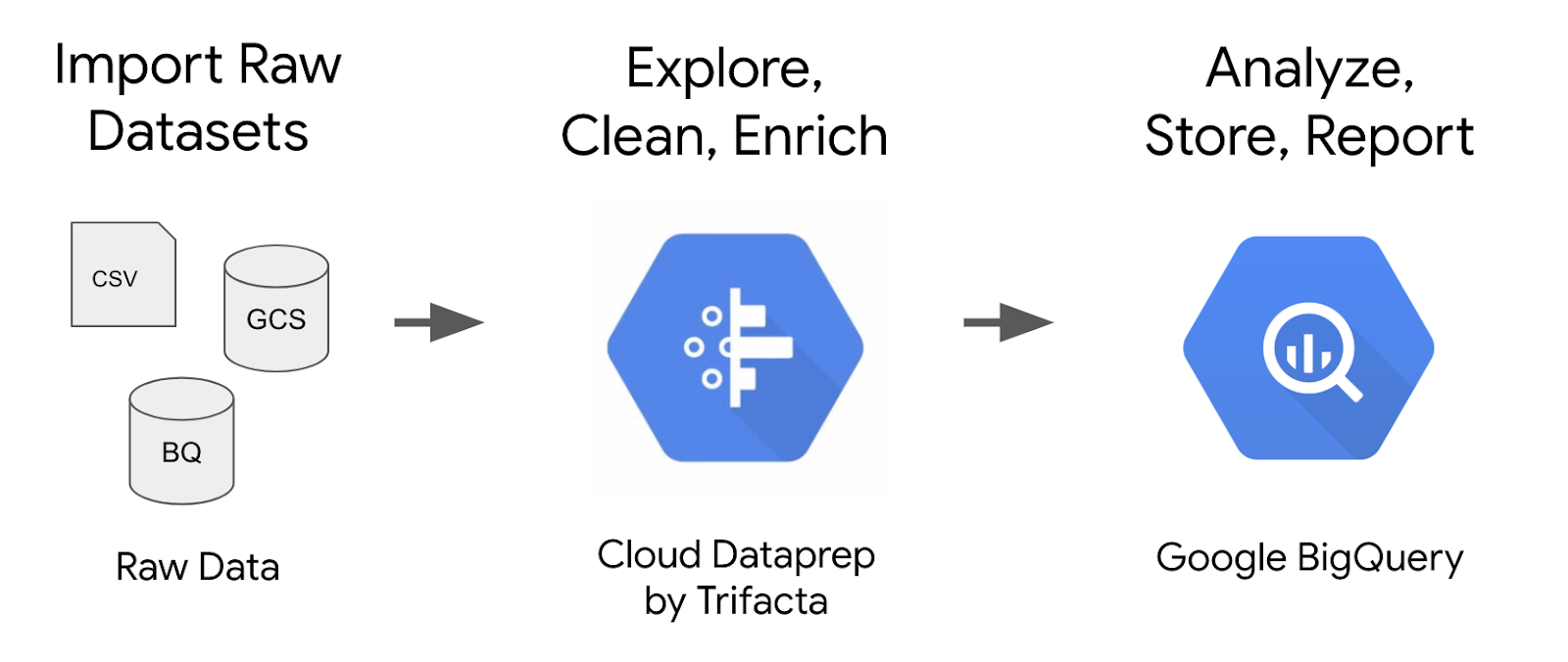
Cloud Dataprep by Trifacta est un service intelligent qui permet d'explorer visuellement, de nettoyer et de préparer des données structurées ou non structurées à des fins d'analyse. Dans cet atelier, nous allons nous servir de l'interface utilisateur de Cloud Dataprep afin de créer un pipeline de transformation de données d'e-commerce. Ce pipeline s'exécutera à intervalles planifiés et renverra les résultats dans BigQuery.
L'ensemble de données que nous utiliserons est un ensemble de données d'e-commerce comprenant des millions d'enregistrements Google Analytics pour le Google Merchandise Store chargé dans BigQuery. Nous avons créé une copie de cet ensemble de données pour cet atelier et nous allons explorer les champs et lignes qu'il contient afin d'obtenir des informations.
Objectifs
Dans cet atelier, vous apprendrez à effectuer les tâches suivantes :
Connecter des ensembles de données BigQuery à Cloud Dataprep
Évaluer la qualité des ensembles de données avec Cloud Dataprep
Créer un pipeline de transformation de données avec Cloud Dataprep
Planifier les résultats des jobs de transformation dans BigQuery
Prérequis
Un projet Google Cloud Platform.
Le navigateur Google Chrome. Cloud Dataprep n'est compatible qu'avec le navigateur Chrome.
Préparation
Pour chaque atelier, nous vous attribuons un nouveau projet Google Cloud et un nouvel ensemble de ressources pour une durée déterminée, sans frais.
Connectez-vous à Qwiklabs dans une fenêtre de navigation privée.
Vérifiez le temps imparti pour l'atelier (par exemple : 01:15:00) : vous devez pouvoir le terminer dans ce délai.
Une fois l'atelier lancé, vous ne pouvez pas le mettre en pause. Si nécessaire, vous pourrez le redémarrer, mais vous devrez tout reprendre depuis le début.
Lorsque vous êtes prêt, cliquez sur Démarrer l'atelier.
Notez vos identifiants pour l'atelier (Nom d'utilisateur et Mot de passe). Ils vous serviront à vous connecter à Google Cloud Console.
Cliquez sur Ouvrir la console Google.
Cliquez sur Utiliser un autre compte, puis copiez-collez les identifiants de cet atelier lorsque vous y êtes invité.
Si vous utilisez d'autres identifiants, des messages d'erreur s'afficheront ou des frais seront appliqués.
Acceptez les conditions d'utilisation et ignorez la page concernant les ressources de récupération des données.
Vérifier les autorisations du projet
Avant de commencer à travailler dans Google Cloud, vous devez vous assurer de disposer des autorisations adéquates pour votre projet dans IAM (Identity and Access Management).
Dans la console Google Cloud, accédez au menu de navigation (), puis sélectionnez IAM et administration > IAM.
Vérifiez que le compte de service Compute par défaut {project-number}-compute@developer.gserviceaccount.com existe et qu'il est associé au rôle editor (éditeur). Le préfixe du compte correspond au numéro du projet, disponible sur cette page : Menu de navigation > Présentation du cloud > Tableau de bord.
Remarque : Si le compte n'est pas disponible dans IAM ou n'est pas associé au rôle editor (éditeur), procédez comme suit pour lui attribuer le rôle approprié.
Dans la console Google Cloud, accédez au menu de navigation et cliquez sur Présentation du cloud > Tableau de bord.
Copiez le numéro du projet (par exemple, 729328892908).
Dans le menu de navigation, sélectionnez IAM et administration > IAM.
Sous Afficher par compte principal, en haut de la table des rôles, cliquez sur Accorder l'accès.
Dans le champ Nouveaux comptes principaux, saisissez :
Remplacez {project-number} par le numéro de votre projet.
Dans le champ Rôle, sélectionnez Projet (ou Basique) > Éditeur.
Cliquez sur Enregistrer.
Ouvrir la console BigQuery
Dans la console Google Cloud, sélectionnez le menu de navigation > BigQuery.
Le message Bienvenue sur BigQuery dans la console Cloud s'affiche. Il contient un lien vers le guide de démarrage rapide et liste les mises à jour de l'interface utilisateur.
Cliquez sur Done (OK).
Bien que cet atelier se concentre principalement sur Cloud Dataprep, vous devez utiliser BigQuery comme point de terminaison pour l'ingestion de l'ensemble de données dans le pipeline et comme destination du résultat une fois le pipeline terminé.
Tâche 1 : Créer un ensemble de données BigQuery vide
Dans cette tâche, vous allez créer un ensemble de données BigQuery qui recevra la table de résultats de votre nouveau pipeline.
Dans le volet de gauche, cliquez sur Afficher les actions () à côté de votre ID de projet, puis sélectionnez Créer un ensemble de données.
Dans la boîte de dialogue Créer un ensemble de données :
Dans le champ ID de l'ensemble de données, saisissez e-commerce.
Conservez les valeurs par défaut dans les autres champs.
Cliquez sur Créer un ensemble de données.
Copiez et collez cette requête SQL dans la zone de texte de l'Éditeur de requête :
#standardSQL
CREATE OR REPLACE TABLE ecommerce.all_sessions_raw_dataprep
OPTIONS(
description="Raw data from analyst team to ingest into Cloud Dataprep"
) AS
SELECT * FROM `data-to-insights.ecommerce.all_sessions_raw`
WHERE date = '20170801'; # limiting to one day of data 56k rows for this lab
Cliquez sur Exécuter.
Cette requête copie un sous-ensemble de l'ensemble de données d'e-commerce brut public dans l'ensemble de données de votre projet pour que vous puissiez l'explorer et le nettoyer dans Cloud Dataprep.
Assurez-vous que la nouvelle table de données brutes existe bien dans votre projet.
Tâche 2 : Ouvrir Cloud Dataprep
Dans cette tâche, vous allez accepter les conditions d'utilisation de Google et de Trifacta, puis autoriser Trifacta à accéder aux données de votre projet.
Exécutez la commande suivante dans Cloud Shell pour créer un compte de service, qui vous permettra d'accéder à Dataprep.
Dans la console GCP, assurez-vous que le projet de votre atelier est sélectionné.
Dans le menu de navigation (), sous le regroupement Analyse, cliquez sur Dataprep.
Sélectionnez les conditions d'utilisation de Google et de Trifacta, puis cliquez sur Accepter.
Dans la boîte de dialogue Share account information with Trifacta (Partager les informations de compte avec Trifacta), cochez la case, puis cliquez sur Agree and Continue (Accepter et continuer).
Pour permettre à Trifacta d'accéder aux données de votre projet, cliquez sur Allow (Autoriser). Ce processus d'autorisation peut prendre quelques minutes.
Sur la page Sign in with Google (Se connecter avec Google) qui apparaît, sélectionnez votre compte Qwiklab et cliquez sur Allow (Autoriser). Si nécessaire, cliquez sur Accept (Accepter) après avoir coché la case.
Pour utiliser l'emplacement par défaut du bucket de stockage, cliquez sur Continue (Continuer).
La page d'accueil de Cloud Dataprep s'ouvre. Si nécessaire, cliquez sur Home (Accueil).
Tâche 3 : Connecter les données BigQuery à Cloud Dataprep
Dans cette tâche, vous allez connecter Cloud Dataprep à votre source de données BigQuery.
Sur la page Cloud Dataprep :
Cliquez sur Create a new flow (Créer un flux).
Cliquez sur Untitled Flow (Flux sans titre) en haut de la page.
Dans la boîte de dialogue "Rename" (Renommer), indiquez les informations suivantes :
Pour Flow Name (Nom du flux), saisissez Ecommerce Analytics Pipeline (Pipeline d'analyse de données d'e-commerce).
Pour Flow Description (Description du flux), saisissez Revenue reporting table for Apparel (Table de rapport sur les revenus pour l'habillement).
Cliquez sur OK.
Cliquez sur l'icône (+) pour ajouter un ensemble de données.
Dans la boîte de dialogue "Add datasets to flow" (Ajouter des ensembles de données au flux), cliquez sur Import Datasets (Importer des ensembles de données) en bas à gauche.
Dans le volet de gauche, cliquez sur BigQuery.
Une fois votre ensemble de données ecommerce chargé, cliquez dessus.
Pour créer un ensemble de données, cliquez sur l'icône Create dataset (Créer un ensemble de données) ().
Cliquez sur Import & Add to Flow (Importer et ajouter au flux).
La source de données est mise à jour automatiquement.
Tâche 4 : Explorer les champs de données d'e-commerce dans une interface utilisateur
Dans cette tâche, vous allez charger et explorer un échantillon de l'ensemble de données dans Cloud Dataprep.
Cliquez sur Edit Recipe (Modifier la recette) dans le panneau de droite.
Si nécessaire, cliquez sur Don't show me any helpers (Ne pas afficher les assistants) dans la boîte de dialogue Transformer (Transformateur).
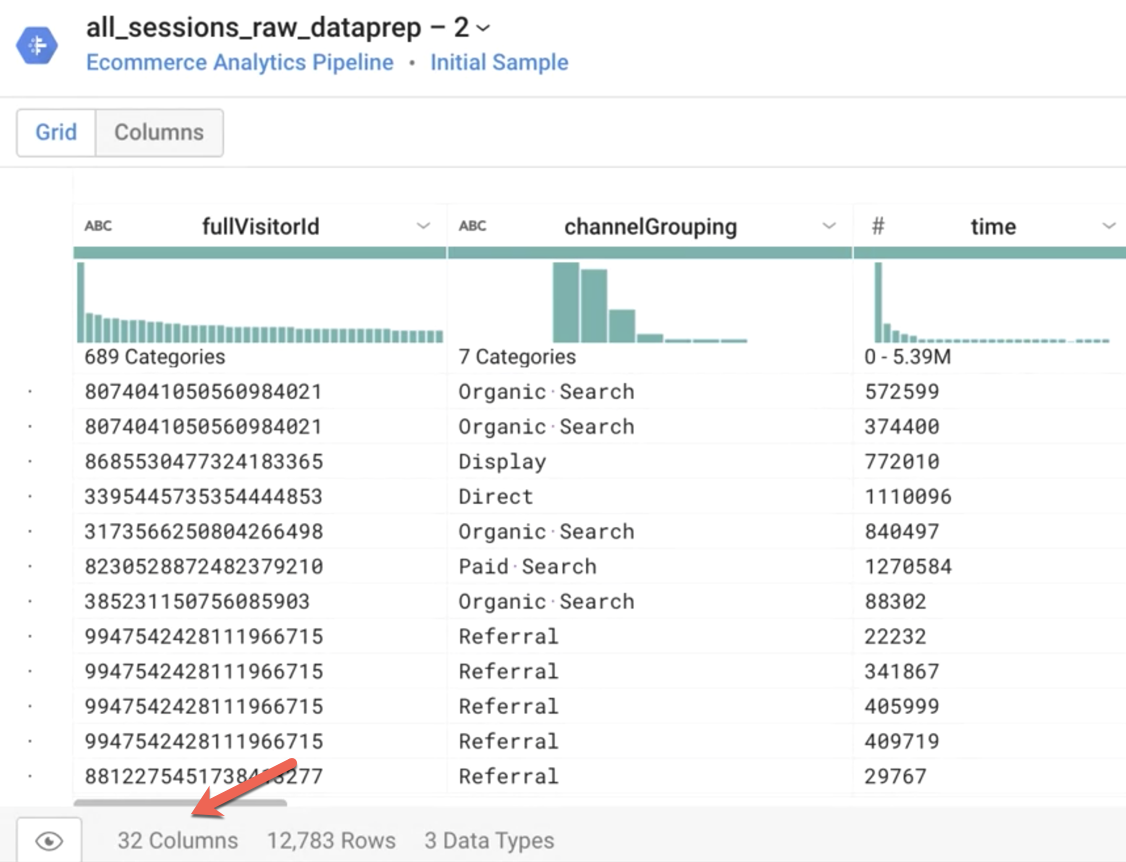
Cloud Dataprep charge un échantillon de votre ensemble de données dans la vue "Transformer" (Transformateur). Ce processus peut prendre quelques minutes.
Répondez aux questions :
Cloud Dataprep charge un échantillon de l'ensemble de données source pour accélérer l'exploration.
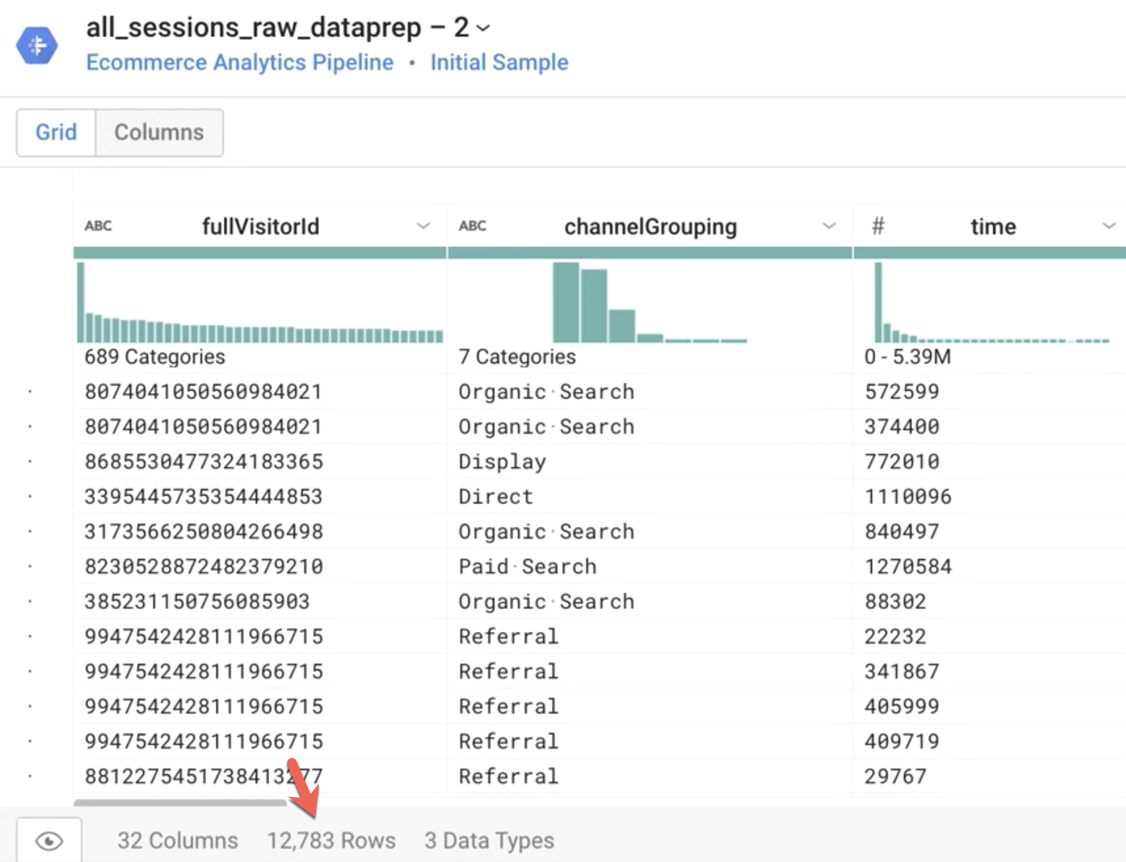
Remarque : Lorsque votre pipeline est exécuté, il opère sur l'intégralité de l'ensemble de données source. Combien de lignes l'échantillon comprend-il ?
Réponse : Environ 12 000 lignes
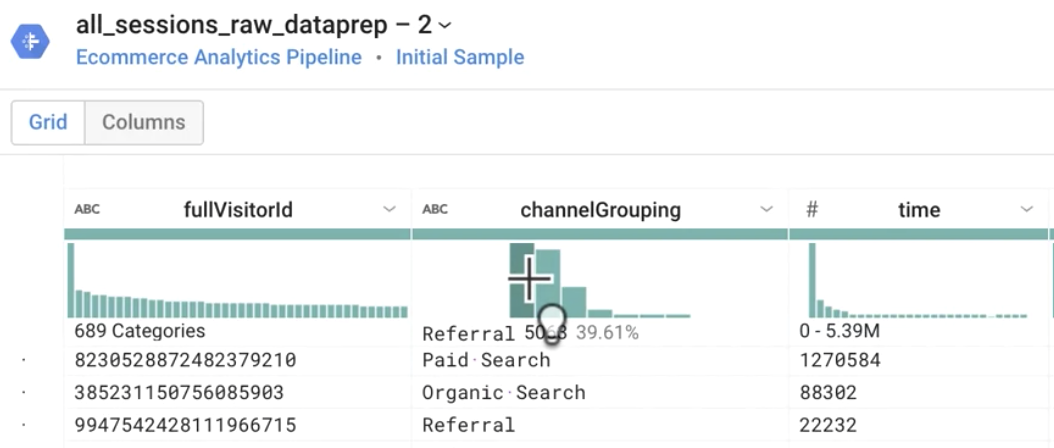
Quelle est la valeur la plus commune dans la colonne channelGrouping ?
Réponse : "Referral" (Référence)
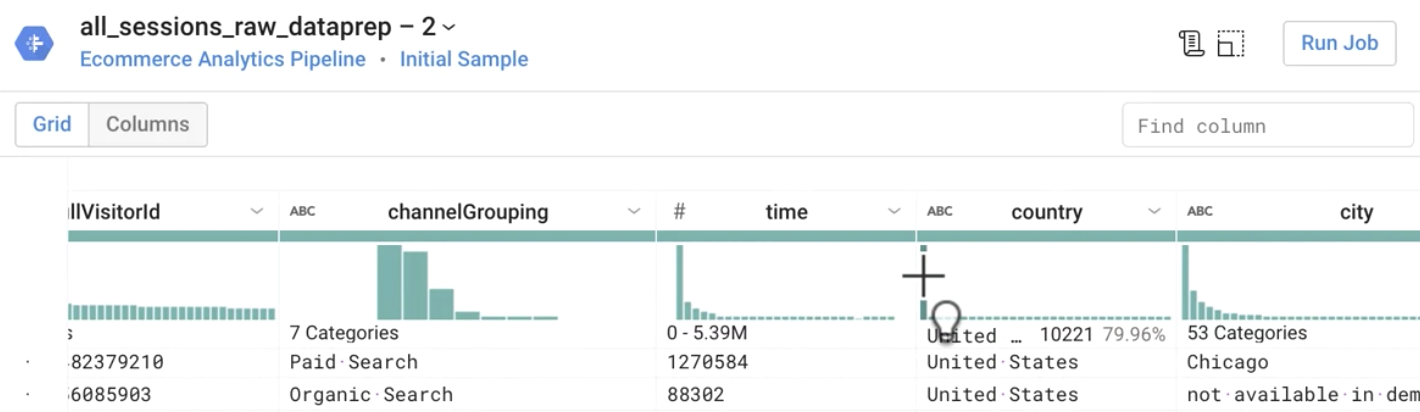
Quels sont les trois principaux pays dont proviennent les sessions ?
Réponse : États-Unis, Inde, Royaume-Uni
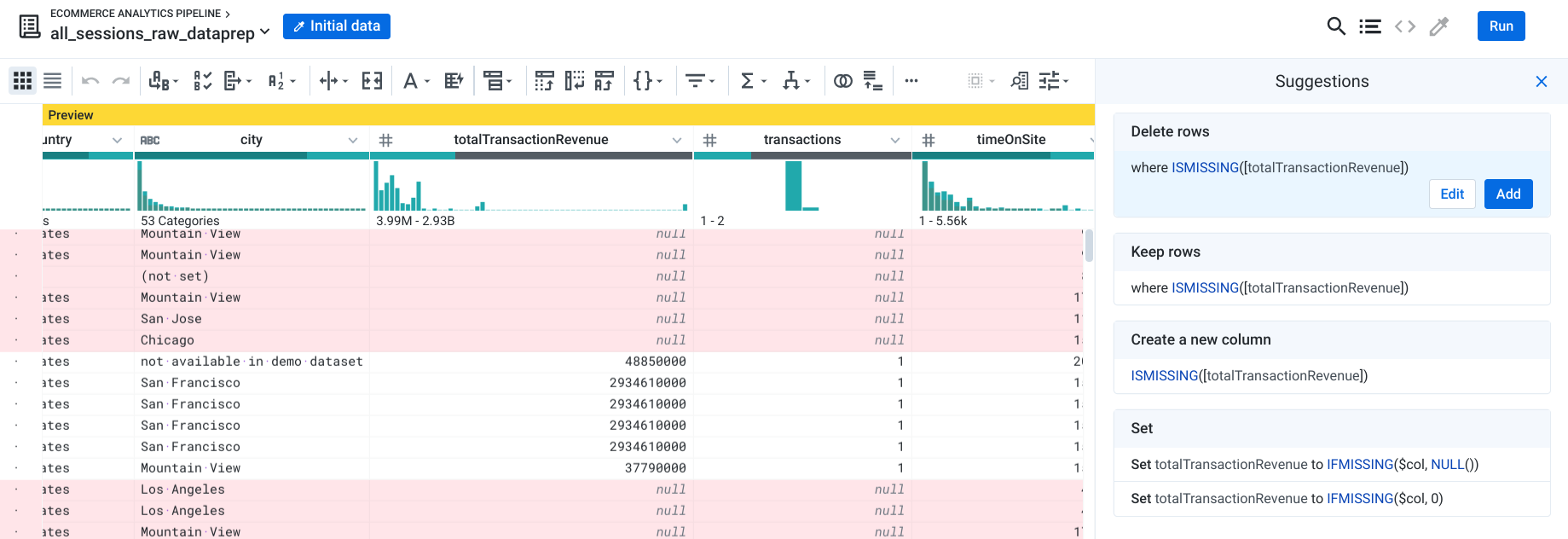
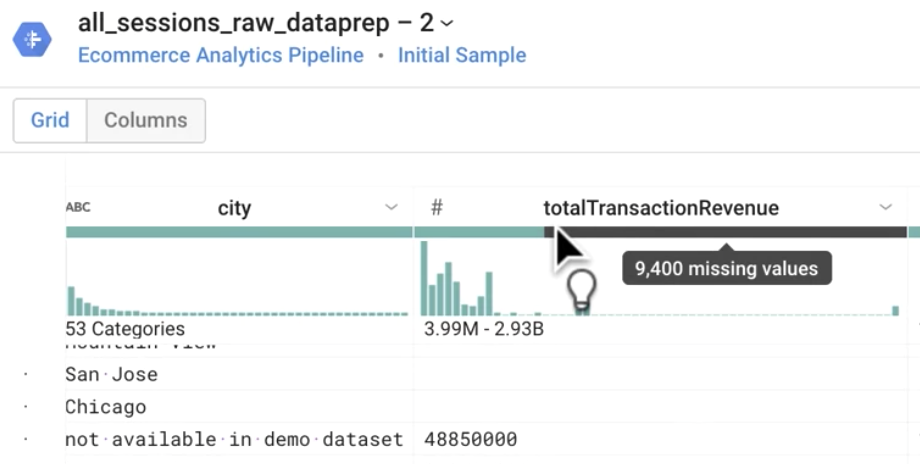
Que représente la barre grise sous totalTransactionRevenue ?
Réponse : Les valeurs manquantes
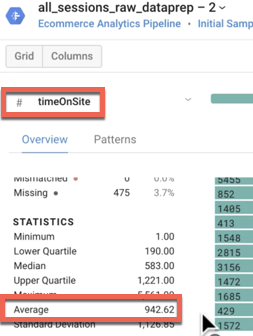
Quelles sont les valeurs moyennes de timeOnSite (Temps passé sur le site) en secondes, pageviews (Nombre de pages vues) et sessionQualityDim (Dimension "Qualité de la session") pour l'échantillon de données ? Conseil : utilisez Column Details (Détails de la colonne).
Réponses :
Average Time On Site (Temps moyen passé sur le site) : 942 secondes (ou 15,7 minutes)
Average Pageviews (Nombre moyen de pages vues) : 20,44 pages
Average Session Quality Dimension (Valeur moyenne de la dimension "Qualité de la session") : 38,36
Remarque : Les réponses peuvent varier légèrement en fonction de l'échantillon de données utilisé par Cloud Dataprep.
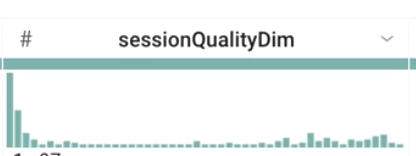
Si on considère l'histogramme sessionQualityDim, les valeurs de données sont-elles réparties de manière uniforme ?
Réponse : Non, elles sont asymétriques (sessions de mauvaise qualité), comme prévu.
Quelle est la plage de dates pour l'échantillon de l'ensemble de données ?
Réponse : 01/08/2017 (un jour de données)
Pourquoi y a-t-il une barre rouge sous la colonne productSKU (SKU du produit) ?
Réponse : La barre rouge indique des valeurs non concordantes. Cloud Dataprep a automatiquement identifié le type de la colonne productSKU (SKU du produit) comme correspondant à un entier. Cloud Dataprep a également détecté des valeurs non entières et a donc marqué ces valeurs comme incompatibles. En réalité, "productSKU" (SKU du produit) ne correspond pas toujours à un entier (par exemple, "GGOEGOCD078399" peut être une valeur correcte). Dans ce cas, Cloud Dataprep a donc identifié de manière incorrecte le type de colonne, qui devrait être une chaîne et non un entier. Vous corrigerez cela à l'étape suivante.
Remarque : Si le type de la colonne productSKU est déjà String (chaîne), la barre rouge ne s'affiche pas.
Pour faire en sorte que le type de la colonne productSKU soit "Chaîne", ouvrez le menu situé à droite de la colonne productSKU en cliquant sur , puis sélectionnez Change type > String (Changer de type > Chaîne).
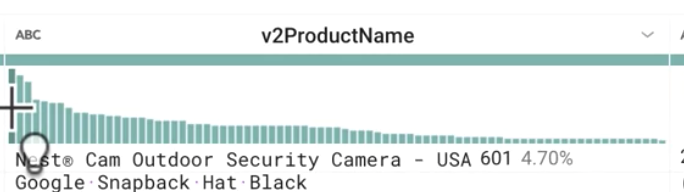
Si l'on considère la colonne v2ProductName (Nom de produit v2), quels sont les produits les plus populaires ?
Réponse : Les produits Nest
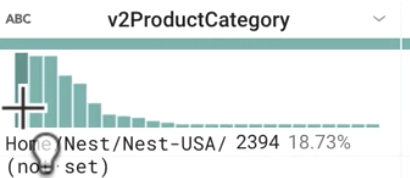
Si l'on considère la colonne v2ProductCategory (Catégorie de produits v2), quelles sont les catégories de produits les plus populaires ? Combien de catégories ont fait l'objet d'un échantillonnage ?
Réponse : "Nest" ("not set", catégorie non définie) et "Apparel" (Habillement) sont les plus populaires des quelque 25 catégories.
Vrai ou faux : La productVariant (Variante de produit) la plus courante est "COLOR" (COULEUR).
Réponse : Faux. Il s'agit de "(not set)" (non défini), car aucune variante n'est disponible pour la plupart des produits (plus de 80 %).
Quelles sont les deux catégories du type ?
Réponse : "PAGE" et "EVENT" (ÉVÉNEMENT)
Quelle est la valeur moyenne de productQuantity (Quantité de produit) ?
Réponse : 3,45 (votre réponse peut varier)
Combien y a-t-il de codes SKU distincts dans l'ensemble de données ?
Réponse : Plus de 600
Parmi les produits les plus populaires, quels sont les noms de ceux qui apparaissent le plus souvent si l'on considère le nombre de lignes ? Et quelles sont les catégories les plus populaires ?
Réponse :
Cam Outdoor Security Camera - USA
Cam Indoor Security Camera - USA
Learning Thermostat 3rd Gen-USA - Stainless Steel
Quel est le principal code de devise pour les transactions ?
Réponse : USD (dollar américain)
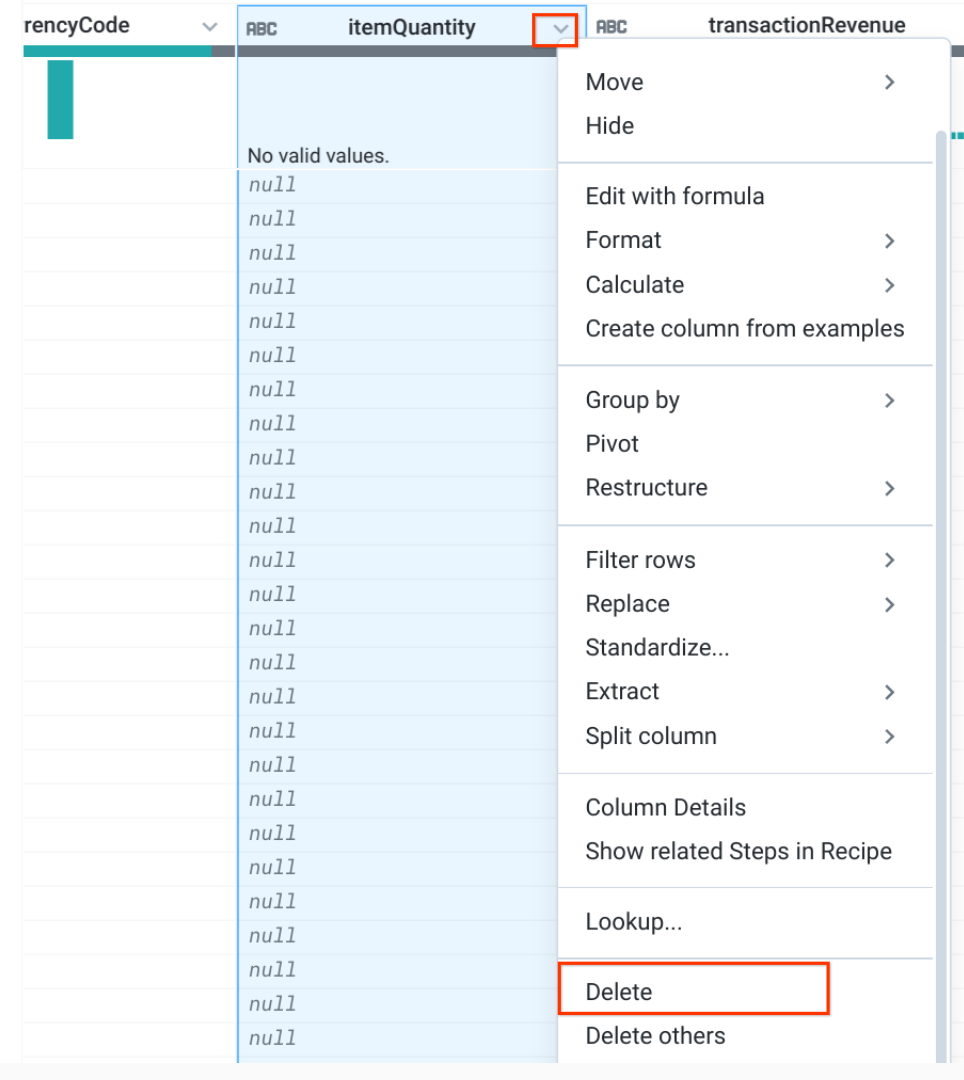
Existe-t-il des valeurs valides pour itemQuantity ou itemRevenue ?
Réponse : Non, ces valeurs sont NULL.
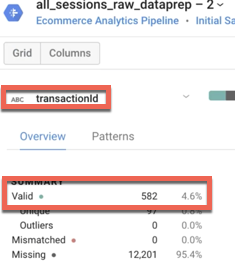
Quel est le pourcentage des ID de transaction ayant une valeur valide ? À quoi est-ce que cela correspond pour notre ensemble de données d'e-commerce ?
Réponse : Environ 4,6 % des ID de transaction ont une valeur valide, ce qui correspond au taux de conversion moyen du site Web (4,6 % des visiteurs effectuent au moins une transaction).
Combien existe-t-il de types d'actions d'e-commerce (eCommerceAction_type), et quelle est l'étape d'action d'e-commerce (eCommerceAction_step) la plus populaire ?
Réponses :
Six types ont des données dans notre échantillon.
0 (ou NULL) est l'étape la plus populaire.
Tâche 5 : Nettoyer les données
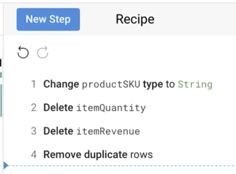
Dans cette tâche, vous allez nettoyer les données en supprimant les colonnes inutilisées, en éliminant les doublons, en créant des champs calculés et en filtrant les lignes. La suppression de colonnes est une pratique courante lorsque les champs sont obsolètes dans le schéma ou qu'ils ont tous des valeurs NULL.
Supprimer les colonnes inutilisées
Sélectionnez la colonne que vous ne souhaitez pas conserver, puis cliquez sur Delete (Supprimer). Faites la même chose pour les colonnes suivantes, qui ne contiennent que des valeurs NULL :
itemRevenue (Revenu généré par l'article)
itemQuantity (Quantité de l'article)
Dédupliquer les lignes
Votre équipe vous a informé que l'ensemble de données source pouvait contenir des sessions en double. Supprimons-les grâce à une étape de déduplication.
Cliquez sur Recipe (Recette) () en haut à droite et sélectionnez New Step (Nouvelle étape).
Dans le champ de recherche Transformation, saisissez deduplicate (dédupliquer) et sélectionnez Remove duplicate rows (Supprimer les lignes en double).
Cliquez sur Add (Ajouter).
Examinez votre recette pour voir ce que vous avez créé jusqu'à présent :
Filtrer les sessions pour exclure celles n'ayant pas généré de revenus
Votre équipe vous a demandé de créer une table de toutes les sessions d'utilisateurs ayant acheté au moins un article sur votre site Web. Filtrez les sessions utilisateur avec un revenu NULL.
Sous la colonne totalTransactionRevenue (Total des revenus de la transaction), cliquez sur la barre des valeurs manquantes.
Dans le panneau Suggestions, cliquez sur Delete rows (Supprimer les lignes) là où il vous est indiqué que des valeurs sont manquantes, puis cliquez sur Add (Ajouter), comme illustré ici.
Cette étape filtre votre ensemble de données afin de n'inclure que les transactions générant des revenus, c'est-à-dire les transactions pour lesquelles totalTransactionRevenue (Total des revenus de la transaction) n'est pas NULL.
Filtrer les sessions pour ne conserver que le type "PAGE"
L'ensemble de données contient à la fois des vues des pages du site Web et des événements déclenchés tels que “viewed product categories” (Catégories de produits vues) ou “added to cart” (Ajouté au panier). Pour éviter de comptabiliser deux fois les pages vues de la session, ajoutez un filtre afin de n'inclure que les événements liés à une vue de page.
Dans la colonne type, cliquez sur la barre pour "PAGE".
Dans le panneau Suggestions, cliquez sur "Keep rows" (Conserver les lignes) là où il vous est indiqué que le type est "PAGE", puis cliquez sur Add (Ajouter).
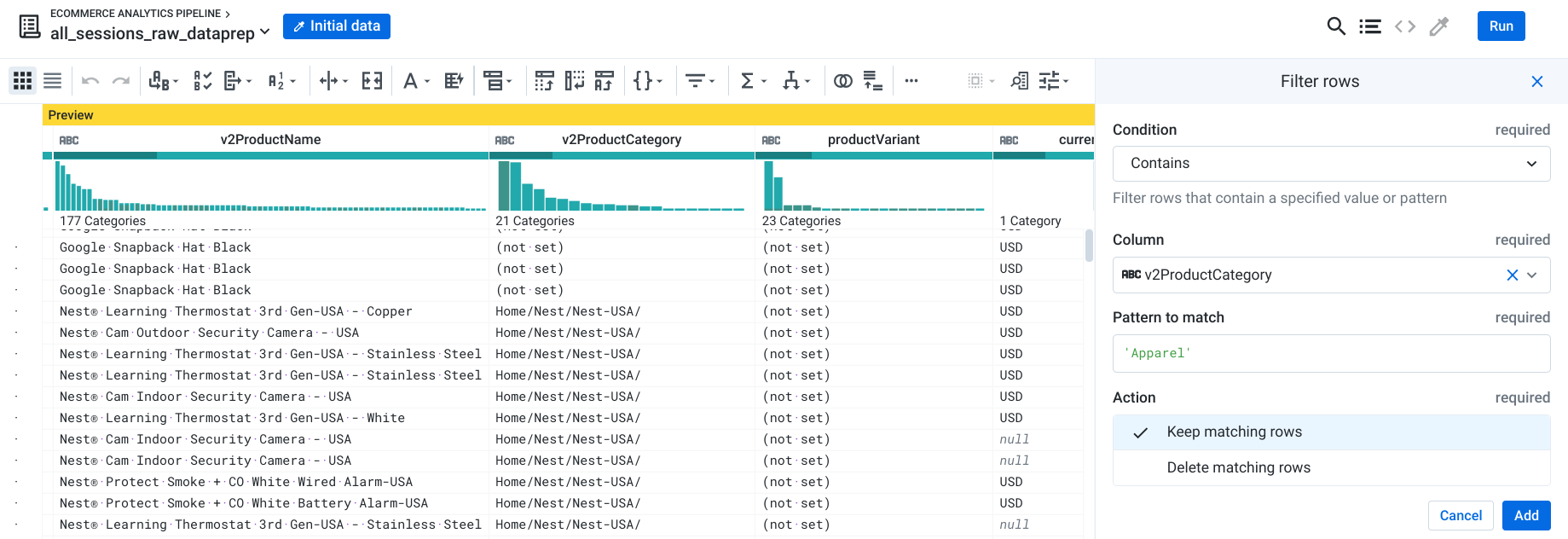
Filtrer les résultats pour ne conserver que les produits d'habillement
Votre équipe vous a maintenant demandé de filtrer davantage vos résultats afin de n'inclure que les transactions de la catégorie "Apparel" (Habillement). Cette catégorie comprend divers articles et accessoires vestimentaires (par exemple, les T-shirts).
Cliquez sur l'icône de la liste déroulante située à côté de la colonne v2ProductCategory (Catégorie de produits v2).
Sélectionnez Filter rows > On column values (Filtrer les lignes > En fonction des valeurs des colonnes).
Sélectionnez Contains (Contient).
Dans Pattern to match (Modèle à mettre en correspondance), saisissez "Apparel" (en respectant bien la casse) pour indiquer que vous ne voulez voir que les produits d'habillement, puis cliquez sur Add (Ajouter).
Remarque : Les produits du catalogue peuvent appartenir à plusieurs catégories, par exemple à "Apparel" et à "Home/Apparel/" (Maison/Habillement/). C'est pourquoi nous cherchons à établir une correspondance avec toutes les lignes dont le nom de la catégorie contient "Apparel".
Tâche 6 : Enrichir les données
Pour en savoir plus sur le schéma utilisé dans cet atelier, consultez le schéma de BigQuery Export [UA]. Recherchez visitId dans cet article et lisez la description pour déterminer si cette valeur est propre à toutes les sessions utilisateur ou juste à l'utilisateur.
"visitId" : identifiant défini pour cette session. Il fait partie de la valeur généralement stockée sous la forme du cookie _utmb. Il est propre à cet utilisateur. Pour obtenir un identifiant parfaitement unique, vous devez combiner les valeurs des champs "fullVisitorId" (ID visiteur complet) et "visitId" (ID visite).
visitId n'est pas unique pour tous les utilisateurs.
Dans cette tâche, vous allez ajouter une nouvelle colonne concaténée pour créer un champ d'ID de session unique. Vous enrichirez ensuite vos données d'étiquette d'e-commerce avec une instruction de cas.
Créer une colonne pour un identifiant de session unique
Comme vous l'avez découvert, l'ensemble de données ne comprend pas de colonne pour les sessions de visiteur unique. Créez un identifiant unique pour chaque session en concaténant les champs fullVisitorID et visitId.
Cliquez sur New Step (Nouvelle étape).
Pour Transformation, saisissez concat, puis sélectionnez Merge columns (Fusionner les colonnes).
Pour Columns (Colonnes), sélectionnez fullVisitorId et visitId.
Pour New column name (Nom de la nouvelle colonne), saisissez unique_session_id (ID de session unique), conservez les valeurs par défaut pour les autres entrées et cliquez sur Add (Ajouter).
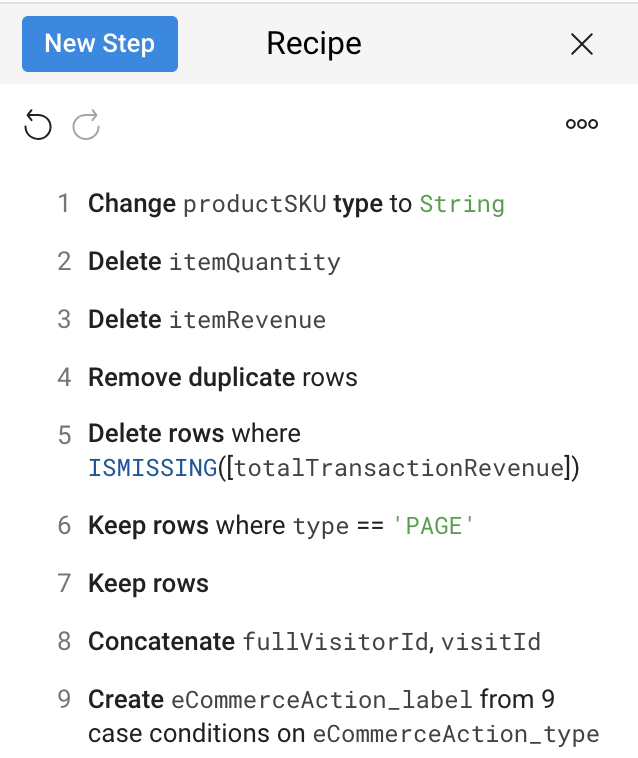
Créer une instruction de cas pour le type d'action d'e-commerce
Le champ eCommerceAction_type (type d'action d'e-commerce) est un entier qui établit une correspondance avec des actions d'e-commerce effectuées au cours de cette session, par exemple 3 = "Add to Cart" (Ajout au panier) ou 5 = "Check out" (Paiement). Créez une colonne de calcul établissant une correspondance avec le nombre entier.
Cliquez sur New Step (Nouvelle étape).
Dans le panneau Transformation, saisissez case (cas), puis sélectionnez Conditional column (Colonne conditionnelle).
Sélectionnez Case on single column (Cas sur une seule colonne) dans la liste déroulante.
Pour Column to evaluate (Colonne à évaluer), indiquez eCommerceAction_type.
À côté de Cases (X) (Cas [X]), cliquez sur Add (Ajouter) huit fois pour un total de neuf cas.
Pour chaque cas, indiquez les valeurs de mise en correspondance suivantes (en incluant les apostrophes) :
Valeur à comparer
Nouvelle valeur
1
"Click through of product lists" (Clic dans des listes de produits)
2
"Product detail views" (Vues de détails produit)
3
"Add product(s) to cart" (Ajout du/des produit(s) au panier)
4
"Remove product(s) from cart" (Suppression du/des produit(s) du panier)
5
"Check out" (Paiement)
6
"Completed purchase" (Achat réalisé)
7
"Refund of purchase" (Remboursement d'achat)
8
"Checkout options" (Options de paiement)
0
"Unknown" (Inconnu)
Conservez les valeurs par défaut des autres champs.
Pour New column name (Nom de la nouvelle colonne), saisissez eCommerceAction_label (Étiquette d'action d'e-commerce) et cliquez sur Add (Ajouter).
Examinez votre recette et comparez-la à cet exemple :
Tâche 7 : Exécuter un job Cloud Dataprep pour charger BigQuery
Lorsque vous êtes satisfait du flux, vous pouvez exécuter la recette de transformation en l'appliquant à votre ensemble de données source. Pour ce faire, vous devez exécuter et surveiller un job Cloud Dataprep (qui démarre et exécute un job Cloud Dataflow).
Sur la page Transformer (Transformateur), en haut à droite, cliquez sur Run (Exécuter).
Dans la section Publishing Actions (Actions de publication), pointez sur Create-CSV (Créer CSV), puis cliquez sur Edit (Modifier).
Sélectionnez BigQuery dans le panneau de gauche et accédez à votre ensemble de données d'e-commerce, puis cliquez sur Create a new table (Créer une table).
Nommez la table de résultats apparel_revenue (revenus pour l'habillement) et sélectionnez Drop the table every run (Supprimer la table à chaque exécution) dans le panneau de droite.
Cliquez sur Update (Mettre à jour).
Cliquez sur Exécuter.
Cliquez sur Job history (Historique des jobs) dans le panneau de gauche pour surveiller votre tâche Cloud Dataprep.
Patientez une à deux minutes, le temps que l'exécution de votre job se termine.
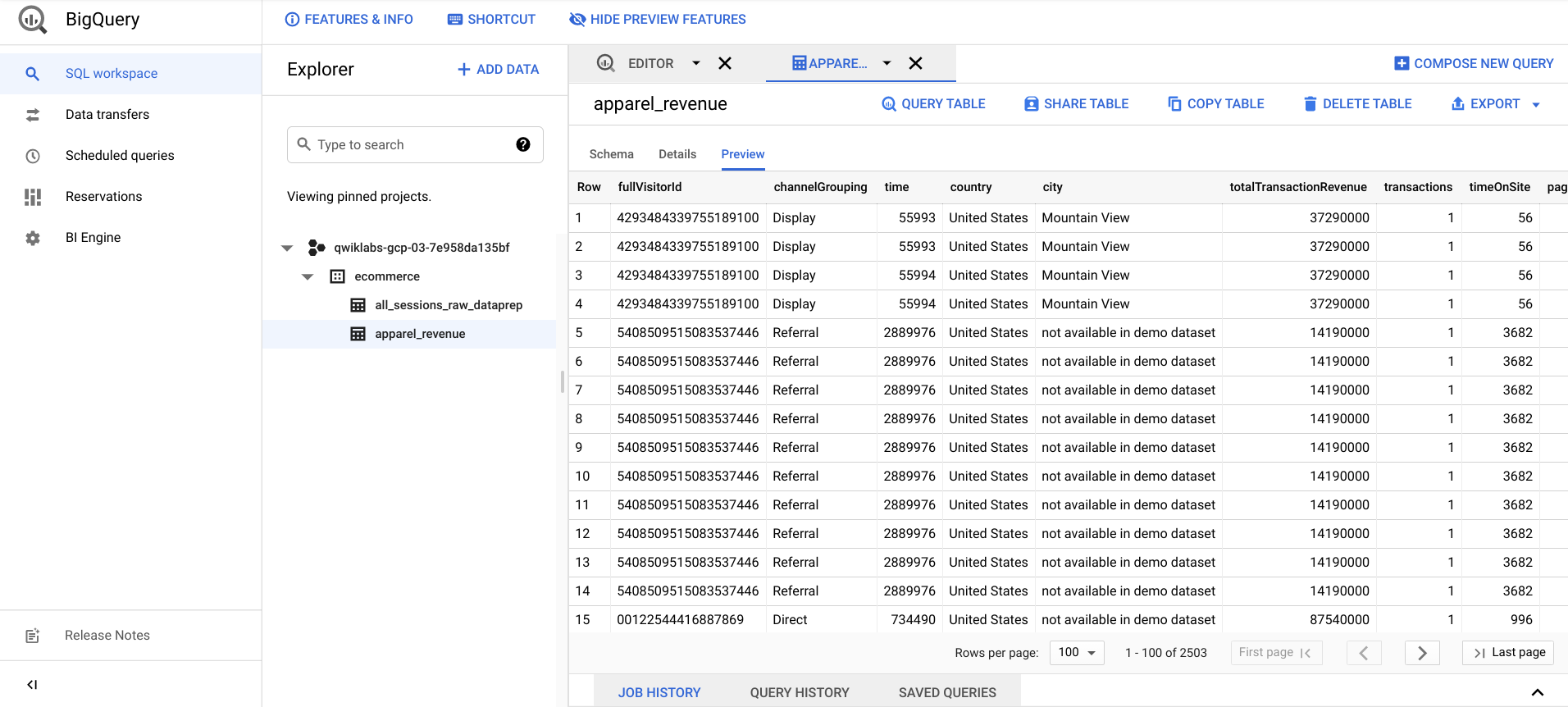
Une fois l'exécution de votre job Cloud Dataprep terminée, actualisez la page de BigQuery et vérifiez que la table de résultats apparel_revenue existe bien.
Sélectionnez apparel_revenue > Preview (Aperçu) et assurez-vous que vous disposez de données sur les revenus des transactions pour les produits d'habillement.
Félicitations !
Vous avez exploré votre ensemble de données d'e-commerce et créé un pipeline de transformation de données récurrentes avec Cloud Dataprep.
Vous possédez un compte Google Analytics et souhaitez interroger vos propres ensembles de données dans BigQuery ? Suivez ce guide de configuration de BigQuery Export.
Terminer l'atelier
Une fois l'atelier terminé, cliquez sur Terminer l'atelier. Google Cloud Skills Boost supprime les ressources que vous avez utilisées, puis efface le compte.
Si vous le souhaitez, vous pouvez noter l'atelier. Sélectionnez un nombre d'étoiles, saisissez un commentaire, puis cliquez sur Envoyer.
Le nombre d'étoiles correspond à votre degré de satisfaction :
1 étoile = très insatisfait(e)
2 étoiles = insatisfait(e)
3 étoiles = ni insatisfait(e), ni satisfait(e)
4 étoiles = satisfait(e)
5 étoiles = très satisfait(e)
Si vous ne souhaitez pas donner votre avis, vous pouvez fermer la boîte de dialogue.
Pour soumettre des commentaires, suggestions ou corrections, veuillez accéder à l'onglet Assistance.
Copyright 2020 Google LLC Tous droits réservés. Google et le logo Google sont des marques de Google LLC. Tous les autres noms d'entreprises et de produits peuvent être des marques des entreprises auxquelles ils sont associés.
Les ateliers créent un projet Google Cloud et des ressources pour une durée déterminée.
Les ateliers doivent être effectués dans le délai imparti et ne peuvent pas être mis en pause. Si vous quittez l'atelier, vous devrez le recommencer depuis le début.
En haut à gauche de l'écran, cliquez sur Démarrer l'atelier pour commencer.
Utilisez la navigation privée
Copiez le nom d'utilisateur et le mot de passe fournis pour l'atelier
Cliquez sur Ouvrir la console en navigation privée
Connectez-vous à la console
Connectez-vous à l'aide des identifiants qui vous ont été attribués pour l'atelier. L'utilisation d'autres identifiants peut entraîner des erreurs ou des frais.
Acceptez les conditions d'utilisation et ignorez la page concernant les ressources de récupération des données.
Ne cliquez pas sur Terminer l'atelier, à moins que vous n'ayez terminé l'atelier ou que vous ne vouliez le recommencer, car cela effacera votre travail et supprimera le projet.
Ce contenu n'est pas disponible pour le moment
Nous vous préviendrons par e-mail lorsqu'il sera disponible
Parfait !
Nous vous contacterons par e-mail s'il devient disponible
Un atelier à la fois
Confirmez pour mettre fin à tous les ateliers existants et démarrer celui-ci
Utilisez la navigation privée pour effectuer l'atelier
Ouvrez une fenêtre de navigateur en mode navigation privée pour effectuer cet atelier. Vous éviterez ainsi les conflits entre votre compte personnel et le compte temporaire de participant, qui pourraient entraîner des frais supplémentaires facturés sur votre compte personnel.
Dans cet atelier, nous allons nous servir de l'interface utilisateur de Cloud Dataprep afin de créer un pipeline de transformation de données d'e-commerce. Ce pipeline s'exécutera à intervalles planifiés et renverra les résultats dans BigQuery.
Durée :
0 min de configuration
·
Accessible pendant 90 min
·
Terminé après 90 min
 ), puis sélectionnez IAM et administration > IAM.
), puis sélectionnez IAM et administration > IAM.
 ) à côté de votre ID de projet, puis sélectionnez Créer un ensemble de données.
) à côté de votre ID de projet, puis sélectionnez Créer un ensemble de données.
 ).
).
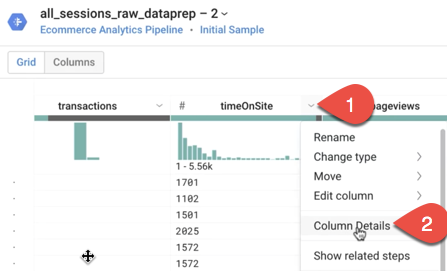
 , puis sélectionnez Change type > String (Changer de type > Chaîne).
, puis sélectionnez Change type > String (Changer de type > Chaîne).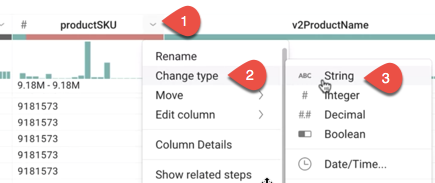
 ) en haut à droite et sélectionnez New Step (Nouvelle étape).
) en haut à droite et sélectionnez New Step (Nouvelle étape).