Présentation
Dans cet atelier, vous êtes à la tête d'une flotte de taxis à New York et vous souhaitez surveiller les performances de votre entreprise en temps réel. Vous allez créer un pipeline de données en flux continu pour capturer, entre autres, les revenus des taxis, le nombre de passagers ou encore l'état des trajets, et visualiser les résultats dans un tableau de bord de gestion.
Objectifs
Dans cet atelier, vous allez apprendre à :
- créer un job Dataflow à partir d'un modèle ;
- transférer en flux continu un pipeline Dataflow vers BigQuery ;
- surveiller un pipeline Dataflow dans BigQuery ;
- analyser les résultats avec SQL ;
- visualiser les métriques clés dans Looker Studio.
Préparation
Pour chaque atelier, nous vous attribuons un nouveau projet Google Cloud et un nouvel ensemble de ressources pour une durée déterminée, sans frais.
-
Cliquez sur le bouton Démarrer l'atelier. Si l'atelier est payant, un pop-up s'affiche pour vous permettre de sélectionner un mode de paiement.
Sur la gauche, vous trouverez le panneau Détails concernant l'atelier, qui contient les éléments suivants :
- Le bouton Ouvrir la console Google Cloud
- Le temps restant
- Les identifiants temporaires que vous devez utiliser pour cet atelier
- Des informations complémentaires vous permettant d'effectuer l'atelier
-
Cliquez sur Ouvrir la console Google Cloud (ou effectuez un clic droit et sélectionnez Ouvrir le lien dans la fenêtre de navigation privée si vous utilisez le navigateur Chrome).
L'atelier lance les ressources, puis ouvre la page Se connecter dans un nouvel onglet.
Conseil : Réorganisez les onglets dans des fenêtres distinctes, placées côte à côte.
Remarque : Si la boîte de dialogue Sélectionner un compte s'affiche, cliquez sur Utiliser un autre compte.
-
Si nécessaire, copiez le nom d'utilisateur ci-dessous et collez-le dans la boîte de dialogue Se connecter.
{{{user_0.username | "Username"}}}
Vous trouverez également le nom d'utilisateur dans le panneau Détails concernant l'atelier.
-
Cliquez sur Suivant.
-
Copiez le mot de passe ci-dessous et collez-le dans la boîte de dialogue Bienvenue.
{{{user_0.password | "Password"}}}
Vous trouverez également le mot de passe dans le panneau Détails concernant l'atelier.
-
Cliquez sur Suivant.
Important : Vous devez utiliser les identifiants fournis pour l'atelier. Ne saisissez pas ceux de votre compte Google Cloud.
Remarque : Si vous utilisez votre propre compte Google Cloud pour cet atelier, des frais supplémentaires peuvent vous être facturés.
-
Accédez aux pages suivantes :
- Acceptez les conditions d'utilisation.
- N'ajoutez pas d'options de récupération ni d'authentification à deux facteurs (ce compte est temporaire).
- Ne vous inscrivez pas à des essais sans frais.
Après quelques instants, la console Cloud s'ouvre dans cet onglet.
Remarque : Pour afficher un menu contenant la liste des produits et services Google Cloud, cliquez sur le menu de navigation en haut à gauche, ou saisissez le nom du service ou du produit dans le champ Recherche.

Activer Google Cloud Shell
Google Cloud Shell est une machine virtuelle qui contient de nombreux outils pour les développeurs. Elle comprend un répertoire d'accueil persistant de 5 Go et s'exécute sur Google Cloud.
Google Cloud Shell vous permet d'accéder à vos ressources Google Cloud grâce à une ligne de commande.
-
Dans la barre d'outils située en haut à droite dans la console Cloud, cliquez sur le bouton "Ouvrir Cloud Shell".

-
Cliquez sur Continuer.
Le provisionnement et la connexion à l'environnement prennent quelques instants. Une fois connecté, vous êtes en principe authentifié et le projet est défini sur votre ID_PROJET. Par exemple :

gcloud est l'outil de ligne de commande pour Google Cloud. Il est préinstallé sur Cloud Shell et permet la complétion par tabulation.
- Vous pouvez lister les noms des comptes actifs à l'aide de cette commande :
gcloud auth list
Résultat :
Credentialed accounts:
- @.com (active)
Exemple de résultat :
Credentialed accounts:
- google1623327_student@qwiklabs.net
- Vous pouvez lister les ID de projet à l'aide de cette commande :
gcloud config list project
Résultat :
[core]
project =
Exemple de résultat :
[core]
project = qwiklabs-gcp-44776a13dea667a6
Remarque : Pour consulter la documentation complète sur gcloud, accédez au guide de présentation de la gcloud CLI.
Tâche 1 : Créer un ensemble de données BigQuery
Dans cette tâche, vous allez créer l'ensemble de données taxirides. Pour cela, vous pouvez utiliser Google Cloud Shell ou la console Google Cloud.
Dans cet atelier, vous allez utiliser un échantillon de l'ensemble de données ouvert de la NYC Taxi & Limousine Commission. Ce petit fichier CSV (valeurs séparées par des virgules) servira à simuler les mises à jour périodiques des données des taxis.
BigQuery est un entrepôt de données sans serveur. Les tables BigQuery sont organisées dans des ensembles de données. Au cours de cet atelier, les données des taxis seront transférées du fichier autonome via Dataflow afin d'être stockées dans BigQuery. Avec cette configuration, tout nouveau fichier de données placé dans le bucket Cloud Storage source sera automatiquement chargé.
Utilisez l'une des options suivantes pour créer l'ensemble de données BigQuery :
Option 1 : Outil de ligne de commande
- Dans Cloud Shell (
 ), exécutez la commande suivante pour créer l'ensemble de données
), exécutez la commande suivante pour créer l'ensemble de données taxirides :
bq --location={{{project_0.default_region|Region}}} mk taxirides
- Exécutez cette commande pour créer la table
taxirides.realtime (schéma vide dans lequel envoyer les données en flux continu plus tard).
bq --location={{{project_0.default_region|Region}}} mk \
--time_partitioning_field timestamp \
--schema ride_id:string,point_idx:integer,latitude:float,longitude:float,\
timestamp:timestamp,meter_reading:float,meter_increment:float,ride_status:string,\
passenger_count:integer -t taxirides.realtime
Option 2 : UI de la console BigQuery
Remarque : Ignorez ces étapes si vous avez déjà créé les tables à l'aide de la ligne de commande.
-
Dans la console Google Cloud, accédez au menu de navigation ( ), puis cliquez sur BigQuery.
), puis cliquez sur BigQuery.
-
Si la boîte de dialogue de bienvenue s'affiche, cliquez sur OK.
-
Cliquez sur Afficher les actions ( ) à côté de l'ID de votre projet, puis sur Créer un ensemble de données.
) à côté de l'ID de votre projet, puis sur Créer un ensemble de données.
-
Dans le champ "ID de l'ensemble de données", saisissez taxirides.
-
Dans "Emplacement des données", sélectionnez :
{{{project_0.default_region|Region}}}
Cliquez ensuite sur Créer l'ensemble de données.
-
Dans le volet "Explorateur", cliquez sur Développer le nœud (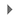 ) pour afficher le nouvel ensemble de données "taxirides".
) pour afficher le nouvel ensemble de données "taxirides".
-
Cliquez sur Afficher les actions () à côté de l'ensemble de données taxirides, puis sur Ouvrir.
-
Cliquez sur Créer une table.
-
Dans "Table", saisissez realtime.
-
Pour le schéma, cliquez sur Modifier sous forme de texte et collez ce qui suit :
ride_id:string,
point_idx:integer,
latitude:float,
longitude:float,
timestamp:timestamp,
meter_reading:float,
meter_increment:float,
ride_status:string,
passenger_count:integer
-
Dans le champ Paramètres de partitionnement et de clustering, sélectionnez code temporel.
-
Cliquez sur Créer une table.
Tâche 2 : Copier les artefacts d'atelier requis
Dans cette tâche, vous allez déplacer les fichiers requis vers votre projet.
Cloud Storage vous permet de stocker et de récupérer autant de données que vous le souhaitez, à tout moment et à l'échelle mondiale. Vous pouvez utiliser Cloud Storage dans diverses situations, par exemple pour diffuser le contenu d'un site Web, stocker des données pour l'archivage et la reprise après sinistre ou distribuer des objets de données volumineux aux utilisateurs via le téléchargement direct.
Un bucket Cloud Storage a été créé pour vous lors du démarrage de l'atelier.
- Dans Cloud Shell (), exécutez les commandes suivantes pour déplacer les fichiers nécessaires au job Dataflow.
gcloud storage cp gs://cloud-training/bdml/taxisrcdata/schema.json gs://{{{project_0.project_id|Project_ID}}}-bucket/tmp/schema.json
gcloud storage cp gs://cloud-training/bdml/taxisrcdata/transform.js gs://{{{project_0.project_id|Project_ID}}}-bucket/tmp/transform.js
gcloud storage cp gs://cloud-training/bdml/taxisrcdata/rt_taxidata.csv gs://{{{project_0.project_id|Project_ID}}}-bucket/tmp/rt_taxidata.csv
Tâche 3 : Configurer un pipeline Dataflow
Dans cette tâche, vous allez configurer un pipeline de flux de données pour lire les fichiers de votre bucket Cloud Storage et écrire les données dans BigQuery.
Dataflow est une solution sans serveur permettant d'analyser des données.
Redémarrer la connexion à l'API Dataflow
- Dans Cloud Shell, exécutez les commandes suivantes pour vous assurer que l'API Dataflow est bien activée dans votre projet.
gcloud services disable dataflow.googleapis.com
gcloud services enable dataflow.googleapis.com
Créer un pipeline de flux de données
-
Dans la console Cloud, accédez au menu de navigation () et cliquez sur Afficher tous les produits > Analyse > Dataflow.
-
Dans la barre de menu supérieure, cliquez sur Créer un job à partir d'un modèle.
-
Saisissez streaming-taxi-pipeline dans le champ "Nom du job" de votre job Dataflow.
-
Dans Point de terminaison régional, sélectionnez :
{{{project_0.default_region|Region}}}
- Dans Modèle Dataflow, sélectionnez le modèle Cloud Storage Text to BigQuery (Stream) sous Process Data Continuously (stream).
Remarque : Veillez à sélectionner l'option de modèle correspondant aux paramètres listés ci-dessous.
- Dans Fichier(s) d'entrée Cloud Storage, collez ou saisissez la commande suivante :
{{{project_0.project_id|Project_ID}}}-bucket/tmp/rt_taxidata.csv
- Pour l'emplacement Cloud Storage de votre fichier de schéma BigQuery, décrit comme fichier JSON, collez ou saisissez la commande suivante :
{{{project_0.project_id|Project_ID}}}-bucket/tmp/schema.json
- Dans Table BigQuery de sortie, collez ou saisissez la commande suivante :
{{{project_0.project_id|Project_ID}}}:taxirides.realtime
- Pour le répertoire temporaire pour le chargement dans BigQuery, collez ou saisissez la commande suivante :
{{{project_0.project_id|Project_ID}}}-bucket/tmp
-
Cliquez sur Paramètres obligatoires.
-
Pour l'emplacement temporaire utilisé pour écrire des fichiers temporaires, collez ou saisissez la commande suivante :
{{{project_0.project_id|Project_ID}}}-bucket/tmp
- Pour le chemin d'accès aux fonctions JavaScript définies par l'utilisateur dans Cloud Storage, collez ou saisissez la commande suivante :
{{{project_0.project_id|Project_ID}}}-bucket/tmp/transform.js
- Dans Nom des fonctions JavaScript définies par l'utilisateur, collez ou saisissez la commande suivante :
transform
-
Dans Nombre maximal de nœuds de calcul, saisissez 2.
-
Dans Nombre de nœuds de calcul, saisissez 1.
-
Décochez Utiliser le type de machine par défaut.
-
Sous Usage général, sélectionnez les options suivantes :
Série : E2
Type de machine : e2-medium (2 vCPU, 4 Go de mémoire)
- Cliquez sur Exécuter le job.
Un nouveau job en flux continu se lance alors. Une représentation visuelle du pipeline de données apparaît. Le transfert des données vers BigQuery commencera au bout de trois à cinq minutes.
Remarque : Si le job Dataflow échoue la première fois, recréez un modèle de job avec un nouveau nom de job et exécutez le job.
Tâche 4 : Analyser les données des taxis à l'aide de BigQuery
Dans cette tâche, vous allez analyser les données en cours de diffusion.
-
Dans la console Cloud, accédez au menu de navigation (), puis cliquez sur BigQuery.
-
Si la boîte de dialogue de bienvenue s'affiche, cliquez sur OK.
-
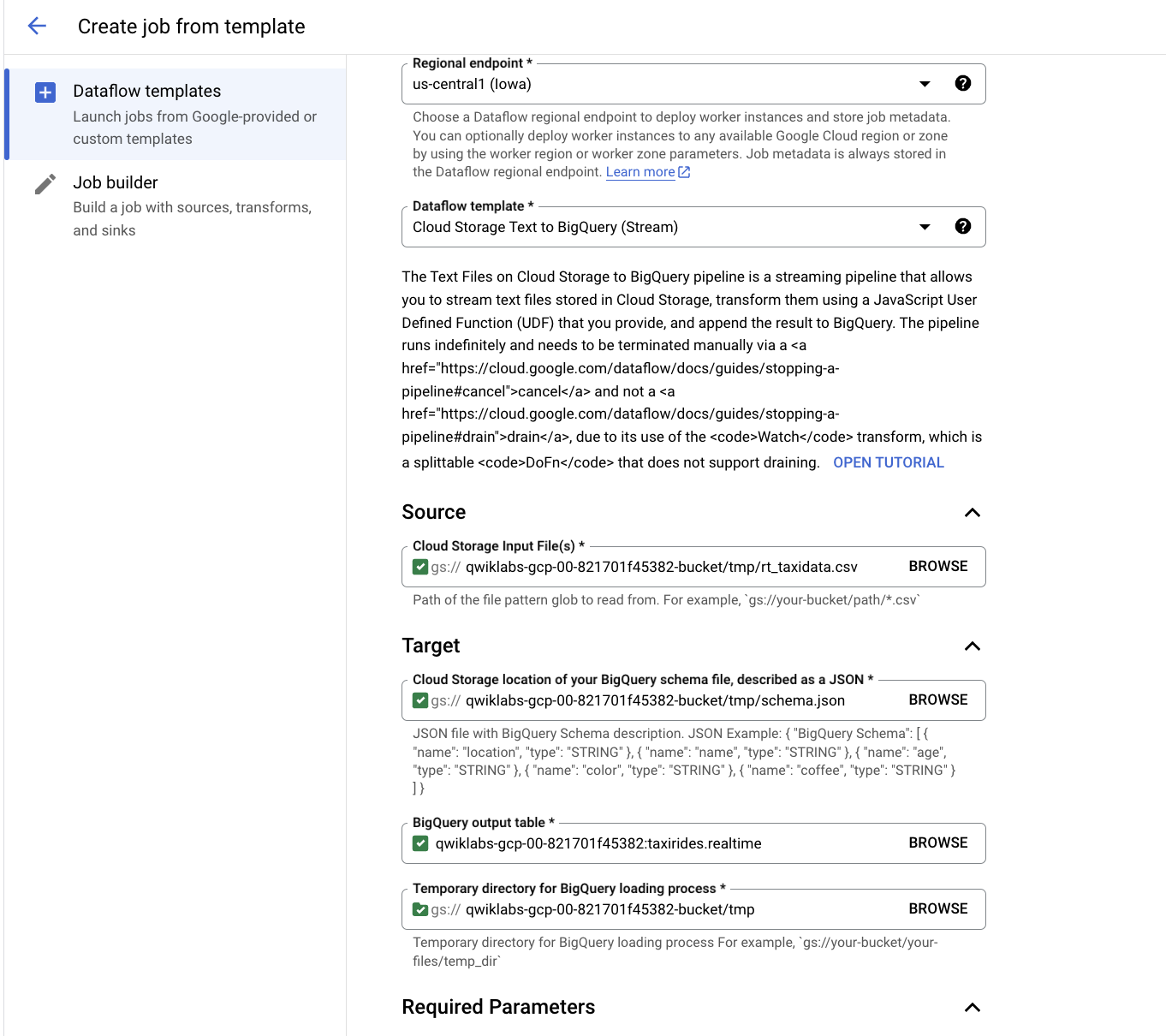
Dans l'éditeur de requête, saisissez la requête suivante, puis cliquez sur Exécuter :
SELECT * FROM taxirides.realtime LIMIT 10
Remarque : Si aucun enregistrement n'est renvoyé, attendez une minute, puis relancez la requête ci-dessus (il faut trois à cinq minutes à Dataflow pour configurer le flux de données).
Le résultat doit ressembler à ce qui suit : 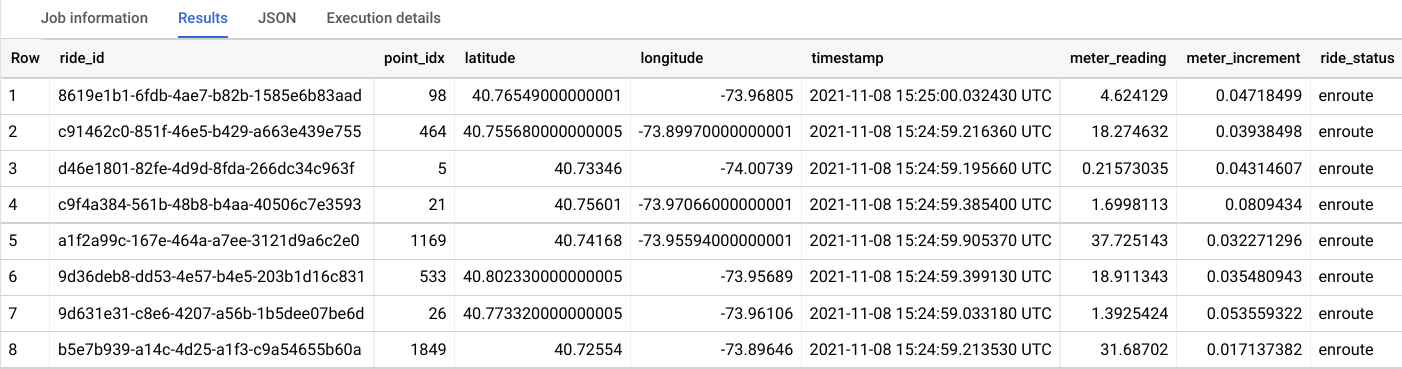
Tâche 5 : Effectuer des agrégations sur le flux pour générer des rapports
Dans cette tâche, vous allez calculer des agrégations sur le flux pour générer des rapports.
-
Dans l'éditeur de requête, effacez la requête existante.
-
Copiez et collez la requête suivante, puis cliquez sur Exécuter.
WITH streaming_data AS (
SELECT
timestamp,
TIMESTAMP_TRUNC(timestamp, HOUR, 'UTC') AS hour,
TIMESTAMP_TRUNC(timestamp, MINUTE, 'UTC') AS minute,
TIMESTAMP_TRUNC(timestamp, SECOND, 'UTC') AS second,
ride_id,
latitude,
longitude,
meter_reading,
ride_status,
passenger_count
FROM
taxirides.realtime
ORDER BY timestamp DESC
LIMIT 1000
)
# calculate aggregations on stream for reporting:
SELECT
ROW_NUMBER() OVER() AS dashboard_sort,
minute,
COUNT(DISTINCT ride_id) AS total_rides,
SUM(meter_reading) AS total_revenue,
SUM(passenger_count) AS total_passengers
FROM streaming_data
GROUP BY minute, timestamp
Remarque : Assurez-vous que Dataflow enregistre bien les données dans BigQuery avant de passer à la tâche suivante.
Le résultat affiche des métriques clés, à la minute près, à chaque fois qu'un taxi dépose des clients.
-
Cliquez sur Enregistrer > Enregistrer la requête.
-
Dans le champ Nom de la boîte de dialogue "Enregistrer la requête", saisissez Ma requête enregistrée.
-
Dans Région, assurez-vous que la région correspond à la région de l'atelier Qwiklabs.
-
Cliquez sur Enregistrer.
Tâche 6 : Arrêter la tâche Dataflow
Dans cette tâche, vous allez arrêter la tâche Dataflow afin de libérer des ressources pour votre projet.
-
Dans la console Cloud, accédez au menu de navigation () et cliquez sur Afficher tous les produits > Analyse > Dataflow.
-
Cliquez sur streaming-taxi-pipeline ou le nom de la nouvelle tâche.
-
Cliquez sur Arrêter, puis sélectionnez Annuler > Arrêter la tâche.
Tâche 7 : Créer un tableau de bord en temps réel
Dans cette tâche, vous allez créer un tableau de bord en temps réel pour visualiser les données.
-
Dans la console Cloud, accédez au menu de navigation (), puis cliquez sur BigQuery.
-
Dans le volet "Explorateur", développez l'ID de votre projet.
-
Développez la section Requêtes, puis cliquez sur Ma requête enregistrée.
Votre requête est chargée dans l'éditeur de requête.
-
Cliquez sur Exécuter.
-
Dans la section "Résultats de la requête", cliquez sur Ouvrir dans > Looker Studio.
Looker Studio s'ouvre. Cliquez sur Commencer.
-
Dans la fenêtre Looker Studio, cliquez sur votre graphique à barres.
(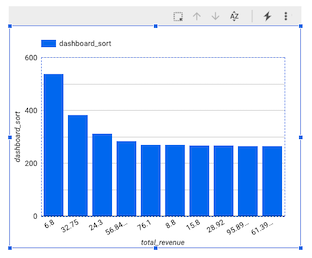
Le volet "Graphique" s'affiche.
-
Cliquez sur Ajouter un graphique, puis sélectionnez Graphique combiné.

-
Dans le champ "Dimension associée à la plage de données" du volet "Configuration", pointez sur minute (Date) et cliquez sur X pour supprimer cet élément.
-
Dans le volet "Données", cliquez sur dashboard_sort et faites glisser cet élément vers Configuration > Dimension associée à la plage de données > Ajouter une dimension.
-
Dans Configuration > Dimension, cliquez sur minute, puis sélectionnez dashboard_sort.
-
Dans Configuration > Métrique, cliquez sur dashboard_sort, puis sélectionnez total_rides.
-
Dans Configuration > Métrique, cliquez sur Record Count (Nombre d'enregistrements), puis sélectionnez total_passengers.
-
Dans Configuration > Métrique, cliquez sur Ajouter une métrique, puis sélectionnez total_revenue.
-
Dans Configuration > Trier, cliquez sur total_rides, puis sélectionnez dashboard_sort.
-
Dans Configuration > Trier, cliquez sur Croissant.
Votre graphique doit ressembler à ceci :
Remarque : La visualisation de données à la minute près n'est actuellement pas possible dans Looker Studio en tant que code temporel. C'est pourquoi nous avons créé notre propre dimension, intitulée dashboard_sort.
-
Lorsque vous êtes satisfait de votre tableau de bord, cliquez sur Enregistrer et partager pour enregistrer cette source de données.
-
Si vous êtes invité à effectuer la configuration de votre compte, saisissez les informations concernant votre pays et votre entreprise, acceptez les conditions d'utilisation, puis cliquez sur Continuer.
-
Si vous êtes invité à choisir les informations que vous souhaitez recevoir, répondez non à tout, puis cliquez sur Continuer.
-
Si la fenêtre Examiner l'accès aux données avant d'enregistrer s'affiche, cliquez sur Confirmer et enregistrer.
-
Si vous êtes invité à choisir un compte, sélectionnez votre compte élève.
-
Quel que soit le moment où quelqu'un consulte votre tableau de bord, il sera à jour avec les dernières transactions. Vous pouvez le constater par vous-même en cliquant sur Plus d'options ( ), puis sur Actualiser les données.
), puis sur Actualiser les données.
Tâche 8 : Créer un tableau de bord de séries temporelles
Dans cette tâche, vous allez créer un graphique de série temporelle.
-
Cliquez sur ce lien Looker Studio pour ouvrir Looker Studio dans un nouvel onglet du navigateur.
-
Sur la page Rapports, dans la section Commencer avec un modèle, cliquez sur le modèle [+] Rapport vide.
-
Un nouveau rapport vide s'ouvre avec la fenêtre Ajouter des données au rapport.
-
Dans la liste Google Connectors (Connecteurs Google), sélectionnez la tuile BigQuery.
-
Cliquez sur Requête personnalisée, puis sélectionnez l'ID de votre projet. Il devrait se présenter au format suivant : qwiklabs-gcp-xxxxxxx.
-
Dans le champ "Saisissez une requête personnalisée", collez la requête suivante :
SELECT
*
FROM
taxirides.realtime
WHERE
ride_status='enroute'
-
Cliquez sur Ajouter > Ajouter au rapport.
Un nouveau rapport sans titre s'affiche. Un délai maximal d'une minute peut être nécessaire pour que l'écran s'actualise.
Créer un graphique de séries temporelles
-
Dans le volet Données, cliquez sur Ajouter un champ > Ajouter un champ calculé.
-
Cliquez sur Tous les champs à gauche.
-
Remplacez le type de champ code temporel par Date et heure > Date, heure et minute (AAAAMMJJhhmm).
-
Dans la boîte de dialogue permettant de modifier le code temporel, cliquez sur Continuer, puis sur OK.
-
Dans la barre de menu supérieure, cliquez sur Ajouter un graphique.
-
Choisissez Graphique de série temporelle.

-
Placez le graphique en bas à gauche, dans l'espace vierge.
-
Dans Configuration > Dimension, cliquez sur code temporel (Date), puis sélectionnez code temporel.
-
Dans Configuration > Dimension, cliquez sur code temporel, puis sélectionnez calendrier.

-
Dans le champ Type de données, sélectionnez Date et heure > Date, heure et minute.
-
Cliquez en dehors de la boîte de dialogue pour la fermer. Il n'est pas nécessaire d'ajouter un nom.
-
Dans Configuration > Métrique, cliquez sur Record Count (Nombre d'enregistrements), puis sélectionnez meter reading.
Félicitations !
Dans cet atelier, vous avez utilisé Dataflow pour transférer des données en flux continu vers BigQuery via un pipeline.
Terminer l'atelier
Une fois l'atelier terminé, cliquez sur Terminer l'atelier. Google Cloud Skills Boost supprime les ressources que vous avez utilisées, puis efface le compte.
Si vous le souhaitez, vous pouvez noter l'atelier. Sélectionnez un nombre d'étoiles, saisissez un commentaire, puis cliquez sur Envoyer.
Le nombre d'étoiles correspond à votre degré de satisfaction :
- 1 étoile = très insatisfait(e)
- 2 étoiles = insatisfait(e)
- 3 étoiles = ni insatisfait(e), ni satisfait(e)
- 4 étoiles = satisfait(e)
- 5 étoiles = très satisfait(e)
Si vous ne souhaitez pas donner votre avis, vous pouvez fermer la boîte de dialogue.
Pour soumettre des commentaires, suggestions ou corrections, veuillez accéder à l'onglet Assistance.
Copyright 2026 Google LLC Tous droits réservés. Google et le logo Google sont des marques de Google LLC. Tous les autres noms de société et de produit peuvent être des marques des sociétés auxquelles ils sont associés.





