







准备工作
- 实验会创建一个 Google Cloud 项目和一些资源,供您使用限定的一段时间
- 实验有时间限制,并且没有暂停功能。如果您中途结束实验,则必须重新开始。
- 在屏幕左上角,点击开始实验即可开始
Load the data
/ 25
Add Cloud Data Fusion API Service Agent role to service account
/ 25
Deploy and execute batch pipeline
/ 25
View the results
/ 25

ETL 是擷取 (Extract)、轉換 (Transform) 和載入 (Load) 的英文縮寫,此概念還有許多不同說法,包括 EL、ELT 和 ELTL。
本實驗室將說明如何使用 Cloud Data Fusion 的 Pipeline Studio,建構 ETL 管道。Pipeline Studio 提供建構區塊和內建外掛程式,可用於逐一串連節點,打造批次管道。您也會使用 Wrangler 外掛程式建構轉換,並套用至流經管道的資料。
ETL 應用程式最常見的資料來源,通常是儲存於逗號分隔值 (CSV) 格式文字檔中的資料,因為許多資料庫系統都會以這種方式匯出及匯入資料。在本實驗室中,您將使用 CSV 檔案,但相同的技術也適用於資料庫來源,以及任何其他可用的資料來源。
輸出內容會寫入 BigQuery 資料表,您將使用標準 SQL,對這個目標資料集執行資料分析。
本實驗室的學習內容包括:
每個實驗室都會提供新的 Google Cloud 專案和一組資源,讓您在時限內免費使用。
請以無痕視窗登入 Google Skills。
請記下實驗室時間限制 (例如 02:00:00),務必在時限內完成作業。
研究室不提供暫停功能。如有需要,您可以重新開始,但原先的進度恕無法保留。
準備就緒之後,請點選「Start Lab」。
請記下研究室憑證 (使用者名稱和密碼),登入 Google Cloud 控制台時會用到。
點選「Open Google console」。
點選「Use another account」,然後複製這個研究室的憑證,並貼到提示中。
如果使用其他憑證,系統會顯示錯誤或向您收取費用。
接受條款,然後略過資源復原頁面。
這個臨時帳戶只在實驗室期間有效,使用時務必遵守下列規定:
 ,即可查看服務清單。
,即可查看服務清單。Cloud Shell 是含有多項開發工具的虛擬機器,提供永久的 5 GB 主目錄,並在 Google Cloud 中運作。Cloud Shell 可讓您透過指令列存取 Google Cloud 資源。gcloud 是 Google Cloud 的指令列工具,已預先安裝於 Cloud Shell,並支援 Tab 鍵完成功能。
在控制台的右上方,點按「啟用 Cloud Shell」按鈕 
點按「繼續」。
請稍候片刻,等待系統完成佈建作業並連線至環境。連線建立後,即代表您已通過驗證,且專案已設為「PROJECT_ID」。
輸出內容
輸出內容範例
輸出內容
輸出內容範例
開始使用 Google Cloud 前,請務必確保專案在 Identity and Access Management (IAM) 中具備正確的權限。
前往 Google Cloud 控制台的「導覽選單」
確認具有預設的運算服務帳戶 {project-number}-compute@developer.gserviceaccount.com,且已指派 editor 角色。帳戶前置字串為專案編號,如需查看,請前往「導覽選單」>「Cloud 總覽」。
如果帳戶未顯示在 IAM 中,或沒有 editor 角色,請依照下列步驟指派必要角色。
前往 Google Cloud 控制台,依序點選「導覽選單」>「Cloud 總覽」。
從「專案資訊」資訊卡複製「專案編號」。
從「導覽選單」依序點選「IAM 與管理」>「身分與存取權管理」。
點選「身分與存取權管理」頁面頂端的「新增」。
在「新增主體」輸入:
將 {project-number} 換成您的專案編號。
從「請選擇角色」選單依序選取「基本」或「專案」>「編輯者」。
點選「儲存」。
在這項工作中,您將於專案內建立 Cloud Storage bucket,並暫存一個 CSV 檔案。Cloud Data Fusion 之後會從這個儲存空間 bucket 讀取資料。
所建 bucket 的名稱就是專案 ID。
點選「Check my progress」,確認目標已達成。
在這項工作中,您會將必要的 IAM 角色,授予與 Cloud Data Fusion 執行個體相關聯的服務帳戶。
在 Google Cloud 控制台中的「導覽選單」上,依序點選「IAM 與管理」>「身分與存取權管理」。
找出 Compute Engine 預設的服務帳戶 {專案編號}-compute@developer.gserviceaccount.com,然後將該服務帳戶複製到剪貼簿。
在「IAM 權限」頁面中,按一下「+ 授予存取權」。
在「新增主體」欄位貼上服務帳戶。
在「選取角色」部分,輸入 Cloud Data Fusion API 服務代理,然後選取該角色。
點選「+ 新增其他角色」。
在「選取角色」部分,選取「Dataproc 管理員」角色。
按一下「儲存」。
點選「Check my progress」,確認目標已達成。
前往控制台,依序點選「導覽選單」圖示 >「IAM 與管理」>「身分與存取權管理」。
勾選「包含 Google 提供的角色授予項目」核取方塊。
向下捲動清單,找到 Google 代管的 Cloud Data Fusion 服務帳戶 (格式為 service-{project-number}@gcp-sa-datafusion.iam.gserviceaccount.com),然後將該帳戶的名稱複製到剪貼簿。
接著,依序點選「IAM 與管理」>「服務帳戶」。
點選預設的 Compute Engine 帳戶 (格式為 {project-number}-compute@developer.gserviceaccount.com),然後選取頂端導覽面板中的「具備存取權的主體」分頁標籤。
點選「授予存取權」按鈕。
在「新增主體」欄位,貼上先前複製的服務帳戶名稱。
在「角色」下拉式選單,選取「服務帳戶使用者」。
點選「儲存」。
在這項工作中,您將使用 Cloud Data Fusion 的 Wrangler 元件,準備及清理原始資料,過程中需要反覆修改調整,但您可以即時查看轉換結果。
前往 Google Cloud 控制台,依序點選「導覽選單」>「Data Fusion」>「執行個體」。
針對執行個體,按一下「查看執行個體」。如果系統提示您使用實驗室憑證登入,請照著做。如果出現導覽提示,請點選「不用了,謝謝」。
在 Cloud Data Fusion UI 的「導覽選單」中,點選「Wrangler」。
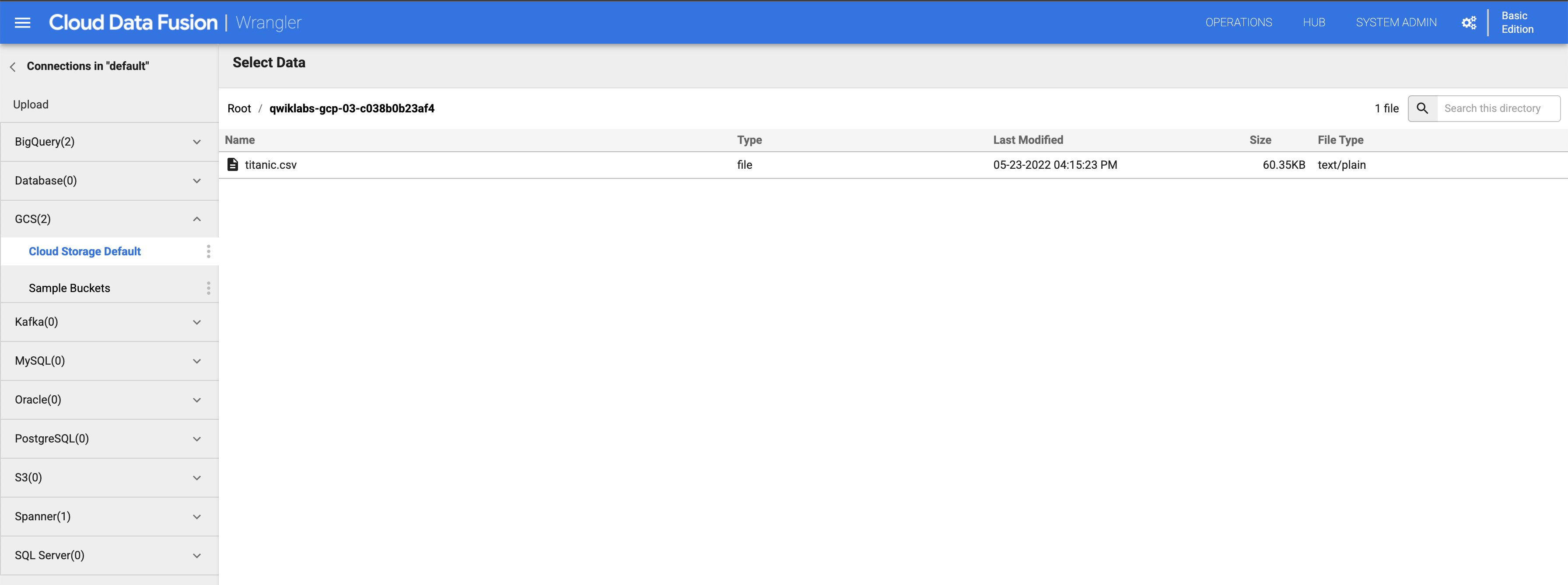
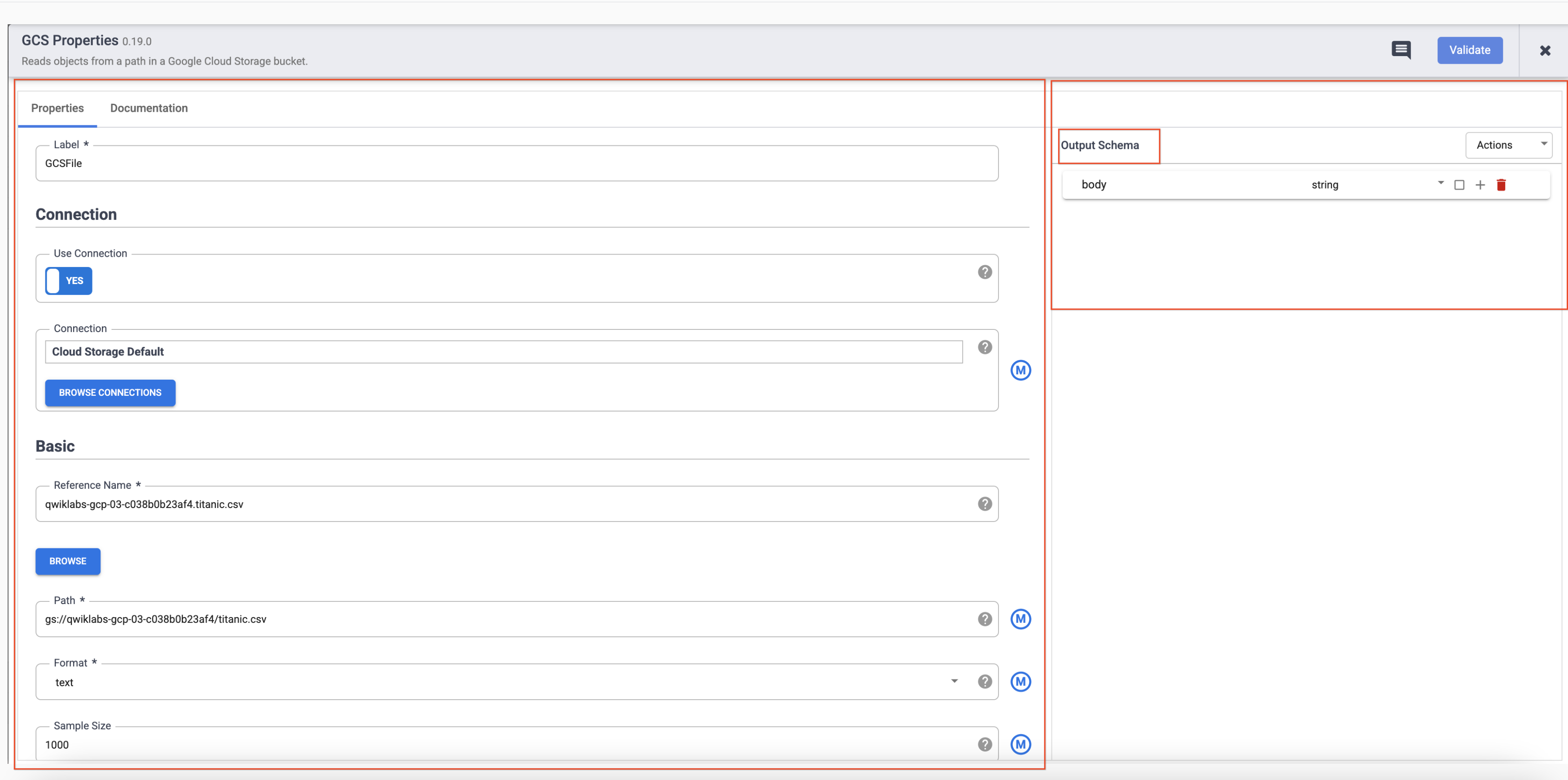
在左側面板點選「(GCS) Google Cloud Storage」,然後選取「Cloud Storage Default」。
點選與專案 ID 對應的 bucket。
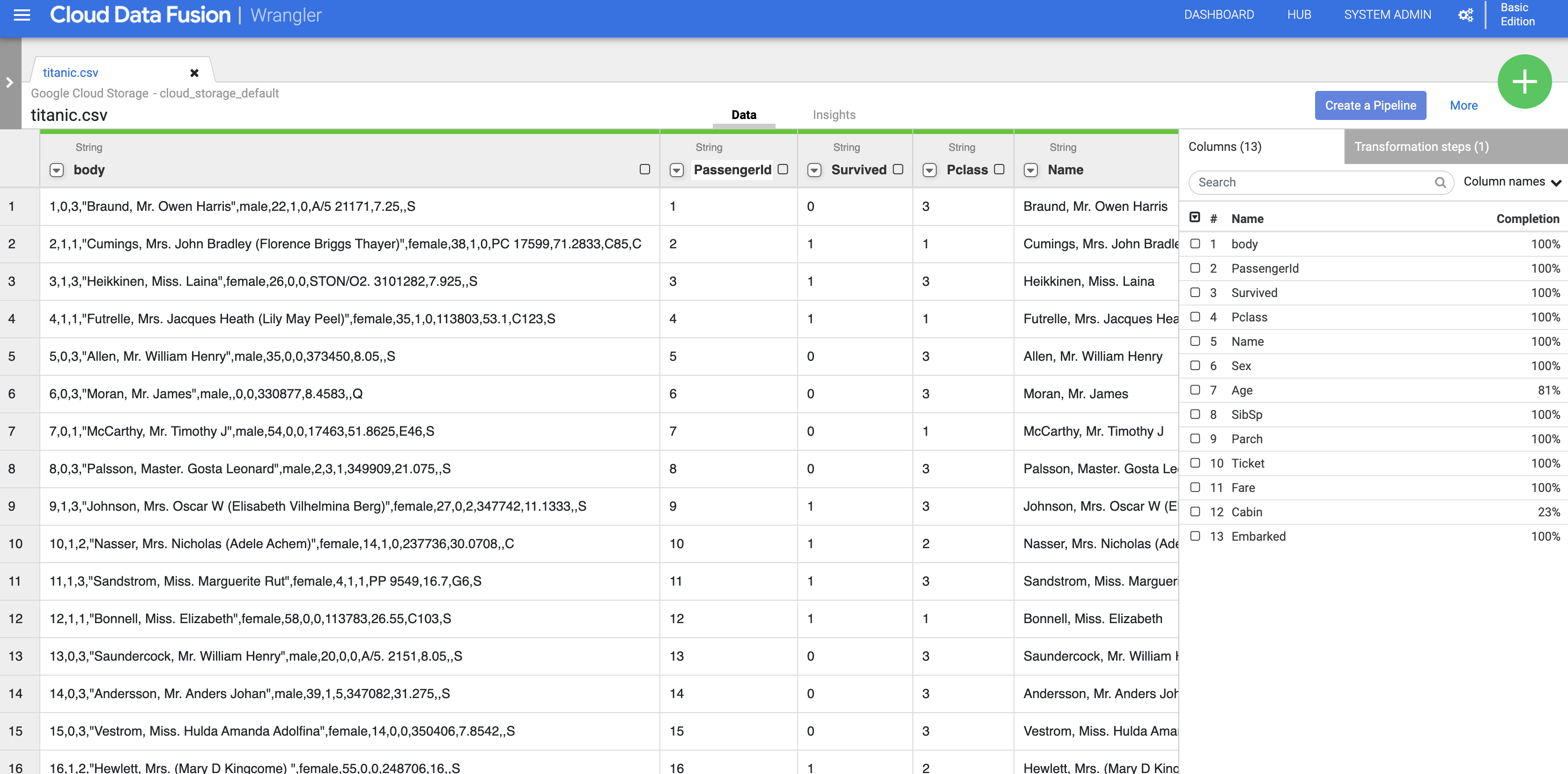
點選「titanic.csv」。
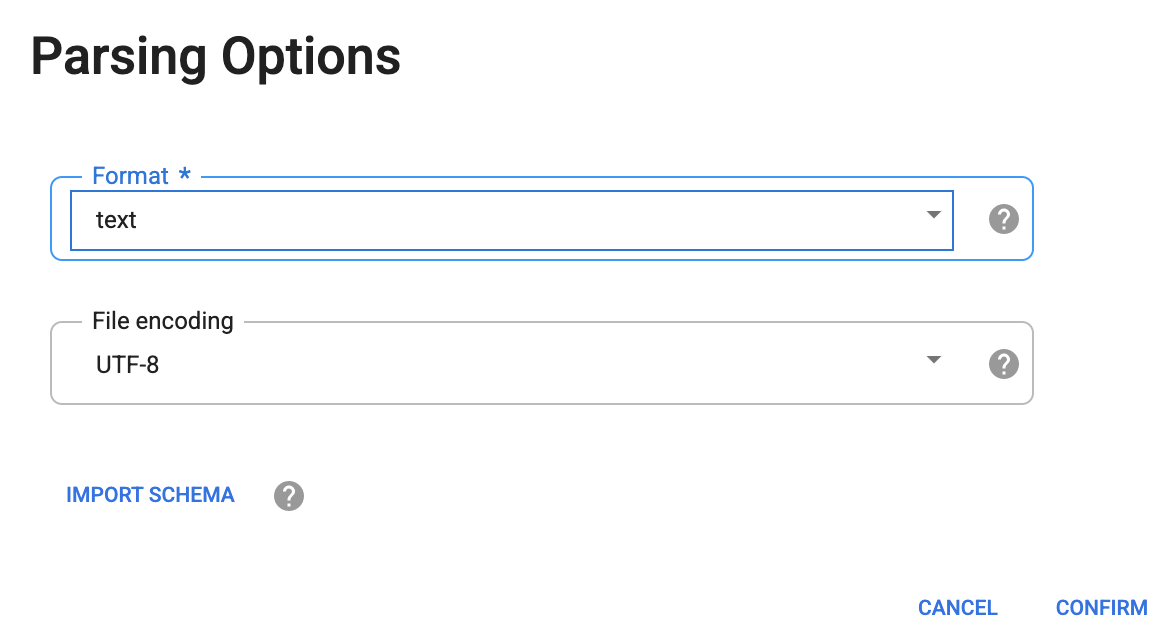
在「Parsing Options」對話方塊的「格式」部分,選取「文字」,然後點選「確認」。
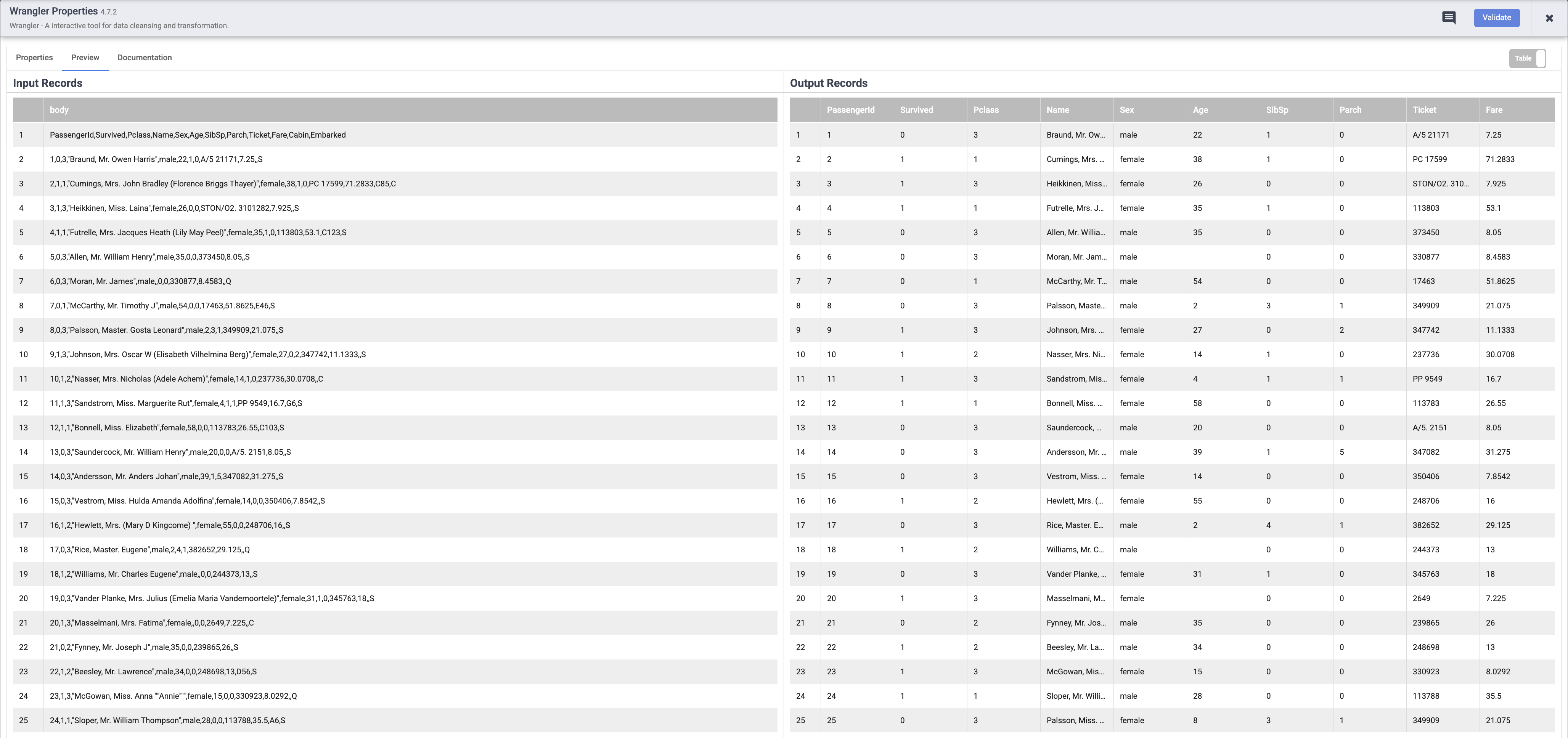
資料會載入 Wrangler 畫面。現在,您可以開始套用並疊代調整資料轉換了。
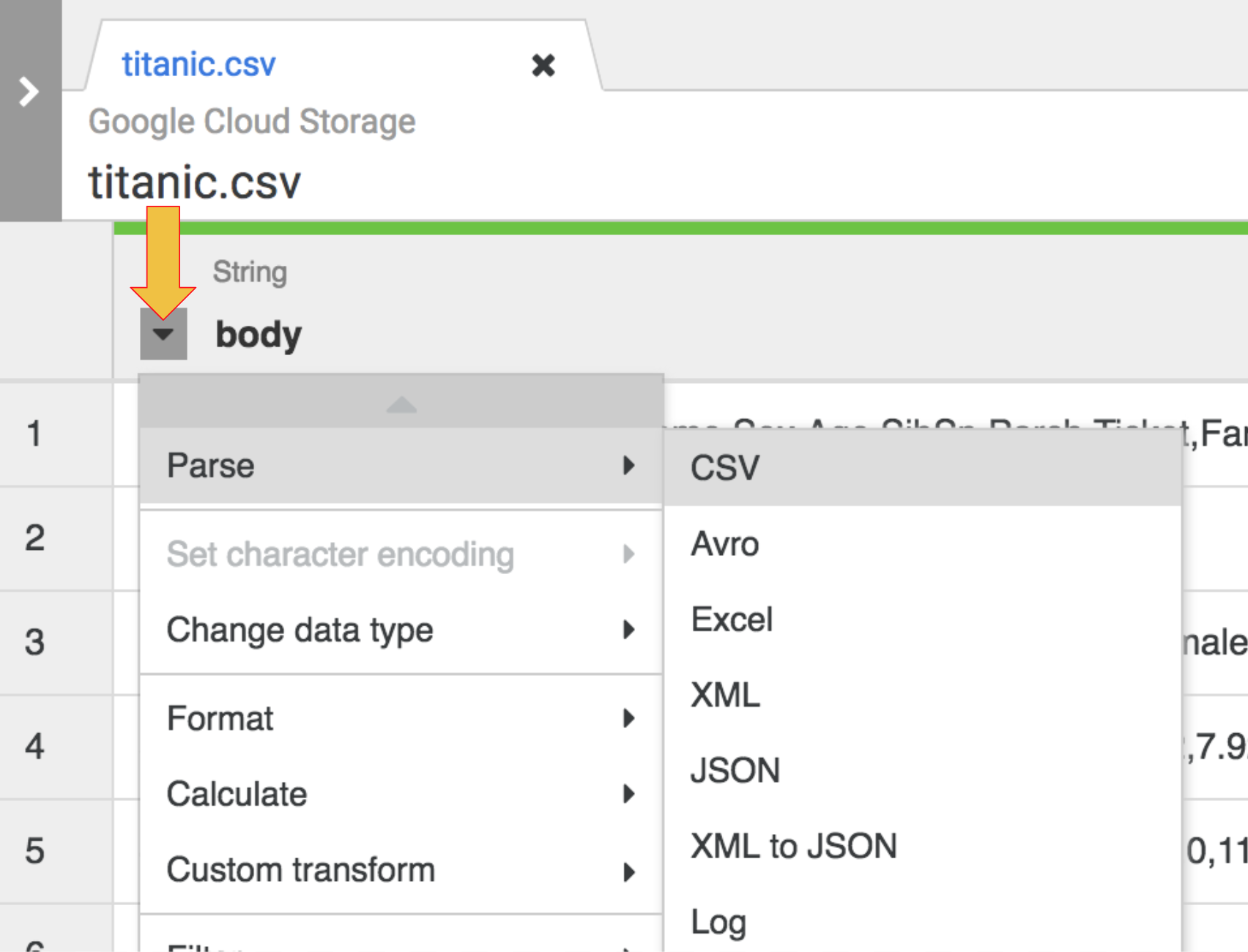
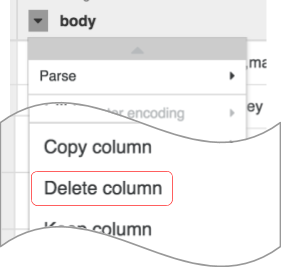
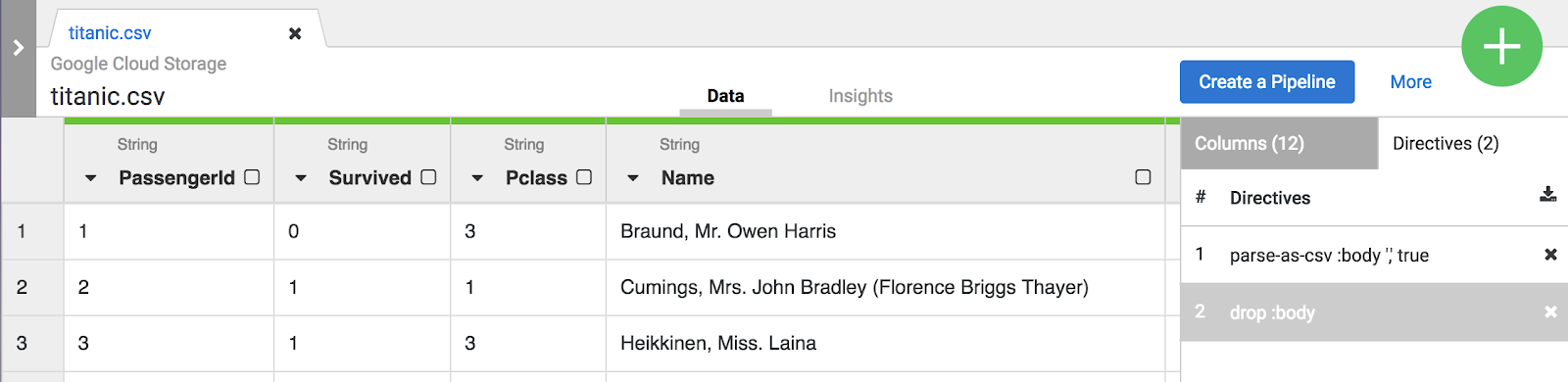
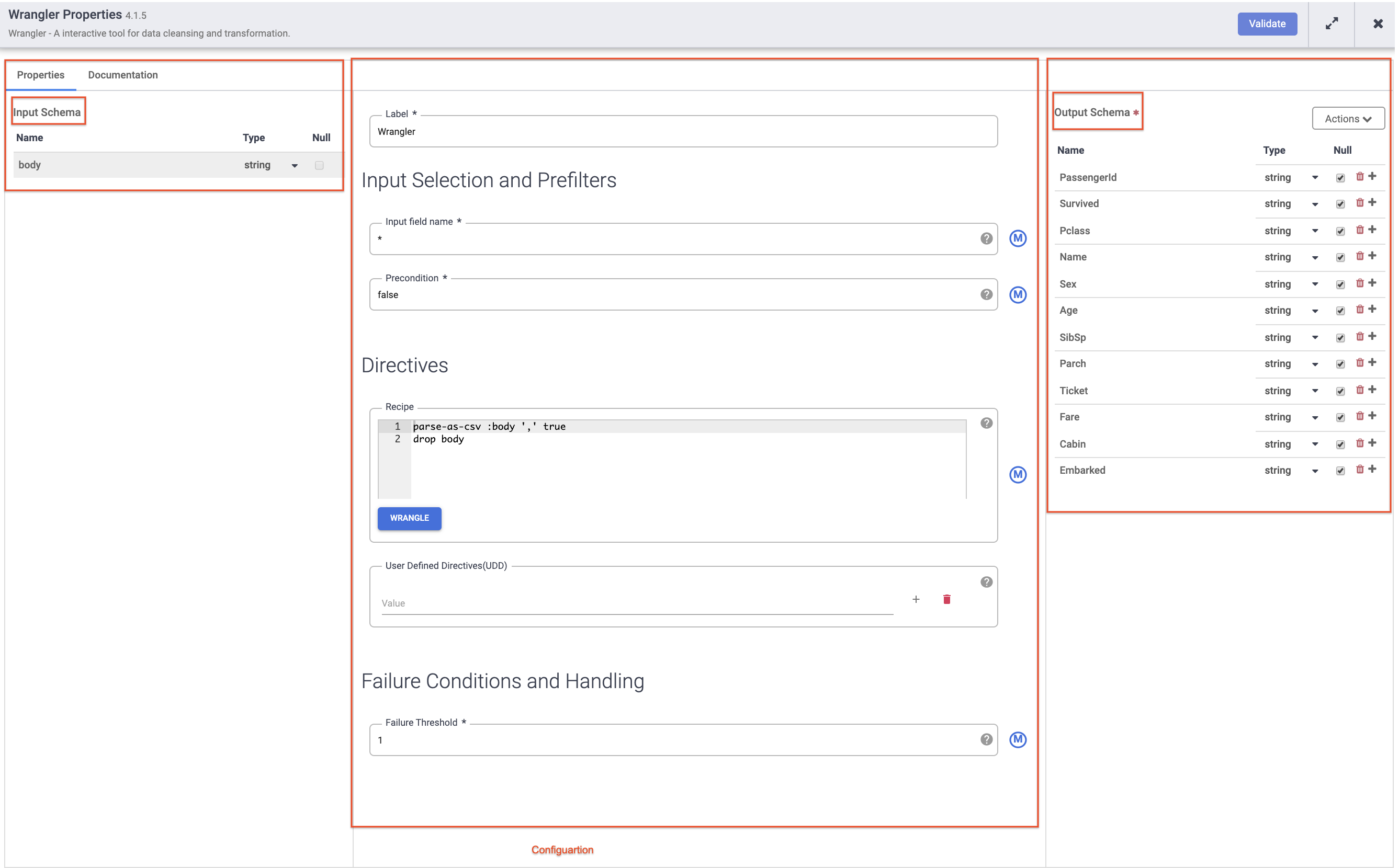
如要將原始 CSV 資料剖析為表格格式,請點選「body」欄標題旁的箭頭,然後依序選取「剖析」和「CSV」。
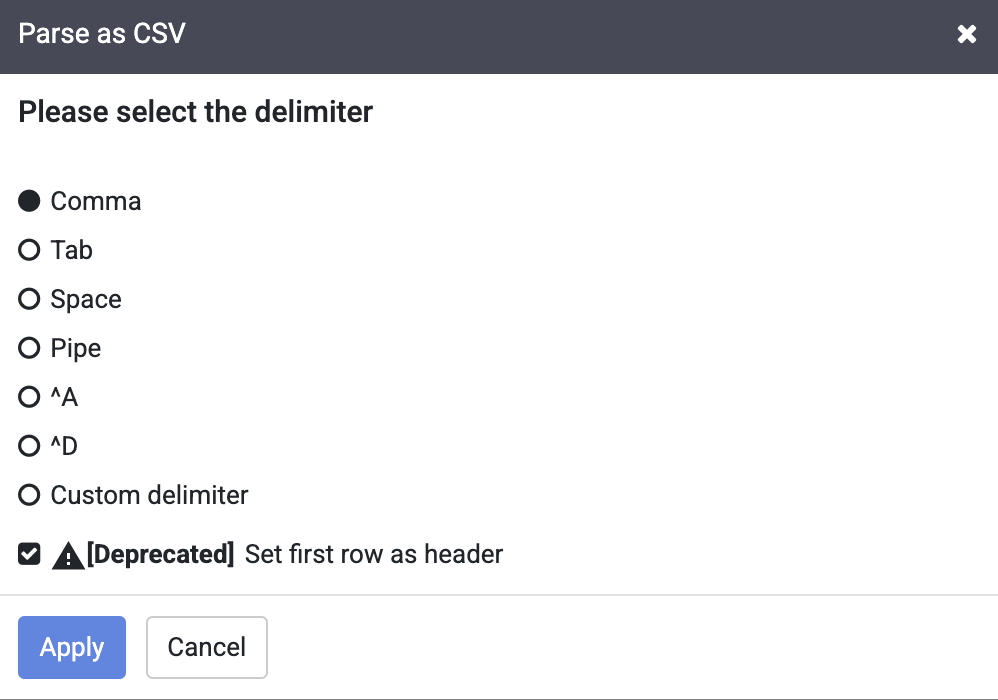
在「Parse as CSV」對話方塊中,勾選「Set first row as header」核取方塊,然後點選「套用」。
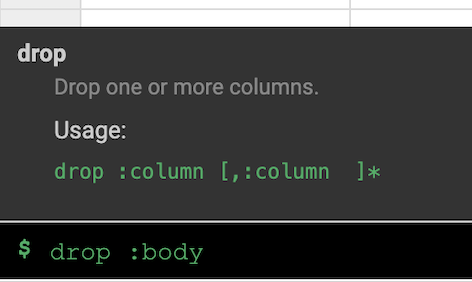
drop :body 指令。
在本實驗室中,這兩項轉換 (或 recipe) 便足以建立 ETL 管道。下一步是在管道建構步驟中納入這個 recipe,代表 ETL 中的 T。
點選「建立管道」按鈕,前往下一節建立管道,瞭解 ETL 管道的整體運作方式。
在下一個對話方塊中,選取「Batch pipeline」即可繼續。
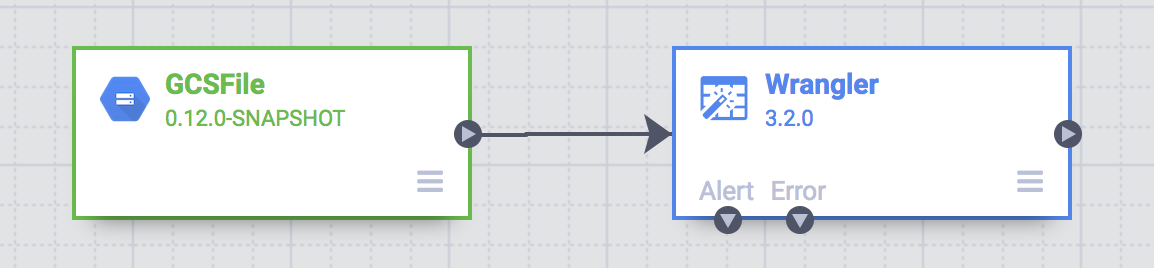
剩餘的管道建構工作會在 Pipeline Studio 中進行,相應 UI 可讓您以視覺化方式編寫資料管道。現在,您應會在工作室中看到 ETL 管道的主要建構區塊。
目前,管道中會顯示兩個節點:GCS File 外掛程式會從 Google Cloud Storage 讀取 CSV 檔案;Wrangler 外掛程式則包含轉換 recipe。
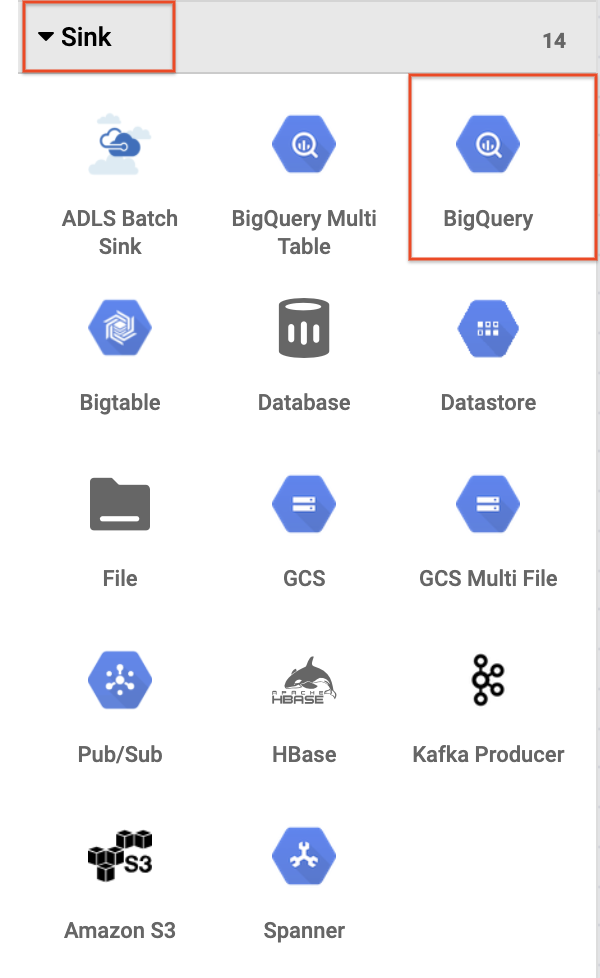
這兩個外掛程式 (節點) 代表 ETL 管道中的 E 和 T。如要完成這個管道,請新增 BigQuery 接收器,也就是 ETL 中的 L。
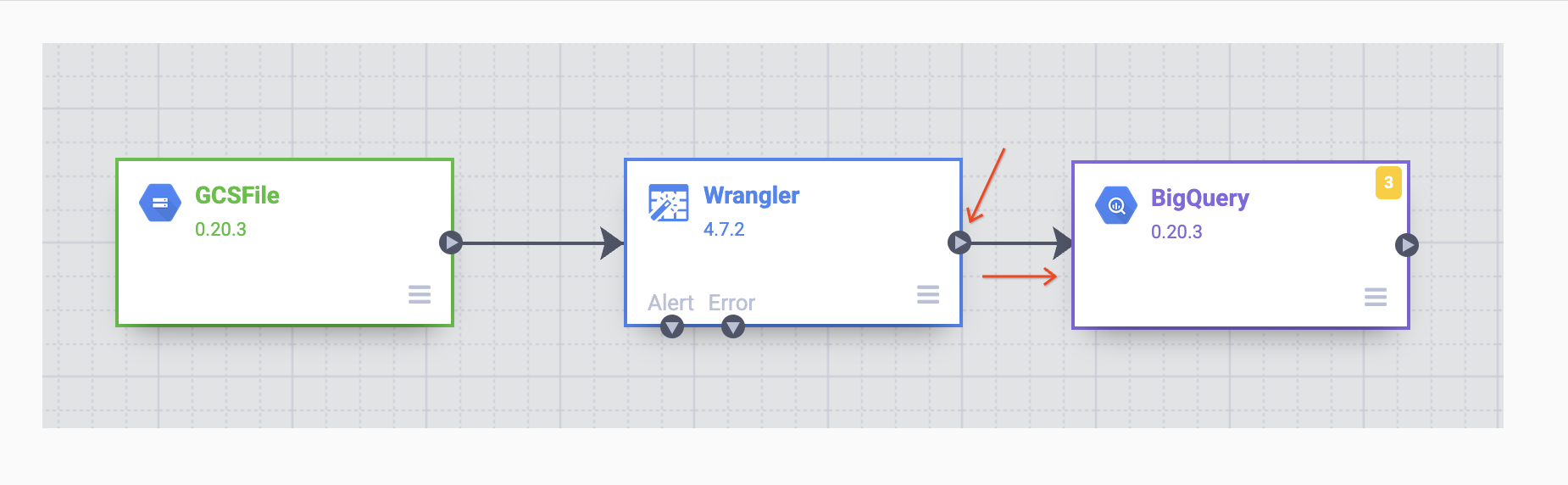
完成後,將 Wrangler 節點連結至 BigQuery 節點,方法是將 Wrangler 節點上的箭頭,拖曳至 BigQuery 節點,如下圖所示。接下來只要指定一些設定選項,就能將資料寫入所需的資料集了。
現在可以設定管道了,方法是開啟每個節點的屬性,確認相關設定,並/或做出額外調整。
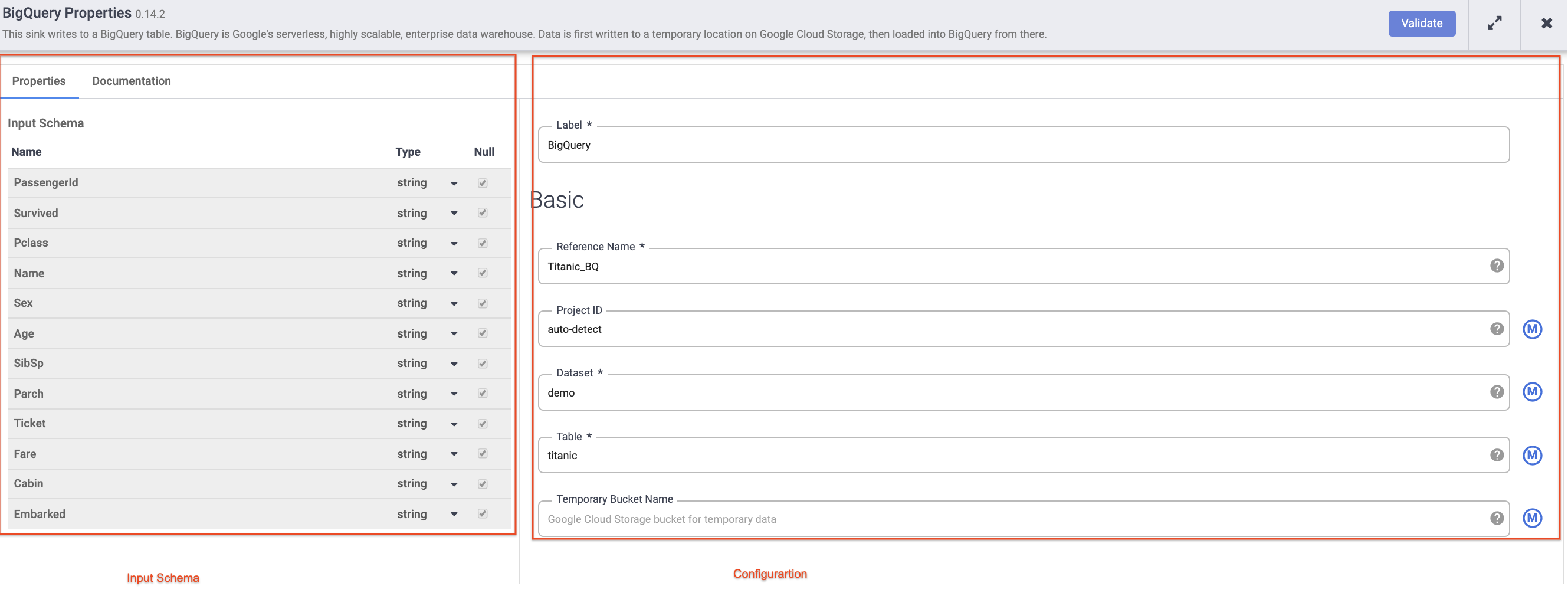
每個外掛程式都有幾個必填欄位,會以星號 (*) 標示。視使用的外掛程式而定,您可能會看到左側的「輸入內容的結構定義」、中間的「設定」部分,以及右側的「輸出內容的結構定義」。
您會發現「接收器」外掛程式沒有輸出內容的結構定義,而「來源」外掛程式沒有輸入內容的結構定義。不過,這兩個外掛程式也都有必填的「參照名稱」欄位,用來識別歷程的資料來源/接收器。
每個外掛程式都會有「標籤」欄位,用於設定資料畫布上顯示管道時,您所看到的節點標籤。
點選右上方的「X」關閉「屬性」方塊。
接著將滑鼠游標懸停在「Wrangler」節點上,然後點選「屬性」。
點選右上方的「X」關閉「屬性」方塊。
將滑鼠游標懸停在 BigQuery 節點上,點選「屬性」,然後輸入下列設定資訊:
在「參照名稱」部分,輸入 Titanic_BQ。
在「資料集」部分,輸入 demo。
在「資料表」部分,輸入 titanic。
點選右上方的「X」關閉「屬性」方塊。
接下來要測試管道能否正常運作。不過在測試前,請務必先命名並儲存草稿,以免工作進度遺失。
點選右上角選單中的「儲存」。系統會提示您命名管道並新增說明。
ETL-batch-pipeline 做為管道名稱。ETL pipeline to parse CSV, transform and write output to BigQuery。按一下「儲存」。
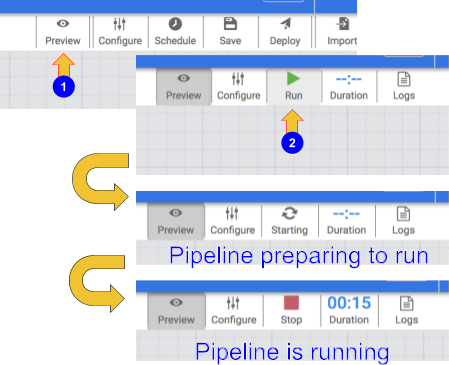
點選「預覽」圖示,測試管道。按鈕列現在會顯示「執行」圖示,點選該圖示,即可在預覽模式下執行管道。
點選「執行」圖示。在預覽模式下執行管道時,實際上不會有任何資料寫入 BigQuery 資料表,但您可以確認資料讀取作業是否正常,以及在部署管道後,資料是否會如預期寫入。「預覽」按鈕是切換鈕,因此完成操作後,請務必再次點選該按鈕,才能退出預覽模式。
管道執行完畢後,將滑鼠游標懸停在 Wrangler 節點上,然後依序點選「屬性」>「預覽」分頁標籤。如果一切順利,您應會看到來自輸入內容 (左側節點) 的原始資料,以及將做為輸出內容發送至右側節點的剖析記錄。請按一下右上方的「X」關閉「屬性」方塊。
再次點選「預覽」圖示,退出預覽模式。
如果目前為止一切順利,您便可繼續部署管道,方法是點選右上方的「部署」圖示 
您會看到確認對話方塊,說明系統正在部署管道:
成功部署後,您就能執行 ETL 管道,將部分資料載入 BigQuery。
點選「執行」圖示,執行 ETL 工作。
完成後,您應該會看到管道狀態變更為「已成功」,表示管道已順利執行。
處理資料時,管道中的各個節點會顯示指標,指出已處理的記錄筆數。 在這項剖析作業中,系統顯示 892 筆記錄,但來源中卻有 893 筆記錄,這是怎麼回事?剖析作業會擷取第一列的資料,用於設定欄標題,因此剩下可處理的資料才會變成 892 筆。
點選「Check my progress」,確認目標已達成
這個管道會將輸出內容寫入 BigQuery 資料表。您可以按照下列步驟確認。
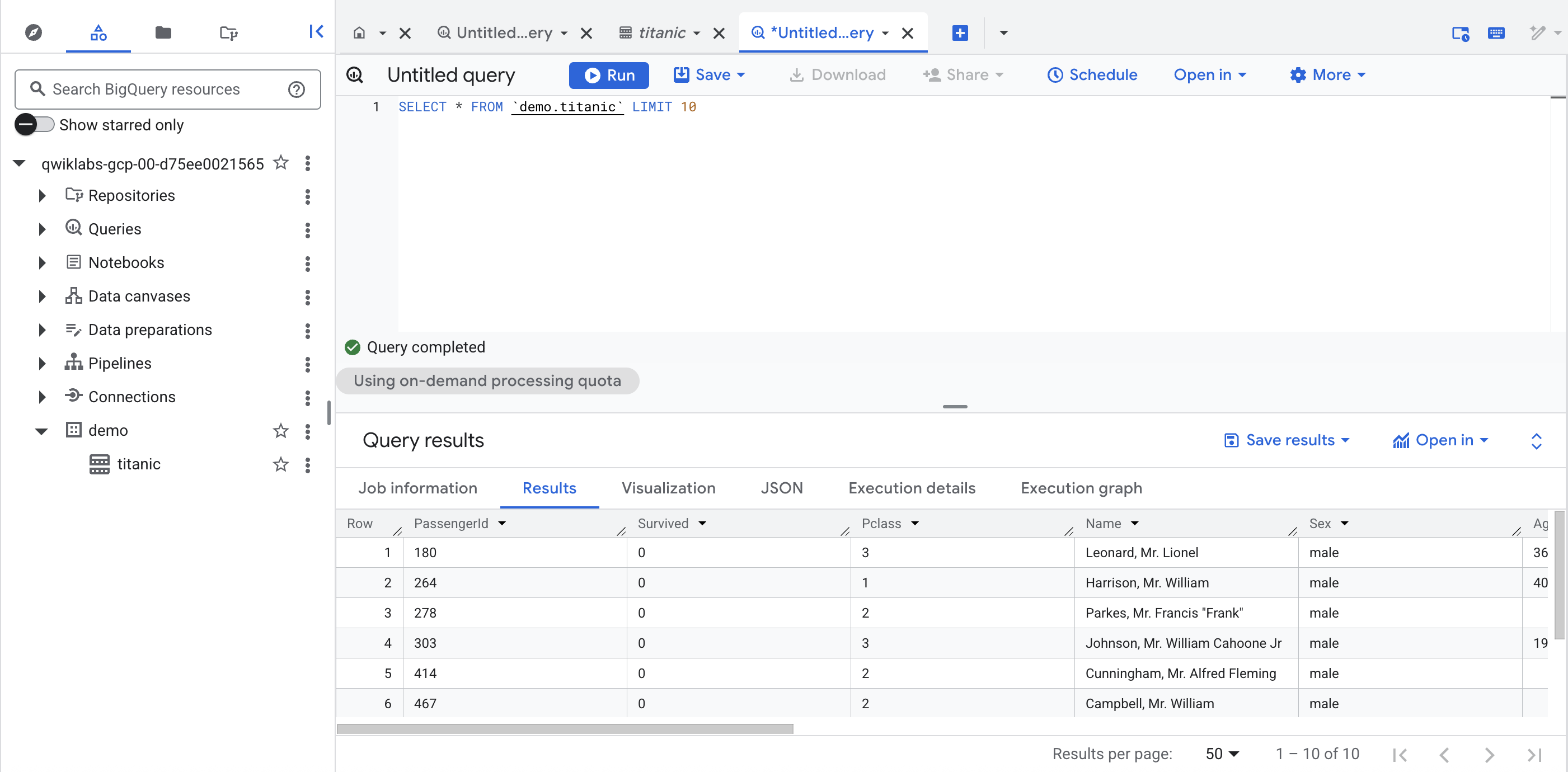
在新的分頁中,前往 Cloud 控制台開啟 BigQuery UI,或在控制台分頁上按一下滑鼠右鍵,然後選取「複製」,再使用「導覽選單」選取「BigQuery」。看到系統提示後,請點選「完成」。
在左側窗格的「傳統版 Explorer」部分,點選您的專案 ID (開頭為 qwiklabs)。
在專案的「demo」資料集下方,點選「titanic」資料表,然後按一下「+」(SQL 查詢),執行簡單的查詢,例如:
點選「Check my progress」,確認目標已達成
您已學會使用 Cloud Data Fusion Pipeline Studio 中的建構區塊,建立批次管道;也瞭解了如何透過 Wrangler 建立資料的轉換步驟。
請繼續進行「在 Cloud Data Fusion 運用 Wrangler 建構轉換並準備資料」實驗室。
使用手冊上次更新日期:2026 年 1 月 27 日
實驗室上次測試日期:2026 年 1 月 27 日
Copyright 2026 Google LLC 保留所有權利。Google 和 Google 標誌是 Google LLC 的商標,其他公司和產品名稱則有可能是其關聯公司的商標。



此内容目前不可用
一旦可用,我们会通过电子邮件告知您

太好了!
一旦可用,我们会通过电子邮件告知您

一次一个实验
确认结束所有现有实验并开始此实验