
始める前に
- ラボでは、Google Cloud プロジェクトとリソースを一定の時間利用します
- ラボには時間制限があり、一時停止機能はありません。ラボを終了した場合は、最初からやり直す必要があります。
- 画面左上の [ラボを開始] をクリックして開始します
Apply a datagroup to an Explore
/ 100
Apply a datagroup to an Explore
/ 100

Looker は Google Cloud で利用できる最新のデータ プラットフォームで、インタラクティブにデータを分析して可視化できます。Looker を使用すると、詳細なデータ分析、さまざまなデータソース間での分析情報の統合、実用的なデータドリブン ワークフローの構築、独自のデータ アプリケーションの作成を行うことができます。
Looker は常に SQL クエリを生成し、接続されたデータベースに送信しています。Looker でクエリを実行すると、SQL の結果がキャッシュに保存され、Looker インスタンス上の暗号化されたファイルに保存されます。
キャッシュ保存すると、過去に実行したクエリの保存済みの結果を利用できます。これにより、データベースで同じクエリを繰り返し実行する必要がなくなり、データベースの負荷が軽減されます。キャッシュ保存は、Looker のパフォーマンスの最適化にも役立ちます。このラボでは、Looker でのキャッシュ保存の仕組みと、LookML データグループを使用してキャッシュ保存ポリシーを定義する方法について学習します。
こちらの説明をお読みください。ラボの時間は制限されており、一時停止することはできません。タイマーは、Google Cloud のリソースを利用できる時間を示しており、[ラボを開始] をクリックするとスタートします。
このハンズオンラボでは、シミュレーションやデモ環境ではなく、実際のクラウド環境を使ってご自身でラボのアクティビティを行うことができます。そのため、ラボの受講中に Google Cloud にログインおよびアクセスするための、新しい一時的な認証情報が提供されます。
このラボを完了するためには、下記が必要です。
準備ができたら、[ラボを開始] をクリックします。
[ラボの詳細] ペインに、このラボで使用する一時的な認証情報が表示されます。
ラボの料金をお支払いいただく必要がある場合は、表示されるポップアップでお支払い方法を選択してください。
[ラボの詳細] ペインに表示されているラボの認証情報を確認してください(このラボの Looker インスタンスにログインする際に使用します)。
[Open Looker] をクリックします。
提供されたユーザー名とパスワードを、[Email] フィールドと [Password] フィールドに入力します。
ユーザー名:
パスワード:
[Log In] をクリックします。
正常にログインすると、このラボで使用する Looker インスタンスが表示されます。
Looker は、データベースのドアマンのような役割を果たします。ユーザーがクエリを実行すると、Looker はまったく同じクエリが以前に実行されたかどうかを判断します。実行されていなかった場合は、データベースでのそのクエリの実行を許可します。結果が返されると、Looker はそれをキャッシュに保存して、後で参照できるようにします。
同じクエリが過去に実行されていた場合は、Looker はキャッシュ保存ポリシーを確認して、結果がまだ有効かどうかを判断します。キャッシュに保存された結果がまだ有効な場合、Looker はキャッシュに保存された結果をビジネス ユーザーに返します。この処理は 1 秒以内に完了します。
同じクエリが過去に実行されていたものの、キャッシュ保存ポリシーに照らして結果がその時点で有効ではない場合は、Looker はデータベースにクエリを送信します。その後、新しい結果をキャッシュに保存し、以降に使用できるようにします。
データグループは、名前付きのキャッシュ保存ポリシーまたはルールを表す Looker の用語です。LookML のデベロッパーは、データグループを使用して Looker インスタンスのキャッシュを管理します。キャッシュ保存ポリシーごとに、別々のデータグループ定義が必要です。作成する必要があるデータグループの数と種類は、データの ETL(抽出、変換、読み込み)処理およびビジネス要件によって異なります。
たとえば、データの更新頻度に応じて、モデルレベル、個々の Explore、または永続的な派生テーブル(PDT)ごとにデータグループを定義しなければならない場合もあります。
persist_with パラメータを使用します。persist_with パラメータを使用します。persist_with パラメータを使用して、同じデータグループ名を指定します。persist_withデータグループをモデルレベルで適用すると、Looker はデフォルトで、このモデル内のすべての Explore に同じキャッシュ保存ルールを適用します。
ただし、個々の Explore にデータグループを適用すると、モデルレベルの設定が上書きされます。Explore はすべてのコンテンツの基盤であるため、Explore 内の Look とダッシュボードに同じキャッシュ保存ロジックが適用されます。
persist_for パラメータを使用して、Explore のクエリを一定期間キャッシュに保存し、永続的な派生テーブルには sql_trigger_value または persist_for を使用します。
datagroup_triggerPDT の場合、データグループを適用して PDT の再構築方法を指定できます。
データグループを使用して、Look とダッシュボードのスケジュールを実行することもできます。キャッシュ保存ポリシーの期限が切れた際に Look またはダッシュボードを自動的に実行するよう Looker に指示できます。それにより、新しいデータを必要とするビジネス ユーザー向けにデータを取得し、「事前にキャッシュに保存」できます。
データグループには、max_cache_age と sql_trigger の 2 つのパラメータがあります。
max_cache_age には、「24 時間」など、キャッシュに保存された結果を保持する時間数を指定します。sql_trigger は、結果が変更されたかどうかを Looker に通知できる SELECT ステートメントを記述するために使用されます。sql_trigger は、値を 1 つだけ返す記述にする必要があります。Looker は接続されたデータベースに定期的にこのステートメントを送信します。結果が変更された場合、Looker はキャッシュを更新します。必須パラメータは 1 つのみですが、適切なキャッシュ保存の結果を得るには、両方使用することをおすすめします。たとえば、sql_trigger のチェックで変更が検出されない場合、ETL プロセスまたは sql_trigger 自体に問題が発生している可能性があります。max_cache_age パラメータを含めると、sql_trigger チェックの結果にかかわらず、設定された期間が経過するとキャッシュが更新されます。
LookML モデルの個々の Explore に対してデータグループを定義して適用します。具体的には、Order Items Explore に含まれるすべてのビューのキャッシュ保存設定を更新して、新しい order_item_id が追加されるたびに更新するようにします。これは、order_item_id が Order Items の主キーであるためです。
切り替えボタンをクリックして Development Mode に切り替えます。
[開発] タブで、qwiklabs-ecommerce という LookML プロジェクトを選択します。
training_ecommerce.model ファイルを開きます。
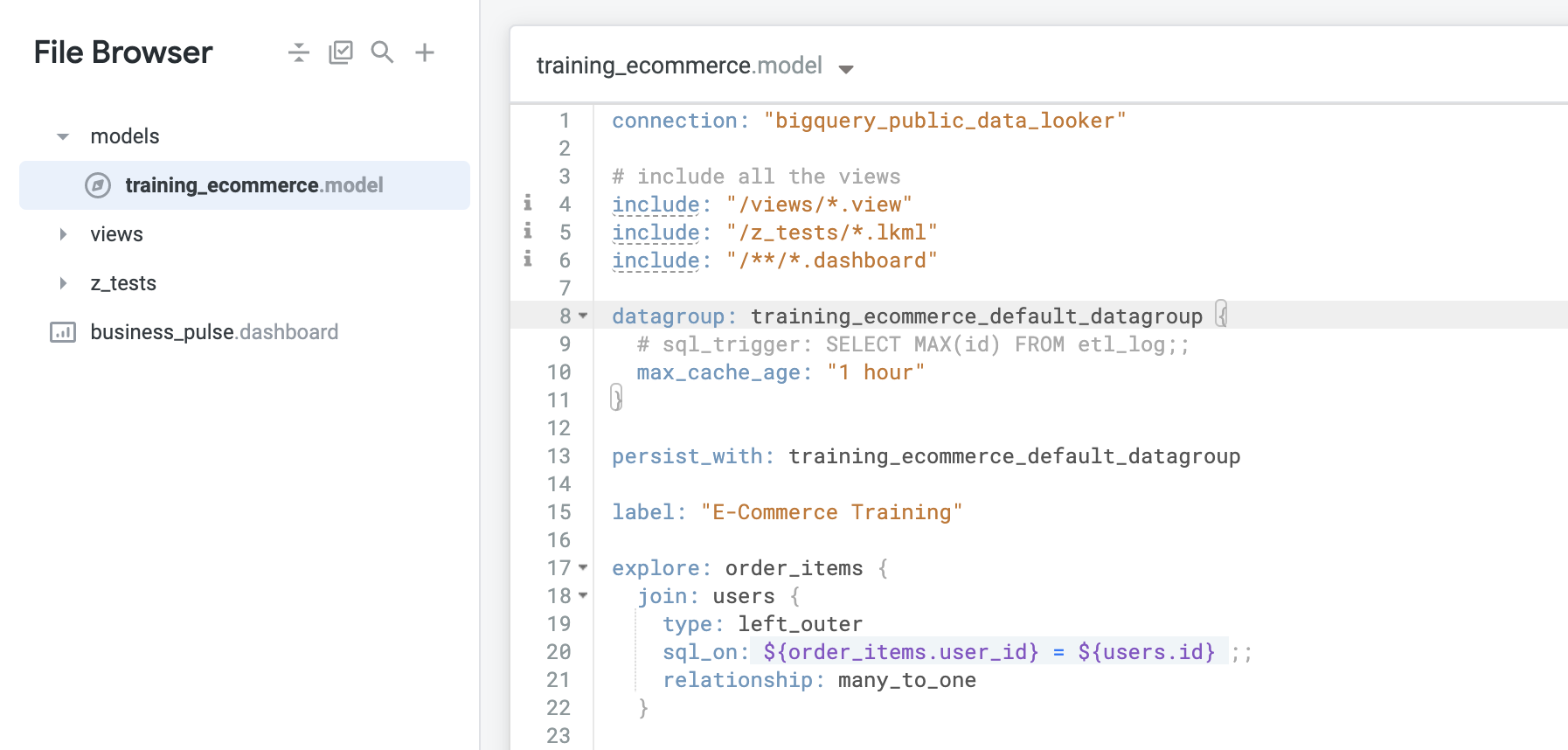
このモデルファイルに、max_cache_age が 1 時間であるデフォルトのデータグループがあることを確認します。Looker にデータベース スキーマからモデルを生成させることで新しい LookML プロジェクトを作成すると、Looker は、デフォルトのデータグループを自動で作成します。このデータグループの名前は、そのモデル名(この場合は training_ecommerce)に _default_datagroup が続くものになります。
このデフォルトのデータグループは現在モデルレベルで定義されているため、このモデルで定義されているすべての Explore に適用されます。データグループを Explore に適用するには、デフォルトのデータグループを削除して、それに応じて更新する必要があります。新しいデータグループの定義を完了するには、sql_trigger と max_cache_age の 2 つのパラメータの値を設定する必要があります。
デフォルトのデータグループと persist_with 定義(8~13 行目)を削除します。
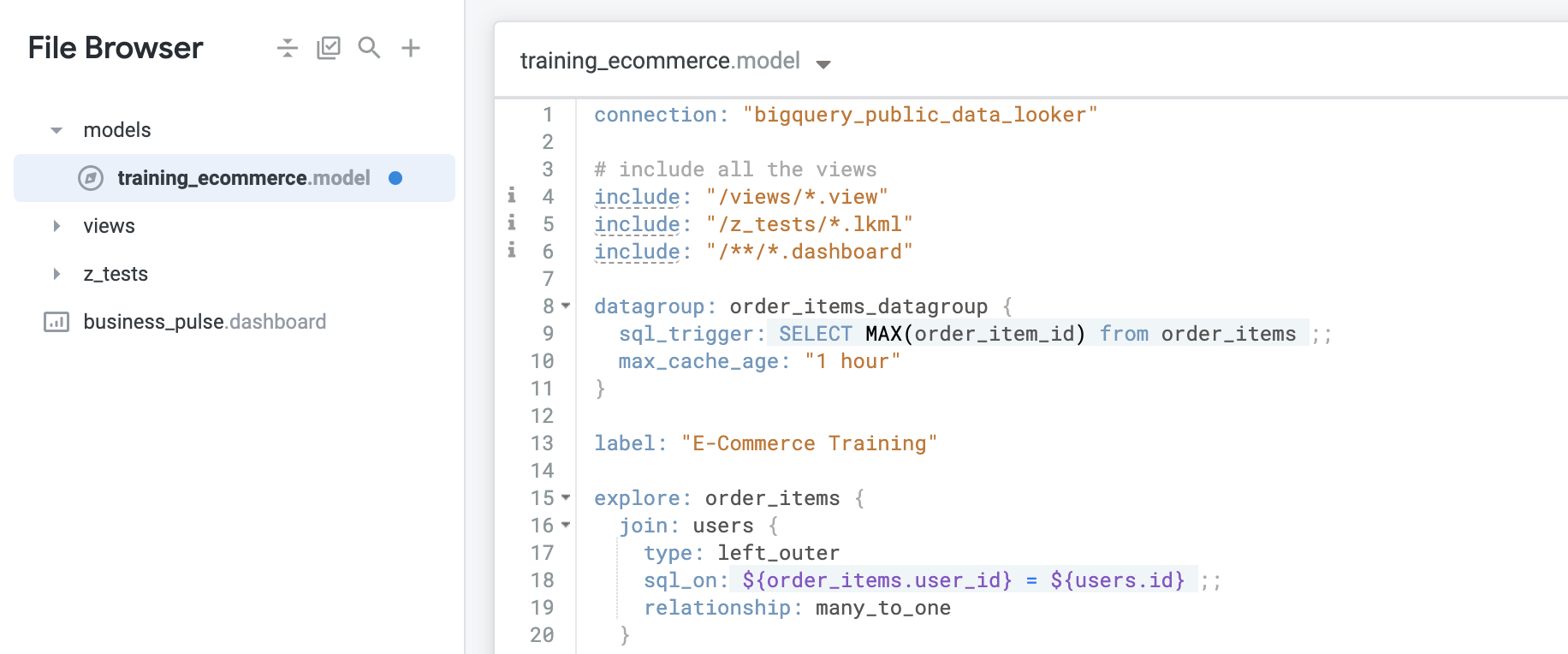
Order Items などの特定の Explore の新しいデータグループを作成するには、次のコードを入力します。
sql_trigger で order_item_id の最大 ID を取得するには、次のコードを入力します。max_cache_age を設定して、データ更新に問題があっても 1 時間ごとにキャッシュの更新が継続されるようにします。次のコードを入力します。データグループを構成するだけでは何も実行されない点に注意してください。これは 2 ステップのプロセスです。データグループを定義した後、persist_with というパラメータを使用して、データグループをオブジェクトに適用する必要があります。
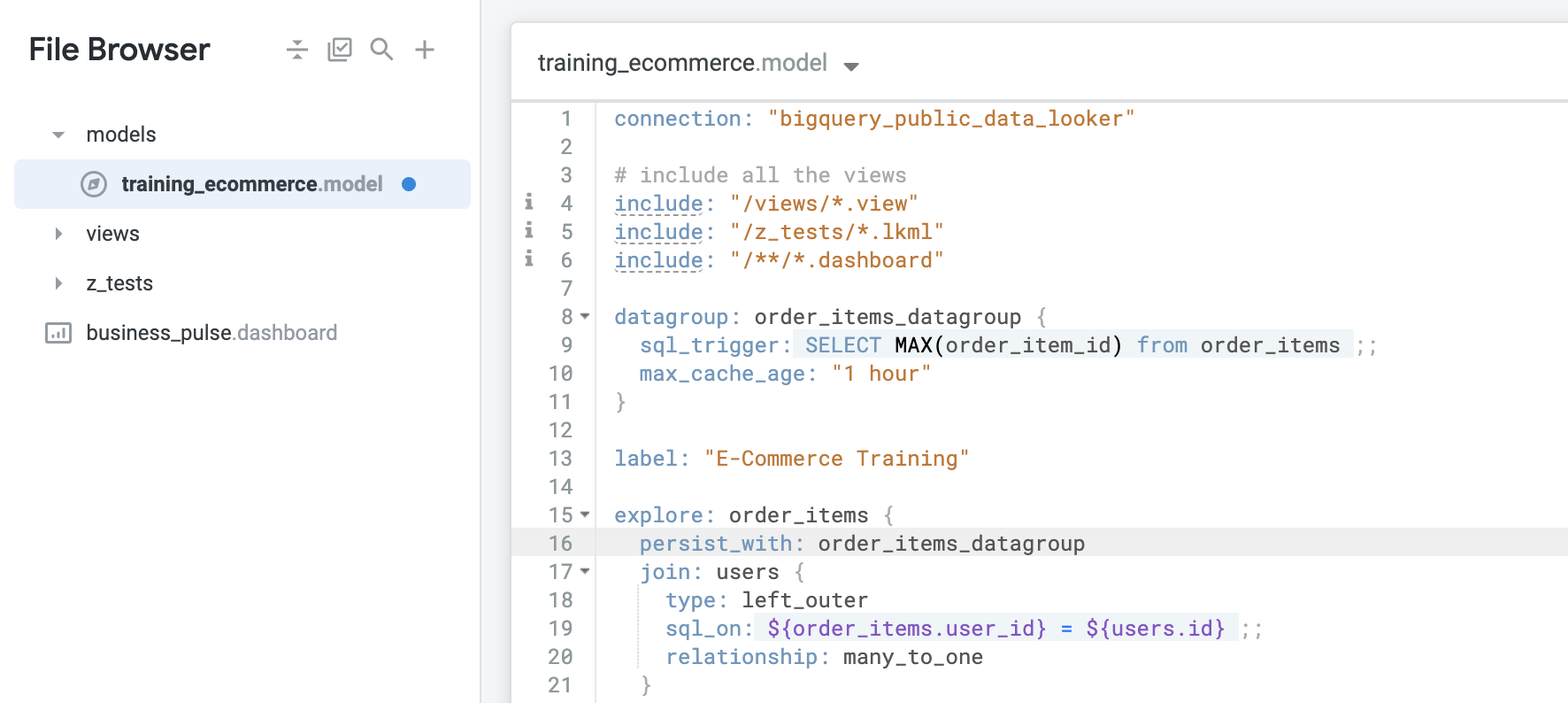
explore: order_items 行の直下に次のコードを入力します。[LookML を検証] をクリックしてから、[Commit Changes & Push] をクリックします。
commit メッセージを追加して、[Commit] をクリックします。
最後に、[本番環境にデプロイ] をクリックします。
これで、新しい注文番号が追加されるたびに更新される独自のキャッシュ保存ポリシー(データグループ)の定義は完了です。また、max_cache_age パラメータを 1 時間に設定して、データの更新に関係なく 1 時間ごとにキャッシュが更新されるようにしました。その後、このデータグループをモデル全体ではなく、個々の Order Items Explore に適用しました。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
このラボでは、Looker でのキャッシュ保存の定義と使用方法を学び、LookML データグループを使用してキャッシュ保存ポリシーを定義する方法を確認しました。
Google Cloud トレーニングと認定資格を通して、Google Cloud 技術を最大限に活用できるようになります。必要な技術スキルとベスト プラクティスについて取り扱うクラスでは、学習を継続的に進めることができます。トレーニングは基礎レベルから上級レベルまであり、オンデマンド、ライブ、バーチャル参加など、多忙なスケジュールにも対応できるオプションが用意されています。認定資格を取得することで、Google Cloud テクノロジーに関するスキルと知識を証明できます。
マニュアルの最終更新日: 2025 年 4 月 24 日
ラボの最終テスト日: 2025 年 4 月 24 日
Copyright 2026 Google LLC. All rights reserved. Google および Google のロゴは Google LLC の商標です。その他すべての企業名および商品名はそれぞれ各社の商標または登録商標です。



このコンテンツは現在ご利用いただけません
利用可能になりましたら、メールでお知らせいたします

ありがとうございます。
利用可能になりましたら、メールでご連絡いたします

1 回に 1 つのラボ
既存のラボをすべて終了して、このラボを開始することを確認してください
ラボを開始するには、この簡単な手順を完了してください。