


![[トピックを作成] ボタン](https://cdn.qwiklabs.com/E%2BgOduwA482MERz41Fr7Eht3LSTahD0ynuQK%2FIAxM5c%3D)
![[サブスクリプションを作成] リンク](https://cdn.qwiklabs.com/BYtMx%2F9FsoYlBXHH29xEwu%2F9cBoWBC7NEwPEGfKAUQ4%3D)
![[サブスクリプションをトピックに追加] ページ](https://cdn.qwiklabs.com/EhpuuSkA35uSsuj27qo%2Bcrt8aUhZ7ETHg88GwIxJbkM%3D)

![[インスタンスを表示] リンク](https://cdn.qwiklabs.com/VEcWYtUEKcc3zx9JzLcTxIp0lFLAtLyOVuzHuJuR4sg%3D)
![Wrangler の [Upload data from your computer] ページ](https://cdn.qwiklabs.com/mOgWqniREaCYyKiVl5RyhDL1DGAwyljV%2BOBC4VmuSBg%3D)
![[JSON] オプションへのナビゲーション パス。](https://cdn.qwiklabs.com/UE3%2B3vm4FCrhgZ5qiMQffHtyxhO1%2BkIQhDPeRYwDK50%3D)

![[テンプレートからジョブを作成] ダイアログ](https://cdn.qwiklabs.com/7AaOXHfwXlkTxmatZ9BjEA%2F%2Bh5y8ko0LADQby4SvZkw%3D)


始める前に
- ラボでは、Google Cloud プロジェクトとリソースを一定の時間利用します
- ラボには時間制限があり、一時停止機能はありません。ラボを終了した場合は、最初からやり直す必要があります。
- 画面左上の [ラボを開始] をクリックして開始します
Load the data
/ 20
Setting up Pub/Sub Topic
/ 20
Add a Pub/Sub subscription
/ 20
Add Cloud Data Fusion API Service Agent role to service account
/ 20
Build and execute runtime pipeline
/ 20
Load the data
/ 20
Setting up Pub/Sub Topic
/ 20
Add a Pub/Sub subscription
/ 20
Add Cloud Data Fusion API Service Agent role to service account
/ 20
Build and execute runtime pipeline
/ 20
Data Fusion では、バッチ パイプラインに加えて、生成されたイベントをリアルタイムで処理するパイプラインも作成できます。現在、リアルタイム パイプラインは、Cloud Managed Service for Spark クラスタで Apache Spark Streaming を使用して実行されます。このラボでは、Data Fusion を使用してストリーミング パイプラインを構築する方法を学びます。
Cloud Pub/Sub のトピックからデータを読み取って、イベントを処理、変換し、その結果を BigQuery に書き込むパイプラインを作成します。
各ラボでは、新しい Google Cloud プロジェクトとリソースセットを一定時間無料で利用できます。
シークレット ウィンドウを使用して Google Skills にログインします。
ラボのアクセス時間(例: 02:00:00)に注意し、時間内に完了できるようにしてください。
一時停止機能はありません。必要な場合はやり直せますが、最初からになります。
準備ができたら、[ラボを開始] をクリックします。
ラボの認証情報(ユーザー名とパスワード)をメモしておきます。この情報は、Google Cloud コンソールにログインする際に使用します。
[Google Console を開く] をクリックします。
[別のアカウントを使用] をクリックし、このラボの認証情報をコピーしてプロンプトに貼り付けます。
他の認証情報を使用すると、エラーが発生したり、料金の請求が発生したりします。
利用規約に同意し、再設定用のリソースページをスキップします。
[ラボを開始] ボタンをクリックします。ラボの料金をお支払いいただく必要がある場合は、表示されるダイアログでお支払い方法を選択してください。 左側の [ラボの詳細] ペインには、以下が表示されます。
[Google Cloud コンソールを開く] をクリックします(Chrome ブラウザを使用している場合は、右クリックして [シークレット ウィンドウで開く] を選択します)。
ラボでリソースがスピンアップし、別のタブで [ログイン] ページが表示されます。
ヒント: タブをそれぞれ別のウィンドウで開き、並べて表示しておきましょう。
必要に応じて、下のユーザー名をコピーして、[ログイン] ダイアログに貼り付けます。
[ラボの詳細] ペインでもユーザー名を確認できます。
[次へ] をクリックします。
以下のパスワードをコピーして、[ようこそ] ダイアログに貼り付けます。
[ラボの詳細] ペインでもパスワードを確認できます。
[次へ] をクリックします。
その後次のように進みます。
その後、このタブで Google Cloud コンソールが開きます。

Cloud Shell は、開発ツールが組み込まれた仮想マシンです。5 GB の永続ホーム ディレクトリを提供し、Google Cloud 上で実行されます。Cloud Shell を使用すると、コマンドラインで Google Cloud リソースにアクセスできます。gcloud は Google Cloud のコマンドライン ツールで、Cloud Shell にプリインストールされており、Tab キーによる入力補完がサポートされています。
Google Cloud Console のナビゲーション パネルで、「Cloud Shell をアクティブにする」アイコン(
[次へ] をクリックします。
環境がプロビジョニングされ、接続されるまでしばらく待ちます。接続の際に認証も行われ、プロジェクトは現在のプロジェクト ID に設定されます。次に例を示します。
有効なアカウント名前を一覧表示する:
(出力)
(出力例)
プロジェクト ID を一覧表示する:
(出力)
(出力例)
Google Cloud で作業を開始する前に、Identity and Access Management(IAM)内で適切な権限がプロジェクトに付与されていることを確認する必要があります。
Google Cloud コンソールのナビゲーション メニュー(
Compute Engine のデフォルトのサービス アカウント {project-number}-compute@developer.gserviceaccount.com が存在し、編集者のロールが割り当てられていることを確認します。アカウントの接頭辞はプロジェクト番号で、ナビゲーション メニュー > [Cloud の概要] から確認できます。
アカウントが IAM に存在しない場合やアカウントに編集者のロールがない場合は、以下の手順に沿って必要なロールを割り当てます。
Google Cloud コンソールのナビゲーション メニューで、[Cloud の概要] をクリックします。
[プロジェクト情報] カードからプロジェクト番号をコピーします。
ナビゲーション メニューで、[IAM と管理] > [IAM] をクリックします。
IAM ページの上部にある [追加] をクリックします。
新しいプリンシパルの場合は、次のように入力します。
{project-number} はプロジェクト番号に置き換えてください。
[ロールを選択] で、[基本](または [Project])> [編集者] を選択します。
[保存] をクリックします。
必要な API にアクセスできることを確認するには、Dataflow API への接続をリセットします。
Cloud コンソールの上部の検索バーに「Dataflow API」と入力します。検索結果の「Dataflow API」をクリックします。
[管理] をクリックします。
[API を無効にする] をクリックします。
確認を求められたら、[無効にする] をクリックします。
また、同じサンプル ツイート ファイルを Cloud Storage バケットにステージングする必要があります。このラボの最後では、バケットから Pub/Sub トピックにデータをストリーミングします。
作成されたバケットの名前は、現在のプロジェクト ID です。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
Pub/Sub を使用するには、データを保持するトピックを作成し、そのトピックにパブリッシュされたデータにアクセスするためのサブスクリプションを作成します。
Cloud コンソールで、ナビゲーション メニューから [すべてのプロダクトを表示] をクリックし、[分析] セクションで [Pub/Sub] をクリックして、[トピック] を選択します。
[トピックを作成] をクリックします。
cdf_lab_topic という名前を付け、[作成] をクリックします。[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
引き続きトピック ページで作業し、トピックにアクセスするためのサブスクリプションを作成します。
cdf_lab_subscription など)を入力し、[配信タイプ] を [Pull] に設定して、[作成] をクリックします。[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
次に、以下の手順に沿って、インスタンスに関連付けられているサービス アカウントに権限を付与します。
Google Cloud コンソールで、[IAM と管理] > [IAM] に移動します。
Compute Engine のデフォルトのサービス アカウント {プロジェクト番号}-compute@developer.gserviceaccount.com が表示されていることを確認し、サービス アカウントをクリップボードにコピーします。
[IAM 権限] ページで、[+アクセスを許可] をクリックします。
[新しいプリンシパル] フィールドに、サービス アカウントを貼り付けます。
[ロールを選択] フィールドをクリックし、「Cloud Data Fusion API サービス エージェント」と入力します。最初の数文字を入力すると [Cloud Data Fusion API サービス エージェント] が表示されるので、それを選択します。
[別のロールを追加] をクリックします。
[Managed Service for Spark 管理者] ロールを追加します。
[保存] をクリックします。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
コンソールのナビゲーション メニューで、[IAM と管理] > [IAM] をクリックします。
[Google 提供のロール付与を含める] チェックボックスをオンにします。
リストを下にスクロールして、Google が管理する service-{project-number}@gcp-sa-datafusion.iam.gserviceaccount.com という表示形式の Cloud Data Fusion サービス アカウントを探し、サービス アカウント名をクリップボードにコピーします。
次に、[IAM と管理] > [サービス アカウント] に移動します。
{project-number}-compute@developer.gserviceaccount.com という表示形式のデフォルトの Compute Engine アカウントをクリックし、上部のナビゲーション メニューの [アクセス権を持つプリンシパル] タブを選択します。
[アクセスを許可] ボタンをクリックします。
[新しいプリンシパル] フィールドに、前の手順でコピーしたサービスアカウントを貼り付けます。
[ロール] プルダウン メニューで、[サービス アカウント ユーザー] を選択します。
[保存] をクリックします。
Cloud Data Fusion を使用する際は、Cloud Console と個別の Cloud Data Fusion UI の両方を使用します。Cloud Console では、Cloud Console プロジェクトの作成や Cloud Data Fusion インスタンスの作成、削除を行えます。Cloud Data Fusion UI では、[Pipeline Studio] や [Wrangler] などのさまざまなページで Cloud Data Fusion の機能を使用できます。
Cloud Data Fusion UI を操作するには、次の手順に従います。
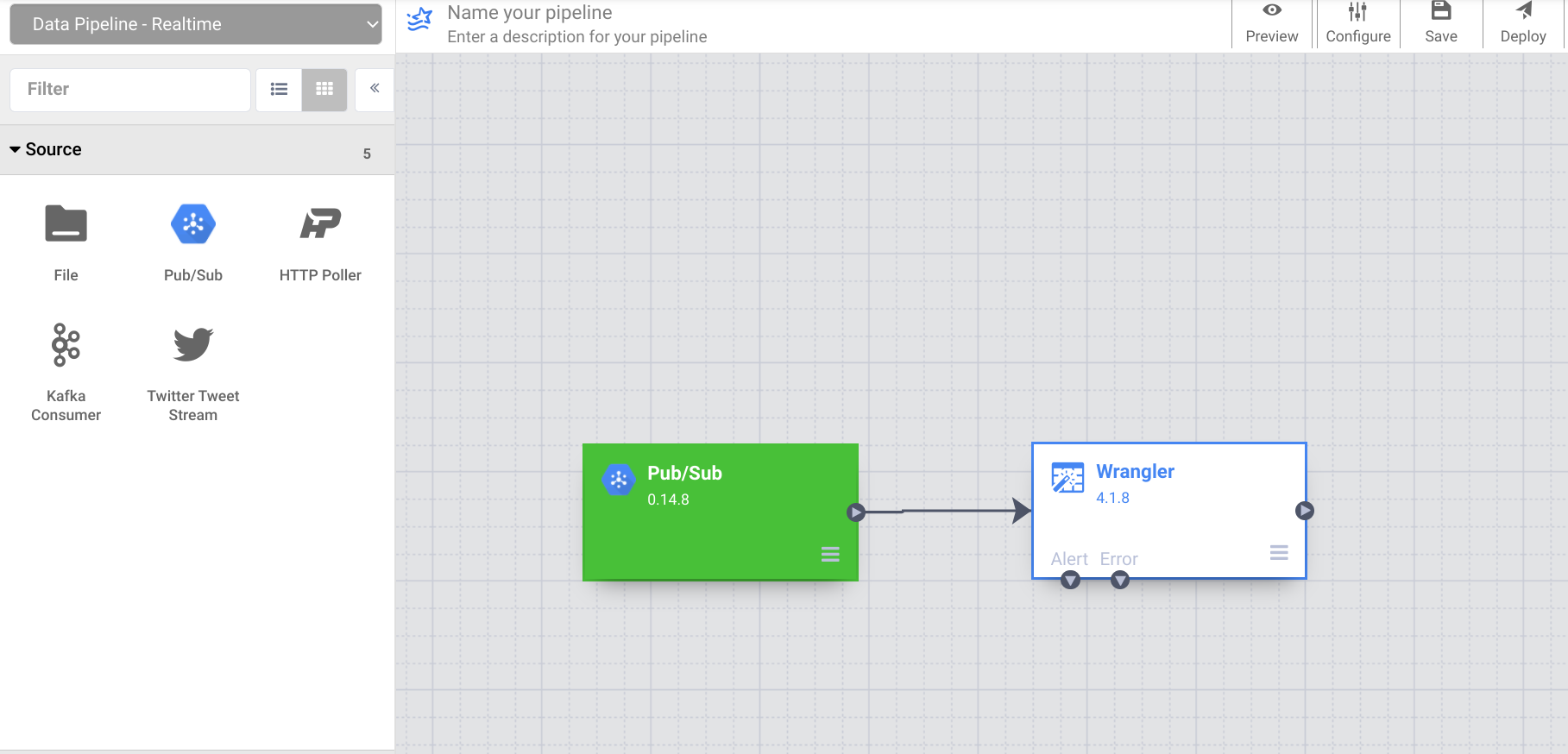
Cloud Data Fusion のコントロール センターで、ナビゲーション メニューを使用して左側のメニューを表示し、[パイプライン] > [Studio] を選択します。
左上のプルダウン メニューを使用して、[データ パイプライン - リアルタイム] を選択します。
データを処理するときに元データがどのようなものであるかを確認できると、元データを変換の出発点として使用できて便利です。この目的のために、Wrangler を使用してデータの準備とクリーニングを行います。このデータファーストのアプローチにより、変換内容をすばやく可視化でき、リアルタイムのフィードバックによって正しく進めているかを確認できます。
プラグイン パレットの [変換] セクションで、[Wrangler] を選択します。Wrangler ノードがキャンバスに表示されます。[プロパティ] ボタンをクリックして開きます。
[ディレクティブ] セクションにある [WRANGLE] ボタンをクリックします。
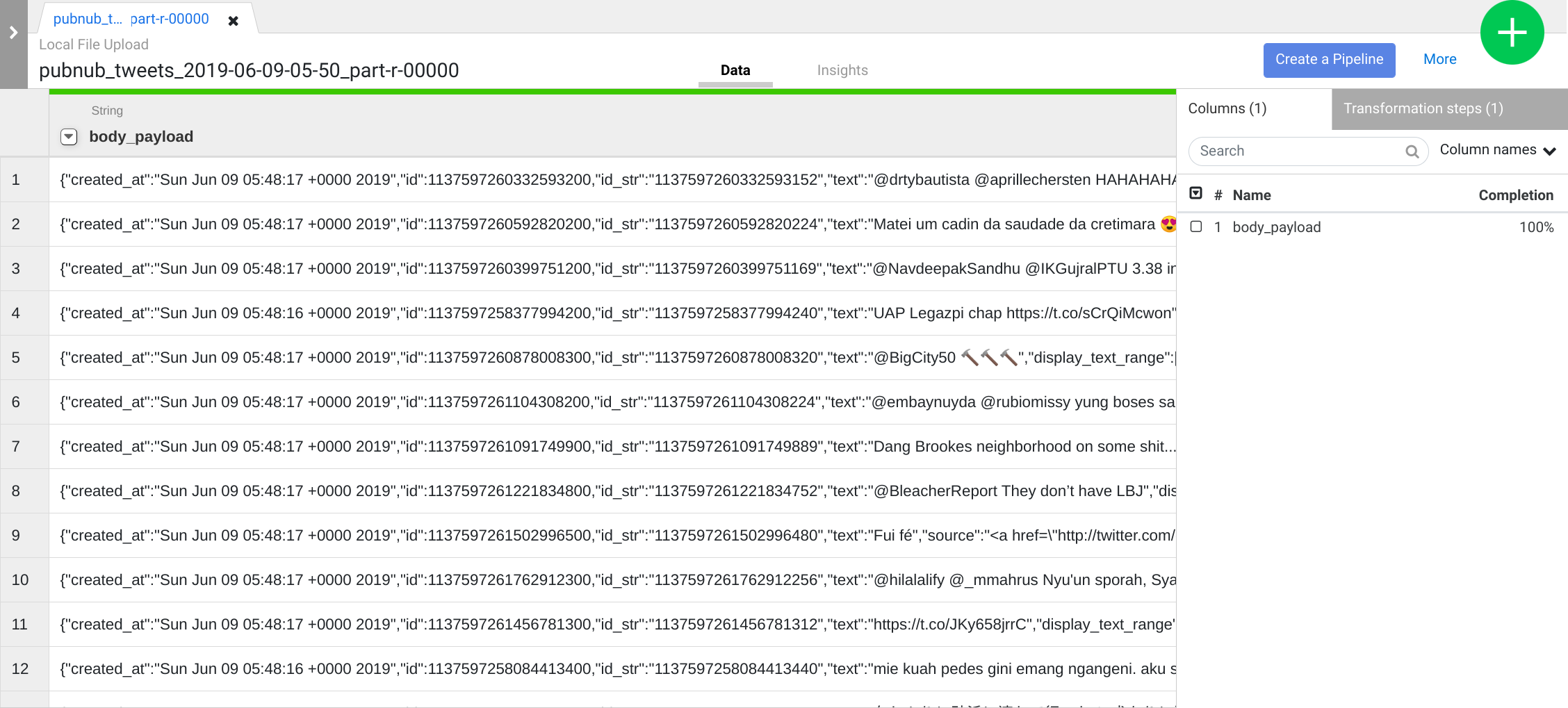
読み込まれたら、左側のサイドメニューで [Upload] をクリックします。次に、アップロード アイコンをクリックして、先ほどパソコンにダウンロードしたサンプル ツイート ファイルをアップロードします。
最初の操作として、JSON データを解析し、行と列に分かれた表形式に変換します。これを行うには、最初の列(body)の見出しにあるプルダウン アイコンを選択し、[Parse] メニュー項目のサブメニューから [JSON] を選択します。ポップアップで [Depth] を [1] に設定し、[Apply] をクリックします。
続けて、より意味のあるデータ構造にするため、同じ操作をもう一度行います。[body] 列のプルダウン アイコンをクリックし、[Parse] > [JSON] を選択して、[Depth] を 1 に設定し、[Apply] をクリックします。
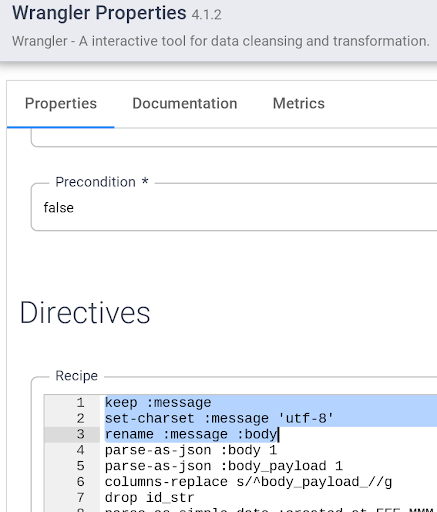
UI を使う方法に加えて、Wrangler のディレクティブ コマンドライン ボックスに変換ステップを記述することもできます。このボックスは Wrangler UI の下部にあり、緑色の $ プロンプトが表示されているコマンドコンソールです。 次のステップでは、このコマンド コンソールに変換ステップを貼り付けて使用します。
以下の変換ステップをすべてコピーし、Wrangler のディレクティブ コマンドラインに貼り付けてください。
ご覧のとおり、Pipeline Studio に戻ると、Wrangler で定義した変換内容を表すノードが 1 つキャンバス上に配置されています。ただし、この時点ではパイプラインにソースは接続されていません。これは前述のとおり、実際の本番環境のデータではなく、ノートパソコン上のサンプルデータに対して変換を適用したためです。
次のステップでは、実際のデータの取得元を指定します。
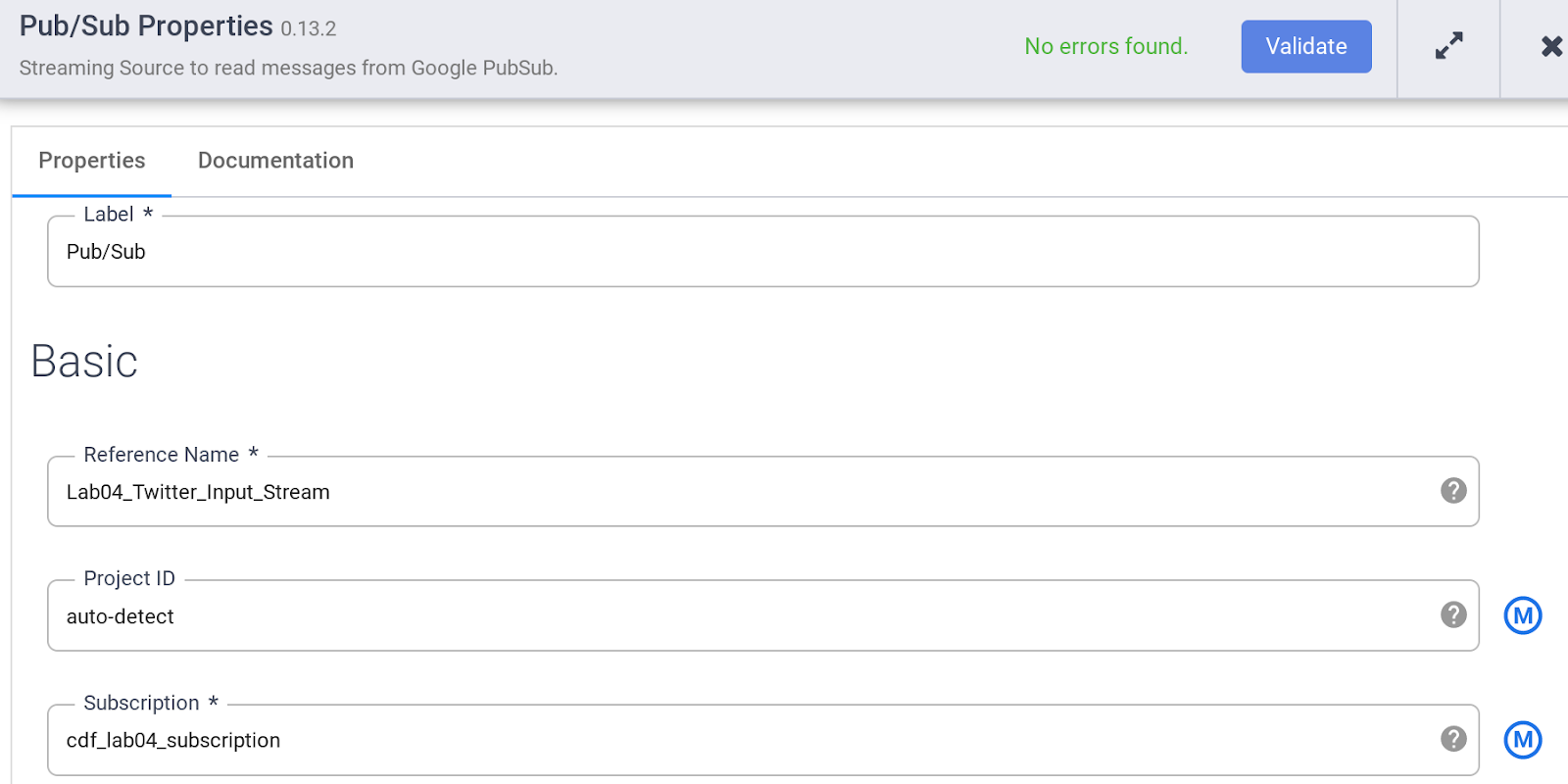
プラグイン パレットの [ソース] セクションで [PubSub] を選択します。PubSub ソースノードがキャンバスに表示されます。[プロパティ] ボタンをクリックして開きます。
PubSub ソースのさまざまなプロパティを以下のように指定します。
a. [リファレンス名] に「Twitter_Input_Stream」と入力します。
b. [サブスクリプション] に「cdf_lab_subscription」(先ほど作成した Pub/Sub サブスクリプションの名前)と入力します。
c. [検証] をクリックして、エラーがないことを確認します。
d. 右上の [X] をクリックして、プロパティ ボックスを閉じます。
Wrangler ではサンプルデータを使用していたため、ソース列は body として表示されていました。一方、PubSub ソースではこのデータは message というフィールド名で出力されます。次のステップで、この違いを調整します。
右上の [X] をクリックして、プロパティ ボックスを閉じます。
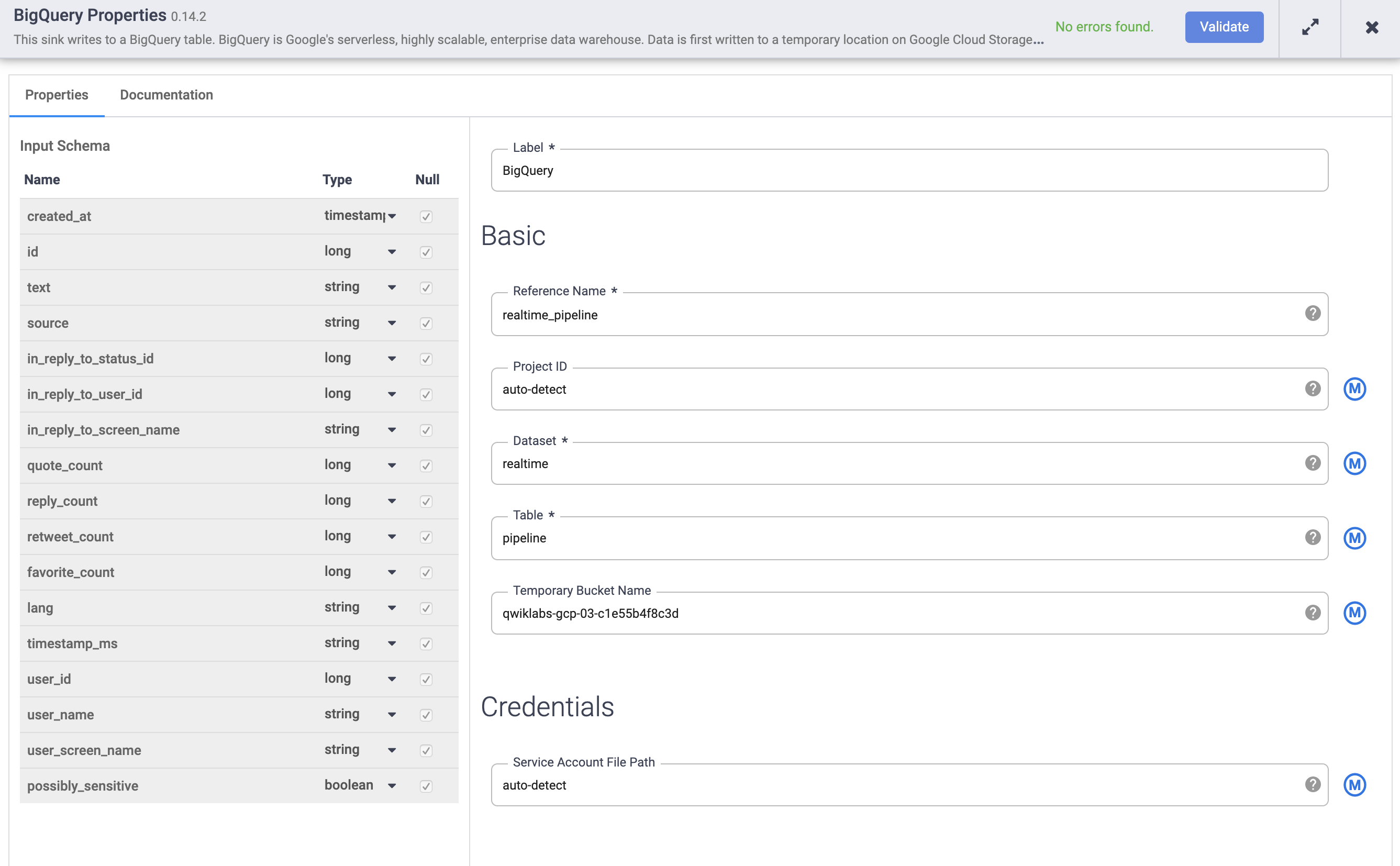
ソースと変換をパイプラインに接続したので、シンクを追加してパイプラインを完成させます。左側のサイドパネルの [シンク] セクションで、[BigQuery] を選択します。BigQuery シンクノードがキャンバスに表示されます。
Wrangler ノードの矢印を BigQuery ノードまでドラッグして、Wrangler ノードを BigQuery ノードに接続します。次に、BigQuery ノードのプロパティを設定します。
BigQuery ノードにカーソルを合わせ、[プロパティ] をクリックします。
a. [リファレンス名] に「realtime_pipeline」と入力します。
b. [データセット] に「realtime」と入力します。
c. [テーブル] に「tweets」と入力します。
d. [検証] をクリックして、エラーがないことを確認します。
右上の [X] をクリックして、プロパティ ボックスを閉じます。
[パイプラインに名前を付ける] をクリックし、名前として「Realtime_Pipeline」を追加して、[保存] をクリックします。
[デプロイ] アイコンをクリックして、パイプラインを開始します。
デプロイが完了したら、[実行] をクリックします。パイプラインの [ステータス] が [実行中] に変わるまで待ちます。これには数分かかる場合があります。
Dataflow テンプレートを使用して、イベントをまとめてサブスクリプションに送信します。
ここでは、テンプレートに基づいて Dataflow ジョブを作成し、ツイート ファイルから複数のメッセージを処理して、先ほど作成した Pub/Sub トピックに公開します。Dataflow のジョブ作成ページから、[Process Data Continuously (Stream)] の [Text Files on Cloud Storage to Pub/Sub] テンプレートを使用します。
Cloud コンソールに戻り、ナビゲーション メニューに移動して、[すべてのプロダクトを表示] をクリックし、[分析] セクションで [Dataflow] をクリックします。
上部のメニューバーの [テンプレートからジョブを作成] をクリックします。
Cloud Dataflow ジョブのジョブ名として「streaming-pipeline」と入力します。
[Cloud Dataflow テンプレート] で、[Text Files on Cloud Storage to Pub/Sub] テンプレートを選択します。
[Input Cloud Storage File(s)] に「gs://<YOUR-BUCKET-NAME>/<FILE-NAME>」と入力します。
<YOUR-BUCKET-NAME> はバケット名に、<FILE-NAME> は先ほどパソコンにダウンロードしたファイルの名前に置き換えてください。
例: gs://qwiklabs-gcp-01-dfdf34926367/pubnub_tweets_2019-06-09-05-50_part-r-00000
projects/<PROJECT-ID>/topics/cdf_lab_topic」と入力します。PROJECT-ID は実際のプロジェクト ID に置き換えてください。
<YOUR-BUCKET-NAME>/tmp/」と入力します。<YOUR-BUCKET-NAME> はお使いのバケットの名前に置き換えてください。
[ジョブを実行] ボタンをクリックします。
Dataflow ジョブを実行し、数分待ちます。Pub/Sub サブスクリプションでメッセージを確認し、その後リアルタイムの Cloud Data Fusion パイプラインで処理される様子を確認できます。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
イベントが Pub/Sub トピックに読み込まれるとすぐに、パイプラインによるイベントの消費が開始されます。各ノードの指標が更新されていく様子を確認してください。
Data Fusion コンソールで、パイプラインの指標が変化するまで待ちます。
このラボでは、Cloud Pub/Sub からストリーミングで受信したメッセージを読み取り、データを処理し、その結果を BigQuery に書き込むリアルタイム パイプラインを Data Fusion で設定する方法を学びました。
マニュアルの最終更新日: 2025 年 2 月 6 日
ラボの最終テスト日: 2025 年 2 月 6 日
Copyright 2026 Google LLC All rights reserved. Google および Google のロゴは、Google LLC の商標です。その他すべての社名および製品名は、それぞれ該当する企業の商標である可能性があります。



このコンテンツは現在ご利用いただけません
利用可能になりましたら、メールでお知らせいたします

ありがとうございます。
利用可能になりましたら、メールでご連絡いたします

1 回に 1 つのラボ
既存のラボをすべて終了して、このラボを開始することを確認してください
ラボを開始するには、この簡単な手順を完了してください。