
Before you begin
- Labs create a Google Cloud project and resources for a fixed time
- Labs have a time limit and no pause feature. If you end the lab, you'll have to restart from the beginning.
- On the top left of your screen, click Start lab to begin
Configure a Service Account & IAM permissions
/ 20
Configure credential file for a Service Account
/ 20
Modify the application to save text from images to Cloud Storage
/ 20
Modify the application to translate text using the Language API
/ 20
Query the BigQuery table
/ 20
Configure a Service Account & IAM permissions
/ 20
Configure credential file for a Service Account
/ 20
Modify the application to save text from images to Cloud Storage
/ 20
Modify the application to translate text using the Language API
/ 20
Query the BigQuery table
/ 20

在挑戰研究室中,您會在特定情境下完成一系列任務。挑戰研究室不會提供逐步說明,您將運用從課程研究室學到的技巧,自行找出方法完成任務!自動評分系統 (如本頁所示) 將根據您是否正確完成任務來提供意見回饋。
在您完成任務的期間,挑戰研究室不會介紹新的 Google Cloud 概念。您須靈活運用所學技巧,例如變更預設值或詳讀並研究錯誤訊息,解決遇到的問題。
若想滿分達標,就必須在時限內成功完成所有任務!
本實驗室適合已參加「在 Google Cloud 使用機器學習 API」課程的學員。準備好迎接挑戰了嗎?
請詳閱以下操作說明。實驗室活動會計時,且中途無法暫停。點選「Start Lab」後就會開始計時,顯示可使用 Google Cloud 資源的時間。
您將在真正的雲端環境完成實作實驗室活動,而不是模擬或示範環境。為此,我們會提供新的暫時憑證,供您在實驗室活動期間登入及存取 Google Cloud。
為了順利完成這個實驗室,請先確認:
按一下「Start Lab」按鈕。如果實驗室會產生費用,請在開啟的對話方塊中選取付款方式。右側的「Lab setup and access」面板會顯示下列項目:
請注意,實驗室計時器位於頁面頂端附近,會顯示剩餘時間。
按一下「Open Google Cloud console」。如果使用 Chrome 瀏覽器,也可以按一下滑鼠右鍵,選取「在無痕視窗中開啟連結」。
接著,實驗室會啟動相關資源,並開啟另一個分頁,顯示「登入」頁面。
提示:您可以在不同的視窗並排開啟分頁。
如有必要,請將下方的 Username 貼到「登入」對話方塊。
您也可以在「Lab setup and access」面板找到「Username」。
點選「下一步」。
複製下方的 Password,並貼到「歡迎使用」對話方塊。
您也可以在「Lab setup and access」面板找到「Password」。
點選「下一步」。
繼續點按後續頁面:
Google Cloud 控制台稍後會在這個分頁開啟。

您是 Jooli 公司數據分析團隊新上任的成員,職責是為公司的機器學習專案協助開發及評估資料集。常見工作包括準備、清理及分析各種資料集。
公司預期您具備執行這些工作所需的技能與知識,因此不會提供逐步指南。
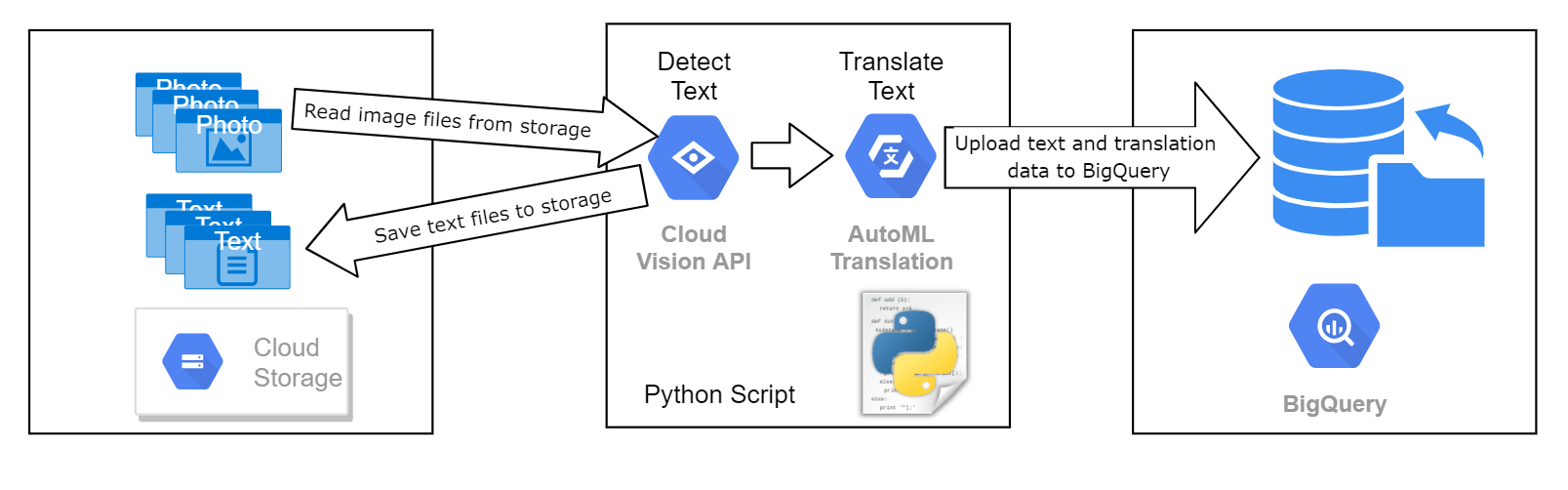
您受託開發程序,分析一組招牌圖片,擷取並翻譯圖片中的文字。這項機器學習專案會使用這個圖片資料集訓練及評估模型,因此我們將使用擷取出的文字資訊來協助分類圖像。所有圖片都包含文字,但文字可能屬於任何語言。圖片會儲存在我們為您提供的 Cloud Storage bucket 中。
您必須使用 Python 指令碼處理每個圖片檔,方法是將圖片檔傳送至 Google Vision API,辨識圖片中的文字。每張圖片的文字都必須儲存回 Cloud Storage 的檔案,每張圖片的文字都應儲存至個別檔案。如果文字語言代碼不是
下圖概略呈現了這個程序。
接著,您必須將處理後的文字資料寫入專案中名為 image_classification_dataset 的資料集,並儲存至預先建立的 BigQuery 資料表 image_text_detail。
團隊中的一位同事已開始編寫程式碼,打算根據先前用來處理一組文字檔的 Python 指令碼,透過 Natural Language API 處理這些圖片。您的同事已調到其他專案,現在必須由您完成這項工作。
這個指令碼的大部分工作都已完成,您收到的版本會存取儲存空間 bucket,並對每個找到的圖片檔進行疊代。不過,由於尚未實作具體的 API 呼叫,您需要進行這項程序,以便找出每張圖片中的文字,然後將該文字傳送至 Translation API。
我們已將進行中的 Python 指令碼副本和一組範例圖片,存放在以實驗室專案 ID 命名的 Cloud Storage bucket 中。
您的同事找出指令碼中未完成的部分,並為需要發出的 API 呼叫加上註解。指令碼中有三個未完成的部分,您必須完成這些內容,才能正確呼叫機器學習 API。這些程式碼都附有 # TBD: 標籤的註解。
最後一行程式碼會將結果資料上傳至 BigQuery。在指令碼中,這行程式碼已透過註解字元停用。確認指令碼的其餘部分運作正常後,請移除註解字元,啟用最後一行程式碼。
處理指令碼前,您必須先準備環境,包括建立具備適當權限的服務帳戶,並下載該帳戶的憑證檔案。取得服務帳戶憑證後,即可修改 Python 指令碼,用來處理圖片檔。
為完成挑戰,您必須將所有圖片的原始擷取文字、語言代碼和翻譯文字資料載入名為 image_text_detail 的 BigQuery 資料表。這項作業的程式碼位於指令碼中,但您必須移除註解字元,才能啟用指令碼結尾的程式碼行。
在您使用更新後的 Python 指令碼成功處理圖像檔案,並將資料上傳至 BigQuery 後,您必須在 BigQuery 中執行下列查詢,確認圖像資料已成功處理:
這項查詢會回報在樣本圖像集中找到的每種語言標誌數量。
從系統為您建立的 Cloud Storage bucket,將 analyze-images-v2.py 檔案複製到 Cloud Shell。
您必須修改這個 Python 指令碼,從專案 bucket 中儲存的圖片檔擷取文字,然後將每個檔案的文字資料儲存到文字檔案,並寫回同一個 bucket。請注意,指令碼中標上 # TBD 註解的部分,表示您需要加入程式碼來存取 API。
在您修改指令碼的第一部分,使用 Cloud Vision API 從圖片檔擷取文字資料後,請執行部分完成的指令碼,確認進度是否正確。
現在請修改 Python 指令碼的第二部分,找出 Vision API 找到的任何
提示 1:您必須設定環境變數,提供 Python 指令碼應使用的憑證檔案詳細資料,才能存取 Google Cloud API。
提示 2:您可以在 Vision API 用戶端的 Python API 說明文件參考頁面中,找到 Vision API 用戶端 document_text_detection API 呼叫的詳細資料;在 Vision API 物件的 Python API 說明文件參考頁面中,找到 Vision API 註解回應物件的詳細資料。
提示 3:如要進一步瞭解 Translation API 用戶端的 Translate API 呼叫,請參閱 Translation V2 API 用戶端的 Python API 說明文件。
您已開發了一套程序,可分析招牌圖片,並擷取及翻譯圖片中的文字。
協助您瞭解如何充分運用 Google Cloud 的技術。我們的課程會介紹專業技能和最佳做法,讓您可以快速掌握要領並持續進修。我們提供從基本到進階等級的訓練課程,並有隨選、線上和虛擬課程等選項,方便您抽空參加。認證可協助您驗證及證明自己在 Google Cloud 技術方面的技能和專業知識。
使用手冊上次更新日期:2025 年 9 月 2 日
實驗室上次測試日期:2025 年 9 月 2 日
Copyright 2026 Google LLC 保留所有權利。Google 和 Google 標誌是 Google LLC 的商標,其他公司和產品名稱則有可能是其關聯公司的商標。



This content is not currently available
We will notify you via email when it becomes available

Great!
We will contact you via email if it becomes available

One lab at a time
Confirm to end all existing labs and start this one
Complete this quick step to start your lab.