
始める前に
- ラボでは、Google Cloud プロジェクトとリソースを一定の時間利用します
- ラボには時間制限があり、一時停止機能はありません。ラボを終了した場合は、最初からやり直す必要があります。
- 画面左上の [ラボを開始] をクリックして開始します
Enable the APIs
/ 10
Deploy the Agent
/ 90
Enable the APIs
/ 10
Deploy the Agent
/ 90

このラボでは、Agent Development Kit(ADK)を使用して、クライアント エージェント サービスを実装しデプロイする方法を中心に説明します。ADK を使用して、MCP サーバーなどのリモートツールを利用する AI エージェントを構築します。ここで重要なのが、アーキテクチャの基本原則である「責任の分担」です。これは、安全な API を介して推論レイヤ(エージェント)が、明確に分離されたツールレイヤ(MCP サーバー)と通信する仕組みによって実現します。
このラボでは、事前に MCP サーバーがデプロイされています。このサーバーは、Gemini CLI などを使用する際に、架空の動物園に登場する動物データを LLM に提供します。ラボの目標は、Python アプリケーションを使用して、架空の動物園のツアーガイド エージェントを構築することです。エージェントは MCP サーバーを通じて動物園の動物に関する詳細情報にアクセスし、Wikipedia の情報も使用して、優れたツアーガイド体験を実現します。

最後に、ツアーガイド エージェントを Google Cloud Run にデプロイします。これにより、ローカルで実行するだけでなく、動物園のすべての来園者がアクセスできるようになります。
このラボでは、次のタスクの実行方法について学びます。
Cloud Run はサーバーレス プラットフォームであり、ADK エージェントのホスティングに最適です。基盤となるインフラストラクチャを管理する必要がないため、開発者はコードに集中できます。運用作業は Cloud Run が行います。
ポップアップ ショップのように、顧客(リクエスト)が来たときにのみオープンしてリソースを使用します。顧客がいないときは完全に閉店します。そのため、使用していないリソースに対して料金は発生しません。
こちらの説明をお読みください。ラボには時間制限があり、一時停止することはできません。タイマーは、Google Cloud のリソースを利用できる時間を示しており、[ラボを開始] をクリックするとスタートします。
このハンズオンラボでは、シミュレーションやデモ環境ではなく実際のクラウド環境を使って、ラボのアクティビティを行います。そのため、ラボの受講中に Google Cloud にログインおよびアクセスするための、新しい一時的な認証情報が提供されます。
このラボを完了するためには、下記が必要です。
Cloud Shell は、開発ツールと一緒に読み込まれる仮想マシンです。5 GB の永続ホーム ディレクトリが用意されており、Google Cloud で稼働します。Cloud Shell を使用すると、コマンドラインで Google Cloud リソースにアクセスできます。
Google Cloud コンソールの上部にある「Cloud Shell をアクティブにする」アイコン 
ウィンドウで次の操作を行います。
接続した時点で認証が完了しており、プロジェクトに各自の Project_ID、
gcloud は Google Cloud のコマンドライン ツールです。このツールは、Cloud Shell にプリインストールされており、タブ補完がサポートされています。
出力:
出力:
gcloud ドキュメントの全文については、gcloud CLI の概要ガイドをご覧ください。
このタスクでは、関連する API を有効にします。さらに、Python プロジェクトをデプロイするために、ソースコードを保存するプロジェクト フォルダを作成します。
このラボの後半では、このウィンドウを Cloud Shell エディタ(上)と Cloud Shell ターミナル(下)を備えた IDE として使用します。
画面の右側に表示される追加のチュートリアルや Gemini のパネルを閉じると、コードエディタのウィンドウをより広く使用できます。
ターミナルで次のコマンドを入力してプロジェクトを設定します。
想定される出力: 更新されたプロパティを確認する出力メッセージが表示されます。
次のコマンドを実行して、必要なサービスをすべて有効にします。
想定される出力: オペレーションが成功したことを確認する出力メッセージが表示されます。
[進行状況を確認]
をクリックして、目標に沿って進んでいることを確認します。
次のコマンドを実行して、エージェントのソースコード用メインフォルダをラボに作成します。
続いて、次のコマンドを実行して仮想環境を作成します。
次のコマンドを実行して、仮想環境を有効にします。
これで、requirements.txt
ファイルを作成する準備が整いました。このファイルには、動物園エージェントに必要な
Python ライブラリの一覧を記述します。
次のコマンドを実行して zoo_guide_agent ディレクトリ内にファイルを作成し、Cloud Shell エディタで編集できるように開きます。
requirements.txt ファイルに次の内容を追加し、Ctrl+S
キーを押して変更を保存します。
ターミナルで次のコマンドを実行して、パッケージ マネージャー
uv を使って Python パッケージをインストールします。
次のコマンドを実行して、現在のプロジェクト、リージョン、ユーザー用に変数を設定します。
次のコマンドを実行して、zoo_guide_agent
ディレクトリ内に、エージェントを認証するための
.env ファイルを作成して開きます。
Cloud Shell エディタに
.env ファイルを含むディレクトリが開きます。
.env ファイルに次のコードを追加し、変更を保存します。
このセクションでは、リモート MCP サーバーへの接続を確立します。
Cloud Shell ターミナルに戻り、次のコマンドを実行して、Cloud Run サービス ID にリモート MCP サーバーを呼び出す権限を付与します。
次のコマンドを実行して、MCP サーバーの URL を環境変数に保存します。
次に、__init__.py ファイルを作成します。このファイルは、zoo_guide_agent
ディレクトリが Python パッケージであることを Python に伝えます。
開いた Cloud Shell エディタで、__init__.py
に次のコードを追加し、変更を保存します。
このタスクでは、動物園ツアーガイド エージェントのワークフローを構成します。まず、初期設定に必要なライブラリをインポートします。次に、動物園エージェントの機能(使用するツール)を定義し、専門エージェントを定義します。その後、ワークフロー エージェントを定義し、最後にメインのワークフローを組み立てます。
agent.py ファイルを作成する
Cloud Shell ターミナルに戻り、次のコマンドを実行してメインの
agent.py ファイルを作成します。作成したファイルは Cloud Shell
エディタで開かれるので、次のステップでマルチエージェント
システムの完全なコードを貼り付けます。
最初のブロックでは、ADK と Google Cloud
から必要なライブラリをすべて取り込みます。また、ロギングを設定し、.env
ファイルから環境変数を読み込みます。これは、モデルやサーバーの URL
にアクセスするために必要です。
次のコードを agent.py ファイルに追加します。

エージェントの機能は、使用できるツールによって決まります。このセクションでは、データを保存するカスタム関数、セキュアな MCP サーバーに接続する MCP ツール、Wikipedia ツールなど、エージェントが利用できるすべての機能を定義します。
次のコードを agent.py の末尾に追加します。
add_prompt_to_state: 📝
このツールは、動物園の来園者が尋ねた内容を記憶します。たとえば、来園者が「ライオンはどこにいますか?」と尋ねると、その具体的な質問がエージェントのメモリに保存され、ワークフロー内の他のエージェントが次に調査すべきことを判断できるようになります。
方法: このツールは Python
関数として実装されており、訪問者のプロンプトを共有の
tool_context.state
ディクショナリに書き込みます。このツールのコンテキストは、1
回の会話におけるエージェントの短期記憶を表します。1 つのエージェントが
State
に保存したデータは、ワークフロー内の次のエージェントで読み取ることができます。
MCPToolset: 🦁
このツールセットは、ツアーガイド
エージェントを、ラボで事前にデプロイされた動物園の MCP
サーバーに接続するために使用されます。このサーバーには、動物園の動物に関する具体的な情報(名前、年齢、飼育施設など)を検索できる専用のツールが用意されています。
方法: このツールセットは、動物園のプライベート サーバーの
URL に安全に接続します。さらに、get_id_token
を使用してセキュアな「キーカード」(サービス アカウントの ID
トークン)を自動的に取得し、そのトークンを使って ID
を証明してアクセス権を取得します。
LangchainTool: 🌍 このツールは、ツアーガイド
エージェントに世界の一般的な知識を提供します。たとえば、来園者が「野生のライオンは何を食べるの?」など、動物園のデータベースに含まれない質問をした場合、エージェントはこのツールを使用して
Wikipedia で回答を検索できます。
方法: このツールはアダプタとして機能し、エージェントが LangChain ライブラリの事前構築済み WikipediaQueryRun ツールを使用できるようにします。
関連情報:

このセクションでは、2 つの専門エージェント(リサーチャー
エージェントと回答フォーマッタ エージェント)を定義します。リサーチャー
エージェントは、オペレーション全体の「頭脳」として機能します。このエージェントは、共有された
State からユーザーのプロンプトを取得し、強力なツール(動物園の
MCP サーバーツールと Wikipedia
ツール)から、どちらを使って回答を検索するかを判断します。
回答フォーマッタ エージェントはプレゼンテーションを担当します。このエージェントは、新しい情報を検索するツールは使用せず、リサーチャー エージェントが収集した元データを State から取得します。そのデータを LLM の言語能力で整形し、フレンドリーな会話形式の回答へと変換します。
次のコードを agent.py の末尾に追加します。
ワークフロー エージェントは、動物園ツアー全体の「バックオフィス」を管理するマネージャーとして機能します。リサーチ リクエストを受け取り、ステップ 3 で定義した 2 つのエージェントが、必ず正しい順序(最初にリサーチ、次にフォーマット)でジョブを実行できるように調整します。これにより、動物園の来園者の質問に一貫して回答できる、予測可能で信頼性の高いプロセスが作成されます。
方法: このエージェントは
SequentialAgent
として動作し、自身で推論を行わない特別なタイプのエージェントです。唯一の役割は、sub_agents(リサーチャー
エージェントと回答フォーマッタ
エージェント)のリストを、あらかじめ定められた順序で実行することです。実行時には、共有メモリを自動的に受け渡しながら処理を進めます。
次のコードブロックを agent.py の末尾に追加します。

メインのワークフローは root_agent で指定されます。ADK
フレームワークでは、この root_agent
がすべての新規会話の開始点になります。このエージェントは、プロセス全体をオーケストレートする役割を担い、初期コントローラとして会話の最初のやり取りを管理します。
次のコードブロックを
agent.py の末尾に追加し、変更を保存します。
これで agent.py ファイルが完成しました。
このように構築することで、各コンポーネント(ツール、ワーカー エージェント、マネージャー エージェント)が、最終的なインテリジェント システムの中で、それぞれ明確な役割を担っていることがわかります。それでは、デプロイに進みましょう。
ローカル環境の準備が整ったら、動物園ツアーガイド エージェントをデプロイするために Google Cloud プロジェクトを準備します。
このステップでは、エージェントのファイル構造の最終チェックを行い、デプロイ コマンドに対応していることを確認します。さらに、デプロイされた Cloud Run サービスがユーザーに代わって Agent Platform モデルを呼び出すために必須の IAM 権限を構成します。これらの手順を完了すると、クラウド環境でエージェントを正常に実行できるようになります。
Cloud Shell ターミナルに戻り、次のコマンドを実行して、変数をシェル セッションに読み込みます。
次のコマンドを実行して、サービス アカウントに Agent Platform ユーザーロールを付与します。これにより、予測を行う権限と Google のモデルを呼び出す権限が、サービス アカウントに付与されます。
ローカルコードの準備が整い、Google Cloud プロジェクトも用意できたので、次はエージェントをデプロイします。
このタスクでは
adk deploy cloud_run
コマンドを使用します。このコマンドは、デプロイ
ワークフロー全体を自動化する便利なツールです。1
つのコマンドで、コードのパッケージ化、コンテナ イメージのビルド、Artifact
Registry への push、Cloud Run
でのサービスの起動までを行い、ウェブからアクセスできる状態にします。
次のコマンドを実行して、エージェントをデプロイします。
続行するかどうか、または
[zoo-tour-guide]
への未認証の呼び出しを許可するかどうかを尋ねられた場合は、「Y」と入力して Enter キーを押してください。
次のコマンドを実行して、既存の Cloud Run サービスの構成設定を変更します。
エージェントが Cloud Run に正常にデプロイされたら、Ctrl キーを押しながら出力内に表示されるサービス URL をクリックして、新しいブラウザタブで開きます。
次のような形式で表示されます。 サービス URL の出力:
Cloud Run にデプロイする際に --with_ui フラグを使用したため、ADK
のデベロッパー UI が表示されます。
[進行状況を確認]
をクリックして、目標に沿って進んでいることを確認します。
エージェントが Cloud Run で稼働するようになったので、このタスクではデプロイが成功したことと、エージェントが想定どおりに動作していることを確認するテストを行います。ADK のウェブ インターフェースにアクセスしてエージェントとやり取りするには、公開サービス URL を使用する必要があります。
前のタスクで出力された公開 Cloud Run サービス URL をウェブブラウザで開くか、出力に表示された URL をクリックします(新しいブラウザタブで開きます)。ADK のデベロッパー UI が開きます。
ADK ツールバーの右上にある [トークンのストリーミング] を [オン] に切り替えます。
これで、動物園エージェントとやり取りできるようになりました。
プロンプト ボックスに「hello」と入力して Enter
キーを押すと、新しい会話が始まります。
結果を確認します。エージェントは、標準の挨拶をすぐに返します。
動物園ガイド エージェントと対話します。次のクエリを入力して、新しい会話を開始してください。
エージェントからは、次のような回答が返されます。
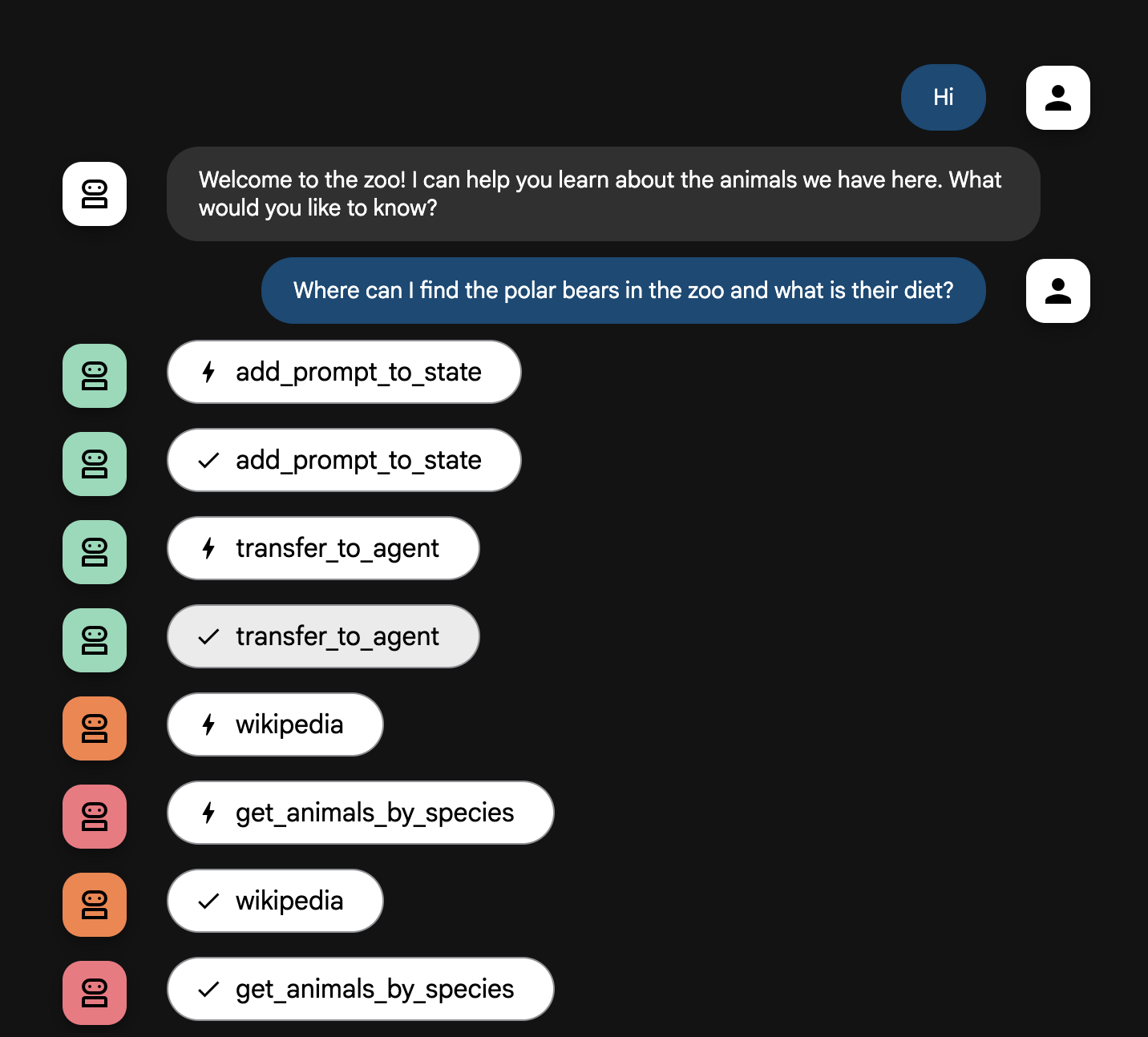

システムはインテリジェントなマルチエージェントのチームとして機能します。このプロセスは明確な順序で管理されているため、ユーザーの質問から最終的な詳細回答に至るまでのフローは、スムーズかつ効率的です。
1. 動物園の案内係(ウェルカム デスク)
プロセス全体は、案内係エージェントから始まります。
役割: 会話を始めることです。ユーザーに挨拶し、どの動物について知りたいかを尋ねるように指示されています。
ツール: ユーザーが応答すると、案内係は add_prompt_to_state ツールを使用して、ユーザーの発言(例: 「ライオンについて教えて」)をそのままキャプチャし、システムメモリに保存します。
引き継ぎ: プロンプトを保存すると、すぐにサブエージェントである tour_guide_workflow に制御が移ります。
2. 包括的リサーチャー(スーパー リサーチャー)
メイン ワークフローの最初のステップであり、オペレーション全体の「頭脳」として機能します。大規模なチームではなく、利用可能なすべての情報にアクセスできる、高いスキルを持つエージェントが 1 人いるイメージです。
役割: ユーザーの質問を分析し、インテリジェントな計画を立てます。言語モデルの高度なツール使用能力を活用して、次のどの情報源を使うべきかを判断します。
動作: 必要なツールを実行して、回答に必要な元データをすべて収集します。たとえば、ユーザーが「ライオンは何歳で、野生では何を食べているの?」と尋ねた場合、年齢の情報は MCP サーバーから取得し、食事に関する情報は Wikipedia ツールから取得します。
3. 回答フォーマッタ(プレゼンター)
包括的リサーチャーがすべての情報を収集した後、最後に実行されるエージェントです。
役割: 動物園ツアーガイドのフレンドリーな声として機能します。1 つまたは両方の情報源から収集した元データを取り込み、推敲します。
動作: すべての情報を統合し、一貫性があり、わかりやすく魅力的な回答へと仕上げます。指示に従い、まず動物園の具体的な情報を提示し、次に興味深い一般的な事実を追加します。
最終結果: このエージェントが生成したテキストは、ユーザーがチャット ウィンドウで確認できる、完全で詳細な回答です。
エージェントの構築について詳しくは、以下のリソースをご覧ください。
このタスクでは、今後の費用発生を防ぐために、このラボで作成した Cloud リソースを削除します。
Cloud Shell ターミナルのタブに戻り、次のコマンドを実行します。
このラボでは、ADK コマンドライン インターフェースを使用して、デプロイに向けた Python プロジェクトの構造化方法を学び、マルチエージェント ワークフローを実装しました。さらに、リモート MCP サーバーに接続してそのツールを利用し、Wikipedia API などの外部ツールを統合することで、内部データを拡張しました。最後に、エージェントをサーバーレス コンテナとして Cloud Run にデプロイしました。
マニュアルの最終更新日: 2025 年 10 月 13 日
ラボの最終テスト日: 2025 年 10 月 13 日
Copyright 2026 Google LLC. All rights reserved. Google および Google のロゴは Google LLC の商標です。その他すべての企業名および商品名はそれぞれ各社の商標または登録商標です。



このコンテンツは現在ご利用いただけません
利用可能になりましたら、メールでお知らせいたします

ありがとうございます。
利用可能になりましたら、メールでご連絡いたします

1 回に 1 つのラボ
既存のラボをすべて終了して、このラボを開始することを確認してください
ラボを開始するには、この簡単な手順を完了してください。