



![[Parsing Options] ダイアログ](https://cdn.qwiklabs.com/YWitruSJtk4eU7YWbqIbiRF53g3I0zVr%2FR6aXtaTsg4%3D)
![Google Cloud Storage の [Parse] > [CSV] メニューの選択](https://cdn.qwiklabs.com/U2JDntxc%2FKfpY47AWLlHPZWUtpHkQrQ1BwYOtecjk70%3D)
![[Parse as CSV] ダイアログ](https://cdn.qwiklabs.com/UaRCX3vSfOplsM91VA29SD53B03rs9OsIU72lN6OcJs%3D)
![[Delete column] メニューの選択](https://cdn.qwiklabs.com/1roWESY1p7e7MHZNuWbG9VAfCMbPFe5ZFXrah5KNqqg%3D)
![CLI の [body] 列を削除するための構文](https://cdn.qwiklabs.com/NMfudgFYncqXKcUtL2WQ3BuneTTu%2FGo%2FLZ9wynboUYQ%3D)
![[Create a Pipeline] ボタン](https://cdn.qwiklabs.com/lUy5RN7iRThwjRx3xooXoOuwQjL1Y6Gfc0UwqmpV7qI%3D)
![[Batch pipeline] の選択](https://cdn.qwiklabs.com/%2FViwOJ%2FDd%2BjbAc%2BPWmxo0QoRE%2FK8zl6uJN84JKEr%2BUk%3D)
![[Sink] セクションの BigQuery](https://cdn.qwiklabs.com/YNHYyeLxih%2BqC6ZfZLZlvbgL6nkpH7JOXuHIwfpEzMo%3D)
![GCS ノードの [Properties] ダイアログ](https://cdn.qwiklabs.com/%2FbMIQ%2BEK24cO4TVcKEfovxdiFX6aCg%2F4xkDttxzmcAk%3D)
![Wrangler ノードの [Properties] ダイアログ](https://cdn.qwiklabs.com/J0qF27H2pb%2BP9iNlTb%2Fj0KsJbNhTQO93HJiPd5Bvmy8%3D)
![[BigQuery Properties] ダイアログ](https://cdn.qwiklabs.com/%2F6lyJKoHOk2dYXvg9oL0rnzBBdXvnPa9szCoFZrni5s%3D)



始める前に
- ラボでは、Google Cloud プロジェクトとリソースを一定の時間利用します
- ラボには時間制限があり、一時停止機能はありません。ラボを終了した場合は、最初からやり直す必要があります。
- 画面左上の [ラボを開始] をクリックして開始します
Load the data
/ 25
Add Cloud Data Fusion API Service Agent role to service account
/ 25
Deploy and execute batch pipeline
/ 25
View the results
/ 25
Load the data
/ 25
Add Cloud Data Fusion API Service Agent role to service account
/ 25
Deploy and execute batch pipeline
/ 25
View the results
/ 25
ETL は、Extract(抽出)、Transform(変換)、Load(読み込み)の略語です。このコンセプトは、EL、ELT、ELTL などと表現される場合もあります。
このラボでは、Cloud Data Fusion の Pipeline Studio を使用して ETL パイプラインを構築する方法を学びます。Pipeline Studio に表示される構成要素と組み込みのプラグインを使用して、バッチ パイプラインをノード単位で構築します。また、Wrangler プラグインを使用して変換を構築し、パイプラインを通過するデータに適用します。
ETL アプリケーションで最もよく使用されるデータソースは、カンマ区切り値(CSV)形式のテキスト ファイルに保存されたデータです。これは、多くのデータベース システムにおいてこの形式でデータのエクスポートやインポートが行われるためです。このラボでは CSV ファイルを使用しますが、データベース ソースやその他の任意のデータソースに対しても、ここで使用する手法を適用できます。
出力は BigQuery テーブルに書き込まれます。また、このターゲット データセットを対象としたデータ分析には標準 SQL を使用します。
このラボでは、次の方法について学びます。
各ラボでは、新しい Google Cloud プロジェクトとリソースセットを一定時間無料で利用できます。
シークレット ウィンドウを使用して Google Skills にログインします。
ラボのアクセス時間(例: 02:00:00)に注意し、時間内に完了できるようにしてください。
一時停止機能はありません。必要な場合はやり直せますが、最初からになります。
準備ができたら、[ラボを開始] をクリックします。
ラボの認証情報(ユーザー名とパスワード)をメモしておきます。この情報は、Google Cloud コンソールにログインする際に使用します。
[Google Console を開く] をクリックします。
[別のアカウントを使用] をクリックし、このラボの認証情報をコピーしてプロンプトに貼り付けます。
他の認証情報を使用すると、エラーが発生したり、料金の請求が発生したりします。
利用規約に同意し、再設定用のリソースページをスキップします。
[ラボを開始] ボタンをクリックします。ラボの料金をお支払いいただく必要がある場合は、表示されるダイアログでお支払い方法を選択してください。 左側の [ラボの詳細] ペインには、以下が表示されます。
[Google Cloud コンソールを開く] をクリックします(Chrome ブラウザを使用している場合は、右クリックして [シークレット ウィンドウで開く] を選択します)。
ラボでリソースがスピンアップし、別のタブで [ログイン] ページが表示されます。
ヒント: タブをそれぞれ別のウィンドウで開き、並べて表示しておきましょう。
必要に応じて、下のユーザー名をコピーして、[ログイン] ダイアログに貼り付けます。
[ラボの詳細] ペインでもユーザー名を確認できます。
[次へ] をクリックします。
以下のパスワードをコピーして、[ようこそ] ダイアログに貼り付けます。
[ラボの詳細] ペインでもパスワードを確認できます。
[次へ] をクリックします。
その後次のように進みます。
その後、このタブで Google Cloud コンソールが開きます。

Cloud Shell は、開発ツールが組み込まれた仮想マシンです。5 GB の永続ホーム ディレクトリを提供し、Google Cloud 上で実行されます。Cloud Shell を使用すると、コマンドラインで Google Cloud リソースにアクセスできます。gcloud は Google Cloud のコマンドライン ツールで、Cloud Shell にプリインストールされており、Tab キーによる入力補完がサポートされています。
Google Cloud Console のナビゲーション パネルで、「Cloud Shell をアクティブにする」アイコン(
[次へ] をクリックします。
環境がプロビジョニングされ、接続されるまでしばらく待ちます。接続の際に認証も行われ、プロジェクトは現在のプロジェクト ID に設定されます。次に例を示します。
有効なアカウント名前を一覧表示する:
(出力)
(出力例)
プロジェクト ID を一覧表示する:
(出力)
(出力例)
Google Cloud で作業を開始する前に、Identity and Access Management(IAM)内で適切な権限がプロジェクトに付与されていることを確認する必要があります。
Google Cloud コンソールのナビゲーション メニュー(
Compute Engine のデフォルトのサービス アカウント {project-number}-compute@developer.gserviceaccount.com が存在し、編集者のロールが割り当てられていることを確認します。アカウントの接頭辞はプロジェクト番号で、ナビゲーション メニュー > [Cloud の概要] から確認できます。
アカウントが IAM に存在しない場合やアカウントに編集者のロールがない場合は、以下の手順に沿って必要なロールを割り当てます。
Google Cloud コンソールのナビゲーション メニューで、[Cloud の概要] をクリックします。
[プロジェクト情報] カードからプロジェクト番号をコピーします。
ナビゲーション メニューで、[IAM と管理] > [IAM] をクリックします。
IAM ページの上部にある [追加] をクリックします。
新しいプリンシパルの場合は、次のように入力します。
{project-number} はプロジェクト番号に置き換えてください。
[ロールを選択] で、[基本](または [Project])> [編集者] を選択します。
[保存] をクリックします。
このタスクでは、プロジェクトに Cloud Storage バケットを作成し、CSV ファイルをステージングします。Cloud Data Fusion はこの Storage バケットからデータを読み取ることになります。
作成されるバケットの名前には、現在のプロジェクト ID が使用されます。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
このタスクでは、Cloud Data Fusion インスタンスに関連付けられたサービス アカウントに、必要な IAM ロールを付与します。
Google Cloud コンソールのナビゲーション メニューで、[IAM と管理] > [IAM] をクリックします。
Compute Engine のデフォルトのサービス アカウント {プロジェクト番号}-compute@developer.gserviceaccount.com を見つけ、そのサービス アカウントをクリップボードにコピーします。
[IAM 権限] ページで、[+アクセスを許可] をクリックします。
[新しいプリンシパル] フィールドに、サービス アカウントを貼り付けます。
[ロールを選択] で、「Cloud Data Fusion API サービス エージェント」と入力し、そのロールを選択します。
[+ 別のロールを追加] をクリックします。
[ロールを選択] で、[Managed Service for Spark 管理者] ロールを選択します。
[Save] をクリックします。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
コンソールのナビゲーション メニューで、[IAM と管理] > [IAM] をクリックします。
[Google 提供のロール付与を含める] チェックボックスをオンにします。
リストを下にスクロールして、Google が管理する service-{project-number}@gcp-sa-datafusion.iam.gserviceaccount.com という表示形式の Cloud Data Fusion サービス アカウントを探し、サービス アカウント名をクリップボードにコピーします。
次に、[IAM と管理] > [サービス アカウント] に移動します。
{project-number}-compute@developer.gserviceaccount.com という表示形式のデフォルトの Compute Engine アカウントをクリックし、上部のナビゲーション メニューの [アクセス権を持つプリンシパル] タブを選択します。
[アクセスを許可] ボタンをクリックします。
[新しいプリンシパル] フィールドに、前の手順でコピーしたサービスアカウントを貼り付けます。
[ロール] プルダウン メニューで、[サービス アカウント ユーザー] を選択します。
[保存] をクリックします。
このタスクでは、Cloud Data Fusion の Wrangler コンポーネントを使用して、元データを準備してクリーニングします。この反復プロセスにより、リアルタイム変換を実現できます。
Google Cloud コンソールのナビゲーション メニューで、[Data Fusion] > [インスタンス] をクリックします。
インスタンスの [インスタンスを表示] をクリックします。プロンプトが表示されたら、ラボの認証情報を使用してログインします。ツアーを開始するダイアログが表示された場合は、[No, Thanks] をクリックします。
Cloud Data Fusion UI で、ナビゲーション メニューの [Wrangler] をクリックします。
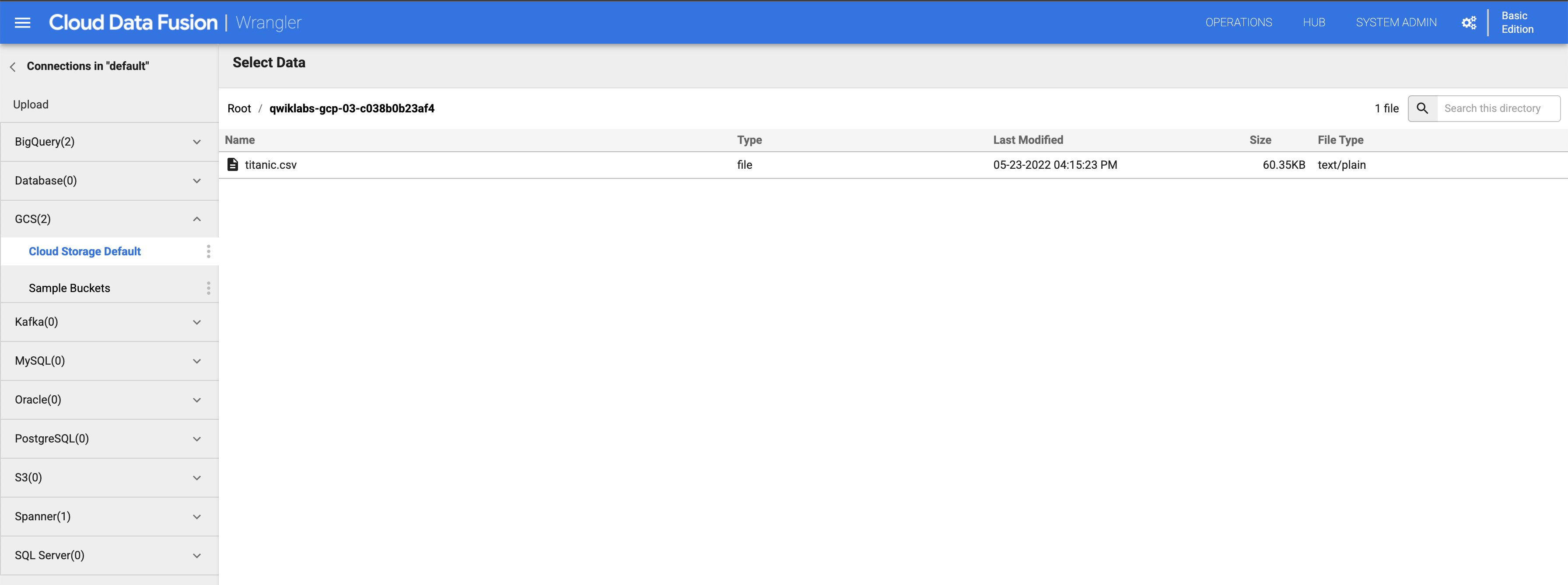
左側のパネルで、[(GCS) Google Cloud Storage] をクリックし、[Cloud Storage Default] を選択します。
プロジェクト ID に対応するバケットをクリックします。
titanic.csv をクリックします。
[Parsing Options] ダイアログ ボックスで、[Format] に [text] を選択し、[Confirm] をクリックします。
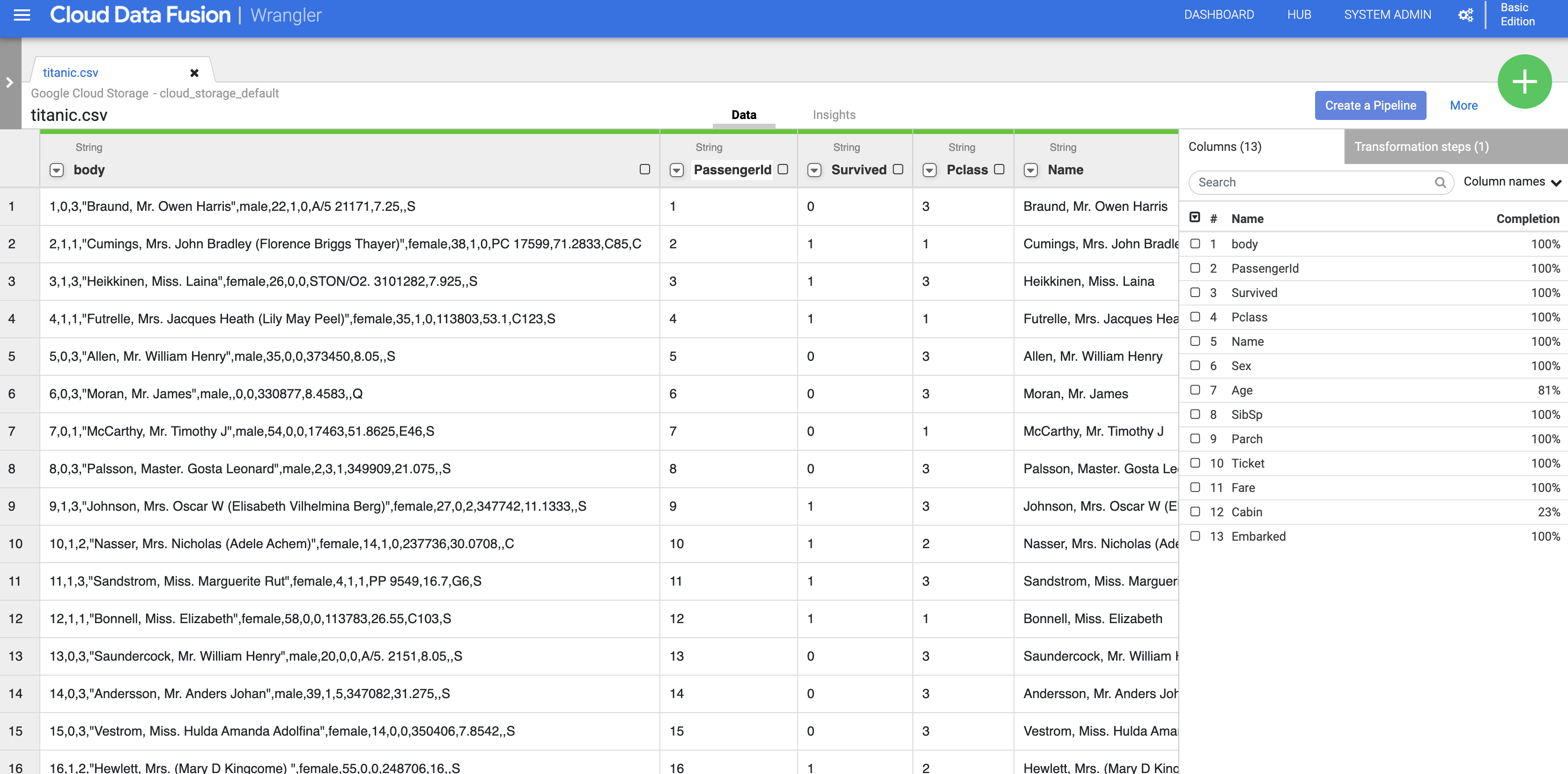
データが Wrangler の画面に読み込まれます。これで、データ変換を繰り返し適用できるようになりました。
元の CSV データを表形式で解析するには、[body] 列見出しの横にある矢印をクリックし、[解析] を選択して、[CSV] を選択します。
[Parse as CSV] ダイアログ ボックスで、[Set first row as header] チェックボックスをオンにして、[Apply] をクリックします。
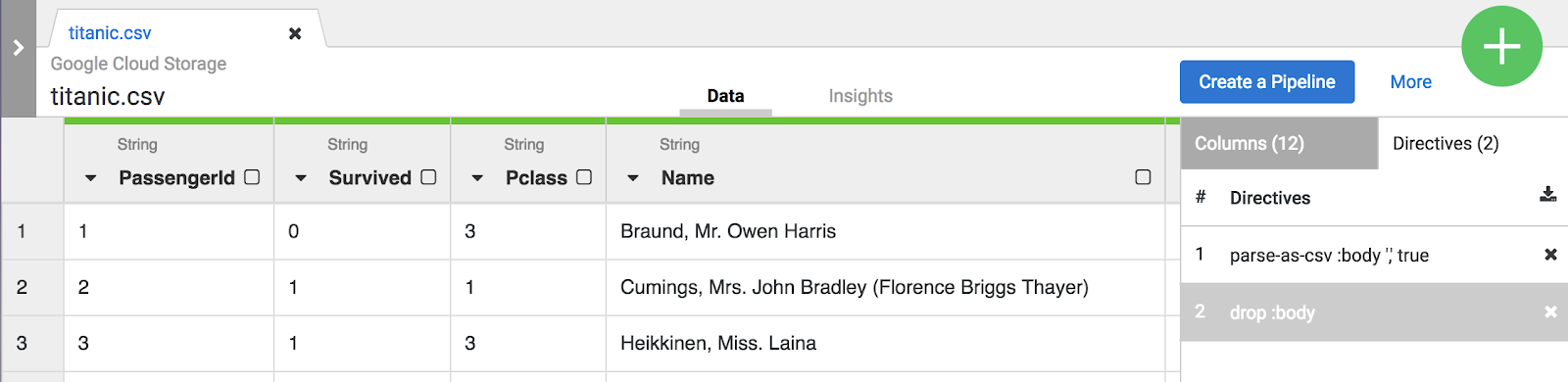
drop: body を使用することもできます。
このラボでは、2 つの変換(レシピ)で問題なく ETL パイプラインを作成できます。次のステップでは、このレシピをパイプライン構築ステップに組み込みます。このレシピは ETL の「T」の役割を果たします。
[Create a Pipeline] ボタンをクリックして次のセクションに進み、パイプラインを作成します。ここで、ETL パイプラインがどのように構成されるかを確認できます。
次に表示されるダイアログで、[Batch pipeline] を選択して続行します。
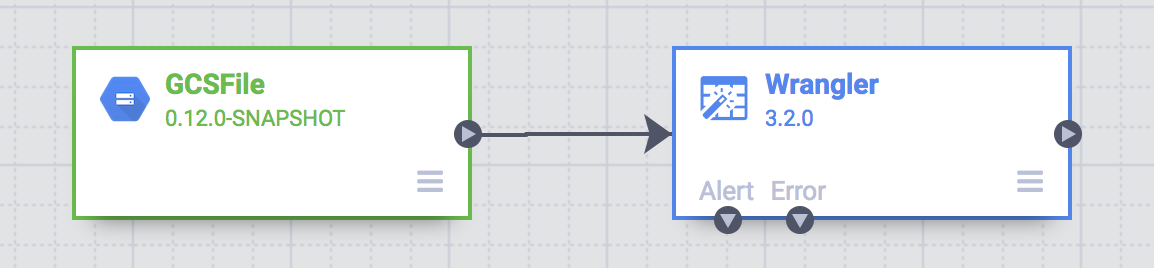
パイプライン構築の残りのタスクは Pipeline Studio で行います。Pipeline Studio は、データ パイプラインを視覚的に構成できる UI です。このツールには ETL パイプラインの主要な構成要素が表示されます。
この時点で、パイプラインに 2 つのノードが表示されています。1 つは Google Cloud Storage から CSV ファイルを読み取る GCS File プラグイン、もう 1 つは複数の変換から構成されるレシピが含まれる Wrangler プラグインです。
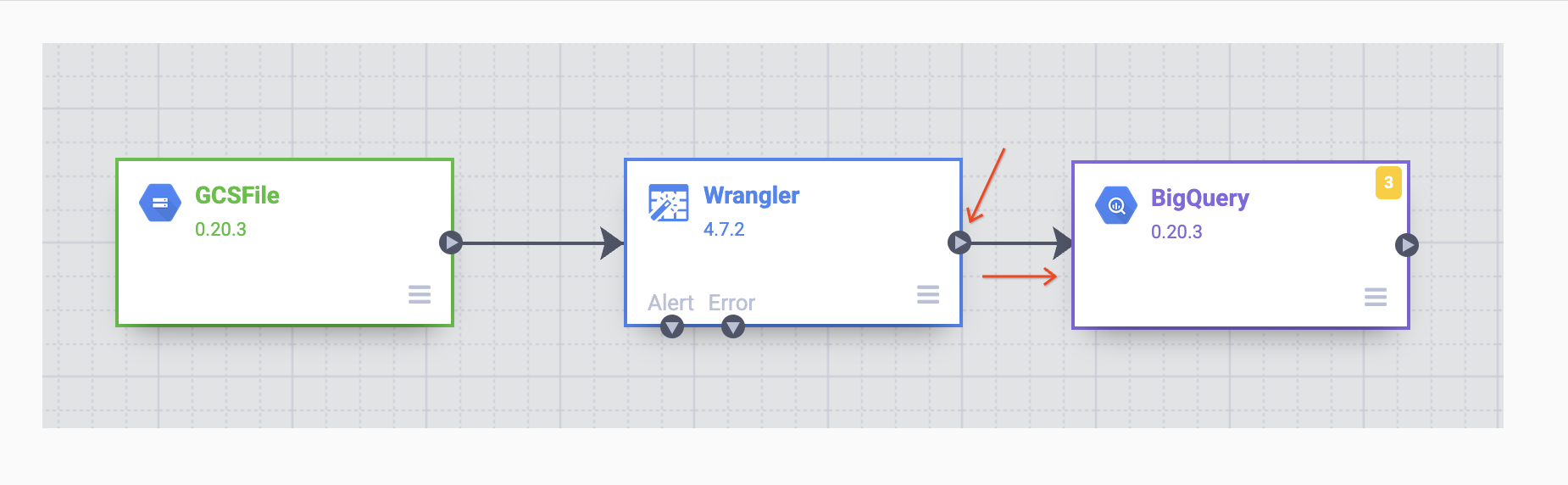
これらの 2 つのプラグイン(ノード)は、ETL パイプラインの「E」と「T」を表しています。このパイプラインを完成させるには、ETL の「L」となる BigQuery シンクを追加します。
BigQuery シンクがキャンバスに配置されたら、Wrangler ノードと BigQuery ノードを接続します。そうするには、以下の図に示すように Wrangler ノードの矢印を BigQuery ノードまでドラッグして接続します。あとは、必要なデータセットにデータを書き込めるように、いくつかの構成オプションを指定するだけです。
次に、パイプラインを構成します。これを行うには、各ノードのプロパティを開いて設定を確認し、必要に応じて変更を加えます。
各プラグインには、必ず存在しなければならない必須フィールドがいくつかあり、該当するフィールドにはアスタリスク(*)が付いています。使用するプラグインに応じて、左側に [Input Schema]、中央に [Configuration] セクション、右側に [Output Schema] が表示されます。
シンク プラグインには出力スキーマがなく、ソース プラグインには入力スキーマがありません。また、シンクとソースの両方のプラグインに、リネージのデータソース / シンクを識別するための必須フィールド [Reference Name] があります。
各プラグインに [Label] フィールドがあります。これは、パイプラインが表示されるキャンバスで確認できるノードのラベルです。
[Properties] ボックスの右上にある [X] をクリックして閉じます。
次に、Wrangler ノードにカーソルを合わせ、[Properties] をクリックします。
[Properties] ボックスの右上にある [X] をクリックして閉じます。
BigQuery ノードにカーソルを合わせて [Properties] をクリックし、次の構成設定値を入力します。
[Reference Name] に「Titanic_BQ」と入力します。
[Dataset] に「demo」と入力します。
[Table] に「titanic」と入力します。
[Properties] ボックスの右上にある [X] をクリックして閉じます。
あとは、パイプラインをテストして、想定どおりに動作することを確認するだけです。その前に、作業内容が失われないように、ドラフトに名前を付けて保存してください。
右上のメニューで [Save] をクリックします。パイプラインの名前を入力し、説明を追加するよう求められます。
ETL-batch-pipeline」を入力します。ETL pipeline to parse CSV, transform and write output to BigQuery」と入力します。[保存] をクリックします。
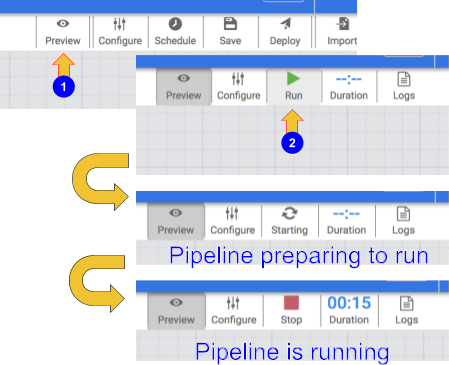
パイプラインをテストするために、[Preview] アイコンをクリックします。ボタンバーに [Run] アイコンが表示されます。このアイコンをクリックすると、パイプラインをプレビュー モードで実行できます。
[Run] アイコンをクリックします。パイプラインがプレビュー モードで実行されている間は、データが実際に BigQuery テーブルに書き込まれることはありませんが、データが正しく読み取られていることと、パイプラインがデプロイされたときにデータが想定どおりに書き込まれることを確認できます。[Preview] ボタンは切り替え式です。プレビュー モードを終了するときは、もう一度クリックしてください。
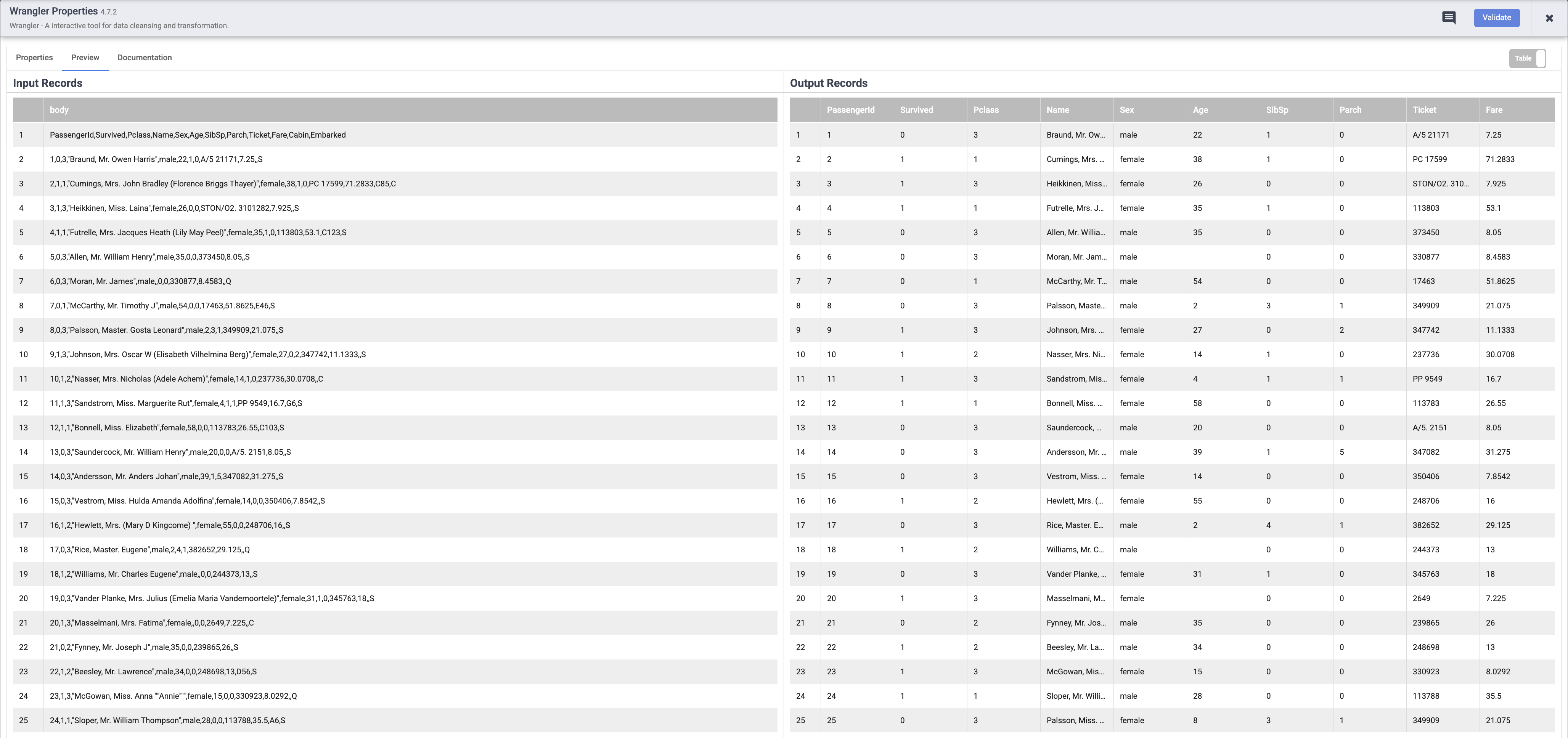
パイプラインの実行が完了したら、Wrangler ノードにカーソルを合わせて [Properties] をクリックします。続けて、[Preview] タブをクリックします。正常に処理されていれば、入力された元データが左側のノードに、出力された解析済みレコードが右側のノードに表示されます。[Properties] ボックスの右上にある [X] をクリックして閉じます。
[Preview] アイコンをもう一度クリックして、プレビュー モードをオフにします。
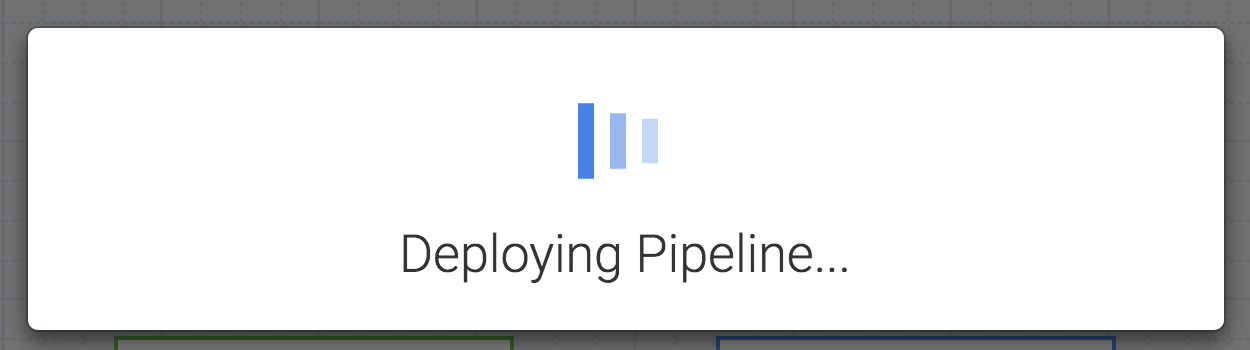
ここまで問題がなければ、パイプラインのデプロイに進みます。右上の [Deploy] アイコン(
パイプラインがデプロイされていることを示す確認ダイアログが表示されます。
パイプラインが正常にデプロイされたら、ETL パイプラインを実行して BigQuery にデータを読み込むことができます。
[Run] アイコンをクリックして ETL ジョブを実行します。
完了すると、パイプラインのステータスが [Succeeded] に変わり、パイプラインが問題なく実行されたことがわかります。
パイプラインでデータが処理されると、パイプラインの各ノードから、処理されたレコード数を示す指標が出力されます。 解析オペレーションでは 892 件のレコードが表示されますが、ソースには 893 件のレコードがありました。これは、解析オペレーションで最初の行が列見出しの設定に使用されたことにより、残りの 892 件のレコードが処理対象となったためです。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
パイプラインは出力を BigQuery テーブルに書き込みます。次の手順で、この点を確認できます。
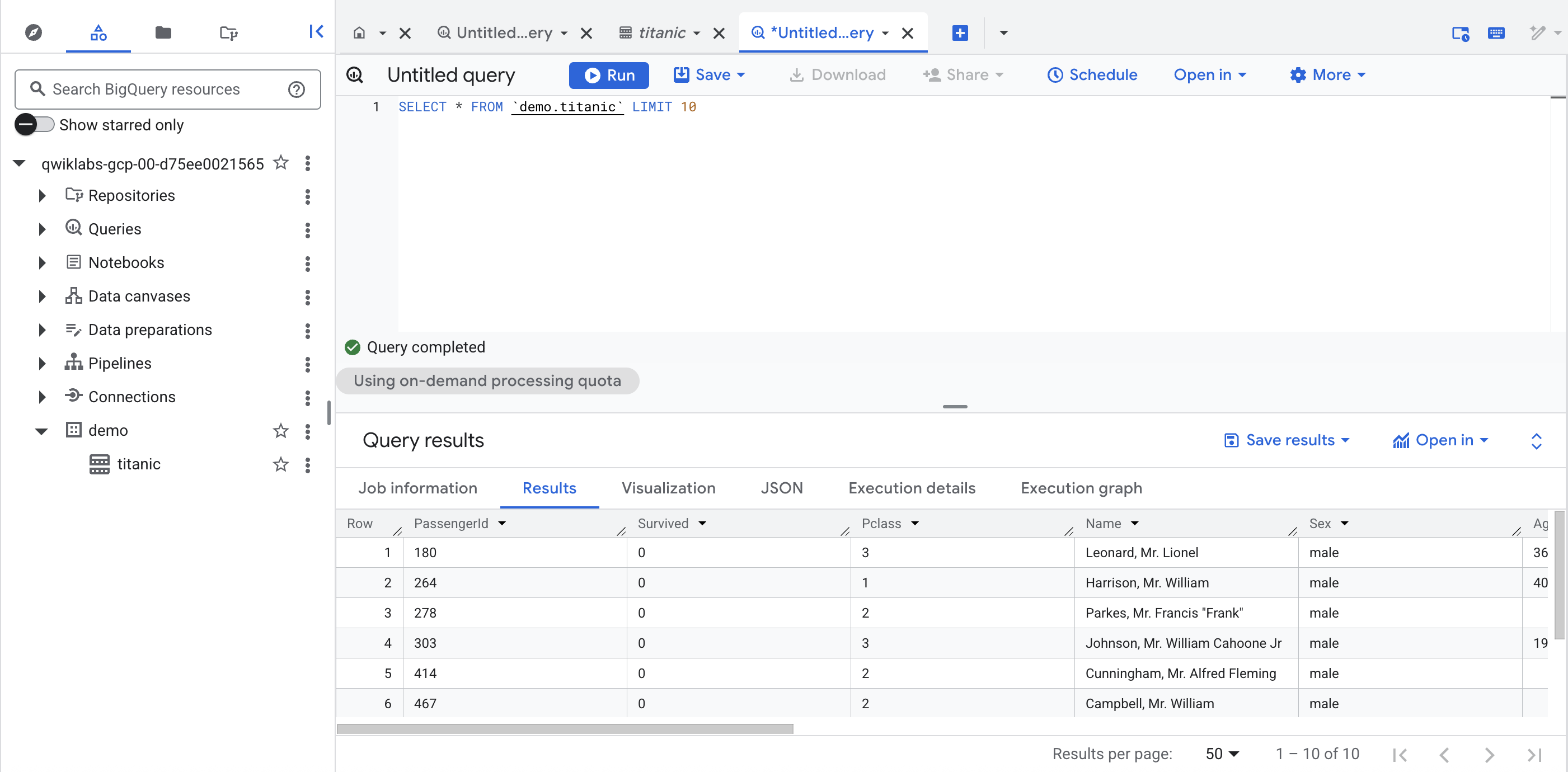
新しいタブで Cloud コンソールの BigQuery UI を開くか、コンソールのタブを右クリックして [タブを複製] を選択し、ナビゲーション メニューを使用して [BigQuery] を選択します。メッセージが表示されたら、[完了] をクリックします。
左側のペインの [従来のエクスプローラ] セクションで、プロジェクト ID(qwiklabs で始まる ID)をクリックします。
プロジェクト内の demo データセットで、titanic テーブルをクリックし、[+](SQL クエリ)をクリックして、次のような簡単なクエリを実行します。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
ここでは、Cloud Data Fusion の Pipeline Studio に表示される構成要素を使用してバッチ パイプラインを構築する方法を学びました。また、Wrangler を使用してデータの変換ステップを作成する方法も学びました。
「Cloud Data Fusion で Wrangler を使用してデータ変換を作成し、データを準備する」に進んでください。
マニュアルの最終更新日: 2026 年 1 月 27 日
ラボの最終テスト日: 2026 年 1 月 27 日
Copyright 2026 Google LLC All rights reserved. Google および Google のロゴは、Google LLC の商標です。その他すべての社名および製品名は、それぞれ該当する企業の商標である可能性があります。



このコンテンツは現在ご利用いただけません
利用可能になりましたら、メールでお知らせいたします

ありがとうございます。
利用可能になりましたら、メールでご連絡いたします

1 回に 1 つのラボ
既存のラボをすべて終了して、このラボを開始することを確認してください
ラボを開始するには、この簡単な手順を完了してください。