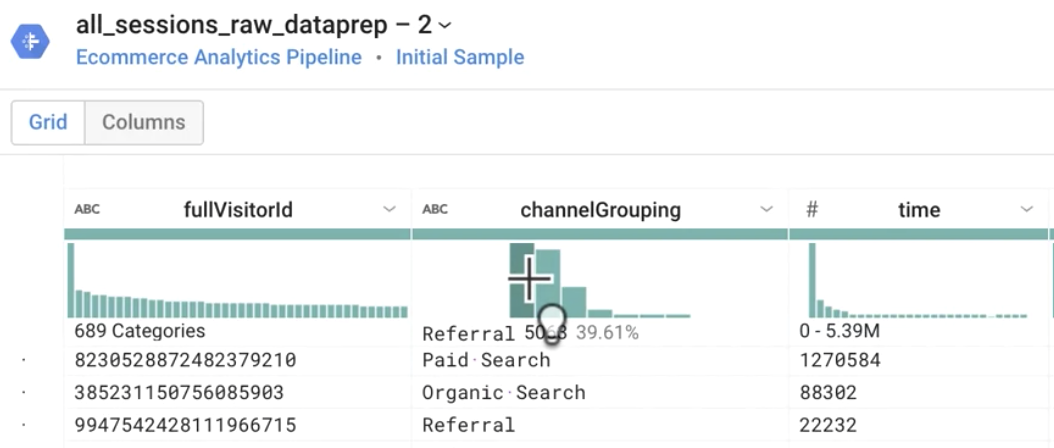
正解: 約 12,000 行
正解: Referral
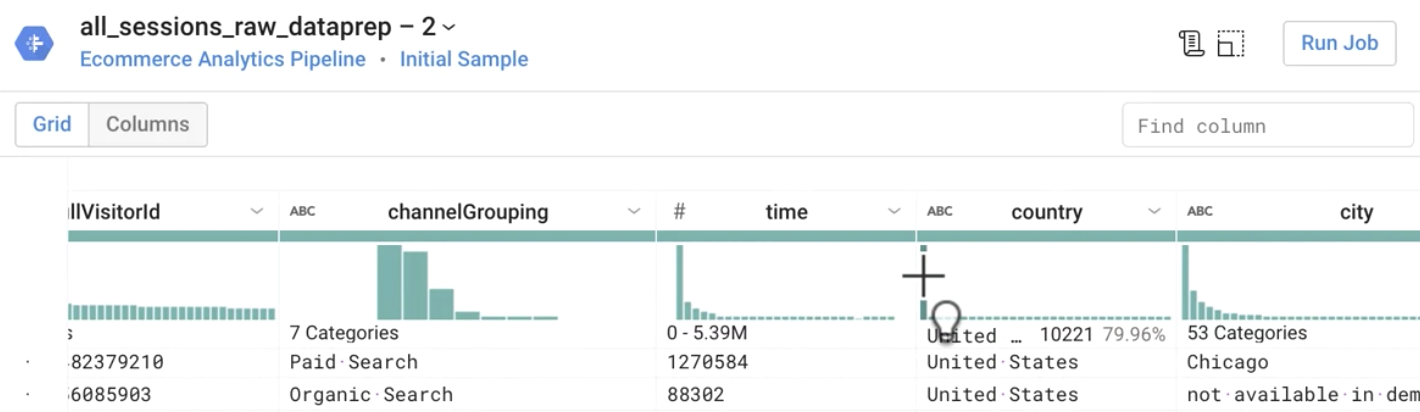
正解: 米国、インド、英国
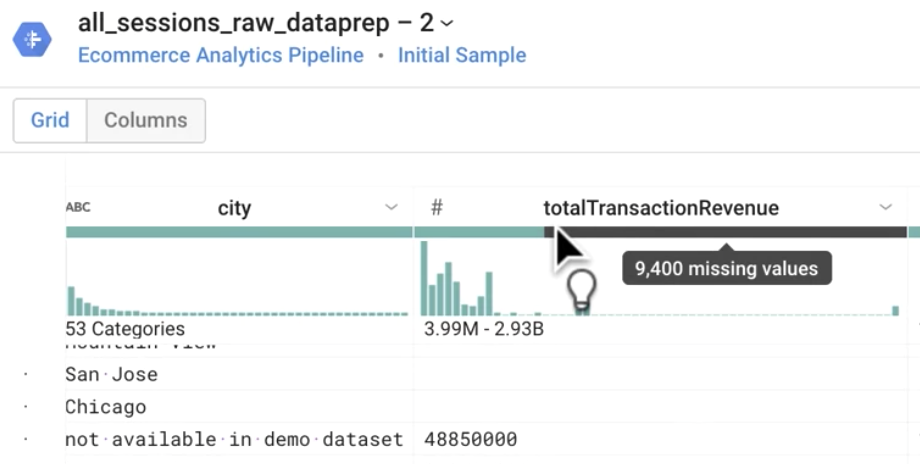
totalTransactionRevenue 列の下にある灰色のバーは何を表していますか。
正解: 欠測値
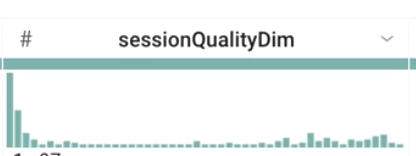
このデータサンプルの timeOnSite(秒)、pageviews、sessionQualityDim の平均値はそれぞれいくつですか(ヒント: [Column Details] を使用します)。
正解:
平均サイト滞在時間: 942 秒(15.7 分)
平均ページビュー: 20.44 ページ
平均セッションの品質ディメンション: 38.36
sessionQualityDim の値は均等に分布していますか(この列のヒストグラムを確認します)。
正解: いいえ。低い値(低品質のセッション)に偏っていますが、これは予想どおりです。
正解: 2017 年 8 月 1 日(1 日分のデータ)
正解: 赤いバーは値の不一致を表しています。productSKU 列は Cloud Dataprep によって自動的に整数型と識別されましたが、整数以外の値が検出されたため、値が不一致であると見なされました。実際、productSKU は整数であるとは限りません(たとえば、「GGOEGOCD078399」が正しい値である場合もあります)。そのため、この場合は Cloud Dataprep が列の型を誤って識別したことになります(整数型ではなく文字列型でなければなりません)。次の手順でこれを修正します。
String になっている場合、赤いバーは表示されません。productSKU 列のデータ型を String に変換するには、productSKU 列の右側にあるメニューを開き(
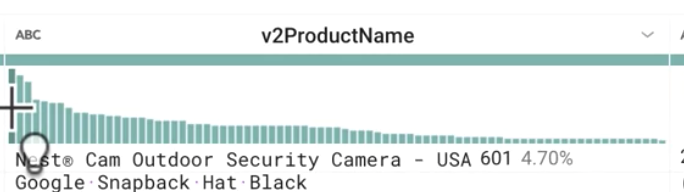
特に件数が多い商品は何ですか(v2ProductName 列を確認します)。
正解: Nest の商品
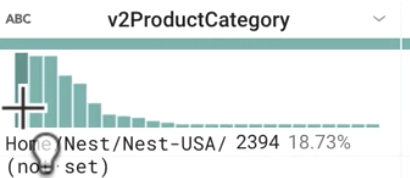
特に件数が多い商品カテゴリは何ですか(v2ProductCategory を確認します)。また、サンプルデータにはいくつのカテゴリがありますか。
正解: 約 25 のカテゴリがあり、特に件数が多いのは Nest、(not set)、Apparel です。
正解: 誤り。最も件数が多いのは (not set) で、ほとんどの商品(80% 以上)にはバリエーションがありません。
正解: PAGE と EVENT
正解: 3.45(異なる値になる場合もあります)
正解: 600 以上
正解:
Cam Outdoor Security Camera - USA
Cam Indoor Security Camera - USA
Learning Thermostat 3rd Gen-USA - Stainless Steel
正解: USD(米ドル)
正解: いいえ。すべて NULL 値です。
有効な値を持つトランザクション ID の割合はどれくらいですか。また、e コマース データセットではこの割合は何を表していますか。
正解: 約 4.6% のトランザクション ID が有効な値を持ちます。これは、ウェブサイトの平均コンバージョン率を表しています(訪問者の 4.6% が購入)。
正解:
サンプルでは、6 つのタイプのデータがあります。
特に多い値は 0 と NULL です。
このタスクでは、データをクリーニングするために、使用されていない列の削除、重複行の削除、計算フィールドの作成、行のフィルタを行います。一般的に、スキーマのフィールドが使用されていない場合や、フィールドがすべて NULL 値の場合は、列を削除します。
不要な列を選択し、[Delete] をクリックします。この操作は、すべて NULL 値である以下の列に対して行います。
itemRevenue
itemQuantity
ソース データセットに重複したセッション値が含まれている可能性があることがわかりました。そのため、重複除去のステップを追加してそれらの行を削除します。
画面右上のレシピアイコン(
[Transformation] の検索ボックスで、「deduplicate」と入力し、[Remove duplicate rows] を選択します。
[Add] をクリックします。
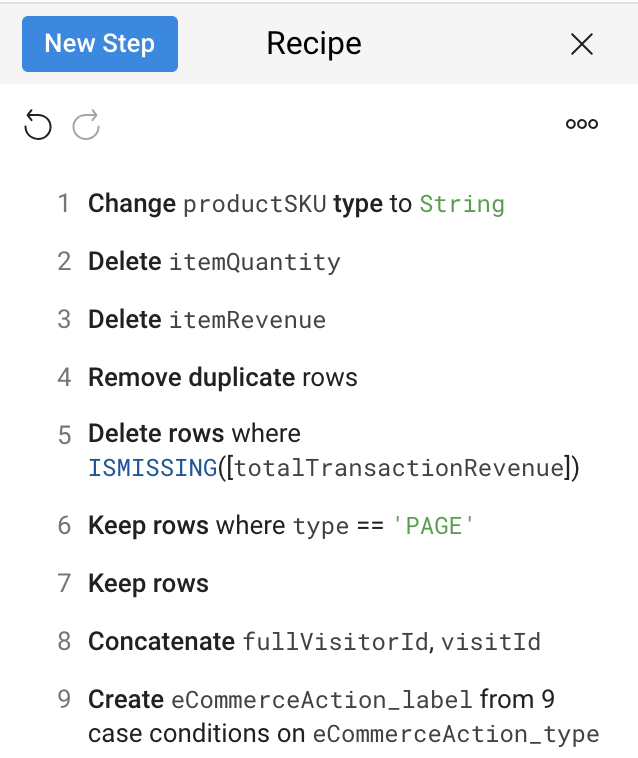
ここまでに作成したレシピを確認します。
このウェブサイトで商品を 1 つ以上購入したすべてのユーザー セッションを含むテーブルを作成するように依頼されました。そのため、収益が NULL のユーザー セッションを除外します。
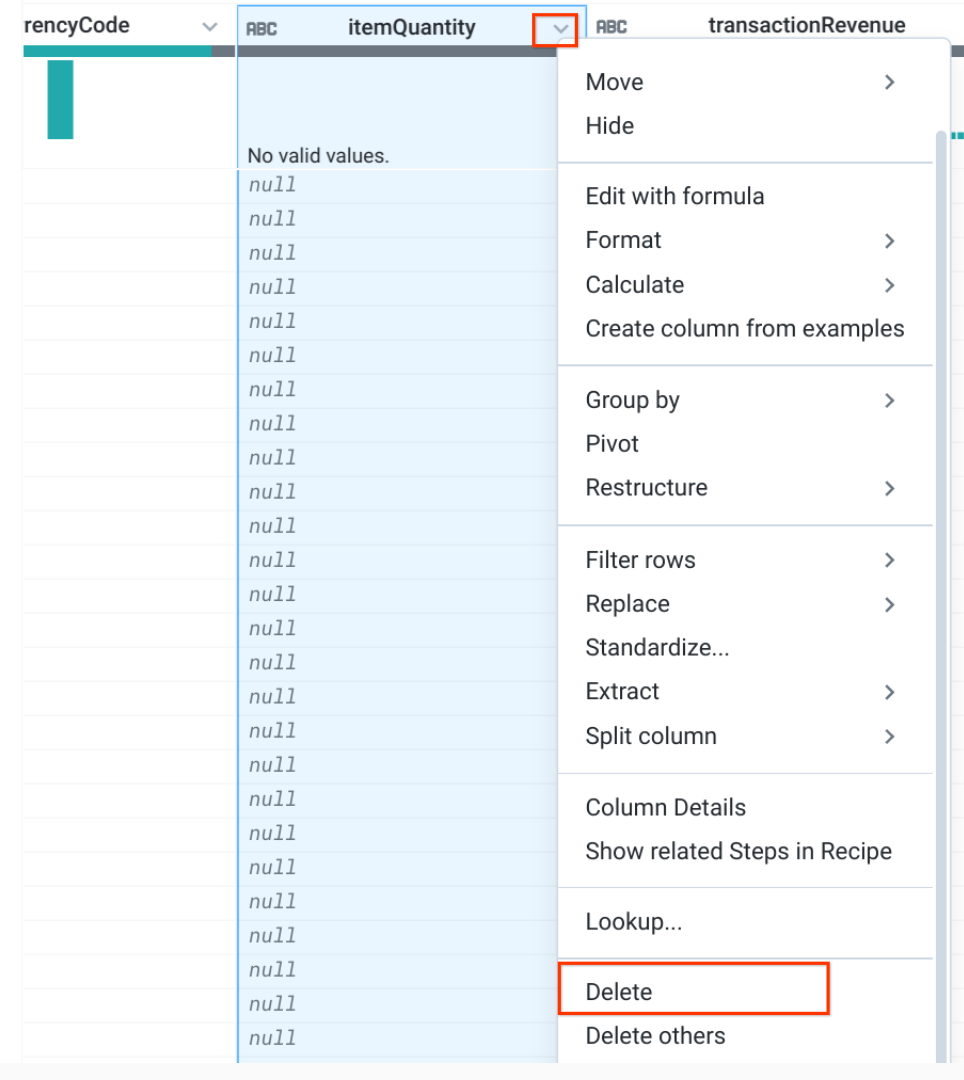
totalTransactionRevenue 列で、欠測値を示すバーをクリックします。
[Suggestions] パネルで、値がない行を削除する [Delete rows] をクリックし、[Add] をクリックします(画像を参照)。
このステップによって、totalTransactionRevenue が NULL のデータが除外され、収益があるトランザクションのみが含まれるようになります。
データセットには、ウェブサイトの「ページ」ビューとトリガーされた「イベント」(「商品カテゴリの表示」や「カートへの追加」など)の両方が含まれます。セッションのページビューが重複してカウントされないように、フィルタを追加してページビュー関連のイベントだけが含まれるようにします。
type 列で、PAGE のバーをクリックします。
[Suggestions] パネルで、タイプが PAGE の [Keep rows]、[Add] の順にクリックします。
カテゴリが Apparel のトランザクションのみが含まれるよう、出力内容をさらにフィルタする必要が生じました(Apparel には T シャツなどの衣料品が含まれます)。
v2ProductCategory 列の横にあるプルダウン アイコンをクリックします。
[Filter rows] > [On column values] を選択します。
[Contains] を選択します。
[Pattern to match] で「Apparel」(大文字と小文字が区別されます)と入力し、[Add] をクリックします。
このラボで使用されるスキーマについて詳しくは、[UA] BigQuery Export スキーマのガイド をご覧ください。スキーマのドキュメントで visitId を検索してその説明を読み、この値がすべてのユーザー セッションに対して一意なのか、そのユーザーに対してのみ一意なのかを確認します。
VisitId: このセッションの ID。通常は _utmb cookie として保存される値の一部で、ユーザーに対してのみ一意です。完全に一意の ID が必要な場合は、「fullVisitorId」と「visitId」を併用してください。
visitId は全ユーザーに対して一意ではありません。
このタスクでは、新しく連結した列を追加して、一意のセッション ID のフィールドを作成します。その後、case ステートメントで e コマースのラベルデータを拡充します。
すでに確認したように、このデータセットには一意のユーザー セッションを表す単一の列がありません。そのため、fullVisitorID フィールドと visitId フィールドを連結してセッションごとに一意の ID を作成します。
[New Step] をクリックします。
[Search transformation] に「concat」と入力し、[Merge columns] を選択します。
[Columns] で、[fullVisitorId] と [visitId] を選択します。
[New column name] に「unique_session_id」と入力し、その他の入力項目はデフォルト値のままにして [Add] をクリックします。
eCommerceAction_type は、そのセッションで実際に実行された e コマース アクションにマッピングされる整数型のフィールドです(3 は「カートへの追加」、5 は「決済」など)。この整数値にマッピングされる計算列を作成します。
[New Step] をクリックします。
[Transformation] パネルで、「case」と入力し、[Conditional column] を選択します。
プルダウンで [Case on single column] を選択します。
[Column to evaluate] で [eCommerceAction_type] を指定します。
[Cases (X)] の横にある [Add] を 8 回クリックし、case が合計 9 個になるようにします。
各 case に対して、以下のマッピング値を指定します(引用符も含めます)。
| 比較する値 | 新しい値 |
|---|---|
| 1 | '商品一覧からのクリック' |
| 2 | '商品の詳細の閲覧' |
| 3 | 'カートへの商品の追加' |
| 4 | 'カートからの商品の削除' |
| 5 | '決済' |
| 6 | '購入の完了' |
| 7 | '購入の払い戻し' |
| 8 | '決済オプション' |
| 0 | '不明' |
他のフィールドはデフォルト値のままにします。
[New column name] に「eCommerceAction_label」と入力し、[Add] をクリックします。
レシピを確認し、こちらの例と比較します。
フローが完了したら、ソース データセットに対して変換レシピを実行します。それには、Cloud Dataprep ジョブを実行し、モニタリングします(Cloud Dataflow ジョブが開始、実行されます)。
[Transformer] ページの右上にある [Run] をクリックします。
[Publishing Actions] セクションにある Create-CSV にカーソルを合わせ、[Edit] をクリックします。
左側のパネルで [BigQuery] を選択して e コマースのデータセットに移動し、[Create a new table] をクリックします。
出力テーブルを apparel_revenue という名前にし、右側のパネルで [Drop the table every run] を選択します。
[Update] をクリックします。
[Run] をクリックします。
左側のパネルで [Job history] をクリックして Cloud Dataprep ジョブをモニタリングします。
ジョブが実行される間、1~2 分待ちます。
Cloud Dataprep ジョブが終了したら BigQuery ページを更新し、出力テーブル apparel_revenue が存在することを確認します。
[apparel_revenue] > [Preview] を選択し、Apparel の商品の収益があるトランザクションのデータが格納されていることを確認します。
ここでは Cloud Dataprep を使用して、e コマースのデータセットを探索し、繰り返し実行されるデータ変換パイプラインを作成しました。
すでに Google アナリティクス アカウントをお持ちで、BigQuery で独自のデータセットをクエリするには、BigQuery Export の設定に関するこちらのガイドをご参照ください。
ラボが完了したら、[ラボを終了] をクリックします。ラボで使用したリソースが Google Cloud Skills Boost から削除され、アカウントの情報も消去されます。
ラボの評価を求めるダイアログが表示されたら、星の数を選択してコメントを入力し、[送信] をクリックします。
星の数は、それぞれ次の評価を表します。
フィードバックを送信しない場合は、ダイアログ ボックスを閉じてください。
フィードバックやご提案の送信、修正が必要な箇所をご報告いただく際は、[サポート] タブをご利用ください。
Copyright 2020 Google LLC All rights reserved. Google および Google のロゴは Google LLC の商標です。その他すべての企業名および商品名はそれぞれ各社の商標または登録商標です。



このコンテンツは現在ご利用いただけません
利用可能になりましたら、メールでお知らせいたします

ありがとうございます。
利用可能になりましたら、メールでご連絡いたします

1 回に 1 つのラボ
既存のラボをすべて終了して、このラボを開始することを確認してください