
准备工作
- 实验会创建一个 Google Cloud 项目和一些资源,供您使用限定的一段时间
- 实验有时间限制,并且没有暂停功能。如果您中途结束实验,则必须重新开始。
- 在屏幕左上角,点击开始实验即可开始
Combine the data and export Parquet files
/ 35
Query data in BigQuery
/ 30
Query data in Dataproc and Spark
/ 35

 重要提醒:
重要提醒: 請務必使用桌機/筆電完成這個實作實驗室。
請務必使用桌機/筆電完成這個實作實驗室。 每個實驗室都只有 5 次嘗試機會。
每個實驗室都只有 5 次嘗試機會。 提醒:第一次嘗試時,不一定能全部答對,甚至可能需要重做,這是正常的過程。
提醒:第一次嘗試時,不一定能全部答對,甚至可能需要重做,這是正常的過程。 實驗室活動開始後,計時器無法暫停。實驗室會在 1 小時 30 分鐘後結束,如果您沒做完,就必須重新開始。
實驗室活動開始後,計時器無法暫停。實驗室會在 1 小時 30 分鐘後結束,如果您沒做完,就必須重新開始。 您可查看實驗室技術提示瞭解詳情。
您可查看實驗室技術提示瞭解詳情。
雲端資料分析領域發展迅速,而分析師必須持續瞭解新平台和技術,才能有效完成工作。為此,比較 BigQuery 和 Dataproc 等不同平台,是不錯的方法。
BigQuery 和 Dataproc 都是雲端資料處理平台,但兩者用於分析資料的資料處理引擎、SQL 方言和開發環境有所不同。
BigQuery 這項簡單易用的資料倉儲服務,適用於大型資料集的執行互動式查詢,還可處理各種資料分析工作。
Dataproc 則是代管的 Hadoop 和 Spark 服務,適用於大型資料集的批次處理工作。儘管比 BigQuery 更具彈性,但設定和使用方式可能較為複雜。
BigQuery 和 Dataproc 都能與其他 Google Cloud 服務整合,因此可輕鬆在服務之間移動資料,並探索資料湖泊來源。
在本實驗室中,您會將兩個 CSV 檔的資料併入一個 Parquet 檔案,接著使用合併後的資料,比較由 BigQuery 執行的分析,以及採用 Dataproc 和 Spark 的分析。
TheLook eCommerce 正在試辦一項計畫,開放消費者在實體商店退回線上訂購的商品。這項計畫旨在讓退化流程更親民,希望能藉此提升顧客滿意度和銷售量。
為追蹤計畫成效,商品部主管 Meredith 要求您準備一份報表,統整各間商店的地址和退貨資料。這份報表可用於追蹤各據點和區域的退貨情況,相關資訊也有助於判斷此前測計畫在不同市場的成效。
首先,您瀏覽目了前從各據點收集到的資料,但很快就發現資料量非常龐大!由於需要收集、處理及分析大量資料,您向資料架構師 Artem 求助。
Artem 建議使用 Dataproc,將您處理的兩個 CSV 檔案合併為單一 Parquet 檔案。Parquet 採用欄位式資料格式,最適合用於快速的數據分析查詢。Artem 補充說道,由於 TheLook eCommerce 剛收購一家採用 Spark 執行分析的公司,這是進一步瞭解 Dataproc 和 Spark 的絕佳機會。
他建議使用合併的資料來生成 Meredith 所需的報表,以便比較兩種執行數據分析的方式:一種是以您熟悉的 BigQuery 為主,另一種則以 Dataproc 和 Spark 為中心。這將有助您進一步瞭解 Dataproc 和 Spark,並比較兩種平台,看看哪一個更符合前測計畫需求。
您感謝 Artem 的建議。不過,在比較 BigQuery 與 Dataproc 和 Spark 之前,您需要先行規劃,瞭解如何收集及處理用於比較的資料。
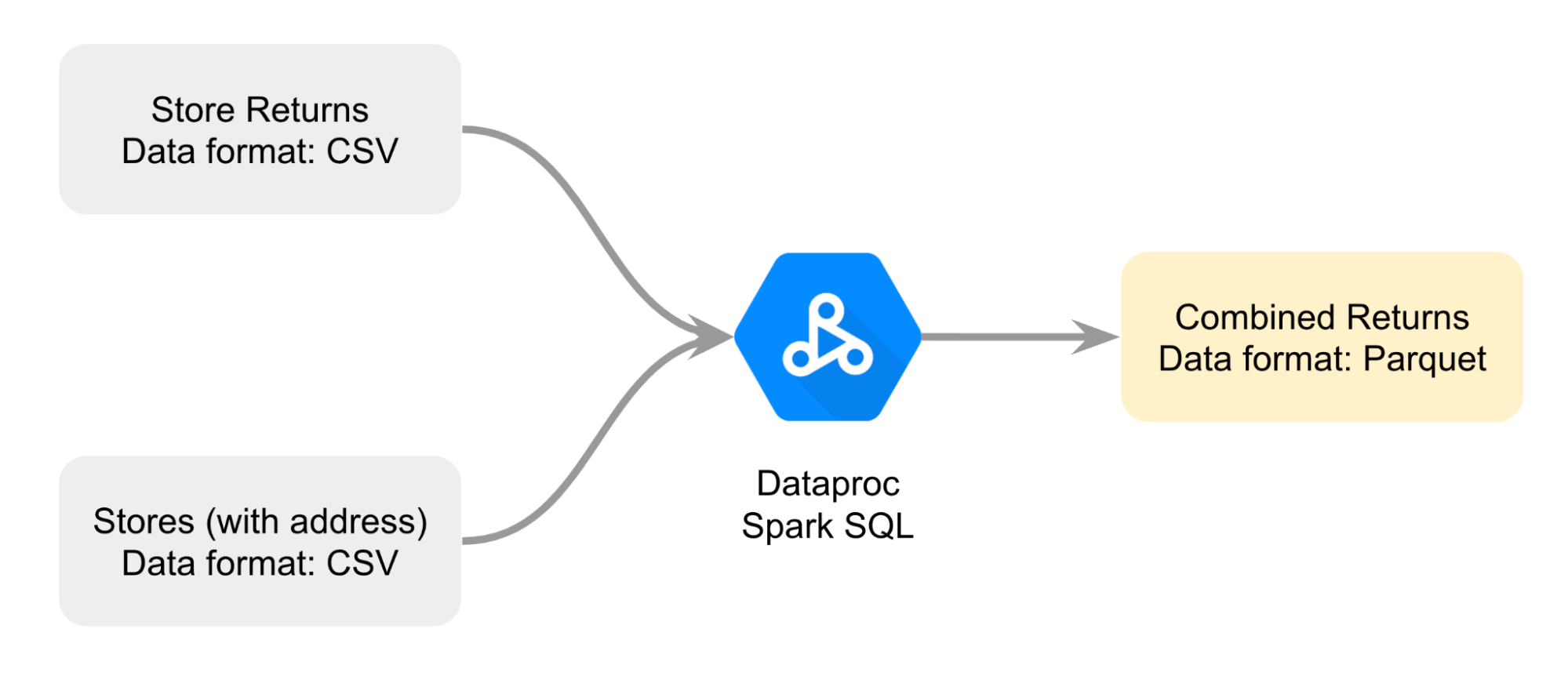
為了更妥善規劃合併作業,您製作了一張圖表;方法是使用 Dataproc Spark SQL 彙整兩個不同的 CSV 檔,產生 Parquet 格式的合併退貨檔案。
這份資料將做為比較基準。
這項工作的步驟如下:首先,您在 Dataproc 叢集上開啟 Jupyter 筆記本。接著,按照筆記本中的操作說明,彙整兩個 CSV 檔並建立 Parquet 檔案。然後,將儲存在 Cloud Storage bucket 的 Parquet 檔案資料載入 BigQuery 標準資料表,以利分析資料。最後,您在 Dataproc 叢集的 Jupyter 筆記本中,參照同一份 Parquet,比較使用 BigQuery,以及使用 Dataproc 和 Spark 的資料分析結果。
請詳閱下列操作說明。實驗室活動會計時,中途無法暫停。點選「Start Lab」後就會開始計時,顯示可使用 Google Cloud 資源的時間。
您會在實際雲端環境完成實驗室活動,而非模擬或示範環境。因此,我們會提供新的臨時憑證,讓您在實驗室活動期間登入及存取 Google Cloud。
如要順利完成這個實驗室活動,請先確認:
點選「Start Lab」按鈕。左側的「Lab Details」面板會顯示下列項目:
點選「Open Google Cloud console」;如果使用 Chrome 瀏覽器,也可以按一下滑鼠右鍵,選取「在無痕視窗中開啟連結」。「登入」頁面會在新的瀏覽器分頁開啟。
提示:為方便切換,可以將分頁安排在不同的視窗並排顯示。
如有需要,請複製下方的 Google Cloud 使用者名稱,然後貼到「登入」對話方塊。點選「下一步」。
您也可以在「Lab Details」面板找到 Google Cloud 使用者名稱。
您也可以在「Lab Details」面板找到 Google Cloud 密碼。
Cloud 控制台稍後會在這個分頁中開啟。

您可以使用 JupyterLab,在 Dataproc 叢集上建立、開啟及編輯 Jupyter 筆記本。這樣做能充分運用叢集資源 (例如利用其高效能和可擴充性),在更大的資料集上更快執行筆記本。您也可以使用 JupyterLab 與他人協作處理專案。
在這項工作中,您會在 Dataproc 內開啟現有的 Dataproc 叢集,然後前往 JupyterLab 找出 Jupyter 筆記本,以便完成本實驗室的其餘工作。
JupyterLab 環境會在新的瀏覽器分頁中開啟。
C2M4-1 Combine and Export.ipynb」檔案。為協助 Meredith 確認據點和市場情況,我們要幫 Meredith 取得每筆退貨的相關資訊,以及退貨據點的實際地址。不過,這些資訊位於兩個不同的 CSV 檔案中。
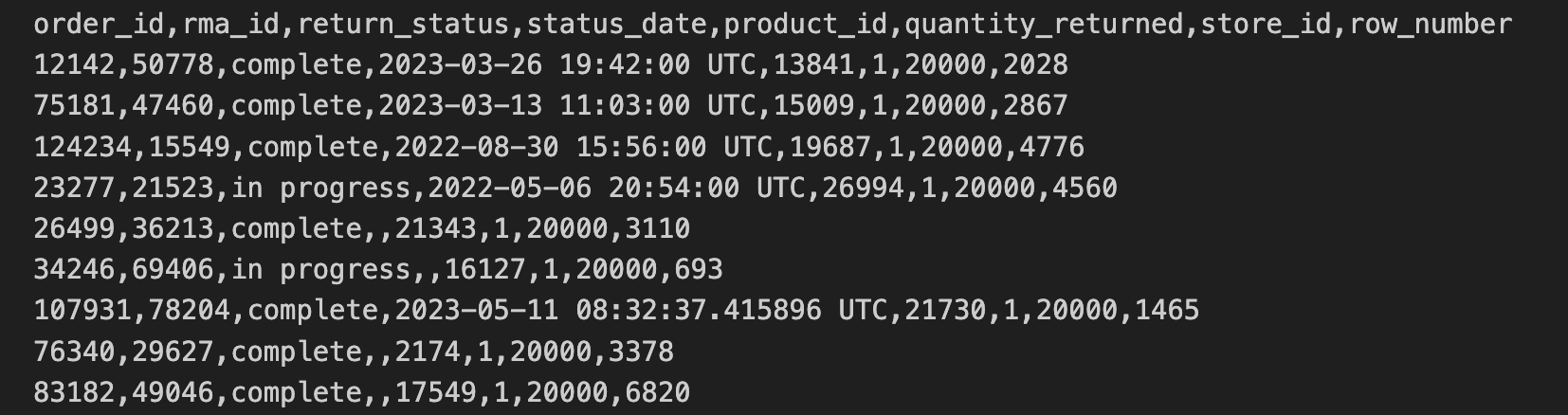
商店退貨資料已從門市匯出為 CSV 格式,並複製到 Cloud Storage bucket 中。這項資料包括 order_id、rma_id、return_status、status_date、product_ied、quantity_returned、store_id。
商店退貨 CSV 檔的前 10 行包含下列內容:
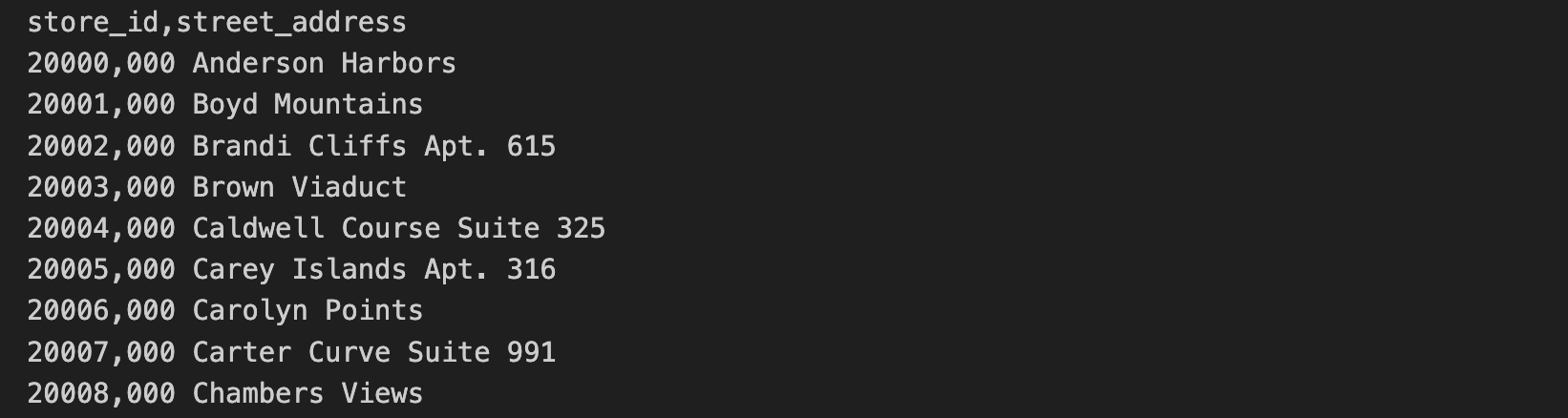
商店地址資料儲存在另一個 CSV 檔案中,其中包括 store_id 和 street_address。
商店地址 CSV 檔的前 10 行包含下列內容:
在這項工作中,您會執行「C2M4-1 Combine and Export.ipynb」檔案中的 SQL 查詢和 Python 指令,進而彙整兩個 CSV 檔案。合併後的檔案會儲存為 Parquet 格式。
在左邊側欄中,按兩下「C2M4-1 Combine and Export.ipynb」檔案,即可在 JupyterLab 環境中開啟。
在 JupyterLab 選單列中,依序點選「Kernel」>「Change Kernel」,選取「PySpark」,然後點選「Select」。
接著,按照筆記本中的操作說明,執行每個儲存格中的程式碼。
 ,逐一執行儲存格。或者,按下 Shift + Enter 鍵即可執行程式碼。儲存格若會用到先前儲存格的輸出內容,「必須」依序執行。如果不小心未依序執行儲存格,請按一下筆記本工具列中的「Refresh」按鈕 (
,逐一執行儲存格。或者,按下 Shift + Enter 鍵即可執行程式碼。儲存格若會用到先前儲存格的輸出內容,「必須」依序執行。如果不小心未依序執行儲存格,請按一下筆記本工具列中的「Refresh」按鈕 ( ),重新啟動核心。
),重新啟動核心。Dataproc 中的 Spark 工作階段可連線至 Dataproc 叢集,並執行 Spark 應用程式。這是啟動 Spark 應用程式及建立 DataFrame 的主要方式。DataFrame 是可供 Spark 處理及執行查詢的資料表。藉由 Spark,您也可以讀取並將資料寫入不同的儲存系統,例如 Google Cloud Storage 或 BigQuery。
在這個筆記本中,您建立了 Spark 工作階段,並透過 CSV 檔將商店退貨資料載入 DataFrame (Spark 所用的資料表)。然後,您利用第二個 CSV 檔載入商店地址,並彙整兩個 DataFrame,將整合後的單一資料表匯出為 Parquet 檔案。最後,您使用查詢修改其中一個資料欄的名稱。
提示:回答下方問題時,請勿關閉含有輸出內容的筆記本。
點選「檢查進度」,確認工作已正確完成。
現在,合併後的 Parquet 檔案已建立並儲存在 Cloud Storage bucket,您可以比較以下兩種執行分析的方式了:以 BigQuery 為主,還有以 Dataproc 和 Spark 為中心。
首先是 BigQuery,這項資料倉儲服務會使用 BigQuery 引擎執行查詢及分析資料。
在上一個工作中,您建立了 Parquet 檔案並儲存在 Cloud Storage bucket。如要在 BigQuery 中存取這項資料,您有兩種方式:使用外部資料表,或採用標準資料表。外部資料表會參照儲存在 BigQuery 外部的資料,例如 Google Cloud Storage 中的資料。標準資料表則會將資料副本直接儲存在 BigQuery 中。
Artem 告訴您,標準資料表可以快速查詢及處理資料,所以通常在處理大數據時更有效率。因此,您決定這項工作採用標準資料表最為合適。
在這項工作中,您會將 Parquet 檔案載入 BigQuery 的標準資料表,並使用 GoogleSQL (BigQuery 環境所用的 SQL 方言) 執行查詢。接著,您將回答問題,確保自己擁有足夠資訊,可在下一個工作比較 BigQuery 與 Dataproc 和 Spark。
返回 Google Cloud 控制台的瀏覽器分頁 (Dataproc 頁面應保持開啟),同時保留 JupyterLab 瀏覽器分頁,不要關閉。
前往 Google Cloud 控制台,依序點選「導覽選單」圖示 
在查詢編輯器中,點選「+ (SQL 查詢)」圖示,開啟新的「未命名的查詢」分頁。
將下列查詢複製到「未命名的查詢」分頁:
這項查詢會將 Parquet 檔案匯入 BigQuery。
URI (統一資源 ID) 是導向 Cloud Storage bucket 中檔案的路徑。如要將 URI 集合做為 LOAD DATA 指令的輸入內容,請將 URI 放在方括號 [] 中,代表值是 URI 陣列。
URI 一律以 gs:// 開頭,表示這是 Cloud Storage 中的資源。上述範例提供的 URI 結尾為 *.parquet,會篩選出副檔名為 .parquet 的檔案。* 符號是萬用字元,代表任何字串。
這項查詢會傳回路徑 gs://
這項查詢會傳回「thelook_gcda.product_returns_to_store」資料表中的列數。
根據預設,在 BigQuery Studio 中執行查詢時,系統會採用 GoogleSQL 方言。GoogleSQL 是標準 SQL 方言的超集,也就是說,GoogleSQL 包含所有標準 SQL 查詢,以及其他擴充功能,可用來在 BigQuery 中輕鬆處理大量資料和複雜的資料類型。
這項查詢會顯示每月收到的退貨數量和相關狀態。
點選「檢查進度」,確認工作已正確完成。
您已在 BigQuery 中完成分析,現在可以探索以 Dataproc 和 Spark 為主的分析了。
Spark 是 Dataproc 用於分析資料的主要資料處理引擎。Dataproc 會自動管理 Spark 叢集,並預先安裝 Spark,因此是資料分析一大利器。
Spark 也使用自己的 SQL 方言,也就是 Spark SQL,這點與 GoogleSQL 類似。Spark SQL屬於是分散式 SQL 方言,可查詢及分析分散在 Spark 叢集中多部機器的資料。
如要採用 Dataproc 和 Spark 執行 Spark SQL 查詢,請使用 Jupyter 筆記本。您可以在這個互動式環境中編寫程式碼,輕鬆顯示輸出內容。
在這項工作中,您會對 Cloud Storage bucket 參照的 Parquet 檔案執行 Spark SQL 查詢。接著,您將回答問題,比較兩種分析執行方式:一種以 BigQuery 為主,另一種以 Dataproc 和 Spark 為核心。
返回瀏覽器中的「JupyterLab」分頁。
按兩下「C2M4-2 Query Store Data with Spark SQL.ipynb」檔案,在 JupyterLab 環境中開啟。
在 JupyterLab 選單列中,依序點選「Kernel」>「Change Kernel」,選取「PySpark」,然後點選「Select」。
按照筆記本中的操作說明,執行每個儲存格中的程式碼。
按一下筆記本中的各個儲存格,然後點選「Run」或按下 Shift + Enter 鍵,即可執行程式碼。
在筆記本中瀏覽 Spark SQL 查詢的輸出內容。
在 JupyterLab 選單列中,依序點選「File」和「Save Notebook」。
如果未儲存筆記本,下方的進度檢查功能可能無法偵測到您已完成這些步驟。
在這個筆記本中,您首先建立了 Spark 工作階段。接下來,您使用 iPython 筆記本參照 Cloud Storage 中 Parquet 檔案的資料,並填入 DataFrame。接著,您建立檢視區塊,將 DataFrame 與 Spark SQL 搭配使用。然後,您執行了 Spark SQL 查詢,從 DataFrame 傳回前三列。最後,您執行了與前一步在 BigQuery 中相同的查詢。
點選「檢查進度」,確認工作已正確完成。
建議您在結束環境前停止叢集。
本實驗室探討了 BigQuery 以及 Dataproc 和 Spark 的資料分析功能,請參閱下表,瞭解兩者間的重點差異。
| 工作 3 | 工作 4 | |
|---|---|---|
| 核心產品 | BigQuery | Dataproc |
| 資料處理引擎 | BigQuery | Spark |
| 資料位置 | BigQuery 標準資料表 | GCS 中的 Parquet 檔案 |
| SQL 方言 | GoogleSQL | Spark SQL |
| 開發環境 | BigQuery Studio | Jupyter Notebooks |
做得好!
您已成功收集及處理所需資料,可以製作 Meredith 要求的報表,並使用合併的資料比較兩種數據分析方法:一種是以您熟悉的 BigQuery 為中心,另一種則以 Dataproc 和 Spark 為重。
首先,您在現有的 Dataproc 叢集上開啟了 Jupyter 筆記本。
然後,您按照筆記本中的操作說明,將包含退貨和地址資料的兩個 CSV 檔案彙整起來,建立合併的 Parquet 檔案,並儲存至 Cloud Storage bucket。
接著您聽取 Artem 的建議,使用合併後的 Parquet 檔案,比較 BigQuery 和 Dataproc 與 Spark 的資料分析結果,進一步瞭解相關的資料處理引擎、SQL 方言、資料位置和開發環境。
現在,您已瞭解如何使用 Dataproc 和 Spark 處理大型資料集了。
結束實驗室前,請確認已完成所有工作。如果已確定完成,請依序點選「結束實驗室」和「提交」。
結束實驗室後,就無法進入實驗室環境,也無法再次存取在實驗室完成的工作。



此内容目前不可用
一旦可用,我们会通过电子邮件告知您

太好了!
一旦可用,我们会通过电子邮件告知您

一次一个实验
确认结束所有现有实验并开始此实验