GSP808

Présentation
En plus des pipelines de traitement par lot, Data Fusion vous permet de créer des pipelines en temps réel qui peuvent traiter les événements à mesure qu'ils sont générés. Actuellement, les pipelines en temps réel s'exécutent à l'aide d'Apache Spark Streaming sur des clusters Cloud Dataproc. Dans cet atelier, vous allez apprendre à créer un pipeline de flux de données à l'aide de Data Fusion.
Vous allez créer un pipeline qui lit un sujet Cloud Pub/Sub, traite les événements, effectue des transformations et écrit la sortie dans BigQuery.
Objectifs
- Apprendre à créer un pipeline en temps réel
- Apprendre à configurer le plug-in source Pub/Sub dans Data Fusion
- Apprendre à définir des transformations pour des données situées dans des connexions non compatibles à l'aide de Wrangler
Préparation
Pour chaque atelier, nous vous attribuons un nouveau projet Google Cloud et un nouvel ensemble de ressources pour une durée déterminée, sans frais.
-
Connectez-vous à Google Skills dans une fenêtre de navigation privée.
-
Vérifiez le temps imparti pour l'atelier (par exemple : 02:00:00) : vous devez pouvoir le terminer dans ce délai.
Une fois l'atelier lancé, vous ne pouvez pas le mettre en pause. Si nécessaire, vous pourrez le redémarrer, mais vous devrez tout reprendre depuis le début.
-
Lorsque vous êtes prêt, cliquez sur Démarrer l'atelier.
Remarque : Une fois que vous avez cliqué sur Démarrer l'atelier, il faut compter environ 15-20 minutes pour que les ressources nécessaires soient provisionnées et une instance Data Fusion créée.
Pendant ce temps, vous pouvez parcourir les étapes ci-dessous pour vous familiariser avec les objectifs de l'atelier.
Les identifiants pour l'atelier (Username (Nom d'utilisateur) et Password (Mot de passe)) s'afficheront dans le volet de gauche une fois l'instance créée. Vous pourrez alors vous connecter à la console.
-
Notez ces identifiants (Username (Nom d'utilisateur) et Password (Mot de passe)). Ils vous serviront à vous connecter à la console Google Cloud.
-
Cliquez sur Open Google Console (Ouvrir la console Google).
-
Cliquez sur Utiliser un autre compte, puis copiez-collez les identifiants de cet atelier lorsque vous y êtes invité.
Si vous utilisez d'autres identifiants, des messages d'erreur s'afficheront ou des frais seront appliqués.
-
Acceptez les conditions d'utilisation et ignorez la page concernant les ressources de récupération des données.
Remarque : Ne cliquez pas sur Terminer l'atelier, à moins que vous n'ayez terminé l'atelier ou que vous ne vouliez le recommencer. Votre travail et le projet seront alors supprimés.
Se connecter à la console Google Cloud
- Dans l'onglet ou la fenêtre de navigateur que vous utilisez pour cet atelier, copiez les données de Username (Nom d'utilisateur) indiqué dans le panneau Connection Details (Détails de connexion), puis cliquez sur le bouton Open Google Console (Ouvrir la console Google).
Remarque : Si vous êtes invité à choisir un compte, cliquez sur Use another account (Utiliser un autre compte).
- Collez les données de Username (Nom d'utilisateur) et de Password (Mot de passe) lorsque vous y êtes invité :
- Cliquez sur Next (Suivant).
- Acceptez les conditions d'utilisation.
Comme il s'agit d'un compte temporaire auquel vous aurez accès uniquement pendant la durée de cet atelier :
- n'ajoutez pas d'options de récupération ;
- ne vous inscrivez pas à des essais sans frais.
- Une fois la console ouverte, affichez la liste des services en cliquant sur le menu de navigation (
 ) en haut à gauche.
) en haut à gauche.

Activer Cloud Shell
Cloud Shell est une machine virtuelle qui contient des outils pour les développeurs. Elle comprend un répertoire d'accueil persistant de 5 Go et s'exécute sur Google Cloud. Google Cloud Shell vous permet d'accéder via une ligne de commande à vos ressources Google Cloud. gcloud est l'outil de ligne de commande associé à Google Cloud. Il est préinstallé sur Cloud Shell et permet la saisie semi-automatique via la touche Tabulation.
-
Dans Google Cloud Console, dans le volet de navigation, cliquez sur Activer Cloud Shell ( ).
).
-
Cliquez sur Continuer.
Le provisionnement et la connexion à l'environnement prennent quelques instants. Une fois connecté, vous êtes en principe authentifié, et le projet est défini sur votre ID_PROJET. Exemple :

Exemples de commandes
gcloud auth list
(Résultat)
Credentialed accounts:
- <myaccount>@<mydomain>.com (active)
(Exemple de résultat)
Credentialed accounts:
- google1623327_student@qwiklabs.net
gcloud config list project
(Résultat)
[core]
project = <ID_Projet>
(Exemple de résultat)
[core]
project = qwiklabs-gcp-44776a13dea667a6
Tâche 1 : Autorisations liées au projet
Vérifier les autorisations du projet
Avant de commencer à travailler dans Google Cloud, vous devez vous assurer de disposer des autorisations adéquates pour votre projet dans IAM (Identity and Access Management).
-
Dans la console Google Cloud, accédez au menu de navigation (), puis cliquez sur IAM et administration > IAM.
-
Vérifiez que le compte de service Compute par défaut {project-number}-compute@developer.gserviceaccount.com existe et qu'il est associé au rôle Éditeur. Le préfixe du compte correspond au numéro du projet, disponible sur cette page : Menu de navigation > Présentation Cloud.

Si le compte n'est pas disponible dans IAM ou n'est pas associé au rôle Éditeur, procédez comme suit pour lui attribuer le rôle approprié.
-
Dans la console Google Cloud, accédez au menu de navigation et cliquez sur Présentation Cloud.
-
Sur la carte Informations sur le projet, copiez le numéro du projet.
-
Dans le menu de navigation, cliquez sur IAM et administration > IAM.
-
En haut de la page IAM, cliquez sur Ajouter.
-
Dans le champ Nouveaux comptes principaux, saisissez :
{project-number}-compute@developer.gserviceaccount.com
Remplacez {project-number} par le numéro de votre projet.
-
Dans le champ Sélectionnez un rôle, sélectionnez De base (ou Projet) > Éditeur.
-
Cliquez sur Enregistrer.
Tâche 2 : Vérifier que l'API Dataflow est activée
Pour vous assurer que vous avez bien accès à l'API requise, redémarrez la connexion à l'API Dataflow.
-
Dans la console Cloud, en haut, saisissez "API Dataflow" dans la barre de recherche. Cliquez sur API Dataflow dans les résultats.
-
Cliquez sur Gérer.
-
Cliquez sur Désactiver l'API.
Si vous êtes invité à confirmer votre choix, cliquez sur Désactiver.
- Cliquez sur Activer.
Tâche 3 : Charger les données
- Vous devez d'abord télécharger les exemples de tweets sur votre ordinateur. Vous les importerez ultérieurement à l'aide de Wrangler pour créer des étapes de transformation.
Vous devrez également placer ce fichier d'exemples de tweets dans votre bucket Cloud Storage. Vers la fin de cet atelier, vous enverrez les données par flux depuis votre bucket dans un sujet Pub/Sub.
- Dans Cloud Shell, exécutez les commandes suivantes pour créer un bucket :
export BUCKET=$GOOGLE_CLOUD_PROJECT
gsutil mb gs://$BUCKET
Le nom du bucket créé porte le même nom correspond à l'ID de votre projet.
- Exécutez la commande ci-dessous pour copier le fichier de tweets dans le bucket :
gsutil cp gs://cloud-training/OCBL164/pubnub_tweets_2019-06-09-05-50_part-r-00000 gs://$BUCKET
- Vérifiez que le fichier a bien été copié dans votre bucket Cloud Storage.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Charger les données
Tâche 4 : Configurer un sujet Pub/Sub
Pour utiliser Pub/Sub, vous devez créer un sujet afin de stocker des données, et un abonnement afin d'accéder à celles publiées sur le sujet.
-
Dans la console Cloud, accédez au menu de navigation, puis cliquez sur Afficher tous les produits. Ensuite, dans la section "Analytics", cliquez sur Pub/Sub et sélectionnez Sujets.
-
Cliquez sur Créer un sujet.
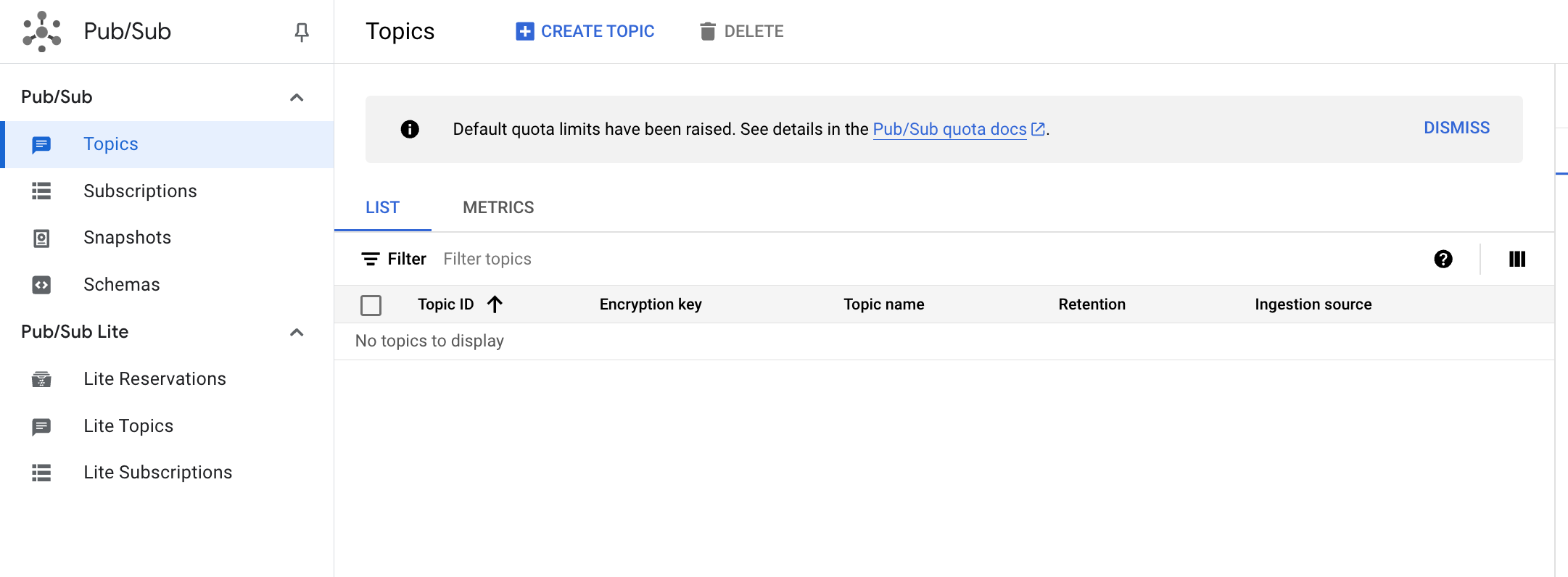
- Le nom du sujet doit être unique. Pour cet atelier, nommez votre sujet
cdf_lab_topic, puis cliquez sur CRÉER.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Configurer un sujet Pub/Sub
Tâche 5 : Ajouter un abonnement Pub/Sub
Restez sur la page du sujet. Vous allez maintenant créer un abonnement pour accéder au sujet.
- Cliquez sur Créer un abonnement.
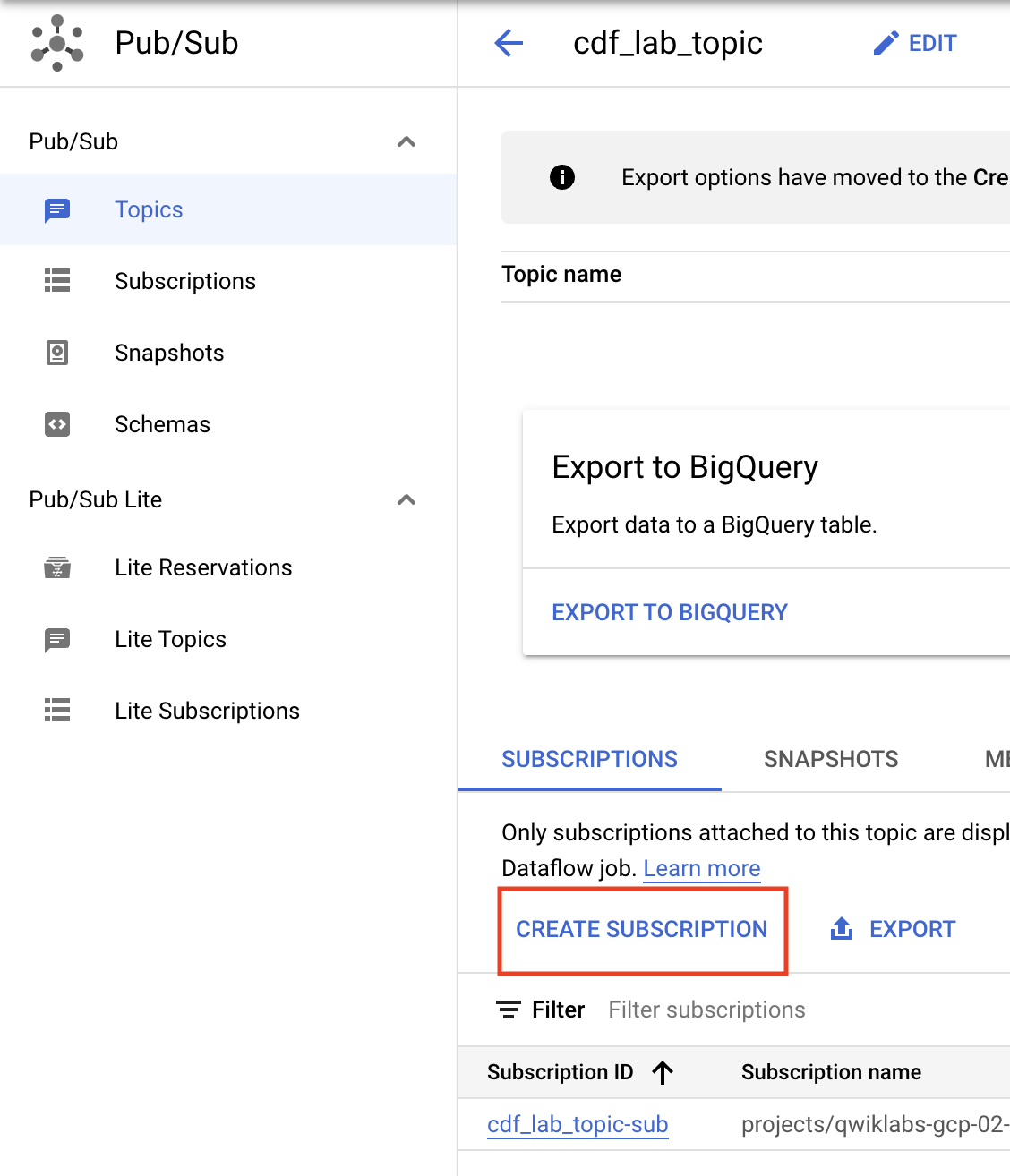
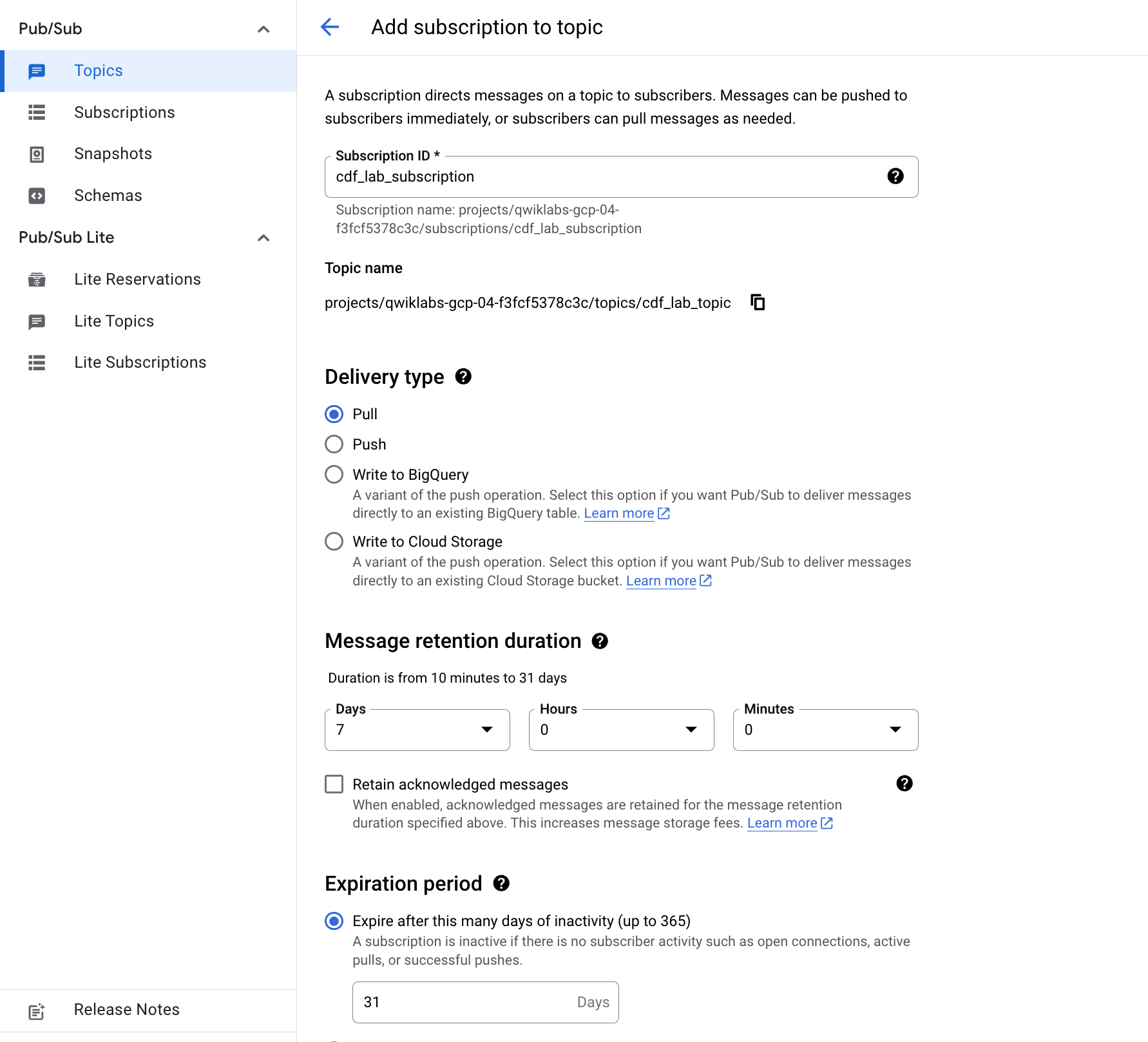
- Attribuez un nom à l'abonnement, par exemple
cdf_lab_subscription, puis sélectionnez Extraire dans "Type de distribution" et cliquez sur Créer.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Ajouter un abonnement Pub/Sub
Tâche 6 : Ajouter les autorisations nécessaires pour votre instance Cloud Data Fusion
- Dans la console Google Cloud, accédez au menu de navigation, puis cliquez sur Afficher tous les produits. Dans la section "Analytics", cliquez sur Data Fusion > Instances.
Remarque : La création de l'instance prend environ 20 minutes. Attendez qu'elle soit prête avant de continuer.
Vous allez à présent accorder des autorisations au compte de service associé à l'instance en suivant les étapes ci-dessous.
-
Dans la console Google Cloud, accédez à IAM et Administration > IAM.
-
Vérifiez que le compte de service par défaut Compute Engine {project-number}-compute@developer.gserviceaccount.com est présent, puis copiez le Compte de service dans votre presse-papiers.
-
Sur la page des autorisations IAM, cliquez sur +Accorder l'accès.
-
Collez le compte de service dans le champ "Nouveaux principaux".
-
Cliquez dans le champ Sélectionner un rôle et commencez à saisir Agent de service de l'API Cloud Data Fusion, puis sélectionnez ce rôle lorsqu'il apparaît.
-
Cliquez sur AJOUTER UN AUTRE RÔLE.
-
Ajoutez le rôle Administrateur Dataproc.
-
Cliquez sur Enregistrer.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Ajouter le rôle Agent de service de l'API Cloud Data Fusion au compte de service
Accorder l'autorisation Utilisateur du compte de service
-
Dans la console, accédez au menu de navigation et cliquez sur IAM et administration > IAM.
-
Cochez la case Inclure les attributions de rôles fournies par Google.
-
Faites défiler la liste jusqu'au compte de service Cloud Data Fusion géré par Google semblable à service-{project-number}@gcp-sa-datafusion.iam.gserviceaccount.com. Copiez le nom du compte de service dans votre presse-papiers.

-
Ensuite, accédez à IAM et administration > Comptes de service.
-
Cliquez sur le compte Compute Engine par défaut, semblable à {project-number}-compute@developer.gserviceaccount.com, et sélectionnez l'onglet Comptes principaux avec accès dans la barre de navigation supérieure.
-
Cliquez sur le bouton Accorder l'accès.
-
Dans le champ Nouveaux comptes principaux, collez le nom du compte de service que vous avez copié plus tôt.
-
Dans le menu déroulant Rôle, sélectionnez Utilisateur du compte de service.
-
Cliquez sur Enregistrer.
Tâche 7 : Parcourir l'UI de Cloud Data Fusion
Lorsque vous utilisez Cloud Data Fusion, vous utilisez à la fois la console Cloud et l'UI distincte de Cloud Data Fusion. Dans la console Cloud, vous pouvez créer un projet de console Cloud, et créer et supprimer des instances Cloud Data Fusion. Dans l'UI de Cloud Data Fusion, vous pouvez accéder à plusieurs pages, telles que Pipeline Studio ou encore Wrangler, qui permettent d'utiliser les différentes fonctionnalités de Cloud Data Fusion.
Pour ouvrir l'UI de Cloud Data Fusion, procédez comme suit :
- Dans la console Cloud, revenez à Data Fusion, puis cliquez sur le lien Afficher l'instance à côté de votre instance Data Fusion. Pour vous connecter, utilisez les identifiants qui vous ont été attribués pour cet atelier. Si vous êtes invité à découvrir le service, cliquez sur Non, merci. L'UI de Cloud Data Fusion s'ouvre.
-
Dans Cloud Data Fusion Control Center, utilisez le menu de navigation pour afficher le menu de gauche, puis sélectionnez Pipeline > Studio.
-
En haut à gauche, utilisez le menu déroulant pour sélectionner Data Pipeline - Realtime (Pipeline de données – En temps réel).
Tâche 8 : Créer un pipeline en temps réel
Lorsque vous manipulez des données, il est utile de pouvoir voir à quoi ressemblent les données brutes afin de s'en servir comme point de départ pour votre transformation. Pour cela, vous allez utiliser Wrangler afin de préparer et de nettoyer les données. Cette approche axée sur les données vous permettra de visualiser rapidement vos transformations, et les commentaires en temps réel vous aideront à vérifier que vous êtes sur la bonne voie.
-
Dans la section Transform (Transformation) de la palette de plug-ins, sélectionnez Wrangler. Le nœud Wrangler s'affiche sur le canevas. Ouvrez-le en cliquant sur le bouton "Properties" (Propriétés).
-
Sous la section Directives, cliquez sur le bouton WRANGLE.
-
Une fois le chargement terminé, cliquez sur Upload (Importer) dans le menu de gauche. Ensuite, cliquez sur l'icône d'importation pour importer le fichier d'exemples de tweets que vous avez téléchargé précédemment sur votre ordinateur.
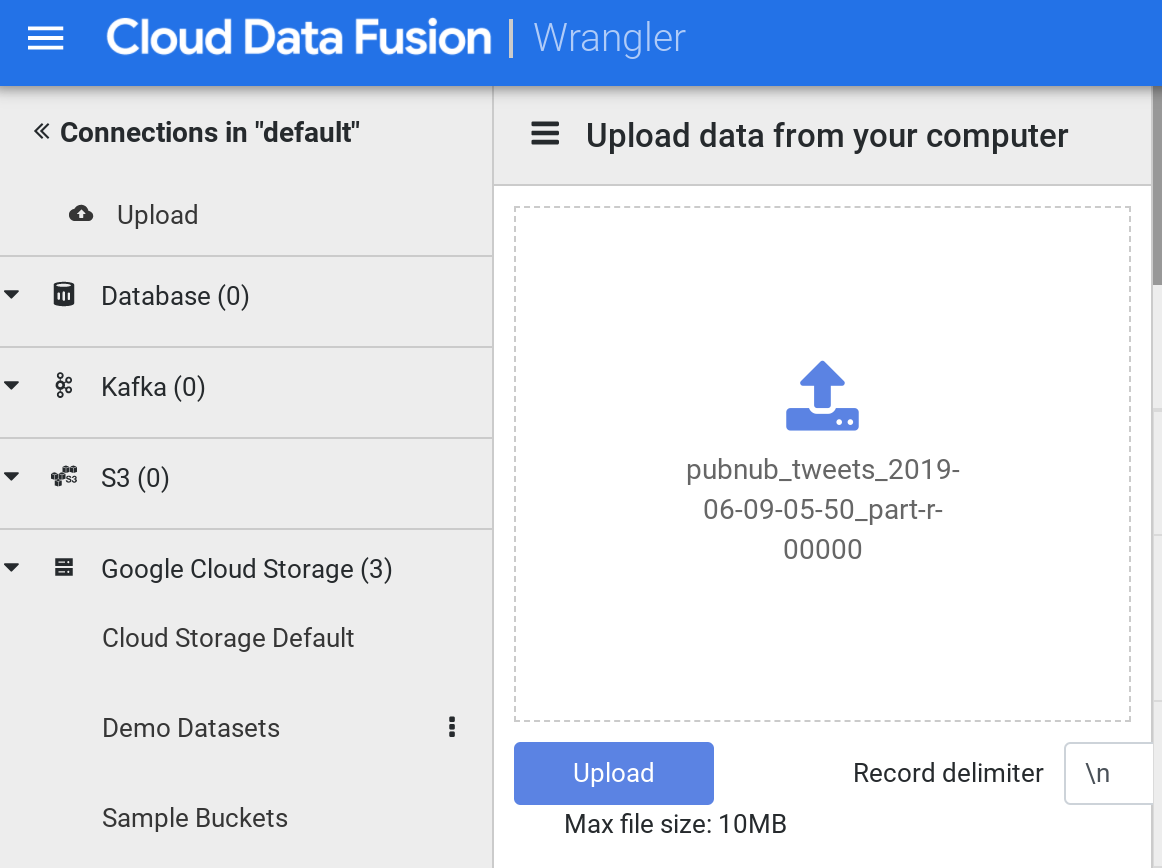
- Les données sont chargées dans l'écran Wrangler sous forme de lignes et de colonnes. Cette opération prend quelques minutes.
Remarque : Considérez qu'il s'agit d'un échantillon des événements que vous recevrez dans Pub/Sub. Il est représentatif de scénarios réels, où vous n'avez généralement pas accès aux données de production lorsque vous développez votre pipeline.
Toutefois, votre administrateur peut vous donner accès à un petit échantillon, ou vous pouvez travailler sur des données fictives qui respectent le contrat d'une API. Dans cette section, vous allez appliquer des transformations à cet échantillon de manière itérative, et vous recevrez des commentaires à chaque étape. Vous apprendrez ensuite à réexécuter les transformations sur des données réelles.
-
La première opération consiste à analyser les données JSON affichées sous la forme d'une représentation tabulaire divisée en lignes et en colonnes. Pour cela, vous devez sélectionner l'icône de menu déroulant située dans l'en-tête de la première colonne (body), puis l'élément de menu Parse (Analyser), et enfin JSON dans le sous-menu. Dans le pop-up, définissez Depth (Profondeur) sur 1, puis cliquez sur Apply (Appliquer).
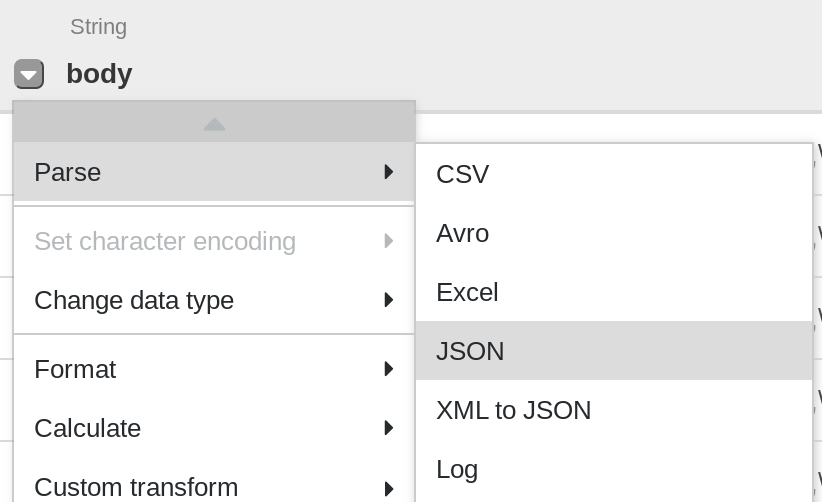
-
Répétez l'étape précédente pour obtenir une structure de données plus pertinente en vue d'une transformation ultérieure. Cliquez sur l'icône de menu déroulant de la colonne body, puis sélectionnez Parse > JSON (Analyser > JSON). Définissez Depth (Profondeur) sur 1, puis cliquez sur Apply (Appliquer).
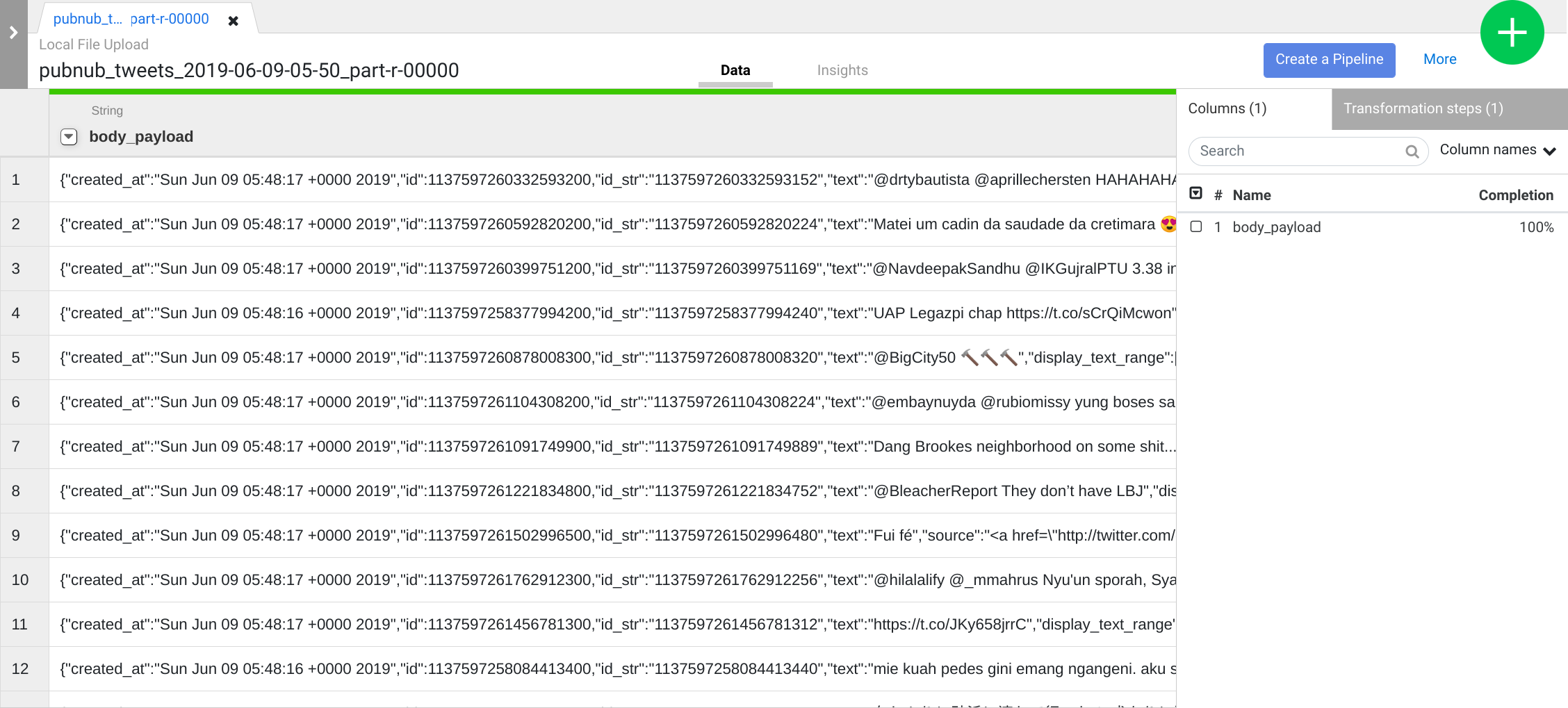
Outre l'UI, vous pouvez également écrire des étapes de transformation dans la zone de ligne de commande des directives Wrangler. Cette zone s'affiche en bas de l'UI de Wrangler (cherchez la console de commande avec l'invite de commande $ en vert).
Vous utiliserez la console de commande pour coller un ensemble d'étapes de transformation à l'étape suivante.
-
Ajoutez les étapes de transformation ci-dessous en les copiant et en les collant dans la zone de ligne de commande des directives Wrangler :
columns-replace s/^body_payload_//g
drop id_str
parse-as-simple-date :created_at EEE MMM dd HH:mm:ss Z yyyy
drop display_text_range
drop truncated
drop in_reply_to_status_id_str
drop in_reply_to_user_id_str
parse-as-json :user 1
drop coordinates
set-type :place string
drop geo,place,contributors,is_quote_status,favorited,retweeted,filter_level,user_id_str,user_url,user_description,user_translator_type,user_protected,user_verified,user_followers_count,user_friends_count,user_statuses_count,user_favourites_count,user_listed_count,user_is_translator,user_contributors_enabled,user_lang,user_geo_enabled,user_time_zone,user_utc_offset,user_created_at,user_profile_background_color,user_profile_background_image_url,user_profile_background_image_url_https,user_profile_background_tile,user_profile_link_color,user_profile_sidebar_border_color,user_profile_sidebar_fill_color,user_profile_text_color,user_profile_use_background_image
drop user_following,user_default_profile_image,user_follow_request_sent,user_notifications,extended_tweet,quoted_status_id,quoted_status_id_str,quoted_status,quoted_status_permalink
drop user_profile_image_url,user_profile_image_url_https,user_profile_banner_url,user_default_profile,extended_entities
fill-null-or-empty :possibly_sensitive 'false'
set-type :possibly_sensitive boolean
drop :entities
drop :user_location
Remarque : Si le message No data. Try removing some transformation steps. (Aucune donnée. Essayez de supprimer certaines étapes de transformation.) s'affiche, supprimez n'importe quelle étape de transformation en cliquant sur X. Une fois les données affichées, vous pouvez continuer.
- Cliquez sur le bouton Apply (Appliquer) en haut à droite. Cliquez ensuite sur X en haut à droite pour fermer la boîte de dialogue "Properties" (Propriétés).
Comme vous pouvez le constater, vous êtes de retour dans Pipeline Studio, où un seul nœud a été placé sur le canevas. Il représente les transformations que vous venez de définir dans Wrangler. Cependant, aucune source n'est connectée à ce pipeline. En effet, comme expliqué ci-dessus, vous avez appliqué ces transformations sur un échantillon représentatif des données sur votre ordinateur portable, et non sur les données à leur emplacement de production réel.
À l'étape suivante, nous allons spécifier l'emplacement réel des données.
-
Dans la section Source de la palette de plug-ins, sélectionnez Pub/Sub. Le nœud de source Pub/Sub s'affiche sur le canevas. Ouvrez-le en cliquant sur le bouton Properties (Propriétés).
-
Spécifiez les différentes propriétés de la source Pub/Sub comme suit :
a. Sous Reference Name (Nom de référence), saisissez Twitter_Input_Stream.
b. Sous Subscription (Abonnement), saisissez cdf_lab_subscription (nom de l'abonnement Pub/Sub que vous avez créé précédemment).
Remarque : La source Pub/Sub n'accepte pas le nom d'abonnement complet, mais uniquement la dernière partie après ".../subscriptions/".
c. Cliquez sur Validate (Valider) pour vous assurer qu'aucune erreur ne sera détectée.
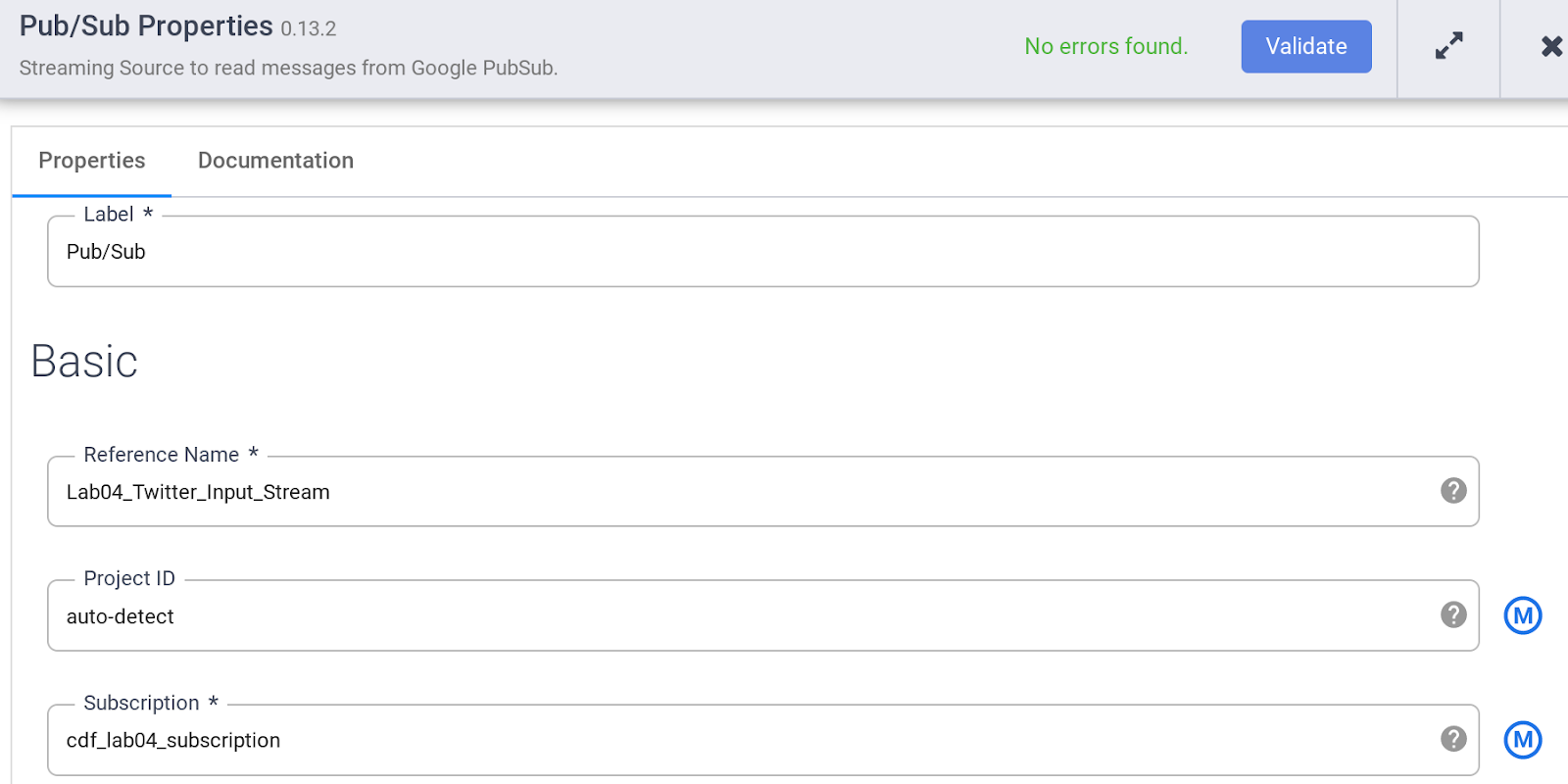
d. Cliquez sur X en haut à droite pour fermer la boîte de dialogue "Properties" (Propriétés).
- Connectez maintenant le nœud de source Pub/Sub au nœud Wrangler que vous avez ajouté précédemment.
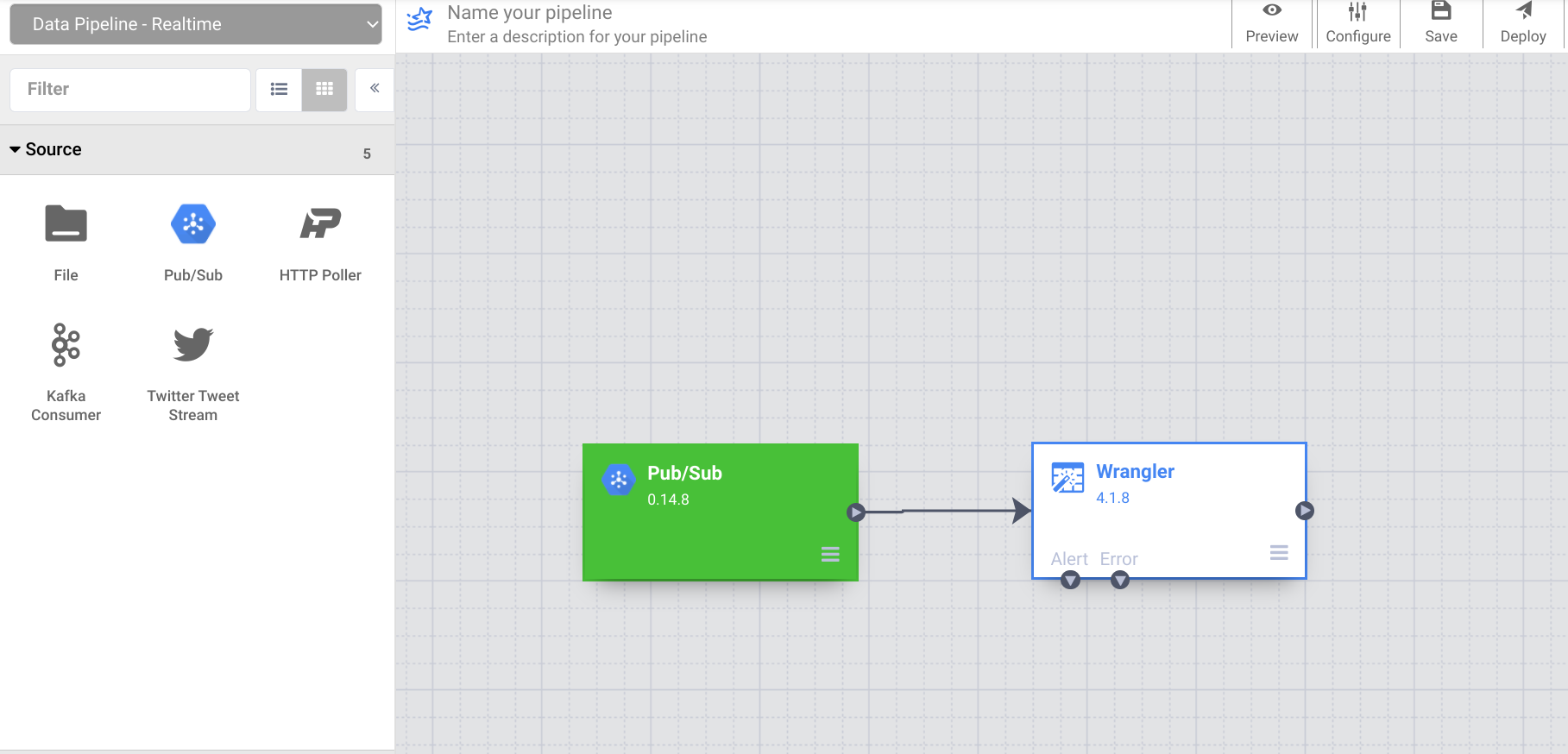
Notez que, comme vous avez utilisé un échantillon des données dans Wrangler, la colonne source s'affichait en tant que "body" dans Wrangler. Toutefois, la source Pub/Sub l'émet dans un champ nommé "message". À l'étape suivante, vous allez corriger cette différence.
- Ouvrez les propriétés de votre nœud Wrangler et ajoutez la directive suivante en haut des étapes de transformation existantes :
keep :message
set-charset :message 'utf-8'
rename :message :body
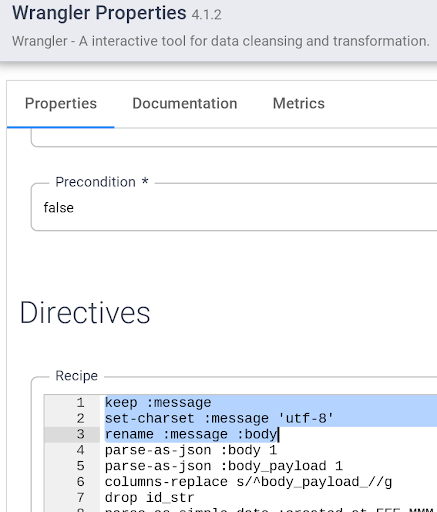
Cliquez sur X en haut à droite pour fermer la boîte de dialogue "Properties" (Propriétés).
-
Maintenant que vous avez connecté une source et une transformation au pipeline, complétez-le en ajoutant un récepteur. Dans la section Sink (Récepteur) du panneau de gauche, sélectionnez BigQuery. Un nœud de récepteur BigQuery s'affiche sur le canevas.
-
Connectez le nœud Wrangler au nœud BigQuery en faisant glisser la flèche du nœud Wrangler vers le nœud BigQuery. Ensuite, vous allez configurer les propriétés du nœud BigQuery.

-
Pointez sur le nœud BigQuery et cliquez sur Properties (Propriétés).
a. Sous Reference Name (Nom de référence), saisissez realtime_pipeline.
b. Sous Dataset (Ensemble de données), saisissez realtime.
c. Sous Table, saisissez tweets.
d. Cliquez sur Validate (Valider) pour vous assurer qu'aucune erreur ne sera détectée.
-
Cliquez sur X en haut à droite pour fermer la boîte de dialogue "Properties" (Propriétés).
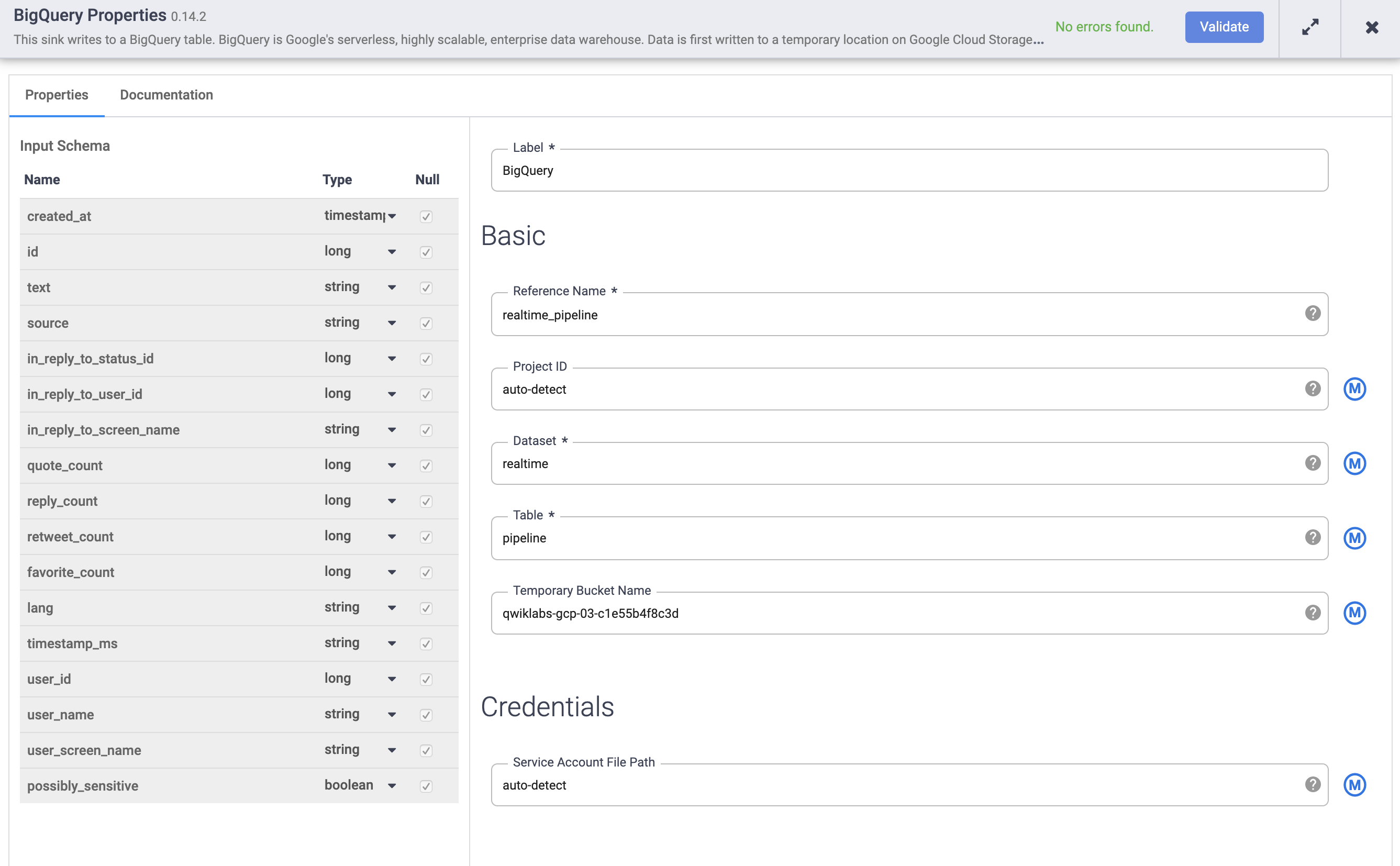
-
Cliquez sur Name your pipeline (Nommer votre pipeline), saisissez Realtime_Pipeline, puis cliquez sur Save (Enregistrer).
-
Cliquez sur l'icône Deploy (Déployer), puis démarrez le pipeline.
-
Une fois le modèle déployé, cliquez sur Run (Exécuter). Attendez que le Status (État) du pipeline passe à Running (En cours d'exécution). Cette opération prend quelques minutes.
Tâche 9 : Envoyer des messages dans Cloud Pub/Sub
Envoyez des événements en les chargeant de façon groupée dans l'abonnement à l'aide du modèle Dataflow.
Vous allez maintenant créer un job Dataflow basé sur un modèle pour traiter plusieurs messages du fichier de tweets et les publier dans le sujet Pub/Sub créé précédemment. Utilisez le modèle Text Files on Cloud Storage to Pub/Sub (Fichiers texte dans Cloud Storage vers Pub/Sub) sous Process Data Continuously (Stream) (Traiter les données en continu (flux)) sur la page de création de job Dataflow.
-
De retour dans la console Cloud, accédez au menu de navigation, cliquez sur Afficher tous les produits, puis sur Dataflow dans la section "Analytics".
-
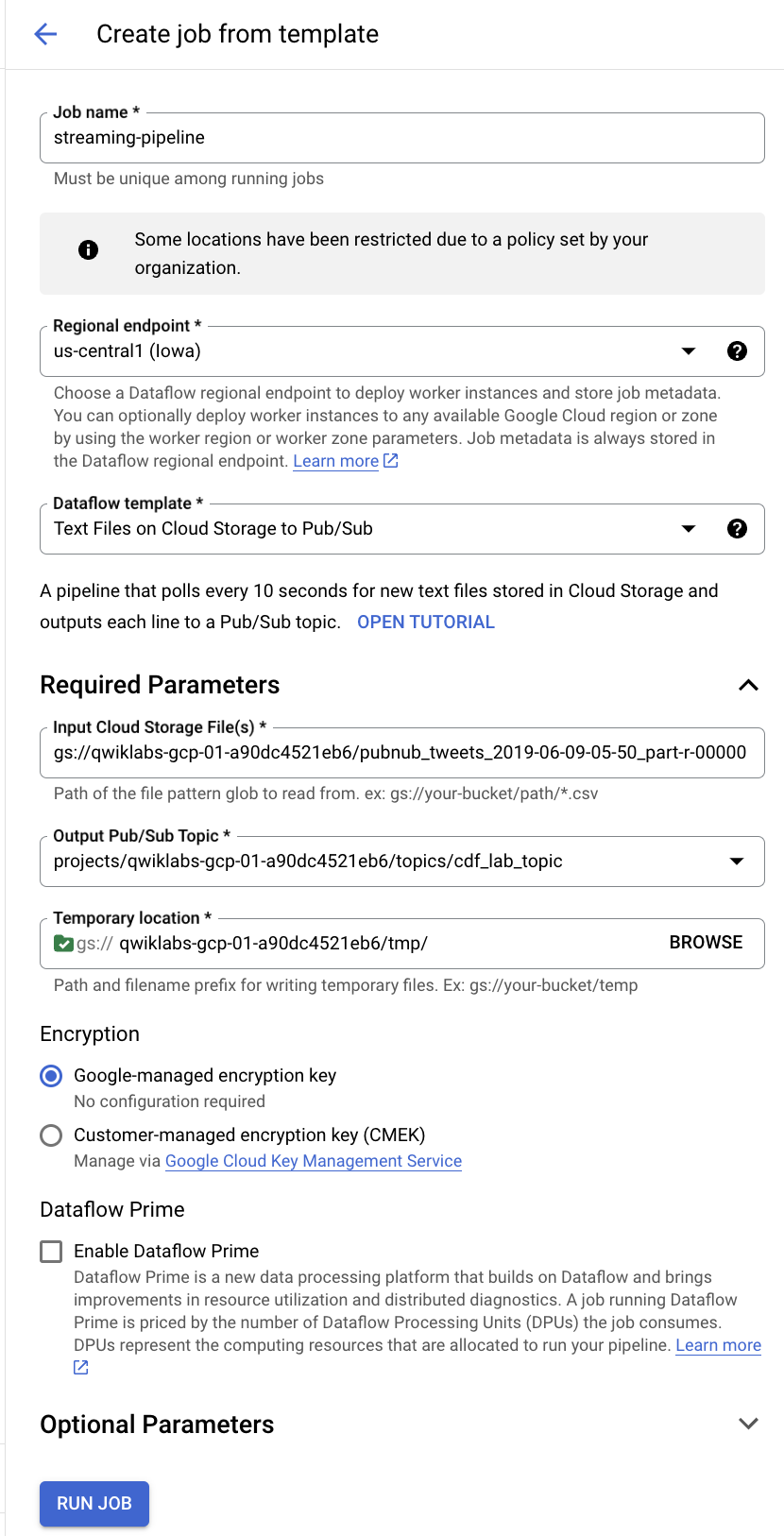
Dans la barre de menu supérieure, cliquez sur CRÉER UN JOB À PARTIR D'UN MODÈLE.
-
Saisissez streaming-pipeline comme nom de votre job Cloud Dataflow.
-
Sous Modèle Dataflow, sélectionnez le modèle Text Files on Cloud Storage to Pub/Sub (Fichiers texte dans Cloud Storage vers Pub/Sub).
-
Sous Input Cloud Storage File(s) (Fichier(s) d'entrée Cloud Storage), saisissez gs://<YOUR-BUCKET-NAME>/<FILE-NAME>
Veillez à remplacer <YOUR-BUCKET-NAME> par le nom de votre bucket et <FILE-NAME> par le nom du fichier que vous avez téléchargé précédemment sur votre ordinateur.
Par exemple : gs://qwiklabs-gcp-01-dfdf34926367/pubnub_tweets_2019-06-09-05-50_part-r-00000
- Sous Output Pub/Sub Topic (Sujet Pub/Sub de sortie), saisissez
projects/<PROJECT-ID>/topics/cdf_lab_topic
Veillez à remplacer PROJECT-ID par l'ID de votre projet.
- Dans Emplacement temporaire, saisissez
<YOUR-BUCKET-NAME>/tmp/
Veillez à remplacer <YOUR-BUCKET-NAME> par le nom de votre bucket.
-
Cliquez sur le bouton Exécuter le job.
-
Exécutez le job Dataflow et patientez quelques minutes. Vous pouvez afficher les messages de l'abonnement Pub/Sub, puis suivre leur traitement en temps réel par le pipeline CDF.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Créer et exécuter un pipeline d'exécution
Tâche 10 : Afficher les métriques du pipeline
Dès que les événements sont chargés dans le sujet Pub/Sub, vous devriez voir le pipeline commencer à les utiliser. Surveillez la mise à jour des métriques sur chaque nœud.
Félicitations !
Dans cet atelier, vous avez appris à configurer un pipeline en temps réel dans Data Fusion qui lit les flux de messages entrants depuis Cloud Pub/Sub, traite les données et les écrit dans BigQuery.
Dernière mise à jour du manuel : 6 février 2025
Dernier test de l'atelier : 6 février 2025
Copyright 2026 Google LLC Tous droits réservés. Google et le logo Google sont des marques de Google LLC. Tous les autres noms de société et de produit peuvent être des marques des sociétés auxquelles ils sont associés.







