Add Cloud Data Fusion API Service Agent role to service account
Revisar mi progreso
/ 25
Deploy a sample pipeline
Revisar mi progreso
/ 25
View the result
Revisar mi progreso
/ 25
Create a cloud data fusion instance
Revisar mi progreso
/ 25
Add Cloud Data Fusion API Service Agent role to service account
Revisar mi progreso
/ 25
Deploy a sample pipeline
Revisar mi progreso
/ 25
View the result
Revisar mi progreso
/ 25
Es posible que este lab incorpore herramientas de IA para facilitar tu aprendizaje.
Descripción general
En este lab, aprenderás a crear una instancia de Data Fusion y a implementar una canalización de muestra que se proporciona.
La canalización lee un archivo JSON que contiene los datos de los productos más vendidos de NYT de Cloud Storage. Luego, la canalización ejecuta transformaciones en el archivo para analizar y limpiar los datos. Por último, carga un subconjunto de los registros en BigQuery.
Objetivos
En este lab, aprenderás a hacer lo siguiente:
Crear una instancia de Data Fusion
Implementar una canalización de ejemplo que ejecute algunas transformaciones en un archivo JSON y filtre los resultados coincidentes en BigQuery
Configuración
En cada lab, recibirás un proyecto de Google Cloud y un conjunto de recursos nuevos por tiempo limitado y sin costo adicional.
Accede a Google Skills en una ventana de incógnito.
Ten en cuenta el tiempo de acceso del lab (por ejemplo, 1:15:00) y asegúrate de finalizarlo en el plazo asignado.
No existe una función de pausa. Si lo necesitas, puedes reiniciar el lab, pero deberás hacerlo desde el comienzo.
Cuando esté listo, haga clic en Comenzar lab.
Anote las credenciales del lab (el nombre de usuario y la contraseña). Las usarás para acceder a la consola de Google Cloud.
Haga clic en Abrir Google Console.
Haga clic en Usar otra cuenta, copie las credenciales para este lab y péguelas en el mensaje emergente que aparece.
Si usas otras credenciales, se generarán errores o incurrirás en cargos.
Acepta las condiciones y omite la página de recursos de recuperación.
Cómo iniciar tu lab y acceder a la consola de Google Cloud
Haz clic en el botón Comenzar lab. Si debes pagar por el lab, se abrirá un diálogo para que selecciones la forma de pago.
A la izquierda, se encuentra el panel Detalles del lab, que tiene estos elementos:
El botón para abrir la consola de Google Cloud
El tiempo restante
Las credenciales temporales que debes usar para el lab
Otra información para completar el lab, si es necesaria
Haz clic en Abrir la consola de Google Cloud (o haz clic con el botón derecho y selecciona Abrir el vínculo en una ventana de incógnito si ejecutas el navegador Chrome).
El lab inicia recursos y abre otra pestaña en la que se muestra la página de acceso.
Sugerencia: Ordena las pestañas en ventanas separadas, una junto a la otra.
Nota: Si ves el diálogo Elegir una cuenta, haz clic en Usar otra cuenta.
De ser necesario, copia el nombre de usuario a continuación y pégalo en el diálogo Acceder.
{{{user_0.username | "Username"}}}
También puedes encontrar el nombre de usuario en el panel Detalles del lab.
Haz clic en Siguiente.
Copia la contraseña que aparece a continuación y pégala en el diálogo Te damos la bienvenida.
{{{user_0.password | "Password"}}}
También puedes encontrar la contraseña en el panel Detalles del lab.
Haz clic en Siguiente.
Importante: Debes usar las credenciales que te proporciona el lab. No uses las credenciales de tu cuenta de Google Cloud.
Nota: Usar tu propia cuenta de Google Cloud para este lab podría generar cargos adicionales.
Haz clic para avanzar por las páginas siguientes:
Acepta los Términos y Condiciones.
No agregues opciones de recuperación o autenticación de dos factores (esta es una cuenta temporal).
No te registres para obtener pruebas gratuitas.
Después de un momento, se abrirá la consola de Google Cloud en esta pestaña.
Nota: Para acceder a los productos y servicios de Google Cloud, haz clic en el menú de navegación o escribe el nombre del servicio o producto en el campo Buscar.
Active Cloud Shell
Cloud Shell es una máquina virtual que contiene herramientas de desarrollo y un directorio principal persistente de 5 GB. Se ejecuta en Google Cloud. Cloud Shell proporciona acceso de línea de comandos a sus recursos de Google Cloud. gcloud es la herramienta de línea de comandos de Google Cloud, la cual está preinstalada en Cloud Shell y es compatible con la función de autocompletado con tabulador.
En el panel de navegación de Google Cloud Console, haga clic en Activar Cloud Shell ().
Haga clic en Continuar.
El aprovisionamiento y la conexión al entorno tardan solo unos momentos. Una vez que se conecte, también estará autenticado, y el proyecto estará configurado con su PROJECT_ID. Por ejemplo:
Comandos de muestra
Si desea ver el nombre de cuenta activa, use este comando:
Si desea ver el ID del proyecto, use este comando:
gcloud config list project
(Resultado)
[core]
project = <project_ID>
(Resultado de ejemplo)
[core]
project = qwiklabs-gcp-44776a13dea667a6
Verifica los permisos del proyecto
Antes de comenzar a trabajar en Google Cloud, asegúrate de que tu proyecto tenga los permisos correctos en Identity and Access Management (IAM).
En el Menú de navegación () de la consola de Google Cloud, haga clic en IAM y administración > IAM.
Confirma que aparezca la cuenta de servicio predeterminada de Compute {project-number}-compute@developer.gserviceaccount.com, y que tenga asignado el rol Editor. El prefijo de la cuenta es el número del proyecto, que puedes encontrar en el menú de navegación > Descripción general de Cloud.
Si no aparece la cuenta en IAM o no tiene asignado el rol Editor, sigue los pasos que se indican a continuación para asignar el rol necesario.
En la consola de Google Cloud, en el menú de navegación, haz clic en Descripción general de Cloud.
En la tarjeta Información del proyecto, copia el Número de proyecto.
En el menú de navegación, haz clic en IAM y administración > IAM.
En la parte superior de la página IAM, haga clic en Agregar.
Reemplaza {project-number} por el número de tu proyecto.
En Seleccionar un rol, elige Básico (o Proyecto) > Editor.
Haz clic en Guardar.
Tarea 1: Habilita la API de Cloud Data Fusion
En el menú de navegación () de la consola de Cloud, haz clic en APIs y servicios > Biblioteca.
En el cuadro de búsqueda, escribe Data fusion para buscar la API de Cloud Data Fusion y haz clic en el hipervínculo.
Si la API ya está habilitada, haz clic en Administrar y, luego, en Inhabilitar API. Confirma la inhabilitación.
Después de que se inhabilite la API, haz clic en Habilitar para volver a habilitarla.
Tarea 2: Crea una instancia de Cloud Data Fusion
En el menú de navegación () de la consola de Google Cloud, haz clic en Ver todos los productos. En Analytics, haz clic en Data Fusion.
Haz clic en el vínculo Crear una instancia en la parte superior de la sección para crear una instancia de Cloud Data Fusion.
En la página Crear instancia de Data Fusion que se carga, haz lo siguiente:
a. Ingresa un nombre para tu instancia (como cdf-lab-instance).
b. En Región, selecciona us-central1.
c. En Edición, selecciona Basic.
d. En la sección Autorización, haz clic en Otorgar permiso si se te solicita.
e. Haz clic en el ícono desplegable junto a Opciones avanzadas, en Supervisión y registro avanzados, marca la casilla de verificación de Managed Service for Spark Cloud Logging.
f. Deja todos los otros campos como están y, luego, haz clic en Crear.
Haz clic en Revisar mi progreso para verificar el objetivo.
Crea una instancia de Cloud Data Fusion
Nota: La instancia tardará alrededor de 10 minutos en crearse. Mientras esperas, mira esta presentación sobre Cloud Data Fusion de Next '19 a partir de la marca de tiempo 15:31. Vuelve y revisa tu instancia de vez en cuando. Podrás terminar de mirar el video después de completar el lab.
Nota: Recuerda que este lab tiene un límite de tiempo y perderás tu trabajo cuando el tiempo se acabe.
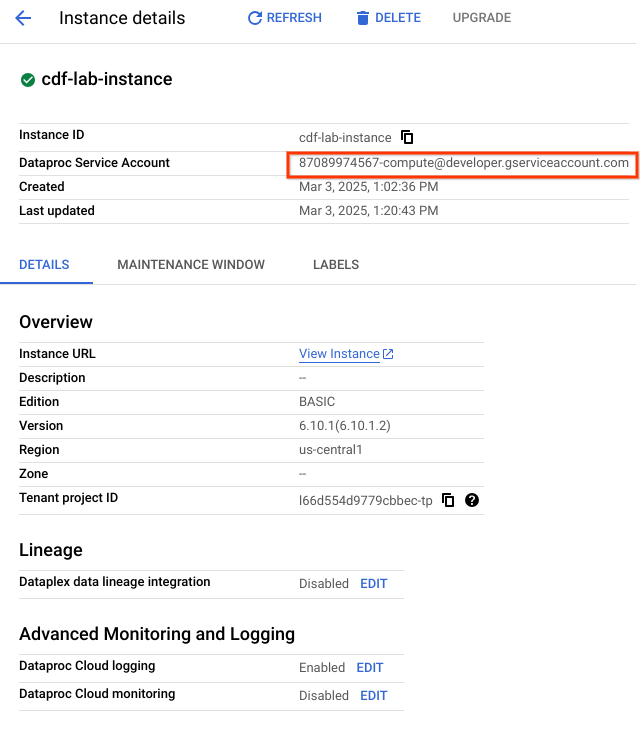
Luego, otorgarás permisos a la cuenta de servicio asociada con la instancia siguiendo estos pasos:
Haz clic en el nombre de la instancia. En la página Detalles de la instancia, copia la Cuenta de servicio de Managed Service for Spark en el portapapeles.
En el menú de navegación () de la consola de Google Cloud, selecciona IAM y administración > IAM.
En la página Permisos de IAM, haz clic en + Otorgar acceso.
En el campo Entidades nuevas, pega la Cuenta de servicio de Managed Service for Spark.
Haz clic en el campo Selecciona un rol, escribe Agente de servicio de la API de Cloud Data Fusion y selecciónalo.
Haz clic en Guardar.
Haz clic en Revisar mi progreso para verificar el objetivo.
Agregar el rol Agente de servicio de la API de Cloud Data Fusion a la cuenta de servicio
Tarea 3: Navega por la IU de Cloud Data Fusion
Cuando usas Cloud Data Fusion, usas la IU de la consola de Cloud y la de Cloud Data Fusion, que está separada.
En la consola de Cloud, puedes crear y borrar instancias de Cloud Data Fusion y ver los detalles de las instancias de Cloud Data Fusion.
En la IU web de Cloud Data Fusion, puedes usar las diversas páginas, como Pipeline Studio o Wrangler, para usar las funciones de Cloud Data Fusion.
Para navegar por la IU de Cloud Data Fusion, sigue estos pasos:
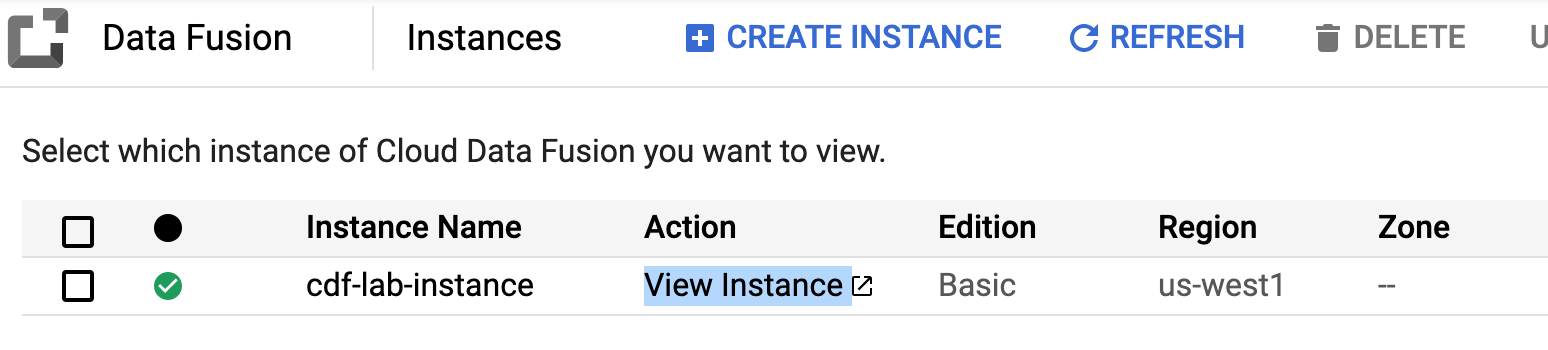
En el menú de navegación () de la consola de Google Cloud, haz clic en Ver todos los productos. En Analytics, haz clic en Data Fusion.
Haz clic en el vínculo Ver instancia junto a tu instancia de Data Fusion. Selecciona tus credenciales del lab para acceder y, si es necesario, marca la casilla de verificación Permite administrar los datos de control de servicio de Google. Haz clic en Continuar.
Si se te solicita hacer una visita guiada por el servicio, haz clic en Cancelar. Ahora deberías estar en la IU de Cloud Data Fusion.
Ten en cuenta que la IU web de Cloud Data Fusion cuenta con su propio panel de navegación (en el lado izquierdo) para que vayas a la página que necesites.
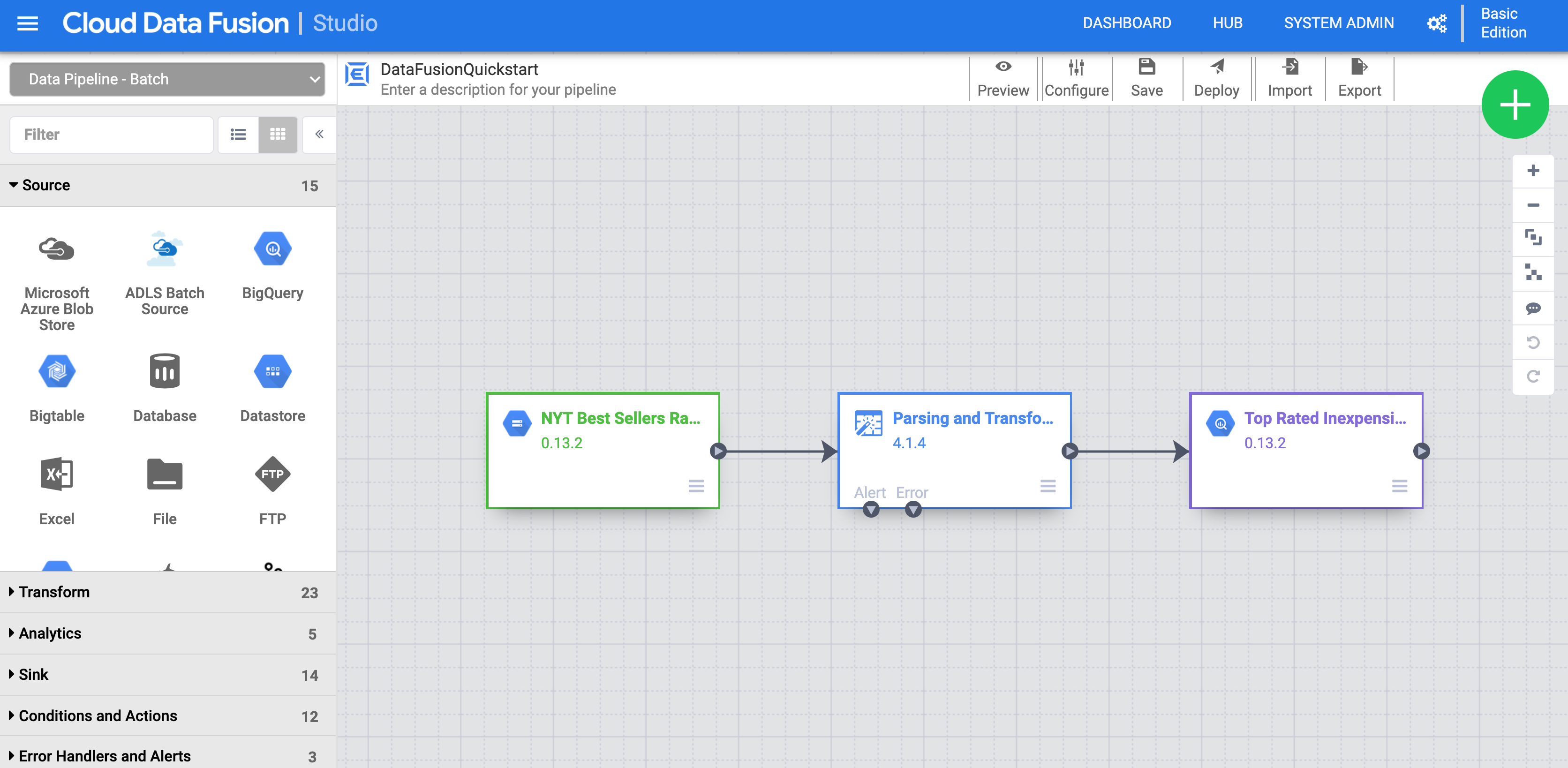
Tarea 4: Implementa una canalización de muestra
Las canalizaciones de muestra están disponibles a través del Hub de Cloud Data Fusion, que te permite compartir canalizaciones, complementos y soluciones reutilizables de Cloud Data Fusion.
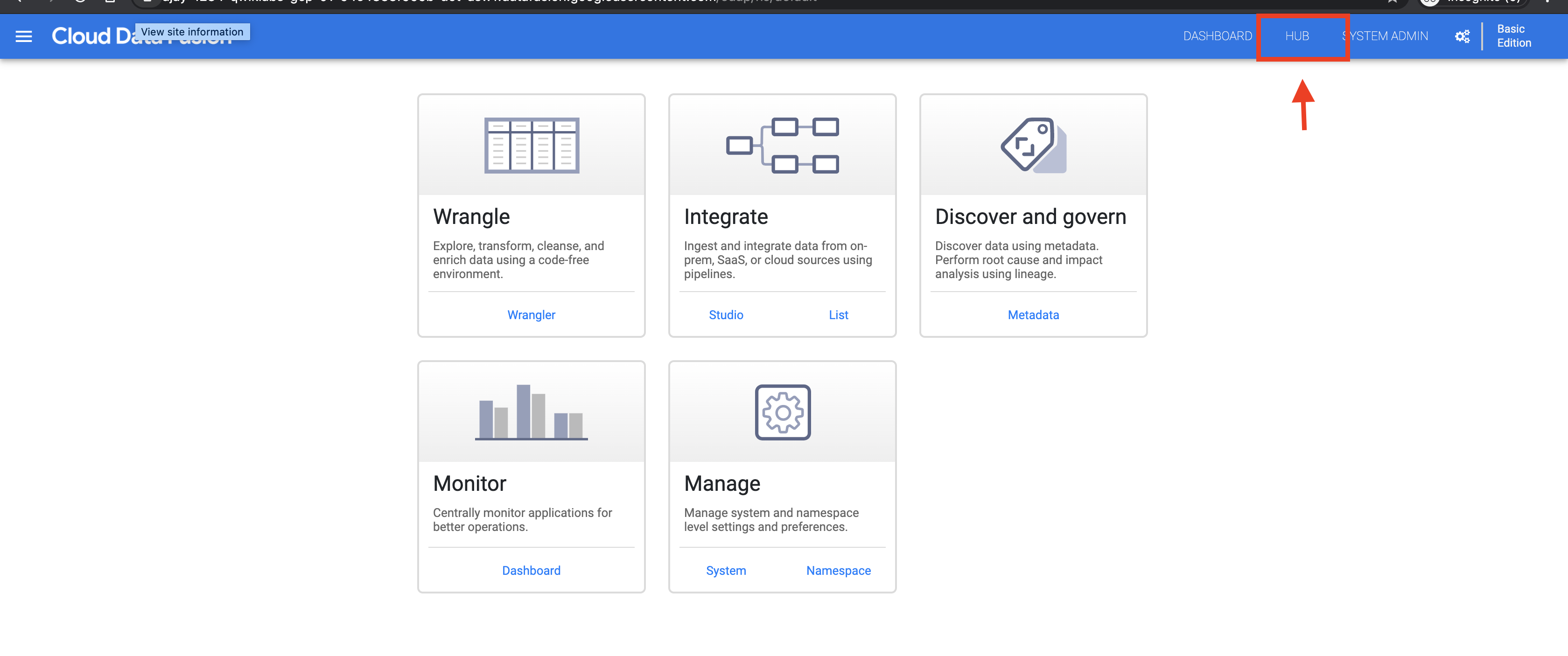
En la IU web de Cloud Data Fusion, haz clic en HUB en la parte superior derecha.
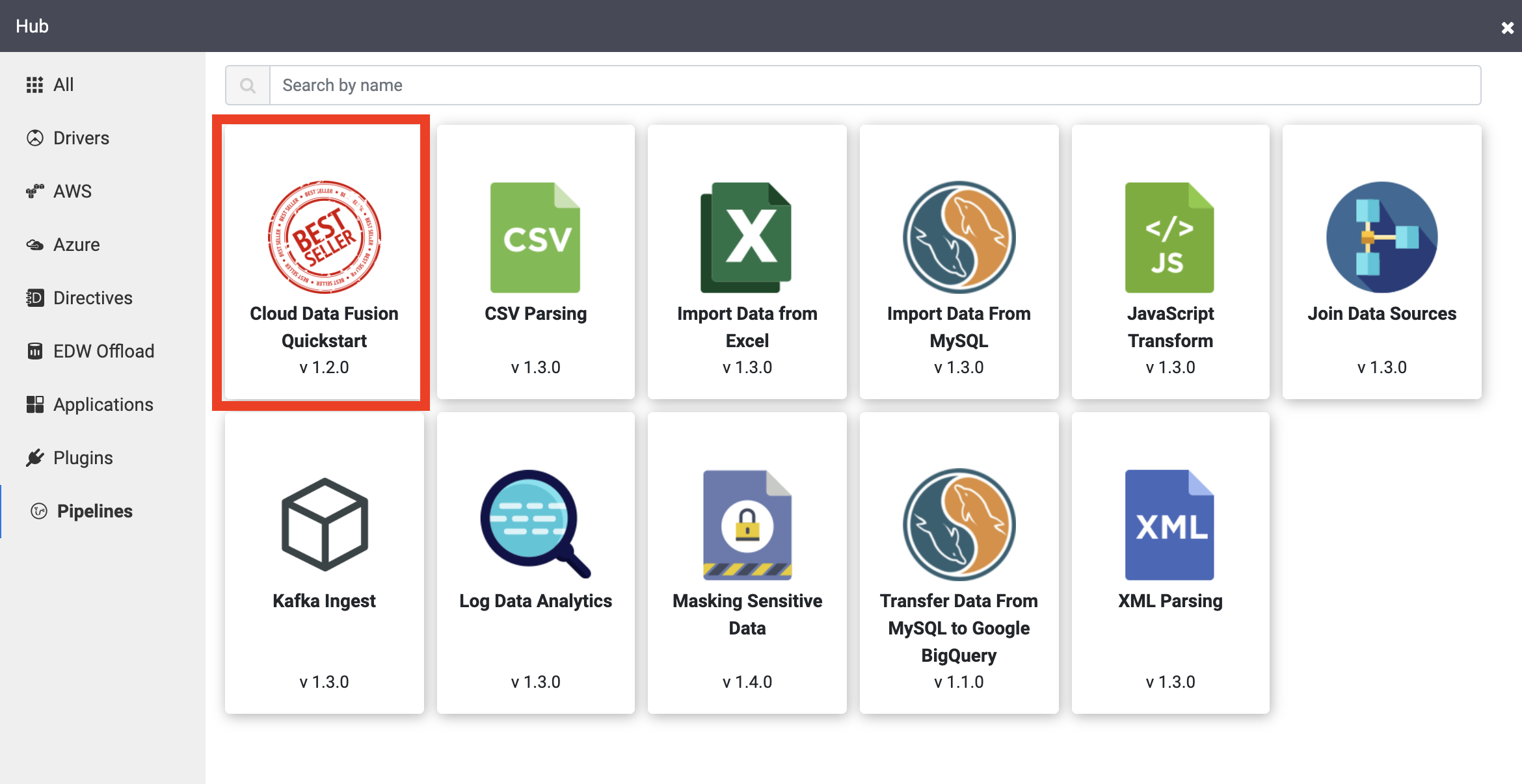
En el panel izquierdo, haz clic en Canalizaciones.
Haz clic en la canalización de la Guía de inicio rápido de Cloud Data Fusion y, luego, en Crear en la ventana emergente que aparece.
En el panel de configuración de inicio rápido de Cloud Data Fusion, haz clic en Finalizar.
Haz clic en Personalizar canalización. Una representación visual de tu canalización aparece en Pipeline Studio, una interfaz gráfica para desarrollar canalizaciones de integración de datos. Los complementos de canalización disponibles se muestran a la izquierda y tu canalización se muestra en el área de lienzo principal. Para explorar tu canalización, mantén el puntero sobre cada nodo de la canalización y haz clic en el botón Propiedades que aparecerá. El menú de propiedades para cada nodo te permite ver los objetos y las operaciones asociadas con el nodo.
Nota:
Un nodo en una canalización es un objeto que está conectado en una secuencia para producir un grafo acíclico dirigido. Ejemplos: Fuente, Receptor, Transformación, Acción, etcétera.
En la parte superior derecha del menú, haz clic en Implementar para enviar la canalización a Cloud Data Fusion. Debes ejecutar la canalización en la siguiente sección.
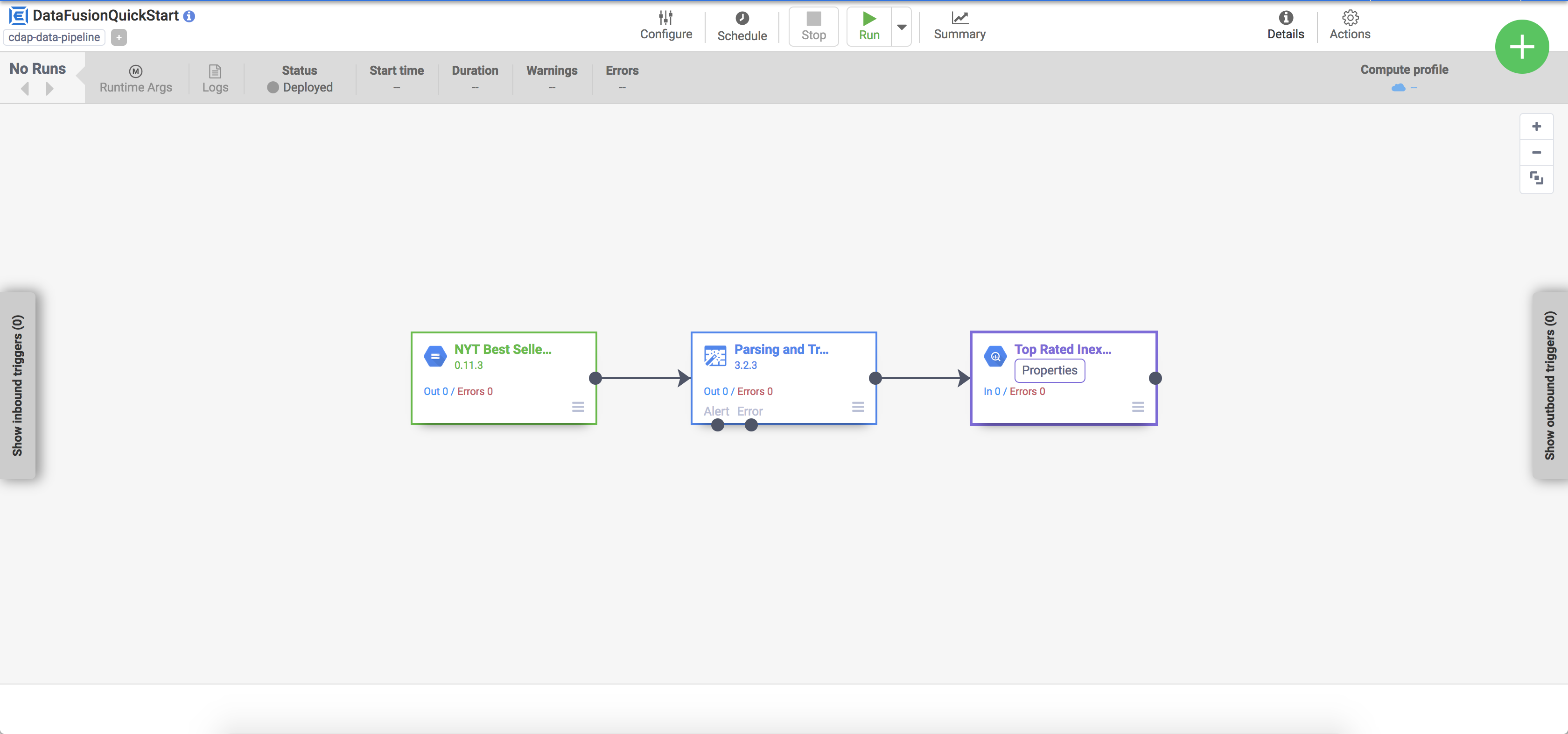
Tarea 5: Visualiza tu canalización
La canalización implementada aparecerá en la vista de detalles de la canalización, donde puedes hacer lo siguiente:
Ver la estructura y configuración de la canalización
Ejecutar la canalización de forma manual o configurar un programa o un activador
Ver un resumen de las ejecuciones históricas de la canalización, incluidos los registros, las métricas y los tiempos de ejecución
Tarea 6: Ejecuta tu canalización
En la vista de detalles de la canalización, haz clic en Ejecutar en la parte superior central para ejecutar tu canalización.
Nota: Cuando ejecutas una canalización, Cloud Data Fusion aprovisiona un clúster de Managed Service for Spark efímero, ejecuta la canalización en el clúster mediante Apache Hadoop MapReduce o Apache Spark y, luego, elimina el clúster. Cuando la canalización pasa al estado En ejecución, puedes supervisar la creación y la eliminación del clúster de Managed Service for Spark. Este clúster solo existe durante el lapso de la canalización.
Nota: Si el estado de la canalización falla, vuelve a ejecutarla.
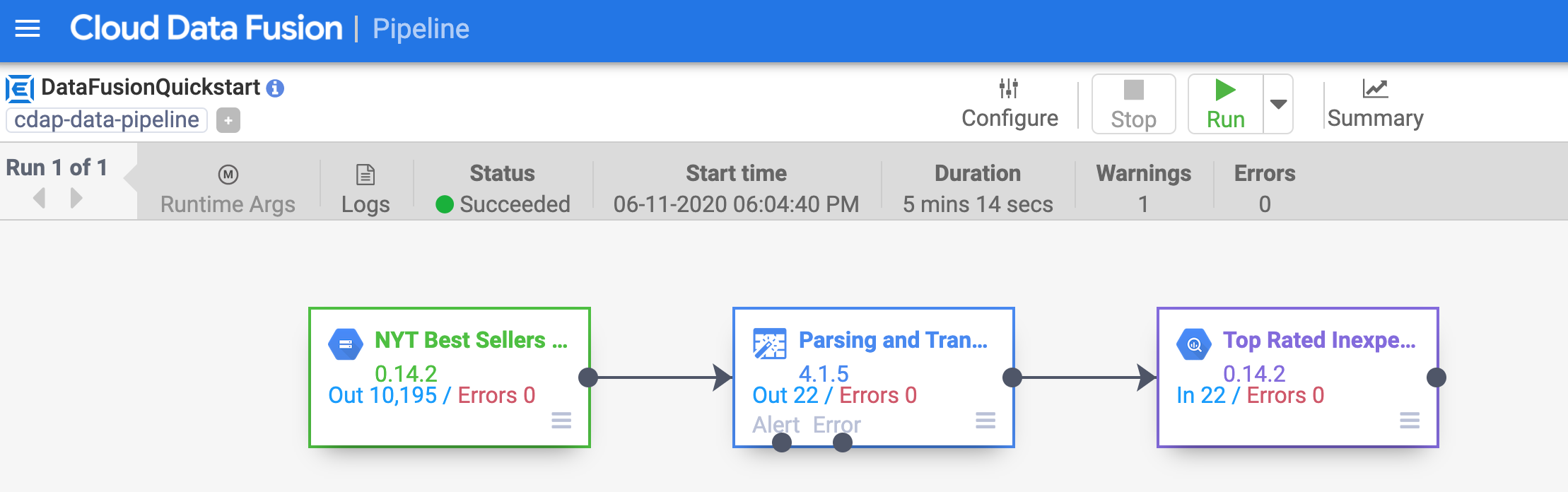
Después de unos minutos, la canalización finaliza. El estado de la canalización cambia a Correcto y se muestra la cantidad de registros que procesa cada nodo.
Haz clic en Revisar mi progreso para verificar el objetivo.
Implementar y ejecutar una canalización de muestra
Tarea 7: Consulta los resultados
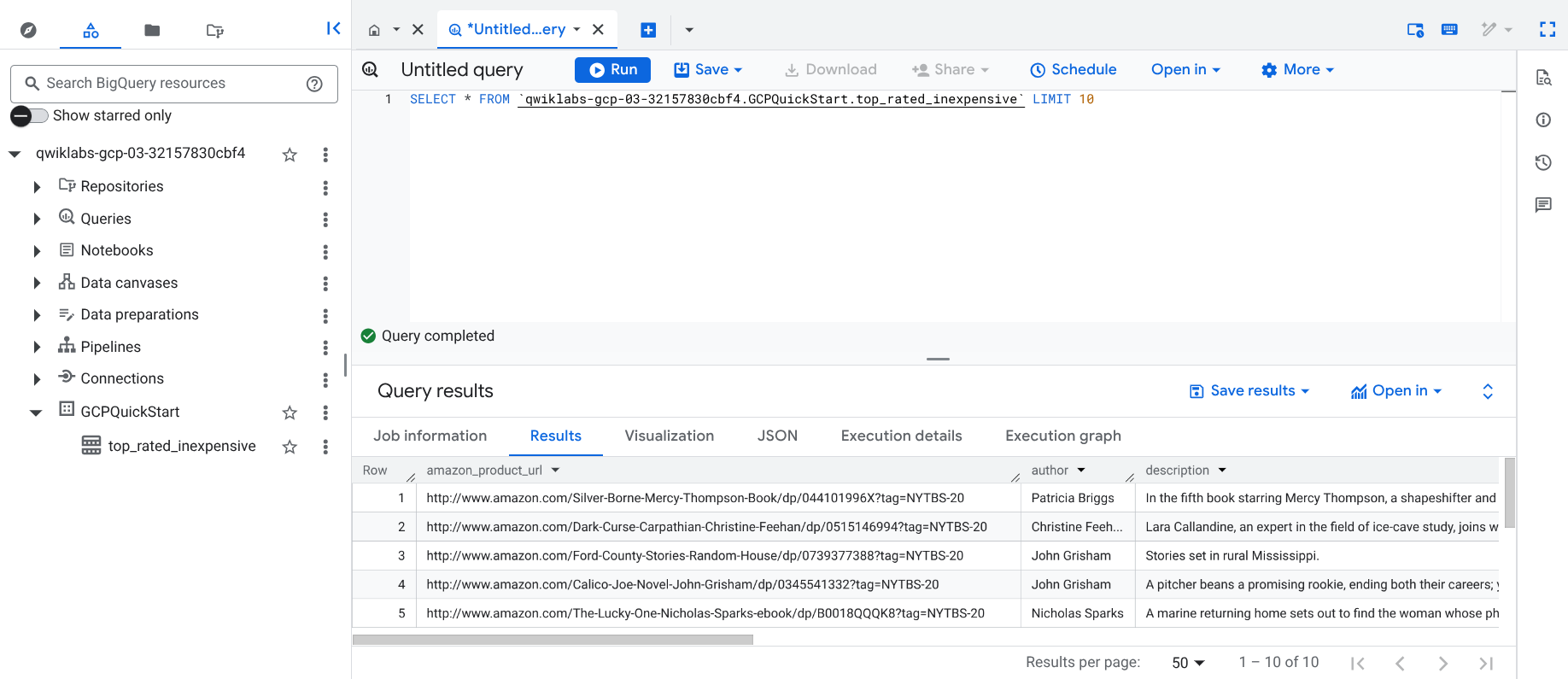
La canalización escribe el resultado en una tabla de BigQuery. Puedes verificarlo con los siguientes pasos.
Haz clic para abrir este vínculo a la IU de BigQuery en la consola de Cloud o haz clic con el botón derecho en la pestaña de la consola y selecciona Duplicar y, luego, usa el menú de navegación () para seleccionar BigQuery.
En el panel Explorador clásico, haz clic en el ID del proyecto (comenzará con qwiklabs).
En el conjunto de datos GCPQuickstart de tu proyecto, haz clic en la tabla top_rated_inexpensive.
Haz clic en + Consulta en SQL, pega la consulta que aparece a continuación y, luego, haz clic en Ejecutar.
SELECT * FROM `{{{project_0.project_id | "PROJECT_ID"}}}.GCPQuickStart.top_rated_inexpensive` LIMIT 10
Espera a que finalice la consulta. Aparecerá una Resultados similar.
Haz clic en Revisar mi progreso para verificar el objetivo.
Consultar el resultado
¡Felicitaciones!
En este lab, aprendiste a crear una instancia de Data Fusion y a implementar una canalización de ejemplo que lee un archivo de entrada de Cloud Storage, transforma y filtra los datos para exportar un subconjunto de los datos a BigQuery.
Finaliza el lab
Cuando hayas completado el lab, haz clic en Finalizar lab. Google Skills quitará los recursos que usaste y limpiará la cuenta.
Tendrás la oportunidad de calificar tu experiencia en el lab. Selecciona la cantidad de estrellas que corresponda, ingresa un comentario y haz clic en Enviar.
La cantidad de estrellas indica lo siguiente:
1 estrella = Muy insatisfecho
2 estrellas = Insatisfecho
3 estrellas = Ni satisfecho ni insatisfecho
4 estrellas = Satisfecho
5 estrellas = Muy satisfecho
Puedes cerrar el cuadro de diálogo si no deseas proporcionar comentarios.
Para enviar comentarios, sugerencias o correcciones, usa la pestaña Asistencia.
Última actualización del manual: 17 de diciembre de 2025
Prueba más reciente del lab: 17 de diciembre de 2025
Copyright 2026 Google LLC. Todos los derechos reservados. Google y el logotipo de Google son marcas de Google LLC. El resto de los nombres de productos y empresas pueden ser marcas de las respectivas empresas a las que están asociados.
Antes de comenzar
Los labs crean un proyecto de Google Cloud y recursos por un tiempo determinado
.
Los labs tienen un límite de tiempo y no tienen la función de pausa. Si finalizas el lab, deberás reiniciarlo desde el principio.
En la parte superior izquierda de la pantalla, haz clic en Comenzar lab para empezar
Usa la navegación privada
Copia el nombre de usuario y la contraseña proporcionados para el lab
Haz clic en Abrir la consola en modo privado
Accede a la consola
Accede con tus credenciales del lab. Si usas otras credenciales, se generarán errores o se incurrirá en cargos.
Acepta las condiciones y omite la página de recursos de recuperación
No hagas clic en Finalizar lab, a menos que lo hayas terminado o quieras reiniciarlo, ya que se borrará tu trabajo y se quitará el proyecto
Este contenido no está disponible en este momento
Te enviaremos una notificación por correo electrónico cuando esté disponible
¡Genial!
Nos comunicaremos contigo por correo electrónico si está disponible
Un lab a la vez
Confirma para finalizar todos los labs existentes y comenzar este
Usa la navegación privada para ejecutar el lab
Usar una ventana de incógnito o de navegación privada es la mejor forma de ejecutar
este lab. Así evitarás cualquier conflicto entre tu cuenta personal
y la cuenta de estudiante, lo que podría generar cargos adicionales en
tu cuenta personal.
En este lab, aprenderás a crear una instancia de Data Fusion y a implementar una canalización de ejemplo.
Duración:
1 min de configuración
·
Acceso por 90 min
·
90 min para completar


 ).
).
 ) de la consola de Google Cloud, haga clic en IAM y administración > IAM.
) de la consola de Google Cloud, haga clic en IAM y administración > IAM.