Add Cloud Data Fusion API Service Agent role to service account
Vérifier ma progression
/ 25
Deploy a sample pipeline
Vérifier ma progression
/ 25
View the result
Vérifier ma progression
/ 25
Create a cloud data fusion instance
Vérifier ma progression
/ 25
Add Cloud Data Fusion API Service Agent role to service account
Vérifier ma progression
/ 25
Deploy a sample pipeline
Vérifier ma progression
/ 25
View the result
Vérifier ma progression
/ 25
Cet atelier peut intégrer des outils d'IA pour vous accompagner dans votre apprentissage.
Présentation
Dans cet atelier, vous allez apprendre à créer une instance Data Fusion et à déployer un exemple de pipeline qui vous est fourni.
Le pipeline lit un fichier JSON dans Cloud Storage contenant les données sur les best-sellers du NYT. Le pipeline exécute ensuite des transformations sur le fichier pour analyser et nettoyer les données. Enfin, il charge un sous-ensemble des enregistrements dans BigQuery.
Objectifs
Dans cet atelier, vous allez apprendre à effectuer les tâches suivantes :
Créer une instance Data Fusion
Déployer un exemple de pipeline qui exécute des transformations sur un fichier JSON et filtre les résultats correspondants dans BigQuery
Configuration
Pour chaque atelier, nous vous attribuons un nouveau projet Google Cloud et un nouvel ensemble de ressources pour une durée déterminée, sans frais.
Connectez-vous à Google Skills dans une fenêtre de navigation privée.
Vérifiez le temps imparti pour l'atelier (par exemple : 01:15:00) : vous devez pouvoir le terminer dans ce délai.
Une fois l'atelier lancé, vous ne pouvez pas le mettre en pause. Si nécessaire, vous pourrez le redémarrer, mais vous devrez tout reprendre depuis le début.
Lorsque vous êtes prêt, cliquez sur Démarrer l'atelier.
Notez vos identifiants pour l'atelier (Nom d'utilisateur et Mot de passe). Ils vous serviront à vous connecter à la console Google Cloud.
Cliquez sur Ouvrir la console Google.
Cliquez sur Utiliser un autre compte, puis copiez-collez les identifiants de cet atelier lorsque vous y êtes invité.
Si vous utilisez d'autres identifiants, des messages d'erreur s'afficheront ou des frais seront appliqués.
Acceptez les conditions d'utilisation et ignorez la page concernant les ressources de récupération des données.
Démarrer l'atelier et se connecter à la console Google Cloud
Cliquez sur le bouton Démarrer l'atelier. Si l'atelier est payant, une boîte de dialogue s'affiche pour vous permettre de sélectionner un mode de paiement.
Sur la gauche, vous trouverez le panneau "Détails concernant l'atelier", qui contient les éléments suivants :
Le bouton "Ouvrir la console Google Cloud"
Le temps restant
Les identifiants temporaires que vous devez utiliser pour cet atelier
Des informations complémentaires vous permettant d'effectuer l'atelier
Cliquez sur Ouvrir la console Google Cloud (ou effectuez un clic droit et sélectionnez Ouvrir le lien dans la fenêtre de navigation privée si vous utilisez le navigateur Chrome).
L'atelier lance les ressources, puis ouvre la page "Se connecter" dans un nouvel onglet.
Conseil : Réorganisez les onglets dans des fenêtres distinctes, placées côte à côte.
Remarque : Si la boîte de dialogue Sélectionner un compte s'affiche, cliquez sur Utiliser un autre compte.
Si nécessaire, copiez le nom d'utilisateur ci-dessous et collez-le dans la boîte de dialogue Se connecter.
{{{user_0.username | "Username"}}}
Vous trouverez également le nom d'utilisateur dans le panneau "Détails concernant l'atelier".
Cliquez sur Suivant.
Copiez le mot de passe ci-dessous et collez-le dans la boîte de dialogue Bienvenue.
{{{user_0.password | "Password"}}}
Vous trouverez également le mot de passe dans le panneau "Détails concernant l'atelier".
Cliquez sur Suivant.
Important : Vous devez utiliser les identifiants fournis pour l'atelier. Ne saisissez pas ceux de votre compte Google Cloud.
Remarque : Si vous utilisez votre propre compte Google Cloud pour cet atelier, des frais supplémentaires peuvent vous être facturés.
Accédez aux pages suivantes :
Acceptez les conditions d'utilisation.
N'ajoutez pas d'options de récupération ni d'authentification à deux facteurs (ce compte est temporaire).
Ne vous inscrivez pas à des essais sans frais.
Après quelques instants, la console Cloud s'ouvre dans cet onglet.
Remarque : Pour accéder aux produits et services Google Cloud, cliquez sur le menu de navigation ou saisissez le nom du service ou du produit dans le champ Recherche.
Activer Cloud Shell
Cloud Shell est une machine virtuelle qui contient des outils pour les développeurs. Elle comprend un répertoire d'accueil persistant de 5 Go et s'exécute sur Google Cloud. Google Cloud Shell vous permet d'accéder via une ligne de commande à vos ressources Google Cloud. gcloud est l'outil de ligne de commande associé à Google Cloud. Il est préinstallé sur Cloud Shell et permet la saisie semi-automatique via la touche Tabulation.
Dans Google Cloud Console, dans le volet de navigation, cliquez sur Activer Cloud Shell ().
Cliquez sur Continuer.
Le provisionnement et la connexion à l'environnement prennent quelques instants. Une fois connecté, vous êtes en principe authentifié, et le projet est défini sur votre ID_PROJET. Exemple :
Avant de commencer à travailler dans Google Cloud, vous devez vous assurer de disposer des autorisations adéquates pour votre projet dans IAM (Identity and Access Management).
Dans la console Google Cloud, accédez au menu de navigation (), puis cliquez sur IAM et administration > IAM.
Vérifiez que le compte de service Compute par défaut {project-number}-compute@developer.gserviceaccount.com existe et qu'il est associé au rôle Éditeur. Le préfixe du compte correspond au numéro du projet, disponible sur cette page : Menu de navigation > Présentation Cloud.
Si le compte n'est pas disponible dans IAM ou n'est pas associé au rôle Éditeur, procédez comme suit pour lui attribuer le rôle approprié.
Dans la console Google Cloud, accédez au menu de navigation et cliquez sur Présentation Cloud.
Sur la carte Informations sur le projet, copiez le numéro du projet.
Dans le menu de navigation, cliquez sur IAM et administration > IAM.
En haut de la page IAM, cliquez sur Ajouter.
Dans le champ Nouveaux comptes principaux, saisissez :
Remplacez {project-number} par le numéro de votre projet.
Dans le champ Sélectionnez un rôle, sélectionnez De base (ou Projet) > Éditeur.
Cliquez sur Enregistrer.
Tâche 1 : Activer l'API Cloud Data Fusion
Dans la console Cloud, accédez au menu de navigation (), puis sélectionnez API et services > Bibliothèque.
Dans le champ de recherche, saisissez Data Fusion pour trouver l'API Cloud Data Fusion, puis cliquez sur le lien hypertexte.
L'API est déjà activée. Cliquez sur Gérer, puis sur Désactiver l'API. Confirmez l'opération en cliquant sur Désactiver.
Une fois l'API désactivée, cliquez sur Activer pour la réactiver.
Tâche 2 : Créer une instance Cloud Data Fusion
Dans la console Google Cloud, accédez au menu de navigation (), puis cliquez sur Afficher tous les produits. Sous Analytics, cliquez sur Data Fusion.
Pour créer une instance Cloud Data Fusion, cliquez sur le lien Créer une instance en haut de la section.
Sur la page Créer une instance Data Fusion qui s'affiche :
a. Saisissez le nom de votre instance (par exemple, cdf-lab-instance).
b. Pour la région, sélectionnez us-central1.
c. Sous Édition, sélectionnez De base.
d. Dans la section Autorisation, cliquez sur Accorder l'autorisation si nécessaire.
e. Cliquez sur la flèche déroulante à côté d'Options avancées. Sous Surveillance et journalisation avancées, cochez la case Managed Service for Spark Cloud Logging.
f. Sans modifier les autres champs, cliquez sur Créer.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Créer une instance Cloud Data Fusion
Remarque : La création de l'instance prend environ 10 minutes. Pendant ce temps, regardez cette présentation de Cloud Data Fusion enregistrée lors de la conférence Next 2019 (à partir du code temporel 15:31). Vérifiez de temps à autre l'état de votre instance. Vous pourrez terminer de regarder la vidéo une fois l'atelier terminé.
Remarque : N'oubliez pas que cet atelier est limité dans le temps et que vous perdrez votre travail une fois le délai écoulé.
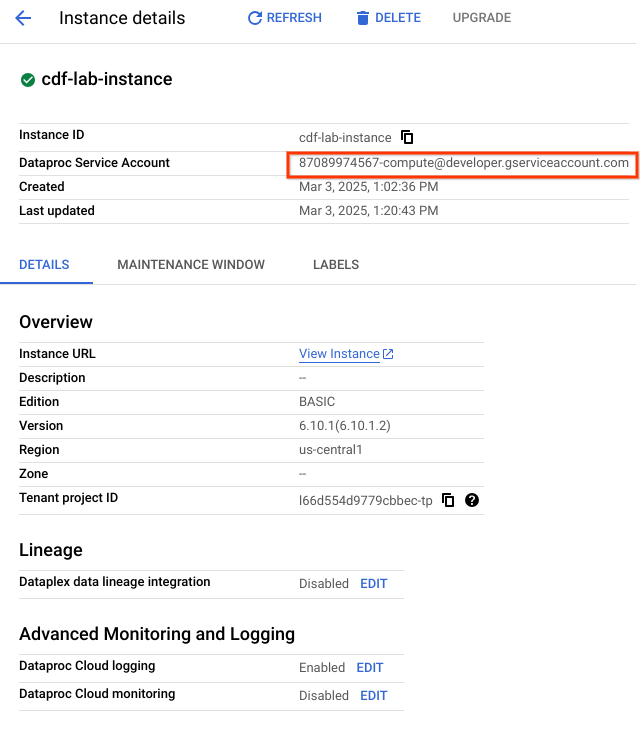
Vous allez à présent accorder des autorisations au compte de service associé à l'instance en suivant les étapes ci-dessous.
Cliquez sur le nom de l'instance. Sur la page "Détails de l'instance", copiez la valeur du champ Compte de service Managed Service for Spark dans votre presse-papiers.
Dans la console Cloud, accédez au menu de navigation (), puis sélectionnez IAM et administration > IAM.
Sur la page des autorisations IAM, cliquez sur +Accorder l'accès.
Collez la valeur du champ Compte de service Managed Service for Spark dans le champ "Nouveaux principaux".
Cliquez dans le champ "Sélectionner un rôle" et commencez à saisir Agent de service de l'API Cloud Data Fusion, puis sélectionnez ce rôle lorsqu'il apparaît.
Cliquez sur Enregistrer.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Ajouter le rôle Agent de service de l'API Cloud Data Fusion au compte de service
Tâche 3 : Parcourir l'UI de Cloud Data Fusion
Lorsque vous utilisez Cloud Data Fusion, vous utilisez à la fois la console Cloud et l'UI distincte de Cloud Data Fusion.
Dans la console Cloud, vous pouvez créer et supprimer des instances Cloud Data Fusion, et afficher les détails des instances Cloud Data Fusion.
Dans l'UI Web de Cloud Data Fusion, vous pouvez accéder à plusieurs pages, telles que Pipeline Studio ou encore Wrangler, qui permettent d'utiliser les différentes fonctionnalités de Cloud Data Fusion.
Pour ouvrir l'UI de Cloud Data Fusion, procédez comme suit :
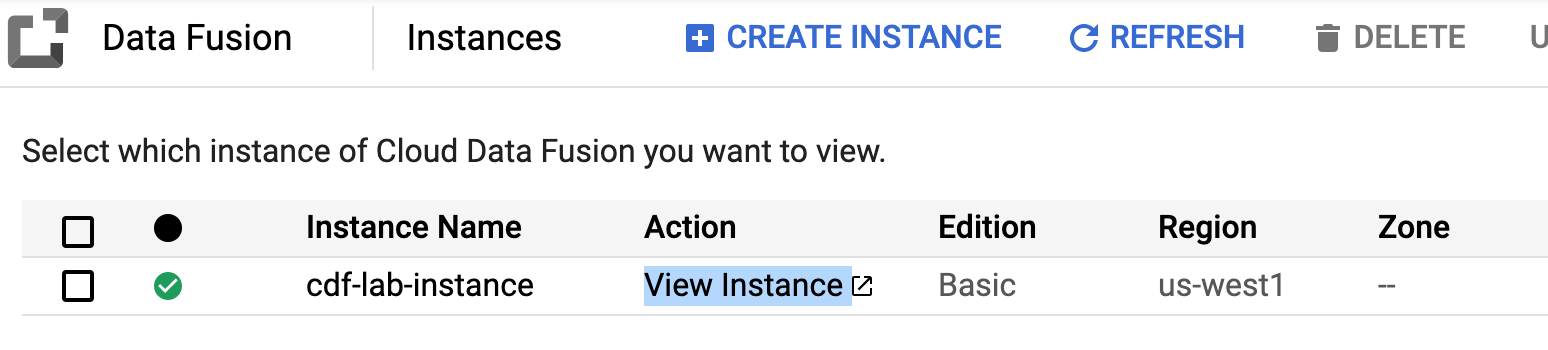
Dans la console Google Cloud, accédez au menu de navigation (), puis cliquez sur Afficher tous les produits. Sous Analytics, cliquez sur Data Fusion.
Cliquez sur le lien Afficher l'instance à côté de votre instance Data Fusion. Utilisez les identifiants qui vous ont été attribués pour cet atelier afin de vous connecter et, si nécessaire, cochez la case à côté de Gérer vos données Google Service Control. Cliquez sur Continuer.
Si vous êtes invité à découvrir le service, cliquez sur Annuler. L'UI de Cloud Data Fusion s'ouvre.
Notez que l'UI Web de Cloud Data Fusion est dotée de son propre panneau de navigation (à gauche) qui permet d'accéder à la page souhaitée.
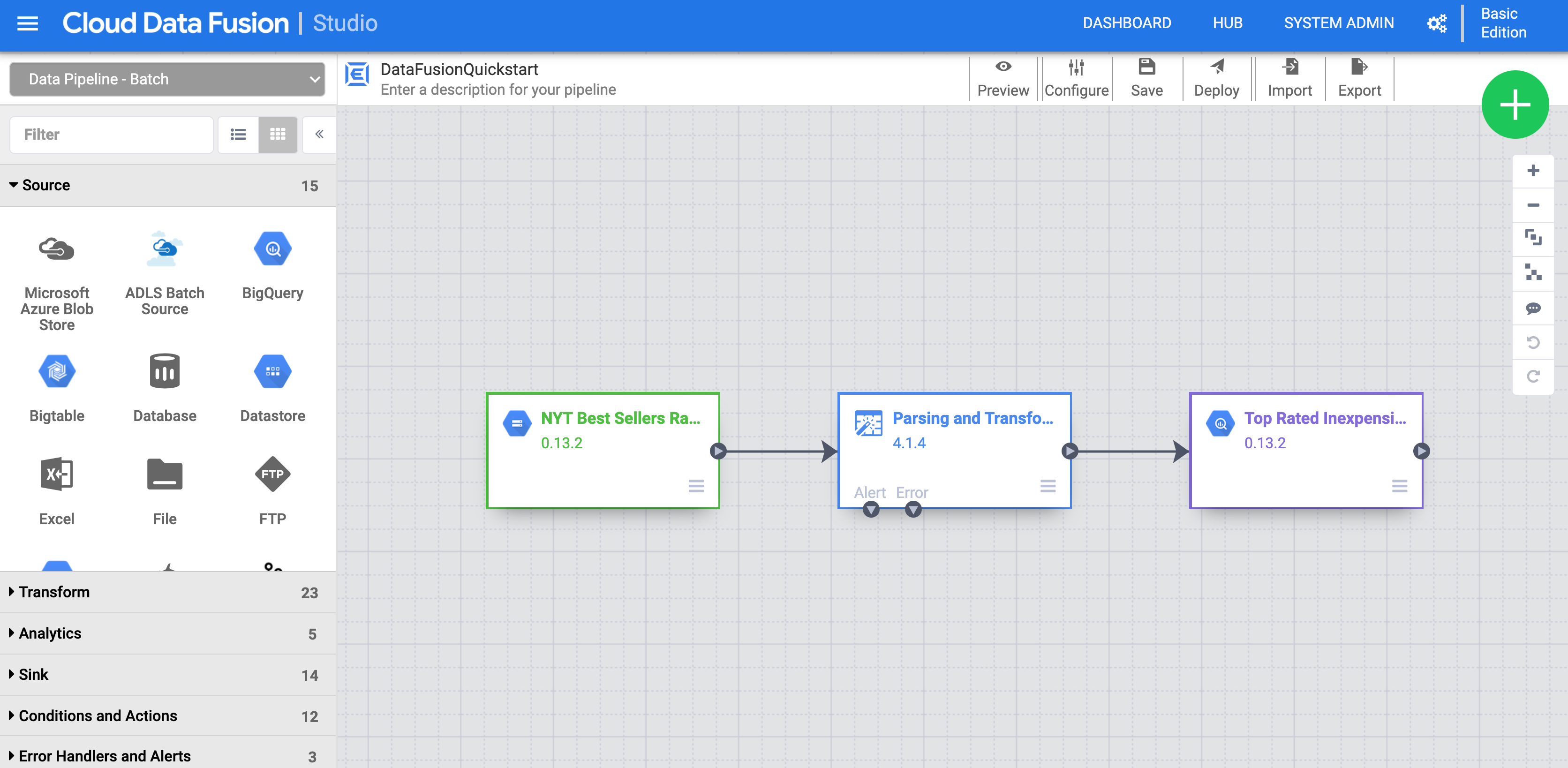
Tâche 4 : Déployer un exemple de pipeline
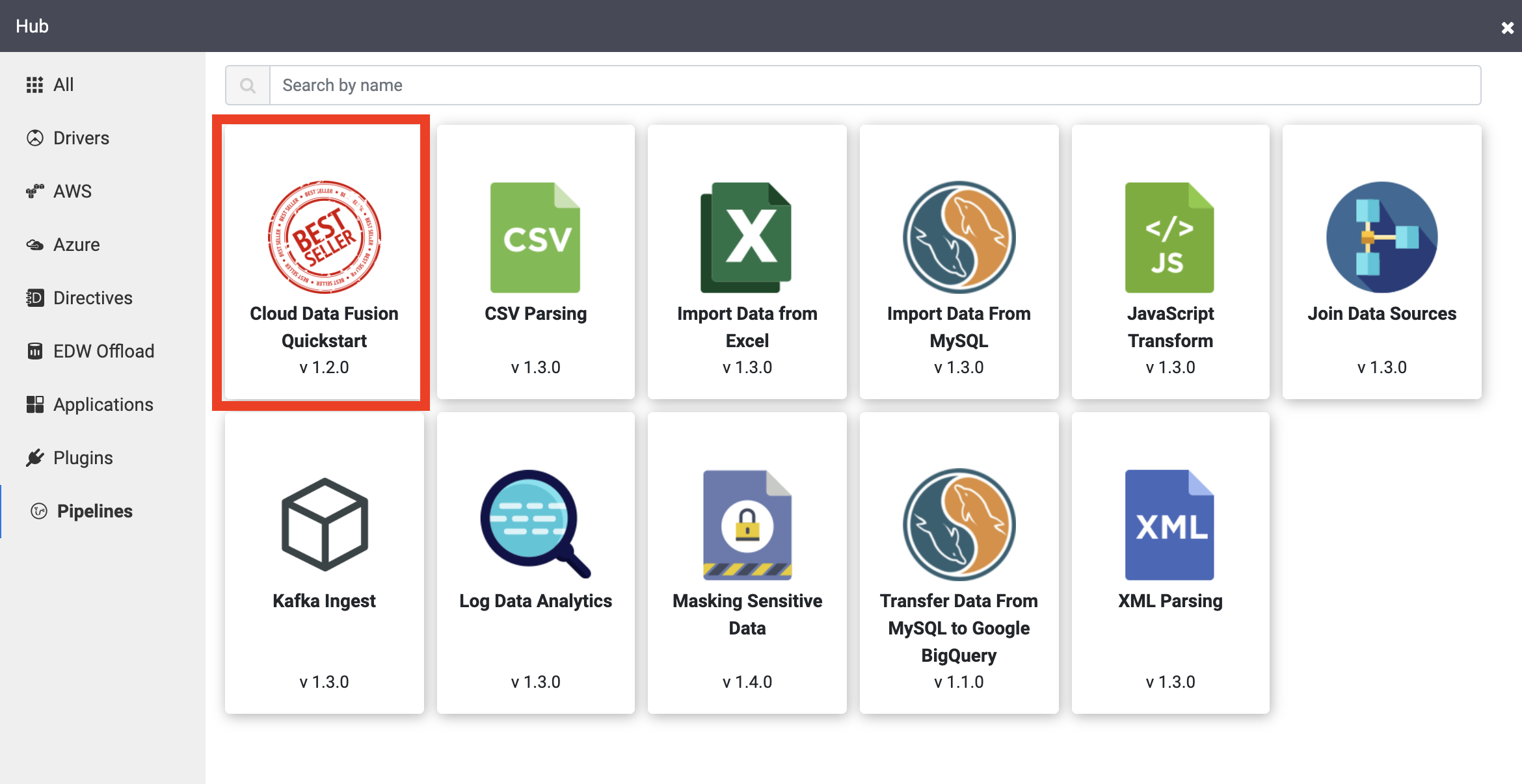
Des exemples de pipelines sont disponibles dans le hub Cloud Data Fusion, qui vous permet de partager des pipelines, des plug-ins et des solutions Cloud Data Fusion réutilisables.
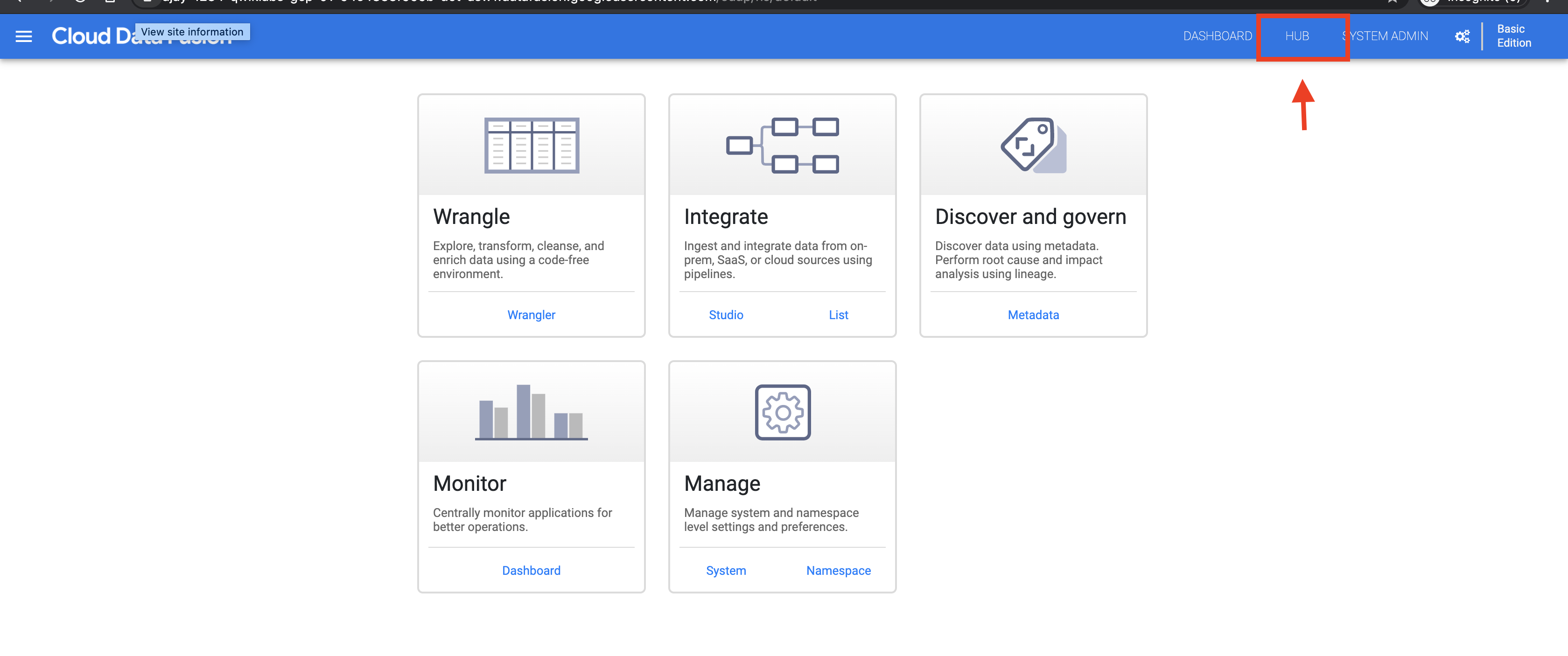
Dans l'UI Web de Cloud Data Fusion, cliquez sur HUB en haut à droite.
Dans le panneau de gauche, cliquez sur Pipelines.
Cliquez sur le pipeline Cloud Data Fusion Quickstart (Guide de démarrage rapide de Cloud Data Fusion), puis sur Create (Créer) dans le pop-up qui s'affiche.
Dans le panneau de configuration du pipeline "Cloud Data Fusion Quickstart" (Guide de démarrage rapide de Cloud Data Fusion), cliquez sur Finish (Terminer).
Cliquez sur Customize Pipeline (Personnaliser le pipeline). Une représentation visuelle de votre pipeline s'affiche dans Pipeline Studio. Il s'agit d'une interface graphique permettant de développer des pipelines d'intégration de données. Les plug-ins de pipeline disponibles sont listés sur la gauche, et votre pipeline est affiché dans la zone principale du canevas. Vous pouvez l'explorer en maintenant le pointeur sur chaque nœud de pipeline et en cliquant sur le bouton Properties (Propriétés) qui s'affiche. Le menu "Properties" (Propriétés) de chaque nœud vous permet d'afficher les objets et les opérations associés au nœud.
Remarque : Dans un pipeline, un nœud est un objet connecté en séquence pour produire un graphe orienté acyclique. Ex. : source, récepteur, transformation, action, etc.
Dans le menu situé en haut à droite, cliquez sur Deploy (Déployer). Le pipeline est alors envoyé à Cloud Data Fusion. Vous l'exécuterez dans la section suivante.
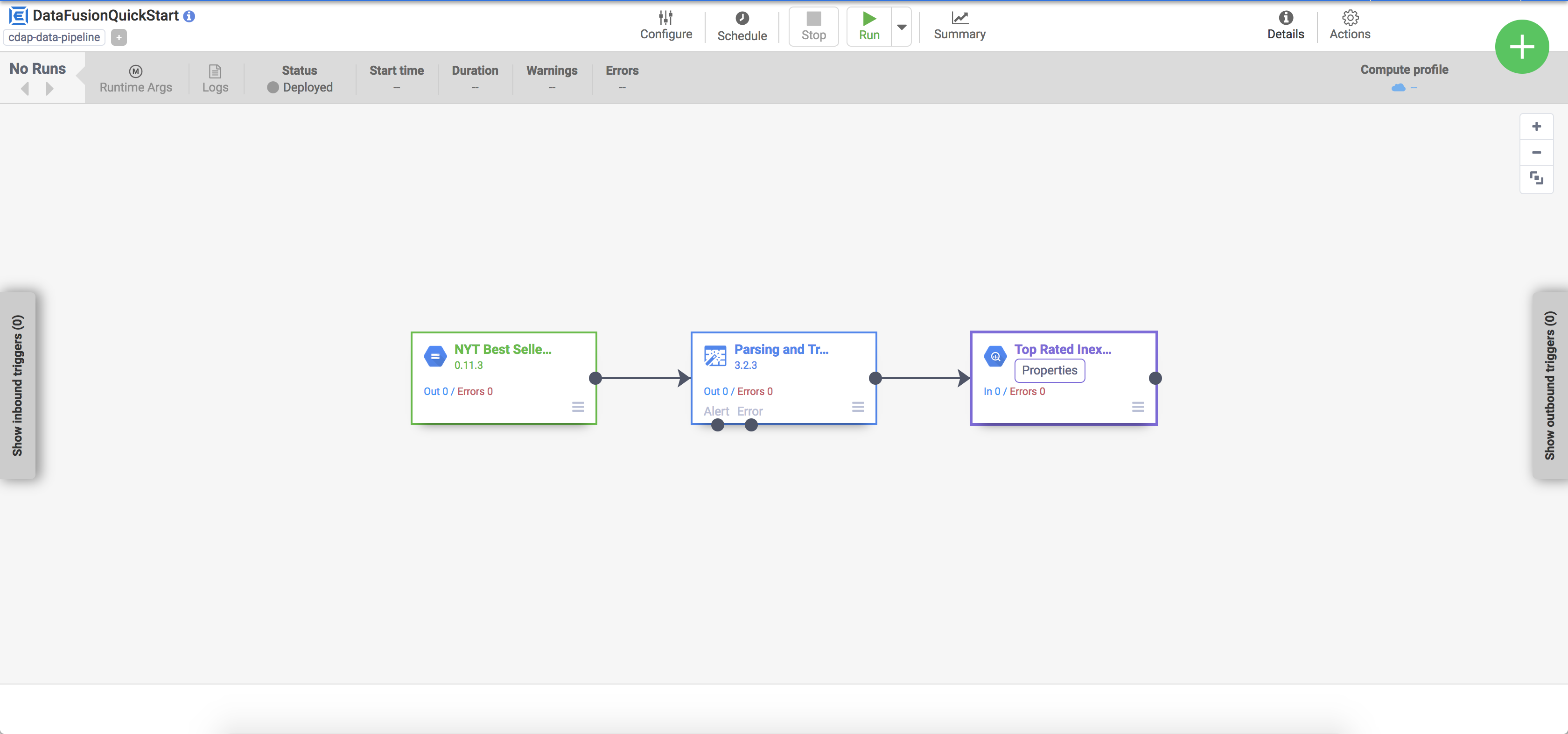
Tâche 5 : Afficher votre pipeline
Le pipeline déployé apparaît dans la vue détaillée du pipeline, où vous pouvez effectuer les opérations suivantes :
Afficher la structure et la configuration du pipeline
Exécuter le pipeline manuellement, ou configurer un calendrier ou un déclencheur
Afficher un résumé des exécutions historiques du pipeline, y compris les temps d'exécution, les journaux et les métriques
Tâche 6 : Exécuter votre pipeline
Dans la vue détaillée du pipeline, cliquez sur Run (Exécuter) en haut au centre pour exécuter le pipeline.
Remarque : Lors de l'exécution d'un pipeline, Cloud Data Fusion provisionne un cluster Managed Service for Spark éphémère, exécute le pipeline sur le cluster à l'aide d'Apache Hadoop MapReduce ou d'Apache Spark, puis supprime le cluster. Lorsque le pipeline passe à l'état "Running" (En cours d'exécution), vous pouvez surveiller la création et la suppression du cluster Managed Service for Spark. Ce cluster n'existe que pendant la durée du pipeline.
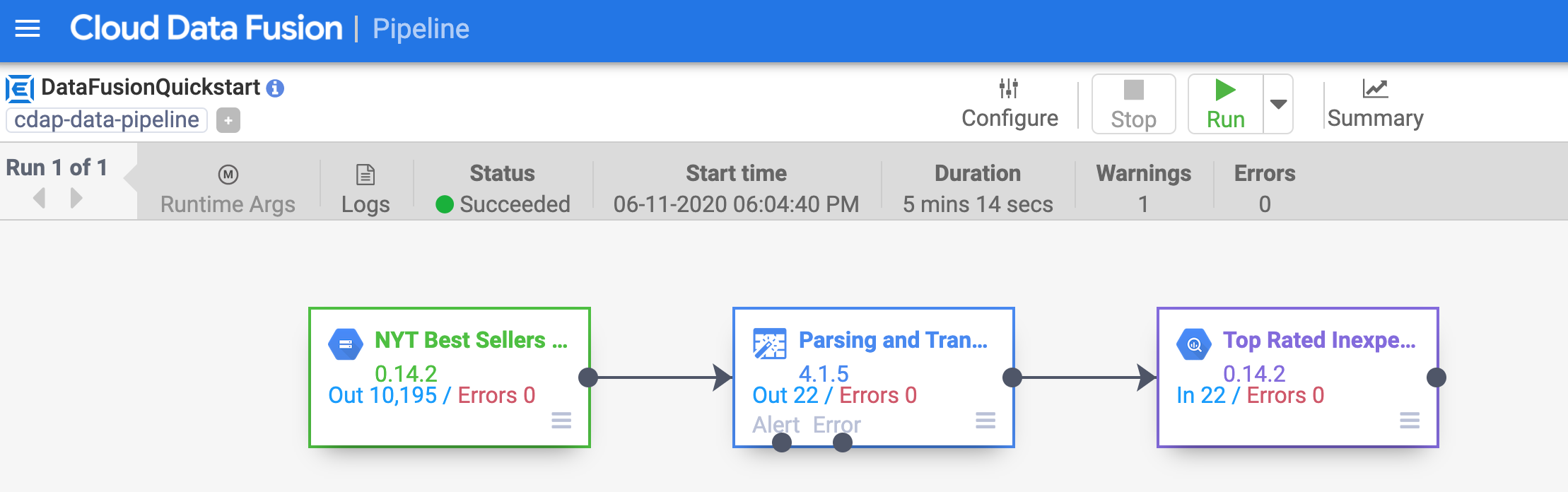
Remarque : Si l'état du pipeline est "Failed" (Échec), réexécutez-le.
Au bout de quelques minutes, le pipeline se termine. Le pipeline passe à l'état Succeeded (Succès) et le nombre d'enregistrements traités par chaque nœud s'affiche.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Déployer et exécuter un exemple de pipeline
Tâche 7 : Afficher les résultats
Le pipeline écrit la sortie dans une table BigQuery. Vous pouvez le vérifier en procédant comme suit.
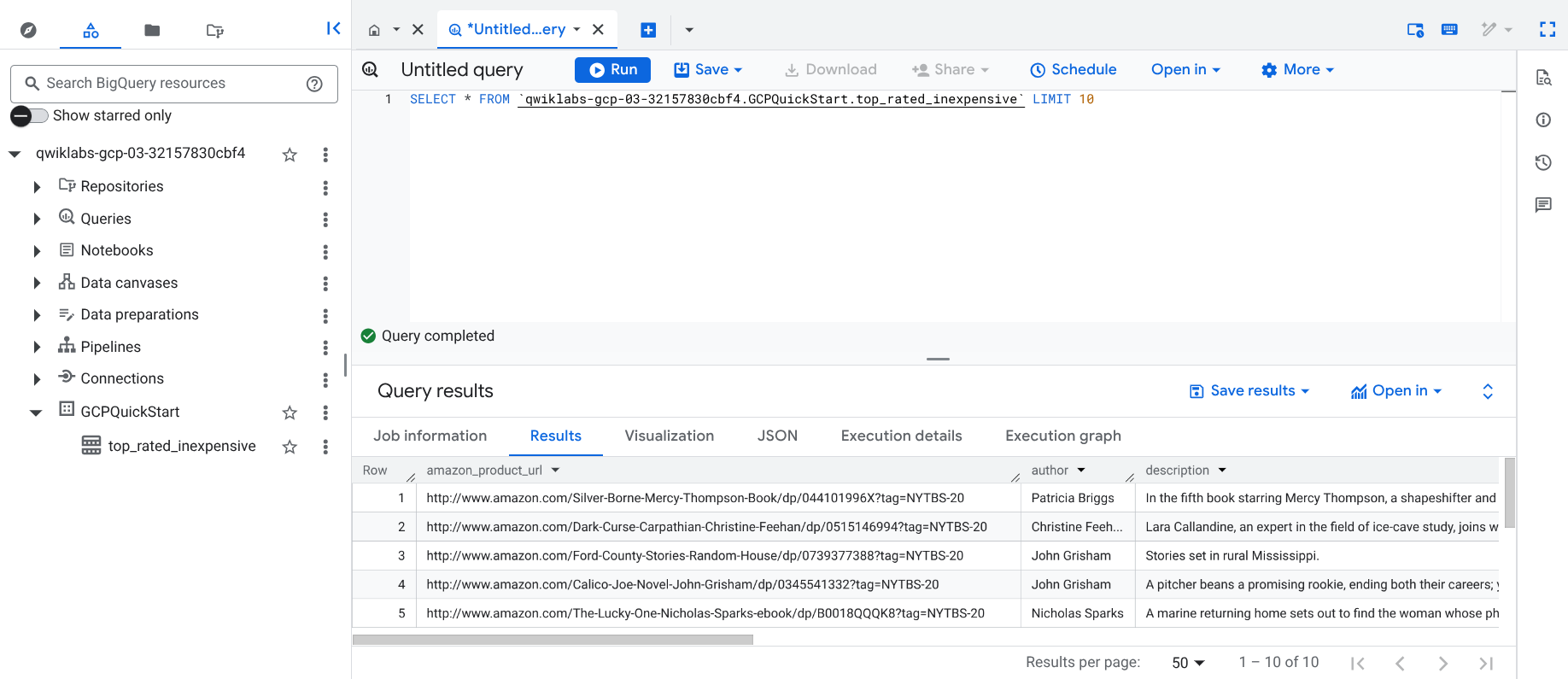
Cliquez sur ce lien pour ouvrir l'UI BigQuery dans la console Cloud. Vous pouvez également effectuer un clic droit sur l'onglet de la console et sélectionner Dupliquer, puis utiliser le menu de navigation () pour sélectionner BigQuery.
Dans le volet Explorateur classique, cliquez sur l'ID de votre projet (qui commence par qwiklabs).
Sous l'ensemble de données GCPQuickstart de votre projet, cliquez sur la table top_rated_inexpensive.
Cliquez sur + Requête SQL, collez la requête ci-dessous, puis cliquez sur Exécuter.
SELECT * FROM `{{{project_0.project_id | "PROJECT_ID"}}}.GCPQuickStart.top_rated_inexpensive` LIMIT 10
Attendez la fin de l'exécution de la requête. Une fenêtre de résultats similaire s'affiche.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Afficher les résultats
Félicitations !
Dans cet atelier, vous avez appris à créer une instance Data Fusion et à déployer un exemple de pipeline qui lit un fichier d'entrée depuis Cloud Storage, transforme et filtre les données pour générer un sous-ensemble de données dans BigQuery.
Terminer l'atelier
Une fois l'atelier terminé, cliquez sur Terminer l'atelier. Google Skills supprime les ressources que vous avez utilisées, puis efface le compte.
Si vous le souhaitez, vous pouvez noter l'atelier. Sélectionnez un nombre d'étoiles, saisissez un commentaire, puis cliquez sur Envoyer.
Voici à quoi correspond le nombre d'étoiles que vous pouvez attribuer à un atelier :
1 étoile = très insatisfait(e)
2 étoiles = insatisfait(e)
3 étoiles = ni insatisfait(e), ni satisfait(e)
4 étoiles = satisfait(e)
5 étoiles = très satisfait(e)
Si vous ne souhaitez pas donner votre avis, vous pouvez fermer la boîte de dialogue.
Pour soumettre des commentaires, suggestions ou corrections, veuillez accéder à l'onglet Assistance.
Dernière mise à jour du manuel : 17 décembre 2025
Dernier test de l'atelier : 17 décembre 2025
Copyright 2026 Google LLC Tous droits réservés. Google et le logo Google sont des marques de Google LLC. Tous les autres noms de société et de produit peuvent être des marques des sociétés auxquelles ils sont associés.
Avant de commencer
Les ateliers créent un projet Google Cloud et des ressources pour une durée déterminée.
Les ateliers doivent être effectués dans le délai imparti et ne peuvent pas être mis en pause. Si vous quittez l'atelier, vous devrez le recommencer depuis le début.
En haut à gauche de l'écran, cliquez sur Démarrer l'atelier pour commencer.
Utilisez la navigation privée
Copiez le nom d'utilisateur et le mot de passe fournis pour l'atelier
Cliquez sur Ouvrir la console en navigation privée
Connectez-vous à la console
Connectez-vous à l'aide des identifiants qui vous ont été attribués pour l'atelier. L'utilisation d'autres identifiants peut entraîner des erreurs ou des frais.
Acceptez les conditions d'utilisation et ignorez la page concernant les ressources de récupération des données.
Ne cliquez pas sur Terminer l'atelier, à moins que vous n'ayez terminé l'atelier ou que vous ne vouliez le recommencer, car cela effacera votre travail et supprimera le projet.
Ce contenu n'est pas disponible pour le moment
Nous vous préviendrons par e-mail lorsqu'il sera disponible
Parfait !
Nous vous contacterons par e-mail s'il devient disponible
Un atelier à la fois
Confirmez pour mettre fin à tous les ateliers existants et démarrer celui-ci
Utilisez la navigation privée pour effectuer l'atelier
Le meilleur moyen d'exécuter cet atelier consiste à utiliser une fenêtre de navigation privée. Vous éviterez ainsi les conflits entre votre compte personnel et le compte temporaire de participant, qui pourraient entraîner des frais supplémentaires facturés sur votre compte personnel.
Dans cet atelier, vous allez apprendre à créer une instance Data Fusion et à déployer un exemple de pipeline.
Durée :
1 min de configuration
·
Accessible pendant 90 min
·
Terminé après 90 min


 ).
).
 ), puis cliquez sur IAM et administration > IAM.
), puis cliquez sur IAM et administration > IAM.