


![[インスタンスの詳細] ページでハイライト表示されているサービス アカウント](https://cdn.qwiklabs.com/cb%2B36UZ5dCnHJijpgAi7c7wrMjcSdEmdd5VZJG4NnWI%3D)
![ハイライト表示された [インスタンスを表示] リンク](https://cdn.qwiklabs.com/VEcWYtUEKcc3zx9JzLcTxIp0lFLAtLyOVuzHuJuR4sg%3D)
![ハイライト表示された [HUB] リンク](https://cdn.qwiklabs.com/L%2FsbuTy4UgnAWPS%2Bo2tYtD2NdXO2bzXjIGRKLL3bswc%3D)
![パイプラインのページでハイライト表示された [Cloud Data Fusion Quickstart] タイル](https://cdn.qwiklabs.com/Q7tlfo3qksHNYYDRSBcR9QtLuzxy24VdmboAKchaq4c%3D)

始める前に
- ラボでは、Google Cloud プロジェクトとリソースを一定の時間利用します
- ラボには時間制限があり、一時停止機能はありません。ラボを終了した場合は、最初からやり直す必要があります。
- 画面左上の [ラボを開始] をクリックして開始します
Create a cloud data fusion instance
/ 25
Add Cloud Data Fusion API Service Agent role to service account
/ 25
Deploy a sample pipeline
/ 25
View the result
/ 25
Create a cloud data fusion instance
/ 25
Add Cloud Data Fusion API Service Agent role to service account
/ 25
Deploy a sample pipeline
/ 25
View the result
/ 25
このラボでは、Data Fusion インスタンスを作成し、提供されているサンプル パイプラインをデプロイする方法を学びます。このパイプラインは、NYT のベストセラー データを含む JSON ファイルを Cloud Storage から読み取ります。その後、ファイルに対して変換を実行し、データの解析とクリーニングを行います。最後に、レコードのサブセットを BigQuery に読み込みます。
このラボでは、次の方法について学びます。
各ラボでは、新しい Google Cloud プロジェクトとリソースセットを一定時間無料で利用できます。
シークレット ウィンドウを使用して Google Skills にログインします。
ラボのアクセス時間(例: 1:15:00)に注意し、時間内に完了できるようにしてください。
一時停止機能はありません。必要な場合はやり直せますが、最初からになります。
準備ができたら、[ラボを開始] をクリックします。
ラボの認証情報(ユーザー名とパスワード)をメモしておきます。この情報は、Google Cloud Console にログインする際に使用します。
[Google Console を開く] をクリックします。
[別のアカウントを使用] をクリックし、このラボの認証情報をコピーしてプロンプトに貼り付けます。
他の認証情報を使用すると、エラーが発生したり、料金の請求が発生したりします。
利用規約に同意し、再設定用のリソースページをスキップします。
[ラボを開始] ボタンをクリックします。ラボの料金をお支払いいただく必要がある場合は、表示されるダイアログでお支払い方法を選択してください。 左側の [ラボの詳細] ペインには、以下が表示されます。
[Google Cloud コンソールを開く] をクリックします(Chrome ブラウザを使用している場合は、右クリックして [シークレット ウィンドウで開く] を選択します)。
ラボでリソースがスピンアップし、別のタブで [ログイン] ページが表示されます。
ヒント: タブをそれぞれ別のウィンドウで開き、並べて表示しておきましょう。
必要に応じて、下のユーザー名をコピーして、[ログイン] ダイアログに貼り付けます。
[ラボの詳細] ペインでもユーザー名を確認できます。
[次へ] をクリックします。
以下のパスワードをコピーして、[ようこそ] ダイアログに貼り付けます。
[ラボの詳細] ペインでもパスワードを確認できます。
[次へ] をクリックします。
その後次のように進みます。
その後、このタブで Google Cloud コンソールが開きます。

Cloud Shell は、開発ツールが組み込まれた仮想マシンです。5 GB の永続ホーム ディレクトリを提供し、Google Cloud 上で実行されます。Cloud Shell を使用すると、コマンドラインで Google Cloud リソースにアクセスできます。gcloud は Google Cloud のコマンドライン ツールで、Cloud Shell にプリインストールされており、Tab キーによる入力補完がサポートされています。
Google Cloud Console のナビゲーション パネルで、「Cloud Shell をアクティブにする」アイコン(
[次へ] をクリックします。
環境がプロビジョニングされ、接続されるまでしばらく待ちます。接続の際に認証も行われ、プロジェクトは現在のプロジェクト ID に設定されます。次に例を示します。
有効なアカウント名前を一覧表示する:
(出力)
(出力例)
プロジェクト ID を一覧表示する:
(出力)
(出力例)
Google Cloud で作業を開始する前に、Identity and Access Management(IAM)内で適切な権限がプロジェクトに付与されていることを確認する必要があります。
Google Cloud コンソールのナビゲーション メニュー(
Compute Engine のデフォルトのサービス アカウント {project-number}-compute@developer.gserviceaccount.com が存在し、編集者のロールが割り当てられていることを確認します。アカウントの接頭辞はプロジェクト番号で、ナビゲーション メニュー > [Cloud の概要] から確認できます。
アカウントが IAM に存在しない場合やアカウントに編集者のロールがない場合は、以下の手順に沿って必要なロールを割り当てます。
Google Cloud コンソールのナビゲーション メニューで、[Cloud の概要] をクリックします。
[プロジェクト情報] カードからプロジェクト番号をコピーします。
ナビゲーション メニューで、[IAM と管理] > [IAM] をクリックします。
IAM ページの上部にある [追加] をクリックします。
新しいプリンシパルの場合は、次のように入力します。
{project-number} はプロジェクト番号に置き換えてください。
[ロールを選択] で、[基本](または [Project])> [編集者] を選択します。
[保存] をクリックします。
Cloud コンソールのナビゲーション メニュー(
検索ボックスに「Data fusion」と入力して Cloud Data Fusion API を検索し、そのハイパーリンクをクリックします。
API はすでに有効になっているため、[管理]、[API を無効にする] の順にクリックします。無効にすることを確認します。
API が無効になったら、[有効にする] をクリックして API を再度有効にします。
Google Cloud コンソールのナビゲーション メニュー(
セクションの上部にある [インスタンスの作成] リンクをクリックして、Cloud Data Fusion インスタンスを作成します。
読み込まれた [Data Fusion インスタンスの作成] ページで、次の操作を行います。
a. インスタンスの名前(例: cdf-lab-instance)を入力します。
b. [リージョン] で「us-central1」を選択します。
c. [エディション] で [Basic] を選択します。
d. [認可] セクションで、必要に応じて [権限を付与] をクリックします。
e. [詳細オプション] の横にあるプルダウン アイコンをクリックし、[高度なモニタリングとロギング] の下にある [Managed Service for Spark Cloud Logging] のチェックボックスをオンにします。
f. 他のフィールドはそのままにして、[作成] をクリックします。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
次に、以下の手順に沿って、インスタンスに関連付けられているサービス アカウントに権限を付与します。
Google Cloud コンソールのナビゲーション メニュー(
[IAM 権限] ページで、[+アクセスを許可] をクリックします。
[新しいプリンシパル] フィールドに Managed Service for Spark サービス アカウントを貼り付けます。
[ロールを選択] フィールドをクリックし、「Cloud Data Fusion API サービス エージェント」と入力します。最初の数文字を入力すると [Cloud Data Fusion API サービス エージェント] が表示されるので、それを選択します。
[保存] をクリックします。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
Cloud Data Fusion を使用する際は、Cloud コンソールと別個の Cloud Data Fusion UI の両方を使用します。
Cloud コンソールで可能な作業は、Cloud Data Fusion インスタンスの作成と削除、および Cloud Data Fusion インスタンスの詳細の表示です。
Cloud Data Fusion ウェブ UI では、Pipeline Studio や Wrangler などのさまざまなページを使用して Cloud Data Fusion の機能を使用できます。
Cloud Data Fusion UI を操作するには、次の手順に従います。
Google Cloud コンソールのナビゲーション メニュー(
Data Fusion インスタンスの横にある [インスタンスを表示] リンクをクリックします。ラボの認証情報を選択してログインし、必要に応じて [Google Service Control データの管理] の横にあるチェックボックスをオンにします。[続行] をクリックします。
サービスのガイドに進むダイアログが表示された場合は [キャンセル] をクリックします。これで Cloud Data Fusion UI が表示されるようになります。
Cloud Data Fusion ウェブ UI には固有のナビゲーション パネル(左側)があり、そこから必要なページに移動できます。
サンプル パイプラインは Cloud Data Fusion のハブに用意されています。このハブでは、再利用可能な Cloud Data Fusion パイプライン、プラグイン、ソリューションを共有できます。
左側のパネルで [Pipelines] をクリックします。
[Cloud Data Fusion Quickstart] パイプラインをクリックし、表示されたポップアップで [Create] をクリックします。
[Cloud Data Fusion Quickstart] 構成パネルで [Finish] をクリックします。
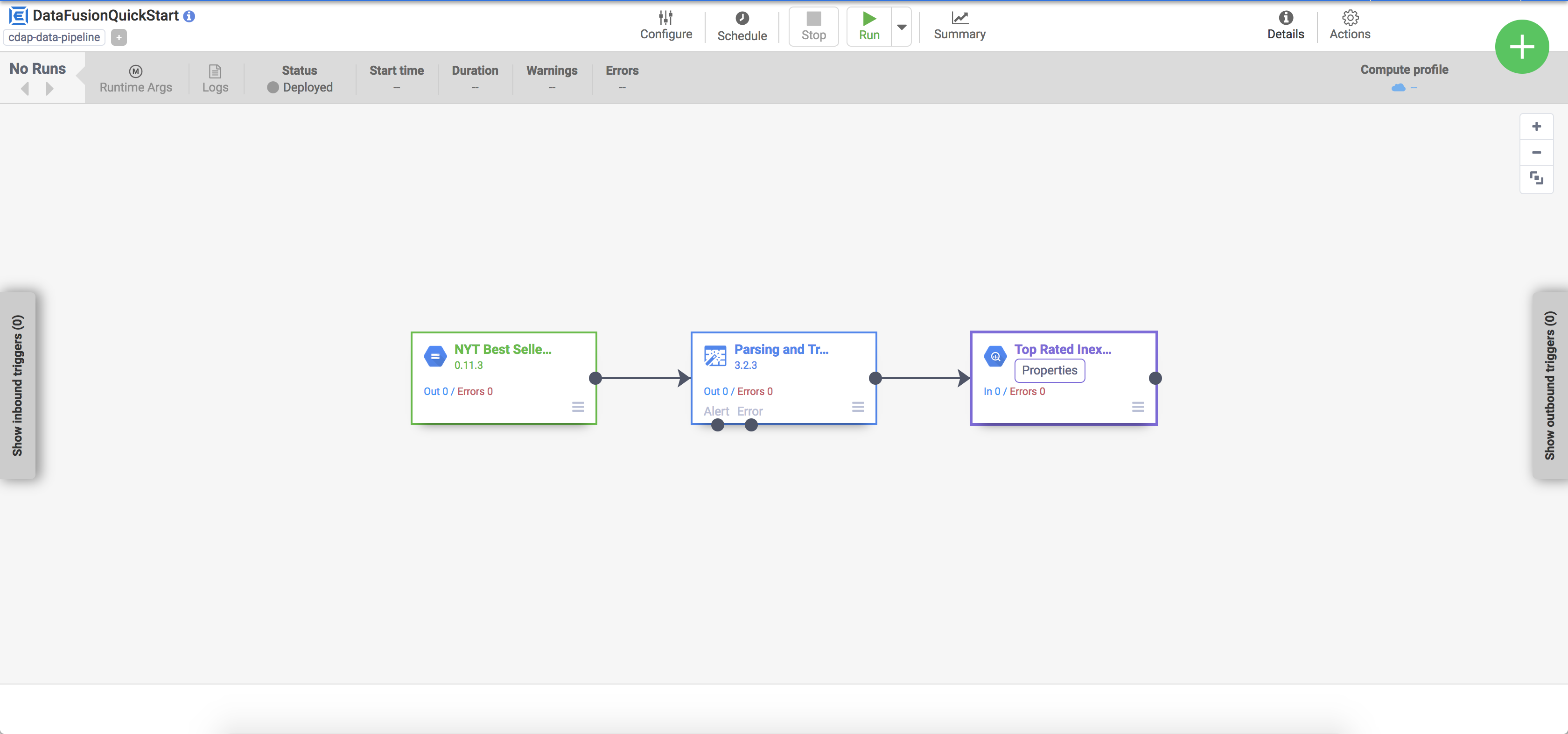
[Customize Pipeline] をクリックします。Pipeline Studio に、パイプラインの視覚的表現が表示されます。Pipeline Studio は、データ統合パイプライン開発用のグラフィカル インターフェースです。左側に使用可能なパイプライン プラグインが表示され、操作するパイプラインはメインのキャンバス領域に表示されます。パイプラインの各ノードの上にポインタを重ねて、表示される [Properties] ボタンをクリックすると、パイプラインの詳細を確認できます。各ノードの [Properties] メニューを使用して、そのノードに関連付けられているオブジェクトやオペレーションを表示できます。
デプロイされたパイプラインがパイプラインの詳細ビューに表示されます。このビューでは、次の操作を行うことができます。
パイプラインの構造と構成を表示する。
手動でパイプラインを実行するか、スケジュールやトリガーを設定する。
実行時間、ログ、指標など、パイプラインの実行履歴の概要を表示する。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
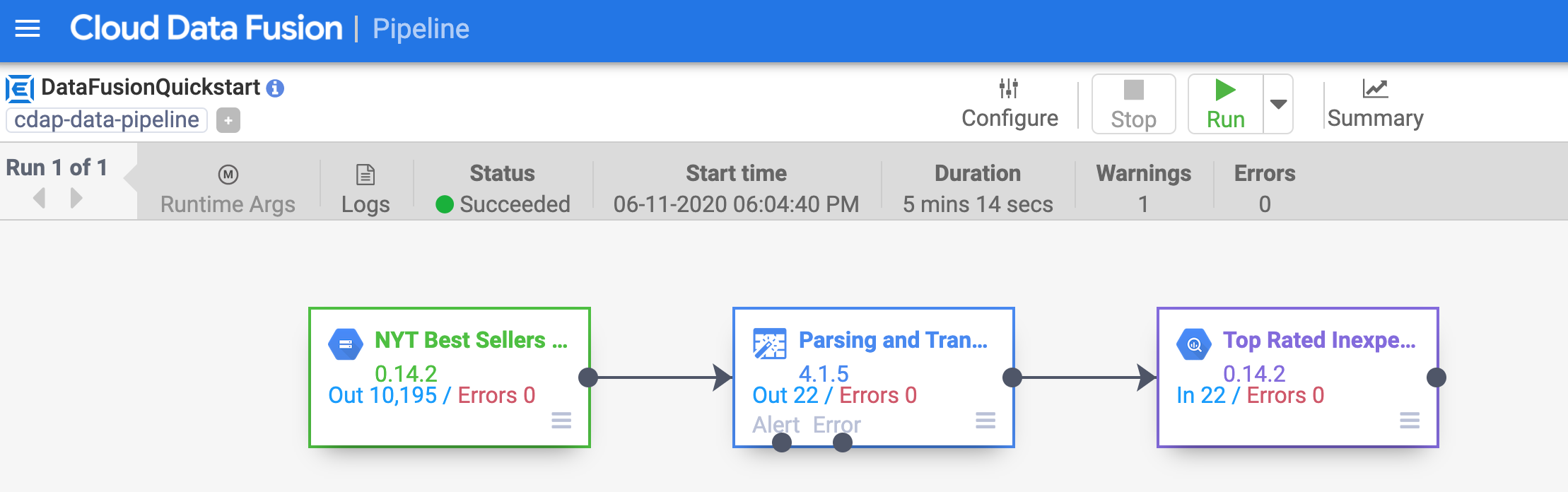
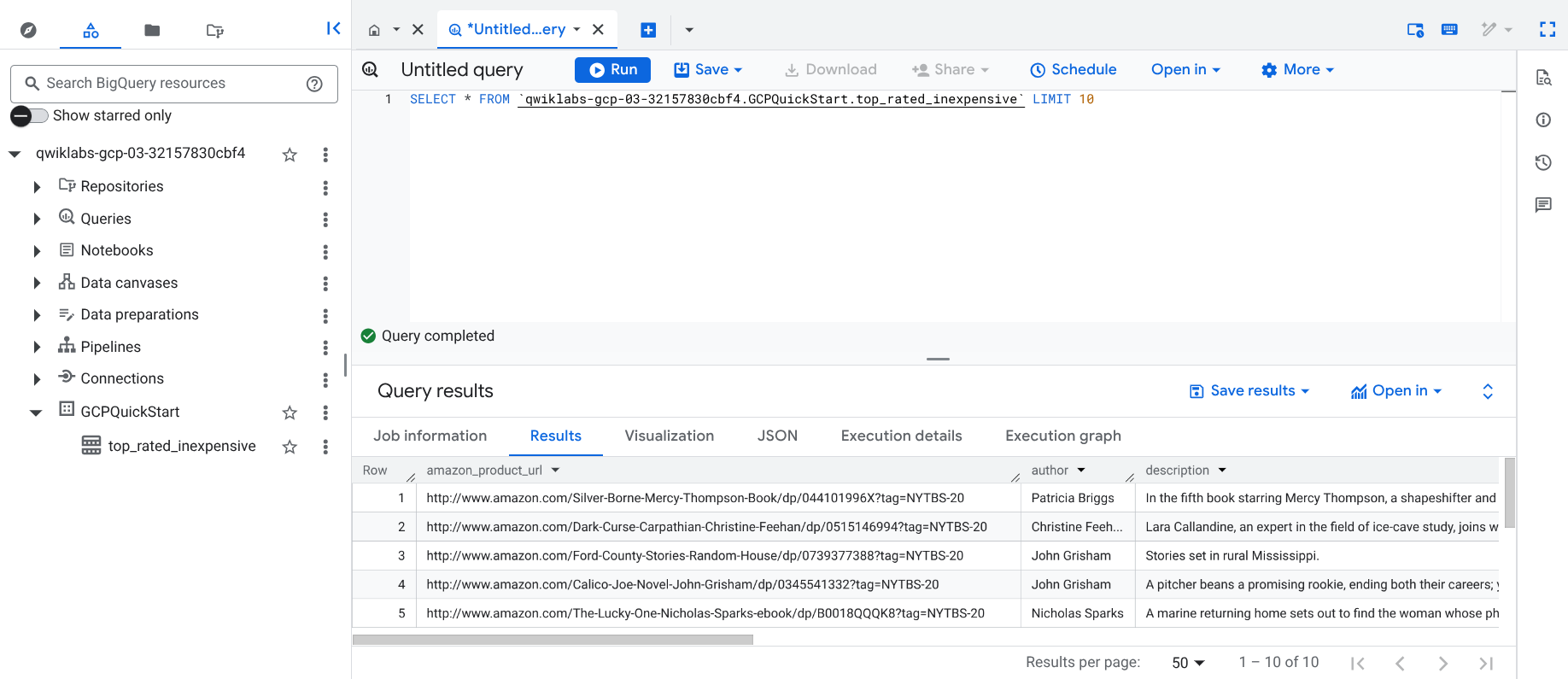
パイプラインは出力を BigQuery テーブルに書き込みます。次の手順で、この点を確認できます。
このリンクをクリックして Cloud コンソールの BigQuery UI を開くか、コンソールのタブを右クリックして [タブを複製] を選択してから、ナビゲーション メニュー(
[従来のエクスプローラ] ペインで、プロジェクト ID(qwiklabs で始まる ID)をクリックします。
プロジェクトの GCPQuickstart データセットの下にある top_rated_inexpensive テーブルをクリックします。
[+ SQL クエリ] をクリックし、以下のクエリを貼り付けて、[実行] をクリックします。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
このラボでは、Data Fusion インスタンスを作成する方法と、Cloud Storage から入力ファイルを読み取り、データを変換およびフィルタリングして、データのサブセットを BigQuery に出力するサンプル パイプラインをデプロイする方法を学びました。
ラボが完了したら、[ラボを終了] をクリックします。ラボで使用したリソースが Google Skills から削除され、アカウントの情報も消去されます。
ラボの評価を求めるダイアログが表示されたら、星の数を選択してコメントを入力し、[送信] をクリックしてください。
星の数は、それぞれ次の評価を表します。
フィードバックを送信しない場合は、ダイアログ ボックスを閉じてください。
フィードバックやご提案の送信、修正が必要な箇所をご報告いただく際は、[サポート] タブをご利用ください。
マニュアルの最終更新日: 2025 年 12 月 17 日
ラボの最終テスト日: 2025 年 12 月 17 日
Copyright 2026 Google LLC All rights reserved. Google および Google のロゴは、Google LLC の商標です。その他すべての社名および製品名は、それぞれ該当する企業の商標である可能性があります。



このコンテンツは現在ご利用いただけません
利用可能になりましたら、メールでお知らせいたします

ありがとうございます。
利用可能になりましたら、メールでご連絡いたします

1 回に 1 つのラボ
既存のラボをすべて終了して、このラボを開始することを確認してください
ラボを開始するには、この簡単な手順を完了してください。