
始める前に
- ラボでは、Google Cloud プロジェクトとリソースを一定の時間利用します
- ラボには時間制限があり、一時停止機能はありません。ラボを終了した場合は、最初からやり直す必要があります。
- 画面左上の [ラボを開始] をクリックして開始します
Combine the data and export Parquet files
/ 35
Query data in BigQuery
/ 30
Query data in Dataproc and Spark
/ 35

 重要:
重要: このハンズオンラボは、デスクトップまたはノートパソコンでのみ完了するようにしてください。
このハンズオンラボは、デスクトップまたはノートパソコンでのみ完了するようにしてください。 ラボごとに 5 回までしか試行できません。
ラボごとに 5 回までしか試行できません。 なお、最初の試行で全問正解できないことや、タスクをやり直す必要があることはよくあります。これは学習プロセスの一部です。
なお、最初の試行で全問正解できないことや、タスクをやり直す必要があることはよくあります。これは学習プロセスの一部です。 ラボを開始すると、タイマーを一時停止することはできません。1 時間 30 分後にラボは終了し、最初からやり直す必要があります。
ラボを開始すると、タイマーを一時停止することはできません。1 時間 30 分後にラボは終了し、最初からやり直す必要があります。 詳しくは、ラボでの技術的なヒントの資料をご覧ください。
詳しくは、ラボでの技術的なヒントの資料をご覧ください。
クラウド データ分析は急速に進化している分野です。そのため、クラウド データ アナリストは、業務で能力を発揮するために、新しいプラットフォームとテクノロジーについて学び続ける必要があります。それには、BigQuery や Dataproc など、さまざまなプラットフォームを比較するのが良い方法です。
BigQuery と Dataproc はどちらもクラウド データ処理プラットフォームですが、データの分析に使用するデータ処理エンジン、SQL 言語、開発環境は異なります。
BigQuery は、大規模なデータセットに対するインタラクティブなクエリに適したデータ ウェアハウスです。使いやすく、幅広いデータ分析タスクを扱えます。
Dataproc は、大規模なデータセットに対するバッチ処理ジョブに適した、Hadoop と Spark のマネージド サービスです。BigQuery よりも柔軟性がありますが、設定と使用が複雑になる可能性があります。
BigQuery と Dataproc はどちらも他の Google Cloud サービスと統合されているため、両サービス間でのデータの移動や、データレイク ソースの検出は容易です。
このラボでは、2 つの CSV ファイルのデータを結合して Parquet ファイルにします。次に、結合したデータを使用して、BigQuery で実行した分析と、同じデータを使用して Dataproc と Spark で実行した分析を比較します。
TheLook eCommerce では、オンライン注文の返品を実店舗で受け付けるプログラムを試験運用しています。このプログラムによって、商品を簡単に返品できるようになるため、顧客満足度と売上の向上につながることが期待されます。
このプログラムの成果を追跡するため、主任マーチャンダイザーの Meredith は、店舗の住所と各店舗の返品データを組み合わせたレポートを作成するよう、あなたに依頼しました。このレポートは、地域ごとの返品を追跡するために使用されます。また、この情報は、さまざまな市場で試験運用プログラムが成功しているか否かを判断するうえでも役立ちます。
あなたはまず、各拠点から収集したデータを調べます。しかし、すぐにデータの量が膨大であると気づきます。収集、処理、分析が必要な大量のデータを扱うため、データ アーキテクトの Artem に連絡して支援を依頼します。
Artem は、Dataproc を使用して、対象となる 2 つの CSV ファイルを 1 つの Parquet ファイルに結合することを提案します。Parquet は、高速分析クエリ用に最適化されたカラム型データ形式です。TheLook eCommerce が Spark を使用して分析を行う企業を買収したばかりであるため、Artem は Dataproc と Spark について詳しく学ぶ絶好の機会だと補足しています。
Artem は、結合したデータを Meredith のレポートに使用し、使い慣れたプロダクトである BigQuery を中心とした分析と、Dataproc と Spark を中心とした分析の 2 つの分析方法を比較することを提案します。この方法は、Dataproc と Spark について詳しく学び、さらに 2 つのプラットフォームを比較して、どちらが試験運用プログラムのニーズに適しているかを確認するのにも向いています。
あなたは、アドバイスをくれた Artem に感謝しつつ次の作業に取り掛かります。BigQuery を Dataproc と Spark の組み合わせと比較する前に、比較に使用するデータを収集して処理する方法について計画を立てる必要があります。
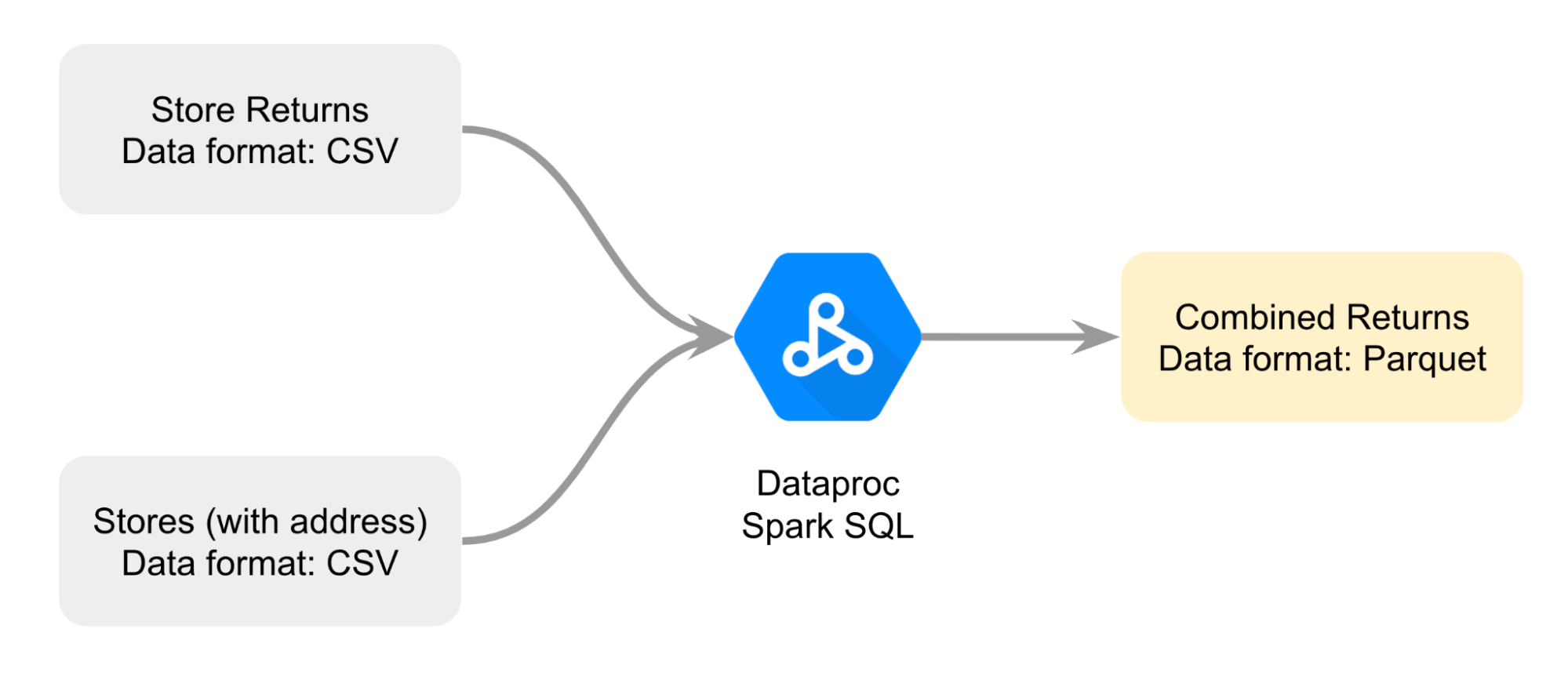
2 つの異なる CSV ファイルを結合する方法をうまく計画できるように、図を作成します。Dataproc Spark SQL を使用してファイル同士を結合し、Parquet 形式のファイルにするというアプローチです。
このデータを土台として使用し、比較を行います。
このタスクの手順は次のとおりです。最初に、Dataproc クラスタ上で Jupyter ノートブックを開きます。次に、ノートブックの手順に沿って、2 つの CSV ファイルを結合して Parquet ファイルを生成します。さらに、Cloud Storage バケットに保存されている Parquet ファイルのデータを BigQuery 標準テーブルに読み込んで分析します。最後に、同じ Parquet を Dataproc クラスタの Jupyter ノートブックで参照して、BigQuery を使用したデータ分析を Dataproc と Spark を使用したデータ分析と比較します。
こちらの手順をお読みください。ラボには時間制限があり、一時停止することはできません。[ラボを開始] をクリックすることでスタートするタイマーは、Google Cloud のリソースを利用できる時間を示しています。
この実践ラボでは、シミュレーションやデモ環境ではなく、実際のクラウド環境を使ってご自身でアクティビティを行うことができます。そのため、ラボの受講中に Google Cloud にログインおよびアクセスするための、新しい一時的な認証情報が提供されます。
このラボを完了するためには、以下が必要です。
[ラボを開始] ボタンをクリックします。左側の [ラボの詳細] パネルには、以下が表示されます。
[Google Cloud コンソールを開く] をクリックします(Chrome ブラウザを使用している場合は、右クリックして [シークレット ウィンドウで開く] を選択します)。新しいブラウザタブで [ログイン] ページが開きます。
ヒント: タブをそれぞれ別のウィンドウで開き、並べて表示しておくと、簡単に切り替えられます。
必要に応じて、下のGoogle Cloud ユーザー名をコピーして、[ログイン] ダイアログに貼り付けます。[Next] をクリックします。
[ラボの詳細] パネルでも Google Cloud ユーザー名を確認できます。
[ラボの詳細] パネルでも Google Cloud のパスワードを確認できます。
しばらくすると、このタブで Cloud コンソールが開きます。

JupyterLab を使用すると、Dataproc クラスタ上で Jupyter ノートブックを作成し、開いたり、編集したりできます。こうすることで、高パフォーマンス、高スケーラビリティといった、このクラスタのリソースの利点を活かして、ノートブックをより高速に実行し、より大きなデータセットを扱うことができるようになります。また、JupyterLab を使用して、他のユーザーと 1 つのプロジェクトで共同作業を行うこともできます。
このタスクでは、Dataproc で既存の Dataproc クラスタを開き、JupyterLab に移動して、このラボの残りのタスクを完了するために使用する Jupyter ノートブックを見つけます。
新しいブラウザタブで JupyterLab 環境が開きます。
C2M4-1 Combine and Export.ipynb ファイルを見つけます。Meredith は、場所と市場を特定できるように、各返品に関する情報と返品が行われた住所が必要です。しかし、これらの情報は 2 つの別々の CSV ファイルにあります。
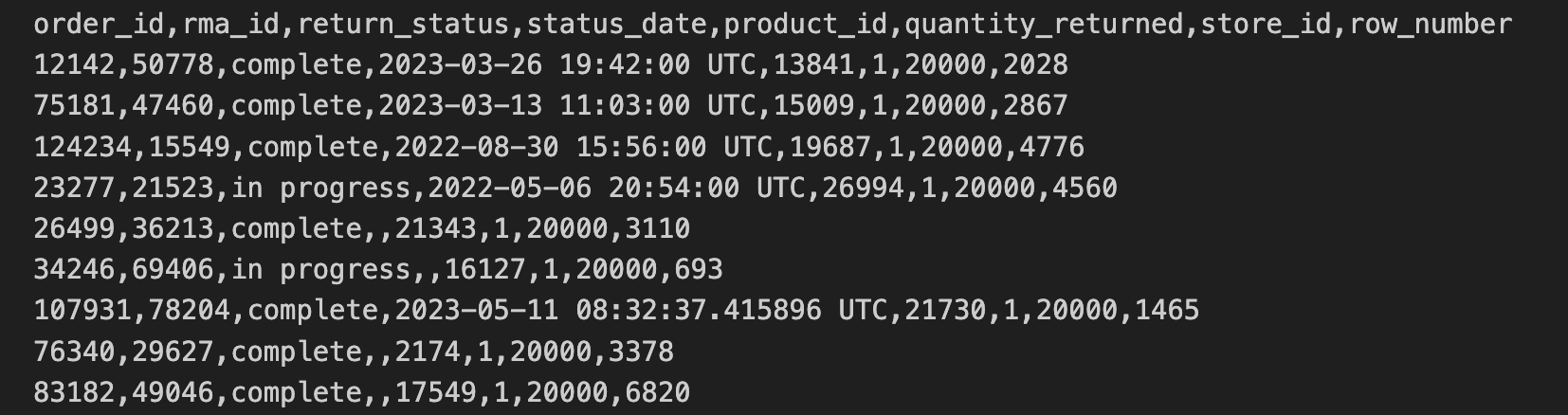
店舗の返品データが CSV 形式で店舗からエクスポートされ、Cloud Storage バケットにコピーされています。このデータには、order_id、rma_id、return_status、status_date、product_ied、quantity_returned、store_id が含まれます。
店舗の返品の CSV の最初の 10 行には、次の情報が含まれています。
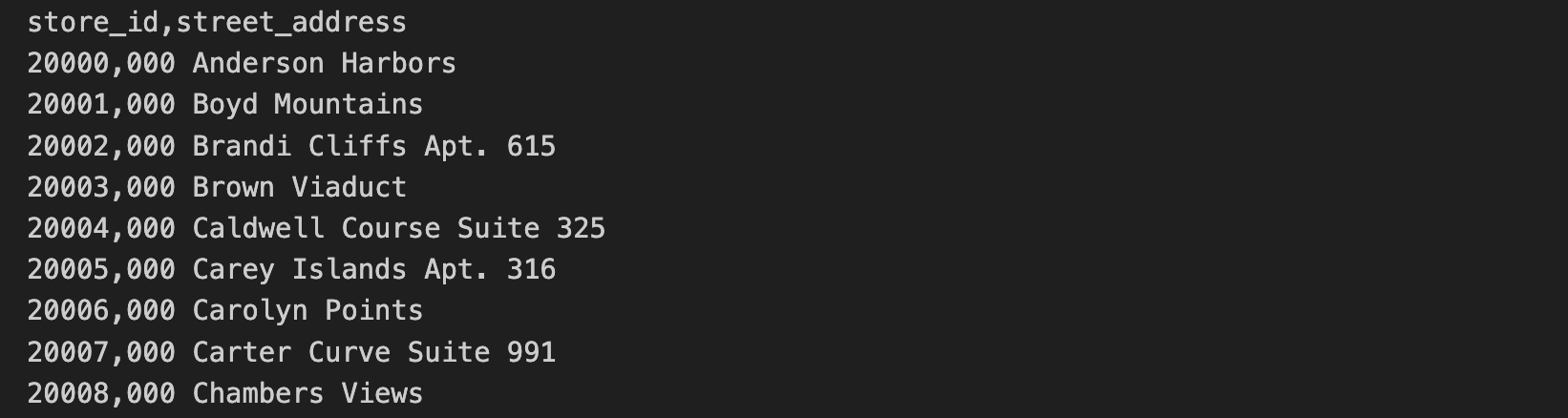
店舗の住所のデータは別の CSV ファイルに含まれています。このデータには、store_id と street_address が含まれます。
店舗の住所の CSV の最初の 10 行には、次の情報が含まれています。
このタスクでは、C2M4-1 Combine and Export.ipynb ファイルに含まれている SQL クエリと Python コマンドを実行して、2 つの CSV ファイルを結合します。結合されたファイルは Parquet ファイルとして保存されます。
左側のサイドバーで、C2M4-1 Combine and Export.ipynb ファイルをダブルクリックして、JupyterLab 環境で開きます。
JupyterLab のメニューバーで、[Kernel] > [Change Kernel] をクリックし、[PySpark] を選択して、[Select] をクリックします。
次に、ノートブックの手順に沿って、各セルのコードを実行します。
![[Run the selected cells and advance] アイコン](https://cdn.qwiklabs.com/cs8oniaQ%2BV6ek48OvvYwfo0bPUG8Xb8joIx5vjgZZJU%3D) )をクリックして各セルを実行します。または、Shift+Enter キーを押してコードを実行します。前のセルの出力に依存するセルは、順番に実行する必要があります。間違ってセルを順序どおりに実行しなかった場合は、ノートブックのツールバーにある [Refresh] ボタン(
)をクリックして各セルを実行します。または、Shift+Enter キーを押してコードを実行します。前のセルの出力に依存するセルは、順番に実行する必要があります。間違ってセルを順序どおりに実行しなかった場合は、ノートブックのツールバーにある [Refresh] ボタン(![[Restart the kernel] アイコン](https://cdn.qwiklabs.com/ybFlkqVtgboIsnDOVUI9vK%2BQQHVrBZg48sgZLm3ZpgY%3D) )をクリックして、カーネルを再起動します。
)をクリックして、カーネルを再起動します。Dataproc の Spark セッションは、Dataproc クラスタに接続して Spark アプリケーションを実行する手段です。Spark アプリケーションを開始して DataFrame を作成するための主な方法です。DataFrame は、Spark が処理してクエリを実行できるテーブルです。Spark を使用して、Google Cloud Storage や BigQuery などのさまざまなストレージ システムに対してデータの読み書きを行うことも可能です。
このノートブックでは、Spark セッションを作成し、CSV ファイルから Spark で使用されるテーブルである DataFrame に店舗の返品データを読み込みました。次に、2 つ目の CSV ファイルから店舗の住所を読み込み、2 つの DataFrame を結合して、結合された単一のテーブルを Parquet ファイルとしてエクスポートしました。最後に、クエリを使用して 1 つの列の名前を変更しました。
ヒント: 以下の質問に答える際は、出力を含むノートブックを開いたままにしてください。
[進行状況を確認] をクリックして、このタスクが正しく完了したことを確認します。
ここまでで、結合された Parquet ファイルが生成されて Cloud Storage バケットに保存されたので、BigQuery を中心とした分析と Dataproc と Spark を中心とした分析という 2 つの分析方法を比較する準備ができました。
では、BigQuery エンジンを使用してクエリを実行して、データを分析するデータ ウェアハウスである BigQuery から始めましょう。
前のタスクでは、Parquet ファイルを生成して Cloud Storage バケットに保存しました。このデータに BigQuery でアクセスする方法には、外部テーブルと標準テーブルの 2 つがあります。外部テーブルでは、Google Cloud Storage など、BigQuery の外部に保存されているデータを参照します。標準テーブルでは、データのコピーを BigQuery に直接保存します。
Artem からは、標準テーブルはデータのクエリと処理を即座にできるため、ビッグデータの処理には標準テーブルの方が効率的であることが多いと説明されました。したがって、このタスクには標準テーブルが最適であると判断します。
このタスクでは、Parquet ファイルを BigQuery の標準テーブルに読み込み、BigQuery 環境で使用される SQL 言語である GoogleSQL を使用してクエリを実行します。次に、次のタスクで BigQuery を Dataproc と Spark の組み合わせと比較するために必要な情報を確認するための質問に答えます。
JupyterLab のブラウザタブを開いたまま、Google Cloud コンソールのブラウザタブに戻ります(Dataproc のページがまだ開いているはずです)。
Google Cloud コンソールのナビゲーション メニュー(
クエリエディタで、+(SQL クエリ)アイコンをクリックして、新しい [無題のクエリ] タブを開きます。
次のクエリを [無題のクエリ] タブにコピーします。
このクエリは、Parquet ファイルを BigQuery にインポートします。
URI(Uniform Resource Identifier)は、Cloud Storage バケット内のファイルへのパスです。複数の URI を角かっこ [] で囲むと、URI の集合を LOAD DATA コマンドへの入力として指定できます。この表記は、値が URI の配列であることを示しています。
URI の先頭は常に gs:// として、Cloud Storage 内のリソースであることを示します。上で例に挙げた URI は、末尾が *.parquet であるため、.parquet という拡張子のファイルに限定します。記号 * はワイルドカードで、任意の文字列を意味します。
このクエリは、パス gs://
このクエリは、thelook_gcda.product_returns_to_store テーブルの行数を返します。
デフォルトでは、BigQuery Studio でクエリを実行すると、GoogleSQL 言語を使用して実行されます。GoogleSQL は標準 SQL 言語のスーパーセットです。つまり、すべての標準 SQL クエリに加えて、BigQuery で大量のデータや複雑なデータ型を簡単に操作できる追加の拡張機能も備えています。
このクエリは、受け取った返品の数を、月とステータスごとに表示します。
[進行状況を確認] をクリックして、このタスクが正しく完了したことを確認します。
BigQuery での分析が完了したので、Dataproc と Spark を中心とした分析に進みます。
Spark は、Dataproc でデータを分析するためのメインのデータ処理エンジンです。Dataproc は Spark クラスタを自動的に管理し、Spark がプリインストールされているため、データ分析において便利で強力な選択肢となります。
Spark では、独自の SQL 言語である Spark SQL も使用します。GoogleSQL と同様に、Spark SQL は SQL 言語です。Spark SQL は分散 SQL 言語です。つまり、Spark クラスタ内の複数のマシンに分散されたデータに対してクエリと分析を実行できます。
Dataproc と Spark で Spark SQL クエリを実行するには、Jupyter ノートブックを使用します。このインタラクティブ環境では、コードを記述して出力を簡単に表示できます。
このタスクでは、Cloud Storage バケットから参照される Parquet ファイルに対して Spark SQL クエリを実行します。次に、BigQuery を中心とした分析と Dataproc と Spark を中心とした分析という 2 つの分析方法の比較を完了するのに役立つ質問に答えます。
ブラウザの [JupyterLab] タブに戻ります。
C2M4-2 Query Store Data with Spark SQL.ipynb ファイルをダブルクリックして、それを JupyterLab 環境で開きます。
JupyterLab のメニューバーで、[Kernel] > [Change Kernel] をクリックし、[PySpark] を選択して、[Select] をクリックします。
ノートブックの手順に沿って、各セルのコードを実行します。
ノートブックの各セルをクリックし、[Run] をクリックするか、Shift+Enter キーを押してコードを実行します。
ノートブックで Spark SQL クエリの出力を確認します。
JupyterLab のメニューバーで、[File]、[Save Notebook] の順にクリックします。
ノートブックが保存されていない場合、以下の進行状況チェックで、これらの手順を完了したことを検出できないことがあります。
このノートブックでは、まず Spark セッションを作成しました。次に、iPython ノートブックを使用して Cloud Storage 内の Parquet ファイルのデータを参照し、DataFrame に入力しました。そして、DataFrame で Spark SQL を使用できるようにビューを作成しました。さらに、DataFrame の先頭の 3 行を返す Spark SQL クエリを実行しました。最後に、前の手順で BigQuery で実行したクエリと同じクエリを実行しました。
[進行状況を確認] をクリックして、このタスクが正しく完了したことを確認します。
ベスト プラクティスとして、環境を終了する前にクラスタを停止してください。
このラボで説明した、BigQuery を使用したデータ分析と、Dataproc と Spark を使用したデータ分析の違いを次の表にまとめます。
| タスク 3 | タスク 4 | |
|---|---|---|
| 中心となるプロダクト | BigQuery | Dataproc |
| データ処理エンジン | BigQuery | Spark |
| データのロケーション | BigQuery の標準テーブル | GCS の Parquet ファイル |
| SQL 言語 | GoogleSQL | Spark SQL |
| 開発環境 | BigQuery Studio | Jupyter ノートブック |
ラボはこれで完了です。
Meredith のレポートに必要なデータを収集して処理し、結合したデータを使い、使い慣れたプロダクトである BigQuery を中心とした分析と Dataproc と Spark を中心とした分析という 2 つのアプローチを比較できました。
まず、既存の Dataproc クラスタで Jupyter ノートブックを開きました。
次に、ノートブックの手順に沿って、返品データと住所データを含む 2 つの CSV ファイルを結合して Parquet ファイルを生成し、その Parquet ファイルを Cloud Storage バケットに保存しました。
Artem のアドバイスに従い、結合結果の Parquet ファイルを使用して、BigQuery を使用したデータ分析と、Dataproc と Spark を使用したデータ分析を比較し、データ処理エンジン、SQL 言語、データ ロケーション、開発環境について詳しく学びました。
これで、Dataproc と Spark を使用して大規模なデータセットを処理する方法についての理解が深まりました。
すべてのタスクが問題なく完了したことを確認してから、ラボを終了してください。準備ができたら、[ラボを終了] をクリックし、[送信] をクリックします。
ラボを終了すると、ラボ環境へのアクセス権が削除され、完了した作業にもう一度アクセスすることはできなくなります。



このコンテンツは現在ご利用いただけません
利用可能になりましたら、メールでお知らせいたします

ありがとうございます。
利用可能になりましたら、メールでご連絡いたします

1 回に 1 つのラボ
既存のラボをすべて終了して、このラボを開始することを確認してください