
始める前に
- ラボでは、Google Cloud プロジェクトとリソースを一定の時間利用します
- ラボには時間制限があり、一時停止機能はありません。ラボを終了した場合は、最初からやり直す必要があります。
- 画面左上の [ラボを開始] をクリックして開始します
Generate images
/ 30
Prompt a model to analyze a long-format video
/ 30
Build a spatial understanding app from a template
/ 40
Generate images
/ 30
Prompt a model to analyze a long-format video
/ 30
Build a spatial understanding app from a template
/ 40

このラボでは、Google AI Studio の強力なマルチモーダル機能について、生成 AI と空間認識に焦点を当てて学習します。実践的な演習を通じて、最先端の AI モデルを実際に操作し、アプリケーションに統合する方法を学びます。博物館の学芸員、展示デザイナーとして、これらのツールを使用して、博物館の新しい展示の要素についてアイデアを出し、プロトタイプを作成します。
このラボでは、次の方法について学びます。
こちらの説明をお読みください。ラボには時間制限があり、一時停止することはできません。タイマーは、Google Cloud のリソースを利用できる時間を示しており、[ラボを開始] をクリックするとスタートします。
このハンズオンラボでは、シミュレーションやデモ環境ではなく実際のクラウド環境を使って、ラボのアクティビティを行います。そのため、ラボの受講中に Google Cloud にログインおよびアクセスするための、新しい一時的な認証情報が提供されます。
このラボを完了するためには、下記が必要です。
[ラボを開始] をクリックします。ラボパネルにこのラボ用の一時的な認証情報が表示されます。
シークレット ウィンドウで Google AI Studio を開きます。Google ログインページが表示されます。
以下のユーザー名をコピーして [Email] 欄に貼り付け、[Next] をクリックします。
以下のパスワードをコピーして [Enter your password] 欄に貼り付け、[Next] をクリックします。
画面に表示される利用規約に同意して続行します。
これで、一時的な受講者用アカウントを使用して Google AI Studio にログインできます。
このタスクでは、新しい恐竜展のコンセプト アートを作成する学芸員の役割を担います。これには、メディア生成専用に設計されたモデルを使用します。
左側のナビゲーション メニューで [Playground] をクリックして、メインのチャット インターフェースを開きます。
右側のパネルで [Run settings] を開き、[Model selection] の下の [Gemini] タブに移動して、[Nano Banana] を選択します。
プロンプトの入力フィールドに、コンセプト アートのリクエストを入力します。
[Run] をクリックして、生成された画像を確認します。この画像は、新しい展示のデザインのベースとして使える可能性があります。
ポップアップで、[Enable Google Drive] をクリックし、受講者用アカウント(例: student-XX-YYYY@qwiklabs.net)を選択して、必要な権限を付与して続行します。
プロンプトと回答を保存するには、自動生成されたタイトルの横にある編集アイコンをクリックし、[Prompt name] として「近未来的な博物館のロビー」と入力します。
[Save] をクリックします。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
このタスクでは、アメリカ自然史博物館の動画ツアーの分析を Gemini にリクエストして、成功した既存の展示を調査します。
左側のナビゲーション メニューで [Playground] をクリックして、メインのチャット インターフェースに戻ります。
右側のパネルで [Run settings] サイドバーを開き、デフォルトの Gemini モデル(現在は Nano Banana に設定)をクリックして別のモデルを選択します。
[Model selection] で [Gemini] タブをクリックして、動画などの大量の入力に対応するように設計されている
プロンプト バー内の添付ファイル アイコン(円で囲んだプラス記号)をクリックし、[Sample Media] を選択します。
動画のリストから [American Museum of Natural History Tour - 10 Min] を選択し、[Add to prompt] をクリックします。
動画の処理が終了するまで待ちます。プロンプト領域に、動画がトークン数とともに表示されます。
[Run] をクリックして、動画の内容についてモデルが要約したテキストを確認します。
プロンプトと回答を保存するには、自動生成されたタイトルの横にある編集アイコンをクリックし、[Prompt name] に「博物館の展示の見どころ」と入力します。
[Save] をクリックします。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
このタスクでは、コードを記述せずにテンプレートからアプリを構築して、博物館の来場者向けのインタラクティブな「展示品の確認」機能のプロトタイプを迅速に作成します。
左側のナビゲーション メニューで [Build] をクリックします。
アプリ テンプレートのギャラリーをスクロールして、[Spatial Understanding] カードを見つけます。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
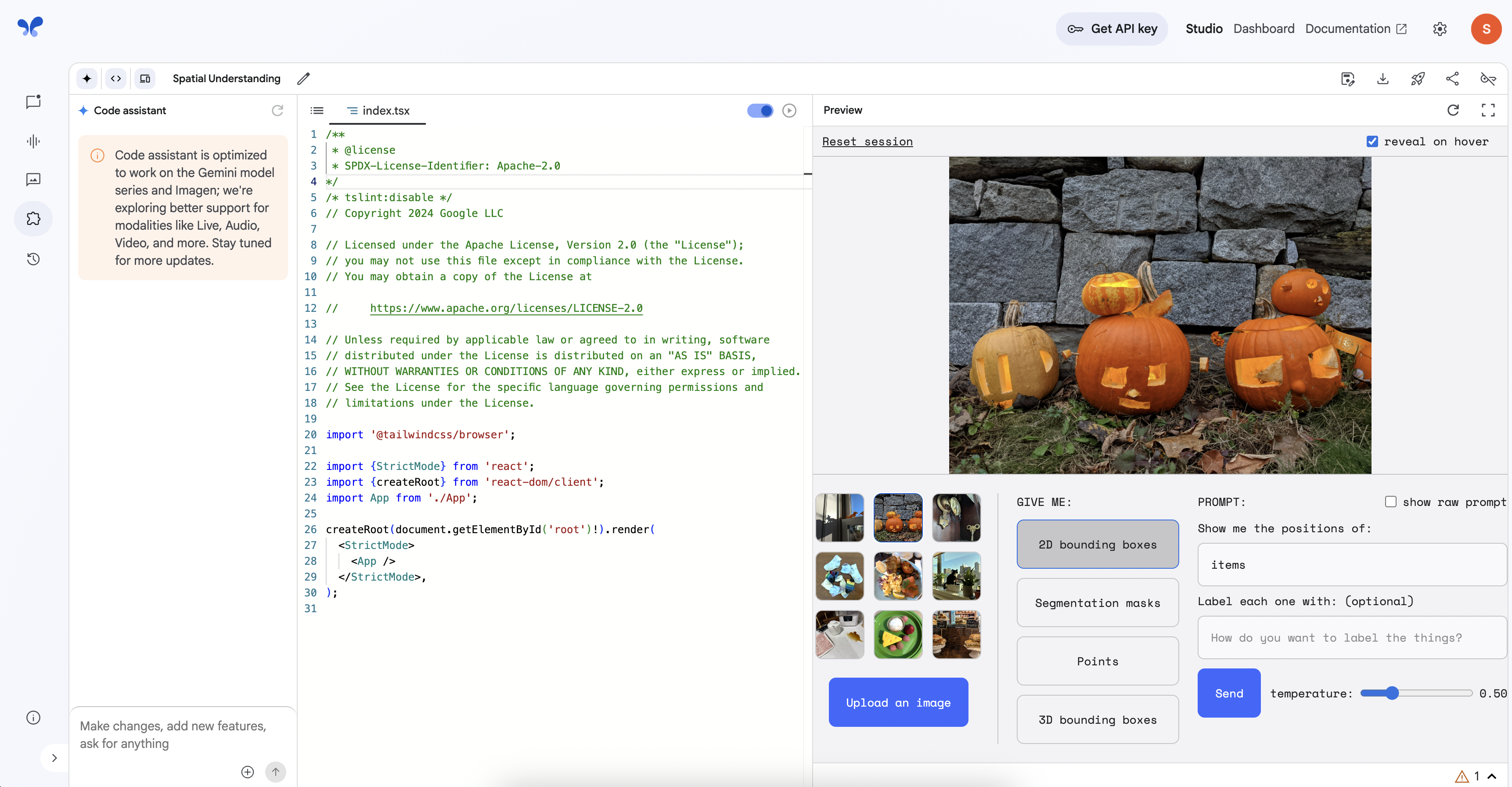
このタスクでは、構築したプロトタイプをテストします。訪問者の操作のシミュレーションとして、収穫祭の展示のサンプル画像内でオブジェクトを特定するようにアプリに指示し、境界ボックスの色を変更するようにコードを変更します。
アプリの [Preview] ペインで、下部にあるサンプル画像を確認します。複数のカボチャが並んでいる画像をクリックします。
プロンプト ボックスの上にある [2D bounding boxes] ボタンが選択されていることを確認します。[PROMPT] 入力ボックスに「カボチャ」と入力し、[Send] をクリックします。カボチャの周囲に標準の境界ボックスが描画されることを確認します。
次に [Segmentation masks] ボタンを選択して、もう一度 [Send] をクリックします。この出力では、検出された各カボチャの面全体が色付きに変わることに注目してください。
最後に、[Points] ボタンを選択し、[Send] をクリックします。検出されたオブジェクトにキーポイントが配置されることを確認します。
続行する前に、[Preview] ペインで [2D bounding boxes] ボタンが再度選択されていることを確認します。
画面の左下にある [Code assistant] 入力フィールドを確認します。フィールド内に「Make changes, add new features...」と表示されています。以下のコマンドを入力します。
[Remix] をクリックするか、アシスタントの送信ボタンを押して、[Apply] を選択します。新しいブラウザ ウィンドウが開きます。ページで [Acknowledge] をクリックし、アシスタントがエディタ ウィンドウでアプリケーション コードを更新するのを確認します。
コードが更新されたら、右側の [Preview] ペインに戻ります。カボチャの画像と [2D bounding boxes] が選択された状態で、「カボチャ」のプロンプトの [Send] ボタンを最後にもう一度クリックします。
結果を確認します。カボチャの周囲に描画された境界ボックスが赤色になり、シンプルなテキスト コマンドでライブ アプリケーションを変更できたことがわかります。
オプションのチャレンジ: テキストを使用してアプリを簡単に変更できることを確認しました。最後に、コード アシスタントで、ほかにもいくつかのコマンドを試してみましょう。次の処理を行う方法を考えてみてください。
緑色に変更する点線にするプロンプトと回答を保存するには、自動生成されたタイトルの横にある編集アイコンをクリックし、[Prompt name] に「空間認識」と入力します。
[Save] をクリックします。
これで完了です。Google AI Studio のマルチモーダル機能を活用して、博物館の新しい展示のアイデアを出し、プロトタイプを作成しました。コンセプト アートや動画クリップの生成、既存の動画ツアーの分析、空間認識アプリを使用したインタラクティブなプロトタイプの構築を行いました。さまざまなリッチメディアを認識、理解、生成できる AI を実際に使用する体験ができました。
Google Cloud トレーニングと認定資格を通して、Google Cloud 技術を最大限に活用できるようになります。必要な技術スキルとベスト プラクティスについて取り扱うクラスでは、学習を継続的に進めることができます。トレーニングは基礎レベルから上級レベルまであり、オンデマンド、ライブ、バーチャル参加など、多忙なスケジュールにも対応できるオプションが用意されています。認定資格を取得することで、Google Cloud テクノロジーに関するスキルと知識を証明できます。
マニュアルの最終更新日: 2026 年 3 月 5 日
ラボの最終テスト日: 2026 年 3 月 5 日
Copyright 2026 Google LLC. All rights reserved. Google および Google のロゴは Google LLC の商標です。その他すべての企業名および商品名はそれぞれ各社の商標または登録商標です。



このコンテンツは現在ご利用いただけません
利用可能になりましたら、メールでお知らせいたします

ありがとうございます。
利用可能になりましたら、メールでご連絡いたします

1 回に 1 つのラボ
既存のラボをすべて終了して、このラボを開始することを確認してください
ラボを開始するには、この簡単な手順を完了してください。