GSP808

Descripción general
Además de las canalizaciones por lotes, Data Fusion también te permite crear canalizaciones en tiempo real que pueden procesar eventos a medida que se generan. Actualmente, las canalizaciones en tiempo real se ejecutan con Apache Spark Streaming en clústeres de Cloud Dataproc. En este lab, aprenderás a crear una canalización de transmisión con Data Fusion.
Crearás una canalización que lee desde un tema de Cloud Pub/Sub y procesa los eventos, ejecuta algunas transformaciones y escribe el resultado en BigQuery.
Objetivos
- Aprender a crear una canalización en tiempo real
- Aprender a configurar el complemento de origen de Pub/Sub en Data Fusion
- Aprender a usar Wrangler para definir transformaciones para datos ubicados en conexiones no compatibles
Configuración y requisitos
En cada lab, recibirás un proyecto de Google Cloud y un conjunto de recursos nuevos por tiempo limitado y sin costo adicional.
-
Accede a Google Skills en una ventana de incógnito.
-
Ten en cuenta el tiempo de acceso del lab (por ejemplo, 02:00:00) y asegúrate de finalizarlo en el plazo asignado.
No existe una función de pausa. Si lo necesitas, puedes reiniciar el lab, pero deberás hacerlo desde el comienzo.
-
Cuando tengas todo listo, haz clic en Comenzar lab.
Nota: Después de que hagas clic en Comenzar lab, el lab tardará entre 15 y 20 minutos en aprovisionar los recursos necesarios y crear una instancia de Data Fusion.
Durante ese período, puedes leer los pasos que se indican a continuación para familiarizarte con los objetivos del lab.
Cuando veas las credenciales del lab (el nombre de usuario y la contraseña) en el panel del lado izquierdo, se habrá creado la instancia y podrás continuar para acceder a la consola.
-
Anota las credenciales del lab (el nombre de usuario y la contraseña). Las usarás para acceder a la consola de Google Cloud.
-
Haz clic en Abrir la consola de Google.
-
Haz clic en Usar otra cuenta, copia las credenciales para este lab y pégalas en el mensaje emergente que aparece.
Si usas otras credenciales, se generarán errores o incurrirás en cargos.
-
Acepta las condiciones y omite la página de recursos de recuperación.
Nota: No hagas clic en Finalizar lab, a menos que lo hayas terminado o quieras reiniciarlo. Esta acción borrará tu trabajo y quitará el proyecto.
Accede a la consola de Google Cloud
- En la pestaña o ventana del navegador que estás usando para esta sesión del lab, copia el Nombre de usuario del panel Detalles de la conexión y haz clic en el botón Abrir la consola de Google.
Nota: Si se te solicita que elijas una cuenta, haz clic en Usar otra cuenta.
- Cuando se te solicite, pega el nombre de usuario y, luego, la contraseña.
- Haz clic en Siguiente.
- Acepta los Términos y Condiciones.
Dado que esta es una cuenta temporal que tendrá la misma duración del lab, sigue estas recomendaciones:
- No agregues opciones de recuperación.
- No te registres para las pruebas gratuitas.
- Cuando se abra la consola, podrás ver la lista de servicios haciendo clic en el Menú de navegación (
 ) en la esquina superior izquierda.
) en la esquina superior izquierda.

Active Cloud Shell
Cloud Shell es una máquina virtual que contiene herramientas de desarrollo y un directorio principal persistente de 5 GB. Se ejecuta en Google Cloud. Cloud Shell proporciona acceso de línea de comandos a sus recursos de Google Cloud. gcloud es la herramienta de línea de comandos de Google Cloud, la cual está preinstalada en Cloud Shell y es compatible con la función de autocompletado con tabulador.
-
En el panel de navegación de Google Cloud Console, haga clic en Activar Cloud Shell ( ).
).
-
Haga clic en Continuar.
El aprovisionamiento y la conexión al entorno tardan solo unos momentos. Una vez que se conecte, también estará autenticado, y el proyecto estará configurado con su PROJECT_ID. Por ejemplo:

Comandos de muestra
gcloud auth list
(Resultado)
Credentialed accounts:
- <myaccount>@<mydomain>.com (active)
(Resultado de ejemplo)
Credentialed accounts:
- google1623327_student@qwiklabs.net
gcloud config list project
(Resultado)
[core]
project = <project_ID>
(Resultado de ejemplo)
[core]
project = qwiklabs-gcp-44776a13dea667a6
Tarea 1: Permisos del proyecto
Verifica los permisos del proyecto
Antes de comenzar a trabajar en Google Cloud, asegúrate de que tu proyecto tenga los permisos correctos en Identity and Access Management (IAM).
-
En el Menú de navegación () de la consola de Google Cloud, haga clic en IAM y administración > IAM.
-
Confirma que aparezca la cuenta de servicio predeterminada de Compute {project-number}-compute@developer.gserviceaccount.com, y que tenga asignado el rol Editor. El prefijo de la cuenta es el número del proyecto, que puedes encontrar en el menú de navegación > Descripción general de Cloud.

Si no aparece la cuenta en IAM o no tiene asignado el rol Editor, sigue los pasos que se indican a continuación para asignar el rol necesario.
-
En la consola de Google Cloud, en el menú de navegación, haz clic en Descripción general de Cloud.
-
En la tarjeta Información del proyecto, copia el Número de proyecto.
-
En el menú de navegación, haz clic en IAM y administración > IAM.
-
En la parte superior de la página IAM, haga clic en Agregar.
-
En Principales nuevas, escriba lo siguiente:
{número-del-proyecto}-compute@developer.gserviceaccount.com
Reemplaza {project-number} por el número de tu proyecto.
-
En Seleccionar un rol, elige Básico (o Proyecto) > Editor.
-
Haz clic en Guardar.
Tarea 2: Asegúrate de que la API de Dataflow esté habilitada correctamente
Para garantizar el acceso a la API necesaria, reinicia la conexión a la API de Dataflow.
-
En la consola de Cloud, escribe “API de Dataflow” en la barra de búsqueda superior. Haz clic en el resultado de API de Dataflow.
-
Haz clic en Administrar.
-
Haz clic en Inhabilitar API.
Si se te solicita confirmar, haz clic en Inhabilitar.
- Haz clic en Habilitar.
Tarea 3: Carga los datos
- Primero, debes descargar los tweets de ejemplo en tu computadora. Más adelante, los subirás con Wrangler para crear pasos de transformación.
También deberás almacenar el mismo archivo de tweets de ejemplo en tu bucket de Cloud Storage. Hacia el final de este lab, transmitirás los datos de tu bucket a un tema de Pub/Sub.
- En Cloud Shell, ejecuta los siguientes comandos para crear un bucket nuevo:
export BUCKET=$GOOGLE_CLOUD_PROJECT
gsutil mb gs://$BUCKET
El nombre del bucket creado es el mismo que el del ID del proyecto.
- Ejecuta el siguiente comando para copiar el archivo de tweets en el bucket:
gsutil cp gs://cloud-training/OCBL164/pubnub_tweets_2019-06-09-05-50_part-r-00000 gs://$BUCKET
- Verifica que el archivo se haya copiado en tu bucket de Cloud Storage.
Haz clic en Revisar mi progreso para verificar el objetivo.
Cargar los datos
Tarea 4: Configura un tema de Pub/Sub
Para usar Pub/Sub, debes crear un tema para conservar datos y una suscripción para acceder a los datos publicados en el tema.
-
En la consola de Cloud, en el menú de navegación, haz clic en Ver todos los productos, en la sección de Analytics, haz clic en Pub/Sub y, luego, selecciona Temas.
-
Haz clic en Crear un tema.
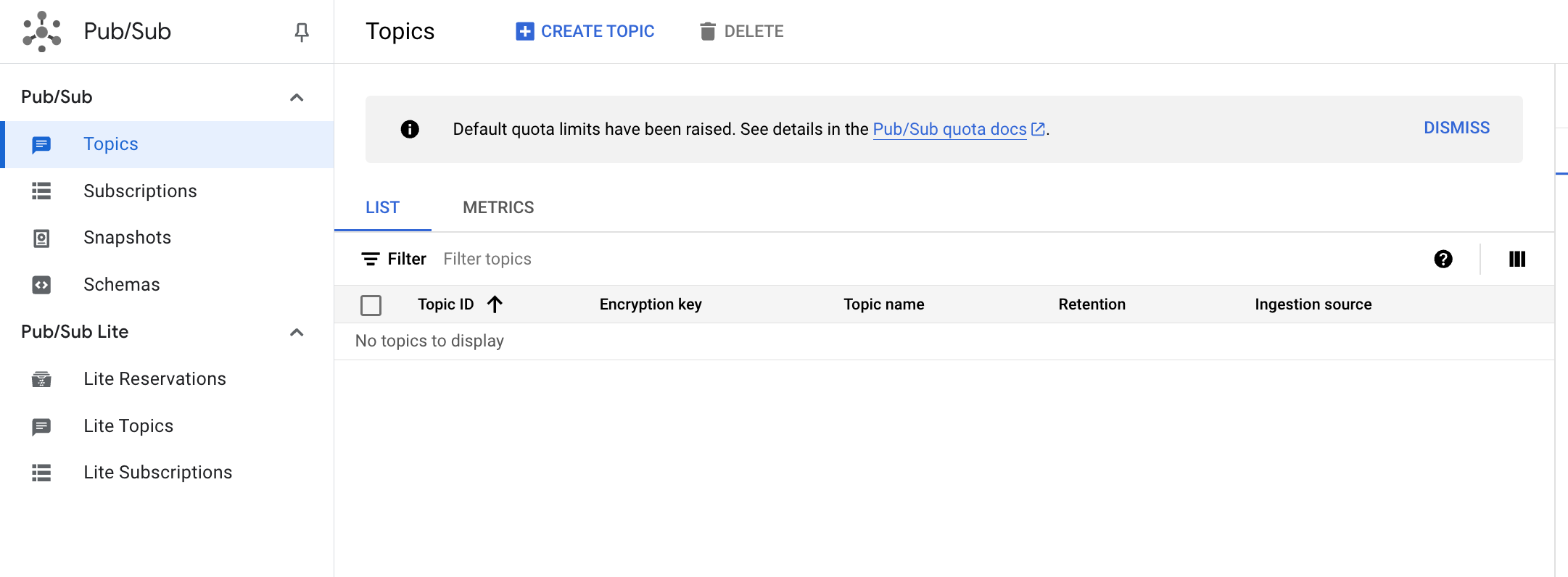
- El tema debe tener un nombre único. Para este lab, asigna a tu tema el nombre
cdf_lab_topic y, luego, haz clic en CREAR.
Haz clic en Revisar mi progreso para verificar el objetivo.
Configurar un tema de Pub/Sub
Tarea 5: Agrega una suscripción a Pub/Sub
Continúa en la página de temas. Ahora, crearás una suscripción para acceder al tema.
- Haz clic en Crear suscripción.
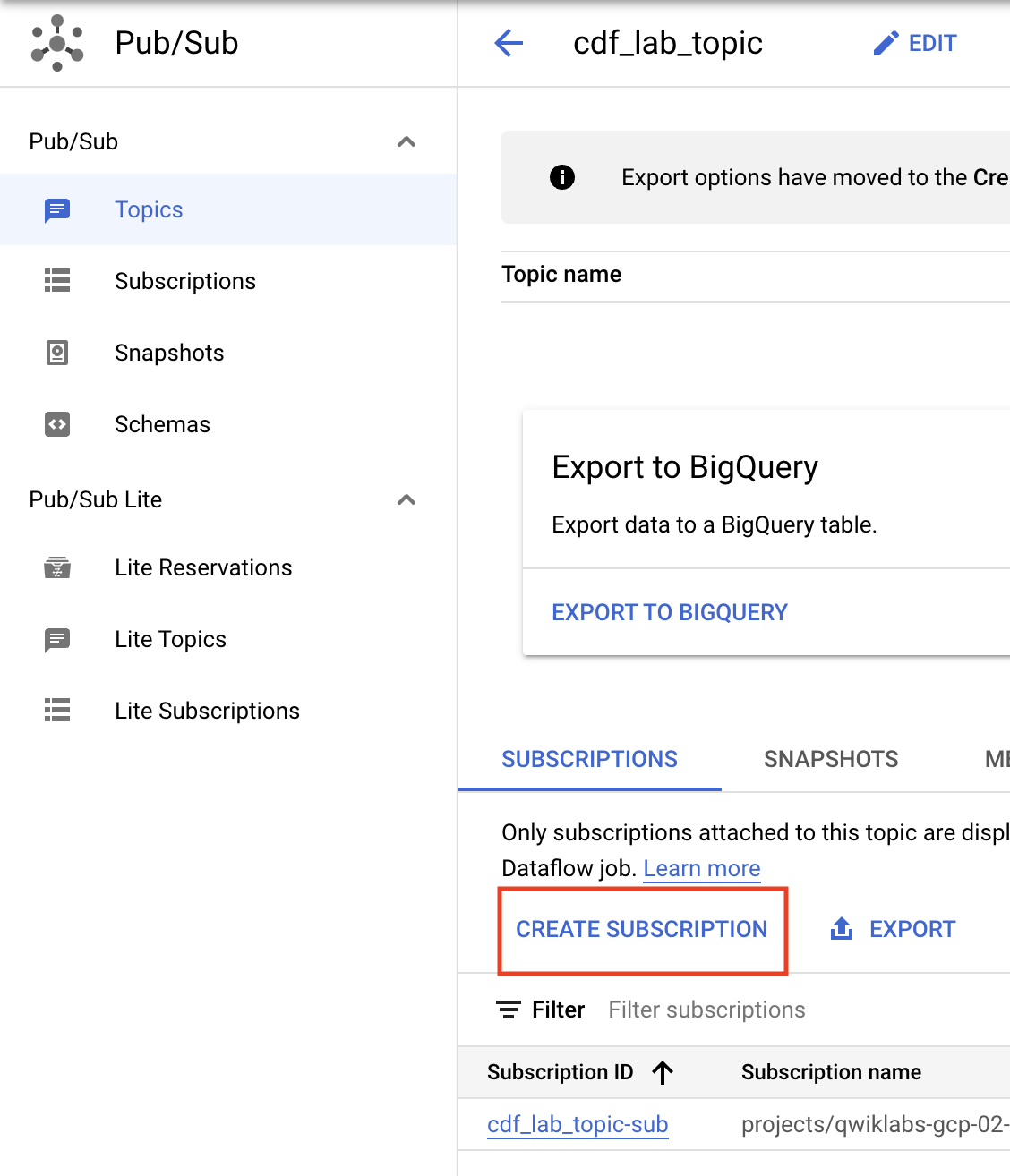
- Ingresa un nombre para la suscripción, como
cdf_lab_subscription, establece el tipo de envío en Extracción y, a continuación, haz clic en Crear.
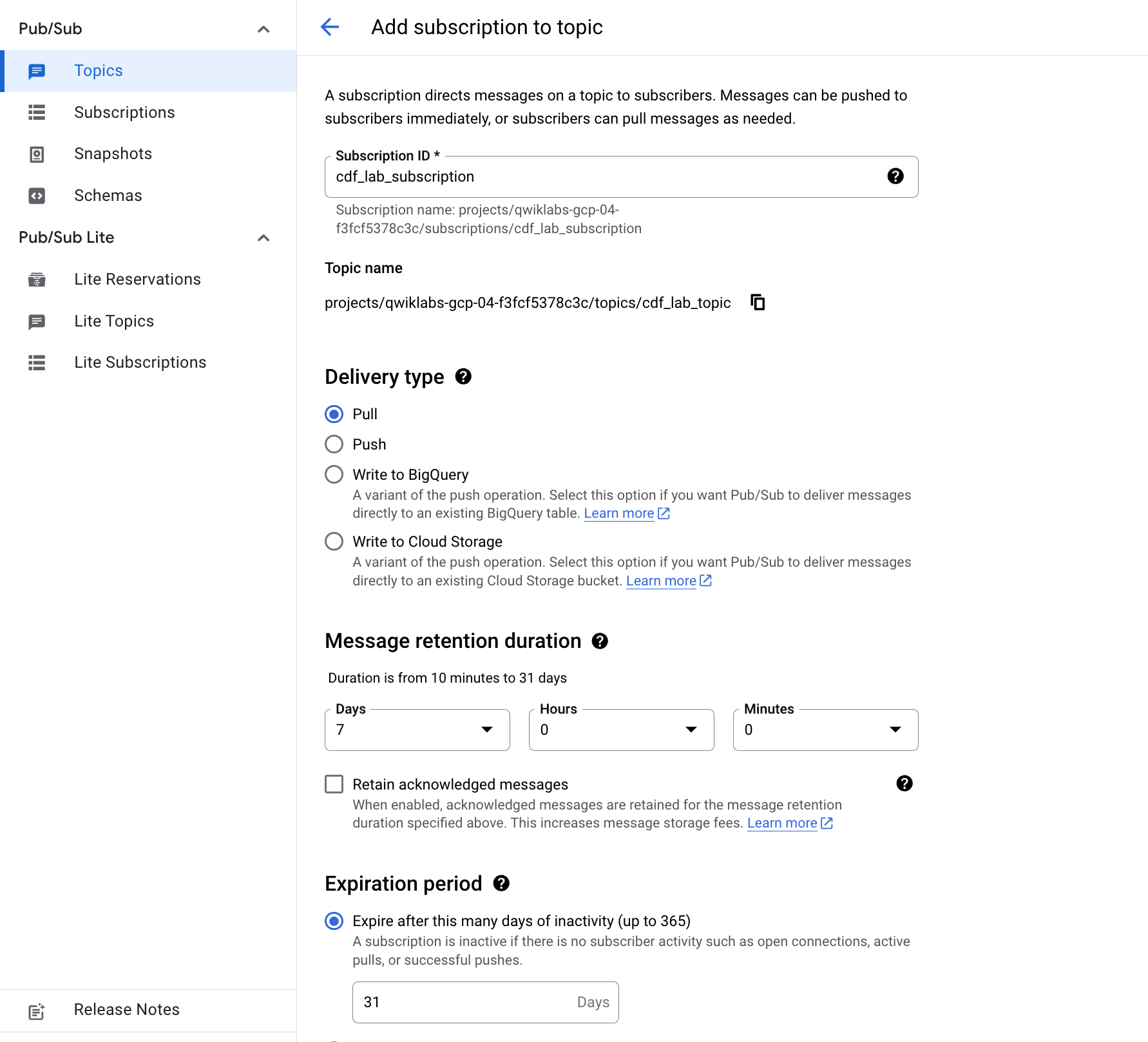
Haz clic en Revisar mi progreso para verificar el objetivo.
Agregar una suscripción a Pub/Sub
Tarea 6: Agrega los permisos necesarios para tu instancia de Cloud Data Fusion
- En el menú de navegación de la consola de Google Cloud, haz clic en Ver todos los productos y, en la sección de Analytics, haz clic en Data Fusion > Instancias.
Nota: La creación de la instancia tardará alrededor de 20 minutos. Espera a que esté lista.
Luego, otorgarás permisos a la cuenta de servicio asociada con la instancia siguiendo estos pasos:
-
En la consola de Google Cloud, navega a IAM y administración > IAM.
-
Verifica que la cuenta de servicio predeterminada de Compute Engine, {project-number}-compute@developer.gserviceaccount.com, esté presente y copia la Cuenta de servicio en tu portapapeles.
-
En la página Permisos de IAM, haz clic en +Otorgar acceso.
-
En el campo Entidades nuevas, pega la cuenta de servicio.
-
Haz clic en el campo Seleccionar un rol, escribe Agente de servicio de la API de Cloud Data Fusion y selecciónalo.
-
Haz clic en AGREGAR OTRO ROL.
-
Agrega el rol de Administrador de Dataproc.
-
Haz clic en Guardar.
Haz clic en Revisar mi progreso para verificar el objetivo.
Agregar el rol Agente de servicio de la API de Cloud Data Fusion a la cuenta de servicio
Otorga permiso de usuario a la cuenta de servicio
-
En la consola, ve a Menú de navegación y haz clic en IAM y administración > IAM.
-
Selecciona la casilla de verificación Incluir asignaciones de roles proporcionadas por Google.
-
Desplázate hacia abajo en la lista hasta encontrar la cuenta de servicio de Cloud Data Fusion administrada por Google que tiene el formato service-{project-number}@gcp-sa-datafusion.iam.gserviceaccount.com. Luego, copia el nombre de la cuenta en el portapapeles.

-
Después, navega a IAM y administración > Cuentas de servicio.
-
Haz clic en la cuenta predeterminada de Compute Engine que tiene el formato {project-number}-compute@developer.gserviceaccount.com y selecciona la pestaña Principales con acceso en la barra de navegación superior.
-
Haz clic en el botón Otorgar acceso.
-
En el campo Principales nuevas, pega la cuenta de servicio que copiaste antes.
-
En el menú desplegable Rol, selecciona Usuario de cuenta de servicio.
-
Haz clic en Guardar.
Tarea 7: Navega por la IU de Cloud Data Fusion
Cuando usas Cloud Data Fusion, usas la IU de la consola de Cloud y la de Cloud Data Fusion, que está separada. En la consola de Cloud, puedes crear un proyecto de la consola, y crear y borrar instancias de Cloud Data Fusion. En la IU de Cloud Data Fusion, puedes usar las diversas páginas, como Pipeline Studio o Wrangler, para usar las funciones de Cloud Data Fusion.
Para navegar por la IU de Cloud Data Fusion, sigue estos pasos:
- En la consola de Cloud, regresa a Data Fusion y haz clic en el vínculo Ver instancia que aparece junto a tu instancia de Data Fusion. Selecciona las credenciales del lab para acceder. Si se te solicita hacer una visita guiada por el servicio, haz clic en No, gracias. Ahora deberías estar en la IU de Cloud Data Fusion.
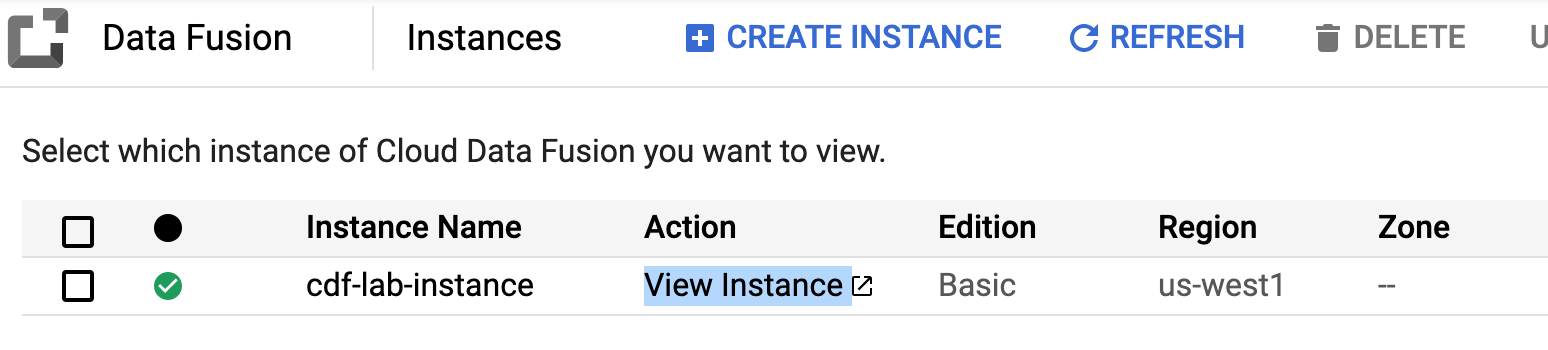
-
En el Centro de control de Cloud Data Fusion, usa el menú de navegación para mostrar el menú de la izquierda y, luego, elige Canalización > Studio.
-
En la parte superior izquierda, usa el menú desplegable para seleccionar Canalización de datos - Tiempo real.
Tarea 8: Crea una canalización en tiempo real
Cuando trabajas con datos, es útil poder ver cómo lucen los datos sin procesar para que puedas usarlos como punto de partida para tu transformación. Con este fin, usarás Wrangler para preparar y limpiar los datos. Gracias a este enfoque centrado en los datos, podrás visualizar tus transformaciones con rapidez, y los comentarios en tiempo real te asegurarán que vas por el camino correcto.
-
En la sección Transformación de la paleta de complementos, selecciona Wrangler. El nodo Wrangler aparecerá en el lienzo. Para abrirlo, haz clic en el botón Properties.
-
Haz clic en el botón WRANGLE en la sección Directives.
-
Cuando se cargue, en el menú del lado izquierdo, haz clic en Upload. Luego, haz clic en el ícono de carga para subir el archivo de tweets de ejemplo que descargaste antes en tu computadora.
- Los datos se cargan en la pantalla de Wrangler en forma de fila/columna. Esto tardará unos minutos.
Nota: Trata esto como una muestra de los eventos que recibirás en Pub/Sub. Esto representa situaciones del mundo real, en las que, por lo general, no tienes acceso a los datos de producción mientras desarrollas tu canalización.
Sin embargo, tu administrador podría darte acceso a una pequeña muestra o podrías estar trabajando con datos simulados que se ajusten al contrato de una API. En esta sección, aplicarás transformaciones a esta muestra de forma iterativa, con comentarios en cada paso. Luego, aprenderás a reproducir las transformaciones en datos reales.
-
La primera operación es analizar los datos JSON sin procesar en una representación tabular que se divide en filas y columnas. Para hacerlo, selecciona el ícono del menú desplegable del encabezado de la primera columna (body), luego, selecciona el elemento Parse del menú y, por último, JSON en el submenú. En la ventana emergente, establece Depth como 1 y, luego, haz clic en Apply.
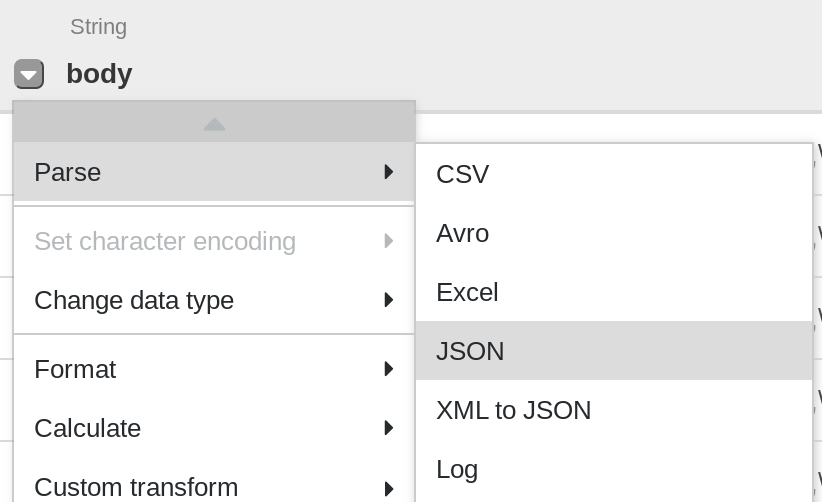
-
Repite el paso anterior para ver una estructura de datos más significativa para una transformación posterior. Haz clic en el ícono desplegable de la columna body, luego selecciona Parse > JSON y establece Depth como 1. Por último, haz clic en Apply.
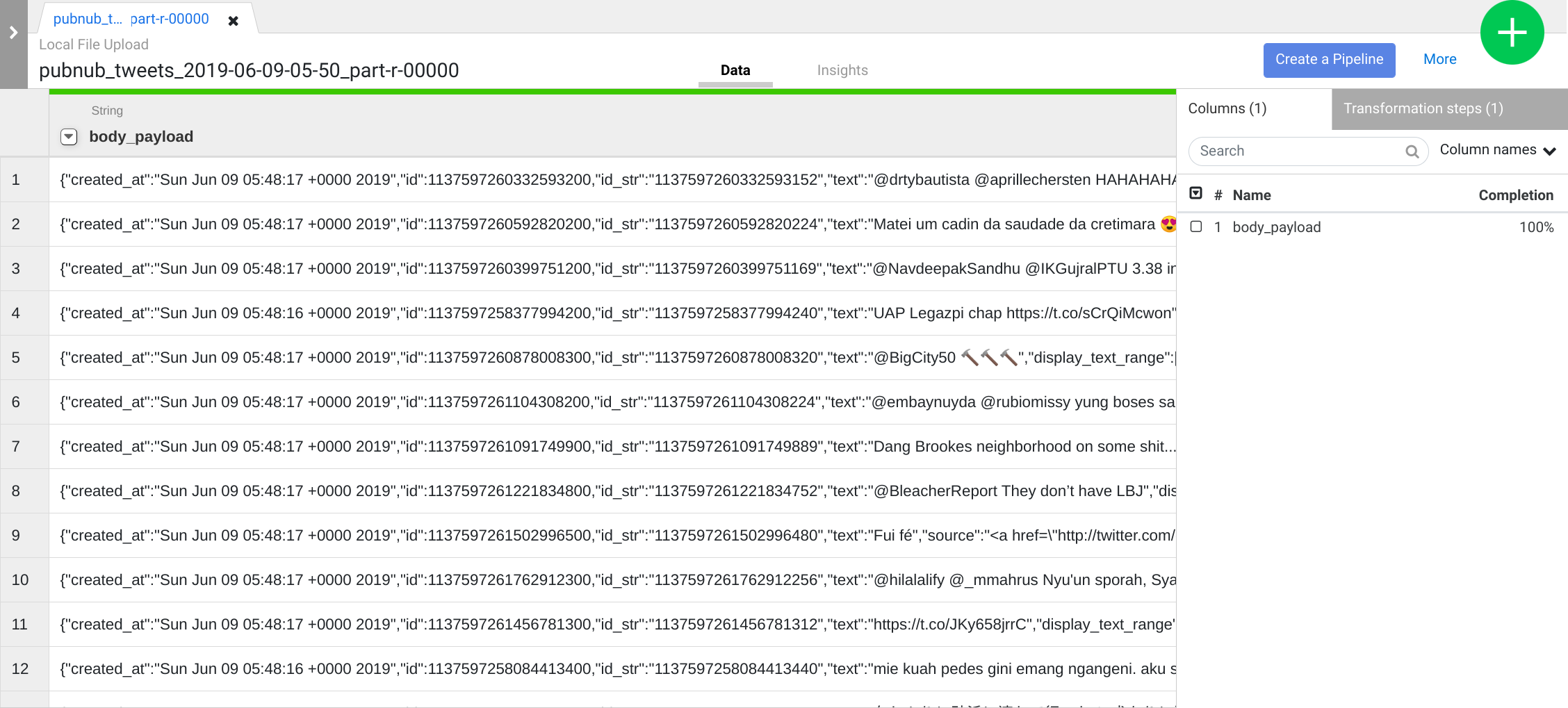
Además de usar la IU, también puedes escribir pasos de transformación en el cuadro de línea de comandos de directivas de Wrangler. Este cuadro aparece en la sección inferior de la IU de Wrangler (busca la consola de comandos con el prompt $ en verde).
Usarás la consola de comandos para pegar un conjunto de pasos de transformación en el siguiente paso.
-
Agrega los pasos de transformación que se indican a continuación. Para ello, copia todo y pégalo en el cuadro de línea de comandos de la directiva de Wrangler:
columns-replace s/^body_payload_//g
drop id_str
parse-as-simple-date :created_at EEE MMM dd HH:mm:ss Z yyyy
drop display_text_range
drop truncated
drop in_reply_to_status_id_str
drop in_reply_to_user_id_str
parse-as-json :user 1
drop coordinates
set-type :place string
drop geo,place,contributors,is_quote_status,favorited,retweeted,filter_level,user_id_str,user_url,user_description,user_translator_type,user_protected,user_verified,user_followers_count,user_friends_count,user_statuses_count,user_favourites_count,user_listed_count,user_is_translator,user_contributors_enabled,user_lang,user_geo_enabled,user_time_zone,user_utc_offset,user_created_at,user_profile_background_color,user_profile_background_image_url,user_profile_background_image_url_https,user_profile_background_tile,user_profile_link_color,user_profile_sidebar_border_color,user_profile_sidebar_fill_color,user_profile_text_color,user_profile_use_background_image
drop user_following,user_default_profile_image,user_follow_request_sent,user_notifications,extended_tweet,quoted_status_id,quoted_status_id_str,quoted_status,quoted_status_permalink
drop user_profile_image_url,user_profile_image_url_https,user_profile_banner_url,user_default_profile,extended_entities
fill-null-or-empty :possibly_sensitive 'false'
set-type :possibly_sensitive boolean
drop :entities
drop :user_location
Nota: Si el mensaje aparece como “No data. Try removing some transformation steps”. Luego, quita cualquiera de los pasos de transformación haciendo clic en X y, una vez que aparezcan los datos, puedes continuar.
- Haz clic en el botón Apply en la parte superior derecha. Luego, haz clic en la X en la parte superior derecha para cerrar el cuadro de propiedades.
Como puedes ver, volviste a Pipeline Studio, en el que se colocó un solo nodo en el lienzo, que representa las transformaciones que acabas de definir en Wrangler. Sin embargo, no hay ninguna fuente conectada a esta canalización, ya que, como se explicó anteriormente, aplicaste estas transformaciones en una muestra representativa de los datos de tu laptop, y no en los datos de su ubicación de producción real.
En el siguiente paso, especifiquemos dónde se ubicarán los datos.
-
En la sección Fuente de la paleta de complementos, selecciona PubSub. El nodo fuente de PubSub aparecerá en el lienzo. Para abrirlo, haz clic en el botón Properties.
-
Especifica las diversas propiedades de la fuente PubSub como se indica a continuación:
a. En Reference name, ingresa Twitter_Input_Stream.
b. En Subscription, ingresa cdf_lab_subscription (que es el nombre de la suscripción a PubSub que creaste anteriormente).
Nota: La fuente PubSub no acepta el nombre de suscripción completamente calificado, sino solo su último componente después de la parte …/subscriptions/.
c. Haz clic en Validate para asegurarte de que no se encontrarán errores.
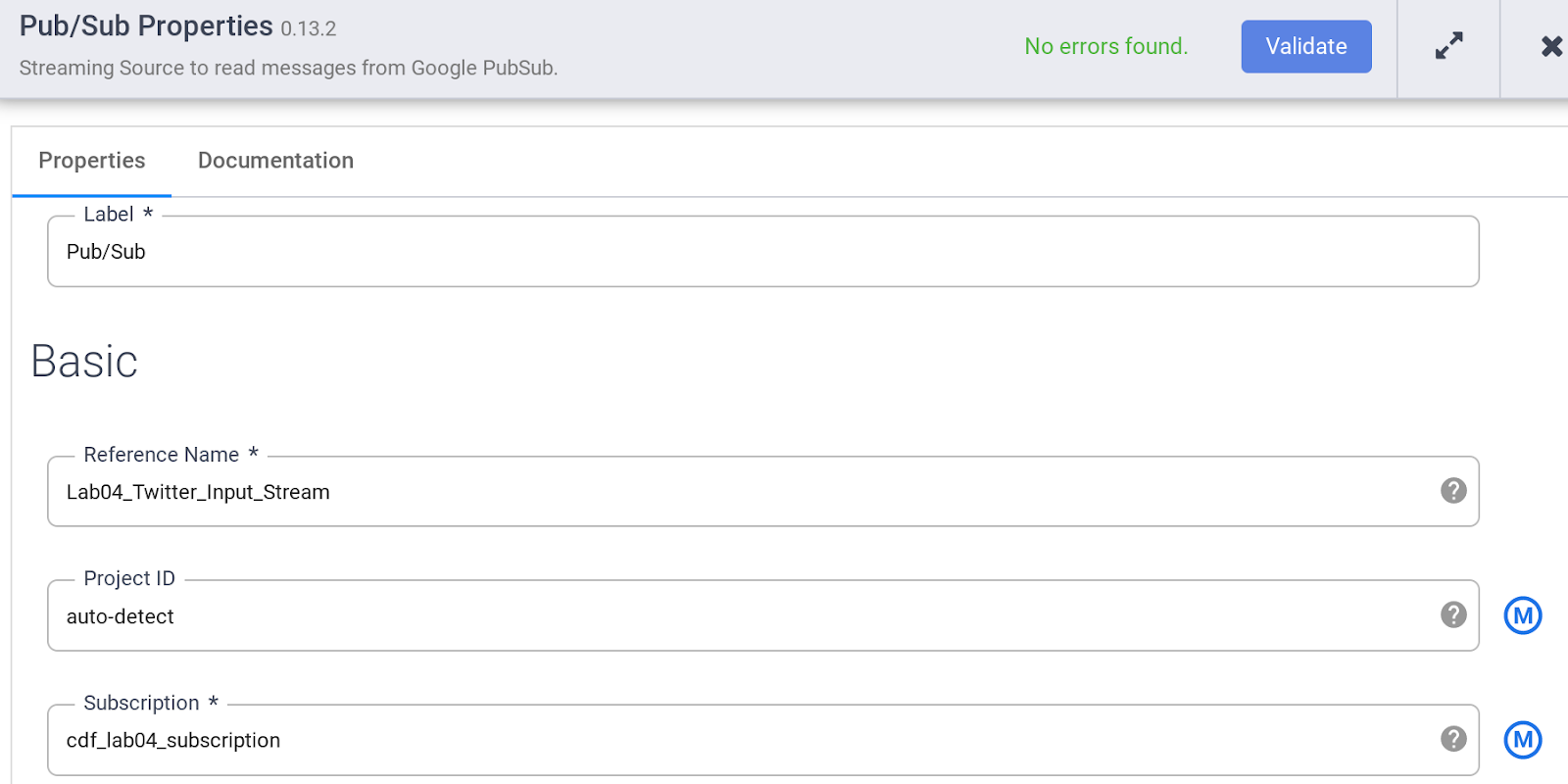
d. Haz clic en X en la parte superior derecha para cerrar el cuadro de propiedades.
- Ahora conecta el nodo de la fuente PubSub al nodo Wrangler que agregaste anteriormente.
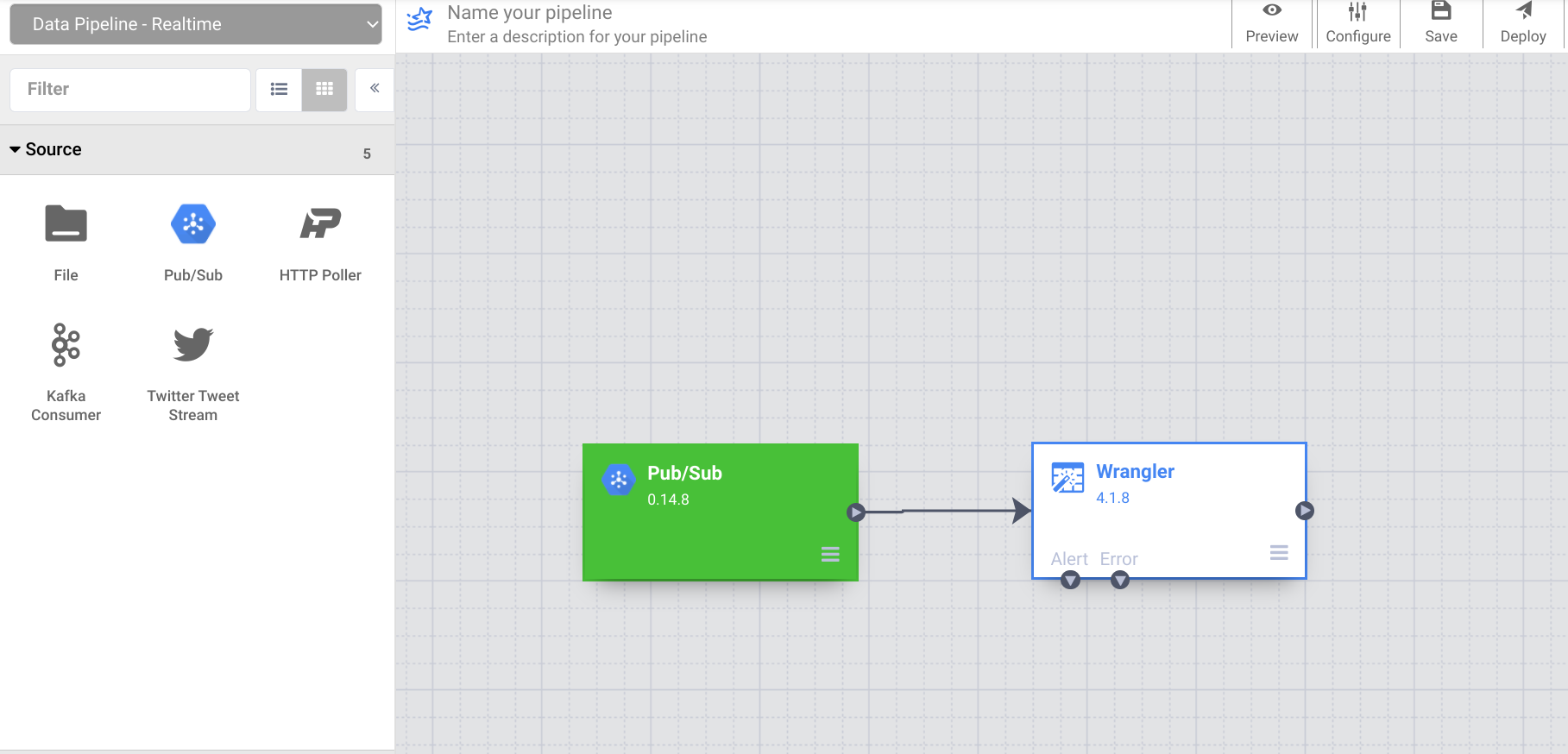
Ten en cuenta que, como antes usaste una muestra de los datos en Wrangler, la columna de origen apareció como body en Wrangler. Sin embargo, la fuente PubSub lo emite en un campo con el nombre message. En el siguiente paso, corregirás esta discrepancia.
- Abre las propiedades de tu nodo de Wrangler y agrega la siguiente directiva en la parte superior de los pasos de transformación existentes:
keep :message
set-charset :message 'utf-8'
rename :message :body
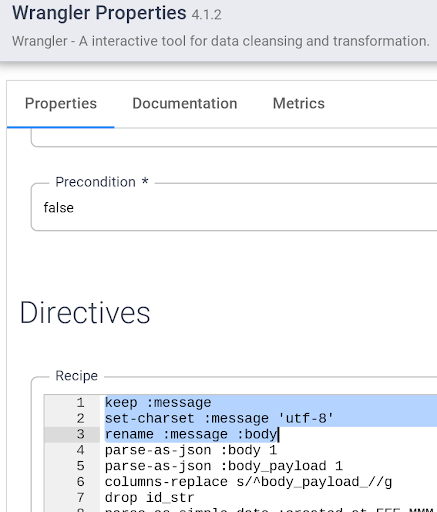
Haz clic en X en la parte superior derecha para cerrar el cuadro de propiedades.
-
Ahora que conectaste una fuente y una transformación a la canalización, complétala agregando un destino. En la sección Receptor del panel lateral izquierdo, elige BigQuery. En el lienzo aparecerá un nodo receptor de BigQuery.
-
Conecta el nodo de Wrangler al de BigQuery arrastrando la flecha del nodo de Wrangler al de BigQuery. A continuación, configurarás las propiedades del nodo de BigQuery.

-
Coloca el cursor sobre el nodo de BigQuery y haz clic en Properties.
a. En Reference name, ingresa realtime_pipeline.
b. En Dataset, ingresa realtime.
c. En Table, ingresa tweets.
d. Haz clic en Validate para asegurarte de que no se encontrarán errores.
-
Haz clic en X en la parte superior derecha para cerrar el cuadro de propiedades.
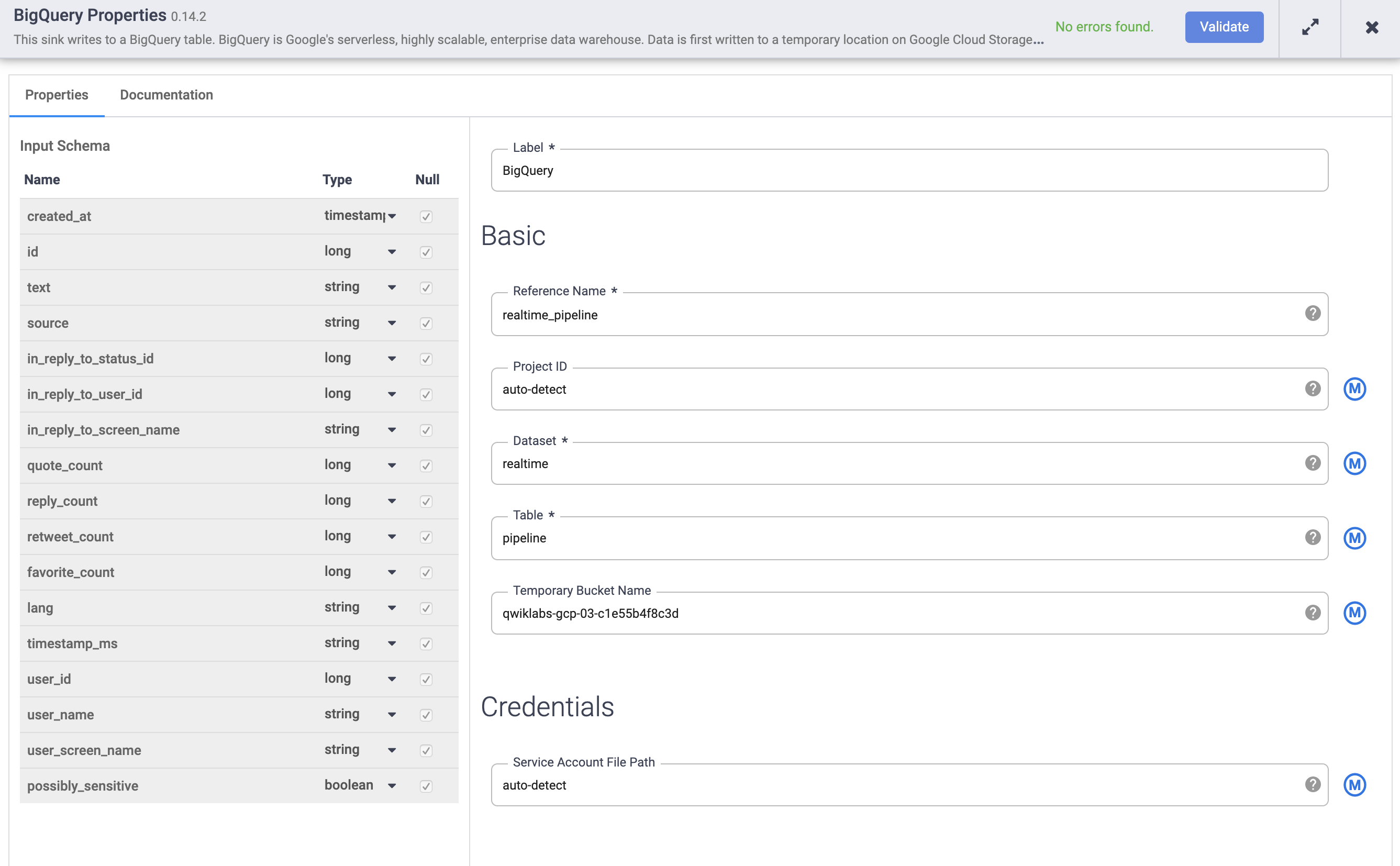
-
Haz clic en Name your pipeline, agrega Realtime_Pipeline como nombre y haz clic en Save.
-
Haz clic en el ícono Deploy y, luego, inicia la canalización.
-
Una vez implementado, haz clic en Run. Espera a que el Estado de la canalización cambie a Running. Esto tardará unos minutos.
Tarea 9: Envía mensajes a Cloud Pub/Sub
Envía eventos cargándolos de forma masiva en la suscripción con la plantilla de Dataflow.
Ahora crearás un trabajo de Dataflow basado en una plantilla para procesar varios mensajes del archivo de tweets y publicarlos en el tema de Pub/Sub creado anteriormente. Usa la plantilla Text Files on Cloud Storage to Pub/Sub en Process Data Continuously (Stream) de la página de creación de trabajos de Dataflow.
-
De vuelta en la consola de Cloud, ve al menú de navegación, haz clic en Ver todos los productos y, en la sección Analytics, haz clic en Dataflow.
-
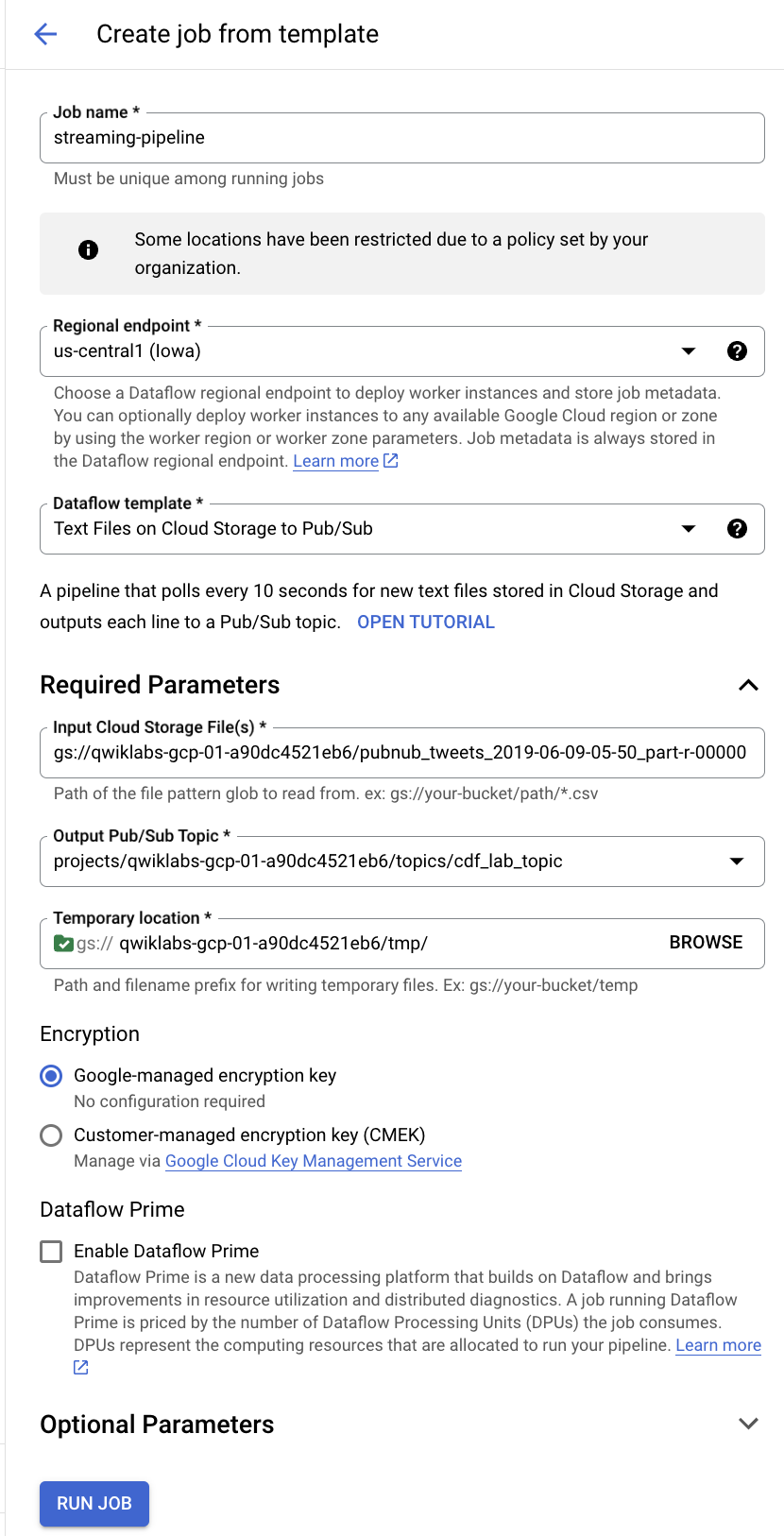
En la barra de menú superior, haz clic en CREAR TRABAJO A PARTIR DE UNA PLANTILLA.
-
Ingresa streaming-pipeline como nombre de tu trabajo en Cloud Dataflow.
-
En Plantilla de Dataflow, selecciona la plantilla Text Files on Cloud Storage to Pub/Sub.
-
En Input Cloud Storage File(s), ingresa gs://<YOUR-BUCKET-NAME>/<FILE-NAME>
Asegúrate de reemplazar <YOUR-BUCKET-NAME> por el nombre de tu bucket y <FILE-NAME> por el nombre del archivo que descargaste antes en tu computadora.
Por ejemplo: gs://qwiklabs-gcp-01-dfdf34926367/pubnub_tweets_2019-06-09-05-50_part-r-00000
- En Output Pub/Sub Topic, ingresa
projects/<PROJECT-ID>/topics/cdf_lab_topic.
Asegúrate de reemplazar PROJECT-ID por tu ID del proyecto real.
- En Ubicación temporal, ingresa
<YOUR-BUCKET-NAME>/tmp/.
Asegúrate de reemplazar <YOUR-BUCKET-NAME> por el nombre de tu bucket.
-
Haz clic en el botón Ejecutar trabajo.
-
Ejecuta el trabajo de Dataflow y espera un par de minutos. Puedes ver mensajes en la suscripción a pubsub y, luego, ver cómo se procesan a través de la canalización de CDF en tiempo real.
Haz clic en Revisar mi progreso para verificar el objetivo.
Crear y ejecutar una canalización de entorno de ejecución
Tarea 10: Visualiza las métricas de tu canalización
En cuanto los eventos se carguen en el tema de Pub/Sub, deberías ver que la canalización los consume. Observa cómo se actualizan las métricas en cada nodo.
¡Felicitaciones!
En este lab, aprendiste a configurar una canalización en tiempo real en Data Fusion que lee mensajes entrantes de transmisión desde Cloud Pub/Sub, procesa los datos y los escribe en BigQuery.
Última actualización del manual: 6 de febrero de 2025
Prueba más reciente del lab: 6 de febrero de 2025
Copyright 2026 Google LLC. Todos los derechos reservados. Google y el logotipo de Google son marcas de Google LLC. El resto de los nombres de productos y empresas pueden ser marcas de las respectivas empresas a las que están asociados.







