 IMPORTANT
IMPORTANT
 Prenez des captures d'écran de chaque tâche de votre travail pour les ajouter à votre portefeuille.
Prenez des captures d'écran de chaque tâche de votre travail pour les ajouter à votre portefeuille.
 Cet atelier pratique ne peut être réalisé que sur un ordinateur de bureau ou un ordinateur portable.
Cet atelier pratique ne peut être réalisé que sur un ordinateur de bureau ou un ordinateur portable.
 Vous ne pouvez tenter l'atelier que cinq fois.
Vous ne pouvez tenter l'atelier que cinq fois.
 Pour rappel, il est normal de ne pas répondre correctement à toutes les questions du premier coup, et même de devoir refaire un exercice. Cela fait partie du processus d'apprentissage.
Pour rappel, il est normal de ne pas répondre correctement à toutes les questions du premier coup, et même de devoir refaire un exercice. Cela fait partie du processus d'apprentissage.
 Une fois l'atelier démarré, le minuteur ne peut pas être mis en pause. Au bout d'une heure et demie, l'atelier se terminera et vous devrez le recommencer.
Une fois l'atelier démarré, le minuteur ne peut pas être mis en pause. Au bout d'une heure et demie, l'atelier se terminera et vous devrez le recommencer.
 Pour en savoir plus, consultez le document Conseils techniques pour les ateliers.
Pour en savoir plus, consultez le document Conseils techniques pour les ateliers.
Présentation de l'activité
Cet atelier fait partie d'un projet de synthèse. Vous allez mettre en pratique vos connaissances sur l'analyse des données cloud et les trois premières étapes du parcours des données : la collecte, le traitement et le stockage.
Vous allez suivre un scénario et effectuer un ensemble de tâches à l'aide de BigQuery. Vous allez faire appel à vos compétences pour utiliser et transformer des données dans l'environnement BigQuery, répondre à des questions sur les données et relever des défis qui permettront de tester vos compétences en transformation de données.
En terminant cet atelier, vous démontrerez votre capacité à utiliser une plate-forme de données cloud comme BigQuery pour stocker et analyser des données. Vous acquerrez également une expérience pratique de l'application de SQL pour explorer, filtrer, dédupliquer et agréger des données afin de répondre à un besoin d'entreprise spécifique.
Scénario
TheLook Fintech est une nouvelle entreprise de technologie financière qui propose des prêts aux propriétaires de boutiques en ligne indépendants ayant besoin de fonds pour acheter des stocks. Sa mission est de transformer la façon dont ces personnes obtiennent des prêts pour développer leur activité. Start-up en pleine croissance, TheLook Fintech a identifié son marché cible et cherche maintenant à se développer rapidement.
Vous avez été embauché en tant qu'analyste de données cloud. Votre première mission consiste à développer et implémenter un plan visant à aider le service trésorerie à exploiter efficacement les données pour suivre ses performances et sa croissance.
Lors d'une réunion avec Trevor, le responsable du service trésorerie, trois questions métier ont été identifiées.
Les voici :
- Comment mieux surveiller notre trésorerie pour nous assurer que les prêts que nous finançons chaque mois ne dépassent pas les revenus que nous percevons ?
- Comment identifier les principales raisons pour lesquelles les clients contractent un prêt auprès de notre entreprise ?
- Comment suivre les régions dans lesquelles les clients contractent des prêts ?
Trevor a également fourni des informations importantes sur les métriques clés nécessaires pour répondre à ces questions métier.
Le flux de trésorerie correspond aux sommes qu'une entreprise reçoit et dépense au fil du temps. TheLook Fintech doit s'assurer que le montant des fonds entrants, provenant des remboursements de prêts et d'autres sources, est supérieur à celui des fonds sortants destinés à financer les prêts et à payer d'autres dépenses.
L'objet du prêt est une autre métrique importante à suivre. Trevor a expliqué qu'il existe une forte corrélation entre les raisons pour lesquelles les emprunteurs contractent des prêts et la probabilité qu'ils les remboursent. Pour s'assurer que l'activité de prêt ne devienne pas risquée, il est important de surveiller l'objectif principal des emprunteurs.
La région de l'emprunteur est également un élément clé. Le service trésorerie cherche à comprendre comment les prêts sont répartis géographiquement. En effet, une forte concentration de prêts dans une même région peut augmenter le risque de défauts collectifs. Une répartition équilibrée des prêts dans les différentes régions peut contribuer à réduire ce risque, car cela garantit que les organismes de prêt ne dépendent pas trop d'une seule région pour le remboursement de leurs prêts.
Votre analyse se concentrera sur ces trois métriques clés.
Dans cet atelier, vous allez utiliser BigQuery pour collecter, traiter et stocker les données afin de répondre à ces questions métier et de préparer une série de rapports pour Trevor.
Pour ce faire, commencez par configurer l'environnement de travail BigQuery. Ensuite, vous explorerez les données des prêts pour trouver les informations demandées par Trevor. Après cela, vous importerez un fichier avec une nouvelle classification des États et stockerez les données sous forme de table standard. Par la suite, vous joindrez deux tables pour préparer un rapport avec les données combinées. Ensuite, vous dédupliquerez les données sur l'objet. Enfin, vous produirez un rapport indiquant le montant total des prêts accordés par jour et par an.
Préparation
Avant de cliquer sur "Démarrer l'atelier"
Lisez ces instructions. Les ateliers sont minutés, et vous ne pouvez pas les mettre en pause. Le minuteur, qui démarre lorsque vous cliquez sur Démarrer l'atelier, indique combien de temps les ressources Google Cloud resteront accessibles.
Cet atelier pratique vous permet de suivre vous-même les activités dans un véritable environnement cloud, et non dans un environnement de simulation ou de démonstration. Nous vous fournissons des identifiants temporaires pour vous connecter à Google Cloud le temps de l'atelier.
Pour réaliser cet atelier :
- Vous devez avoir accès à un navigateur Internet standard (nous vous recommandons d'utiliser Chrome).
Remarque : Ouvrez une fenêtre de navigateur en mode incognito/navigation privée pour effectuer cet atelier. Vous éviterez ainsi les conflits entre votre compte personnel et le compte temporaire de participant, qui pourraient entraîner des frais supplémentaires facturés sur votre compte personnel.
- Vous disposez d'un temps limité. N'oubliez pas qu'une fois l'atelier commencé, vous ne pouvez pas le mettre en pause.
Remarque : Si vous possédez déjà votre propre compte ou projet Google Cloud, veillez à ne pas l'utiliser pour réaliser cet atelier afin d'éviter que des frais supplémentaires ne vous soient facturés.
Démarrer l'atelier et se connecter à la console Google Cloud
-
Cliquez sur le bouton Démarrer l'atelier. Sur la gauche, vous trouverez le panneau Détails concernant l'atelier, qui contient les éléments suivants :
- Le temps restant
- Le bouton Ouvrir la console Google Cloud
- Les identifiants temporaires que vous devez utiliser pour cet atelier
- D'éventuelles informations complémentaires vous permettant d'effectuer l'atelier
Remarque : Si l'atelier est payant, un pop-up s'affiche pour vous permettre de sélectionner un mode de paiement.
-
Cliquez sur Ouvrir la console Google Cloud (ou effectuez un clic droit et sélectionnez Ouvrir le lien dans la fenêtre de navigation privée) si vous utilisez le navigateur Chrome. La page Se connecter s'ouvre dans un nouvel onglet du navigateur.
Conseil : Vous pouvez réorganiser les onglets dans des fenêtres distinctes, placées côte à côte, pour passer facilement de l'un à l'autre.
Remarque : Si la boîte de dialogue Sélectionner un compte s'affiche, cliquez sur Utiliser un autre compte.
-
Si nécessaire, copiez le nom d'utilisateur Google Cloud ci-dessous et collez-le dans la boîte de dialogue Se connecter. Cliquez sur Suivant.
{{{user_0.username | "Google Cloud username"}}}
Vous trouverez également le nom d'utilisateur Google Cloud dans le panneau Détails concernant l'atelier.
- Copiez le mot de passe Google Cloud ci-dessous et collez-le dans la boîte de dialogue Bienvenue. Cliquez sur Suivant.
{{{user_0.password | "Google Cloud password"}}}
Vous trouverez également le mot de passe Google Cloud dans le panneau Détails concernant l'atelier.
Important : Vous devez utiliser les identifiants qui vous ont été fournis pour l'atelier. N'utilisez pas ceux de votre compte Google Cloud.
Remarque : Si vous utilisez votre propre compte Google Cloud pour cet atelier, des frais supplémentaires peuvent vous être facturés.
- Parcourez les pages suivantes :
- Acceptez les conditions d'utilisation.
- N'ajoutez pas d'options de récupération ni d'authentification à deux facteurs (ce compte est temporaire).
- Ne vous inscrivez pas à des essais sans frais.
Après quelques instants, la console s'ouvre dans cet onglet.
Remarque : Vous pouvez afficher le menu qui contient la liste des produits et services Google Cloud en cliquant sur le menu de navigation en haut à gauche.

Tâche 1 : Lancer BigQuery
En tant qu'analyste de données cloud, l'une des premières choses que vous devrez faire lorsque vous travaillerez sur un projet sera d'ouvrir votre environnement de travail et de localiser les données que vous utiliserez dans votre analyse.
Dans cette tâche, vous allez ouvrir l'environnement BigQuery, sélectionner un projet BigQuery existant et localiser l'ensemble de données "Fintech".
- Accédez au menu de navigation > BigQuery. Cliquez sur OK.
- Localisez l'ensemble de données Fintech dans la section "Explorateur". Il s'agit de l'ensemble de données que vous utiliserez pour la prochaine tâche.
Tâche 2 : Explorer les données "Fintech"
L'ensemble de données Fintech contient des informations sur les prêts qui peuvent être utilisées pour répondre aux questions de Trevor sur son activité. L'une des informations clés est le montant total des prêts.
Dans cette tâche, vous allez explorer les tables de l'ensemble de données "Fintech" pour trouver la table et la colonne qui contiennent le montant total des prêts. Ces informations sont importantes pour aider Trevor à suivre les sorties d'argent de l'entreprise.
- Ouvrez chaque table de l'ensemble de données Fintech.
- Utilisez l'onglet Détails pour en savoir plus sur chaque table.
- Utilisez l'onglet Schéma pour identifier les colonnes incluses dans chaque table et le type de données fournies dans chaque colonne.
- Utilisez l'onglet Aperçu pour afficher un aperçu des données. Recherchez la colonne contenant le montant des prêts pour vérifier qu'elle contient les informations dont vous avez besoin.
Trevor explique que lorsque TheLook Fintech prête de l'argent à ses clients, la date à laquelle les fonds sont disponibles est appelée "issued date" (date d'émission). Il s'agit d'une autre information clé dont vous aurez besoin pour aider son équipe à suivre le montant total de trésorerie qui sort chaque jour ou chaque mois.
Localisez la table de l'ensemble de données "Fintech" qui contient la date d'émission de chaque prêt, puis répondez aux questions ci-dessous.
Tâche 3 : Importer un fichier CSV et créer une table standard
La plupart des données nécessaires à l'analyse se trouvent dans l'ensemble de données "Fintech", mais certaines doivent être collectées à partir d'une autre source. Trevor a fourni un fichier CSV qui mappe les États américains à des régions et sous-régions. Ces informations clés permettront à Trevor de suivre les prêts par État ou région où les emprunteurs les ont souscrits.
Le fichier CSV se trouve dans Cloud Storage à l'emplacement suivant :
gs://sureskills-lab-dev/future-workforce/da-capstone/temp_35_us/state_region_mapping/
Voici un exemple des données figurant dans le fichier CSV :
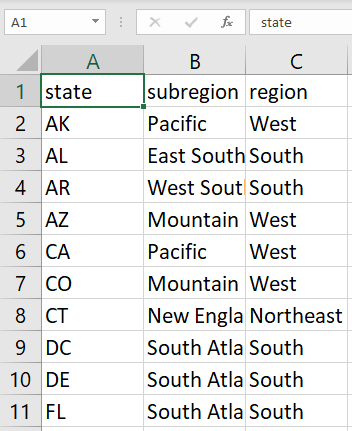
Dans cette tâche, vous allez importer le fichier CSV dans BigQuery et le stocker sous forme de table standard.
- Examinez le code suivant. Vous allez l'utiliser pour importer le fichier CSV. Répondez ensuite aux questions ci-dessous.
LOAD DATA OVERWRITE fintech.state_region
(
state string,
subregion string,
region string
)
FROM FILES (
format = 'CSV',
uris = ['gs://sureskills-lab-dev/future-workforce/da-capstone/temp_35_us/state_region_mapping/state_region_*.csv']);
-
Copiez et collez la commande ci-dessus dans l'onglet Sans titre pour créer la table standard avec les données du fichier CSV.
-
Cliquez sur Exécuter.
Ensuite, vérifiez la table que vous avez créée et comparez-la au fichier CSV d'origine :
-
Dans le volet Explorateur, sélectionnez la table state_region. Si elle ne s'affiche pas, vous devrez peut-être actualiser l'ensemble de données.
-
Cliquez sur l'onglet Aperçu et examinez les données que vous venez d'importer dans BigQuery.
Cliquez sur Vérifier ma progression pour vérifier que vous avez correctement accompli cette tâche.
Importer un fichier CSV et créer une table standard
Tâche 4 : Joindre les données de deux tables
Maintenant que vous avez exploré et collecté les données dont vous avez besoin, vous êtes prêt à les traiter pour les rendre utilisables pour l'analyse.
Trevor souhaite obtenir un unique rapport incluant l'ID du prêt (loan_id), son montant (loan_amount) et le nom de la région (region), mais ces informations se trouvent actuellement dans deux tables différentes.
Dans cette tâche, vous allez identifier les tables contenant les colonnes dont vous avez besoin et utiliser SQL pour joindre les deux tables afin de créer le rapport.
- Examinez les tables de l'ensemble de données "Fintech", puis répondez aux questions ci-dessous.
- Dans l'éditeur de requête, exécutez les requêtes A et B, puis consultez les résultats. Répondez ensuite à la question ci-dessous :
Requête A
SELECT
lo.loan_id,
lo.loan_amount,
sr.region
FROM fintech.loan lo
INNER JOIN fintech.state_region sr
ON lo.region = sr.region;
Requête B
SELECT
lo.loan_id,
lo.loan_amount,
sr.region
FROM fintech.loan lo
INNER JOIN fintech.state_region sr
ON lo.state = sr.state;
Tâche 5 : Créer une table basée sur les résultats d'une requête avec une instruction CTAS
Trevor souhaite filtrer et analyser plus en détail les données du rapport à l'aide de Google Sheets.
Pour ce faire, vous devrez d'abord créer une table pour stocker les données.
Une instruction CTAS, ou CREATE TABLE AS SELECT, est une instruction SQL qui crée une table en fonction des résultats d'une instruction SELECT. Il s'agit d'un outil puissant qui permet de créer des tables rapidement et facilement. Les tables créées avec des instructions CTAS peuvent également être exportées facilement dans BigQuery pour être partagées avec d'autres utilisateurs.
Dans cette tâche, vous allez créer une table à l'aide de CREATE TABLE AS SELECT, puis l'associer à Google Sheets.
- Copiez et collez la commande suivante dans l'éditeur de requête :
CREATE OR REPLACE TABLE fintech.loan_with_region AS
SELECT
lo.loan_id,
lo.loan_amount,
sr.region
FROM fintech.loan lo
INNER JOIN fintech.state_region sr
ON lo.state = sr.state;
Remarque : Cette requête est une modification de celle que vous avez utilisée dans la tâche précédente pour créer le rapport. Toutefois, dans cette nouvelle version, CREATE OR REPLACE TABLE est utilisé pour créer une table ou remplacer la table existante chaque fois que la requête est exécutée.
-
Cliquez sur Exécuter.
-
Recherchez la nouvelle table. Vous devrez peut-être actualiser la page.
Cliquez sur Vérifier ma progression pour vérifier que vous avez correctement accompli cette tâche.
Créer une table basée sur les résultats d'une requête avec une instruction CTAS
-
Dans le volet Explorateur, sélectionnez la table loan_with_region (prêts avec régions) que vous venez de créer. (Cliquez sur Actualiser pour actualiser l'ensemble de données si la table ne s'affiche pas.)
-
Pour ouvrir Sheets, effectuez un clic droit sur le lien Ouvrir Google Sheets, puis sélectionnez l'option permettant d'ouvrir le lien dans une nouvelle fenêtre de navigation privée.
-
Pour vous connecter à Google Workspace, utilisez les identifiants (nom d'utilisateur et mot de passe) fournis sur la page de l'atelier, sur laquelle vous êtes actuellement.
-
Dans la barre d'outils, cliquez sur Ouvrir dans, puis sélectionnez Feuilles connectées. Cliquez sur Commencer.
-
Une feuille de calcul Google Sheets s'ouvre. Elle contient les mêmes données que la table loan_with_region.
-
Vérifiez les données de la feuille de calcul Google Sheets.
Vous pouvez désormais partager la feuille de calcul Google Sheets avec Trevor, ce qui lui permettra de travailler avec les données au format feuille de calcul.
Tâche 6 : Utiliser des données imbriquées
Trevor souhaite identifier les principales raisons pour lesquelles ses clients contractent des prêts auprès de TheLook Fintech, car il a constaté que c'est un bon indicateur de remboursement.
Il vous demande de créer un rapport simple qui inclut l'objet de chaque prêt demandé. Toutefois, il peut être difficile de trouver ces données, car elles sont collectées lors du processus de demande de prêt et stockées dans une colonne imbriquée appelée "purpose" (objet).
Dans cette tâche, vous allez rechercher la colonne "purpose" (objet), qui est imbriquée dans l'enregistrement "application" (demande), et exécuter une requête pour trouver les raisons pour lesquelles les emprunteurs contractent des prêts.
-
Dans le volet Explorateur, sélectionnez la table loan (prêts).
-
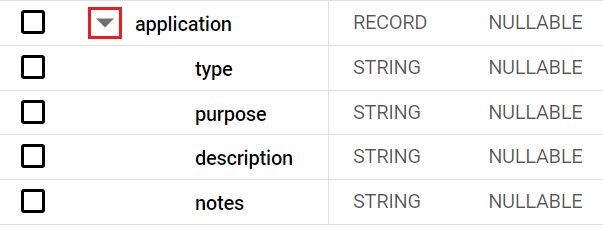
Sélectionnez l'onglet Schéma et recherchez la colonne application (demandes).
-
Dans l'onglet "Schéma", cliquez sur la flèche du menu déroulant à côté de application pour développer l'enregistrement.
- Cliquez sur l'onglet Aperçu, puis examinez l'échantillon de données de la table loan.
Pensez-vous que la requête ci-dessous renverra l'objet de chaque prêt à partir de la table "loan" ?
- Copiez et collez la commande suivante dans l'éditeur de requête :
SELECT loan_id,purpose
FROM fintech.loan;
- Cliquez sur Exécuter.
- Copiez et collez la commande suivante dans l'éditeur de requête :
SELECT loan_id,application.purpose
FROM fintech.loan;
- Cliquez sur Exécuter.
Cette requête renvoie l'objet de chaque prêt dans la table loan. Trevor peut l'utiliser pour examiner les raisons les plus courantes pour lesquelles ses clients contractent des prêts auprès de son entreprise TheLook Fintech.
Les colonnes dans les enregistrements (ou structs) sont référencées par le nom de l'enregistrement suivi du nom de la colonne, en utilisant un point de séparation. Par exemple, pour faire référence à la colonne purpose dans l'enregistrement application, vous devez utiliser la notation application.purpose.
Cliquez sur Vérifier ma progression pour vérifier que vous avez correctement accompli cette tâche.
Utiliser des données imbriquées
Tâche 7 : Dédupliquer des données
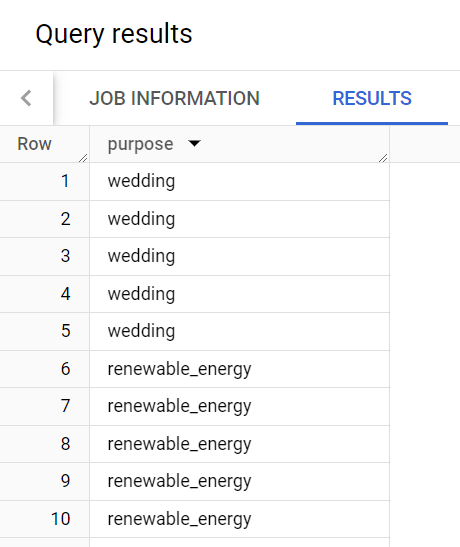
Vous avez créé la liste des objets de prêt pour Trevor, mais il semble que certaines raisons pour lesquelles les emprunteurs ont contracté un prêt apparaissent plusieurs fois.
C'est, par exemple, le cas de la raison "wedding" (mariage).
Voici les résultats de la requête :
Les analystes de données cloud sont souvent confrontés au problème des données en double. Le processus de suppression des doublons d'un ensemble de données est appelé déduplication.
Défi : Créer une table à une seule colonne avec des valeurs distinctes
- Écrivez une requête pour créer une table intitulée
fintech.loan_purposes (fintech.objets_prêts) comportant une seule colonne nommée purpose (objet) avec des valeurs distinctes pour la colonne purpose de la table fintech.loan.
Conseil : Vous pouvez utiliser une instruction CREATE TABLE AS SELECT (CTAS).
Cliquez sur Vérifier ma progression pour vérifier que vous avez correctement accompli cette tâche.
Dédupliquer des données
Tâche 8 : Répondre à des questions métier à l'aide d'un rapport
Trevor a également besoin d'un rapport indiquant le montant total des prêts accordés par an. Dans cette tâche, vous allez écrire une requête qui fournit ces données, puis créer une table avec les résultats.
Trevor explique qu'il souhaite obtenir un rapport dont la structure est similaire et qui inclut deux colonnes : issue_year (année d'émission) et total_amount (montant total).
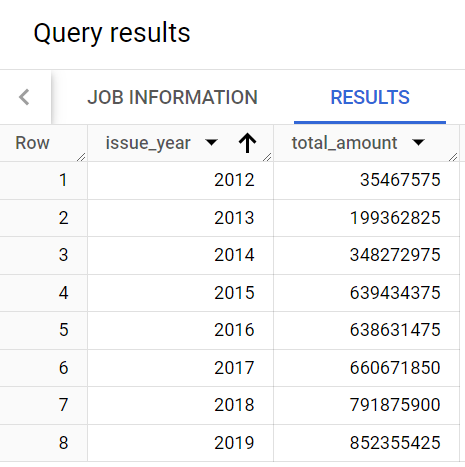
Cliquez sur Suivant, puis vérifiez les données.
- Copiez et collez la commande suivante dans l'éditeur de requête :
SELECT issue_year, loan_amount
FROM fintech.loan
ORDER BY issue_year, issue_date;
- Cliquez sur Exécuter.
La requête devrait renvoyer un résultat semblable à ce qui suit :
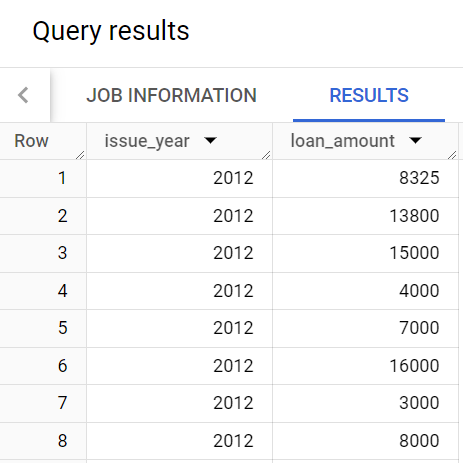
Remarque : Il y a plusieurs lignes par année. Par exemple, les premières lignes concernent l'année 2012. Trevor souhaite une ligne par année, comme indiqué dans l'exemple de rapport.
- Copiez et collez la commande suivante dans l'éditeur de requête :
SELECT issue_year, sum(loan_amount) AS total_amount
FROM fintech.loan
GROUP BY issue_year;
- Cliquez sur Exécuter.
Notez que le mot clé GROUP BY et la fonction sum() ont été utilisés dans la requête.
Défi : Créer une table qui comptabilise les prêts regroupés par année
Écrivez une requête pour créer une table nommée loan_count_by_year (nombre de prêts par année) dans l'ensemble de données "Fintech" qui comptabilise les ID de prêts (loan_id) regroupés par année d'émission (issue_year).
Conseil : Vous êtes bloqué ? Les outils d'IA générative comme Gemini peuvent vous aider à utiliser la syntaxe SQL et à identifier les erreurs potentielles dans votre code, ainsi qu'à mieux comprendre votre code.
Cliquez sur Vérifier ma progression pour vérifier que vous avez correctement accompli cette tâche.
Répondre à des questions métier avec un rapport
Conclusion
En tant qu'analyste de données cloud chez TheLook Fintech, vous avez réussi à fournir à Trevor et au service trésorerie les données dont ils ont besoin pour mieux comprendre les flux de trésorerie de l'entreprise et prendre des décisions éclairées.
Vous avez commencé par explorer les données sur les prêts pour trouver les informations demandées par Trevor, comme le montant total des prêts dans l'ensemble de données "Fintech".
Vous avez ensuite importé un fichier avec une nouvelle classification des États, que Trevor souhaitait utiliser pour modifier la façon dont les prêts sont classés par région.
Puis, vous avez créé une table avec les résultats d'une requête. Trevor pourra l'utiliser pour créer un rapport indiquant l'ID du prêt, son montant et le nom de la région.
Vous avez dédupliqué les données pour supprimer les enregistrements en double.
Enfin, vous avez généré un rapport indiquant le montant total des prêts accordés par jour et par an, dont Trevor avait besoin pour mieux comprendre les flux de trésorerie de l'entreprise.
Vous êtes en bonne voie pour comprendre comment collecter, traiter et stocker des données à des fins d'analyse.
Terminer l'atelier
Avant de terminer l'atelier, assurez-vous d'avoir bien accompli toutes les tâches. Cliquez alors sur Terminer l'atelier, puis sur Envoyer.
Une fois l'atelier terminé, vous n'aurez plus accès à l'environnement de l'atelier ni au travail que vous avez effectué.
Copyright 2026 Google LLC Tous droits réservés. Google et le logo Google sont des marques de Google LLC. Tous les autres noms de société et de produit peuvent être des marques des sociétés auxquelles ils sont associés.





