Cet atelier peut intégrer des outils d'IA pour vous accompagner dans votre apprentissage.
Présentation
Sans le matériel et l'infrastructure adaptés, stocker et interroger des ensembles de données volumineux peut s'avérer chronophage et coûteux. BigQuery est un entrepôt de données d'entreprise qui résout ce problème en permettant d'effectuer des requêtes SQL ultra-rapides grâce à la puissance de traitement de l'infrastructure de Google. Il vous suffit de transférer vos données dans BigQuery. Nous nous chargeons du reste. Vous pouvez contrôler l'accès au projet et à vos données en fonction des besoins de votre entreprise, par exemple en autorisant d'autres personnes à afficher vos données ou à les interroger.
Vous pouvez accéder à BigQuery via la console Google Cloud, l'outil de ligne de commande ou en appelant l'API REST BigQuery à l'aide de diverses bibliothèques clientes telles que Java, .NET ou Python. Plusieurs outils tiers permettent également d'interagir avec BigQuery, par exemple pour visualiser ou charger des données. Dans cet atelier, vous accéderez à BigQuery à l'aide de l'interface utilisateur Web.
Vous pouvez utiliser l'UI Web de BigQuery dans la console Cloud en tant qu'interface graphique pour réaliser des tâches telles qu'exécuter des requêtes, charger des données ou en exporter. Dans cet atelier pratique, vous allez apprendre à interroger des tables dans un ensemble de données public et à charger des exemples de données dans BigQuery via la console Google Cloud.
Objectifs
Dans cet atelier, vous allez apprendre à effectuer les tâches suivantes :
Interroger un ensemble de données public
Créer une table personnalisée
Charger des données dans une table
Interroger une table
Configurer vos environnements
Mettre en place l'atelier
Pour chaque atelier, nous vous attribuons un nouveau projet Google Cloud et un nouvel ensemble de ressources pour une durée déterminée, sans frais.
Connectez-vous à Google Skills dans une fenêtre de navigation privée.
Vérifiez le temps imparti pour l'atelier (par exemple : 01:15:00) : vous devez pouvoir le terminer dans ce délai.
Une fois l'atelier lancé, vous ne pourrez pas le mettre sur pause. Si nécessaire, vous pourrez le redémarrer, mais vous devrez tout reprendre depuis le début.
Lorsque vous êtes prêt, cliquez sur Démarrer l'atelier.
Notez vos identifiants pour l'atelier (Nom d'utilisateur et Mot de passe). Ils vous serviront à vous connecter à la console Google Cloud.
Cliquez sur Ouvrir la console Google.
Cliquez sur Utiliser un autre compte, puis copiez-collez les identifiants de cet atelier lorsque vous y êtes invité.
Si vous utilisez d'autres identifiants, des messages d'erreur s'afficheront ou des frais seront facturés.
Acceptez les conditions d'utilisation et ignorez la page concernant les ressources de récupération des données.
Ouvrir la console BigQuery
Dans la console Google Cloud, sélectionnez le menu de navigation > BigQuery.
Le message Bienvenue sur BigQuery dans la console Cloud s'affiche. Il contient un lien vers le guide de démarrage rapide et liste les mises à jour de l'interface utilisateur.
Cliquez sur Done (OK).
Tâche 1 : Interroger un ensemble de données public
Dans cette tâche, vous allez charger dans BigQuery un ensemble de données public (USA Names), puis interroger cet ensemble de données pour déterminer les prénoms les plus couramment donnés aux États-Unis entre 1910 et 2013.
Charger l'ensemble de données USA Names
Dans le volet "Explorateur", indiquez usa_names dans Saisissez un terme à rechercher, puis appuyez sur Entrée.
Cliquez sur RECHERCHER DANS TOUS LES PROJETS.
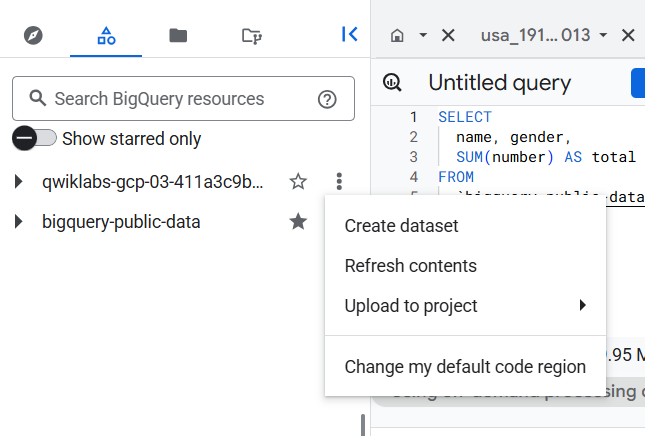
Dans le volet "Explorateur", pointez sur bigquery-public-data, puis cliquez sur Ajouter aux favoris.
Dans le champ Saisissez un terme à rechercher, indiquez bigquery-public-data.
Tous les ensembles de données du projet s'affichent.
Remarque : Si le nouveau projet bigquery-public-data n'apparaît pas dans le volet "Explorateur", cliquez sur + AJOUTER DES DONNÉES > Ajouter un projet aux favoris en saisissant son nom > Ajouter un projet aux favoris (saisissez "bigquery-public-data"), puis cliquez sur AJOUTER AUX FAVORIS.
Sélectionnez Développer le nœud pour bigquery-public-data.
Faites défiler la liste des ensembles de données publics en cliquant sur Plus de résultats jusqu'à trouver usa_names.
Cliquez sur usa_names pour développer l'ensemble de données.
Cliquez sur la table usa_1910_2013 pour l'ouvrir.
Interroger l'ensemble de données USA Names
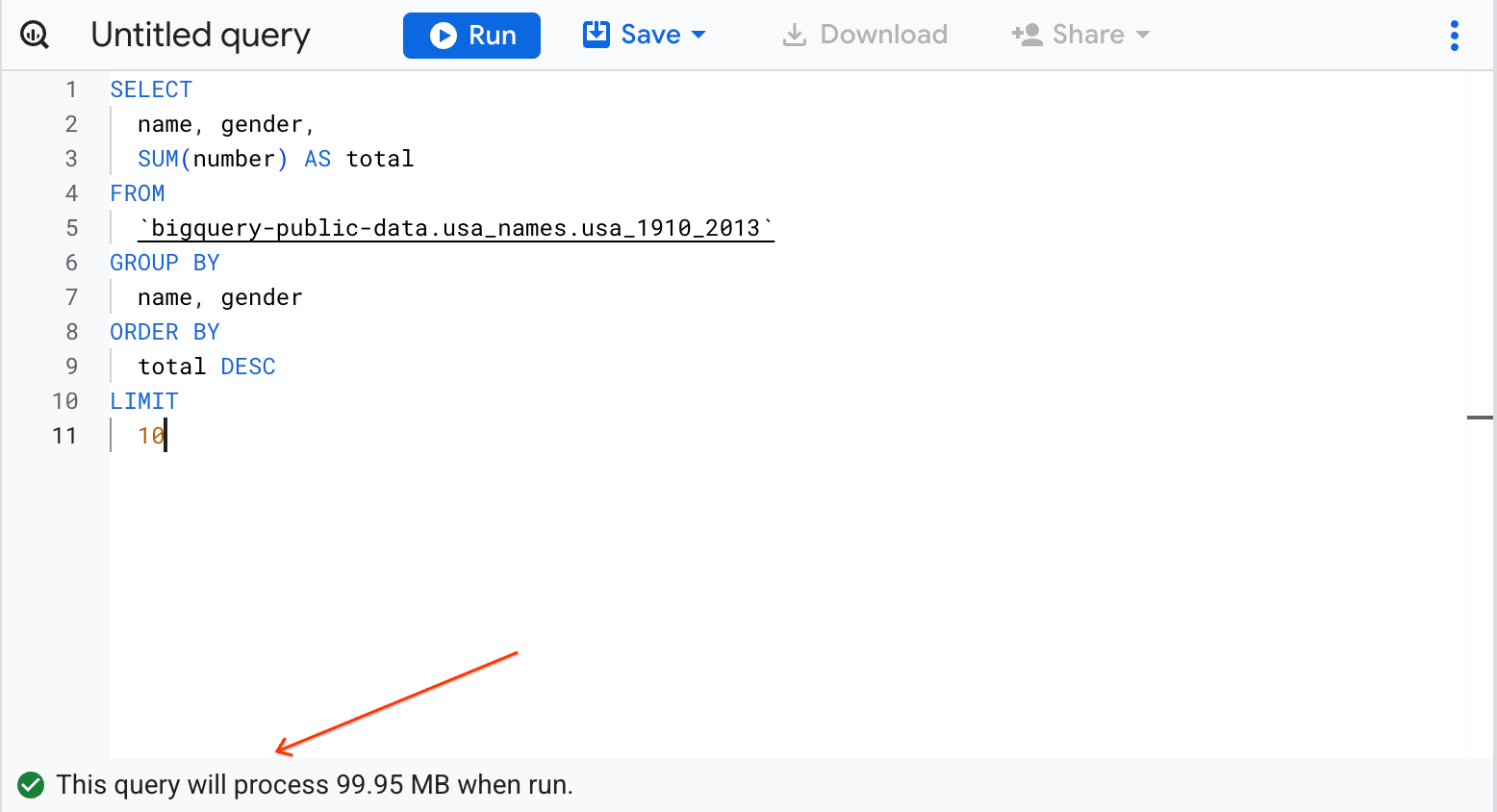
Vous allez interroger l'ensemble de données bigquery-public-data.usa_names.usa_1910_2013 afin d'extraire le prénom et le genre des bébés, puis afficher les 10 premiers prénoms par ordre décroissant.
Cliquez sur Interroger, puis sélectionnez Dans un nouvel onglet.
Copiez et collez la requête suivante dans la zone de texte de l'éditeur de requête, en remplaçant la requête existante :
SELECT
name, gender,
SUM(number) AS total
FROM
`bigquery-public-data.usa_names.usa_1910_2013`
GROUP BY
name, gender
ORDER BY
total DESC
LIMIT
10
En haut à droite de la fenêtre, consultez l'outil de validation de requête.
BigQuery affiche une coche verte si la requête est valide. Dans le cas contraire, un point d'exclamation rouge apparaît. Lorsque la requête est correctement formulée, l'outil de validation indique également la quantité de données à traiter lors de son exécution. Vous pourrez ainsi déterminer le coût d'exécution de la requête.
Cliquez sur Exécuter.
Les résultats de la requête s'affichent sous l'éditeur de requête. En haut de la section des résultats, BigQuery indique le temps écoulé et la quantité de données traitées par la requête. La table contenant les résultats de la requête figure sous ces informations. La ligne d'en-tête contient le nom de la colonne indiqué dans le champ GROUP BY (Grouper par) de la requête.
Tâche 2 : Créer une table personnalisée
Dans cette tâche, vous allez créer une table personnalisée, y charger des données et y exécuter une requête.
Télécharger les données sur votre ordinateur local
Le fichier que vous téléchargez contient environ 7 Mo de données correspondant aux prénoms populaires donnés aux bébés. Il est fourni par l'Administration de la sécurité sociale des États-Unis.
Téléchargez le fichier ZIP des prénoms de bébé sur votre ordinateur local.
Remarque : Si ce lien ne fonctionne pas, copiez le fichier ZIP depuis les ressources destinées aux participants disponibles dans le volet de gauche du guide d'instruction.
Décompressez le fichier sur votre ordinateur.
Ouvrez le fichier yob2014.txt pour obtenir un aperçu des données. Il s'agit d'un fichier CSV contenant les trois colonnes suivantes : prénom, genre (M ou F) et nombre d'enfants portant ce prénom. Le fichier ne comporte pas de ligne d'en-tête.
Notez l'emplacement du fichier yob2014.txt pour pouvoir le retrouver plus tard.
Tâche 3 : Créer un ensemble de données
Dans cette tâche, vous allez créer un ensemble de données pour y stocker votre table, ajouter des données à votre projet, puis créer la table de données que vous allez interroger.
Les ensembles de données vous permettent de contrôler l'accès aux tables et aux vues d'un projet. Dans cet atelier, vous n'allez utiliser qu'une table, mais vous aurez tout de même besoin d'un ensemble de données pour la stocker.
Revenez à la console Cloud. Dans le volet Explorateur, effacez bigquery-public-data dans le champ "Saisissez un terme à rechercher".
Remarque : Si vous avez ajouté un projet aux favoris en saisissant son nom, faites défiler la page vers le haut jusqu'aux premiers résultats de recherche.
Cliquez sur l'ID de votre projet (qui commence par "qwiklabs").
Cliquez sur les trois points à côté de l'ID de votre projet, puis sur Créer un ensemble de données.
Sur la page Créer l'ensemble de données :
Pour ID de l'ensemble de données, saisissez babynames.
Pour Emplacement des données, sélectionnez US (plusieurs régions aux États-Unis).
Pour Expiration de la table par défaut, conservez la valeur par défaut.
Pour Chiffrement, conservez la valeur par défaut.
Cliquez sur Créer l'ensemble de données en bas du volet.
Tâche 4 : Charger les données dans une table
Dans cette tâche, vous allez charger des données dans la table que vous avez créée.
Dans le volet "Explorateur", développez l'ensemble de données associé à l'ID de votre projet.
Cliquez sur les trois points situés à côté de babynames, puis sur Créer une table.
Utilisez les valeurs par défaut pour tous les paramètres, sauf indication contraire.
Sur la page Créer une table :
Sous Source, cliquez sur Importer depuis le menu déroulant Créer une table à partir de.
Sous Sélectionner un fichier, cliquez sur Parcourir, accédez au fichier yob2014.txt, puis cliquez sur Ouvrir.
Sous Format de fichier, sélectionnez CSV dans le menu déroulant.
Dans le champ Nom de la table, saisissez names_2014.
Dans la section Schéma, cliquez sur le bouton Modifier sous forme de texte et collez la définition de schéma suivante dans la zone de texte.
name:string,gender:string,count:integer
Cliquez sur Créer la table en bas de la fenêtre.
Remarque : Même si une erreur indiquant l'échec de l'importation s'affiche, vos données doivent avoir été importées. Pour faire disparaître l'erreur, cliquez sur Fermer, puis sur Annuler pour quitter la boîte de dialogue d'importation et enfin sur Oui, quitter lorsqu'un avertissement indique que vos modifications ne seront pas enregistrées.
Prévisualiser la table
Dans le volet "Explorateur", sélectionnez babynames > names_2014.
Dans le volet des détails, cliquez sur l'onglet Aperçu.
Tâche 5 : Interroger la table
Maintenant que vous avez chargé des données dans votre table, vous pouvez exécuter des requêtes sur celle-ci. Le processus est identique à l'exemple précédent, sauf que cette fois, vous interrogez votre table au lieu d'une table publique.
Dans l'éditeur de requête, cliquez sur Créer une requête SQL.
Copiez et collez la requête suivante dans la zone Éditeur de requête. Cette requête permet de récupérer les cinq premiers prénoms masculins donnés aux enfants nés aux États-Unis en 2014.
Remarque : L'éditeur est sensible à la casse lorsque le texte est entre guillemets simples (').Vous devez donc vous assurer que les noms de l'ensemble de données et de la table que vous avez créés sont identiques.
SELECT
name, count
FROM
`babynames.names_2014`
WHERE
gender = 'M'
ORDER BY count DESC LIMIT 5
Cliquez sur Exécuter. Les résultats sont affichés sous la fenêtre de requête.
Félicitations !
Vous avez interrogé un ensemble de données public, créé une table personnalisée sur laquelle vous avez chargé des données, puis exécuté une requête.
Terminer l'atelier
Une fois l'atelier terminé, cliquez sur Terminer l'atelier. Google Skills supprime les ressources que vous avez utilisées, puis efface le compte.
Si vous le souhaitez, vous pouvez noter l'atelier. Sélectionnez un nombre d'étoiles, saisissez un commentaire, puis cliquez sur Envoyer.
Voici à quoi correspond le nombre d'étoiles que vous pouvez attribuer à un atelier :
1 étoile = très insatisfait(e)
2 étoiles = insatisfait(e)
3 étoiles = ni insatisfait(e), ni satisfait(e)
4 étoiles = satisfait(e)
5 étoiles = très satisfait(e)
Si vous ne souhaitez pas donner votre avis, vous pouvez fermer la boîte de dialogue.
Pour soumettre des commentaires, suggestions ou corrections, veuillez accéder à l'onglet Assistance.
Copyright 2026 Google LLC Tous droits réservés. Google et le logo Google sont des marques de Google LLC. Tous les autres noms de société et de produit peuvent être des marques des sociétés auxquelles ils sont associés.
Avant de commencer
Les ateliers créent un projet Google Cloud et des ressources pour une durée déterminée.
Les ateliers doivent être effectués dans le délai imparti et ne peuvent pas être mis en pause. Si vous quittez l'atelier, vous devrez le recommencer depuis le début.
En haut à gauche de l'écran, cliquez sur Démarrer l'atelier pour commencer.
Utilisez la navigation privée
Copiez le nom d'utilisateur et le mot de passe fournis pour l'atelier
Cliquez sur Ouvrir la console en navigation privée
Connectez-vous à la console
Connectez-vous à l'aide des identifiants qui vous ont été attribués pour l'atelier. L'utilisation d'autres identifiants peut entraîner des erreurs ou des frais.
Acceptez les conditions d'utilisation et ignorez la page concernant les ressources de récupération des données.
Ne cliquez pas sur Terminer l'atelier, à moins que vous n'ayez terminé l'atelier ou que vous ne vouliez le recommencer, car cela effacera votre travail et supprimera le projet.
Ce contenu n'est pas disponible pour le moment
Nous vous préviendrons par e-mail lorsqu'il sera disponible
Parfait !
Nous vous contacterons par e-mail s'il devient disponible
Un atelier à la fois
Confirmez pour mettre fin à tous les ateliers existants et démarrer celui-ci
Utilisez la navigation privée pour effectuer l'atelier
Le meilleur moyen d'exécuter cet atelier consiste à utiliser une fenêtre de navigation privée. Vous éviterez ainsi les conflits entre votre compte personnel et le compte temporaire de participant, qui pourraient entraîner des frais supplémentaires facturés sur votre compte personnel.
Prêt à analyser des ensembles de données volumineux dans le cloud ? Dans cet atelier sur les bases de BigQuery, vous allez charger et analyser un ensemble de données public avec SQL.
Durée :
0 min de configuration
·
Accessible pendant 60 min
·
Terminé après 60 min
 Ajouter aux favoris.
Ajouter aux favoris.