
始める前に
- ラボでは、Google Cloud プロジェクトとリソースを一定の時間利用します
- ラボには時間制限があり、一時停止機能はありません。ラボを終了した場合は、最初からやり直す必要があります。
- 画面左上の [ラボを開始] をクリックして開始します
Import a CSV file and create a standard table
/ 20
Create a table based on the results of a query using CTAS
/ 20
Work with nested data
/ 20
Deduplicate data
/ 20
Answer business questions with a report
/ 20
Import a CSV file and create a standard table
/ 20
Create a table based on the results of a query using CTAS
/ 20
Work with nested data
/ 20
Deduplicate data
/ 20
Answer business questions with a report
/ 20
 重要:
重要: 各タスクの作業内容のスクリーンショットを撮り、ポートフォリオに追加してください。
各タスクの作業内容のスクリーンショットを撮り、ポートフォリオに追加してください。 このハンズオンラボは、デスクトップ パソコンまたはノートパソコンでのみ完了するようにしてください。
このハンズオンラボは、デスクトップ パソコンまたはノートパソコンでのみ完了するようにしてください。 ラボごとに 5 回までしか試行できません。
ラボごとに 5 回までしか試行できません。 なお、最初の試行で全問正解できないことや、タスクをやり直す必要があることはよくあります。これは学習プロセスの一部です。
なお、最初の試行で全問正解できないことや、タスクをやり直す必要があることはよくあります。これは学習プロセスの一部です。 ラボを開始すると、タイマーを一時停止することはできません。1 時間 30 分後にラボは終了し、最初からやり直す必要があります。
ラボを開始すると、タイマーを一時停止することはできません。1 時間 30 分後にラボは終了し、最初からやり直す必要があります。 詳しくは、ラボでの技術的なヒントの資料をご覧ください。
詳しくは、ラボでの技術的なヒントの資料をご覧ください。
このラボは、キャップストーン プロジェクトの一部です。このラボでは、クラウドデータ分析とデータ ジャーニーの最初の 3 つの段階(収集、処理、保存)に関する知識を当てはめます。
このラボでは、シナリオと、BigQuery を使用して完了すべき一連のタスクが用意されています。これらのタスクでは、BigQuery 環境でデータを操作して変換するスキルを使用し、データに関する質問に答え、データ変換スキルをテストする課題を完了する必要があります。
このラボを完了すると、BigQuery などのクラウドデータ プラットフォームをデータの保存と分析に使用する能力を実証し、特定のビジネスニーズに対応するために SQL を適用してデータを探索、フィルタ、重複除去、集計する実践的な経験を積むことができます。
TheLook Fintech は、在庫購入資金を必要とする独立したオンライン ストア オーナーに融資を提供する新興金融テクノロジー企業です。同社の使命は、融資方法を変えて、企業を成長させることです。TheLook Fintech は、成長段階にあるスタートアップ企業として、ターゲット市場を的確に特定し、現在、急速なスケールアップに向けた取り組みを進めています。
あなたはクラウドデータ アナリストとして採用されました。最初の任務は、財務部門がデータを効果的に活用して業績と成長を追跡できるようにするための計画を策定し、実装することです。
財務部門の責任者であるトレバーとの会議で、3 つのビジネス上の質問が特定されました。
これらの質問は次のとおりです。
トレバーとの会議では、これらのビジネス上の質問に答えるために必要な主要な指標についての重要な情報を得ることもできました。
キャッシュフローとは、時間の経過に応じて会社に出入りする現金の額を示します。TheLook Fintech は、融資を受ける額やその他の資金調達元からの入金額が、融資の資金提供やその他の費用の支払いによる出金額を上回るようにする必要があります。
融資の目的も、追跡すべき重要な指標です。トレバーは、借り手が融資を受ける理由と、その融資を返済する可能性との間に強い相関関係があると説明しました。融資業務が順調に進んでいることを確認するには、融資の主な目的をモニタリングすることが重要です。
また、借り手の所在地も重要な懸念事項です。財務部門は、融資の地理的な分布について把握しようとしています。これは、融資が 1 つの地域に集中すると、集団不履行のリスクが高まる可能性が大きいからです。地域間で融資を均等に分散し、融資の返済に関して特定の地域に過度に依存しないようにすることで、このリスクを軽減できます。
分析では、これら 3 つの主要な指標に焦点を当てます。
このラボでは、BigQuery を使用してデータを収集、処理、保存し、これらのビジネス上の質問に答え、トレバーのために一連のレポートを準備します。
これには、第一に BigQuery の作業環境を設定します。第二に、融資データを調べて、トレバーがリクエストしている情報を見つけます。第三に、州の新たな分類を含むファイルをインポートし、データを標準テーブルとして保存します。第四に、2 つのテーブルを結合して、結合データを含むレポートを作成します。第五に、目的データの重複を除去します。最後に、日次および年次の融資総額を示すレポートを作成します。
こちらの手順をお読みください。ラボには時間制限があり、一時停止することはできません。[ラボを開始] をクリックすることでスタートするタイマーは、Google Cloud のリソースを利用できる時間を示しています。
この実践ラボでは、シミュレーションやデモ環境ではなく、実際のクラウド環境を使ってご自身でアクティビティを行うことができます。そのため、ラボの受講中に Google Cloud にログインおよびアクセスするための、新しい一時的な認証情報が提供されます。
このラボを完了するためには、以下が必要です。
[ラボを開始] ボタンをクリックします。左側の [ラボの詳細] パネルには、以下が表示されます。
[Google Cloud コンソールを開く] をクリックします(Chrome ブラウザを使用している場合は、右クリックして [シークレット ウィンドウで開く] を選択します)。新しいブラウザタブで [ログイン] ページが開きます。
ヒント: タブをそれぞれ別のウィンドウで開き、並べて表示しておくと、簡単に切り替えられます。
必要に応じて、下のGoogle Cloud ユーザー名をコピーして、[ログイン] ダイアログに貼り付けます。[Next] をクリックします。
[ラボの詳細] パネルでも Google Cloud ユーザー名を確認できます。
[ラボの詳細] パネルでも Google Cloud のパスワードを確認できます。
しばらくすると、このタブで Cloud コンソールが開きます。

クラウドデータ アナリストは、プロジェクトの作業を開始する際に、まず作業環境を開き、分析で使用するデータを見つける必要があります。
このタスクでは、BigQuery 環境を開き、既存の BigQuery プロジェクトを選択して、fintech データセットを見つけます。
fintech データセットには、トレバーのビジネス上の質問に回答するために使用できる融資情報が含まれています。重要な情報の一つは、融資の合計額です。
このタスクでは、fintech データセットのテーブルを調べて、融資の合計額を含むテーブルと列を見つけます。この情報は、トレバーが会社の現金支出を把握するうえで重要です。
トレバーによれば、TheLook Fintech が顧客に融資する際に、顧客が資金を利用できる日付は「発行日」と呼ばれています。これは、トレバーのチームが毎日または毎月支払われる現金の合計額を追跡するために必要な、もう 1 つの重要な情報です。
fintech データセット内で各融資の発行日を含むテーブルを見つけて、次の質問に答えてください。
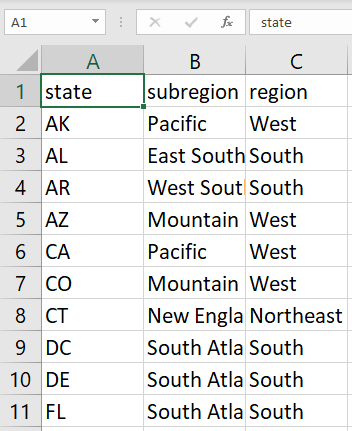
分析に必要なデータのほとんどは fintech データセット内にありますが、一部のデータは別の情報源から収集する必要があります。トレバーから、米国の州を地域と小地域にマッピングしている CSV ファイルが提供されています。この情報を使用することで、トレバーは借り手が融資を受けた州または地域別に融資を追跡できます。
CSV ファイルは、Cloud Storage の次の場所にあります。
CSV ファイルのデータの例を以下に示します。
このタスクでは、CSV ファイルを BigQuery にインポートし、標準テーブルとして保存します。
上記のコマンドをコピーして [無題] タブに貼り付け、CSV ファイルのデータを含む標準テーブルを作成します。
[実行] をクリックします。
次に、作成したテーブルを確認し、元の CSV ファイルと比較します。
[エクスプローラ] ペインで、state_region テーブルを選択します。テーブルが表示されない場合は、データセットの更新が必要な可能性があります。
[プレビュー] タブをクリックして、BigQuery にインポートしたデータを確認します。
[進行状況を確認] をクリックして、このタスクが正しく完了したことを確認します。
必要なデータを調べて収集したので、分析に使用できるようにデータを処理する準備が整いました。
トレバーは、loan_id、loan_amount、region の名前を含む単一のレポートを必要としていますが、これらの情報は現在 2 つのテーブルに分かれています。
このタスクでは、必要な列を含むテーブルを特定し、SQL を使用して 2 つのテーブルを結合して、レポートを作成します。
クエリ A
クエリ B
トレバーは、レポートのデータを Google スプレッドシートでさらにフィルタリングして分析したいと考えています。
これにはまず、データを保存するテーブルを作成する必要があります。
CTAS ステートメント(CREATE TABLE AS SELECT ステートメント)は、SELECT ステートメントの結果に基づいて新しいテーブルを作成する SQL ステートメントです。これは、新しいテーブルをすばやく簡単に作成できる強力なツールです。CTAS ステートメントで作成したテーブルは、BigQuery で簡単にエクスポートして他のユーザーと共有することもできます。
このタスクでは、CREATE TABLE AS SELECT を使用して新しいテーブルを作成し、そのテーブルを Google スプレッドシートに接続します。
CREATE OR REPLACE TABLE を使用して、テーブルを作成するか、既存のテーブルを置き換えます。[実行] をクリックします。
新しいテーブルを見つけます。更新が必要な場合があります。
[進行状況を確認] をクリックして、このタスクが正しく完了したことを確認します。
[エクスプローラ] ペインで、新しく作成した loan_with_region テーブルを選択します。テーブルが表示されない場合は、[更新] をクリックしてデータセットを更新します。
スプレッドシートを開くには、[Google スプレッドシートを開く] のリンクを右クリックし、[新しいシークレット ウィンドウ] でリンクを開くオプションを選択します。
Google Workspace にログインするには、現在のラボページに記載されている認証情報(ユーザー名とパスワード)を使用します。
ツールバーで [次で開く] をクリックし、[コネクテッド シート] を選択します。[開始する] をクリックします。
loan_with_region テーブルに接続されているのと同じデータを含む Google スプレッドシートが開きます。
Google スプレッドシートのデータを確認します。
これで、Google スプレッドシートをトレバーと共有して、スプレッドシート形式でデータを操作できるようになりました。
トレバーは、人々が TheLook Fintech から融資を受ける主な理由を調査しています。これは、借り手が融資を受ける理由が、資金が返済されるかどうかを的確に予測することがわかったためです。
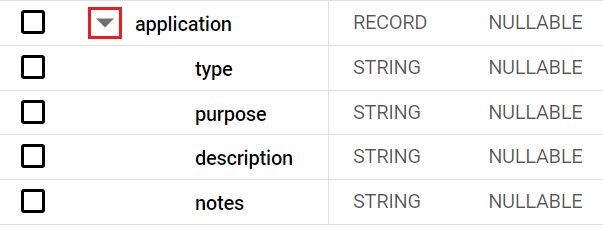
あなたは、借り手が融資を申し込んだときに提示した目的を含む簡単なレポートを作成するように依頼されました。ただし、このデータは融資の申請プロセスの一部として取得され、purpose というネストされた列に保存されるため、見つけるのが難しい場合があります。
このタスクでは、アプリケーション レコードにネストされている purpose 列を見つけ、クエリを実行して、借り手が融資を受ける理由を調べます。
[エクスプローラ] ペインで、loan テーブルを選択します。
[スキーマ] タブを選択し、[application] 列を見つけます。
[スキーマ] タブで、[application] の横にあるプルダウン矢印をクリックして、レコードを展開します。
次のクエリは、loan テーブルから各融資の目的を返しますか?
このクエリは、loan テーブルの各融資の目的を返します。トレバーはこれを使用して、人々が TheLook Fintech から融資を受ける最も一般的な理由を調べることができます。
レコード(または構造体)内の列は、ドット表記を使用してレコード名と列名を指定することで参照します。たとえば、application レコードの purpose 列を参照するには、application.purpose 表記を使用します。
[進行状況を確認] をクリックして、このタスクが正しく完了したことを確認します。
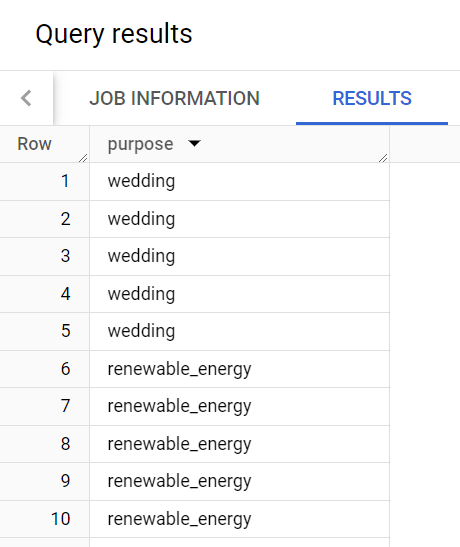
トレバーのために融資の目的のリストを作成したところ、借り手が融資を受けた理由が複数回表示されていました。
たとえば、「wedding」という理由が複数回表示されています。
クエリの結果は次のとおりです。
重複データは、クラウドデータ アナリストがよく直面する問題です。データセットから重複を削除するプロセスは、重複除去と呼ばれます。
fintech.loan テーブルの purpose 列の個別の値を含む、purpose という名前の列を 1 つ持った fintech.loan_purposes という名前のテーブルを作成するクエリを記述します。CREATE TABLE AS SELECT(CTAS)ステートメントを使用できます。[進行状況を確認] をクリックして、このタスクが正しく完了したことを確認します。
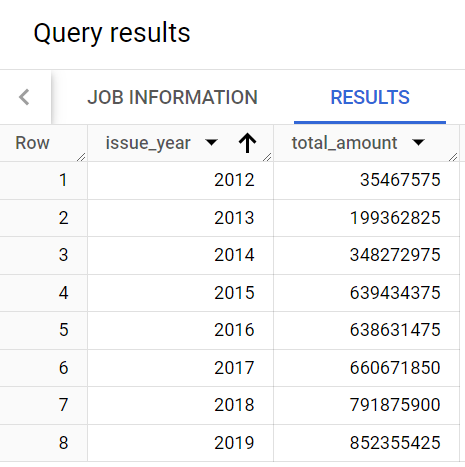
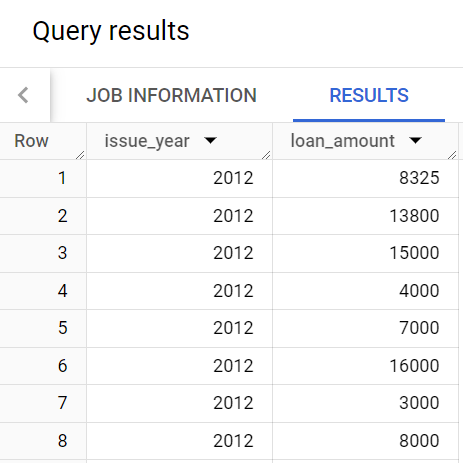
トレバーは、年次の融資総額を示すレポートも必要としています。このタスクでは、そのデータを生成するクエリを作成し、結果を含むテーブルを作成します。
トレバーは、これと似た構造で、issue_year 列と total_amount 列の両方を含むレポートを希望しています。
次に、データを確認します。
クエリによって次のような結果が返されるはずです。
クエリに、キーワード GROUP BY と関数 sum() が使用されていることに注目してください。
fintech データセットに、issue_year 別にグループ化された loan_id の数をカウントする loan_count_by_year というテーブルを作成するクエリを記述します。
[進行状況を確認] をクリックして、このタスクが正しく完了したことを確認します。
あなたは TheLook Fintech のクラウドデータ アナリストとして、トレバーと財務部門が会社のキャッシュフローをよりよく理解し、情報に基づいたビジネス上の意思決定を行うために必要なデータを提供しました。
まず、融資データを調べて、トレバーがリクエストした情報(fintech データセットの融資総額など)を見つけました。
次に、新しい州による分類を含むファイルをインポートしました。トレバーは、この分類を使用して、融資の地域による分類方法を変更したいと考えていました。
その後、クエリの結果を含む新しいテーブルを作成しました。トレバーは、このテーブルを使用して、融資 ID、融資額、地域名を表示するレポートを作成する予定です。
重複除去により、重複するレコードを削除しました。
最後に、日次および年次の融資総額を示すレポートを作成しました。このレポートは、トレバーが会社のキャッシュフローをより深く理解するために必要としていたものです。
これで、分析用のデータを収集、処理、保存する方法を理解するための道を一歩前進しました。
すべてのタスクが問題なく完了したことを確認してから、ラボを終了してください。準備ができたら、[ラボを終了] をクリックし、[送信] をクリックします。
ラボを終了すると、ラボ環境へのアクセス権が削除され、完了した作業にもう一度アクセスすることはできなくなります。
Copyright 2026 Google LLC All rights reserved. Google および Google のロゴは、Google LLC の商標です。その他すべての社名および製品名は、それぞれ該当する企業の商標である可能性があります。



このコンテンツは現在ご利用いただけません
利用可能になりましたら、メールでお知らせいたします

ありがとうございます。
利用可能になりましたら、メールでご連絡いたします

1 回に 1 つのラボ
既存のラボをすべて終了して、このラボを開始することを確認してください
ラボを開始するには、この簡単な手順を完了してください。