



![Cloud Data Fusion の [リネージ] タブ](https://cdn.qwiklabs.com/7%2FjWh5dxyUISQhwtbXImC%2FLgBupIAwDMSLfULz2J2DI%3D)


始める前に
- ラボでは、Google Cloud プロジェクトとリソースを一定の時間利用します
- ラボには時間制限があり、一時停止機能はありません。ラボを終了した場合は、最初からやり直す必要があります。
- 画面左上の [ラボを開始] をクリックして開始します
Add Cloud Data Fusion API Service Agent role to service account
/ 30
Import, Deploy and Run Shipment Data Cleansing pipeline
/ 35
Import, Deploy, and Run the Delayed Shipments data pipeline
/ 35
Add Cloud Data Fusion API Service Agent role to service account
/ 30
Import, Deploy and Run Shipment Data Cleansing pipeline
/ 35
Import, Deploy, and Run the Delayed Shipments data pipeline
/ 35
このラボでは、Cloud Data Fusion を使用して、データリネージ(データの起源とその経緯)を調べる方法を説明します。
Cloud Data Fusion のデータリネージは次の処理を行う場合に有用です。
Cloud Data Fusion は、データセット レベル、フィールド レベルでリネージを追跡するだけでなく、時間制約付きリネージを追跡して、時系列でもリネージを表示します。
このラボでは、元データをクリーンアップしてからダウンストリーム処理を行う一般的なシナリオを示す 2 つのパイプラインを使用します。元データから、分析出力のためのクリーンアップされた配送データまでのデータ証跡は、Cloud Data Fusion のリネージ機能を使用して確認できます。
このラボでは、次の方法について学びます。
各ラボでは、新しい Google Cloud プロジェクトとリソースセットを一定時間無料で利用できます。
シークレット ウィンドウを使用して Google Skills にログインします。
ラボのアクセス時間(例: 02:00:00)に注意し、時間内に完了できるようにしてください。
一時停止機能はありません。必要な場合はやり直せますが、最初からになります。
準備ができたら、[ラボを開始] をクリックします。
ラボの認証情報(ユーザー名とパスワード)をメモしておきます。この情報は、Google Cloud コンソールにログインする際に使用します。
[Google Console を開く] をクリックします。
[別のアカウントを使用] をクリックし、このラボの認証情報をコピーしてプロンプトに貼り付けます。
他の認証情報を使用すると、エラーが発生したり、料金の請求が発生したりします。
利用規約に同意し、再設定用のリソースページをスキップします。
[ラボを開始] ボタンをクリックします。ラボの料金をお支払いいただく必要がある場合は、表示されるダイアログでお支払い方法を選択してください。 左側の [ラボの詳細] ペインには、以下が表示されます。
[Google Cloud コンソールを開く] をクリックします(Chrome ブラウザを使用している場合は、右クリックして [シークレット ウィンドウで開く] を選択します)。
ラボでリソースがスピンアップし、別のタブで [ログイン] ページが表示されます。
ヒント: タブをそれぞれ別のウィンドウで開き、並べて表示しておきましょう。
必要に応じて、下のユーザー名をコピーして、[ログイン] ダイアログに貼り付けます。
[ラボの詳細] ペインでもユーザー名を確認できます。
[次へ] をクリックします。
以下のパスワードをコピーして、[ようこそ] ダイアログに貼り付けます。
[ラボの詳細] ペインでもパスワードを確認できます。
[次へ] をクリックします。
その後次のように進みます。
その後、このタブで Google Cloud コンソールが開きます。

Cloud Shell は、開発ツールが組み込まれた仮想マシンです。5 GB の永続ホーム ディレクトリを提供し、Google Cloud 上で実行されます。Cloud Shell を使用すると、コマンドラインで Google Cloud リソースにアクセスできます。gcloud は Google Cloud のコマンドライン ツールで、Cloud Shell にプリインストールされており、Tab キーによる入力補完がサポートされています。
Google Cloud Console のナビゲーション パネルで、「Cloud Shell をアクティブにする」アイコン(
[次へ] をクリックします。
環境がプロビジョニングされ、接続されるまでしばらく待ちます。接続の際に認証も行われ、プロジェクトは現在のプロジェクト ID に設定されます。次に例を示します。
有効なアカウント名前を一覧表示する:
(出力)
(出力例)
プロジェクト ID を一覧表示する:
(出力)
(出力例)
Google Cloud で作業を開始する前に、Identity and Access Management(IAM)内で適切な権限がプロジェクトに付与されていることを確認する必要があります。
Google Cloud コンソールのナビゲーション メニュー(
Compute Engine のデフォルトのサービス アカウント {project-number}-compute@developer.gserviceaccount.com が存在し、編集者のロールが割り当てられていることを確認します。アカウントの接頭辞はプロジェクト番号で、ナビゲーション メニュー > [Cloud の概要] から確認できます。
アカウントが IAM に存在しない場合やアカウントに編集者のロールがない場合は、以下の手順に沿って必要なロールを割り当てます。
Google Cloud コンソールのナビゲーション メニューで、[Cloud の概要] をクリックします。
[プロジェクト情報] カードからプロジェクト番号をコピーします。
ナビゲーション メニューで、[IAM と管理] > [IAM] をクリックします。
IAM ページの上部にある [追加] をクリックします。
新しいプリンシパルの場合は、次のように入力します。
{project-number} はプロジェクト番号に置き換えてください。
[ロールを選択] で、[基本](または [Project])> [編集者] を選択します。
[保存] をクリックします。
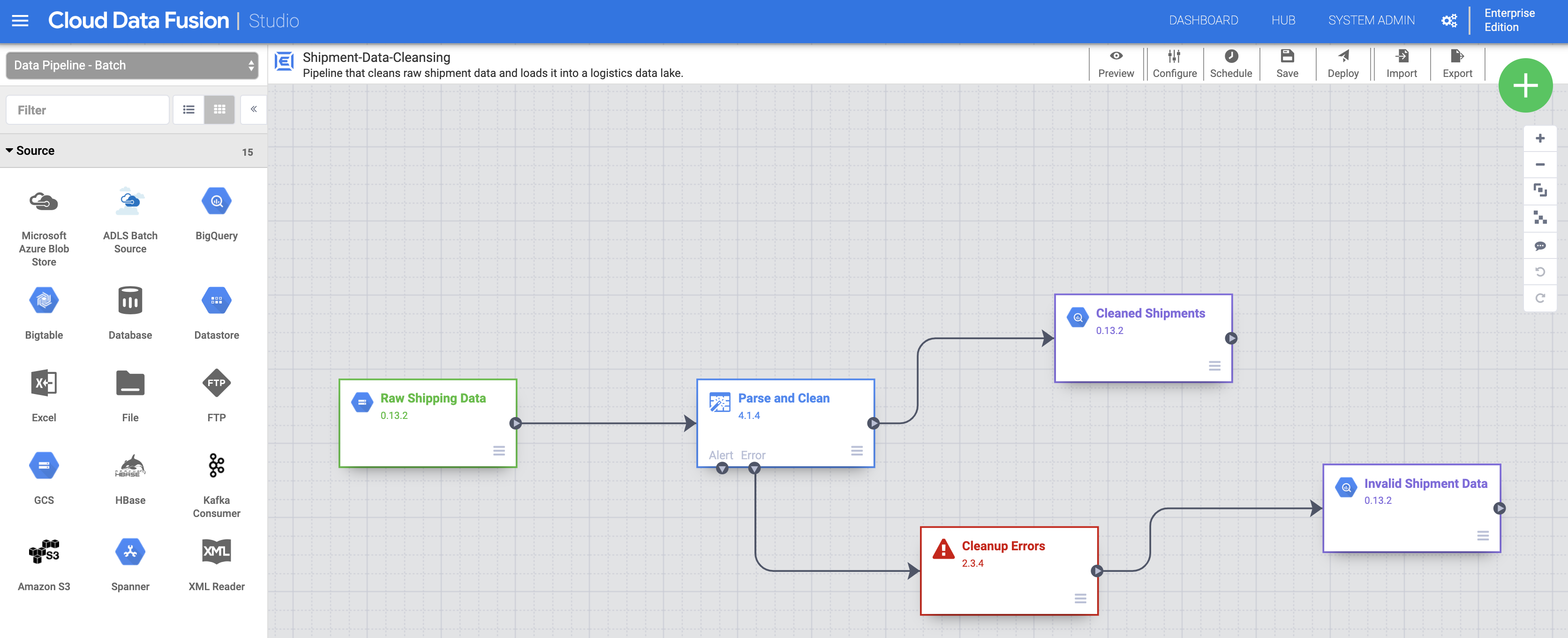
このラボでは、次の 2 つのパイプラインを使用します。
配送データ クレンジングと米国での遅延配送のリンクを使用して、これらのサンプル データセットをローカルマシンにダウンロードします。
次に、以下の手順に沿って、インスタンスに関連付けられているサービス アカウントに権限を付与します。
Google Cloud コンソールで、[IAM と管理] > [IAM] に移動します。
Compute Engine のデフォルトのサービス アカウント {プロジェクト番号}-compute@developer.gserviceaccount.com が表示されていることを確認し、サービス アカウントをクリップボードにコピーします。
[IAM 権限] ページで、[+アクセス権を付与] をクリックします。
[新しいプリンシパル] フィールドに、サービス アカウントを貼り付けます。
[ロールを選択] フィールドをクリックし、「Cloud Data Fusion API サービス エージェント」と入力します。最初の数文字を入力すると [Cloud Data Fusion API サービス エージェント] が表示されるので、それを選択します。
[別のロールを追加] をクリックします。
[Managed Service for Spark 管理者] ロールを追加します。
[保存] をクリックします。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
コンソールのナビゲーション メニューで、[IAM と管理] > [IAM] をクリックします。
[Google 提供のロール付与を含める] チェックボックスをオンにします。
リストを下にスクロールして、Google が管理する service-{project-number}@gcp-sa-datafusion.iam.gserviceaccount.com という表示形式の Cloud Data Fusion サービス アカウントを探し、サービス アカウント名をクリップボードにコピーします。
次に、[IAM と管理] > [サービス アカウント] に移動します。
{project-number}-compute@developer.gserviceaccount.com という表示形式のデフォルトの Compute Engine アカウントをクリックし、上部のナビゲーション メニューの [アクセス権を持つプリンシパル] タブを選択します。
[アクセスを許可] ボタンをクリックします。
[新しいプリンシパル] フィールドに、前の手順でコピーしたサービスアカウントを貼り付けます。
[ロール] プルダウン メニューで、[サービス アカウント ユーザー] を選択します。
[保存] をクリックします。
[Data Fusion] に移動し、[Instances] をクリックしてから、Data Fusion インスタンスの横にある [インスタンスを表示] リンクをクリックします。ラボの認証情報を選択してログインします。サービスのガイドに進むダイアログが表示された場合は [No, Thanks] をクリックします。これで Cloud Data Fusion UI が表示されるようになります。
左側のナビゲーション パネルから [Studio] をクリックして、Cloud Data Fusion Studio ページを開きます。
次に、パイプラインをデプロイします。[Studio] ページの右上にある [デプロイ] をクリックします。デプロイ後、[パイプライン] ページが開きます。
パイプライン ページの中央上部にある [実行] をクリックして、パイプラインを実行します。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
配送データ クレンジングのステータスが [Succeeded] になった後、先ほどダウンロードした米国での遅延配送データ パイプラインをインポートしてデプロイします。
左側のナビゲーション パネルから [Studio] をクリックして、Cloud Data Fusion Studio ページに戻ります。
[Studio] ページの右上にある [インポート] をクリックしてから、先ほどダウンロードした 米国での遅延配送データ パイプラインを選択してインポートします。
[Studio] ページの右上にある [デプロイ] をクリックして、パイプラインをデプロイします。デプロイ後、[パイプライン] ページが開きます。
[パイプライン] ページの中央上部にある [実行] をクリックしてパイプラインを実行します。
この 2 つ目のパイプラインが正常に完了すると、以下の手順を続行できます。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
リネージを調べる前に、データセットを確認する必要があります。
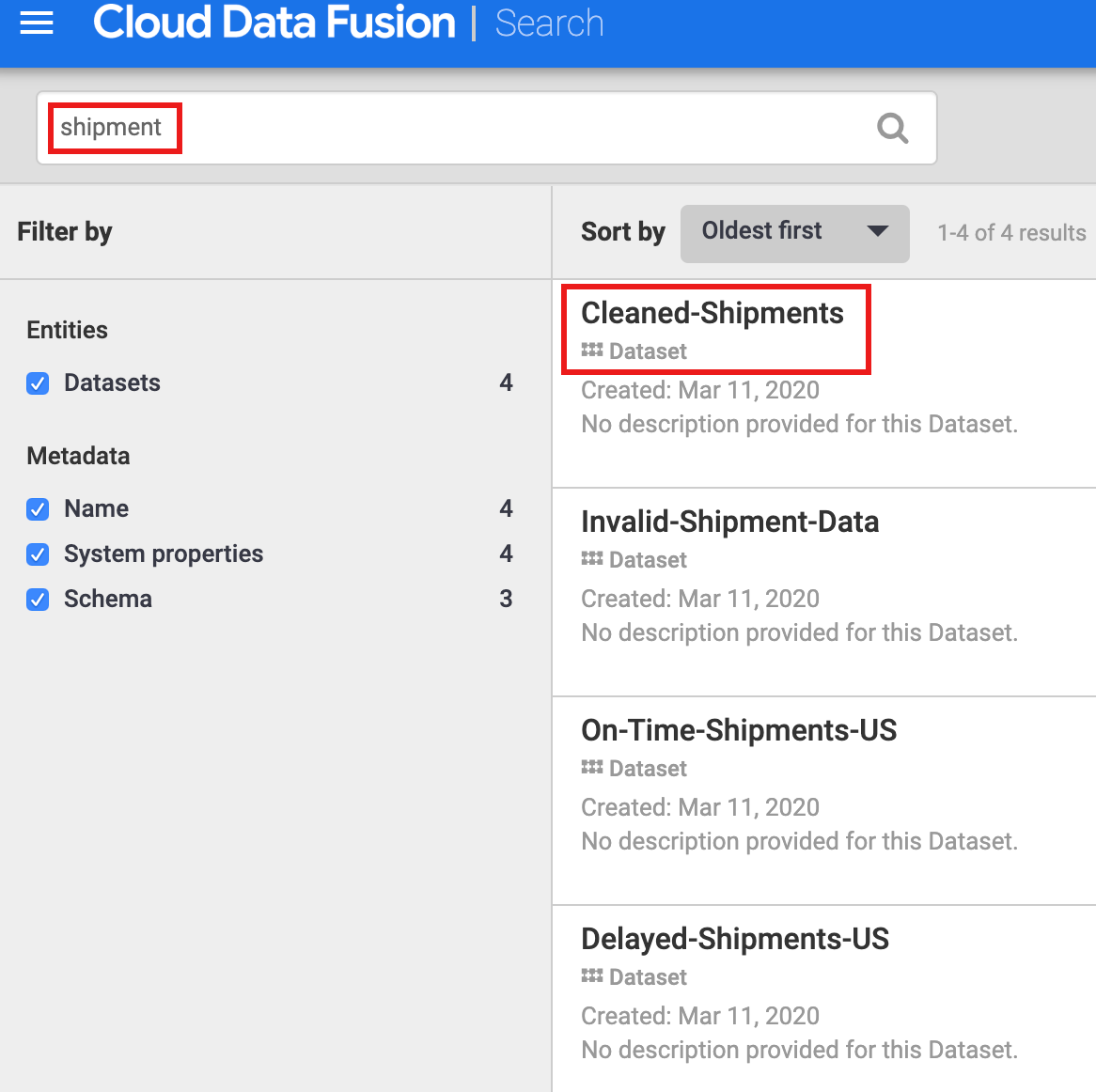
shipment」と入力します。検索結果にこのデータセットが含まれます。メタデータ検索では、Cloud Data Fusion パイプラインによって利用、処理、生成されたデータセットが検出されます。パイプラインは、テクニカル メタデータとオペレーション メタデータを生成して収集する構造化フレームワークで実行されます。テクニカル メタデータには、データセット名、タイプ、スキーマ、フィールド、作成時間、処理情報が含まれます。このテクニカル情報は、Cloud Data Fusion のメタデータ検索とリネージ機能で使用されます。
ソースとシンクの Reference Name は一意のデータセット識別子で優れた検索キーワードですが、検索条件としては他のテクニカル メタデータ(データセットの説明、スキーマ、フィールド名、メタデータ接頭辞など)を使用できます。
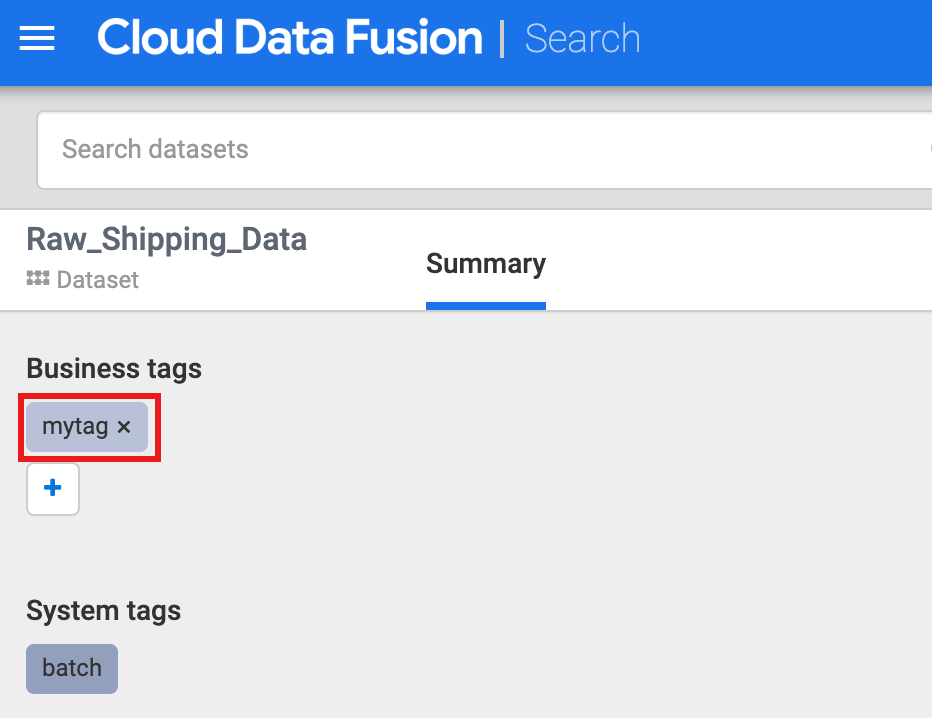
Cloud Data Fusion は、検索条件として使用できるタグや Key-Value プロパティなどのビジネス メタデータを含むデータセットのアノテーションもサポートしています。たとえば、未加工の配送データのデータセットにビジネスタグ アノテーションを追加して検索するには、次を行います。
Cloud Data Fusion UI の左側のナビゲーション パネルで [メタデータ] を選択して、メタデータの検索ページを開きます。
メタデータ オプションの検索ページで「Raw shipping data」と入力します。
[Raw_Shipping_Data] をクリックします。
[ビジネスタグ] で [+] をクリックし、タグ名(英数字とアンダースコアも使用可能)を入力して Enter キーを押します。
タグを検索するには、タグ名をクリックするか、[メタデータ] 検索ページの検索ボックスに「tags: tag_name」と入力します。
Cloud Data Fusion UI の左側のナビゲーション パネルから [メタデータ] を選択してメタデータの検索ページを開き、検索ボックスに「shipment」と入力します。
[検索] ページに表示されている [クリーンアップされた配送] のデータセット名をクリックします。
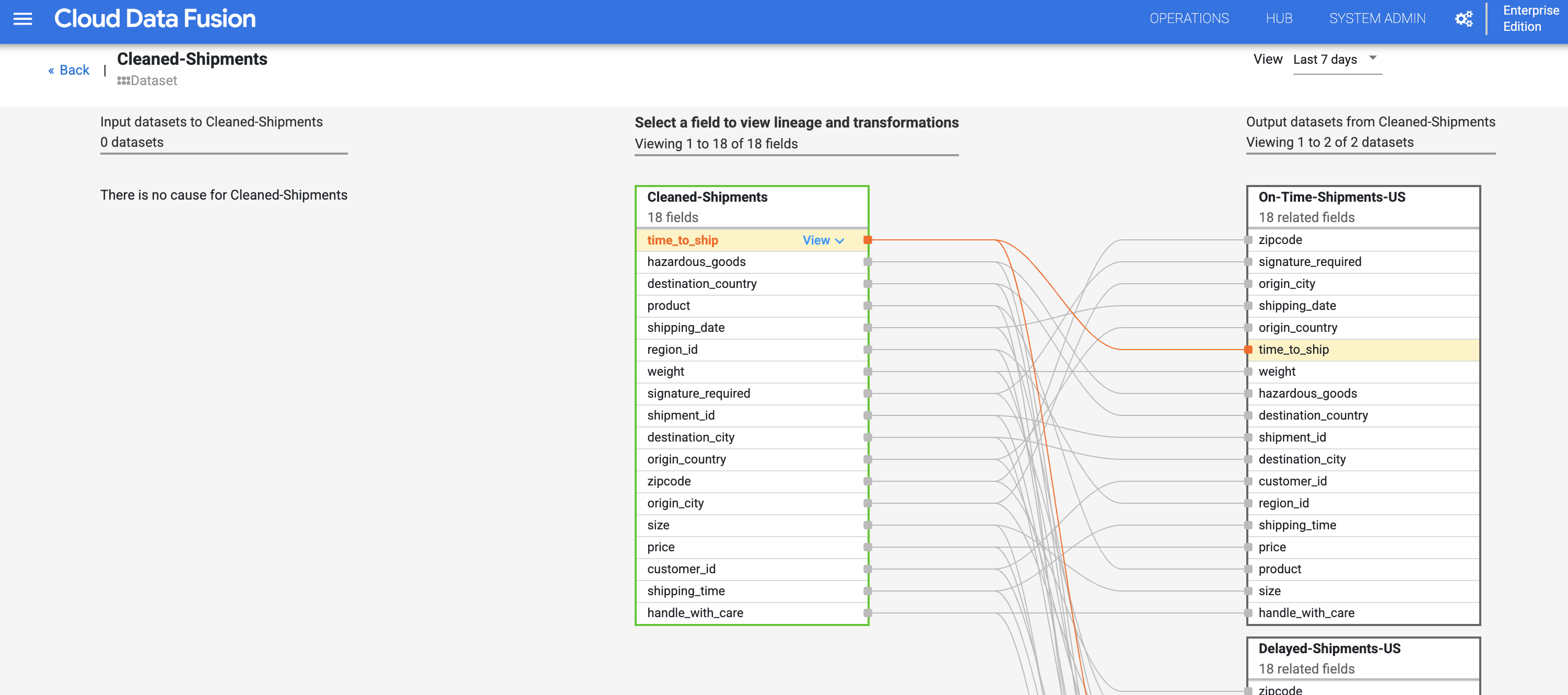
次に、[リネージ] タブをクリックします。リネージグラフで、このデータセットが、Raw_Shipping_Data データセットを使用した配送データ クレンジング パイプラインによって生成されたことが示されます。
Cloud Data Fusion のフィールド レベルのリネージは、データセットのフィールドと、フィールド セットに実行して別のフィールド セットを生成する変換との間の関係を示します。データセット レベルのリネージと同様に、フィールド レベルのリネージには時間の制約があり、結果は、時系列で変化します。
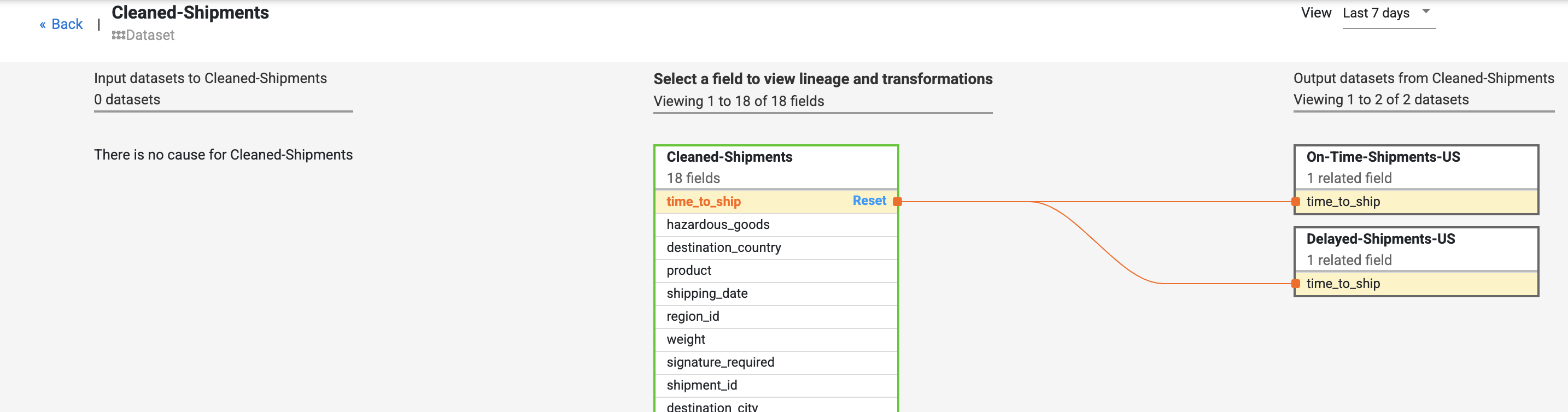
フィールドレベルのリネージは、このフィールドが時間の経過とともにどのように変換されたかを示します。time_to_ship フィールドの次の変化に注目してください。(i)float 型の列に変換する、(ii)値が次のノードか、下流のエラーパスにリダイレクトされるかを判断する。
リネージは、特定のフィールドが経てきた変更の履歴を示します。その他の例としては、複数のフィールドを連結して新しいフィールドを作成する(名と姓を組み合わせて名前を作成するなど)、フィールドに対して計算を行う(数値を合計数に対する割合に変換するなど)といったものがあります。
原因と影響を示すリンクでは、フィールドの両側で行われた変換が人間が読める台帳形式で表示されます。
このラボでは、データリネージを確認する方法を学びました。この情報は、レポートとガバナンスにおいて不可欠であることが考えられます。さまざまな受講者が、データが現在の状態になるまでの経緯を理解するのに役立ちます。
マニュアルの最終更新日: 2022 年 11 月 14 日
ラボの最終テスト日: 2023 年 8 月 8 日
Copyright 2026 Google LLC All rights reserved. Google および Google のロゴは、Google LLC の商標です。その他すべての社名および製品名は、それぞれ該当する企業の商標である可能性があります。



このコンテンツは現在ご利用いただけません
利用可能になりましたら、メールでお知らせいたします

ありがとうございます。
利用可能になりましたら、メールでご連絡いたします

1 回に 1 つのラボ
既存のラボをすべて終了して、このラボを開始することを確認してください
ラボを開始するには、この簡単な手順を完了してください。