GSP812

Descripción general
En este lab, se muestra cómo usar Cloud Data Fusion para explorar linajes de datos, es decir, los orígenes de los datos y sus movimientos a lo largo del tiempo.
El linaje de datos de Cloud Data Fusion te ayuda a realizar las siguientes tareas:
- Detectar la causa raíz de eventos de datos con errores
- Realizar un análisis de impacto antes de implementar cambios en los datos
Cloud Data Fusion proporciona linaje a nivel de los conjuntos de datos y de los campos, y tiene un límite de tiempo para mostrar el linaje a lo largo del tiempo.
-
El linaje a nivel de conjunto de datos muestra la relación entre los conjuntos de datos y las canalizaciones en un intervalo de tiempo seleccionado.
-
El linaje a nivel de campo muestra las operaciones que se realizaron en un conjunto de campos en el conjunto de datos de origen para producir un grupo diferente de campos en el conjunto de datos de destino.
Para los fines de este lab, usarás dos canalizaciones que demuestran una situación típica en la que se limpian datos sin procesar y, luego, se envían para el procesamiento downstream. Esta ruta de datos (desde datos sin procesar hasta datos de envío limpios y resultados de análisis) se puede explorar con la característica de linaje de Cloud Data Fusion.
Nota: Por el momento, la función de linaje de Cloud Data Fusion solo está disponible en la edición Enterprise del producto.
Objetivos
En este lab, explorarás cómo realizar las siguientes acciones:
- Ejecutar canalizaciones de muestra para producir linaje
- Explorar linajes a nivel de conjunto de datos y de campo
- Aprender a pasar información de protocolos de enlace de la canalización upstream a la downstream
Configuración y requisitos
En cada lab, recibirás un proyecto de Google Cloud y un conjunto de recursos nuevos por tiempo limitado y sin costo adicional.
-
Accede a Google Skills en una ventana de incógnito.
-
Ten en cuenta el tiempo de acceso del lab (por ejemplo, 02:00:00) y asegúrate de finalizarlo en el plazo asignado.
No existe una función de pausa. Si lo necesitas, puedes reiniciar el lab, pero deberás hacerlo desde el comienzo.
-
Cuando tengas todo listo, haz clic en Comenzar lab.
Nota: Después de que hagas clic en Comenzar lab, el lab tardará entre 15 y 20 minutos en aprovisionar los recursos necesarios y crear una instancia de Data Fusion.
Durante ese período, puedes leer los pasos que se indican a continuación para familiarizarte con los objetivos del lab.
Cuando veas las credenciales del lab (el nombre de usuario y la contraseña) en el panel del lado izquierdo, se habrá creado la instancia y podrás continuar para acceder a la consola.
-
Anota las credenciales del lab (el nombre de usuario y la contraseña). Las usarás para acceder a la consola de Google Cloud.
-
Haz clic en Abrir la consola de Google.
-
Haz clic en Usar otra cuenta, copia las credenciales para este lab y pégalas en el mensaje emergente que aparece.
Si usas otras credenciales, se generarán errores o incurrirás en cargos.
-
Acepta las condiciones y omite la página de recursos de recuperación.
Nota: No hagas clic en Finalizar lab, a menos que lo hayas terminado o quieras reiniciarlo. Esta acción borrará tu trabajo y quitará el proyecto.
Cómo iniciar tu lab y acceder a la consola de Google Cloud
-
Haz clic en el botón Comenzar lab. Si debes pagar por el lab, se abrirá un diálogo para que selecciones la forma de pago.
A la izquierda, se encuentra el panel Detalles del lab, que tiene estos elementos:
- El botón para abrir la consola de Google Cloud
- El tiempo restante
- Las credenciales temporales que debes usar para el lab
- Otra información para completar el lab, si es necesaria
-
Haz clic en Abrir la consola de Google Cloud (o haz clic con el botón derecho y selecciona Abrir el vínculo en una ventana de incógnito si ejecutas el navegador Chrome).
El lab inicia recursos y abre otra pestaña en la que se muestra la página de acceso.
Sugerencia: Ordena las pestañas en ventanas separadas, una junto a la otra.
Nota: Si ves el diálogo Elegir una cuenta, haz clic en Usar otra cuenta.
-
De ser necesario, copia el nombre de usuario a continuación y pégalo en el diálogo Acceder.
{{{user_0.username | "Username"}}}
También puedes encontrar el nombre de usuario en el panel Detalles del lab.
-
Haz clic en Siguiente.
-
Copia la contraseña que aparece a continuación y pégala en el diálogo Te damos la bienvenida.
{{{user_0.password | "Password"}}}
También puedes encontrar la contraseña en el panel Detalles del lab.
-
Haz clic en Siguiente.
Importante: Debes usar las credenciales que te proporciona el lab. No uses las credenciales de tu cuenta de Google Cloud.
Nota: Usar tu propia cuenta de Google Cloud para este lab podría generar cargos adicionales.
-
Haz clic para avanzar por las páginas siguientes:
- Acepta los Términos y Condiciones.
- No agregues opciones de recuperación o autenticación de dos factores (esta es una cuenta temporal).
- No te registres para obtener pruebas gratuitas.
Después de un momento, se abrirá la consola de Google Cloud en esta pestaña.
Nota: Para acceder a los productos y servicios de Google Cloud, haz clic en el menú de navegación o escribe el nombre del servicio o producto en el campo Buscar.

Active Cloud Shell
Cloud Shell es una máquina virtual que contiene herramientas de desarrollo y un directorio principal persistente de 5 GB. Se ejecuta en Google Cloud. Cloud Shell proporciona acceso de línea de comandos a sus recursos de Google Cloud. gcloud es la herramienta de línea de comandos de Google Cloud, la cual está preinstalada en Cloud Shell y es compatible con la función de autocompletado con tabulador.
-
En el panel de navegación de Google Cloud Console, haga clic en Activar Cloud Shell ( ).
).
-
Haga clic en Continuar.
El aprovisionamiento y la conexión al entorno tardan solo unos momentos. Una vez que se conecte, también estará autenticado, y el proyecto estará configurado con su PROJECT_ID. Por ejemplo:

Comandos de muestra
gcloud auth list
(Resultado)
Credentialed accounts:
- <myaccount>@<mydomain>.com (active)
(Resultado de ejemplo)
Credentialed accounts:
- google1623327_student@qwiklabs.net
gcloud config list project
(Resultado)
[core]
project = <project_ID>
(Resultado de ejemplo)
[core]
project = qwiklabs-gcp-44776a13dea667a6
Verifica los permisos del proyecto
Antes de comenzar a trabajar en Google Cloud, asegúrate de que tu proyecto tenga los permisos correctos en Identity and Access Management (IAM).
-
En el Menú de navegación ( ) de la consola de Google Cloud, haga clic en IAM y administración > IAM.
) de la consola de Google Cloud, haga clic en IAM y administración > IAM.
-
Confirma que aparezca la cuenta de servicio predeterminada de Compute {project-number}-compute@developer.gserviceaccount.com, y que tenga asignado el rol Editor. El prefijo de la cuenta es el número del proyecto, que puedes encontrar en el menú de navegación > Descripción general de Cloud.

Si no aparece la cuenta en IAM o no tiene asignado el rol Editor, sigue los pasos que se indican a continuación para asignar el rol necesario.
-
En la consola de Google Cloud, en el menú de navegación, haz clic en Descripción general de Cloud.
-
En la tarjeta Información del proyecto, copia el Número de proyecto.
-
En el menú de navegación, haz clic en IAM y administración > IAM.
-
En la parte superior de la página IAM, haga clic en Agregar.
-
En Principales nuevas, escriba lo siguiente:
{número-del-proyecto}-compute@developer.gserviceaccount.com
Reemplaza {project-number} por el número de tu proyecto.
-
En Seleccionar un rol, elige Básico (o Proyecto) > Editor.
-
Haz clic en Guardar.
Requisitos previos
En este lab, trabajarás con dos canalizaciones:
-
Shipment Data Cleansing, que lee los datos de envío sin procesar de un pequeño conjunto de datos de muestra y aplica transformaciones para limpiar los datos.
-
Delayed Shipments USA, que lee los datos de envío limpios, los analiza y busca los envíos dentro de EE.UU. que se retrasaron más de una vez.
Usa los vínculos Shipment Data Cleansing y Delayed Shipments USA para descargar los conjuntos de datos de muestra en tu máquina local.
Tarea 1: Agrega los permisos necesarios para tu instancia de Cloud Data Fusion
- En la barra de título de la consola de Google Cloud, escribe Data Fusion en el campo Buscar y, luego, haz clic en Data Fusion en los resultados de la búsqueda. Haz clic en Instancias.
Nota: La creación de la instancia tardará alrededor de 20 minutos. Espera a que esté lista.
Luego, otorgarás permisos a la cuenta de servicio asociada con la instancia siguiendo estos pasos:
-
En la consola de Google Cloud, navega a IAM y administración > IAM.
-
Verifica que la cuenta de servicio predeterminada de Compute Engine, {project-number}-compute@developer.gserviceaccount.com, esté presente y, luego, copia la Cuenta de servicio en tu portapapeles.
-
En la página Permisos de IAM, haz clic en +Otorgar acceso.
-
En el campo Entidades nuevas, pega la cuenta de servicio.
-
Haz clic en el campo Seleccionar un rol, escribe Agente de servicio de la API de Cloud Data Fusion y selecciónalo.
-
Haz clic en AGREGAR OTRO ROL.
-
Agrega el rol Administrador de Managed Service for Spark.
-
Haz clic en Guardar.
Haz clic en Revisar mi progreso para verificar el objetivo.
Agregar el rol Agente de servicio de la API de Cloud Data Fusion a la cuenta de servicio
Otorga permiso de usuario a la cuenta de servicio
-
En la consola, ve a Menú de navegación y haz clic en IAM y administración > IAM.
-
Selecciona la casilla de verificación Incluir asignaciones de roles proporcionadas por Google.
-
Desplázate hacia abajo en la lista hasta encontrar la cuenta de servicio de Cloud Data Fusion administrada por Google que tiene el formato service-{project-number}@gcp-sa-datafusion.iam.gserviceaccount.com. Luego, copia el nombre de la cuenta en el portapapeles.

-
Después, navega a IAM y administración > Cuentas de servicio.
-
Haz clic en la cuenta predeterminada de Compute Engine que tiene el formato {project-number}-compute@developer.gserviceaccount.com y selecciona la pestaña Principales con acceso en la barra de navegación superior.
-
Haz clic en el botón Otorgar acceso.
-
En el campo Principales nuevas, pega la cuenta de servicio que copiaste antes.
-
En el menú desplegable Rol, selecciona Usuario de cuenta de servicio.
-
Haz clic en Guardar.
Tarea 2: Abre la IU de Cloud Data Fusion
-
Navega a Data Fusion, haz clic en Instancias y, luego, haz clic en el vínculo Ver instancia junto a tu instancia de Data Fusion. Selecciona las credenciales del lab para acceder. Si se te solicita hacer una visita guiada por el servicio, haz clic en No, gracias. Ahora deberías estar en la IU de Cloud Data Fusion.
-
Haz clic en Studio en el panel de navegación izquierdo para abrir la página Studio de Cloud Data Fusion.
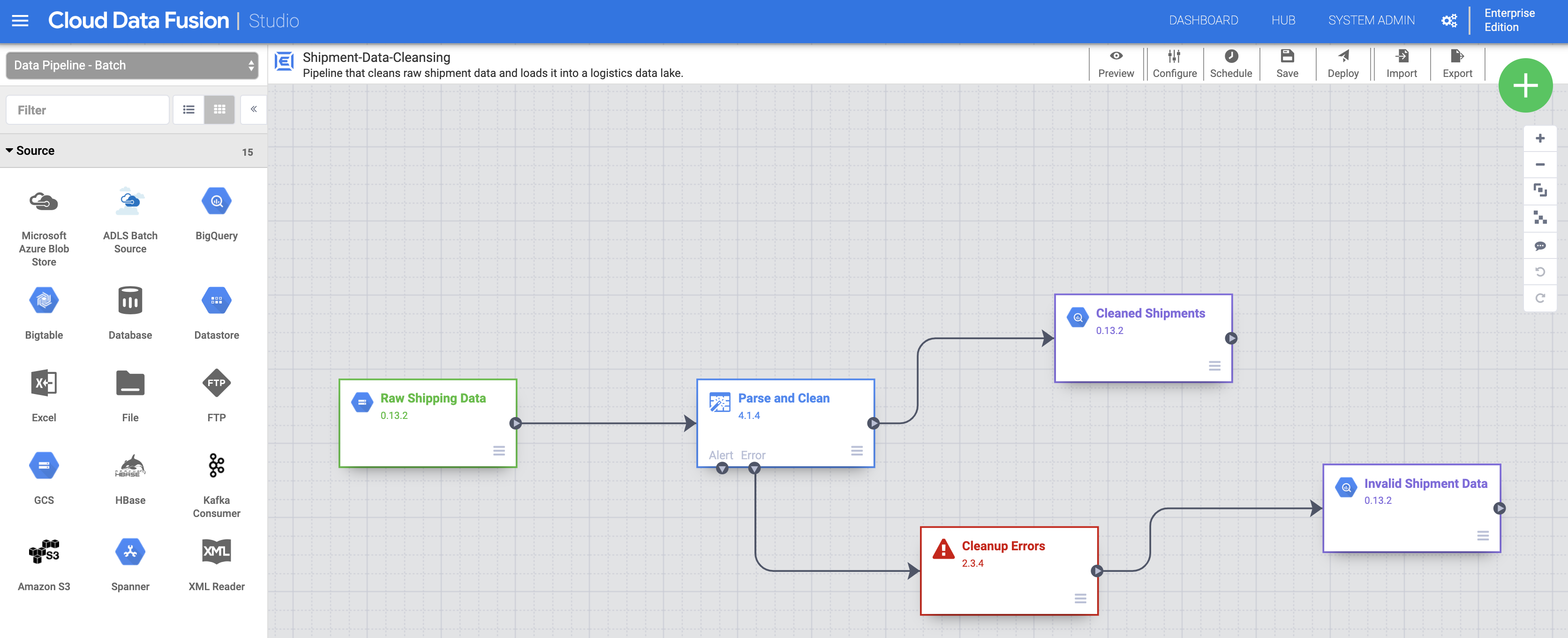
Tarea 3: Importa, implementa y ejecuta la canalización de limpieza de datos de envíos
- A continuación, importarás los datos de envío sin procesar. Haz clic en Importar en la parte superior derecha de la página de Studio y, luego, selecciona e importa la canalización Shipment Data Cleansing que descargaste anteriormente.
Nota: Si en una ventana emergente se te solicita actualizar los complementos de la canalización, haz clic en Corregir todo para actualizar los complementos a las versiones más recientes.
-
Ahora, implementa la canalización. Haz clic en Implementar en la parte superior derecha de la página Studio. Después de la implementación, se abrirá la página Canalización.
-
Haz clic en Ejecutar en la parte superior central de la página Canalización para ejecutar la tarea.
Nota: Si la canalización falla, vuelve a ejecutarla.
Haz clic en Revisar mi progreso para verificar el objetivo.
Importar, implementar y ejecutar la canalización de limpieza de datos de envío
Tarea 4: Importa, implementa y ejecuta los datos y la canalización de envíos retrasados.
Después de que el estado de limpieza de datos de envío muestre el estado Correcto, importarás e implementarás la canalización de datos Delayed Shipments USA que descargaste anteriormente.
-
Haz clic en Studio en el panel de navegación izquierdo para volver a la página de Studio en Cloud Data Fusion.
-
Haz clic en Importar en la parte superior derecha de la página de Studio y, luego, selecciona e importa la canalización de datos Delayed Shipments USA que descargaste anteriormente.
Nota:
Si en una ventana emergente se te solicita actualizar los complementos de la canalización, haz clic en Corregir todo para actualizar los complementos a las versiones más recientes.
-
Implementa la canalización haciendo clic en Implementar en la parte superior derecha de la página Studio. Después de la implementación, se abrirá la página Canalización.
-
En la parte superior central de la página Canalización, haz clic en Ejecutar para ejecutar la canalización.
Nota: Si la canalización falla, vuelve a ejecutarla.
Después de que esta segunda canalización se complete de forma correcta, puedes seguir los pasos restantes que se indican a continuación.
Haz clic en Revisar mi progreso para verificar el objetivo.
Importar, implementar y ejecutar los datos y la canalización de envíos retrasados
Tarea 5: Descubre algunos conjuntos de datos
Debes descubrir un conjunto de datos antes de explorar su linaje.
- Selecciona Metadatos en el panel de navegación izquierdo de la IU de Cloud Data Fusion para abrir la página de búsqueda de metadatos.
- Dado que el conjunto de datos Shipment Data Cleansing especificó "Cleaned-Shipments" como el conjunto de datos de referencia, ingresa
shipment en el cuadro de búsqueda. Los resultados de la búsqueda incluyen este conjunto de datos.
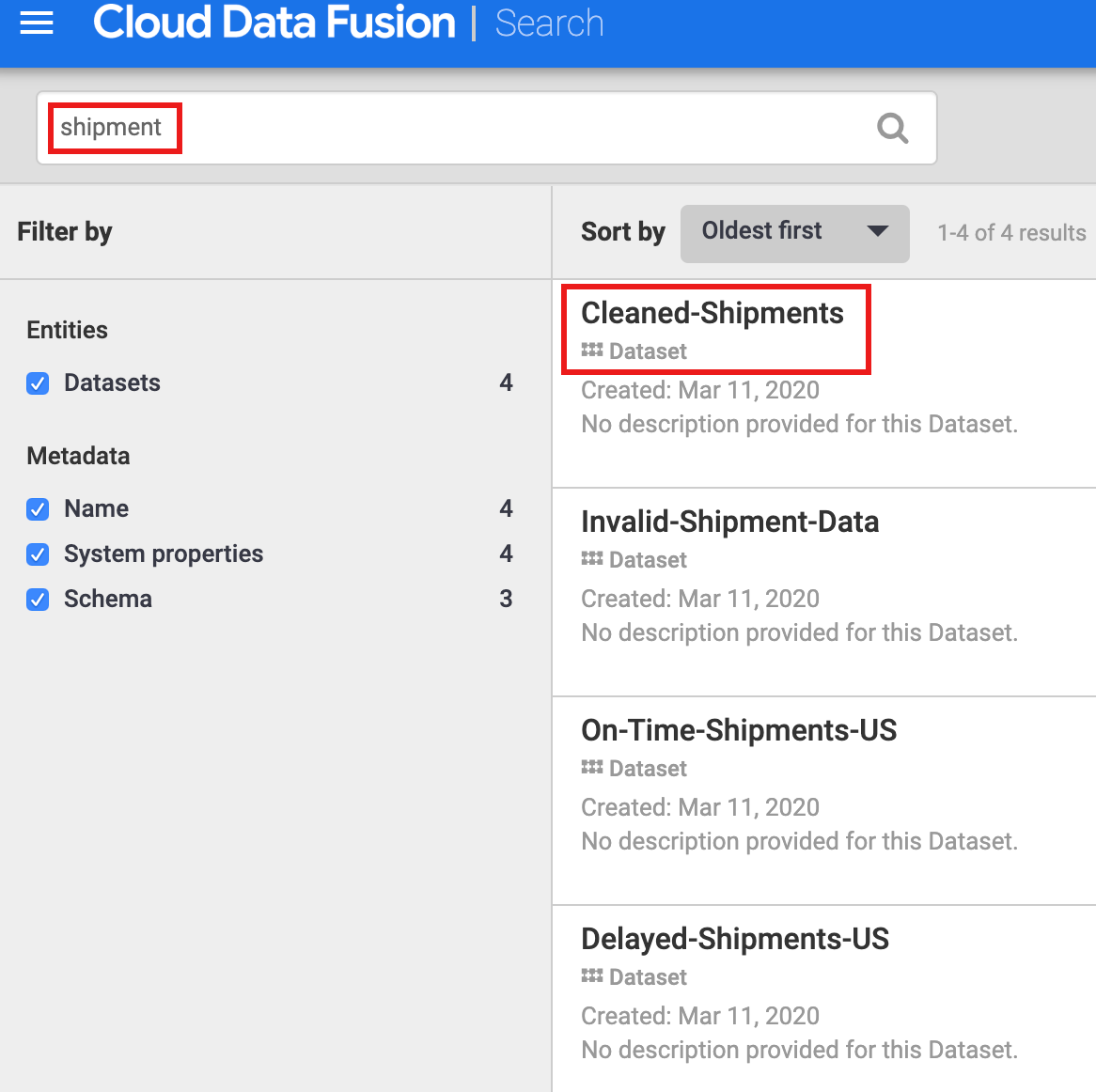
Tarea 6: Usa etiquetas para descubrir conjuntos de datos
Las búsquedas de metadatos descubren conjuntos de datos que se usaron, procesaron o generaron a través de las canalizaciones de Cloud Data Fusion. Las canalizaciones se ejecutan en un framework estructurado que genera y recopila metadatos técnicos y operativos. Los metadatos técnicos incluyen el nombre del conjunto de datos, el tipo, el esquema, los campos, la fecha de creación y la información de procesamiento. La información técnica y el linaje de los metadatos de Cloud Data Fusion usan esta información técnica.
Aunque el nombre de la referencia de las fuentes y los receptores es un identificador único de conjunto de datos y un excelente término de búsqueda, puedes usar otros metadatos técnicos como criterios de búsqueda, como la descripción del conjunto de datos, un esquema o un nombre de campo o el prefijo de metadatos.
Cloud Data Fusion también admite la anotación de conjuntos de datos con metadatos empresariales, como etiquetas y propiedades de pares clave-valor, que se pueden usar como criterios de búsqueda. Por ejemplo, para agregar y buscar una anotación de etiqueta de la empresa en el conjunto de datos de envío sin procesar, haz lo siguiente:
-
Selecciona Metadatos en el panel de navegación izquierdo de la IU de Cloud Data Fusion para abrir la página de búsqueda de metadatos.
-
Ingresa Raw shipping data en la página de búsqueda de la opción de metadatos.
-
Haz clic en Raw_Shipping_Data.
-
En Etiquetas comerciales, haz clic en +, inserta el nombre de una etiqueta (se permiten los caracteres alfanuméricos y los guiones bajos) y, luego, presiona Intro.
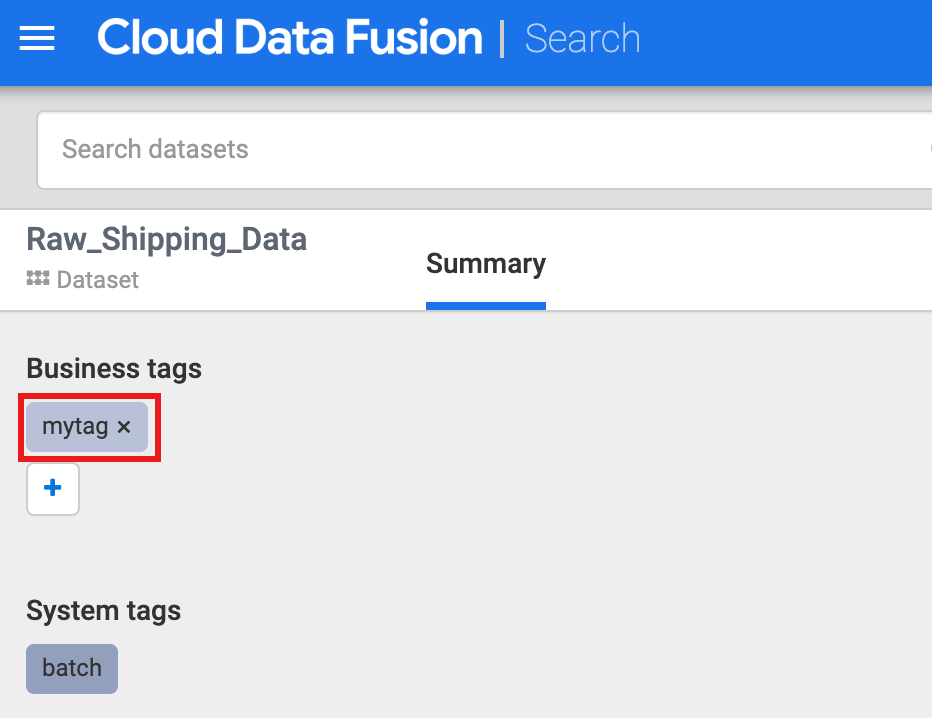
Para realizar una búsqueda en una etiqueta, haz clic en el nombre de la etiqueta o ingresa las etiquetas nombre_de_la_etiqueta en el cuadro de búsqueda de la página de búsqueda de Metadatos.
Tarea 7: Explora el linaje de datos
Linaje a nivel de conjunto de datos
-
Selecciona Metadatos en el panel de navegación izquierdo de la IU de Cloud Data Fusion para abrir la página de búsqueda de metadatos y, luego, ingresa shipment en el cuadro de búsqueda.
-
Haz clic en el nombre del conjunto de datos Cleaned-Shipments que aparece en la página de búsqueda.
-
Luego, haz clic en la pestaña Linaje. El gráfico de linaje muestra que este conjunto de datos lo generó la canalización Shipments-Data-Cleansing, que consumió el conjunto de datos Raw_Shipping_Data.
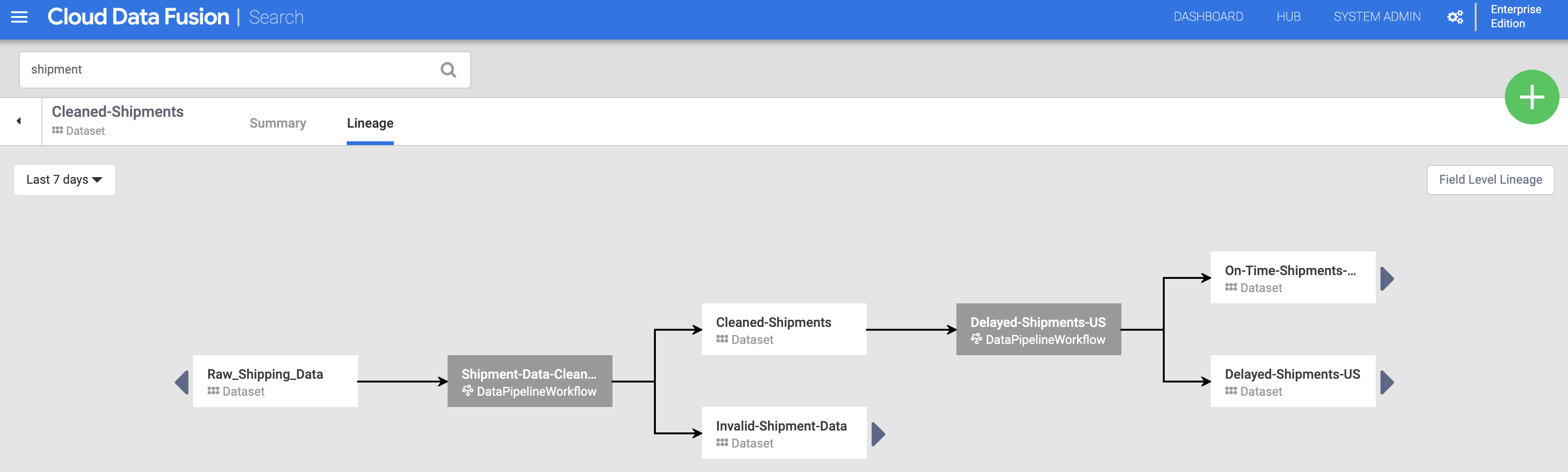
Linaje a nivel de campo
El linaje a nivel de campo en Cloud Data Fusion muestra la relación entre los campos de un conjunto de datos y las transformaciones que se realizaron en un conjunto de campos para producir un conjunto de campos diferente. Al igual que el linaje a nivel de conjunto de datos, el linaje a nivel de campo está restringido, y sus resultados cambian a lo largo del tiempo.
- Para continuar con el paso de linaje a nivel de conjunto de datos, haz clic en el botón Linaje a nivel de campo en la parte superior derecha del gráfico de linaje a nivel de conjunto de datos Cleaned Shipments para mostrar su gráfico de linaje a nivel de campo.
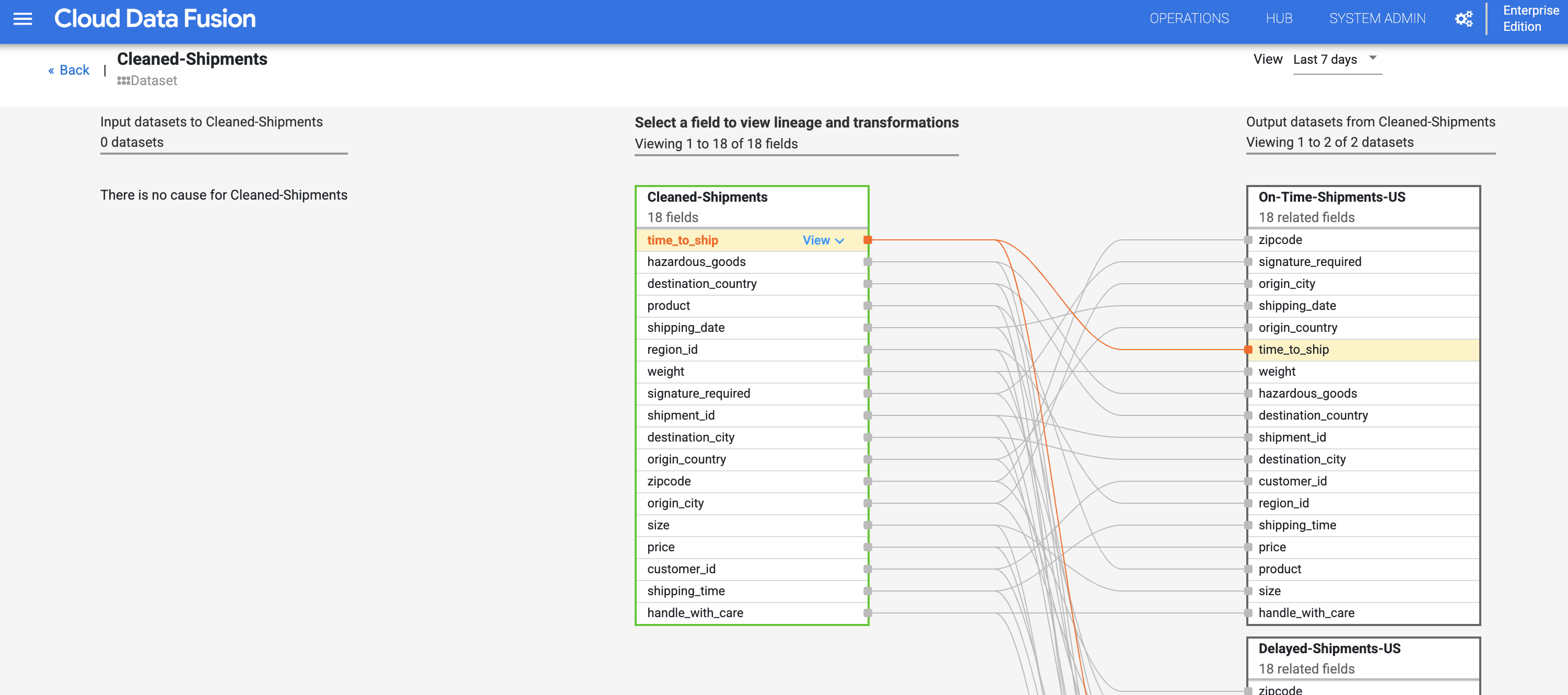
- El gráfico de linaje a nivel de campo muestra las conexiones entre campos. Puedes seleccionar un campo para ver su linaje. Selecciona Ver y, luego, Fijar campo para ver solo el linaje de ese campo.
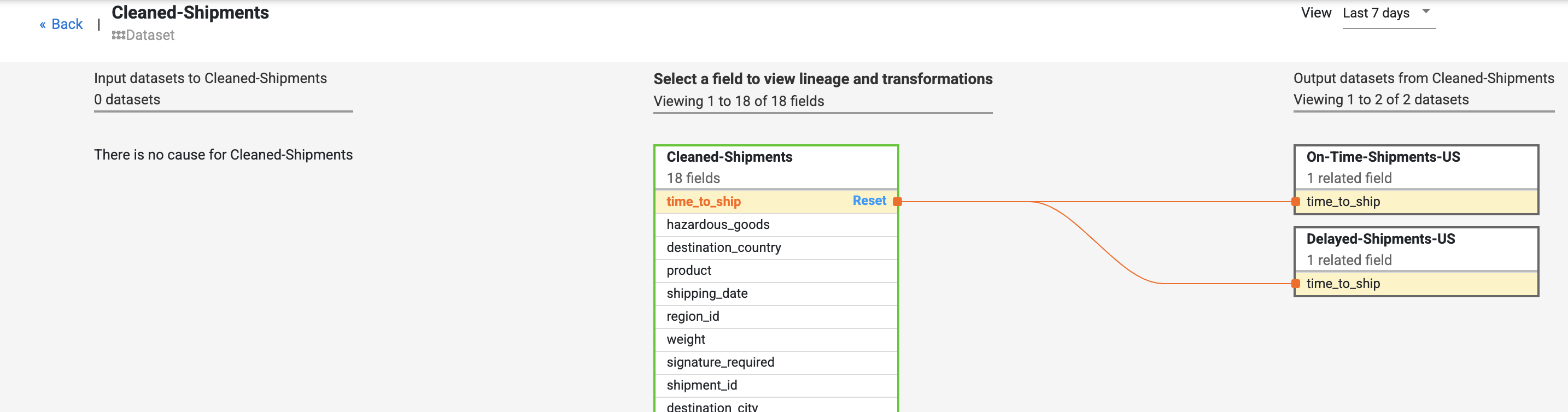
- Busca el campo time_to_ship en el conjunto de datos Cleaned-Shipments, selecciona Ver y, luego, Ver impacto para realizar un análisis de impacto.

El linaje a nivel de campo muestra cómo se transformó este campo a lo largo del tiempo. Observa las transformaciones del campo time_to_ship: (i) convertirlo en una columna de tipo float y (ii) determinar si el valor se redirecciona al siguiente nodo o a la ruta de error.
El linaje visibiliza el historial de cambios que experimentó el campo específico. Otros ejemplos incluyen la concatenación de algunos campos para redactar un nuevo campo (como nombre y apellido, que se combinaron para producir nombre) o cálculos realizados en un campo (como convertir un número en un porcentaje en relación con el recuento total).
Los vínculos de impacto y causa muestran las transformaciones realizadas en ambos lados de un campo en un formato de registro legible por humanos.
¡Felicitaciones!
En este lab, aprendiste a explorar el linaje de tus datos. Esta información puede ser fundamental para la generación de informes y la administración. Diferentes públicos pueden aprovecharla para comprender cómo los datos llegaron a su estado actual.
Actualización más reciente del manual: 14 de noviembre de 2022
Prueba más reciente del lab: 8 de agosto de 2023
Copyright 2026 Google LLC. Todos los derechos reservados. Google y el logotipo de Google son marcas de Google LLC. El resto de los nombres de productos y empresas pueden ser marcas de las respectivas empresas a las que están asociados.





