GSP893

Présentation
Looker est une plate-forme de données moderne intégrée à Google Cloud. Elle permet d'analyser et de visualiser vos données de manière interactive. Vous pouvez utiliser Looker pour effectuer des analyses de données approfondies, intégrer des insights provenant de différentes sources de données, mettre en place des workflows exploitables basés sur les données et créer des applications de données personnalisées.
Looker génère en permanence des requêtes SQL et les envoie à la base de données connectée. Chaque fois qu'un utilisateur exécute une requête dans Looker, les résultats SQL sont mis en cache et stockés dans un fichier chiffré sur l'instance Looker.
La mise en cache exploite les résultats enregistrés des requêtes exécutées précédemment, afin que la même requête ne soit pas exécutée plusieurs fois. Cela contribue à réduire la charge de la base de données. La mise en cache permet également d'optimiser les performances de Looker. Dans cet atelier, vous allez découvrir le fonctionnement de la mise en cache dans Looker et apprendre à utiliser les groupes de données LookML pour définir des règles de mise en cache.
Objectifs de l'atelier
- Définir la mise en cache et les différents objets datagroup dans LookML
- Appliquer un groupe de données à une exploration individuelle dans un modèle LookML
Préparation
Avant de cliquer sur le bouton "Démarrer l'atelier"
Lisez ces instructions. Les ateliers sont minutés, et vous ne pouvez pas les mettre en pause. Le minuteur, qui démarre lorsque vous cliquez sur Démarrer l'atelier, indique combien de temps les ressources Google Cloud resteront accessibles.
Cet atelier pratique vous permet de suivre vous-même les activités dans un véritable environnement cloud, et non dans un environnement de simulation ou de démonstration. Nous vous fournissons des identifiants temporaires pour vous connecter à Google Cloud le temps de l'atelier.
Pour réaliser cet atelier :
- vous devez avoir accès à un navigateur Internet standard (nous vous recommandons d'utiliser Chrome) ;
Remarque : Ouvrez une fenêtre de navigateur en mode incognito/navigation privée pour effectuer cet atelier. Vous éviterez ainsi les conflits entre votre compte personnel et le compte temporaire de participant, qui pourraient entraîner des frais supplémentaires facturés sur votre compte personnel.
- vous disposez d'un temps limité ; n'oubliez pas qu'une fois l'atelier commencé, vous ne pouvez pas le mettre en pause.
Remarque : Si vous possédez déjà votre propre compte ou projet Google Cloud, veillez à ne pas l'utiliser pour réaliser cet atelier afin d'éviter que des frais supplémentaires ne vous soient facturés.
Démarrer votre atelier et vous connecter à Looker
-
Lorsque vous êtes prêt, cliquez sur Démarrer l'atelier.
Le volet "Détails concernant l'atelier" s'affiche avec les identifiants temporaires que vous devez utiliser pour cet atelier.
Si l'atelier est payant, un pop-up s'affiche pour vous permettre de sélectionner un mode de paiement.
Notez les identifiants qui vous ont été attribués pour cet atelier dans le volet "Détails concernant l'atelier". Ils vous serviront à vous connecter à l'instance Looker de cet atelier.
Remarque : Si vous utilisez d'autres identifiants, des messages d'erreur s'afficheront ou des frais seront appliqués.
-
Cliquez sur Ouvrir Looker.
-
Saisissez le nom d'utilisateur et le mot de passe fournis dans les champs Adresse e-mail et Mot de passe.
Nom d'utilisateur :
{{{looker.developer_username | Username}}}
Mot de passe :
{{{looker.developer_password | Password}}}
Important : Vous devez utiliser les identifiants fournis dans le volet "Détails concernant l'atelier" sur cette page. Ne saisissez pas vos identifiants Google Cloud Skills Boost. Si vous possédez un compte Looker personnel, ne l'utilisez pas pour cet atelier.
-
Cliquez sur Connexion.
Une fois la connexion établie, l'instance Looker de cet atelier s'affichera.
Fonctionnement de la mise en cache dans Looker
Looker gère la partie "accès" aux bases de données. Lorsqu'un utilisateur exécute une requête, Looker détermine si la même requête a déjà été exécutée. Si ce n'est pas le cas, l'outil permet à la requête de s'exécuter sur la base de données. Et lorsque les résultats sont renvoyés, Looker les met en cache en prévision d'une utilisation ultérieure.
Si la même requête a déjà été exécutée, Looker vérifie la règle de mise en cache pour déterminer si les résultats sont toujours valides. En cas de confirmation, Looker renvoie les résultats mis en cache à l'utilisateur professionnel. Tout cela en moins d'une seconde.
Si la même requête a été exécutée auparavant, mais que les résultats ne sont plus valides selon la règle de mise en cache, Looker envoie la requête à la base de données. L'outil met ensuite en cache les nouveaux résultats en prévision d'une utilisation ultérieure.
Groupes de données
Un groupe de données (datagroup) est le terme Looker désignant une règle ou une stratégie de mise en cache nommée. Les développeurs LookML utilisent les groupes de données pour gérer la mise en cache sur une instance Looker. Chaque règle de mise en cache nécessite une définition de groupe de données distincte. Le nombre et les types de groupes de données à créer dépendent des processus d'extraction, de transformation et de chargement (ETL) de vos données, ainsi que de vos exigences métier.
Par exemple, vous devrez peut-être définir des groupes de données au niveau du modèle, pour des explorations individuelles ou pour des tables dérivées persistantes (PDT), selon la fréquence à laquelle vos données sont mises à jour.
- Pour appliquer un groupe de données par défaut à toutes les explorations, utilisez le paramètre
persist_with au niveau du modèle.
- Pour appliquer un groupe de données à une exploration spécifique, utilisez le paramètre
persist_with dans la définition de cette exploration.
- Pour appliquer un groupe de données à un ensemble spécifique d'explorations, mais pas à toutes les explorations d'un modèle, utilisez le paramètre
persist_with dans la définition de chaque exploration et spécifiez le même nom de groupe de données.
Objets pouvant utiliser des groupes de données
persist_with
Si vous appliquez un groupe de données au niveau du modèle, Looker applique par défaut les mêmes règles de mise en cache à toutes les explorations de ce modèle.
Toutefois, vous pouvez appliquer un groupe de données à une exploration individuelle, ce qui remplace tout paramètre au niveau du modèle. Les explorations étant à la base de tout le contenu, la même logique de mise en cache s'applique aux Looks et aux tableaux de bord dans l'exploration.
Remarque : Si votre connexion à la base de données est configurée pour utiliser des noms d'utilisateur dynamiques dans Looker, vous ne pouvez pas utiliser de groupe de données pour les modèles qui emploient cette connexion. Utilisez plutôt un paramètre persist_for pour mettre en cache les requêtes d'exploration pendant une durée déterminée, et utilisez sql_trigger_value ou persist_for pour les tables dérivées persistantes.
datagroup_trigger
Pour les PDT, vous pouvez appliquer un groupe de données afin de spécifier comment la table est régénérée.
Planifications
Les planifications d'explorations et de tableaux de bord peuvent également être exécutées sur des groupes de données. Vous pouvez demander à Looker d'exécuter une exploration ou un tableau de bord automatiquement à l'expiration d'une règle de mise en cache. Ainsi, les nouvelles données sont récupérées et "pré-mises en cache" pour les utilisateurs professionnels qui en ont besoin.
Configuration du groupe de données
Les groupes de données utilisent deux paramètres : max_cache_age et sql_trigger.
-
max_cache_age spécifie le nombre d'heures pendant lesquelles un résultat mis en cache doit être conservé, par exemple 24 heures.
-
sql_trigger permet d'écrire une instruction SELECT qui indique à Looker si les résultats ont changé. Le paramètre sql_trigger doit être écrit de façon à ne renvoyer qu'une seule valeur. Looker envoie régulièrement cette instruction à la base de données connectée et, si le résultat a changé, Looker actualise le cache.
Bien qu'un seul paramètre soit requis, il est préférable d'utiliser les deux pour obtenir les résultats de mise en cache souhaités. Par exemple, si la vérification sql_trigger ne détecte aucun changement, cela peut signifier que le processus ETL ou le paramètre sql_trigger lui-même a rencontré un problème. Si vous incluez un paramètre max_cache_age, le cache sera actualisé après une durée définie, quel que soit le résultat de la vérification sql_trigger.
Remarque : Seul un de ces paramètres est obligatoire, mais il est recommandé de les utiliser tous les deux.
Tâche 1 : Appliquer un groupe de données à une exploration
Vous allez définir et appliquer des groupes de données à des explorations individuelles dans un modèle LookML. Plus précisément, vous allez actualiser la mise en cache de toutes les vues de l'exploration "Order Items" (Articles commandés) chaque fois qu'un nouvel order_item_id est ajouté, car order_item_id est la clé primaire des articles commandés.
Ouvrir le modèle
-
Cliquez sur le bouton d'activation pour passer en mode Développement.
-
Dans l'onglet Développer, sélectionnez le projet LookML qwiklabs-ecommerce.
-
Ouvrez le fichier training_ecommerce.model.
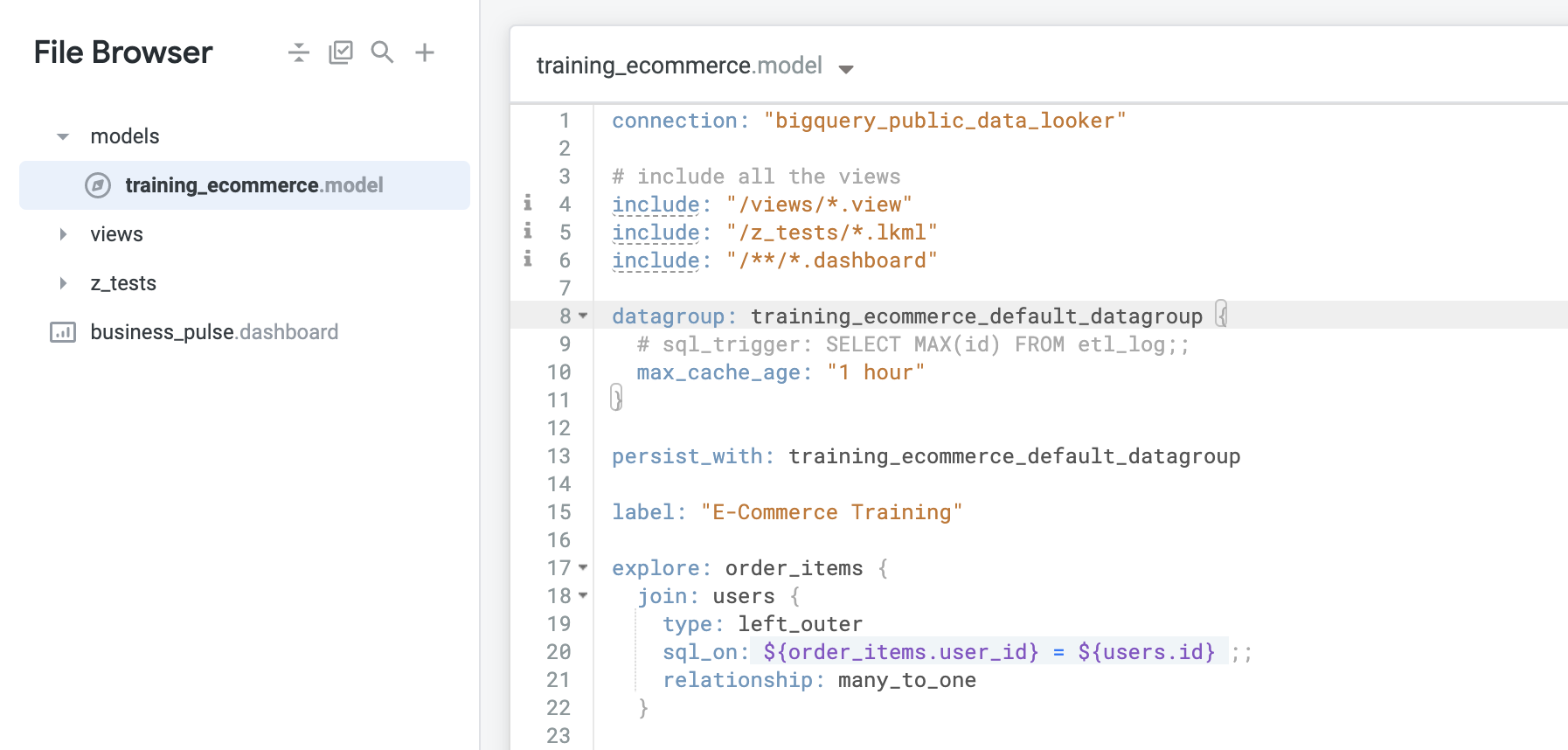
Notez que ce fichier de modèle comporte un groupe de données par défaut avec une valeur max_cache_age d'une heure. Chaque fois que vous créez un projet LookML en demandant à Looker de générer le modèle à partir du schéma de la base de données, Looker crée automatiquement un groupe de données par défaut portant le nom du modèle, ici training_ecommerce, suivi de _default_datagroup.
Supprimer le groupe de données par défaut et le remplacer
Comme ce groupe de données par défaut est actuellement défini au niveau du modèle, il est appliqué à toutes les explorations définies dans le modèle. Vous souhaitez appliquer le groupe de données à l'exploration. Vous devez donc supprimer le groupe par défaut et en créer un correspondant à vos besoins. Pour définir le nouveau groupe de données, vous devez fournir des valeurs pour les deux paramètres : sql_trigger et max_cache_age.
-
Supprimez le groupe de données par défaut et la définition persist_with (lignes 8 à 13).
-
Pour créer un groupe de données pour une exploration spécifique, comme Order Items (Articles commandés), saisissez le code suivant :
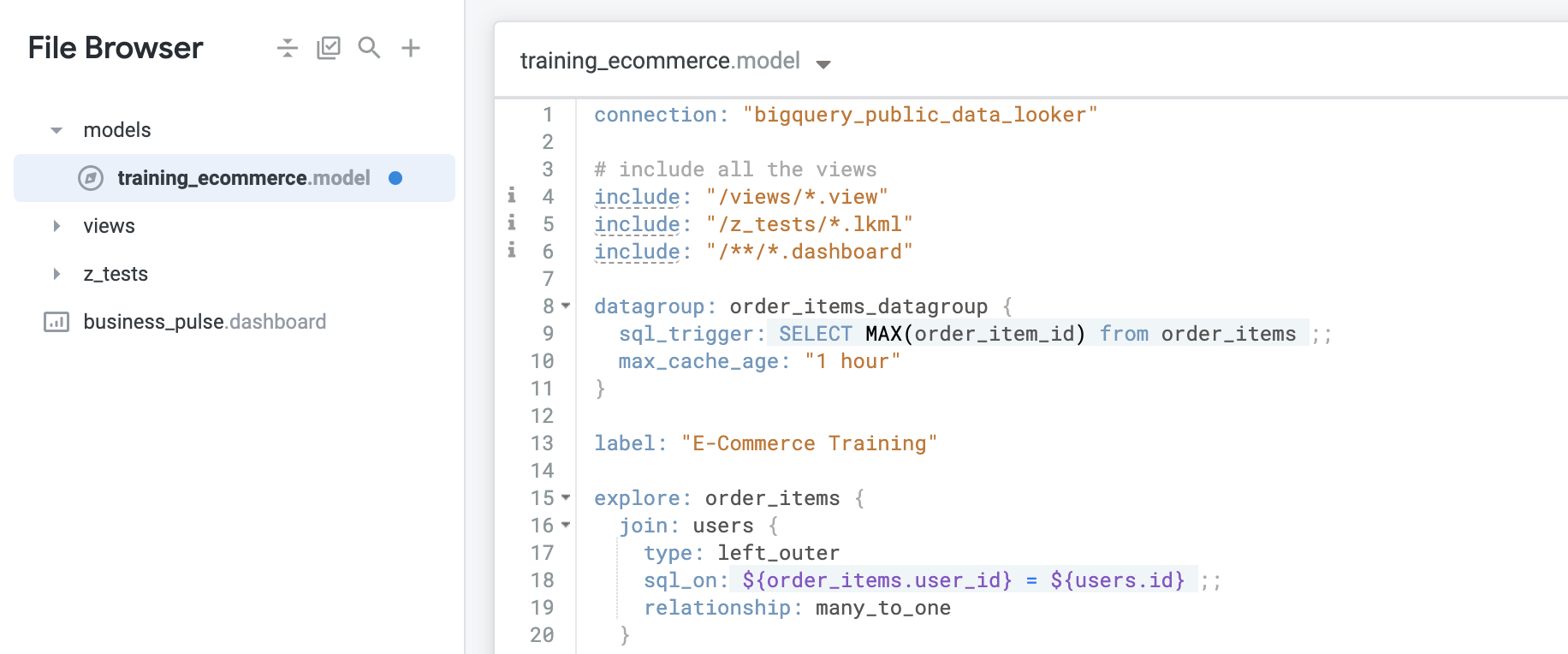
datagroup: order_items_datagroup {}
- Concernant le paramètre
sql_trigger, afin de sélectionner l'ID maximal pour order_item_id, saisissez le code suivant :
sql_trigger: SELECT MAX(order_item_id) from order_items ;;
- Définissez
max_cache_age de manière à ce que la mise en cache continue de s'actualiser toutes les heures, même en cas de problème avec les mises à jour des données. Saisissez le code ci-dessous :
max_cache_age: "1 hour"
Appliquer le groupe de données
Notez que la configuration d'un groupe de données en soi n'a aucun effet. Il s'agit d'un processus en deux étapes. Après avoir défini le groupe de données, vous devez l'appliquer à un objet à l'aide du paramètre persist_with.
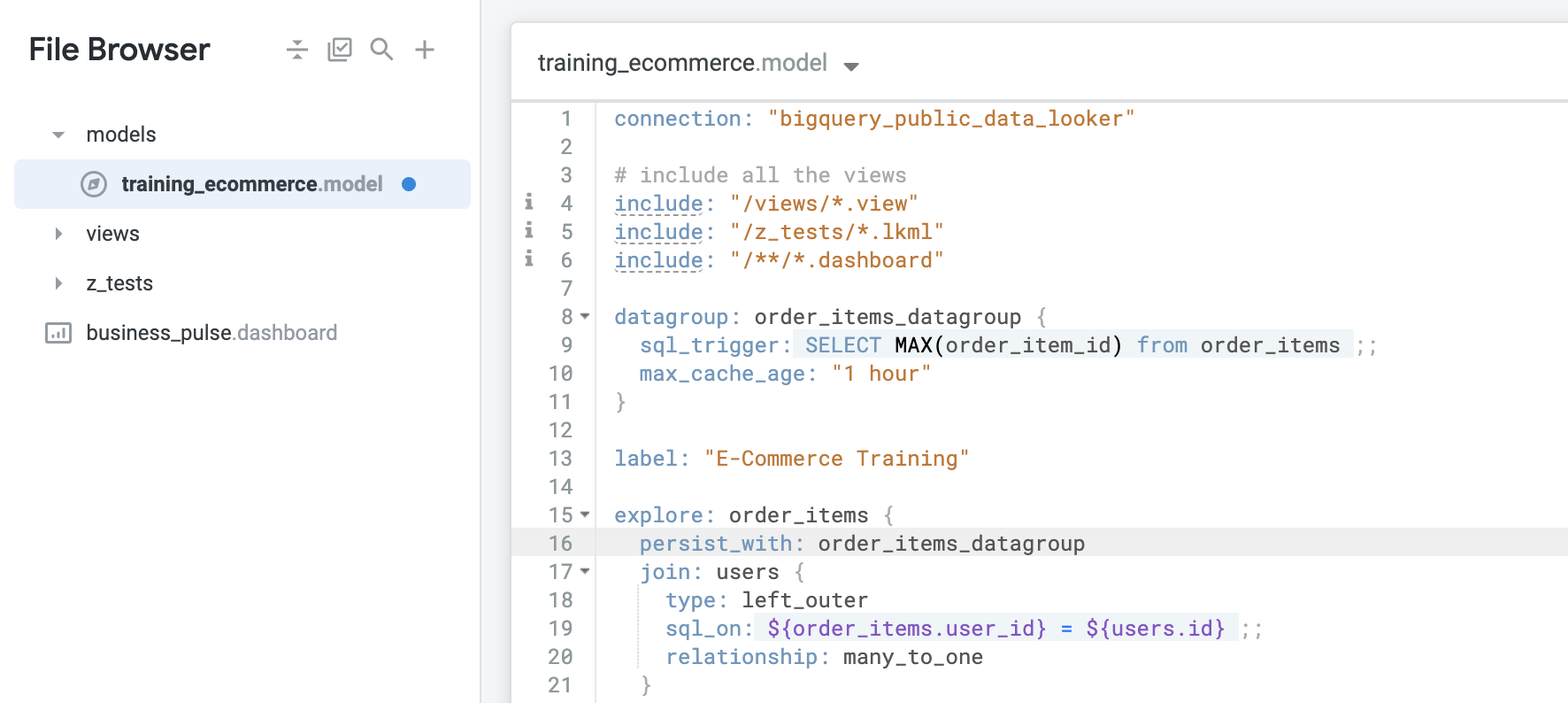
- Pour appliquer le groupe de données à la définition de l'exploration Order Items (Articles commandés), saisissez le code suivant directement sous la ligne
explore: order_items :
persist_with: order_items_datagroup
- Cliquez sur Enregistrer les modifications.
Valider les modifications et les déployer en production
-
Cliquez sur Valider le LookML, puis sur Valider les modifications et envoyer.
-
Ajoutez un message de commit, puis cliquez sur Valider.
-
Enfin, cliquez sur Déployer en production.
Parfait ! Vous venez de définir votre propre règle de mise en cache (groupe de données) pour qu'elle soit mise à jour chaque fois qu'un nouveau numéro de commande est ajouté. Vous avez également utilisé un paramètre de durée maximale de cache défini sur une heure, de sorte que la mise en cache continuera à s'actualiser toutes les heures, quelles que soient les mises à jour des données. Vous avez ensuite appliqué ce groupe de données à l'exploration Order Items (Articles commandés) individuelle au lieu de l'appliquer à l'ensemble du modèle.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Appliquer un groupe de données à une exploration
Félicitations !
Dans cet atelier, vous avez appris à définir et à utiliser la mise en cache dans Looker, et vous avez découvert comment utiliser les groupes de données LookML pour définir des règles de mise en cache.
Étapes suivantes et informations supplémentaires
Formations et certifications Google Cloud
Les formations et certifications Google Cloud vous aident à tirer pleinement parti des technologies Google Cloud. Nos cours portent sur les compétences techniques et les bonnes pratiques à suivre pour être rapidement opérationnel et poursuivre votre apprentissage. Nous proposons des formations pour tous les niveaux, à la demande, en salle et à distance, pour nous adapter aux emplois du temps de chacun. Les certifications vous permettent de valider et de démontrer vos compétences et votre expérience en matière de technologies Google Cloud.
Dernière mise à jour du manuel : 24 avril 2025
Dernier test de l'atelier : 24 avril 2025
Copyright 2026 Google LLC. Tous droits réservés. Google et le logo Google sont des marques de Google LLC. Tous les autres noms d'entreprises et de produits peuvent être des marques des entreprises auxquelles ils sont associés.





