


始める前に
- ラボでは、Google Cloud プロジェクトとリソースを一定の時間利用します
- ラボには時間制限があり、一時停止機能はありません。ラボを終了した場合は、最初からやり直す必要があります。
- 画面左上の [ラボを開始] をクリックして開始します
Enable VPC flow logging on subnets and create instances
/ 50
Create exports and analyze flow logs in BigQuery
/ 50

このラボでは VPC Flow Logs について確認します。VPC Flow Logs は、VM インスタンスで送受信されるネットワーク フローを記録します。これらのログは、ネットワーク モニタリング、フォレンジック、リアルタイム セキュリティ分析のほか、費用の最適化にも使用できます。
ラボでは VPC フローロギングを有効にし、Cloud Logging を使用してログを表示します。次に、ネットワーク モニタリング、フォレンジック、リアルタイム セキュリティ分析を行い、最後に VPC フローロギングを無効にします。
このラボでは、次の方法について学びます。
各ラボでは、新しい Google Cloud プロジェクトとリソースセットを一定時間無料で利用できます。
シークレット ウィンドウを使用して Google Skills にログインします。
ラボのアクセス時間(例: 1:15:00)に注意し、時間内に完了できるようにしてください。
一時停止機能はありません。必要な場合はやり直せますが、最初からになります。
準備ができたら、[ラボを開始] をクリックします。
ラボの認証情報(ユーザー名とパスワード)をメモしておきます。この情報は、Google Cloud コンソールにログインする際に使用します。
[Google コンソールを開く] をクリックします。
[別のアカウントを使用] をクリックし、このラボの認証情報をコピーしてプロンプトに貼り付けます。 他の認証情報を使用すると、エラーや料金が発生します。
利用規約に同意し、再設定用のリソースページをスキップします。
Google Cloud Shell は、開発ツールと一緒に読み込まれる仮想マシンです。5 GB の永続ホーム ディレクトリが用意されており、Google Cloud で稼働します。
Google Cloud Shell を使用すると、コマンドラインで Google Cloud リソースにアクセスできます。
Google Cloud コンソールで、右上のツールバーにある [Cloud Shell をアクティブにする] ボタンをクリックします。
[続行] をクリックします。
環境がプロビジョニングされ、接続されるまでしばらく待ちます。接続した時点で認証が完了しており、プロジェクトに各自のプロジェクト ID が設定されます。次に例を示します。
gcloud は Google Cloud のコマンドライン ツールです。このツールは、Cloud Shell にプリインストールされており、タブ補完がサポートされています。
出力:
出力例:
出力:
出力例:
このタスクでは、2 つのサブネットでフローロギングを有効にします。ユーザー定義のカスタム ネットワークでフローロギングを有効にする方法もまったく同じです。サブネットの作成と同時にフローロギングを有効にすることもできます。
VPC フローロギングを有効にしたのは
ZONE_RESOURCE_POOL_EXHAUSTED エラーが発生した場合、gcloud コマンドでゾーンを更新し、再度実行してみてください。たとえば、us-central1-a が失敗する場合は、代わりに us-central1-b をお試しください。[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
このタスクでは、インスタンス間の接続テスト用にネットワーク トラフィックを作成します。
| インスタンス | 内部 IP | 外部 IP |
|---|---|---|
| default-ap-vm | ***** |
***** |
| default-eu-vm | ***** |
***** |
| default-us-vm | ***** |
***** |
default-us-vm インスタンスの行で、[SSH] をクリックします。これらのコマンドは以下のことを行います。
続いて、同じコマンドをもう一度実行します。ただし今度は、default-us-vm から default-eu-vm に ping を実行する代わりに、default-eu-vm から default-us-vm に ping を実行します。
default-eu-vm インスタンスの行で [SSH] をクリックします。Cloud コンソールに戻り、default-ap-vm インスタンスの行で [SSH] をクリックします。
SSH で接続したら、次のコマンドを実行します。
このタスクでは、すべてのプロジェクトの VPC Flow Logs を Cloud Logging で表示します。
Cloud コンソールで、ナビゲーション メニュー > [すべてのプロダクトを表示] をクリックします。[オブザーバビリティ] セクションで、[ロギング] > [ログ エクスプローラ] をクリックします。
[クエリ] パネルの [すべてのリソース] で、[サブネットワーク] をクリックし、[適用] をクリックします。
[すべてのログ名] で、[compute.googleapis.com/vpc_flows] をクリックし、[適用] をクリックします。
compute.googleapis.com%2Fvpc_flows を貼り付けてみてください。[クエリを実行] をクリックします。
VPC Flow Logs のエントリが [クエリ結果] パネルに表示されます。compute.googleapis.com/vpc_flows が表示されない場合は、このログタイプが表示されるまで数分待ちます。
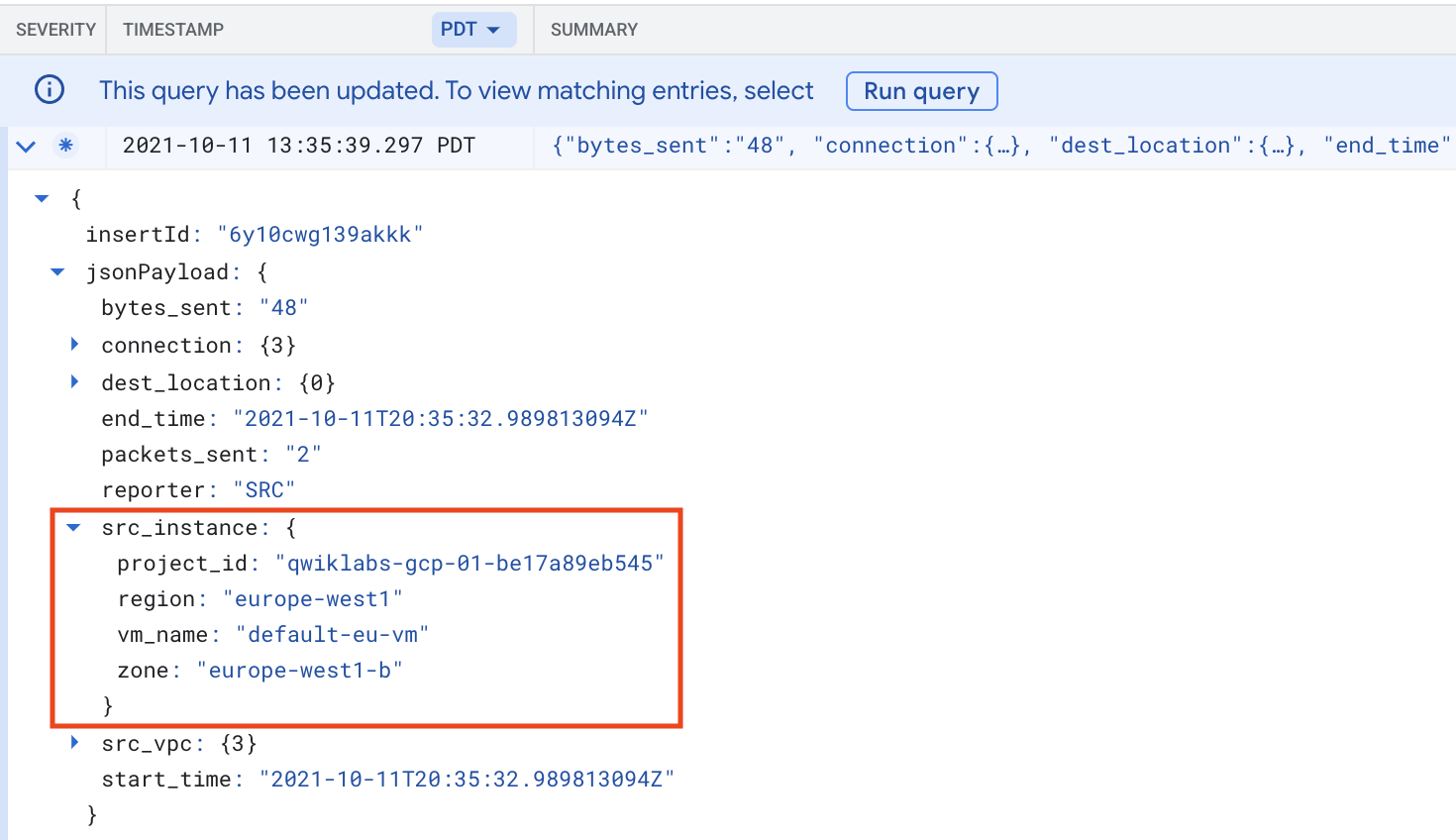
いずれかのログエントリを展開します。
そのログエントリ内で jsonPayload、connection の順に展開します。
jsonPayload フィールドのないログエントリもあります。他のログエントリを開いて、このフィールドのあるログエントリを見つけてください。接続に関する情報を調べます。送信元と宛先の両方のポートと IP アドレスが記録されていることに注目してください。
jsonPayload 内に src_instance があるログを見つけます。src_instance の情報を調べてください。
src_instance は、作成したいずれかのインスタンスか、外部 IP アドレスになります。外部 IP アドレスの場合は、VPC ネットワークの外部からのトラフィックがあったことになります。
このタスクでは、クエリビルダーを使用して高度なフィルタリングを実行します。また、特定の送信元 IP アドレスや宛先 IP アドレス、特定のポートとプロトコルのアクセスログを調べます。
高度なログフィルタは、プロジェクト内のすべてのログエントリのサブセットを指定するブール式です。たとえば次のようなことが可能です。
[クエリ] ボックスの内部をクリックします。
現在のクエリを削除して、次の内容を貼り付けます。<INSERT_PROJECT_ID> は Google Skills プロジェクト ID に置き換えます。
Internal_IP_Of_default_us_vm を default_us_vm インスタンスの内部 IP アドレス(先ほど記録しました)に置き換えてください。送信元 IP アドレスが default-us-vm インスタンスの内部 IP アドレスであるすべてのログエントリが表示されます。送信元インスタンスが default-us-vm であるエントリを表示する先ほどのフィルタと同じエントリが表示されるはずです。
src_ip を照合する行)を削除して以下の行に置き換えます。これにより、宛先ポートが 22(SSH)のエントリのみが表示されます。[クエリを実行] をクリックして結果を確認します。SSH で VM に 3 回接続したため、3 つのログが表示されます。
フィルタの最後の行を次のように変更します。これにより、宛先ポートが 80(HTTP)のトラフィックのみが表示されます。
[クエリを実行] をクリックして結果を確認します。
複数のポートを照合するには、ポートフィルタの末尾に OR を追加して最後の行を置き換えます。
いくつかのログエントリが表示される場合があります。これらは、host ユーティリティを使用して行った DNS 呼び出しに対応します。
ping を使用してインスタンスで ICMP トラフィックを生成しましたが、ICMP(プロトコル番号 1)のトラフィックを表示するフィルタを作成してもエントリは表示されません。興味のある方は試してみてください。このタスクでは、フィルタを作成して、VPC にアクセスしようとしている RDP トラフィックがないか調べます。
ここでは VPC ネットワーク内で Linux インスタンスを実行しているため、RDP トラフィックは存在しないはずです。しかし、デフォルト設定に含まれているファイアウォール ルールで任意の送信元からの RDP トラフィックが許可されているため、RDP プロトコルを使用してインターネットからサーバーに接続される可能性があります。
RDP トラフィックが見つかることはよくあります。これは、インターネット上に不要なトラフィックがいかに蔓延しているか、VPC ネットワークやファイアウォール ルールを正しく設定することがいかに重要かを示しています。
このラボでは、デフォルトの VPC をデフォルトのファイアウォール ルールのまま使用しています。これにより、これらのルールを調整して不要なトラフィックを除外しないとどうなるのかがわかります。
フローログは、Cloud Logging のエクスポート先としてサポートされている任意の宛先にエクスポートできます(Pub/Sub、BigQuery など)。エクスポートを作成すると、一致するログが、選択した宛先にエクスポートされます。エクスポートされるのはそれ以降のログのみで、既存のログはエクスポートされません。
ログを BigQuery にエクスポートすると、BigQuery の分析ツールを使用して分析できます。ログを Pub/Sub にエクスポートすると、他のアプリケーション、他のリポジトリ、またはサードパーティにストリーミングできます。
Cloud エクスポートを作成すると、そのエクスポートに現在のフィルタが適用されます。したがって、エクスポートされるのは、そのフィルタに一致するイベントだけです。たとえば、宛先ポート 3389 へのトラフィックのみを表示するフィルタを使用している場合は、そのフィルタに一致するトラフィックのみがエクスポートされます。
これにより、エクスポートされるデータの量を減らしたり(費用の節約になります)、データの内容に応じてエクスポートを使い分けたりできます。このラボではトラフィックの量が限られているため、フィルタをクリアしてすべてのログをエクスポートします。
flowlogs_dataset」と入力し、[データセットを作成] をクリックします。作成したシンク(FlowLogBQExport)が表示されているはずです。シンクが表示されない場合は、[ログルーター] をクリックします。
 )をクリックし、[シンクの詳細を表示する] を選択します。
)をクリックし、[シンクの詳細を表示する] を選択します。では、Pub/Sub へのエクスポートを作成してみましょう。
[ログルーターのシンク] ページが表示されます。作成したシンク(FlowLogsTopic)が表示されているはずです。シンクが表示されない場合は、[ログルーター] をクリックします。
そのエクスポートの作成時に存在していたフィルタが表示されます。
この新しい Pub/Sub トピックをサブスクライブすると、新しいログが届いたときに通知を受け取ることができます。これにより、ログをストリーミングして SIEM(セキュリティ情報およびイベント管理)ツールと統合できます。
SIEM ツールを使用すると、運用に関するリアルタイムの分析情報を得たり、強力な可視化機能を使用して監査レポートを作成したりできます。
このタスクでは、BigQuery でフローログを分析します。
compute_googleapis_com_vpc_flows_ で始まるテーブル名をクリックし、使用されているテーブルのスキーマと詳細を確認します。このクエリは、ポート 22 に接続するトラフィックに関する情報を返します。
数秒後に結果が表示されます。1 つまたは 2 つのエントリ(このラボで生成したアクティビティ)が表示されるはずです。BigQuery で表示されるのはエクスポートの作成以降のアクティビティのみです。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
このタスクでは、VPC フローロギングを無効にします。VPC フローロギングを無効にするには --no-enable-flow-logs オプションを使用します。
このラボでは、サブネットの VPC フローロギングを有効にし、Cloud Logging でログにアクセスしました。特定のサブネット、VM、ポート、プロトコルでログをフィルタしました。ネットワーク モニタリング、フォレンジック、リアルタイム セキュリティ分析も行いました。最後に、VPC フローロギングを無効にしました。
ラボが完了したら、[ラボを終了] をクリックします。ラボで使用したリソースが Google Skills から削除され、アカウントの情報も消去されます。
ラボの評価を求めるダイアログが表示されたら、星の数を選択してコメントを入力し、[送信] をクリックします。
星の数は、それぞれ次の評価を表します。
フィードバックを送信しない場合は、ダイアログ ボックスを閉じてください。
フィードバックやご提案の送信、修正が必要な箇所をご報告いただく際は、[サポート] タブをご利用ください。
Copyright 2026 Google LLC All rights reserved. Google および Google のロゴは、Google LLC の商標です。その他すべての社名および製品名は、それぞれ該当する企業の商標である可能性があります。



このコンテンツは現在ご利用いただけません
利用可能になりましたら、メールでお知らせいたします

ありがとうございます。
利用可能になりましたら、メールでご連絡いたします

1 回に 1 つのラボ
既存のラボをすべて終了して、このラボを開始することを確認してください