GSP807

Présentation
L'ETL fait référence au processus d'extraction, de transformation et de chargement. Il existe d'autres variantes de ce concept, comme EL, ELT et ELTL.
Dans cet atelier, vous allez apprendre à utiliser Pipeline Studio dans Cloud Data Fusion pour créer un pipeline ETL. Pipeline Studio vous permet de créer votre pipeline par lot, nœud par nœud, à l'aide de composants de base et de plug-ins intégrés. Vous utiliserez également le plug-in Wrangler pour créer des transformations et les appliquer aux données qui transitent par le pipeline.
Les données stockées dans des fichiers texte au format CSV (valeurs séparées par une virgule) sont la source de données la plus courante pour les applications ETL, étant donné que de nombreux systèmes de base de données procèdent à l'importation et l'exportation des données via ce type de fichiers. Pour les besoins de cet atelier, vous utiliserez un fichier CSV, mais les mêmes techniques peuvent être appliquées aux sources de base de données et à toute autre source de données disponible.
Le résultat sera écrit dans une table BigQuery, et vous utiliserez le langage SQL standard pour effectuer des analyses de données sur cet ensemble de données cible.
Objectifs
Dans cet atelier, vous allez apprendre à effectuer les tâches suivantes :
- Créer un pipeline par lots avec Pipeline Studio dans Cloud Data Fusion.
- Utiliser Wrangler pour transformer des données de manière interactive.
- Écrire la sortie dans BigQuery.
Préparation
Pour chaque atelier, nous vous attribuons un nouveau projet Google Cloud et un nouvel ensemble de ressources pour une durée déterminée, sans frais.
-
Connectez-vous à Google Skills dans une fenêtre de navigation privée.
-
Vérifiez le temps imparti pour l'atelier (par exemple : 02:00:00) : vous devez pouvoir le terminer dans ce délai.
Une fois l'atelier lancé, vous ne pouvez pas le mettre en pause. Si nécessaire, vous pourrez le redémarrer, mais vous devrez tout reprendre depuis le début.
-
Lorsque vous êtes prêt, cliquez sur Démarrer l'atelier.
Remarque : Une fois que vous avez cliqué sur Démarrer l'atelier, il faut compter environ 15-20 minutes pour que les ressources nécessaires soient provisionnées et une instance Data Fusion créée.
Pendant ce temps, vous pouvez parcourir les étapes ci-dessous pour vous familiariser avec les objectifs de l'atelier.
Les identifiants pour l'atelier (Username (Nom d'utilisateur) et Password (Mot de passe)) s'afficheront dans le volet de gauche une fois l'instance créée. Vous pourrez alors vous connecter à la console.
-
Notez ces identifiants (Username (Nom d'utilisateur) et Password (Mot de passe)). Ils vous serviront à vous connecter à la console Google Cloud.
-
Cliquez sur Open Google Console (Ouvrir la console Google).
-
Cliquez sur Utiliser un autre compte, puis copiez-collez les identifiants de cet atelier lorsque vous y êtes invité.
Si vous utilisez d'autres identifiants, des messages d'erreur s'afficheront ou des frais seront appliqués.
-
Acceptez les conditions d'utilisation et ignorez la page concernant les ressources de récupération des données.
Remarque : Ne cliquez pas sur Terminer l'atelier, à moins que vous n'ayez terminé l'atelier ou que vous ne vouliez le recommencer. Votre travail et le projet seront alors supprimés.
Se connecter à la console Google Cloud
- Dans l'onglet ou la fenêtre de navigateur que vous utilisez pour cet atelier, copiez les données de Username (Nom d'utilisateur) indiqué dans le panneau Connection Details (Détails de connexion), puis cliquez sur le bouton Open Google Console (Ouvrir la console Google).
Remarque : Si vous êtes invité à choisir un compte, cliquez sur Use another account (Utiliser un autre compte).
- Collez les données de Username (Nom d'utilisateur) et de Password (Mot de passe) lorsque vous y êtes invité :
- Cliquez sur Next (Suivant).
- Acceptez les conditions d'utilisation.
Comme il s'agit d'un compte temporaire auquel vous aurez accès uniquement pendant la durée de cet atelier :
- n'ajoutez pas d'options de récupération ;
- ne vous inscrivez pas à des essais sans frais.
- Une fois la console ouverte, affichez la liste des services en cliquant sur le menu de navigation (
 ) en haut à gauche.
) en haut à gauche.

Activer Cloud Shell
Cloud Shell est une machine virtuelle qui contient des outils pour les développeurs. Elle comprend un répertoire d'accueil persistant de 5 Go et s'exécute sur Google Cloud. Google Cloud Shell vous permet d'accéder via une ligne de commande à vos ressources Google Cloud. gcloud est l'outil de ligne de commande associé à Google Cloud. Il est préinstallé sur Cloud Shell et permet la saisie semi-automatique via la touche Tabulation.
-
Dans Google Cloud Console, dans le volet de navigation, cliquez sur Activer Cloud Shell ( ).
).
-
Cliquez sur Continuer.
Le provisionnement et la connexion à l'environnement prennent quelques instants. Une fois connecté, vous êtes en principe authentifié, et le projet est défini sur votre ID_PROJET. Exemple :

Exemples de commandes
gcloud auth list
(Résultat)
Credentialed accounts:
- <myaccount>@<mydomain>.com (active)
(Exemple de résultat)
Credentialed accounts:
- google1623327_student@qwiklabs.net
gcloud config list project
(Résultat)
[core]
project = <ID_Projet>
(Exemple de résultat)
[core]
project = qwiklabs-gcp-44776a13dea667a6
Vérifier les autorisations du projet
Avant de commencer à travailler dans Google Cloud, vous devez vous assurer de disposer des autorisations adéquates pour votre projet dans IAM (Identity and Access Management).
-
Dans la console Google Cloud, accédez au menu de navigation (), puis cliquez sur IAM et administration > IAM.
-
Vérifiez que le compte de service Compute par défaut {project-number}-compute@developer.gserviceaccount.com existe et qu'il est associé au rôle Éditeur. Le préfixe du compte correspond au numéro du projet, disponible sur cette page : Menu de navigation > Présentation Cloud.

Si le compte n'est pas disponible dans IAM ou n'est pas associé au rôle Éditeur, procédez comme suit pour lui attribuer le rôle approprié.
-
Dans la console Google Cloud, accédez au menu de navigation et cliquez sur Présentation Cloud.
-
Sur la carte Informations sur le projet, copiez le numéro du projet.
-
Dans le menu de navigation, cliquez sur IAM et administration > IAM.
-
En haut de la page IAM, cliquez sur Ajouter.
-
Dans le champ Nouveaux comptes principaux, saisissez :
{project-number}-compute@developer.gserviceaccount.com
Remplacez {project-number} par le numéro de votre projet.
-
Dans le champ Sélectionnez un rôle, sélectionnez De base (ou Projet) > Éditeur.
-
Cliquez sur Enregistrer.
Tâche 1 : Charger les données
Dans cette tâche, vous allez créer un bucket Cloud Storage dans votre projet et y préparer un fichier CSV. Cloud Data Fusion lira par la suite les données qui se trouvent dans ce bucket de stockage.
- Dans Cloud Shell, exécutez les commandes suivantes pour créer un bucket et y copier les données pertinentes :
export BUCKET=$GOOGLE_CLOUD_PROJECT
gcloud storage buckets create gs://$BUCKET
Le nom du bucket créé correspond à l'ID de votre projet.
- Pour copier les fichiers de données (un fichier CSV et un fichier XML) dans votre bucket, exécutez la commande suivante :
gsutil cp gs://cloud-training/OCBL163/titanic.csv gs://$BUCKET
Cliquez sur Vérifier ma progression pour valider l'objectif.
Charger les données
Tâche 2 : Ajouter les autorisations nécessaires pour votre instance Cloud Data Fusion
Dans cette tâche, vous allez attribuer les rôles IAM nécessaires au compte de service associé à l'instance Cloud Data Fusion.
- Dans le menu de navigation de la console Google Cloud, cliquez sur Afficher tous les produits, puis sélectionnez Data Fusion > Instances dans la catégorie Analyse. Vous devriez voir une instance Cloud Data Fusion déjà configurée et prête à être utilisée.
Remarque : La création de l'instance prend environ 10 minutes. Attendez qu'elle soit prête avant de continuer.
-
Dans la console Google Cloud, accédez au menu de navigation, puis cliquez sur IAM et administration > IAM.
-
Recherchez le compte de service Compute Engine par défaut {project-number}-compute@developer.gserviceaccount.com, puis copiez le Compte de service dans votre presse-papiers.
-
Sur la page des autorisations IAM, cliquez sur +Accorder l'accès.
-
Collez le compte de service dans le champ "Nouveaux comptes principaux".
-
Dans Sélectionner un rôle, saisissez Agent de service de l'API Cloud Data Fusion, puis sélectionnez ce rôle.
-
Cliquez sur + Ajouter un autre rôle.
-
Dans Sélectionner un rôle, choisissez le rôle Administrateur Dataproc.
-
Cliquez sur Enregistrer.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Ajouter le rôle Agent de service de l'API Cloud Data Fusion au compte de service
Accorder l'autorisation Utilisateur du compte de service
-
Dans la console, accédez au menu de navigation et cliquez sur IAM et administration > IAM.
-
Cochez la case Inclure les attributions de rôles fournies par Google.
-
Faites défiler la liste jusqu'au compte de service Cloud Data Fusion géré par Google semblable à service-{project-number}@gcp-sa-datafusion.iam.gserviceaccount.com. Copiez le nom du compte de service dans votre presse-papiers.

-
Ensuite, accédez à IAM et administration > Comptes de service.
-
Cliquez sur le compte Compute Engine par défaut, semblable à {project-number}-compute@developer.gserviceaccount.com, et sélectionnez l'onglet Comptes principaux avec accès dans la barre de navigation supérieure.
-
Cliquez sur le bouton Accorder l'accès.
-
Dans le champ Nouveaux comptes principaux, collez le nom du compte de service que vous avez copié plus tôt.
-
Dans le menu déroulant Rôle, sélectionnez Utilisateur du compte de service.
-
Cliquez sur Enregistrer.
Tâche 3 : Créer un pipeline par lot
Dans cette tâche, vous allez utiliser le composant Wrangler de Cloud Data Fusion pour préparer et nettoyer les données brutes. Ce processus itératif vous permet de visualiser les transformations en temps réel.
-
Dans le menu de navigation de la console Google Cloud, cliquez sur Data Fusion > Instances.
-
Cliquez sur Afficher l'instance pour votre instance. Si vous y êtes invité, connectez-vous à l'aide des identifiants de l'atelier. Si vous êtes invité à faire une visite guidée, cliquez sur Non, merci.
-
Dans l'interface utilisateur de Cloud Data Fusion, cliquez sur Wrangler dans le menu de navigation.
-
Dans le panneau de gauche, cliquez sur (GCS) Google Cloud Storage, puis sélectionnez Cloud Storage Default (Cloud Storage par défaut).
-
Cliquez sur le bucket correspondant à l'ID de votre projet.
-
Cliquez sur titanic.csv.
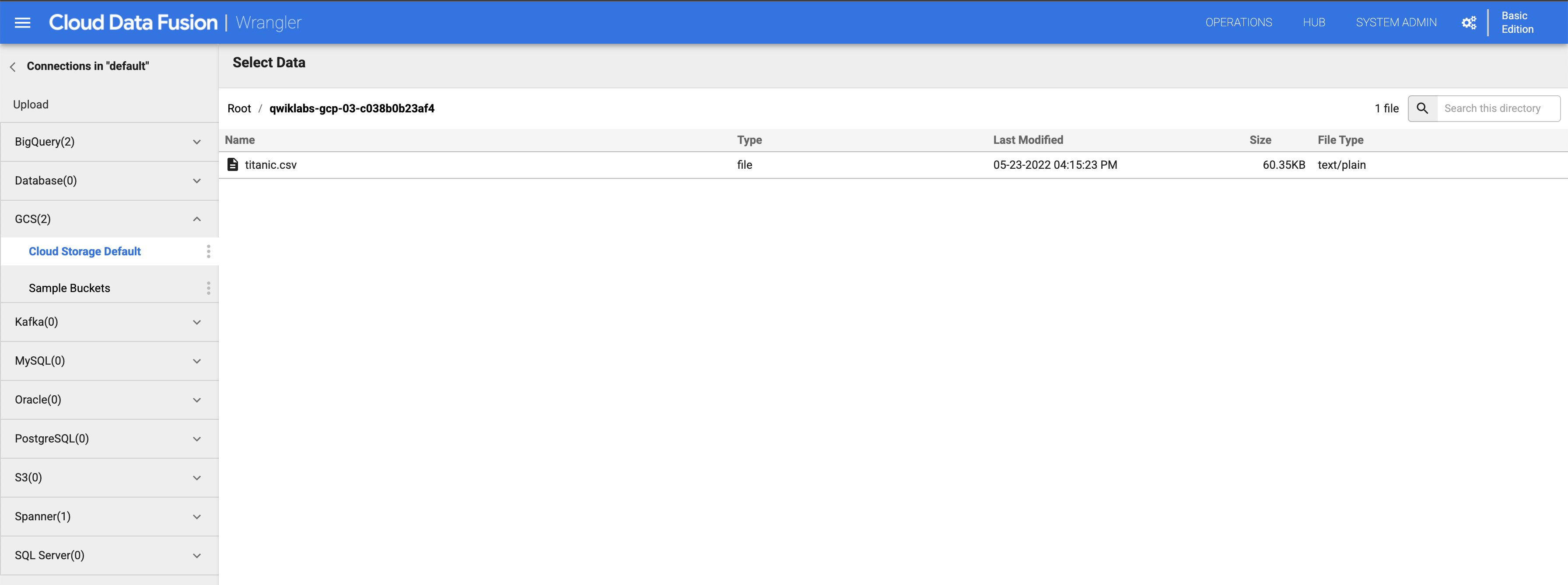
-
Dans la boîte de dialogue Parsing Options (Options d'analyse), sélectionnez text (texte) pour Format (Format), puis cliquez sur Confirm (Confirmer).
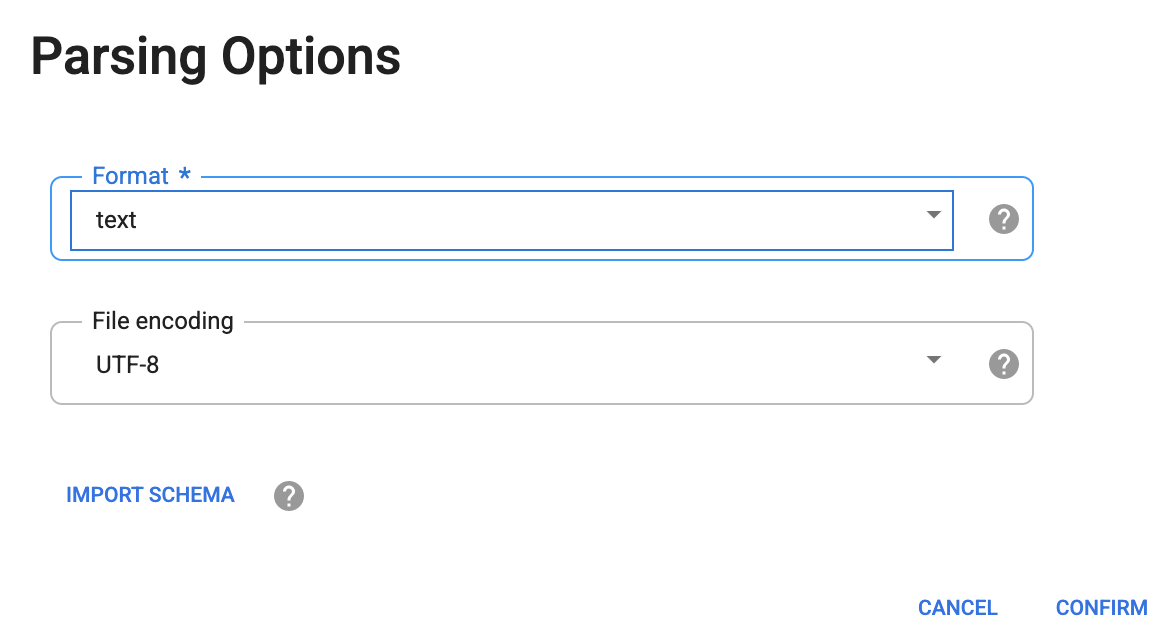
Les données sont chargées dans l'écran Wrangler. Vous pouvez maintenant commencer à appliquer les transformations de données de manière itérative.
-
Pour analyser les données CSV brutes et les convertir en format tabulaire, cliquez sur la flèche à côté de l'en-tête de la colonne body, sélectionnez Parse (Analyser), puis CSV.
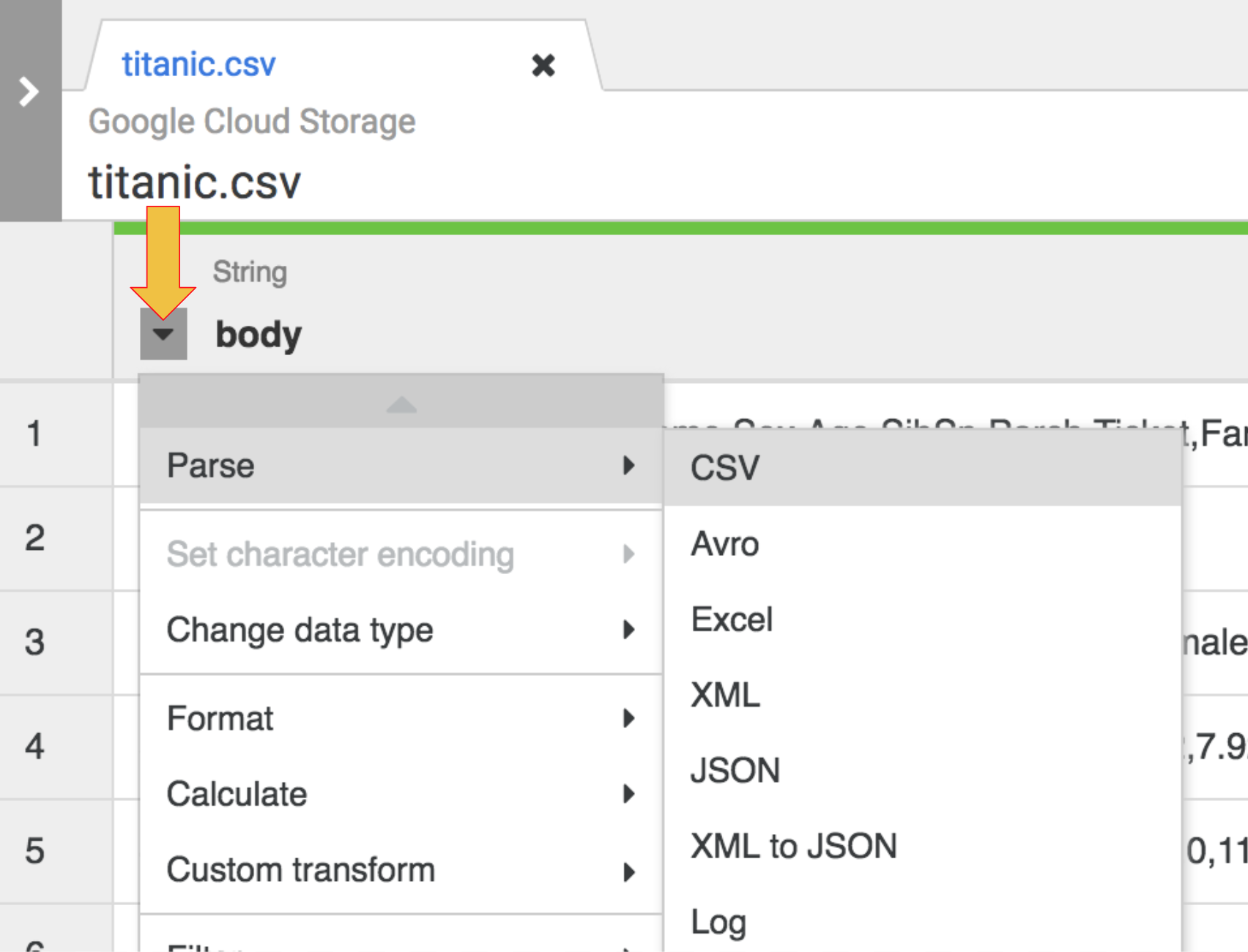
-
Dans la boîte de dialogue Parse as CSV (Analyser en tant que CSV), cochez la case Set first row as header (Définir la première ligne comme en-tête), puis cliquez sur Apply (Appliquer).
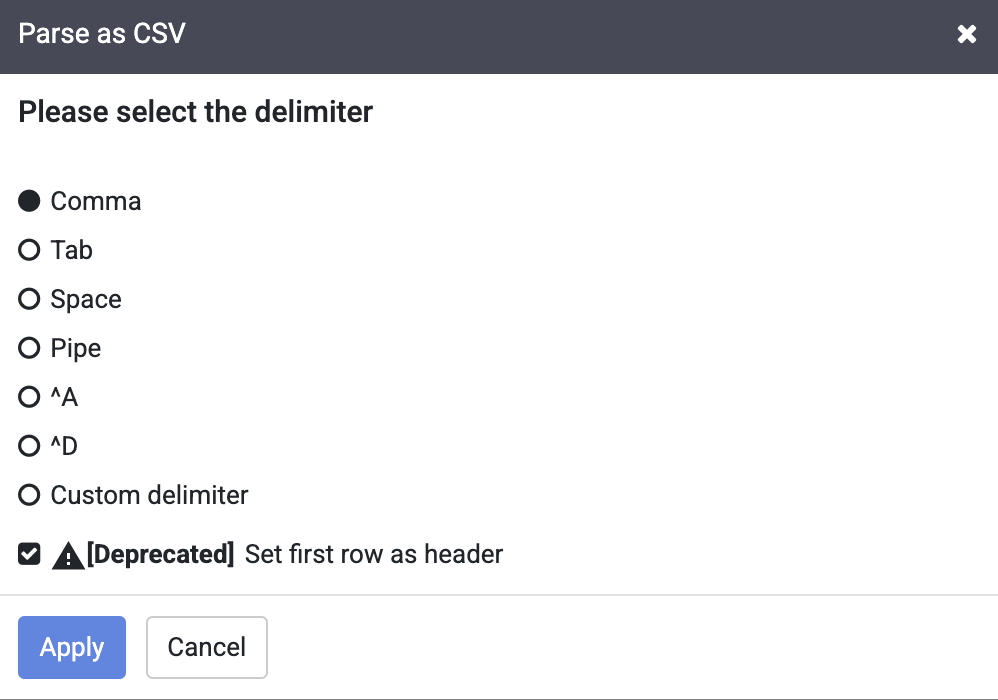
Remarque : Vous pouvez ignorer l'avertissement d'abandon à côté de la case à cocher Set first row as header (Définir la première ligne comme en-tête).
- À ce stade, les données brutes sont analysées et vous pouvez voir les colonnes générées par cette opération (colonnes à droite de la colonne body). Tout à droite s'affiche la liste de tous les noms de colonnes.
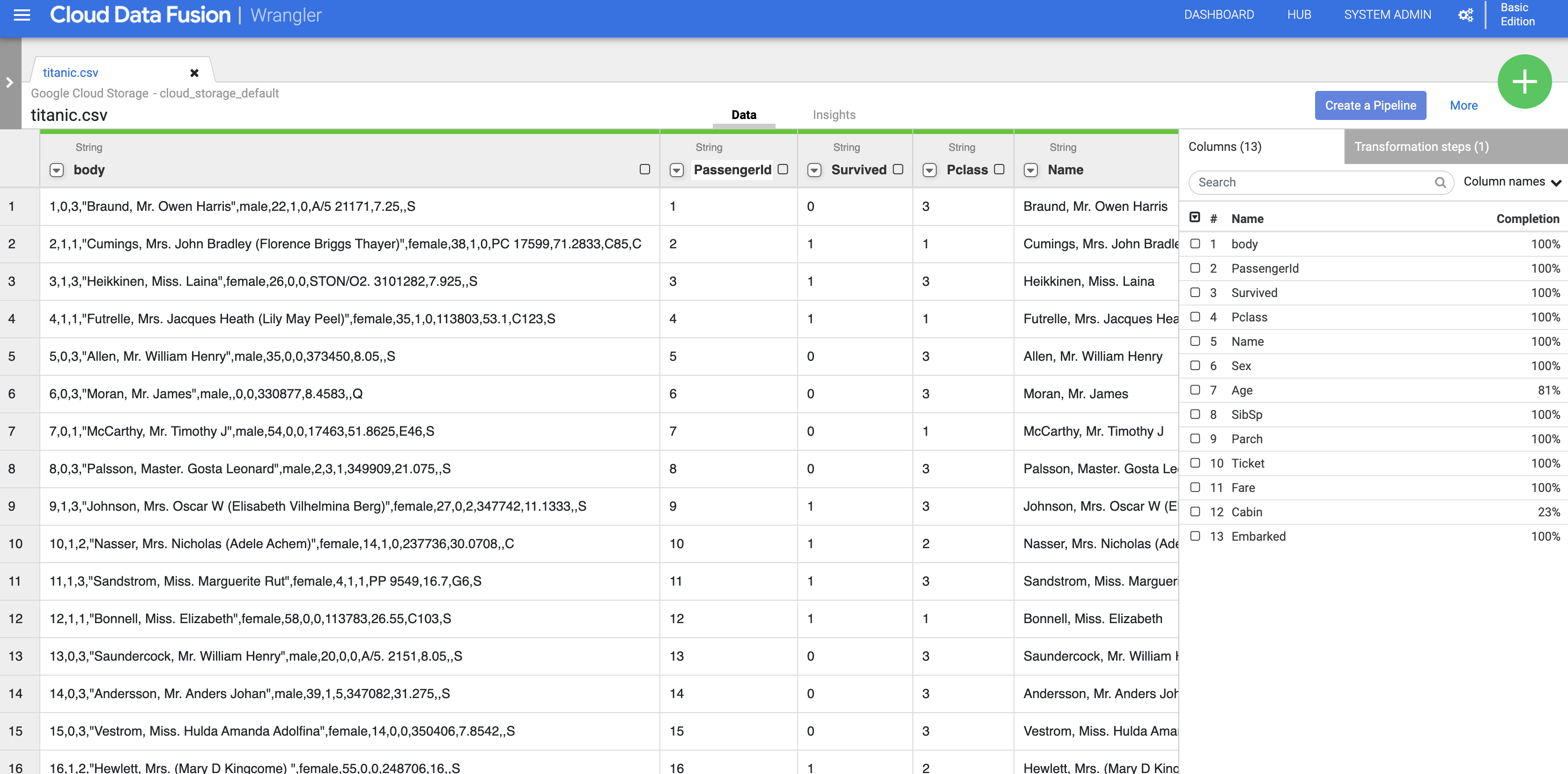
- Pour supprimer la colonne de données brutes, cliquez sur la flèche à côté de l'en-tête de colonne body, puis sur Delete column (Supprimer la colonne).
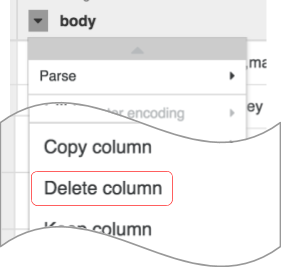
Remarque : Pour appliquer des transformations, vous pouvez également utiliser l'interface de ligne de commande (CLI). La CLI est la barre noire située en bas de l'écran (avec l'invite de commande $ affichée en vert). Dès que vous commencez à saisir des commandes, la fonction de saisie automatique s'active et vous présente une option correspondante. Par exemple, pour supprimer la colonne "body", vous auriez pu utiliser la directive suivante : drop: body.
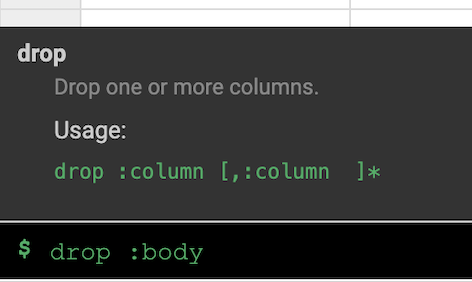
- Sur la droite de l'interface utilisateur de Wrangler, cliquez sur l'onglet Transformation steps (Étapes de transformation) pour afficher votre recette actuelle.
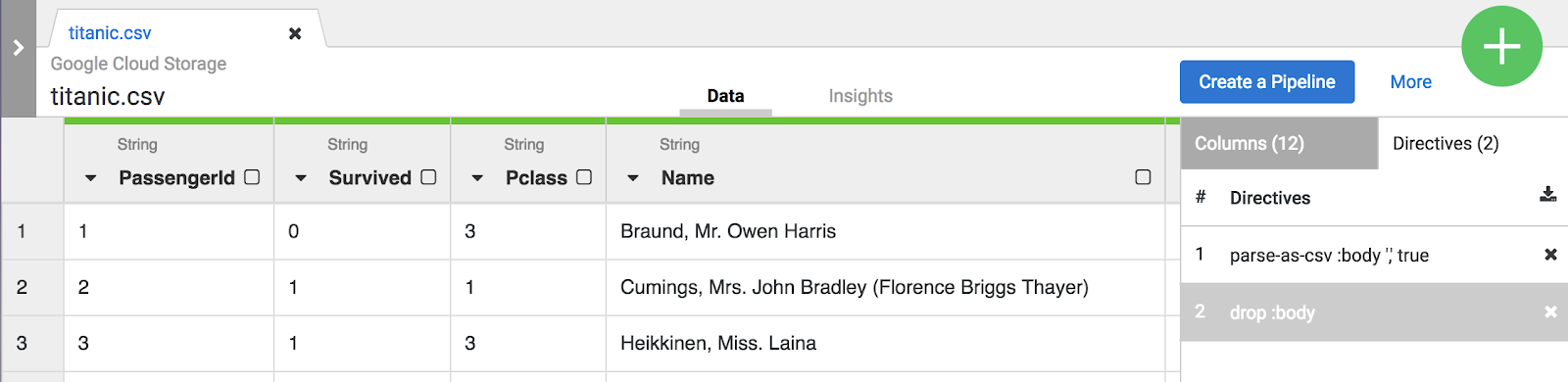
Remarque : Les sélections effectuées dans le menu et la CLI créent des directives qui sont visibles dans l'onglet Transformation steps (Étapes de transformation) situé à droite de l'écran. Les directives sont des transformations individuelles, qui sont collectivement désignées par le terme "recette".
Pour cet atelier, les deux transformations, ou la recette, suffisent à créer le pipeline ETL. L'étape suivante consiste à intégrer cette recette à l'étape de création de pipeline, où elle représentera la transformation (T) du processus ETL.
-
Cliquez sur le bouton Créer un pipeline pour passer à la section suivante et créer un pipeline. Vous y verrez comment le pipeline ETL prend forme.

-
Lorsque la boîte de dialogue suivante s'affiche, sélectionnez Batch pipeline (Pipeline de traitement par lot) pour continuer.
Remarque : Un pipeline de traitement par lot peut être exécuté de manière interactive, ou programmé pour s'exécuter à une fréquence allant de toutes les cinq minutes à une fois par an.
Tâche 4 : Configurer le récepteur BigQuery
Pour le reste des tâches de création de pipeline, vous allez utiliser Pipeline Studio, une interface qui vous permet de composer des pipelines de données de façon visuelle. Les principaux composants de base de votre pipeline ETL devraient maintenant s'afficher dans le studio.
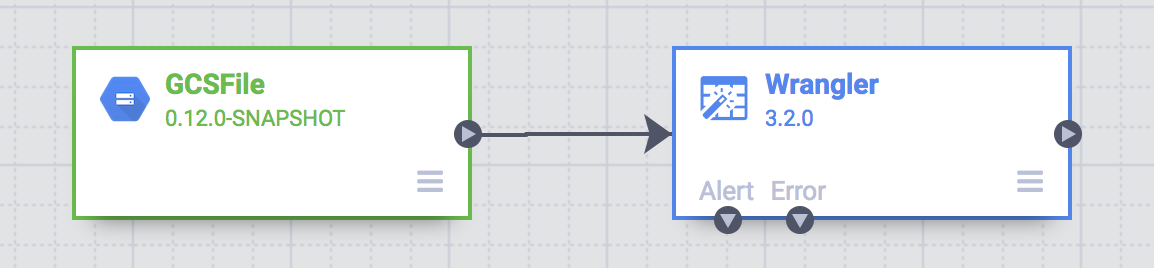
À ce stade, votre pipeline comprend deux nœuds : le plug-in GCS File qui lit le fichier CSV depuis Google Cloud Storage et le plug-in Wrangler qui contient la recette avec les transformations.
Remarque : Dans un pipeline, un nœud est un objet connecté en séquence pour produire un graphe orienté acyclique. Ex. : source, récepteur, transformation, action, etc.
Ces deux plug-ins (nœuds) représentent les étapes d'extraction (E) et de transformation (T) de votre pipeline ETL. Pour terminer ce pipeline, ajoutez le récepteur BigQuery, qui correspond à l'étape de chargement de notre ETL.
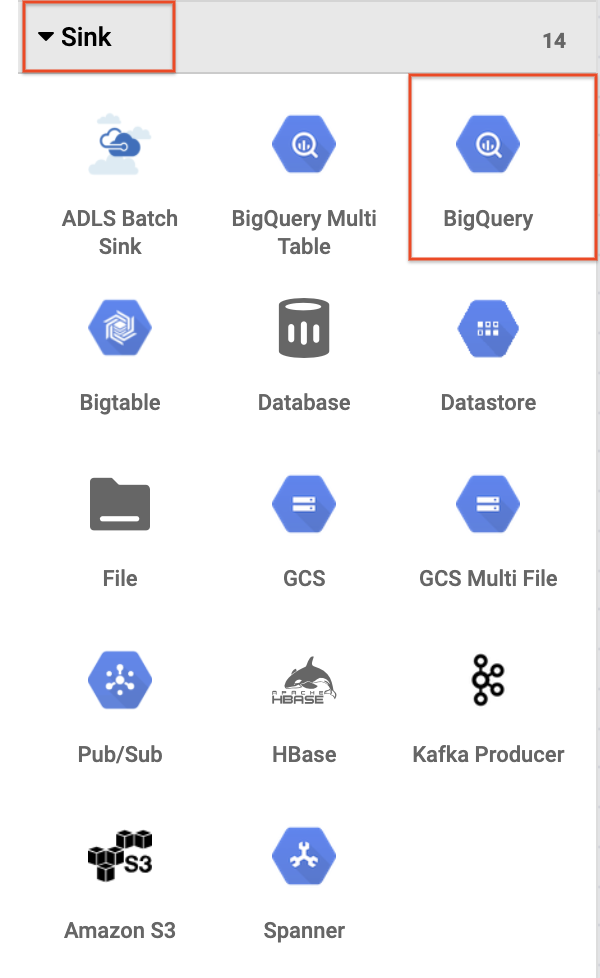
- Pour ajouter le récepteur BigQuery au pipeline, accédez à la section Sink (Récepteur) du panneau de gauche et cliquez sur l'icône BigQuery afin de placer le récepteur sur le canevas.
-
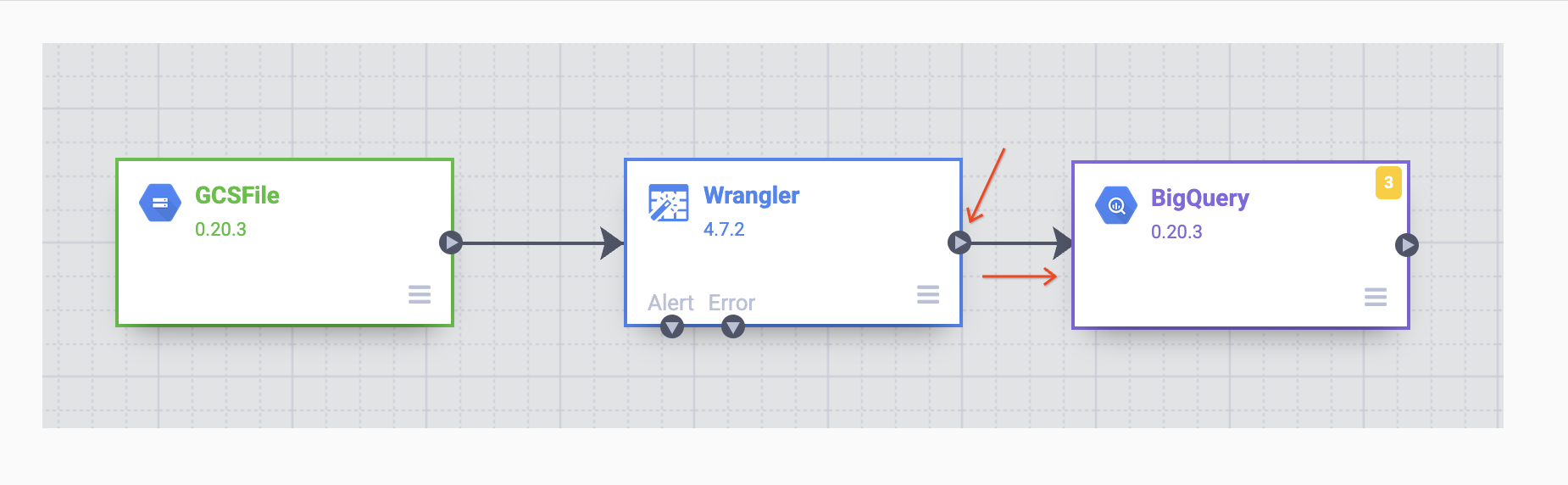
Une fois le récepteur BigQuery placé sur le canevas, connectez le nœud Wrangler au nœud BigQuery. Pour ce faire, faites glisser la flèche en partant du nœud Wrangler vers le nœud BigQuery, comme illustré ci-dessous. Il ne vous reste plus qu'à spécifier quelques options de configuration pour pouvoir écrire les données dans l'ensemble de données de votre choix.
Tâche 5 : Configurer le pipeline
Il est maintenant temps de configurer le pipeline. Pour cela, ouvrez les propriétés de chaque nœud afin de vérifier ses paramètres et/ou d'apporter des modifications supplémentaires.
- Pointez sur le nœud GCS pour afficher le bouton Propriétés. Cliquez sur ce bouton pour ouvrir les paramètres de configuration.
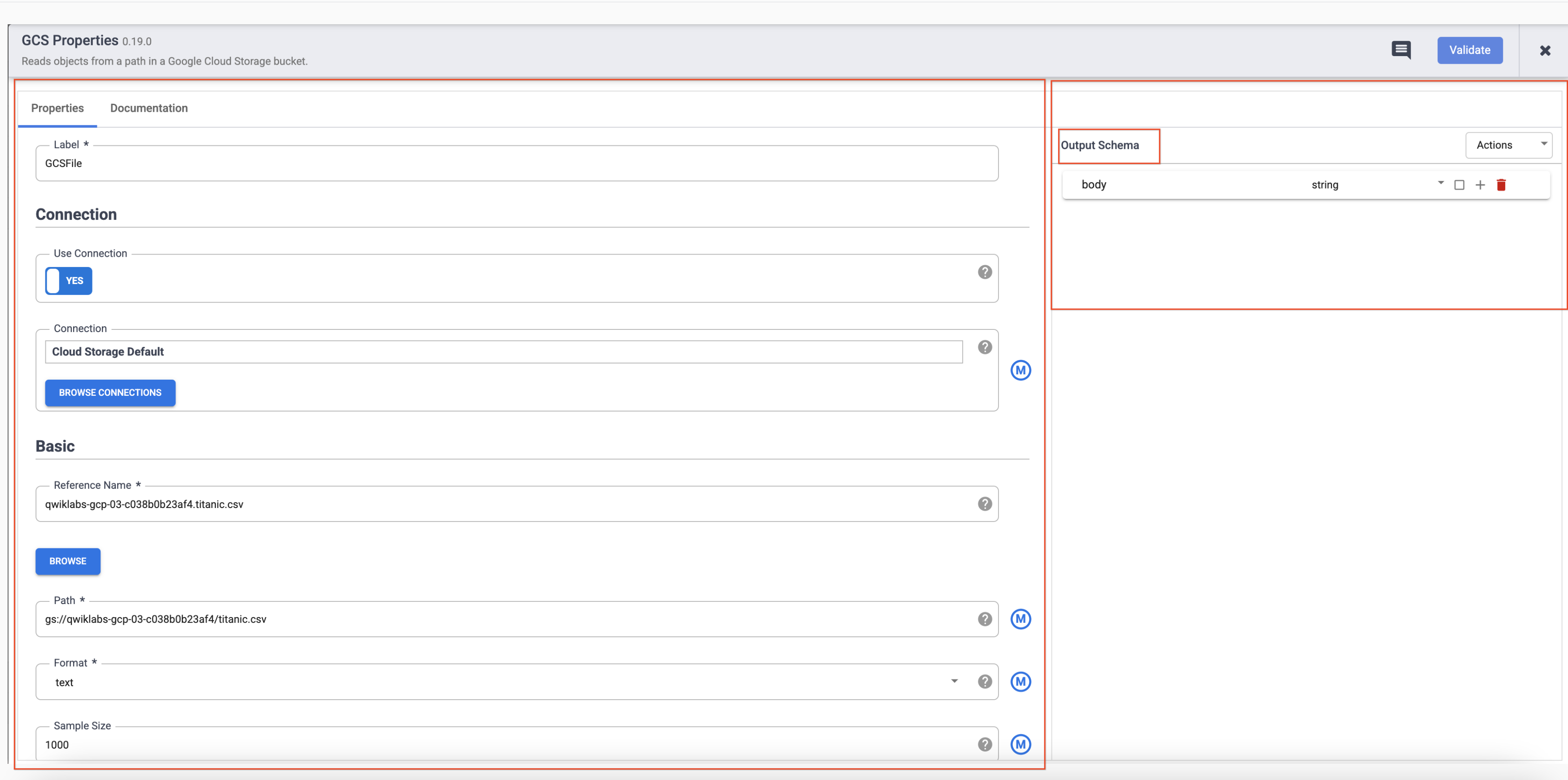
Chaque plug-in comporte des champs obligatoires, qui doivent être présents et sont marqués d'un astérisque (*). Selon le plug-in que vous utilisez, vous pouvez voir un schéma d'entrée à gauche, une section de configuration au milieu et un schéma de sortie à droite.
Vous remarquerez que les plug-ins de récepteur n'ont pas de schéma de sortie et que les plug-ins de source n'ont pas de schéma d'entrée. Les plug-ins de récepteur et de source comportent également un champ Nom de la référence obligatoire pour identifier la source/le récepteur de données à des fins de traçabilité.
Chaque plug-in comporte un champ Étiquette. Il s'agit de l'étiquette du nœud que vous voyez sur le canevas où votre pipeline est affiché.
-
Cliquez sur X en haut à droite de la boîte de dialogue "Propriétés" pour la fermer.
-
Ensuite, pointez sur le nœud Wrangler et cliquez sur Propriétés.
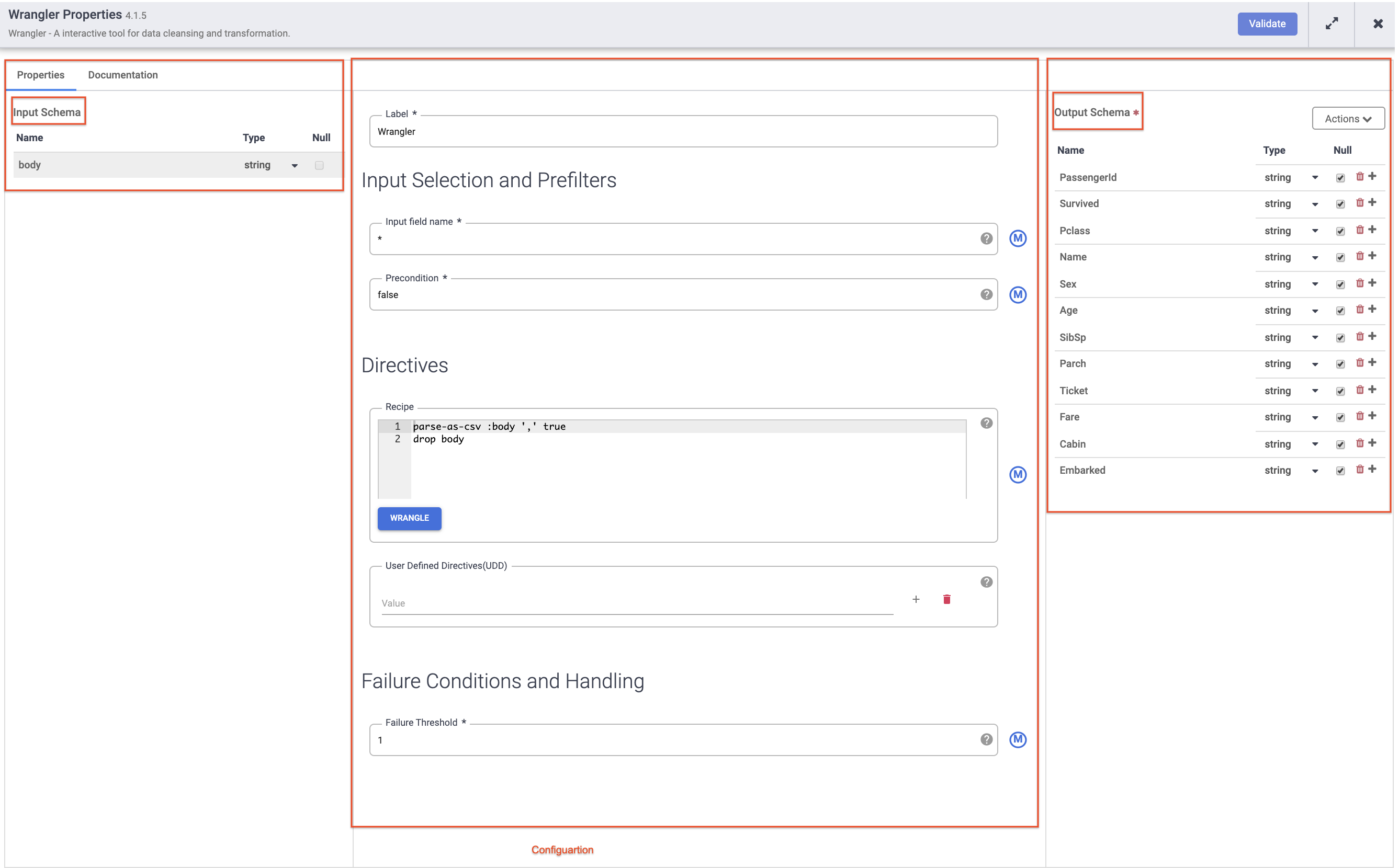
Remarque :
Les plug-ins comme Wrangler contiennent un schéma d'entrée. Ce sont les champs qui sont transmis au plug-in pour traitement. Une fois traitées par le plug-in, les données sortantes peuvent être envoyées dans le schéma de sortie au nœud suivant du pipeline ou, dans le cas d'un récepteur, être écrites dans un ensemble de données.
-
Cliquez sur X en haut à droite de la boîte de dialogue "Propriétés" pour la fermer.
-
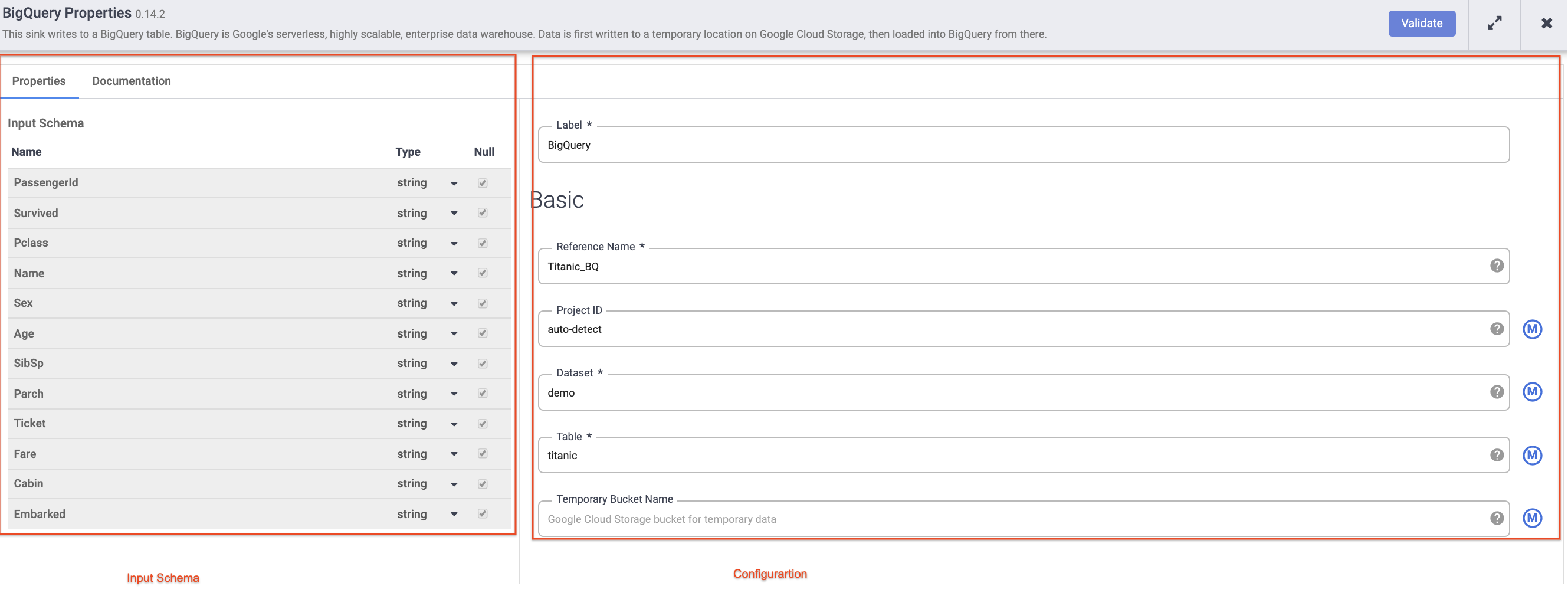
Pointez sur votre nœud BigQuery, cliquez sur Propriétés et saisissez les paramètres de configuration suivants :
-
Dans le champ Nom de la référence, saisissez Titanic_BQ.
-
Dans le champ Ensemble de données, saisissez demo.
-
Pour Table, saisissez titanic.
-
Cliquez sur X en haut à droite de la boîte de dialogue "Propriétés" pour la fermer.
Tâche 6 : Tester le pipeline
Il ne vous reste plus qu'à tester votre pipeline pour vérifier qu'il fonctionne comme prévu. Mais avant cela, assurez-vous de nommer et d'enregistrer votre brouillon pour ne pas perdre votre travail.
-
Cliquez sur Enregistrer dans le menu en haut à droite. Vous serez invité à donner un nom au pipeline et à ajouter une description.
- Saisissez
ETL-batch-pipeline comme nom de votre pipeline.
- Saisissez
Pipeline ETL pour analyser le fichier CSV, transformer les données et écrire le résultat dans BigQuery comme description.
-
Cliquez sur Enregistrer.
-
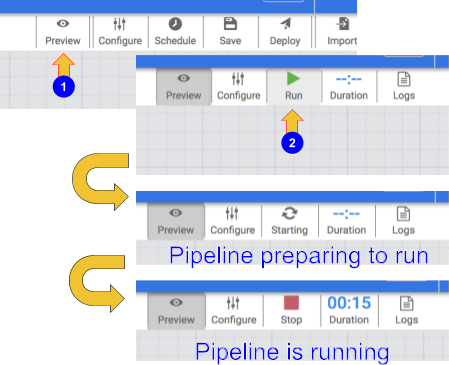
Pour tester votre pipeline, cliquez sur l'icône Aperçu. La barre de boutons affiche désormais une icône d'exécution sur laquelle vous pouvez cliquer pour exécuter le pipeline en mode Aperçu.
-
Cliquez sur l'icône Exécuter. Lorsque le pipeline s'exécute en mode Aperçu, aucune donnée n'est écrite dans la table BigQuery. Vous pouvez toutefois vérifier que les données sont lues correctement et qu'elles seront écrites comme prévu une fois le pipeline déployé. Le bouton "Aperçu" est un bouton bascule. Assurez-vous de cliquer à nouveau dessus pour quitter le mode Aperçu une fois que vous avez terminé.
-
Une fois l'exécution du pipeline terminée, pointez sur le nœud Wrangler et cliquez sur Propriétés, puis sur l'onglet Aperçu. Si tout s'est bien passé, vous devriez voir les données brutes issues de l'entrée (le nœud de gauche) et les enregistrements analysés qui seront émis en sortie (le nœud de droite). Cliquez sur X en haut à droite de la boîte de dialogue "Propriétés" pour la fermer.
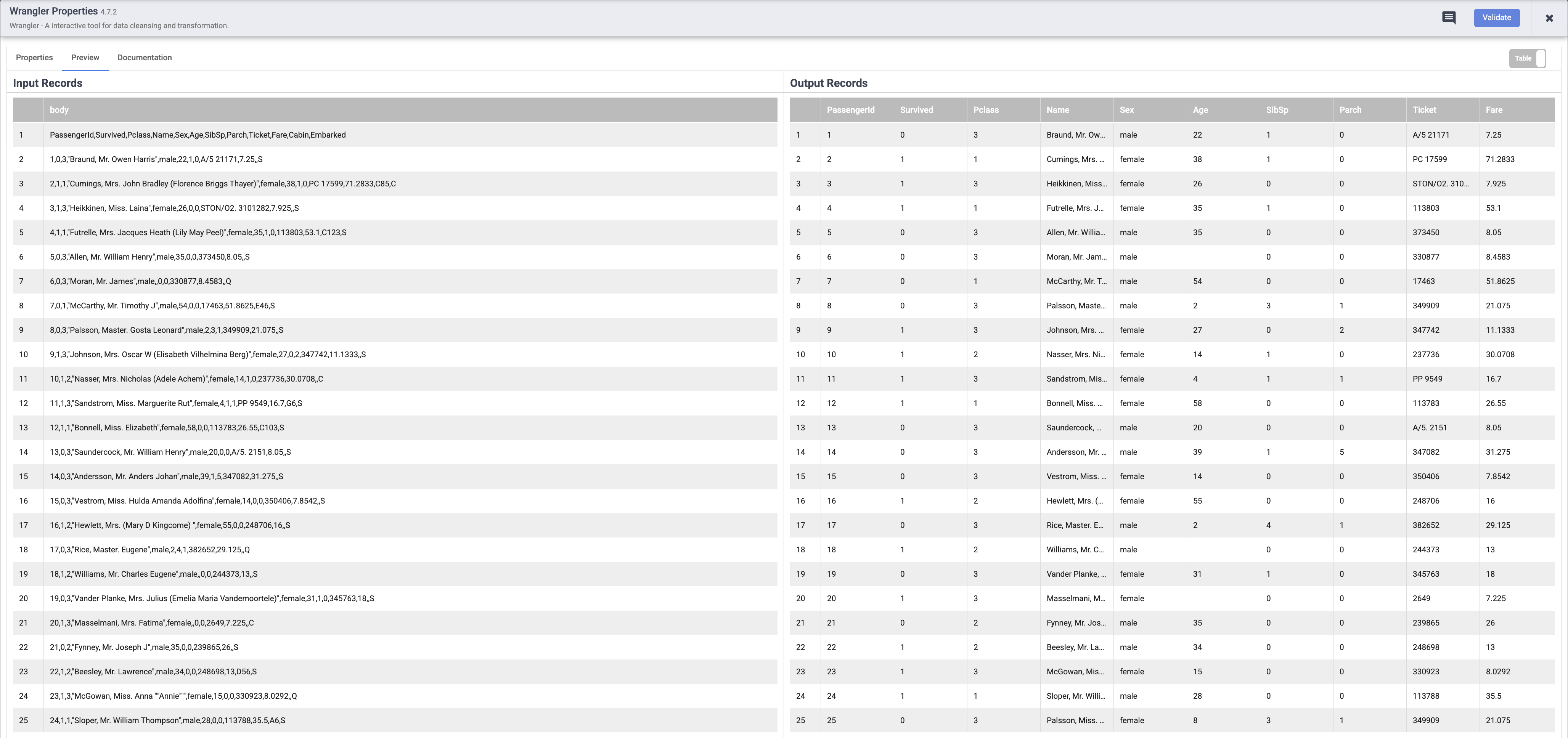
Remarque : Chaque nœud qui traite des données doit afficher un résultat similaire. C'est un bon moyen de vérifier que vous êtes sur la bonne voie avant de déployer votre pipeline. Si vous rencontrez des erreurs, vous pouvez facilement les corriger en mode Brouillon.
-
Cliquez à nouveau sur l'icône Aperçu pour désactiver le mode Aperçu.
-
Si tout vous semble correct, vous pouvez déployer le pipeline. Cliquez sur l'icône Déployer  en haut à droite pour déployer le pipeline.
en haut à droite pour déployer le pipeline.
Une boîte de dialogue de confirmation s'affiche pour indiquer que votre pipeline est en cours de déploiement :
-
Une fois votre pipeline déployé, vous êtes prêt à exécuter votre pipeline ETL et à charger des données dans BigQuery.
-
Cliquez sur l'icône Exécuter pour exécuter le job ETL.
-
Une fois l'opération terminée, l'état du pipeline doit passer à Réussi, ce qui indique que le pipeline s'est exécuté correctement.

-
À mesure que les données sont traitées par le pipeline, vous verrez des métriques émises par chaque nœud du pipeline indiquant le nombre d'enregistrements traités.
L'opération d'analyse affiche 892 enregistrements, alors que la source en contenait 893. Que s'est-il passé ? L'opération d'analyse a utilisé la première ligne pour définir les en-têtes de colonne. Il restait donc 892 enregistrements à traiter.

Cliquez sur Vérifier ma progression pour valider l'objectif.
Déployer et exécuter un pipeline par lot
Tâche 7 : Afficher les résultats
Le pipeline écrit la sortie dans une table BigQuery. Vous pouvez le vérifier la table en procédant comme suit.
-
Dans un nouvel onglet, ouvrez l'interface BigQuery dans la console Cloud. Vous pouvez également effectuer un clic droit sur l'onglet de la console et sélectionner Dupliquer, puis utiliser le menu de navigation du nouvel onglet pour sélectionner BigQuery. Lorsque vous y êtes invité, cliquez sur OK.
-
Dans le volet de gauche, dans la section Explorateur classique, cliquez sur l'ID de votre projet (qui commence par qwiklabs).
-
Sous l'ensemble de données demo de votre projet, cliquez sur la table titanic, puis sur + (requête SQL). Exécutez ensuite une requête simple, telle que :
SELECT * FROM `demo.titanic` LIMIT 10
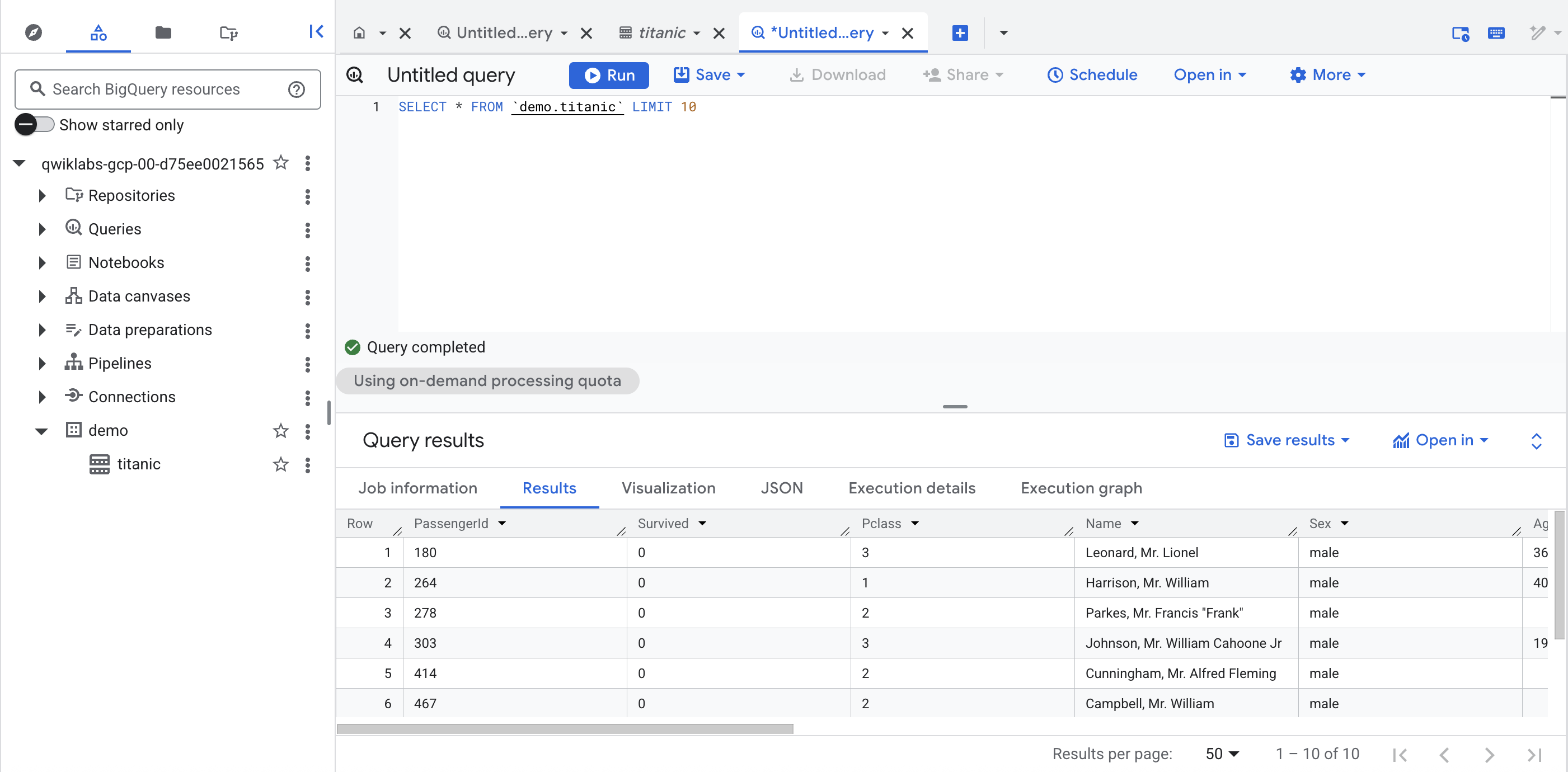
Cliquez sur Vérifier ma progression pour valider l'objectif.
Afficher les résultats
Félicitations !
Vous savez désormais utiliser les composants de base disponibles dans Pipeline Studio de Cloud Data Fusion pour créer un pipeline par lot. Vous avez également appris à utiliser Wrangler pour créer des étapes de transformation pour vos données.
Atelier suivant
Poursuivez avec Créer des transformations et préparer des données avec Wrangler dans Cloud Data Fusion.
Dernière mise à jour du manuel : 27 janvier 2026
Dernier test de l'atelier : 27 janvier 2026
Copyright 2026 Google LLC Tous droits réservés. Google et le logo Google sont des marques de Google LLC. Tous les autres noms de société et de produit peuvent être des marques des sociétés auxquelles ils sont associés.






