 IMPORTANT
IMPORTANT
 Cet atelier pratique ne peut être réalisé que sur un ordinateur de bureau ou un ordinateur portable.
Cet atelier pratique ne peut être réalisé que sur un ordinateur de bureau ou un ordinateur portable.
 Vous ne pouvez tenter l'atelier que cinq fois.
Vous ne pouvez tenter l'atelier que cinq fois.
 Pour rappel, il est normal de ne pas répondre correctement à toutes les questions du premier coup, et même de devoir refaire un exercice. Cela fait partie du processus d'apprentissage.
Pour rappel, il est normal de ne pas répondre correctement à toutes les questions du premier coup, et même de devoir refaire un exercice. Cela fait partie du processus d'apprentissage.
 Une fois l'atelier démarré, le minuteur ne peut pas être mis en pause. Au bout d'une heure et demie, l'atelier se terminera et vous devrez le recommencer.
Une fois l'atelier démarré, le minuteur ne peut pas être mis en pause. Au bout d'une heure et demie, l'atelier se terminera et vous devrez le recommencer.
 Pour en savoir plus, consultez le document Conseils techniques pour les ateliers.
Pour en savoir plus, consultez le document Conseils techniques pour les ateliers.
Présentation de l'activité
L'analyse de données cloud est un domaine en évolution rapide. Les analystes de données cloud doivent se tenir informés des nouvelles plates-formes et technologies pour rester efficaces dans leur travail. Pour ce faire, il est très utile de comparer différentes plates-formes, comme BigQuery et Dataproc.
BigQuery et Dataproc sont deux plates-formes de traitement de données cloud, mais elles utilisent des moteurs de traitement de données, des dialectes SQL et des environnements de développement différents pour analyser les données.
BigQuery est un entrepôt de données adapté aux requêtes interactives sur de grands ensembles de données. Il est facile à utiliser et peut gérer un large éventail de tâches d'analyse de données.
Dataproc est un service géré Hadoop et Spark qui convient aux jobs de traitement par lots sur de grands ensembles de données. Il est plus flexible que BigQuery, mais sa configuration et son utilisation peuvent être plus complexes.
BigQuery et Dataproc sont tous deux intégrés à d'autres services Google Cloud, ce qui facilite le transfert de données entre eux et la découverte des sources de lacs de données.
Dans cet atelier, vous allez joindre les données de deux fichiers CSV dans un fichier Parquet. Vous utiliserez ensuite les données combinées pour comparer l'analyse effectuée avec BigQuery à celle effectuée avec les mêmes données à l'aide de Dataproc et Spark.
Scénario
TheLook eCommerce teste un programme permettant d'accepter les retours de commandes en ligne dans n'importe lequel de ses magasins physiques. Ce programme permettra aux clients de retourner plus facilement des articles, ce qui devrait améliorer la satisfaction client et les ventes.
Pour suivre le succès de ce programme, Meredith, la responsable du merchandising, vous a demandé de préparer un rapport combinant les adresses des magasins et les données sur les retours pour chacun d'eux. Ce rapport permettra de suivre les retours par emplacement et par région. Les informations recueillies aideront également à déterminer le succès du programme pilote sur différents marchés.
Pour commencer, vous explorez les données collectées jusqu'à présent pour chaque magasin. Cependant, vous vous rendez vite compte que la quantité de données est énorme. Vous contactez Artem, l'architecte de données, pour obtenir de l'aide concernant le volume élevé de données qui devront être collectées, traitées et analysées.
Artem vous suggère d'utiliser Dataproc pour combiner les deux fichiers CSV sur lesquels vous travaillez en un seul fichier Parquet. Parquet est un format de données en colonnes optimisé pour les requêtes analytiques rapides. Artem ajoute que TheLook eCommerce vient d'acquérir une entreprise qui effectue des analyses avec Spark. C'est donc une excellente occasion d'en savoir plus sur Dataproc et Spark.
Il vous propose d'utiliser les données combinées pour le rapport de Meredith afin de comparer deux méthodes d'analyse : l'une centrée sur BigQuery, un produit que vous connaissez déjà, et l'autre centrée sur Dataproc et Spark. C'est un bon moyen d'en savoir plus sur Dataproc et Spark, mais aussi de comparer les deux plates-formes et de voir laquelle est la mieux adaptée aux besoins du programme pilote.
Vous remerciez Artem pour ses conseils. Mais avant de comparer BigQuery à Dataproc et Spark, vous devez définir comment vous allez collecter et traiter les données qui seront utilisées pour la comparaison.
Vous créez un diagramme pour mieux planifier la façon dont vous allez combiner les deux fichiers CSV différents. Votre approche consiste à joindre les fichiers avec Dataproc Spark SQL pour générer un fichier de retours combiné au format Parquet.
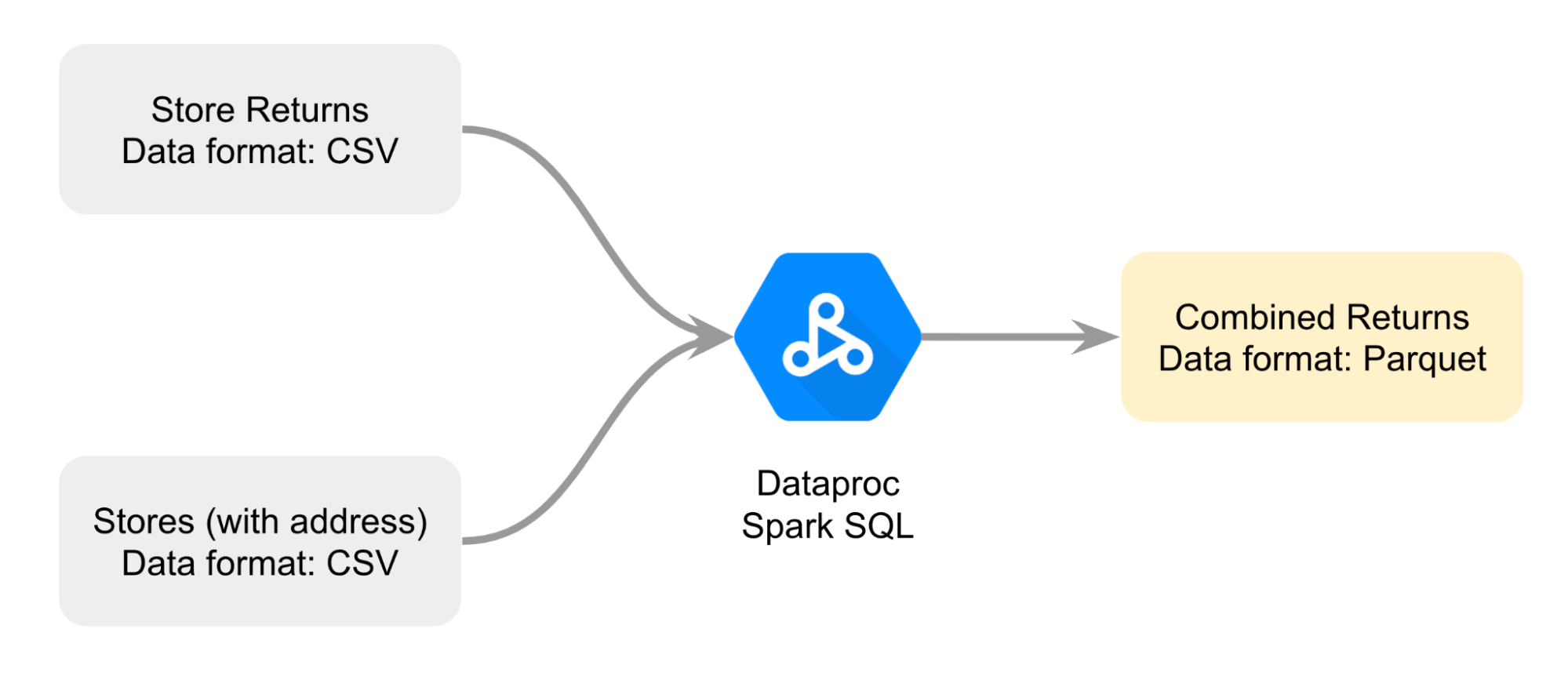
Il s'agit des données que vous utiliserez comme base de comparaison.
Voici comment vous allez procéder : d'abord, vous allez ouvrir un notebook Jupyter sur un cluster Dataproc. Dans un deuxième temps, vous allez suivre les instructions du notebook pour joindre les deux fichiers CSV et créer un fichier Parquet. Ensuite, vous allez charger les données du fichier Parquet stocké dans un bucket Cloud Storage dans une table standard BigQuery pour les analyser. Enfin, vous allez référencer le même fichier Parquet dans un notebook Jupyter sur un cluster Dataproc afin de comparer l'analyse de données avec BigQuery à l'analyse de données avec Dataproc et Spark.
Configuration
Avant de cliquer sur "Démarrer l'atelier"
Lisez ces instructions. Les ateliers sont minutés, et vous ne pouvez pas les mettre en pause. Le minuteur, qui démarre lorsque vous cliquez sur Démarrer l'atelier, indique combien de temps les ressources Google Cloud resteront accessibles.
Cet atelier pratique vous permet de suivre vous-même les activités dans un véritable environnement cloud, et non dans un environnement de simulation ou de démonstration. Nous vous fournissons des identifiants temporaires pour vous connecter à Google Cloud le temps de l'atelier.
Pour réaliser cet atelier :
- Vous devez avoir accès à un navigateur Internet standard (nous vous recommandons d'utiliser Chrome).
Remarque : Ouvrez une fenêtre de navigateur en mode incognito/navigation privée pour effectuer cet atelier. Vous éviterez ainsi les conflits entre votre compte personnel et le compte temporaire de participant, qui pourraient entraîner des frais supplémentaires facturés sur votre compte personnel.
- Vous disposez d'un temps limité. N'oubliez pas qu'une fois l'atelier commencé, vous ne pouvez pas le mettre en pause.
Remarque : Si vous possédez déjà votre propre compte ou projet Google Cloud, veillez à ne pas l'utiliser pour réaliser cet atelier afin d'éviter que des frais supplémentaires ne vous soient facturés.
Démarrer l'atelier et se connecter à la console Google Cloud
-
Cliquez sur le bouton Démarrer l'atelier. Sur la gauche, vous trouverez le panneau Détails concernant l'atelier, qui contient les éléments suivants :
- Le temps restant
- Le bouton Ouvrir la console Google Cloud
- Les identifiants temporaires que vous devez utiliser pour cet atelier
- D'éventuelles informations complémentaires vous permettant d'effectuer l'atelier
Remarque : Si l'atelier est payant, un pop-up s'affiche pour vous permettre de sélectionner un mode de paiement.
-
Cliquez sur Ouvrir la console Google Cloud (ou effectuez un clic droit et sélectionnez Ouvrir le lien dans la fenêtre de navigation privée) si vous utilisez le navigateur Chrome. La page Se connecter s'ouvre dans un nouvel onglet du navigateur.
Conseil : Vous pouvez réorganiser les onglets dans des fenêtres distinctes, placées côte à côte, pour passer facilement de l'un à l'autre.
Remarque : Si la boîte de dialogue Sélectionner un compte s'affiche, cliquez sur Utiliser un autre compte.
-
Si nécessaire, copiez le nom d'utilisateur Google Cloud ci-dessous et collez-le dans la boîte de dialogue Se connecter. Cliquez sur Suivant.
{{{user_0.username | "Google Cloud username"}}}
Vous trouverez également le nom d'utilisateur Google Cloud dans le panneau Détails concernant l'atelier.
- Copiez le mot de passe Google Cloud ci-dessous et collez-le dans la boîte de dialogue Bienvenue. Cliquez sur Suivant.
{{{user_0.password | "Google Cloud password"}}}
Vous trouverez également le mot de passe Google Cloud dans le panneau Détails concernant l'atelier.
Important : Vous devez utiliser les identifiants qui vous ont été fournis pour l'atelier. N'utilisez pas ceux de votre compte Google Cloud.
Remarque : Si vous utilisez votre propre compte Google Cloud pour cet atelier, des frais supplémentaires peuvent vous être facturés.
- Parcourez les pages suivantes :
- Acceptez les conditions d'utilisation.
- N'ajoutez pas d'options de récupération ni d'authentification à deux facteurs (ce compte est temporaire).
- Ne vous inscrivez pas à des essais sans frais.
Après quelques instants, la console s'ouvre dans cet onglet.
Remarque : Vous pouvez afficher le menu qui contient la liste des produits et services Google Cloud en cliquant sur le menu de navigation en haut à gauche.
 Remarque : Une fois que vous aurez cliqué sur Démarrer l'atelier, le temps nécessaire au provisionnement des ressources de l'atelier sera indiqué. Toutefois, il est possible que cela prenne un peu plus de temps que prévu.
Remarque : Une fois que vous aurez cliqué sur Démarrer l'atelier, le temps nécessaire au provisionnement des ressources de l'atelier sera indiqué. Toutefois, il est possible que cela prenne un peu plus de temps que prévu.
Tâche 1 : Ouvrir JupyterLab sur un cluster Dataproc
JupyterLab permet de créer, d'ouvrir et de modifier des notebooks Jupyter sur un cluster Dataproc. Cela vous permet de profiter des ressources du cluster, telles que ses performances élevées et son évolutivité, et d'exécuter vos notebooks plus rapidement et sur des ensembles de données plus volumineux. Vous pouvez également utiliser JupyterLab pour collaborer avec d'autres personnes sur des projets.
Dans cette tâche, vous allez ouvrir un cluster Dataproc existant dans Dataproc et accéder à JupyterLab pour localiser les notebooks Jupyter que vous utiliserez afin d'effectuer les tâches restantes de cet atelier.
- Dans le champ Recherche de la barre de titre de la console Google Cloud, saisissez "Dataproc", puis appuyez sur ENTRÉE.
- Dans les résultats de recherche, sélectionnez Dataproc.
- Sur la page Clusters, cliquez sur le nom du cluster listé, mycluster.
- Sur la page à onglets Détails du cluster, sélectionnez l'onglet Interfaces Web.
- Dans la section Passerelle des composants, cliquez sur le lien JupyterLab.
Remarque : Veillez à ne pas confondre le lien JupyterLab avec le lien Jupyter.
L'environnement JupyterLab s'ouvre dans un nouvel onglet du navigateur.
- Recherchez le fichier
C2M4-1 Combine and Export.ipynb dans le dossier GCS listé dans la barre latérale de gauche.
Tâche 2 : Combiner les données et exporter des fichiers Parquet
Pour que Meredith puisse identifier les magasins et les marchés, elle a besoin d'informations sur chaque retour et sur l'adresse physique où il a été effectué. Toutefois, ces informations se trouvent dans deux fichiers CSV distincts.
Les données sur les retours en magasin ont été exportées depuis les magasins au format CSV et copiées dans un bucket Cloud Storage. Ces données incluent les attributs order_id, rma_id, return_status, status_date, product_ied, quantity_returned et store_id.
Les 10 premières lignes du fichier CSV des retours en magasin contiennent les informations suivantes :
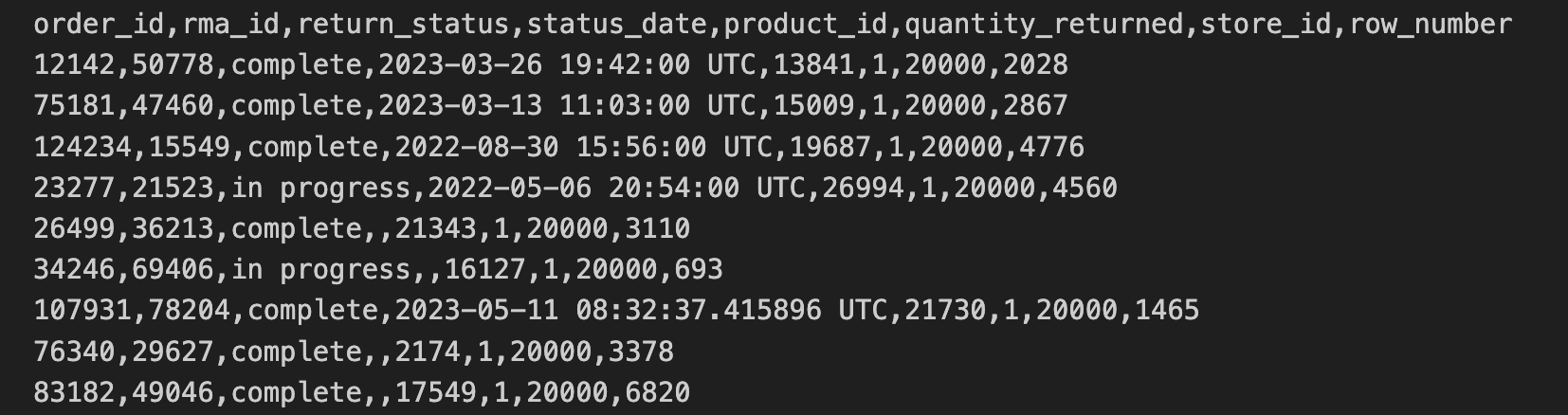
Les données sur les adresses des magasins se trouvent dans un fichier CSV distinct. Ces données incluent les attributs store_id et street_address.
Les 10 premières lignes du fichier CSV des adresses des magasins contiennent les informations suivantes :
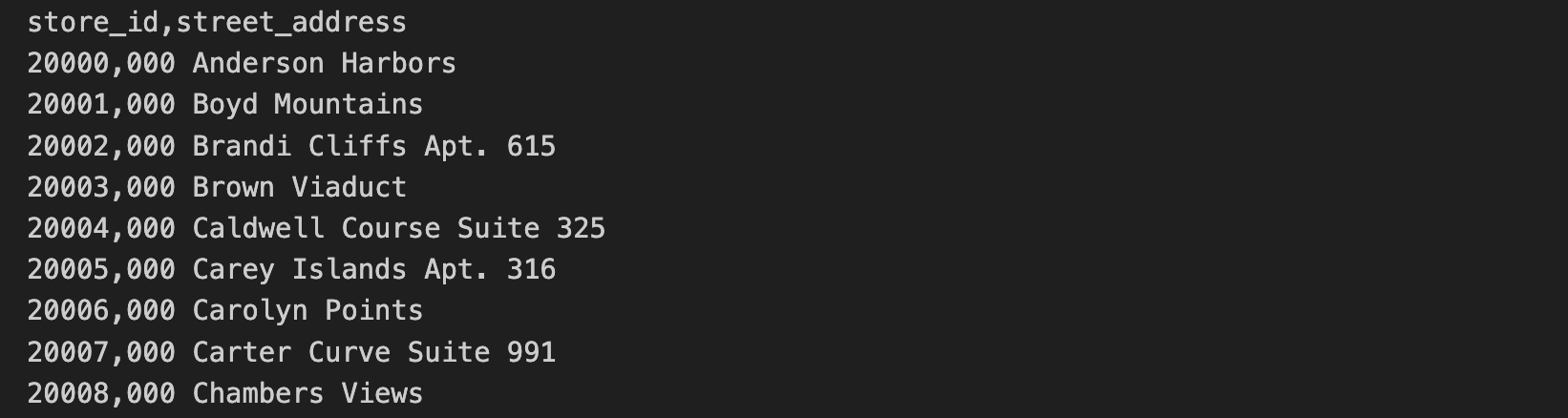
Dans cette tâche, vous allez exécuter les requêtes SQL et les commandes Python contenues dans le fichier C2M4-1 Combine and Export.ipynb pour joindre les deux fichiers CSV. Les fichiers combinés seront stockés sous forme de fichier Parquet.
-
Dans la barre latérale de gauche, double-cliquez sur le fichier C2M4-1 Combine and Export.ipynb pour l'ouvrir dans l'environnement JupyterLab.
-
Dans la barre de menu JupyterLab, cliquez sur Noyau > Modifier le noyau, sélectionnez PySpark, puis cliquez sur Sélectionner.
Ensuite, suivez les instructions du notebook et exécutez le code dans chacune des cellules.
- Cliquez sur chaque cellule du notebook, puis sur l'icône Exécuter les cellules sélectionnées et progresser (
 ) pour exécuter chaque cellule. Vous pouvez aussi appuyer sur MAJ+ENTRÉE pour exécuter le code. Les cellules qui dépendent de la sortie d'une cellule précédente DOIVENT être exécutées dans l'ordre. Si vous faites une erreur et exécutez une cellule dans le désordre, cliquez sur le bouton Actualiser (
) pour exécuter chaque cellule. Vous pouvez aussi appuyer sur MAJ+ENTRÉE pour exécuter le code. Les cellules qui dépendent de la sortie d'une cellule précédente DOIVENT être exécutées dans l'ordre. Si vous faites une erreur et exécutez une cellule dans le désordre, cliquez sur le bouton Actualiser ( ) dans la barre d'outils du notebook pour redémarrer le noyau.
) dans la barre d'outils du notebook pour redémarrer le noyau.
Remarque : Les cellules du notebook doivent être exécutées dans l'ordre pour que le notebook fonctionne correctement. Si un message d'erreur s'affiche lorsque vous exécutez une cellule du notebook, assurez-vous que chaque cellule a été exécutée, puis réessayez d'exécuter l'intégralité du notebook pour résoudre l'erreur.
- Explorez les résultats de chaque cellule du notebook. Les deux fichiers CSV sont maintenant associés, et le fichier Parquet que vous utiliserez dans la tâche suivante a été créé automatiquement.
Une session Spark dans Dataproc permet de se connecter à un cluster Dataproc et d'exécuter des applications Spark. Il s'agit du principal moyen de démarrer des applications Spark et de créer des DataFrames. Les DataFrames sont des tables que Spark peut traiter et sur lesquelles il peut exécuter des requêtes. Avec Spark, vous pouvez également lire et écrire des données dans différents systèmes de stockage, tels que Google Cloud Storage ou BigQuery.
Remarque : Dataproc peut également traiter les requêtes enregistrées dans des fichiers texte, ce qui est la solution habituelle pour les processus automatisés. L'utilisation d'un notebook est une approche standard lors du développement et de l'exploration des données.
Dans ce notebook, vous avez créé une session Spark et chargé les données sur les retours en magasin à partir d'un fichier CSV dans un DataFrame, qui est une table utilisée dans Spark. Ensuite, vous avez chargé les adresses des magasins à partir d'un deuxième fichier CSV, joint les deux Dataframes et exporté la table jointe unique sous forme de fichier Parquet. Enfin, vous avez utilisé une requête pour modifier le nom d'une des colonnes.
Conseil : Gardez le notebook avec les sorties ouvert pendant que vous répondez aux questions ci-dessous.
Cliquez sur Vérifier ma progression pour vérifier que vous avez correctement accompli cette tâche.
Combiner les données et exporter des fichiers Parquet
Tâche 3 : Interroger les données dans BigQuery
Maintenant que le fichier Parquet combiné est créé et stocké dans un bucket Cloud Storage, vous êtes prêt à comparer les deux méthodes d'analyse : l'une centrée sur BigQuery et l'autre sur Dataproc et Spark.
Commencez par BigQuery, un entrepôt de données qui utilise le moteur BigQuery pour exécuter des requêtes et analyser des données.
Dans la dernière tâche, vous avez créé un fichier Parquet et l'avez stocké dans un bucket Cloud Storage. Pour accéder à ces données dans BigQuery, vous avez le choix entre une table externe et une table standard. Les tables externes font référence à des données stockées en dehors de BigQuery, par exemple dans Google Cloud Storage. Les tables standards stockent une copie des données directement dans BigQuery.
Artem vous a expliqué que les tables standards sont souvent le choix le plus efficace pour travailler avec le big data, car les données peuvent être interrogées et traitées rapidement. Vous décidez donc qu'une table standard est le meilleur choix pour cette tâche.
Dans cette tâche, vous allez charger le fichier Parquet dans une table standard de BigQuery et exécuter une requête à l'aide de GoogleSQL, le dialecte SQL utilisé dans l'environnement BigQuery. Ensuite, vous répondrez à des questions pour vous assurer d'avoir les informations nécessaires pour comparer BigQuery à Dataproc et Spark dans la tâche suivante.
-
Revenez à l'onglet de navigateur de la console Google Cloud (où la page Dataproc doit être encore ouverte), tout en gardant l'onglet de navigateur JupyterLab ouvert.
-
Dans le menu de navigation ( ) de la console Google Cloud, cliquez sur BigQuery > Studio. BigQuery Studio est la principale façon d'écrire et d'exécuter des requêtes dans BigQuery.
) de la console Google Cloud, cliquez sur BigQuery > Studio. BigQuery Studio est la principale façon d'écrire et d'exécuter des requêtes dans BigQuery.
Remarque : Il est possible que la boîte de dialogue Bienvenue sur BigQuery dans la console Cloud s'affiche. Elle fournit des liens vers le guide de démarrage rapide et les notes de version concernant les mises à jour de l'interface utilisateur. Cliquez sur OK pour continuer.
-
Dans l'éditeur de requête, cliquez sur l'icône + (Requête SQL) pour ouvrir un nouvel onglet Requête sans titre.
-
Copiez la requête suivante et collez-la dans l'onglet Requête sans titre :
LOAD DATA OVERWRITE thelook_gcda.product_returns_to_store
FROM FILES (
format="PARQUET",
uris=["gs://{{{project_0.project_id | "PROJECT_ID"}}}/store_returns_output/store_returns.parquet/*.parquet"]
) ;
Cette requête importe le fichier Parquet dans BigQuery.
- Cliquez sur Exécuter.
Un URI (Uniform Resource Identifier) est le chemin d'accès à un fichier dans un bucket Cloud Storage. Vous pouvez fournir une collection d'URI en entrée de la commande LOAD DATA en les encadrant de crochets []. Cela indique que la valeur est un tableau d'URI.
L'URI commence toujours par gs://, ce qui indique qu'il s'agit d'une ressource dans Cloud Storage. L'URI fourni dans l'exemple ci-dessus filtre les fichiers avec une extension .parquet, car il se termine par *.parquet. Le symbole * est un caractère générique, ce qui signifie qu'il peut remplacer n'importe quelle chaîne.
Cette requête renvoie tous les fichiers du chemin d'accès gs:///store_returns_output/store_returns.parquet/ dont le nom se termine par ".parquet", et charge les données dans la table "store_returns".
- Copiez la requête suivante dans l'éditeur de requête :
SELECT count(*)
FROM thelook_gcda.product_returns_to_store;
Cette requête renvoie le nombre de lignes dans la table "thelook_gcda.product_returns_to_store".
- Cliquez sur Exécuter.
Par défaut, lorsque vous exécutez une requête dans BigQuery Studio, elle est exécutée à l'aide du dialecte GoogleSQL. GoogleSQL est un sur-ensemble du dialecte SQL standard. Cela signifie qu'il inclut toutes les requêtes SQL standards et les extensions supplémentaires qui facilitent l'utilisation de grandes quantités de données et de types de données complexes dans BigQuery.
- Copiez la requête suivante dans l'éditeur de requête :
SELECT
substring(CAST(status_date AS STRING), 1, 7) as year_month,
return_status,
count(order_id) as order_count
FROM thelook_gcda.product_returns_to_store
GROUP BY year_month, return_status;
Cette requête affiche le nombre de retours reçus par mois et par état.
- Cliquez sur Exécuter.
Remarque : La colonne "year_month" peut contenir des valeurs nulles dans le résultat.
Cliquez sur Vérifier ma progression pour vérifier que vous avez correctement accompli cette tâche.
Interroger les données dans BigQuery
Tâche 4 : Interroger des données dans Dataproc et Spark
Maintenant que vous avez terminé votre analyse dans BigQuery, vous êtes prêt à explorer l'analyse centrée sur Dataproc et Spark.
Spark est le principal moteur de traitement des données pour l'analyse des données avec Dataproc. Dataproc gère automatiquement le cluster Spark et est préinstallé avec Spark, ce qui en fait un choix pratique et très efficace pour l'analyse des données.
Spark utilise également son propre dialecte SQL, Spark SQL. Comme GoogleSQL, Spark SQL est un dialecte SQL. Spark SQL est un dialecte SQL distribué, ce qui signifie qu'il peut interroger et analyser des données distribuées sur plusieurs machines du cluster Spark.
Pour exécuter des requêtes Spark SQL avec Dataproc et Spark, vous utiliserez un notebook Jupyter. Cet environnement interactif vous permet d'écrire du code et d'afficher facilement son résultat.
Dans cette tâche, vous allez exécuter des requêtes SparkSQL sur le fichier Parquet référencé à partir du bucket Cloud Storage. Vous répondrez ensuite à des questions qui vous aideront à comparer les deux méthodes d'analyse : l'une centrée sur BigQuery et l'autre sur Dataproc et Spark.
-
Revenez à l'onglet JupyterLab dans votre navigateur.
-
Double-cliquez sur le fichier C2M4-2 Query Store Data with Spark SQL.ipynb pour l'ouvrir dans l'environnement JupyterLab.
-
Dans la barre de menu JupyterLab, cliquez sur Noyau > Modifier le noyau, sélectionnez PySpark, puis cliquez sur Sélectionner.
Suivez les instructions du notebook et exécutez le code dans chacune des cellules.
-
Cliquez sur chaque cellule du notebook, puis sur Exécuter, ou appuyez sur MAJ+ENTRÉE pour exécuter le code.
-
Explorez les résultats des requêtes Spark SQL dans le notebook.
-
Dans la barre de menu JupyterLab, cliquez sur Fichier, puis sur Enregistrer le notebook.
Si le notebook n'a pas été enregistré, il est possible que la vérification de la progression ci-dessous ne puisse pas détecter que vous avez effectué ces étapes.
Dans ce notebook, vous avez d'abord créé une session Spark. Vous avez ensuite référencé les données des fichiers Parquet dans Cloud Storage à l'aide du notebook iPython et rempli un DataFrame. Puis vous avez créé une vue pour que le DataFrame puisse être utilisé avec Spark SQL. Vous avez ensuite exécuté une requête Spark SQL qui a renvoyé les trois premières lignes du DataFrame. Enfin, vous avez exécuté la même requête que celle que vous avez exécutée dans BigQuery à l'étape précédente.
Cliquez sur Vérifier ma progression pour vérifier que vous avez correctement accompli cette tâche.
Interroger des données dans Dataproc et Spark
Tâche 5 : Arrêter le cluster
Avant de quitter l'environnement, veillez à arrêter le cluster.
Remarque : Le fait de laisser des clusters en cours d'exécution utilise des ressources et peut entraîner des coûts supplémentaires.
- Revenez à l'onglet BigQuery de votre navigateur.
- Dans le champ Rechercher de la barre de titre de la console Google Cloud, saisissez Dataproc.
- Sélectionnez Dataproc dans les résultats de recherche. Cliquez sur Clusters dans le menu de gauche.
- Dans la liste des clusters, cochez la case à côté de mycluster.
- Dans la barre Action, cliquez sur Arrêter, puis sur Confirmer.
Résumé
Consultez le tableau ci-dessous, qui récapitule les différences entre l'analyse de données avec BigQuery et l'analyse de données avec Dataproc et Spark abordées dans cet atelier.
|
Tâche 3 |
Tâche 4 |
| Produit central |
BigQuery |
Dataproc |
| Moteur de traitement des données |
BigQuery |
Spark |
| Emplacement des données |
Table BigQuery standard |
Fichier Parquet dans GCS |
| Dialecte SQL |
GoogleSQL |
Spark SQL |
| Environnement de développement |
BigQuery Studio |
Notebooks Jupyter |
Conclusion
Bravo !
Vous avez réussi à collecter et à traiter les données nécessaires pour le rapport de Meredith. Vous avez également utilisé les données combinées pour comparer deux approches d'analyse : l'une centrée sur BigQuery, un produit que vous connaissez déjà, et l'autre centrée sur Dataproc et Spark.
Vous avez d'abord ouvert un notebook Jupyter sur un cluster Dataproc existant.
Vous avez ensuite suivi les instructions du notebook pour joindre deux fichiers CSV contenant des données sur les retours et les adresses afin de créer un fichier Parquet combiné et de le stocker dans un bucket Cloud Storage.
En suivant les conseils d'Artem, vous avez ensuite utilisé le fichier Parquet combiné pour comparer l'analyse des données à l'aide de BigQuery et de Dataproc et Spark. Vous avez ainsi pu en savoir plus sur leurs moteurs de traitement des données, leurs dialectes SQL, leurs emplacements de données et leur environnement de développement.
Vous êtes en bonne voie pour maîtriser l'utilisation de Dataproc et Spark pour travailler avec de grands ensembles de données.
Terminer l'atelier
Avant de terminer l'atelier, assurez-vous d'avoir bien accompli toutes les tâches. Cliquez alors sur Terminer l'atelier, puis sur Envoyer.
Une fois l'atelier terminé, vous n'aurez plus accès à l'environnement de l'atelier ni au travail que vous avez effectué.






