
始める前に
- ラボでは、Google Cloud プロジェクトとリソースを一定の時間利用します
- ラボには時間制限があり、一時停止機能はありません。ラボを終了した場合は、最初からやり直す必要があります。
- 画面左上の [ラボを開始] をクリックして開始します
Create and schedule a scan configuration
/ 20
Modify the existing inspection template and create a de-identify template for structured data.
/ 20
Create and run an inspection job
/ 30
Create and run a de-identify job
/ 30
Create and schedule a scan configuration
/ 20
Modify the existing inspection template and create a de-identify template for structured data.
/ 20
Create and run an inspection job
/ 30
Create and run a de-identify job
/ 30

Sensitive Data Protection は、機密情報を検出、分類、保護できるようにするためのフルマネージド サービスです。主なオプションには、機密データを継続的にプロファイリングする機密データの検出、秘匿化を含む機密データの匿名化、カスタム ワークロードやアプリケーションに検出、検査、匿名化を組み込むことができる Cloud Data Loss Prevention(DLP)API などがあります。
たとえば、機密データを含む元データが Cloud Storage に保存されており、そのファイルをエンドユーザーが分析や ML モデルのトレーニングに使用する前に、機密データを特定し、保護、秘匿化する必要があるとします。Sensitive Data Protection はこのような場合に役立ちます。
このラボでは、まず Cloud Storage 内の機密データを継続的にモニタリングするための検出を有効にします。次に、検出結果に基づいて、Cloud Storage ファイルの検査と匿名化(秘匿化)に使用できる、再利用可能なカスタム テンプレートを作成および変更します。最後に、これらのテンプレートを使用してジョブを実行し、Cloud Storage ファイル内の特定の種類の機密データをより詳細に検査して匿名化します。
このラボでは、次の方法について学びます。
こちらの説明をお読みください。ラボには時間制限があり、一時停止することはできません。タイマーは、Google Cloud のリソースを利用できる時間を示しており、[ラボを開始] をクリックするとスタートします。
このハンズオンラボでは、シミュレーションやデモ環境ではなく実際のクラウド環境を使って、ラボのアクティビティを行います。そのため、ラボの受講中に Google Cloud にログインおよびアクセスするための、新しい一時的な認証情報が提供されます。
このラボを完了するためには、下記が必要です。
[ラボを開始] ボタンをクリックします。ラボの料金をお支払いいただく必要がある場合は、表示されるダイアログでお支払い方法を選択してください。 左側の [ラボの詳細] ペインには、以下が表示されます。
[Google Cloud コンソールを開く] をクリックします(Chrome ブラウザを使用している場合は、右クリックして [シークレット ウィンドウで開く] を選択します)。
ラボでリソースがスピンアップし、別のタブで [ログイン] ページが表示されます。
ヒント: タブをそれぞれ別のウィンドウで開き、並べて表示しておきましょう。
必要に応じて、下のユーザー名をコピーして、[ログイン] ダイアログに貼り付けます。
[ラボの詳細] ペインでもユーザー名を確認できます。
[次へ] をクリックします。
以下のパスワードをコピーして、[ようこそ] ダイアログに貼り付けます。
[ラボの詳細] ペインでもパスワードを確認できます。
[次へ] をクリックします。
その後次のように進みます。
その後、このタブで Google Cloud コンソールが開きます。

Sensitive Data Protection の検出サービスを使用すると、組織全体で機密データやリスクの高いデータが存在する場所を特定できます。検出スキャン構成を作成すると、Sensitive Data Protection によって、確認対象として選択したリソースがスキャンされ、データ プロファイルが生成されます。データ プロファイルとは、特定された infoType(機密データの種類)に関する分析情報と、データリスクおよび機密性レベルに関するメタデータのセットのことです。
このタスクでは、検出スキャンを作成して、プロジェクト内のすべての Cloud Storage バケットにわたってデータを自動的にプロファイリングします。完全な検出結果が生成されるまでには時間がかかるため、このタスクの最後のセクションで主な結果のハイライトと概要が提供されます。
Google Cloud コンソールで、ナビゲーション メニュー(
[データ保護] で [Sensitive Data Protection] をクリックします。
[検出] というタブをクリックします。
[Cloud Storage] で、[有効にする] をクリックします。
[検出タイプの選択] で、[Cloud Storage] のオプションを有効にしたまま、[続行] をクリックします。
[スコープの選択] で、[選択したプロジェクトをスキャン] のオプションを有効にしたまま、[続行] をクリックします。
[スケジュールの管理] はデフォルトのままにして、[続行] をクリックします。
このラボでは作成直後に検出スキャンを実行するようスケジュールを設定しますが、定期的に(毎日または毎週など)実行する、特定のイベント(検査テンプレートが更新されたときなど)の後に実行するなど、スキャンのスケジュール オプションは多数用意されています。
[検査テンプレートの選択] で、[新しい検査テンプレートを作成] オプションを有効にしたままにします。その他のデフォルト値はそのままにして、[続行] をクリックします。
デフォルトでは、新しい検査テンプレートには約 80 種類の事前定義された infoType が含まれています。
[信頼度のしきい値] の [最小の可能性] のデフォルトは [可能性あり] です。つまり、[可能性あり]、[高い]、[かなり高い] と評価された結果のみが得られます。
後のタスクで、この検査テンプレートを変更して、infoType と信頼度のしきい値の他のオプションを試します。
[アクションを追加] で、[Security Command Center に公開] を有効にします。
[アクションを追加] で、[データ プロファイルのコピーを BigQuery に保存する] も有効にして、BigQuery に結果を保存するデータセットとテーブル(このラボで事前に作成済み)を指定します。
| プロパティ | 値 |
|---|---|
| プロジェクト ID |
|
| データセット ID | cloudstorage_discovery |
| テーブル ID | data_profiles |
[続行] をクリックします。
[フォールバック処理のロケーションの設定] はデフォルトのままにして、[続行] をクリックします。
[構成を保存するロケーションの設定] で、[us(米国の複数のリージョン)] のオプションを有効にしたまま、[続行] をクリックします。
この構成の表示名を「Cloud Storage の検出」と指定します。
[作成] をクリックし、[構成を作成] をクリックして作成を確定します。
[プロファイル] タブをクリックします。
[ロケーション タイプ] で [リージョン] >
[
[
注: [ファイルストア] タブをクリックして表示したら、次のセクションのスクリーンショットを確認して、検出結果からデータについてどのようなことがわかるかを把握してから、タスク 2 に進んでください。検出スキャンが完全に完了するのを待つ必要はありません。下の [進捗チェック] をクリックして、タスク 2 に進んでください。
進捗状況を確認するためにこのページを開いたままにする場合は、新しい情報が反映されるよう、定期的にページを更新してください。
[進行状況を確認]
をクリックして、目標に沿って進んでいることを確認します。
注: 構成スキャンの開始後、完全な結果が利用可能になるまでには時間がかかる場合があります。
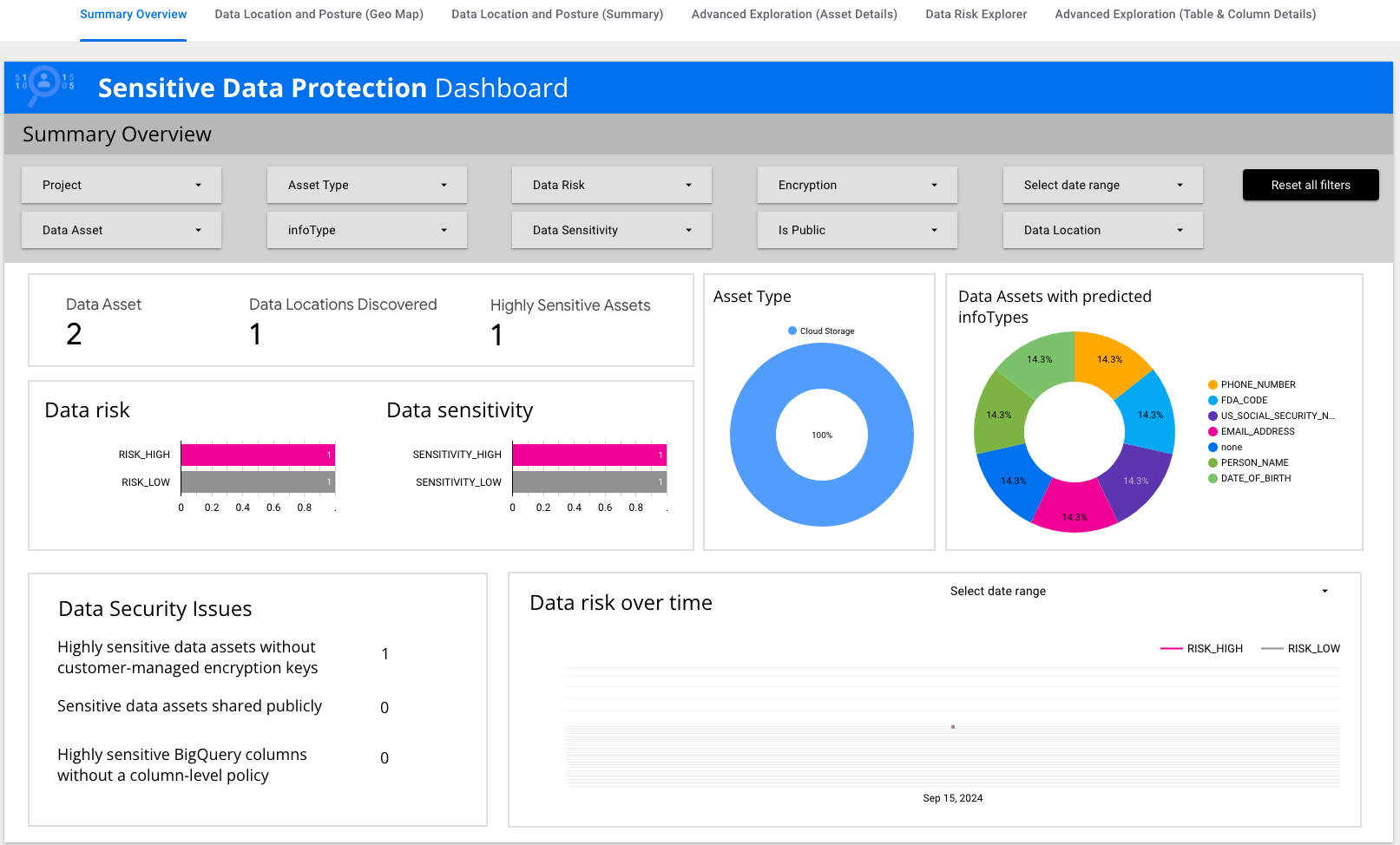
以下の画像は、このラボ環境で Cloud Storage の検出を有効にした場合に得られる主な結果を示しています。検出結果によると、このラボ環境に含まれる Cloud Storage データには、非常に機密性の高いデータである米国社会保障番号など、複数の infoType が存在する可能性があることが示されています。
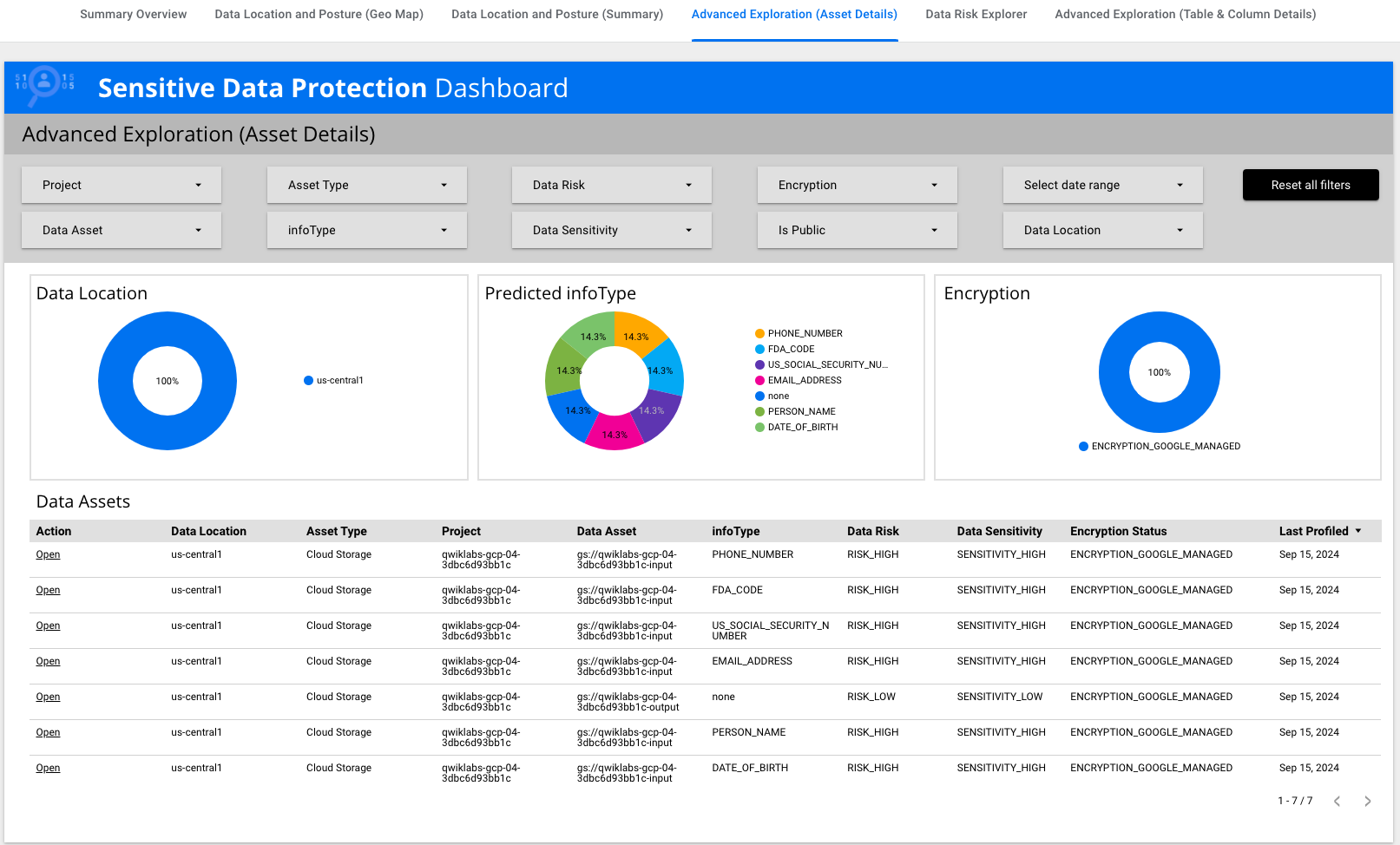
[プロファイル] タブでは、Cloud Storage バケット名ごとに機密性とリスクのレベルが特定されます。1 つは機密性が低いバケット(ジョブからの出力を受け取る空のバケット)で、もう 1 つは機密性が高いバケット(米国社会保障番号を含む元データが格納されたバケット)です。
このラボ環境では、プロファイルを表示するために、[ロケーション タイプ] で [リージョン] > [
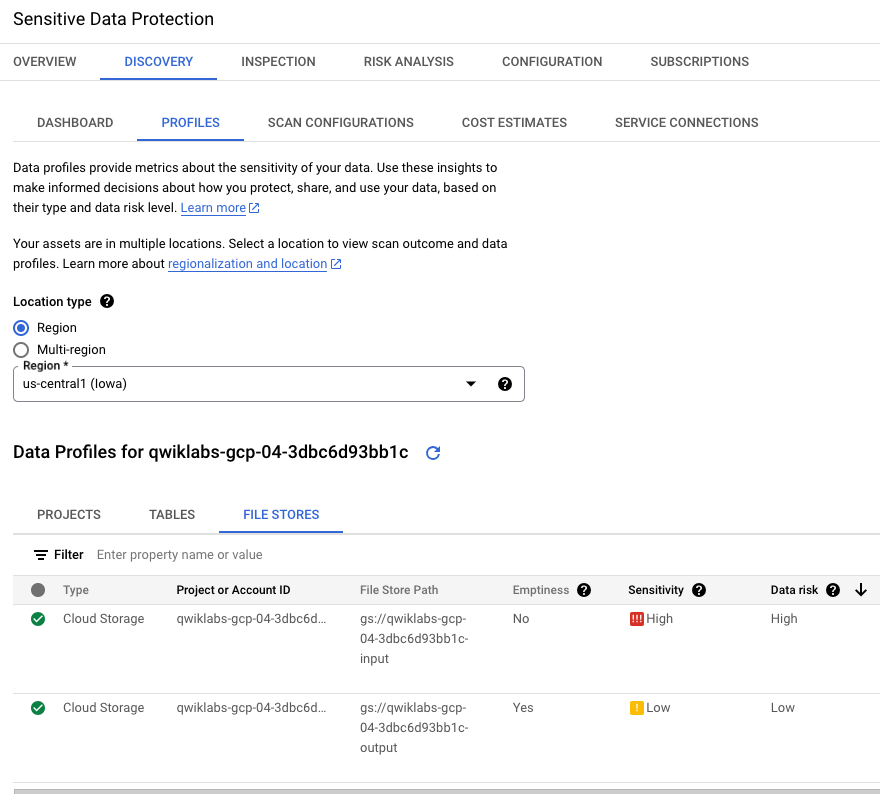
Cloud Storage の 2 つのプロファイルが特定されています。1 つは機密性の低いプロファイル(ジョブからの出力を受け取る空のバケット)で、もう 1 つは機密性の高いプロファイル(元データを含むバケット)です。
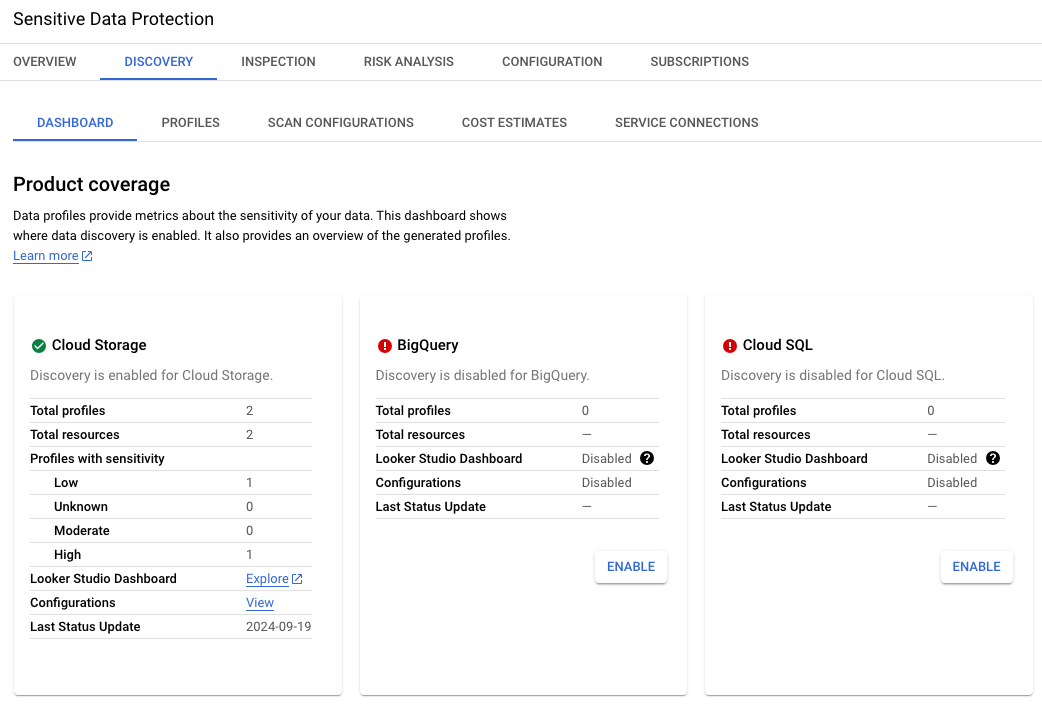
結果のこのセクションには、2 つのデータ プロファイルのグローバル
ロケーションが示されています。この例では、両方とも
us-central1 リージョンにあります。
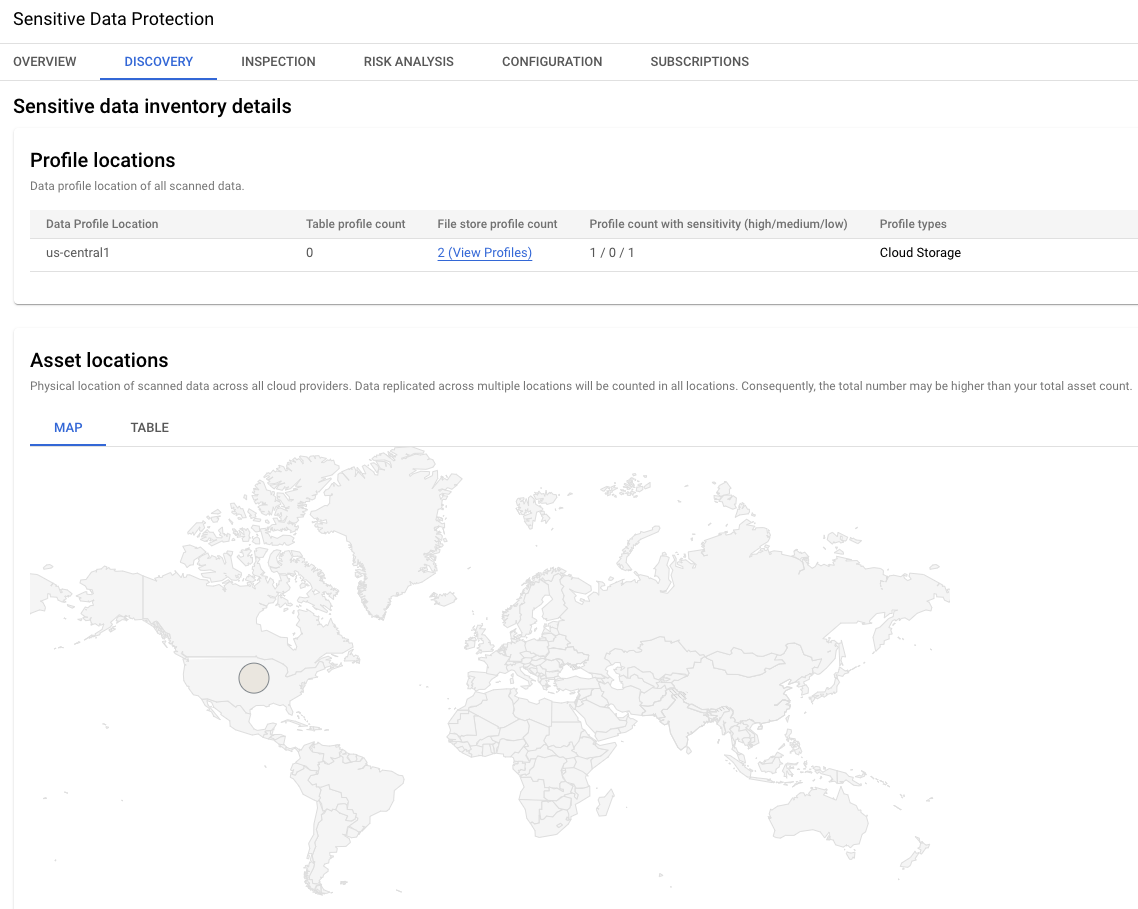
検出結果には、Cloud Storage で特定された主要な InfoType(米国社会保障番号、生年月日、メールアドレス、名前など)も含まれています。
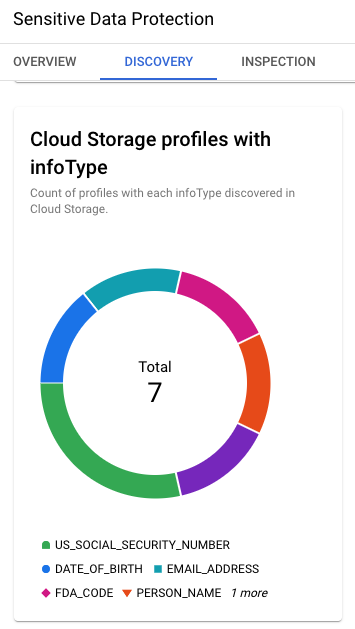
Cloud Storage ファイルで米国社会保障番号が特定されたことがわかったので、ファイルが ML モデルのトレーニングに使用される前に、この機密データを検査して秘匿化する計画を立てることができます。
このタスクでは、次の 2 つのテンプレートを構成します。
ラボの後半では、これらのテンプレートを使用して検査ジョブと匿名化ジョブを実行し、米国社会保障番号をさらに検査して秘匿化します。
Cloud Storage の検出を有効にすると、infoType や信頼度のしきい値など、いくつかのデフォルト値が設定された新しい検査テンプレートが作成されたことを思い出してください。
このセクションでは、すべての検出結果の確認が終わり、米国社会保障番号に焦点を当てるように検査テンプレートを変更するとします。
ナビゲーション メニュー(
[構成] タブをクリックします。
[テンプレート] タブで、検出によって生成されたテンプレートの行(テンプレート ID 7216194786087173213 など)を見つけます。
このテンプレート ID をメモします。これはタスク 4 で使用します。
このテンプレート ID の [アクション] で、その他アイコンをクリックし、[編集] を選択します。
[表示名] を「Inspection Template for US SSN」に変更します。
[説明] を「This template was created as part of a Sensitive Data Protection
profiler configuration and was modified for deeper inspection for US
Social Security numbers.」に更新します。
[InfoType] で、[infoType を管理] をクリックします。
[US_SOCIAL_SECURITY_NUMBER] のチェックボックスをオンにし、他のすべてのオプションの選択を解除します。
[すべての行を選択する](フィルタ アイコンの下)をクリックし、もう一度クリックしてすべての値の選択を解除すると、他のすべてのオプションの選択を簡単に解除できます。
[完了] をクリックして検査テンプレートに戻ります。
[信頼度のしきい値(最小の可能性)] で、[低い] を選択します。
[可能性あり]、[高い]、[かなり高い] と評価された検出結果に加えて、[低い] も結果に含まれるようになるため、米国社会保障番号が含まれる可能性があるインスタンスをよりくわしく確認できるようになります。
その他のデフォルト値はそのままにして、[保存] をクリックします。
[保存の確認] をクリックします。
Sensitive Data Protection の概要ページに戻ります。
[構成] タブをクリックします。
[テンプレート] タブで、[テンプレートを作成] をクリックします。
次の値を指定して、匿名化テンプレートを作成します。
| プロパティ | 値 |
|---|---|
| テンプレートの種類 | 匿名化(機密データの削除) |
| データ変換のタイプ | 記録 |
| テンプレート ID | us_ssn_deidentify |
| 表示名 | De-identification Template for US SSN |
| ロケーション タイプ | [Multi_region] > [global(グローバル)] |
その他のデフォルト値はそのままにして、[続行] をクリックします。
[匿名化の構成] > [変換ルール]
で、フィールド名に ssn と
email を入力し、Enter
キーを押して追加します。
[変換タイプ] で [プリミティブ フィールド変換] を選択します。
[変換方法] > [変換] で、[置換] を選択します。
このオプションでは、ステップ 6 で指定したフィールド(ssn と email)の各インスタンスの内容が置き換えられます。
[変換方法] > [型の置換] で、[文字列] を選択します。
[変換方法] > [文字列値]
は、デフォルト値の [redacted] のままにします。
[+ 変換ルールを追加] をクリックして 2 つ目のルールを追加します。
この 2 つ目のルールの [変換ルール]
で、フィールド名「message」を入力し、Enter
キーを押して追加します。
このラボ環境では、Cloud Storage に CSV ファイルがあります。このファイルに含まれている message という列(またはフィールド)には、顧客とサービス エージェント間のチャット メッセージの例が保存されています。
[変換タイプ] で [infoType に基づく一致] を選択し、[変換を追加] をクリックします。
[変換方法] で [infoType 名での置換] を選択します。
[変換する InfoType] で、[検査テンプレートまたは検査構成で定義されているが、他のルールで指定されていない、検出されたすべての infoType] を選択します。
このオプションでは、このテンプレートを使用してジョブを実行すると、message というフィールドを持つすべてのファイルに infoType の検査と秘匿化が適用されます。
[作成] をクリックします。
[進行状況を確認]
をクリックして、目標に沿って進んでいることを確認します。
注: 前述のように、構成スキャンの開始後、完全な結果が利用可能になるまでには時間がかかる場合があります。
テンプレートを作成している間に時間が経過したため、検出スキャンによって生成された結果の一部を Looker ダッシュボードで確認できるようになっています。このタスクでは、タスク 1 で BigQuery に保存されたデータ プロファイル情報から取得された最初の検出結果を Looker ダッシュボードで確認します。
Sensitive Data Protection の概要ページに戻ります。
[検出] > [スキャン構成] タブで、[Cloud Storage の検出] という名前の行を見つけます。[Data Studio] で、その行の [Looker] をクリックします。
[承認のリクエスト] で [承認] をクリックします。
[qwiklabs.net のアカウントを選択] ダイアログ
ウィンドウで、
[データアクセスの確認] で [確認] をクリックします。
[同意の付与] で、[許可] をクリックします。
[概要] ページを確認します。
データリスク、データの機密性、アセットタイプなどの主要な情報を要約したデータタイルが表示されます。
infoType に
US_SOCIAL_SECURITY_NUMBER が含まれていることを確認します。
[編集して共有] をクリックします。
[基本情報を入力] で、国を選択し、会社名(例: NA)を入力します。
利用規約に同意する場合はチェックボックスをオンにして、[続行] をクリックします。
すべてのメール設定で [いいえ] を選択してから、[続行] をクリックします。
[データアクセスを確認してから保存] で、[同意して保存する] をクリックします。
Data Studio で [表示] をクリックしてレポートを表示します。
infoType が
US_SOCIAL_SECURITY_NUMBER
の行を特定し、その行の最初の列にある [開く]
をクリックします。
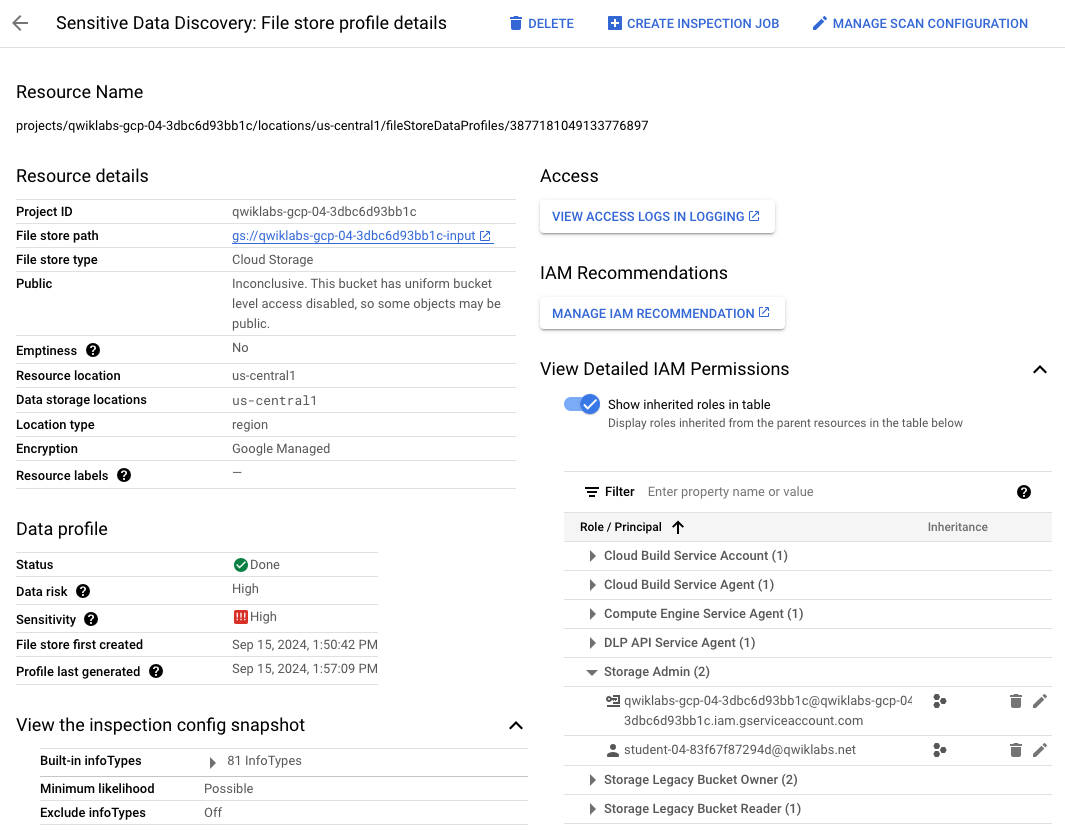
[機密データの検出: Cloud Storage Filestore のプロファイルの詳細]
ページで、[プロジェクトを選択](上部のメニューバー)がプロジェクト
ID
IAM 権限など、スキャンされたリソースに関する多くの詳細情報が表示されます。
[詳細な IAM 権限の表示] の横にある矢印を開きます。
[ストレージ管理者] の横にある矢印を開きます。
別のユーザー(
Sensitive Data Protection では、検出スキャン後の一般的なワークフローとして、特定の infoType をさらに深く調査するために、より詳細な検査ジョブを実行します。
タスク 2 で、米国社会保障番号をより詳細に検査するための検査テンプレートを作成したことを思い出してください。このタスクでは、そのテンプレートを使用して検査ジョブを作成し、実行します。
Sensitive Data Protection の概要ページに戻ります。
[検査] タブをクリックし、[ジョブとジョブトリガーを作成] をクリックします。
[入力データを選択] で、次の値を指定します。
| プロパティ | 値 |
|---|---|
| ジョブ ID | us_ssn_inspection |
| ロケーション タイプ | [Multi_region] > [us(米国の複数のリージョン)] |
| ストレージの種類 | Google Cloud Storage |
| ロケーション タイプ | 単一のファイルまたはフォルダパスをスキャン |
| URL |
gs:/// を追加してください)
|
| スキャンの繰り返し |
このオプションを有効にします(このオプションを有効にするには、上記の URL
の末尾に / を追加してください)
|
| サンプリング | 値を 100% に引き上げます |
| サンプリング方法 | サンプルなし |
| ファイル | [テキスト] と [CSV] を選択(他のオプションはすべて選択を解除)して、[OK] をクリックします |
[続行] をクリックします。
[監査用テンプレート] > [テンプレート名]
で、以下に示す検査テンプレートのパスを追加します。TEMPLATE_ID
は、タスク 2 で変更した検査テンプレートのテンプレート
ID(7216194786087173213 など)に置き換えます。
projects/
テンプレート ID を再度表示するには、Sensitive Data Protection の概要ページの [構成] タブに移動します。
その他のデフォルト値はそのままにして、[続行] をクリックします。
[アクションを追加] で、[BigQuery に保存] オプションを有効にし、[引用を含める] チェックボックスをオンにします。
このオプションを使用すると、ジョブで機密性が高い可能性があるデータのロケーションとコンテンツの両方を BigQuery にコピーできます。
結果を BigQuery に保存するために、データセットとテーブル(このラボで事前に作成済み)を指定します。
| プロパティ | 値 |
|---|---|
| プロジェクト ID |
|
| データセット ID | cloudstorage_inspection |
| テーブル ID | us_ssn |
[アクションを追加] で、[Security Command Center に公開] も有効にします。
[続行] をクリックします。
ジョブをすぐに実行するため、[スケジュール] をデフォルトの [なし(1 回限りのジョブを作成直後に実行)] のままにして、[続行] をクリックします。
検出スキャンと同様に、検査ジョブを特定のスケジュールで実行するようにスケジュールを設定できます。上記の設定の場合、ジョブは作成後すぐに実行されます。
このページを閉じずに、ジョブが完了するまで待ちます。
ジョブのステータスが [完了] になったら、次のセクションに進みます。
前のセクションでは、検査結果を us_ssn という名前の BigQuery テーブルに保存しました。下のボタンを 1 回クリックするだけで、BigQuery に簡単に移動して結果を確認できます。
[結果を BigQuery で表示] をクリックします。
BigQuery で [プレビュー] をクリックして、テーブルの内容を確認します。
quote という列に注目してください。この列には、検査ジョブで追加の確認が必要というフラグを付けられた値の正確なコピーが含まれています。また、テーブルを右にスクロールして container name という列を確認すると、引用された値を含むロケーション(具体的にはファイル名)を確認できます。
[進行状況を確認]
をクリックして、目標に沿って進んでいることを確認します。
検出に加えて、匿名化と呼ばれる別の Sensitive Data Protection サービスも利用できます。このサービスでは、匿名化ジョブを実行して機密データが秘匿化された Cloud Storage ファイルの新しいコピーを作成することで、Cloud Storage の機密データの脆弱性を軽減できます。これらの新しいコピーは、機密データを含む元のバージョンの代わりに、ダウンストリームのワークフローと共有できます。
このタスクでは、タスク 2 で作成した匿名化テンプレートを使用して、匿名化ジョブを作成して実行します。
Sensitive Data Protection の概要ページに戻ります。
[検査] タブをクリックし、[ジョブとジョブトリガーを作成] をクリックします。
[入力データを選択] で、次の値を指定します。
| プロパティ | 値 |
|---|---|
| ジョブ ID | us_ssn_deidentify |
| ロケーション タイプ | [Multi_region] > [us(米国の複数のリージョン)] |
| ストレージの種類 | Google Cloud Storage |
| ロケーション タイプ | オプションの「含める / 除外する」ルールでバケットをスキャンします |
| バケット名 |
|
| サンプリング | 値を 100% に引き上げます |
| サンプリング方法 | サンプルなし |
| ファイル | [テキスト] と [CSV] を選択(他のオプションはすべて選択を解除)して、[OK] をクリックします |
ignore」と入力します。
[除外するパス 1] の値は次のようになります。
gs://
このオプションを使用すると、ignore
というサブディレクトリ内のファイルを無視するように匿名化ジョブに指示できます。
検査テンプレートの値は追加しないことに注意してください。次のステップでは、代わりに匿名化テンプレートの値を定義します。
[検出の設定] で、すべての値をデフォルトのままにして、[続行] をクリックします。
[アクションの追加] で、ページを下にスクロールして [匿名化コピーを作成する] を見つけて有効にします。
[構造化された匿名化テンプレート] で、構造化ファイル(CSV ファイルやテキスト ファイルなど)用に以前作成した匿名化テンプレートを入力します。
projects/
| プロパティ | 値 |
|---|---|
| プロジェクト ID |
|
| データセット ID | cloudstorage_transformations |
| テーブル ID | deidentify_ssn_csv |
gs://
この値は、秘匿化された出力を、このラボで出力ファイル用に事前に作成した 2 つ目のバケットに書き込むようにジョブに指示します。
[ファイル] で [テキスト] と [CSV] を選択(他のオプションはすべて選択を解除)し、[OK] をクリックします。
[続行] をクリックします。
ジョブをすぐに実行するため、[スケジュール] はデフォルトの [なし] のままにして、[続行] をクリックします。
検査ジョブと同様に、スケジュールのオプションには、定期的なスケジュール(毎週など)での匿名化ジョブの実行が含まれます。
このページを閉じずに、ジョブが完了するまで待ちます。
ジョブのステータスが [完了] になったら、このブラウザタブを開いたままにして、次のセクションに進みます。
前のセクションでは、匿名化の詳細を deidentify_ssn_csv という BigQuery テーブルに保存しました。このセクションでは、BigQuery に移動して変換の詳細を確認します。
Google Cloud コンソールで、ナビゲーション メニュー(
[エクスプローラ] ペインで、
[プレビュー] をクリックして結果を確認します。
container_name 列と transformation.type 列に注目してください。これらの列には、特定の変換ルールを使用して匿名化されたファイルの詳細が示されています。
検査ジョブの結果ページに戻り、[構成] をクリックします。
[アクション] > [匿名化された Cloud Storage データの出力バケット] までスクロールします。
バケットのリンク(gs://
[進行状況を確認]
をクリックして、目標に沿って進んでいることを確認します。
このラボでは、Cloud Storage ファイル内の機密データを継続的にモニタリングするための検出を有効にしました。また、検査と匿名化のための再利用可能なテンプレートを作成および変更し、追加調査用にジョブの結果を BigQuery に書き込むオプションを有効にして、検査ジョブと匿名化ジョブを実行しました。
Cloud Storage の Sensitive Data Protection について詳しくは、次のリソースをご覧ください。
Google Cloud トレーニングと認定資格を通して、Google Cloud 技術を最大限に活用できるようになります。必要な技術スキルとベスト プラクティスについて取り扱うクラスでは、学習を継続的に進めることができます。トレーニングは基礎レベルから上級レベルまであり、オンデマンド、ライブ、バーチャル参加など、多忙なスケジュールにも対応できるオプションが用意されています。認定資格を取得することで、Google Cloud テクノロジーに関するスキルと知識を証明できます。
マニュアルの最終更新日: 2026 年 3 月 10 日
ラボの最終テスト日: 2026 年 3 月 10 日
Copyright 2026 Google LLC. All rights reserved. Google および Google のロゴは Google LLC の商標です。その他すべての企業名および商品名はそれぞれ各社の商標または登録商標です。



このコンテンツは現在ご利用いただけません
利用可能になりましたら、メールでお知らせいたします

ありがとうございます。
利用可能になりましたら、メールでご連絡いたします

1 回に 1 つのラボ
既存のラボをすべて終了して、このラボを開始することを確認してください
ラボを開始するには、この簡単な手順を完了してください。