GSP807

Descripción general
ETL significa, en inglés, extracción, transformación y carga. Existen varias mutaciones de este concepto,
como EL, ELT y ELTL.
En este lab, aprenderás a usar Pipeline Studio en Cloud Data Fusion para crear una canalización de ETL. Pipeline Studio expone los componentes básicos y los complementos integrados para que puedas crear tu canalización por lotes, un nodo a la vez. También usarás el complemento Wrangler para crear transformaciones y aplicarlas a tus datos que pasan por la canalización.
Las fuentes de datos más comunes para las aplicaciones de ETL normalmente son datos almacenados en archivos de texto en formato de valores separados por comas (CSV), ya que muchos sistemas de bases de datos los importan y exportan de esta forma. Para este lab, usarás un archivo CSV, pero se pueden aplicar las mismas técnicas a las fuentes de bases de datos y a cualquier otra fuente de datos que tengas disponible.
El resultado se escribirá en una tabla de BigQuery y usarás SQL estándar para realizar análisis de datos en relación con este conjunto de datos de destino.
Objetivos
En este lab, aprenderás a hacer lo siguiente:
- Crear una canalización por lotes con Pipeline Studio en Cloud Data Fusion
- Usar Wrangler para transformar datos de forma interactiva
- Escribir el resultado en BigQuery
Configuración y requisitos
En cada lab, recibirás un proyecto de Google Cloud y un conjunto de recursos nuevos por tiempo limitado y sin costo adicional.
-
Accede a Google Skills en una ventana de incógnito.
-
Ten en cuenta el tiempo de acceso del lab (por ejemplo, 02:00:00) y asegúrate de finalizarlo en el plazo asignado.
No existe una función de pausa. Si lo necesitas, puedes reiniciar el lab, pero deberás hacerlo desde el comienzo.
-
Cuando tengas todo listo, haz clic en Comenzar lab.
Nota: Después de que hagas clic en Comenzar lab, el lab tardará entre 15 y 20 minutos en aprovisionar los recursos necesarios y crear una instancia de Data Fusion.
Durante ese período, puedes leer los pasos que se indican a continuación para familiarizarte con los objetivos del lab.
Cuando veas las credenciales del lab (el nombre de usuario y la contraseña) en el panel del lado izquierdo, se habrá creado la instancia y podrás continuar para acceder a la consola.
-
Anota las credenciales del lab (el nombre de usuario y la contraseña). Las usarás para acceder a la consola de Google Cloud.
-
Haz clic en Abrir la consola de Google.
-
Haz clic en Usar otra cuenta, copia las credenciales para este lab y pégalas en el mensaje emergente que aparece.
Si usas otras credenciales, se generarán errores o incurrirás en cargos.
-
Acepta las condiciones y omite la página de recursos de recuperación.
Nota: No hagas clic en Finalizar lab, a menos que lo hayas terminado o quieras reiniciarlo. Esta acción borrará tu trabajo y quitará el proyecto.
Cómo iniciar tu lab y acceder a la consola de Google Cloud
-
Haz clic en el botón Comenzar lab. Si debes pagar por el lab, se abrirá un diálogo para que selecciones la forma de pago.
A la izquierda, se encuentra el panel Detalles del lab, que tiene estos elementos:
- El botón para abrir la consola de Google Cloud
- El tiempo restante
- Las credenciales temporales que debes usar para el lab
- Otra información para completar el lab, si es necesaria
-
Haz clic en Abrir la consola de Google Cloud (o haz clic con el botón derecho y selecciona Abrir el vínculo en una ventana de incógnito si ejecutas el navegador Chrome).
El lab inicia recursos y abre otra pestaña en la que se muestra la página de acceso.
Sugerencia: Ordena las pestañas en ventanas separadas, una junto a la otra.
Nota: Si ves el diálogo Elegir una cuenta, haz clic en Usar otra cuenta.
-
De ser necesario, copia el nombre de usuario a continuación y pégalo en el diálogo Acceder.
{{{user_0.username | "Username"}}}
También puedes encontrar el nombre de usuario en el panel Detalles del lab.
-
Haz clic en Siguiente.
-
Copia la contraseña que aparece a continuación y pégala en el diálogo Te damos la bienvenida.
{{{user_0.password | "Password"}}}
También puedes encontrar la contraseña en el panel Detalles del lab.
-
Haz clic en Siguiente.
Importante: Debes usar las credenciales que te proporciona el lab. No uses las credenciales de tu cuenta de Google Cloud.
Nota: Usar tu propia cuenta de Google Cloud para este lab podría generar cargos adicionales.
-
Haz clic para avanzar por las páginas siguientes:
- Acepta los Términos y Condiciones.
- No agregues opciones de recuperación o autenticación de dos factores (esta es una cuenta temporal).
- No te registres para obtener pruebas gratuitas.
Después de un momento, se abrirá la consola de Google Cloud en esta pestaña.
Nota: Para acceder a los productos y servicios de Google Cloud, haz clic en el menú de navegación o escribe el nombre del servicio o producto en el campo Buscar.

Active Cloud Shell
Cloud Shell es una máquina virtual que contiene herramientas de desarrollo y un directorio principal persistente de 5 GB. Se ejecuta en Google Cloud. Cloud Shell proporciona acceso de línea de comandos a sus recursos de Google Cloud. gcloud es la herramienta de línea de comandos de Google Cloud, la cual está preinstalada en Cloud Shell y es compatible con la función de autocompletado con tabulador.
-
En el panel de navegación de Google Cloud Console, haga clic en Activar Cloud Shell ( ).
).
-
Haga clic en Continuar.
El aprovisionamiento y la conexión al entorno tardan solo unos momentos. Una vez que se conecte, también estará autenticado, y el proyecto estará configurado con su PROJECT_ID. Por ejemplo:

Comandos de muestra
gcloud auth list
(Resultado)
Credentialed accounts:
- <myaccount>@<mydomain>.com (active)
(Resultado de ejemplo)
Credentialed accounts:
- google1623327_student@qwiklabs.net
gcloud config list project
(Resultado)
[core]
project = <project_ID>
(Resultado de ejemplo)
[core]
project = qwiklabs-gcp-44776a13dea667a6
Verifica los permisos del proyecto
Antes de comenzar a trabajar en Google Cloud, asegúrate de que tu proyecto tenga los permisos correctos en Identity and Access Management (IAM).
-
En el Menú de navegación ( ) de la consola de Google Cloud, haga clic en IAM y administración > IAM.
) de la consola de Google Cloud, haga clic en IAM y administración > IAM.
-
Confirma que aparezca la cuenta de servicio predeterminada de Compute {project-number}-compute@developer.gserviceaccount.com, y que tenga asignado el rol Editor. El prefijo de la cuenta es el número del proyecto, que puedes encontrar en el menú de navegación > Descripción general de Cloud.

Si no aparece la cuenta en IAM o no tiene asignado el rol Editor, sigue los pasos que se indican a continuación para asignar el rol necesario.
-
En la consola de Google Cloud, en el menú de navegación, haz clic en Descripción general de Cloud.
-
En la tarjeta Información del proyecto, copia el Número de proyecto.
-
En el menú de navegación, haz clic en IAM y administración > IAM.
-
En la parte superior de la página IAM, haga clic en Agregar.
-
En Principales nuevas, escriba lo siguiente:
{número-del-proyecto}-compute@developer.gserviceaccount.com
Reemplaza {project-number} por el número de tu proyecto.
-
En Seleccionar un rol, elige Básico (o Proyecto) > Editor.
-
Haz clic en Guardar.
Tarea 1: Carga los datos
En esta tarea, crearás un bucket de Cloud Storage en tu proyecto y almacenarás en etapa intermedia un archivo CSV. Más adelante, Cloud Data Fusion leerá los datos de este bucket de almacenamiento.
- En la consola de Cloud Shell, ejecuta los siguientes comandos para crear un bucket nuevo y copiar en él los datos pertinentes:
export BUCKET=$GOOGLE_CLOUD_PROJECT
gcloud storage buckets create gs://$BUCKET
El nombre del bucket creado es el ID de tu proyecto.
- Para copiar los archivos de datos (un archivo CSV y uno en formato XML) en tu bucket, ejecuta el siguiente comando:
gsutil cp gs://cloud-training/OCBL163/titanic.csv gs://$BUCKET
Haz clic en Revisar mi progreso para verificar el objetivo.
Cargar los datos
Tarea 2: Agrega los permisos necesarios para tu instancia de Cloud Data Fusion
En esta tarea, otorgarás los roles de IAM necesarios a la cuenta de servicio asociada con la instancia de Cloud Data Fusion.
- En el menú de navegación de la consola de Google Cloud, haz clic en Ver todos los productos y, en las categorías de Análisis, selecciona Data Fusion > Instancias. Deberías ver una instancia de Cloud Data Fusion ya configurada y lista para usar.
Nota: Espera alrededor de 10 minutos a que se cree la instancia.
-
En el menú de navegación de la consola de Google Cloud, haz clic en IAM y administración > IAM.
-
Busca la cuenta de servicio predeterminada de Compute Engine {project-number}-compute@developer.gserviceaccount.com y, luego, copia la Cuenta de servicio en el portapapeles.
-
En la página Permisos de IAM, haz clic en + Otorgar acceso.
-
En el campo Entidades nuevas, pega la cuenta de servicio.
-
En Selecciona un rol, escribe Agente de servicio de la API de Cloud Data Fusion y, luego, selecciónalo.
-
Haz clic en + Agregar otro rol.
-
En Selecciona un rol, elige el rol Administrador de Managed Service for Spark.
-
Haz clic en Guardar.
Haz clic en Revisar mi progreso para verificar el objetivo.
Agregar el rol Agente de servicio de la API de Cloud Data Fusion a la cuenta de servicio
Otorga permiso de usuario a la cuenta de servicio
-
En la consola, ve a Menú de navegación y haz clic en IAM y administración > IAM.
-
Selecciona la casilla de verificación Incluir asignaciones de roles proporcionadas por Google.
-
Desplázate hacia abajo en la lista hasta encontrar la cuenta de servicio de Cloud Data Fusion administrada por Google que tiene el formato service-{project-number}@gcp-sa-datafusion.iam.gserviceaccount.com. Luego, copia el nombre de la cuenta en el portapapeles.

-
Después, navega a IAM y administración > Cuentas de servicio.
-
Haz clic en la cuenta predeterminada de Compute Engine que tiene el formato {project-number}-compute@developer.gserviceaccount.com y selecciona la pestaña Principales con acceso en la barra de navegación superior.
-
Haz clic en el botón Otorgar acceso.
-
En el campo Principales nuevas, pega la cuenta de servicio que copiaste antes.
-
En el menú desplegable Rol, selecciona Usuario de cuenta de servicio.
-
Haz clic en Guardar.
Tarea 3: Crea una canalización por lotes
En esta tarea, usarás el componente Wrangler de Cloud Data Fusion para preparar y limpiar datos sin procesar. Este proceso iterativo permite visualizar las transformaciones en tiempo real.
-
En el menú de navegación de la consola de Google Cloud, haz clic en Data Fusion > Instancias.
-
Haz clic en Ver instancia junto a tu instancia. Si se te solicita, usa tus credenciales del lab para acceder. Si se te solicita hacer una visita guiada, haz clic en No, gracias.
-
En el menú de navegación de la IU de Cloud Data Fusion, haz clic en Wrangler.
-
En el panel izquierdo, haz clic en (GCS) Google Cloud Storage y selecciona Cloud Storage Default.
-
Haz clic en el bucket que corresponde al ID de tu proyecto.
-
Haz clic en titanic.csv.
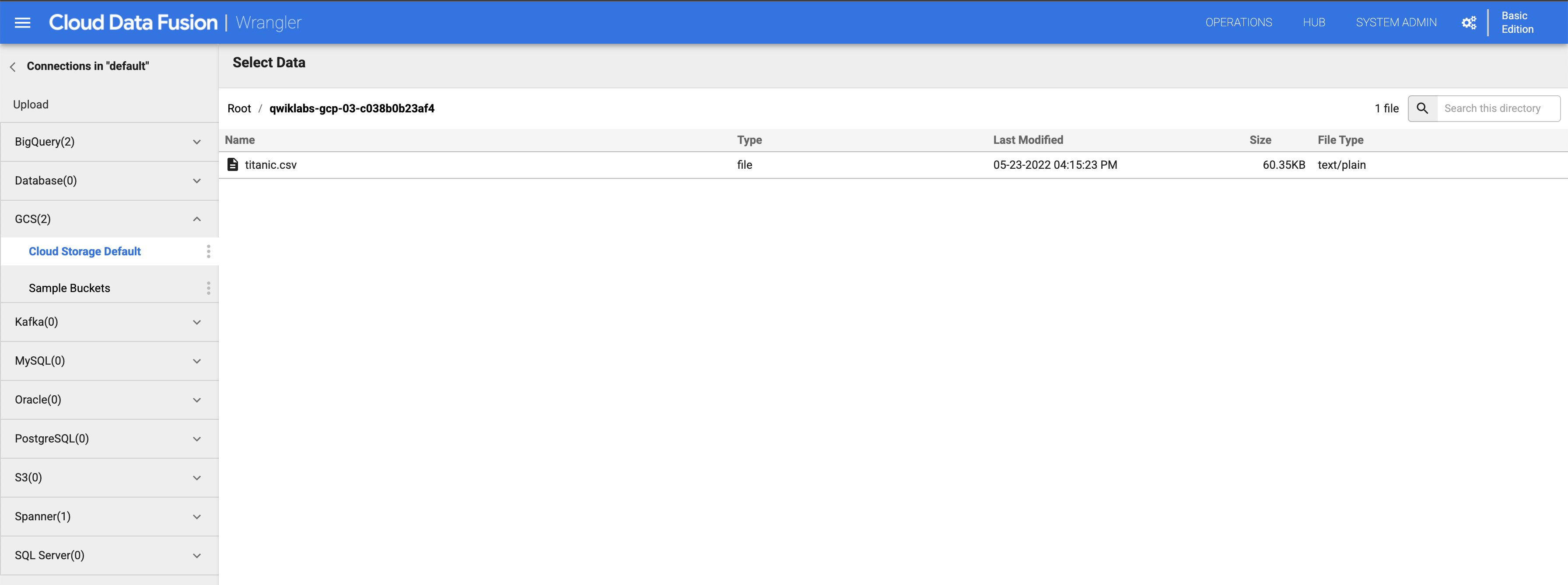
-
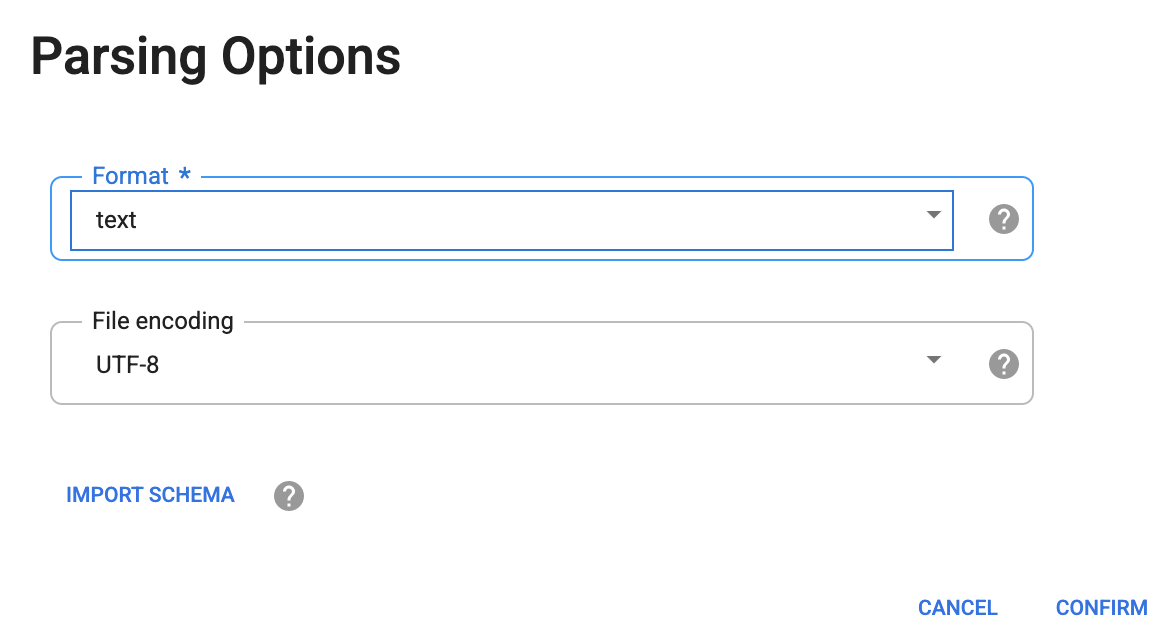
En el cuadro de diálogo Parsing Options, para Format, selecciona text y haz clic en Confirm.
Los datos se cargan en la pantalla de Wrangler. Ahora puedes comenzar a aplicar las transformaciones de datos de forma iterativa.
-
Para analizar los datos CSV sin procesar en un formato tabular, haz clic en la flecha junto al encabezado de la columna body, selecciona Parse y, luego, CSV.
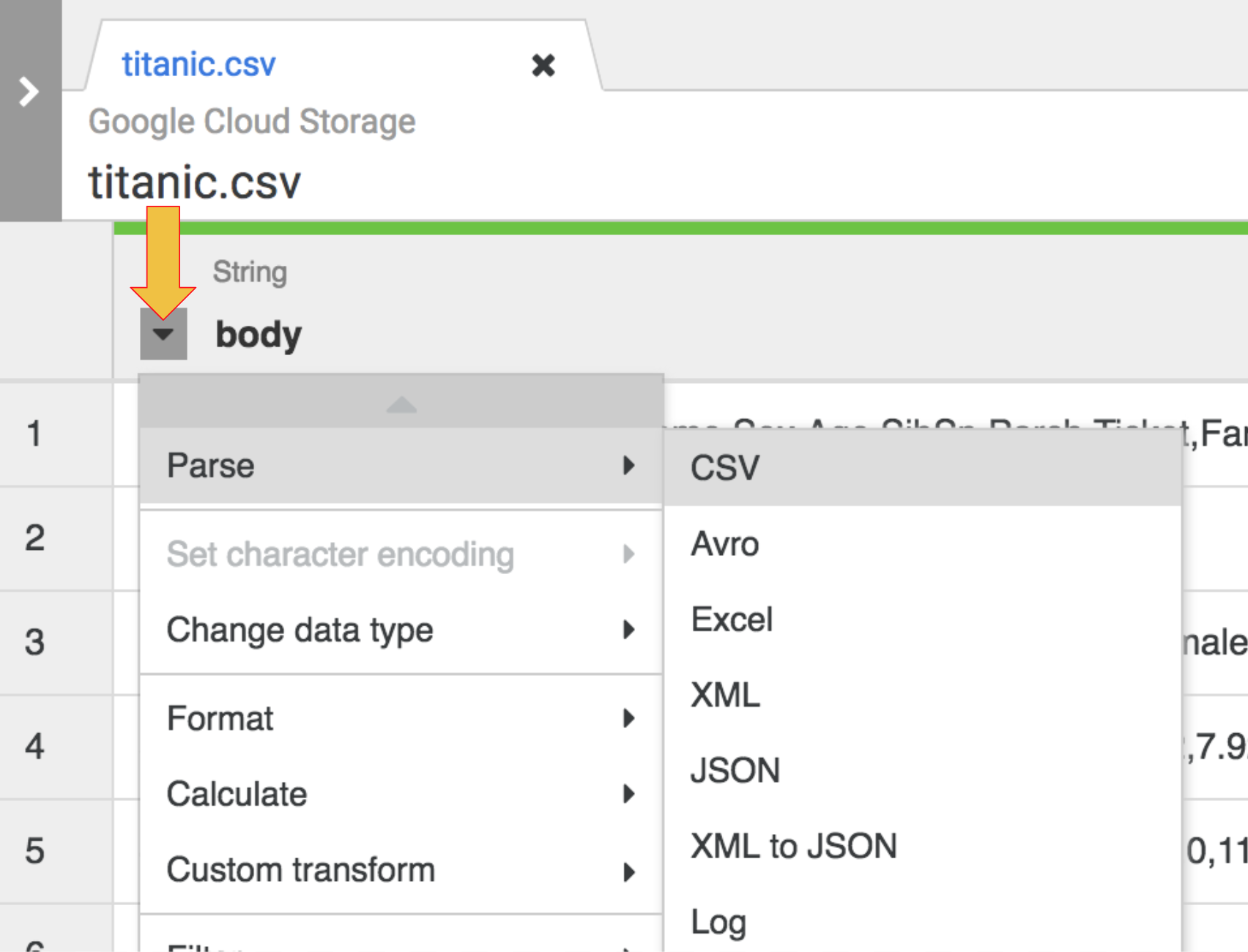
-
En el cuadro de diálogo Parse as CSV, selecciona la casilla de verificación Set first row as header y, luego, haz clic en Apply.
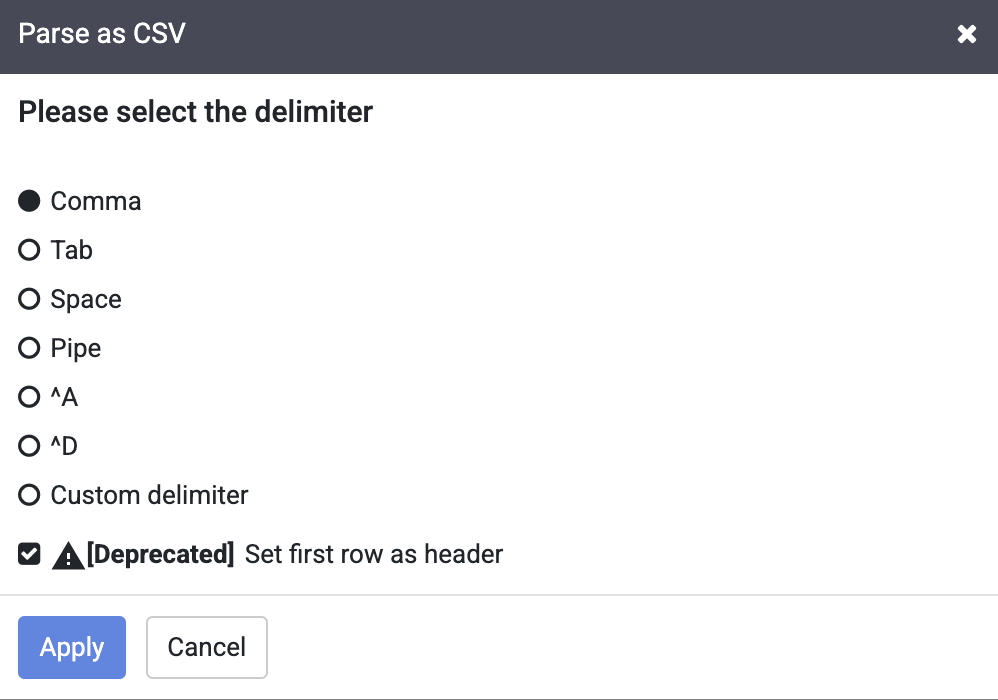
Nota: Puedes pasar por alto la advertencia de obsoleto que aparece junto a la casilla de verificación Set first row as header.
- En esta fase, los datos sin procesar están analizados y puedes ver las columnas generadas por esta operación (a la derecha de la columna body). En el extremo derecho, verás la lista de todos los nombres de las columnas.
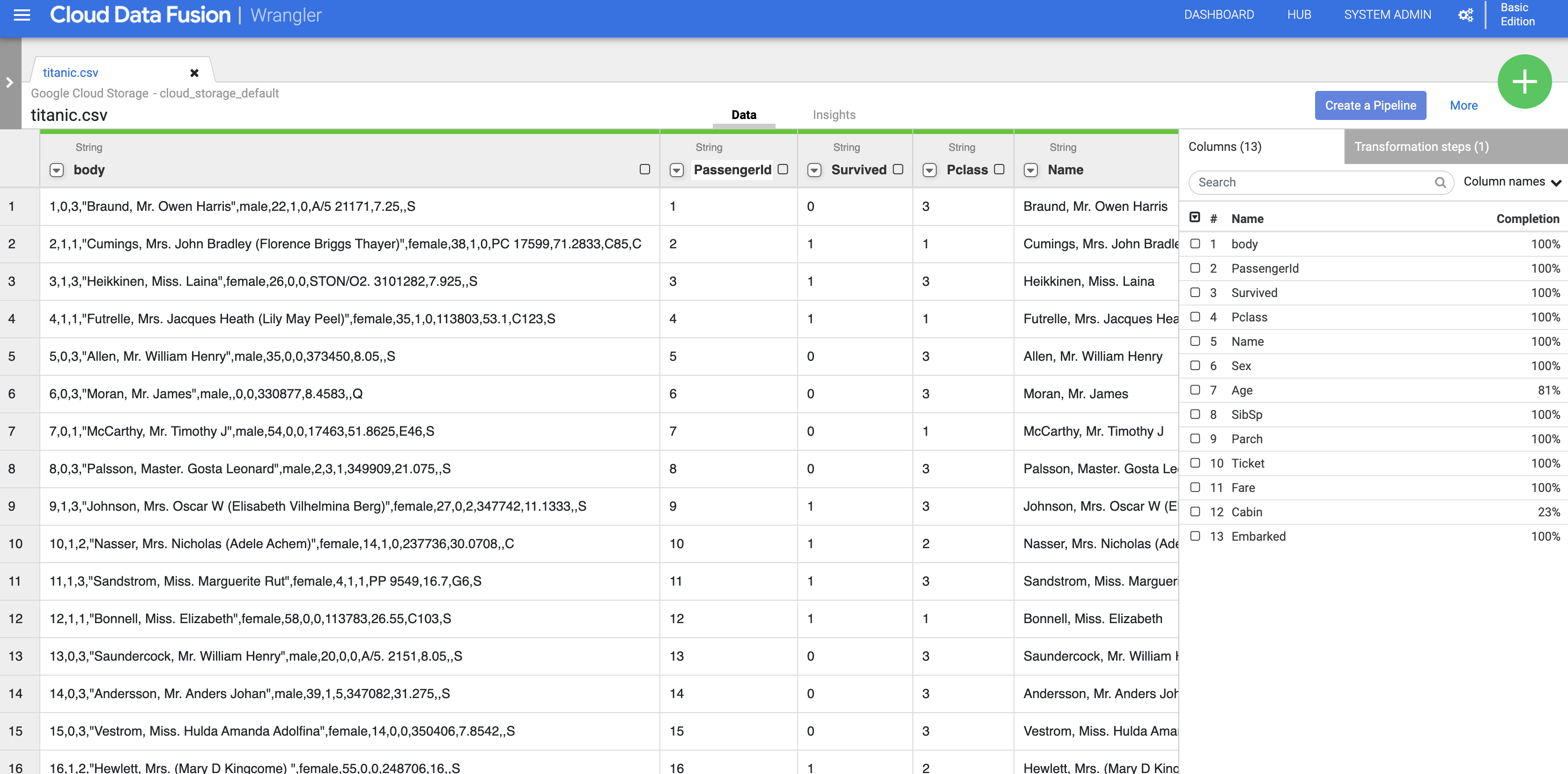
- Para quitar la columna de datos sin procesar, haz clic en la flecha junto al encabezado de la columna body y, luego, en Delete column.
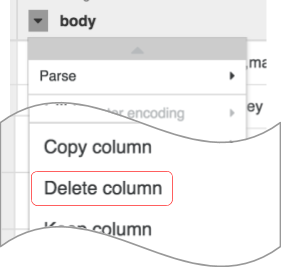
Nota: Para aplicar transformaciones, también puedes usar la interfaz de línea de comandos (CLI). La CLI es la barra negra en la parte inferior de la pantalla (con el prompt $ de color verde). Cuando comiences a escribir comandos, se iniciará la función de autocompletar que te mostrará una opción de concordancia. Por ejemplo, para quitar la columna body, podrías haber usado de forma alternativa la directiva: drop :body.
- En el lado derecho de la IU de Wrangler, haz clic en la pestaña Transformation steps para ver tu receta actual.
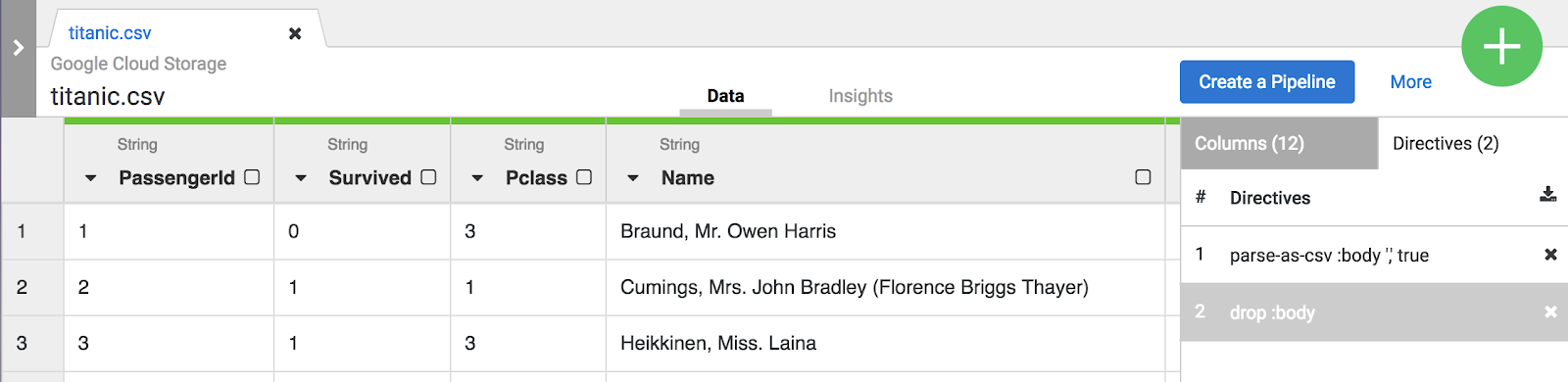
Nota: Tanto las selecciones de menú como la CLI crean directivas que son visibles en la pestaña Transformation steps
en el lado derecho de la pantalla. Las directivas son transformaciones individuales que se denominan en conjunto “receta”.
Para los fines de este lab, las dos transformaciones, o receta, son suficientes para crear la canalización de ETL. El siguiente paso es llevar esta receta a un paso de creación de canalización en el que la receta representa la T en ETL.
-
Haz clic en el botón Create a pipeline para pasar a la siguiente sección y crear una canalización, en la que verás cómo se une la canalización de ETL.

-
Cuando se te presente el próximo diálogo, selecciona Batch pipeline para continuar.
Nota: Una canalización por lotes puede ejecutarse de forma interactiva o programarse para ejecutarse con una frecuencia de hasta 5 minutos o tan solo una vez al año.
Tarea 4: Configura el receptor de BigQuery
El resto de las tareas de creación de canalizaciones se realizarán en Pipeline Studio, la IU que te permite componer canalizaciones de datos de forma visual. Ahora deberías ver los componentes básicos principales de tu canalización de ETL en el estudio.
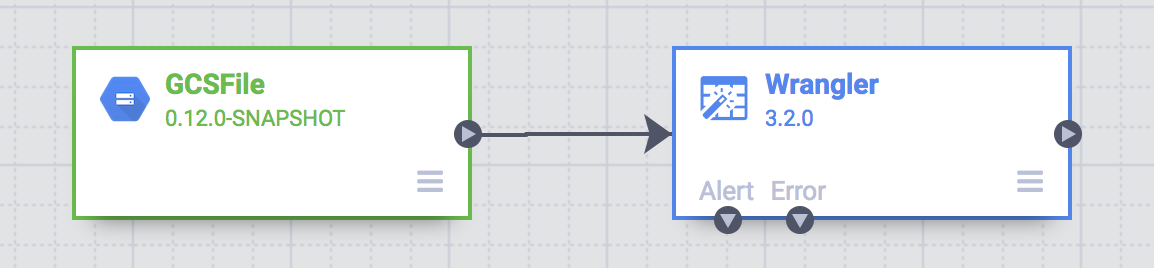
En este punto, verás dos nodos en tu canalización: el complemento GCS File, que leerá el archivo CSV de Google Cloud Storage, y el complemento Wrangler, que contiene la receta con las transformaciones.
Nota: Un nodo en una canalización es un objeto que está conectado en una secuencia para producir un grafo acíclico dirigido. P. ej., Source, Sink, Transform, Action, etcétera.
Estos dos complementos (nodos) representan la E y la T en tu canalización de ETL. Para completar esta canalización, agrega el receptor de BigQuery, la parte L de nuestro proceso ETL.
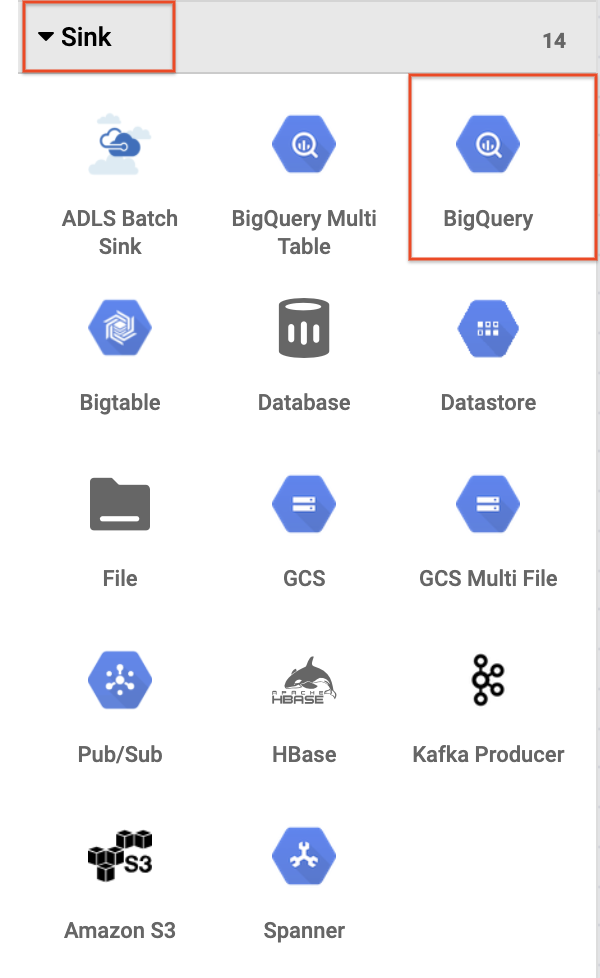
- Para agregar el receptor de BigQuery a la canalización, navega a la sección Sink en el panel de la izquierda y haz clic en el ícono de BigQuery para ponerlo en el lienzo.
-
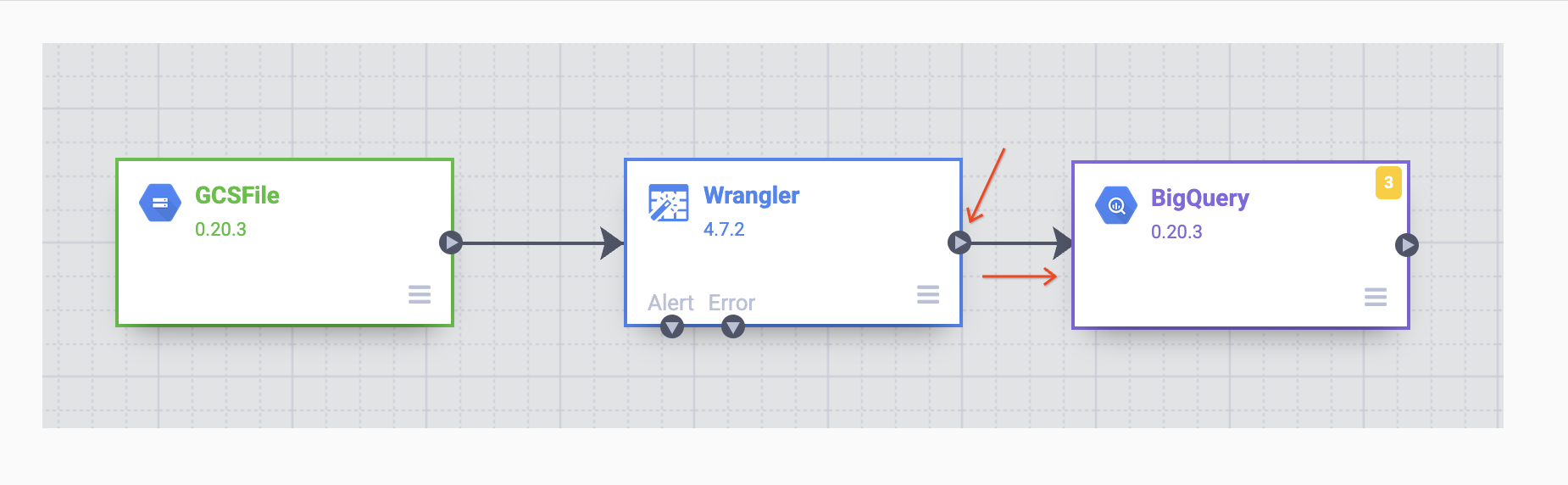
Cuando el receptor de BigQuery se haya ubicado en el lienzo, conecta el nodo de Wrangler con el nodo de BigQuery. Para hacerlo, arrastra la flecha desde el nodo de Wrangler y conéctalo al nodo de BigQuery como se muestra a continuación. Ahora, lo único que queda por hacer es especificar algunas opciones de configuración para que puedas escribir los datos en el conjunto de datos que quieras.
Tarea 5: Configura la canalización
Ahora es el momento de configurar la canalización. Para ello, abre las propiedades de cada nodo para verificar su configuración o hacer cambios adicionales.
- Coloca el cursor sobre el nodo GCS y se mostrará un botón Properties. Haz clic en este botón para abrir la configuración.
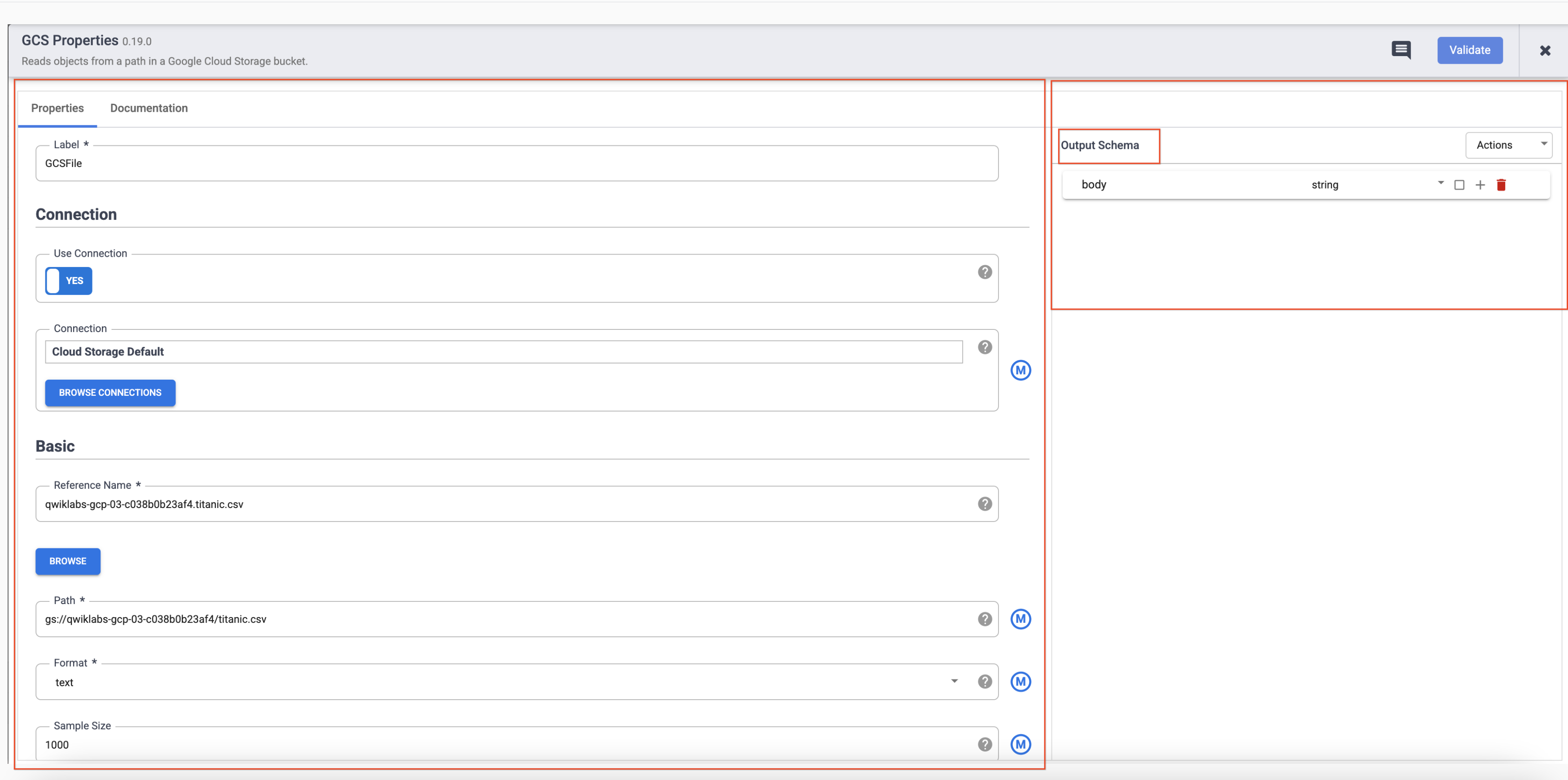
Cada complemento tiene algunos campos obligatorios que deben estar presentes y están marcados con un asterisco (*). Según el complemento que uses, es posible que veas un esquema de entrada a la izquierda, una sección de configuración en el medio y un esquema de salida a la derecha.
Notarás que los complementos de Sink no tienen un esquema de salida y los complementos de Source no tienen un esquema de entrada. Ambos complementos, Sink y Source, también tendrán un campo obligatorio Reference name para identificar la fuente o el receptor de datos para el linaje.
Cada complemento tendrá un campo Label. Esta es la etiqueta del nodo que ves en el lienzo en el que se muestra tu canalización.
-
Haz clic en X en la parte superior derecha del cuadro Properties para cerrarlo.
-
Luego, coloca el cursor sobre el nodo Wrangler y haz clic en Properties.
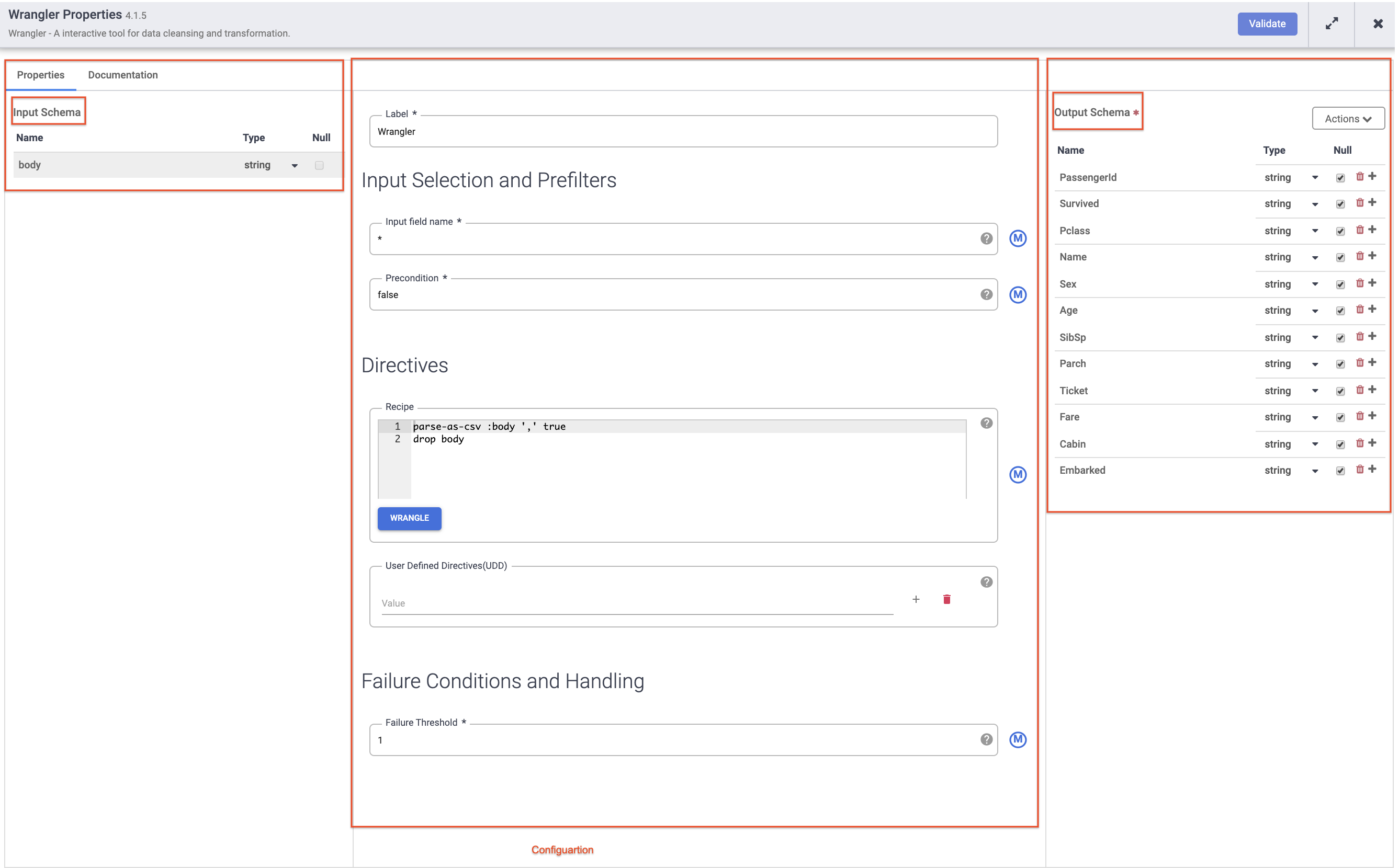
Nota:
Complementos como Wrangler que contienen un esquema de entrada. Estos son los campos que se pasan al complemento para que se procesen. Una vez que el complemento los procesa, los datos salientes pueden enviarse en el esquema de salida al siguiente nodo de la canalización o, en el caso de un receptor, escribirse en un conjunto de datos.
-
Haz clic en X en la parte superior derecha del cuadro Properties para cerrarlo.
-
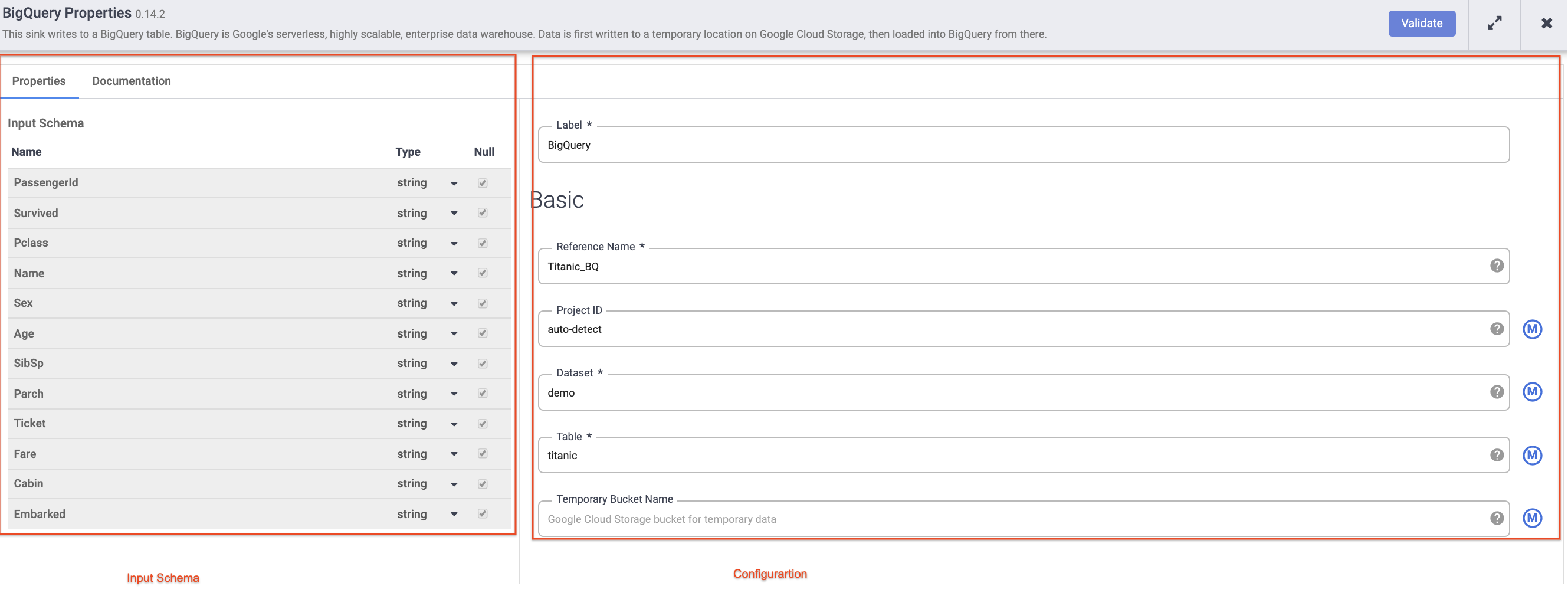
Coloca el cursor sobre el nodo de BigQuery, haz clic en Properties y, luego, ingresa los siguientes parámetros de configuración:
-
En Reference name, ingresa Titanic_BQ.
-
En Dataset, ingresa demo.
-
En Table, ingresa titanic.
-
Haz clic en X en la parte superior derecha del cuadro Properties para cerrarlo.
Tarea 6: Prueba la canalización
Ahora, solo queda probar tu canalización para ver si funciona como se espera, pero antes de hacerlo, asegúrate de asignarle un nombre a tu borrador y guardarlo para no perder nada de tu trabajo.
-
Ahora, haz clic en Save en el menú de la esquina superior derecha. Se te pedirá que le asignes un nombre y agregues una descripción a la canalización.
- Ingresa
ETL-batch-pipeline como el nombre de tu canalización.
- Ingresa
ETL pipeline to parse CSV, transform and write output to BigQuery en la descripción.
-
Haz clic en Save.
-
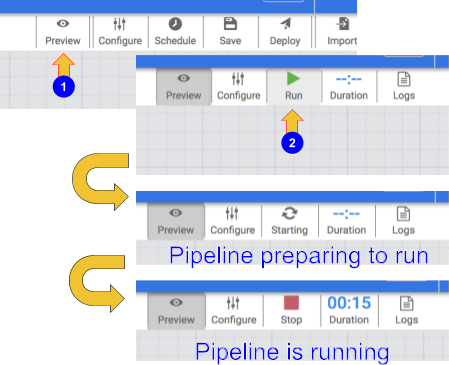
Para probar tu canalización, haz clic en el ícono Preview. En la barra de botones, ahora se mostrará un ícono de ejecución en el que puedes hacer clic para ejecutar la canalización en modo de vista previa.
-
Haz clic en el ícono Run. Mientras la canalización se ejecuta en modo de vista previa, no se escriben datos en la tabla de BigQuery, pero podrás confirmar que los datos se leen correctamente y que se escribirán como se espera una vez que se implemente la canalización. El botón de vista previa es un botón de activación, así que asegúrate de hacer clic en él de nuevo para salir del modo de vista previa cuando termines.
-
Cuando tu canalización termine de ejecutarse, coloca el cursor sobre el nodo Wrangler y haz clic en Properties. Luego, haz clic en la pestaña Preview. Si todo salió bien, deberías ver los datos sin procesar que se ingresaron, el nodo a la izquierda y los registros analizados que se emitirán como salida al nodo de la derecha. Haz clic en X en la parte superior derecha del cuadro Properties para cerrarlo.
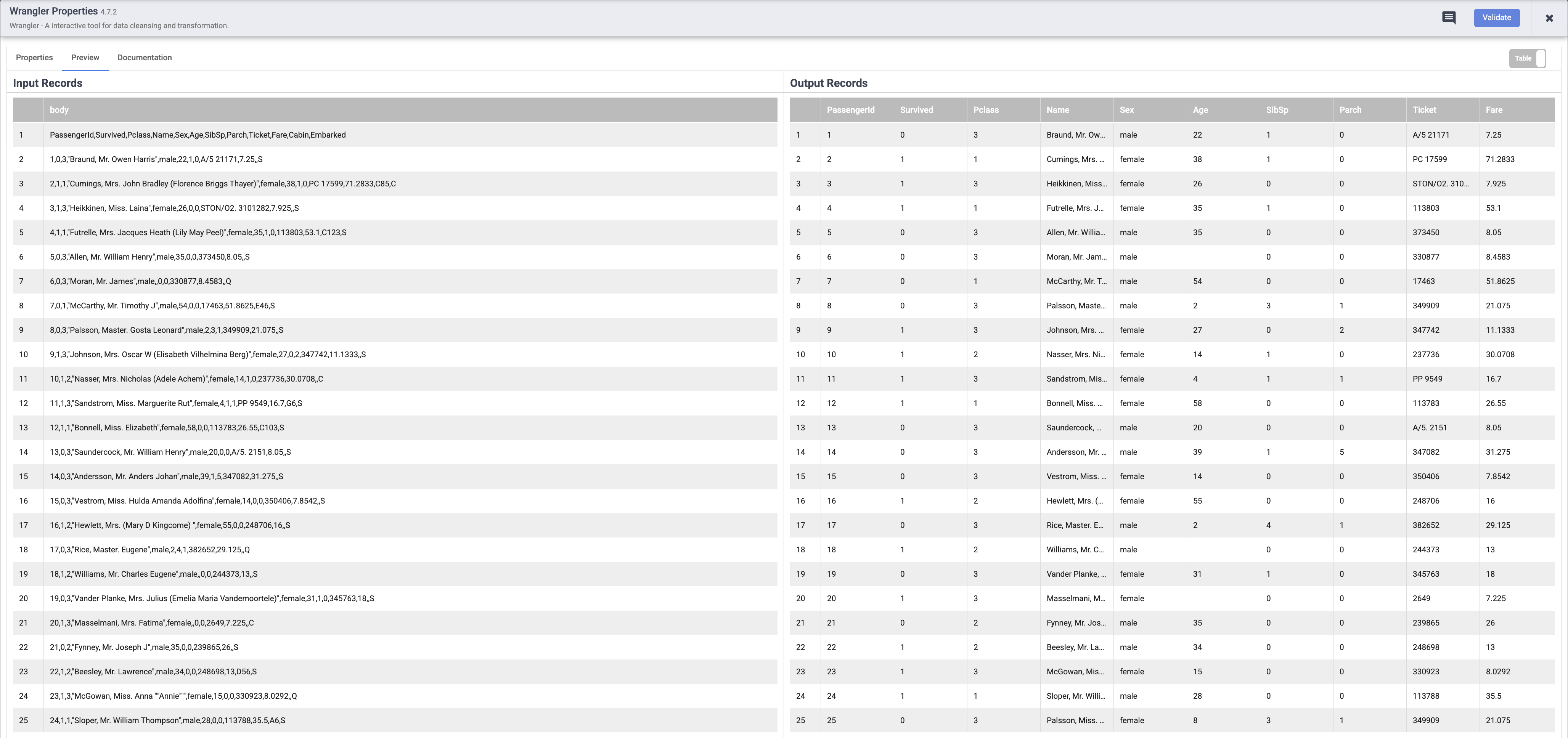
Nota: Cada nodo que opera con datos debería mostrarte una salida similar. Esta es una buena forma de probar tu trabajo para asegurarte de que estás en el camino correcto antes de implementar tu canalización. Si encuentras algún error, puedes corregirlo fácilmente en el modo borrador.
-
Haz clic en el ícono Preview de nuevo, esta vez para salir del modo de vista previa.
-
Si todo parece estar bien hasta ahora, puedes continuar con la implementación de la canalización. Haz clic en el ícono Deploy en la parte superior derecha  para implementar la canalización.
para implementar la canalización.
Verás un diálogo de confirmación que indica que tu canalización se está implementando:
-
Una vez que tu canalización se implementó correctamente, ya puedes ejecutar tu canalización de ETL y cargar algunos datos en BigQuery.
-
Haz clic en el ícono Run para ejecutar el trabajo de ETL.
-
Cuando termines, deberías ver que el estado de la canalización cambia a Succeeded, lo que indica que la canalización se ejecutó correctamente.

-
A medida que la canalización procesa los datos, verás métricas que emite cada nodo de la canalización y que indican cuántos registros se procesaron.
En la operación de análisis, se muestran 892 registros, mientras que en la fuente había 893. ¿Qué sucedió? La operación de análisis tomó la primera fila y la consumió para establecer los encabezados de las columnas, por lo que los 892 registros restantes son lo que quedó para procesar.

Haz clic en Revisar mi progreso para verificar el objetivo.
Implementar y ejecutar una canalización por lotes
Tarea 7: Consulta los resultados
La canalización escribe el resultado en una tabla de BigQuery. Puedes verificarlo con los siguientes pasos.
-
En una nueva pestaña, abre la IU de BigQuery en la consola de Cloud o haz clic con el botón derecho en la pestaña de la consola y selecciona Duplicar y, luego, usa el menú de navegación para seleccionar BigQuery. Cuando se te solicite, haz clic en Listo.
-
En el panel izquierdo, en la sección Explorador clásico, haz clic en el ID del proyecto (comenzará con qwiklabs).
-
En el conjunto de datos demo de tu proyecto, haz clic en la tabla titanic y, luego, en "+" (consulta en SQL). Ejecuta una consulta simple, como la siguiente:
SELECT * FROM `demo.titanic` LIMIT 10
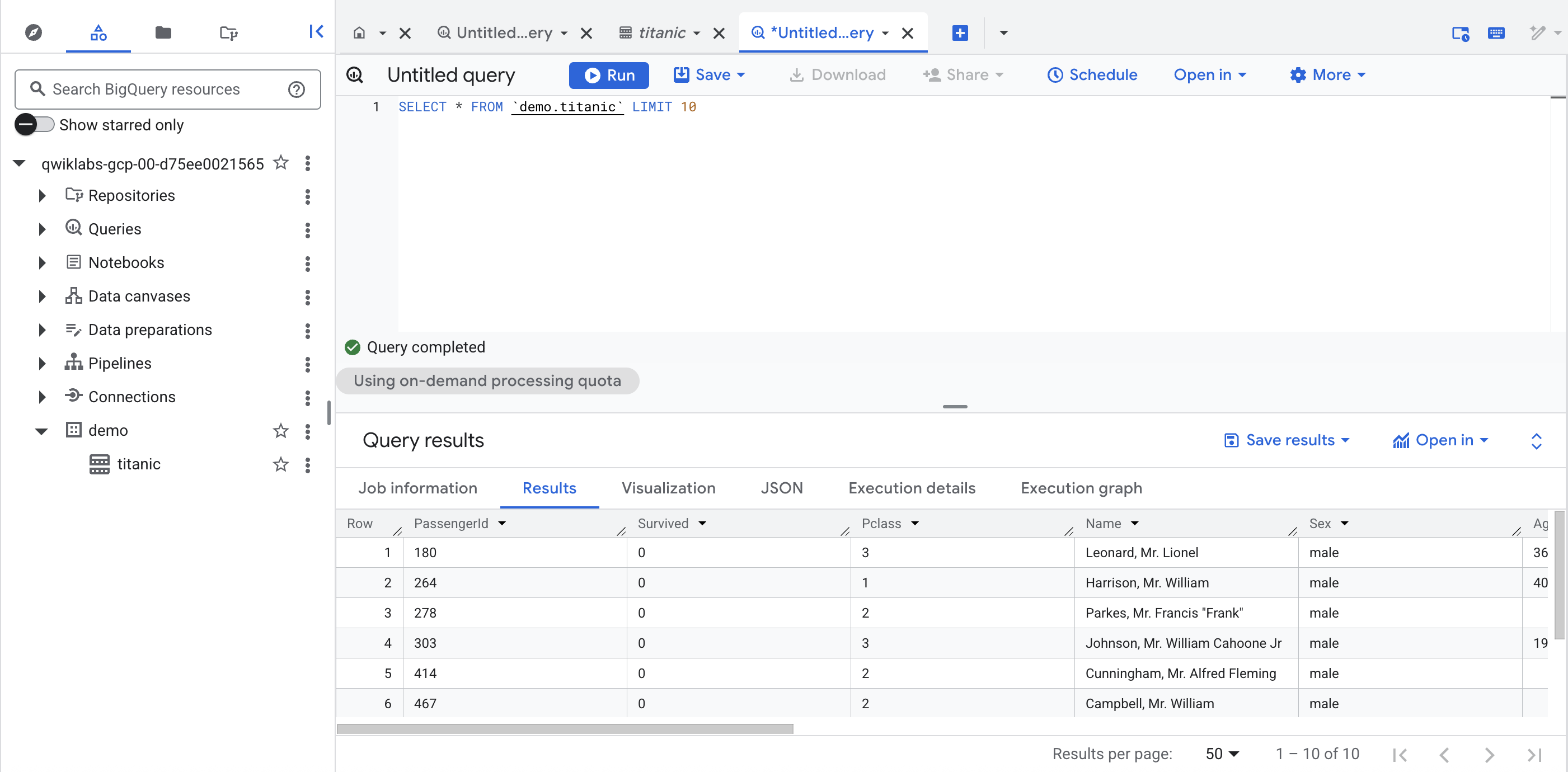
Haz clic en Revisar mi progreso para verificar el objetivo.
Consultar los resultados
¡Felicitaciones!
Ahora aprendiste a usar los componentes básicos disponibles en Pipeline Studio de Cloud Data Fusion para crear una canalización por lotes. También aprendiste a usar Wrangler para crear pasos de transformación para tus datos.
Realiza tu próximo lab
Continúa con Cómo compilar transformaciones y preparar datos con Wrangler en Cloud Data Fusion.
Última actualización del manual: 27 de enero de 2026
Prueba más reciente del lab: 27 de enero de 2026
Copyright 2026 Google LLC. Todos los derechos reservados. Google y el logotipo de Google son marcas de Google LLC. El resto de los nombres de productos y empresas pueden ser marcas de las respectivas empresas a las que están asociados.





