GSP1350

Présentation
Cet atelier montre comment implémenter et déployer un service d'agent IA
client à l'aide de l'Agent Development Kit
(ADK). L'agent utilise des outils distants, en l'occurrence un serveur MCP. Le
principe architectural clé illustré dans cet exemple est la séparation des
préoccupations : une couche de raisonnement (l'agent) communique avec une
autre couche séparée pour les outils (le serveur MCP) via une API sécurisée.
Dans cet atelier, un serveur MCP a déjà été prédéployé. Il fournit des données
sur les animaux d'un zoo fictif aux LLM, par exemple lorsque vous utilisez la
Gemini CLI. Vous devrez créer un agent de guide touristique (une application
Python) pour le zoo fictif. L'agent utilise le serveur MCP pour accéder aux
informations sur les animaux du zoo et Wikipédia pour créer la meilleure
expérience de visite guidée possible.

Enfin, vous déploierez l'agent de guide touristique sur Google Cloud Run, afin
qu'il soit accessible à tous les visiteurs du zoo et pas seulement en local.
Prérequis
-
Un serveur MCP en cours d'exécution sur Cloud Run ou son URL de service
associée
- Un projet Google Cloud dans lequel la facturation est activée
Points abordés
Dans cet atelier, vous allez apprendre à effectuer les tâches suivantes :
- Structurer un projet Python pour le déployer avec ADK
- Implémenter un agent utilisant des outils avec google-adk
-
Connecter un agent à un serveur MCP distant pour utiliser son ensemble
d'outils
-
Déployer une application Python en tant que conteneur sans serveur sur
Cloud Run
-
Configurer une authentification sécurisée de service à service à l'aide de
rôles IAM
- Supprimer les ressources Cloud pour éviter d'accumuler des coûts
Ce dont vous avez besoin
- Un compte Google Cloud et un projet Google Cloud
-
Un navigateur Web (par exemple,
Chrome)
Pourquoi effectuer le déploiement sur Cloud Run ?
Cloud Run est parfait pour héberger des agents ADK, car il s'agit d'une
plate-forme sans serveur : vous pouvez donc vous concentrer sur votre code
sans avoir à gérer l'infrastructure sous-jacente. Cloud Run gère également les
tâches opérationnelles à votre place.
Il fonctionne un peu comme une boutique éphémère, qui n'ouvre et n'utilise des
ressources que lorsque des clients (en l'occurrence, des requêtes) se
présentent. Lorsqu'il n'y a pas de clients, la boutique est complètement
fermée, ce qui évite d'avoir à payer quand elle est vide.
Principales caractéristiques de Cloud Run
Exécute des conteneurs partout
-
Vous fournissez un conteneur (image Docker) contenant votre application.
- Cloud Run l'exécute sur l'infrastructure de Google.
-
Vous n'avez pas besoin de gérer les correctifs de l'OS, la configuration des
VM ni le scaling.
Scaling automatique
-
Si personne n'utilise votre application, aucune instance n'est exécutée
(vous ne payez rien en cas d'inactivité).
-
Si vous recevez soudain 1 000 requêtes, Cloud Run lance autant de ressources
que nécessaire pour les traiter.
Sans état par défaut
- Chaque requête peut être envoyée à une instance différente.
-
Si vous devez stocker l'état, utilisez un service externe comme Cloud SQL,
Firestore ou Redis.
Compatible avec n'importe quel langage ou framework
-
Tant qu'il s'exécute dans un conteneur Linux, Cloud Run est compatible avec
Python, Go, Node.js, Java ou .NET.
Services facturés à l'utilisation
-
Facturation par requête + temps de calcul (avec une précision à 100 ms).
-
À l'inverse des VM classiques, les ressources ne sont pas facturées
lorsqu'elles sont inactives.
Préparation
Avant de cliquer sur le bouton "Démarrer l'atelier"
Lisez ces instructions. Les ateliers sont minutés, et vous ne pouvez pas les mettre en pause. Le minuteur, qui démarre lorsque vous cliquez sur Démarrer l'atelier, indique combien de temps les ressources Google Cloud resteront accessibles.
Cet atelier pratique vous permet de suivre les activités dans un véritable environnement cloud, et non dans un environnement de simulation ou de démonstration. Des identifiants temporaires vous sont fournis pour vous permettre de vous connecter à Google Cloud le temps de l'atelier.
Pour réaliser cet atelier :
- Vous devez avoir accès à un navigateur Internet standard (nous vous recommandons d'utiliser Chrome).
Remarque : Ouvrez une fenêtre de navigateur en mode incognito (recommandé) ou de navigation privée pour effectuer cet atelier. Vous éviterez ainsi les conflits entre votre compte personnel et le compte temporaire de participant, qui pourraient entraîner des frais supplémentaires facturés sur votre compte personnel.
- Vous disposez d'un temps limité. N'oubliez pas qu'une fois l'atelier commencé, vous ne pouvez pas le mettre en pause.
Remarque : Utilisez uniquement le compte de participant pour cet atelier. Si vous utilisez un autre compte Google Cloud, des frais peuvent être facturés à ce compte.
Activer Cloud Shell
Cloud Shell est une machine virtuelle qui contient de nombreux outils pour les développeurs. Elle comprend un répertoire d'accueil persistant de 5 Go et s'exécute sur Google Cloud. Cloud Shell vous permet d'accéder via une ligne de commande à vos ressources Google Cloud.
-
Cliquez sur Activer Cloud Shell  en haut de la console Google Cloud.
en haut de la console Google Cloud.
-
Passez les fenêtres suivantes :
- Accédez à la fenêtre d'informations de Cloud Shell.
- Autorisez Cloud Shell à utiliser vos identifiants pour effectuer des appels d'API Google Cloud.
Une fois connecté, vous êtes en principe authentifié et le projet est défini sur votre ID_PROJET : . Le résultat contient une ligne qui déclare l'ID_PROJET pour cette session :
Your Cloud Platform project in this session is set to {{{project_0.project_id | "PROJECT_ID"}}}
gcloud est l'outil de ligne de commande pour Google Cloud. Il est préinstallé sur Cloud Shell et permet la complétion par tabulation.
- (Facultatif) Vous pouvez lister les noms des comptes actifs à l'aide de cette commande :
gcloud auth list
- Cliquez sur Autoriser.
Résultat :
ACTIVE: *
ACCOUNT: {{{user_0.username | "ACCOUNT"}}}
To set the active account, run:
$ gcloud config set account `ACCOUNT`
- (Facultatif) Vous pouvez lister les ID de projet à l'aide de cette commande :
gcloud config list project
Résultat :
[core]
project = {{{project_0.project_id | "PROJECT_ID"}}}
Remarque : Pour consulter la documentation complète sur gcloud, dans Google Cloud, accédez au guide de présentation de la gcloud CLI.
Tâche 1 : Télécharger et installer ADK et créer un dossier de projet
Dans cette tâche, vous allez activer les API requises et créer un dossier de
projet pour stocker le code source qui servira à déployer votre projet Python.
Activer les API et définir les variables d'environnement
-
Dans Cloud Shell, cliquez sur Ouvrir l'éditeur pour ouvrir
l'éditeur Cloud Shell dans votre répertoire d'accueil.
-
Dans la barre d'action de l'éditeur Cloud Shell, cliquez sur
View > Terminal (Afficher > Terminal).
Remarque : Vous devrez peut-être agrandir votre fenêtre de navigateur pour voir l'option de menu "View" (Afficher).
Pour le reste de cet atelier, utilisez cette fenêtre comme IDE, avec l'éditeur
Cloud Shell en haut et le terminal Cloud Shell en bas.
Fermez les éventuels tutoriels ou panneaux Gemini qui s'affichent sur le côté
droit de l'écran pour donner plus de place à l'éditeur de code.
-
Dans le terminal, saisissez la commande suivante pour configurer votre
projet :
gcloud config set project {{{project_0.project_id | filled in at lab start}}}
Résultat attendu : Vous devez voir un message confirmant
la mise à jour de la propriété.
Remarque : Si vous redémarrez Cloud Shell ou si la fenêtre reste inactive, vous devrez reconfigurer le projet.
-
Exécutez la commande suivante pour activer tous les services nécessaires.
gcloud services enable \
run.googleapis.com \
artifactregistry.googleapis.com \
cloudbuild.googleapis.com \
aiplatform.googleapis.com \
compute.googleapis.com
Résultat attendu : Vous devez voir un message de résultat
confirmant que l'opération a réussi.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Activer les API
Créer les répertoires du projet
-
Exécutez la commande suivante, qui crée un dossier principal dans
l'atelier pour le code source de l'agent :
mkdir zoo_guide_agent && cd zoo_guide_agent
-
Ensuite, exécutez la commande suivante pour créer un environnement
virtuel :
uv venv
-
Exécutez la commande suivante pour activer l'environnement virtuel :
source .venv/bin/activate
Vous êtes maintenant prêt à créer le fichier requirements.txt. Ce
fichier liste les bibliothèques Python dont votre agent de zoo a besoin.
-
Exécutez la commande suivante pour créer le fichier dans le répertoire
zoo_guide_agent et l'ouvrir dans l'éditeur Cloud Shell
afin de pouvoir le modifier :
cloudshell edit requirements.txt
-
Ajoutez les lignes suivantes au fichier requirements.txt et
appuyez sur Ctrl+S pour enregistrer vos modifications :
google-adk==1.12.0
langchain-community
wikipedia
-
Exécutez la commande suivante dans le terminal pour que le gestionnaire de
paquets uv installe vos packages Python :
uv pip install -r requirements.txt
-
Définissez des variables pour le projet, la région et l'utilisateur
actuels à l'aide des commandes suivantes :
export PROJECT_ID=$(gcloud config get-value project)
export REGION=$(gcloud compute project-info describe \
--format="value(commonInstanceMetadata.items[google-compute-default-region])")
export PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
export SERVICE_ACCOUNT="${PROJECT_NUMBER}-compute@developer.gserviceaccount.com"
Remarque : Si vous redémarrez Cloud Shell ou si la fenêtre reste inactive, vous devrez réinitialiser les variables ci-dessus.
-
Créez et ouvrez un fichier .env pour authentifier l'agent
dans le répertoire zoo_guide_agent à l'aide de la commande
suivante :
cloudshell edit .env
Le répertoire contenant le fichier .env s'ouvre dans l'éditeur
Cloud Shell.
-
Ajoutez les lignes suivantes au fichier .env et enregistrez
vos modifications :
MODEL="{{{ project_0.startup_script.gemini_flash_model_id | filled in at lab start }}}"
SERVICE_ACCOUNT="${PROJECT_NUMBER}-compute@developer.gserviceaccount.com"
Se connecter au point de terminaison du serveur MCP sécurisé
Dans cette section, vous allez établir une connexion au serveur MCP distant.
-
Revenez au terminal Cloud Shell et exécutez la commande suivante pour
autoriser l'identité de service Cloud Run à appeler le serveur MCP
distant :
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT" \
--role="roles/run.invoker"
-
Exécutez la commande suivante pour enregistrer l'URL du serveur MCP dans
une variable d'environnement :
echo -e "\nMCP_SERVER_URL=https://zoo-mcp-server-${PROJECT_NUMBER}.${REGION}.run.app/mcp/" >> .env
-
Ensuite, vous allez créer le fichier __init__.py. Ce fichier
indique à Python que le répertoire zoo_guide_agent est un
package :
cloudshell edit __init__.py
-
Dans l'éditeur Cloud Shell qui s'ouvre, ajoutez le code suivant à
__init__.py et enregistrez vos modifications :
from . import agent
Tâche 2 : Créer le workflow de l'agent
Dans cette tâche, vous allez configurer le workflow de l'agent de guide
touristique pour le zoo. Vous allez d'abord importer les bibliothèques
nécessaires à la configuration initiale. Ensuite, vous définirez les capacités
de l'agent du zoo (les outils qu'il utilise), ainsi que les agents
spécialisés. Enfin, vous définirez l'agent de workflow et vous assemblerez le
workflow principal.
Créer le fichier principal agent.py
Étape 1 : Importer les bibliothèques et effectuer la configuration initiale
Ce premier bloc importe toutes les bibliothèques nécessaires depuis ADK et
Google Cloud. Il configure également la journalisation et charge les variables
d'environnement à partir de votre fichier .env, ce qui est
essentiel pour accéder au modèle et à l'URL du serveur.
Étape 2 : Définir les outils (les capacités de l'agent)

Un agent n'est efficace que s'il dispose des bons outils. Dans cette section,
vous allez définir toutes les fonctionnalités de votre agent, y compris une
fonction personnalisée pour enregistrer des données, un outil MCP qui se
connecte à votre serveur MCP sécurisé, ainsi qu'un outil Wikipédia.
Présentation des trois outils
-
add_prompt_to_state 📝 : cet outil mémorise
les questions posées par les visiteurs du zoo. Lorsqu'un visiteur demande
"Où sont les lions ?", il enregistre cette question spécifique dans la
mémoire de l'agent afin que les autres agents du workflow sachent ce
qu'ils doivent rechercher.
Comment ? Une fonction Python écrit le prompt du visiteur
dans le dictionnaire partagé tool_context.state. Ce
dictionnaire représente la mémoire à court terme de l'agent pour une
conversation unique. Les données enregistrées dans l'état de session par
un agent peuvent être lues par l'agent suivant dans le workflow.
-
MCPToolset 🦁 : cet outil permet de
connecter l'agent de guide touristique au serveur MCP du zoo prédéployé
dans cet atelier. Ce serveur dispose d'outils dédiés à la recherche
d'informations spécifiques sur les animaux du zoo, comme leur nom, leur
âge et leur enclos.
Comment ? Il se connecte de manière sécurisée à l'URL du
serveur privé du zoo. Il utilise get_id_token pour obtenir
automatiquement une "carte d'accès" sécurisée (jeton d'ID de compte de
service) afin de prouver son identité et d'obtenir l'accès.
-
LangchainTool 🌍 : cet outil fournit à
l'agent de guide touristique des connaissances générales sur le monde. Si
un visiteur pose une question qui ne figure pas dans la base de données du
zoo (par exemple, "Que mangent les lions dans leur habitat naturel ?"),
cet outil permet à l'agent de rechercher la réponse sur Wikipédia.
Comment ? Il sert d'adaptateur permettant à l'agent
d'utiliser l'outil WikipediaQueryRun prédéfini depuis la bibliothèque
LangChain.
Ressources :
Étape 3 : Définir les agents spécialisés

Dans cette section, vous allez définir deux agents spécialisés : l'agent de
recherche et l'agent de formulation des réponses. L'agent de recherche
est le "cerveau" de votre opération. Cet agent interprète le prompt de
l'utilisateur à partir de l'état de session partagé, interroge
ses outils avancés (le serveur MCP du zoo et Wikipédia) et détermine celui
qu'il doit utiliser pour trouver la réponse.
Le rôle de l'agent de formulation des réponses est la présentation.
Il ne recherche aucune information nouvelle dans les outils. Son rôle est de
transformer les données brutes collectées par l'agent de recherche (transmises
via l'état de session) en réponse conviviale et conversationnelle en utilisant
les compétences linguistiques du LLM.
Étape 4 : Définir l'agent de workflow
L'agent de workflow est l'entité qui gère la visite du zoo en coulisses. Une
fois la demande de recherche envoyée, il s'assure que les deux agents que vous
avez définis à l'étape 3 interviennent dans le bon ordre : d'abord la
recherche, puis la formulation de la réponse. Il garantit que le processus
consistant à répondre aux questions des visiteurs du zoo est fiable et
rigoureux.
Comment ? Il s'agit d'un agent séquentiel
(SequentialAgent) spécifique qui ne réfléchit pas par lui-même.
Son seul rôle est d'exécuter une liste de sous-agents (l'agent de
recherche et l'agent de formulation) dans un ordre fixe, en transmettant
automatiquement la mémoire partagée de l'un à l'autre.
Étape 5 : Assembler le workflow principal

Le workflow principal est désigné par root_agent, qui sert de
point de départ à toutes les nouvelles conversations dans le framework ADK. Le
rôle principal de cet agent est d'orchestrer le processus global. Il agit
comme le contrôleur initial qui gère le premier tour de la conversation.
Votre fichier agent.py est maintenant terminé.
Les différentes étapes vous ont permis de comprendre le rôle spécifique de
chaque composant (outils, agents de traitement et agents de gestion) dans la
création du système intelligent final. Passons maintenant au déploiement.
Tâche 3 : Préparer l'application pour le déploiement
Maintenant que votre environnement local est prêt, vous devez préparer votre
projet Google Cloud pour déployer l'agent de guide touristique du zoo.
Cette étape implique de vérifier une dernière fois la structure de fichiers de
votre agent pour vous assurer qu'elle est compatible avec la commande de
déploiement. Plus important encore, vous allez configurer une autorisation IAM
essentielle qui permet à votre service Cloud Run déployé d'agir en votre nom
et d'appeler les modèles Agent Platform. Vous aurez ainsi la certitude que
l'environnement cloud est prêt à exécuter votre agent.
-
Revenez au terminal Cloud Shell et exécutez la commande suivante pour
charger les variables dans votre session shell :
source .env
-
Exécutez la commande suivante pour attribuer au compte de service le rôle
"Utilisateur Agent Platform", qui lui donne l'autorisation d'effectuer des
prédictions et d'appeler les modèles de Google :
# Accorder le rôle "Utilisateur Agent Platform" au compte de service
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT" \
--role="roles/aiplatform.user"
Tâche 4 : Déployer l'agent à l'aide de la CLI ADK
Maintenant que votre code local et votre projet Google Cloud sont prêts, il
est temps de déployer l'agent.
Dans cette tâche, vous allez utiliser la commande
adk deploy cloud_run, qui permet d'automatiser l'ensemble du
workflow de déploiement en toute simplicité. Cette commande unique crée un
package à partir du code, génère une image de conteneur, la transmet à
Artifact Registry et lance le service sur Cloud Run pour le rendre accessible
sur le Web.
Déployer l'agent
-
Exécutez la commande suivante pour déployer l'agent :
# Exécuter la commande de déploiement
adk deploy cloud_run \
--project=$PROJECT_ID \
--region=$REGION \
--service_name=zoo-tour-guide \
--with_ui \
.
-
Si vous êtes invité à confirmer que vous souhaitez continuer et/ou à
autoriser les appels non authentifiés vers [zoo-tour-guide],
appuyez sur Y dans les deux cas, puis sur
ENTRÉE.
Remarque : L'exécution de cette commande de déploiement peut prendre entre 5 et 10 minutes.
-
Exécutez la commande suivante pour modifier les paramètres de
configuration du service Cloud Run existant :
gcloud run services update zoo-tour-guide \
--region=$REGION \
--update-labels=dev-tutorial=codelab-adk
Obtenir le lien de déploiement
-
Une fois l'agent déployé dans Cloud Run, appuyez sur CTRL et cliquez sur
l'URL du service dans le résultat pour l'ouvrir dans un
nouvel onglet de navigateur.
Le format doit ressembler au résultat suivant.
Résultat de l'URL du service :
https://zoo-tour-guide-{{{project_0.startup_script.project_number | filled in at lab start}}}.{{{project_0.default_region | filled in at lab start}}}.run.app
Comme vous avez utilisé le flag --with_ui lors du déploiement sur
Cloud Run, vous devriez voir l'UI de développement ADK.
Remarque : Toute personne disposant de l'URL peut accéder à cet agent. Il est donc recommandé de réserver cette approche aux tests internes.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Déployer l'agent
Tâche 5 : Tester l'agent déployé
Maintenant que votre agent est en service sur Cloud Run, vous allez effectuer
un test pour vérifier que le déploiement a réussi et que l'agent fonctionne
comme prévu. Vous devez utiliser l'URL du service public pour accéder à
l'interface Web d'ADK et interagir avec l'agent.
-
Ouvrez l'URL publique du service Cloud Run qui a été générée à la tâche
précédente dans votre navigateur Web ou cliquez sur l'URL dans le résultat
(elle doit s'ouvrir dans un nouvel onglet de navigateur). L'UI de
développement ADK s'ouvre.
-
Activez l'option Token Streaming (Distribution de jetons)
en haut à droite de la barre d'outils ADK.
Vous pouvez maintenant interagir avec l'agent du zoo.
-
Saisissez Bonjour dans le champ du prompt et appuyez sur
ENTRÉE pour démarrer une nouvelle conversation.
Observez le résultat. L'agent doit répondre rapidement en présentant son
message de bienvenue standard :
"🍎 Bonjour ! Je suis le guide du zoo. Je peux vous aider à découvrir les animaux incroyables qui vivent ici. Que souhaitez-vous savoir ou explorer aujourd'hui ?"
-
Maintenant, interagissez avec l'agent de guide touristique. Saisissez la
requête suivante pour démarrer une nouvelle conversation :
Où sont les manchots ?
Vous devriez obtenir un résultat semblable à celui-ci :
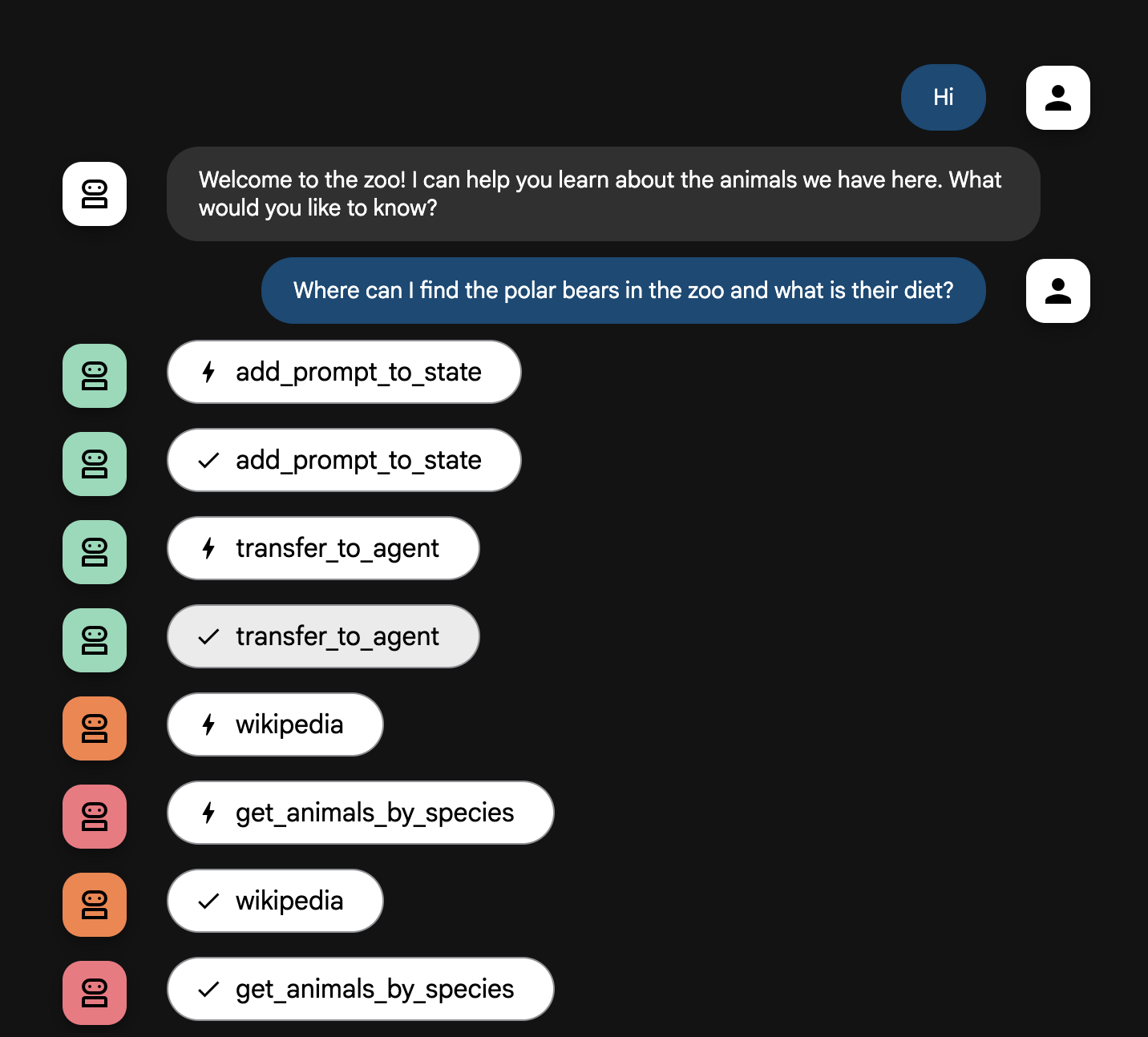

Explication du flux de l'agent
Votre système fonctionne comme une équipe intelligente multi-agents. Le
processus est géré par une séquence claire pour assurer un flux efficace et
fluide, de la question de l'utilisateur à la réponse détaillée finale.
1. L'accueil du zoo ("La réception")
L'ensemble du processus commence par l'agent qui accueille les utilisateurs.
Son rôle : lancer la conversation. Sa consigne est de saluer
l'utilisateur et de lui demander quel animal l'intéresse.
Son outil : lorsque l'utilisateur répond, cet agent utilise
l'outil add_prompt_to_state pour recueillir ses mots exacts (par exemple, "je
veux en savoir plus sur les lions") et les enregistrer dans la mémoire du
système.
Le transfert : après avoir enregistré le prompt, il passe
immédiatement le contrôle au sous-agent tour_guide_workflow.
2. Le chercheur complet ("Le superchercheur")
Cet agent intervient en premier dans le workflow principal et représente le
"cerveau" de l'opération. Au lieu d'une grande équipe, vous disposez désormais
d'un seul agent hautement qualifié qui peut accéder à toutes les informations
disponibles.
Son rôle : analyser la question de l'utilisateur et élaborer
un plan intelligent. Il utilise la fonctionnalité avancée d'exploitation des
outils intégrée au modèle de langage pour déterminer s'il a besoin :
-
des données internes issues des registres du zoo (via le serveur MCP) ;
- des informations générales issues du Web (via l'API Wikipédia) ;
- ou des deux, pour les questions complexes.
Son action : il exécute les outils nécessaires pour collecter
toutes les données brutes requises. Par exemple, si on lui demande "Quel âge
ont vos lions et de quoi se nourrissent-ils dans leur habitat naturel ?", il
appellera le serveur MCP pour obtenir l'âge et l'outil Wikipédia pour obtenir
des informations sur leur régime alimentaire.
3. L'outil de formulation des réponses ("Le présentateur")
Une fois que l'agent de recherche a rassemblé tous les faits, c'est le dernier
agent à entrer en action.
Son rôle : incarner la voix bienveillante du guide du zoo. Il
prend les données brutes (qui peuvent provenir d'une seule source ou des deux)
et les affine.
Son action : il synthétise toutes les informations en une
seule réponse cohérente et dynamique. En suivant ses instructions, il présente
d'abord les informations spécifiques au zoo, puis ajoute les informations
générales pertinentes.
Résultat final : le texte généré par cet agent constitue la
réponse complète et détaillée que l'utilisateur voit dans la fenêtre de
discussion.
Étapes suivantes et informations supplémentaires
Si vous souhaitez en savoir plus sur la création d'agents, consultez les
ressources suivantes :
Tâche 6 : Nettoyer l'environnement
Dans cette tâche, vous allez supprimer les ressources cloud que vous avez
créées dans cet atelier pour éviter d'accumuler des frais.
Félicitations !
Dans cet atelier, vous avez appris à structurer un projet Python pour le
déployer à l'aide de l'interface de ligne de commande ADK, à implémenter un
workflow multi-agent, à vous connecter à un serveur MCP distant pour utiliser
ses outils, à enrichir des données internes en intégrant des outils externes
comme l'API Wikipédia et à déployer l'agent en tant que conteneur sans serveur
sur Cloud Run.
Dernière mise à jour du manuel : 13 octobre 2025
Dernier test de l'atelier : 13 octobre 2025
Copyright 2026 Google LLC. Tous droits réservés. Google et le logo Google sont des marques de Google LLC. Tous les autres noms d'entreprises et de produits peuvent être des marques des entreprises auxquelles ils sont associés.





