GSP1281

Présentation
Sensitive Data Protection
est un service entièrement géré conçu pour vous aider à découvrir, classer et
protéger les informations sensibles. Les principales options incluent la
découverte des données sensibles pour détecter en continu ce type de données,
l'anonymisation de ces données, y compris le masquage, et l'API Cloud Data
Loss Prevention (DLP) pour intégrer la découverte, l'inspection et
l'anonymisation dans des charges de travail et des applications
personnalisées.
Imaginez que vous disposez de données brutes dans Cloud Storage contenant des
informations sensibles, et que vous souhaitez les identifier, les protéger et
les masquer avant que les fichiers ne parviennent aux utilisateurs finaux pour
l'analyse ou pour l'entraînement de modèles de machine learning. Sensitive
Data Protection vous facilite la tâche.
Dans cet atelier, vous allez commencer par activer la découverte afin de
mettre en place une surveillance continue des données sensibles dans
Cloud Storage. En fonction des résultats, vous allez créer et modifier des
modèles personnalisés et réutilisables pour l'inspection et l'anonymisation
(le masquage) des fichiers Cloud Storage. Enfin, vous utiliserez ces modèles
pour inspecter et masquer plus en détail des types de données sensibles
spécifiques dans vos fichiers Cloud Storage.
Points abordés
Dans cet atelier, vous allez apprendre à effectuer les tâches suivantes :
-
Activer la découverte pour la surveillance continue des données sensibles
dans les fichiers Cloud Storage
-
Créer et modifier des modèles réutilisables pour les jobs d'inspection et
d'anonymisation
- Examiner et interpréter les résultats de la découverte
-
Exécuter des jobs d'inspection et d'anonymisation avec l'option permettant
d'écrire les résultats dans BigQuery
Préparation
Avant de cliquer sur le bouton "Démarrer l'atelier"
Lisez ces instructions. Les ateliers sont minutés, et vous ne pouvez pas les mettre en pause. Le minuteur, qui démarre lorsque vous cliquez sur Démarrer l'atelier, indique combien de temps les ressources Google Cloud resteront accessibles.
Cet atelier pratique vous permet de suivre les activités dans un véritable environnement cloud, et non dans un environnement de simulation ou de démonstration. Des identifiants temporaires vous sont fournis pour vous permettre de vous connecter à Google Cloud le temps de l'atelier.
Pour réaliser cet atelier :
- Vous devez avoir accès à un navigateur Internet standard (nous vous recommandons d'utiliser Chrome).
Remarque : Ouvrez une fenêtre de navigateur en mode incognito (recommandé) ou de navigation privée pour effectuer cet atelier. Vous éviterez ainsi les conflits entre votre compte personnel et le compte temporaire de participant, qui pourraient entraîner des frais supplémentaires facturés sur votre compte personnel.
- Vous disposez d'un temps limité. N'oubliez pas qu'une fois l'atelier commencé, vous ne pouvez pas le mettre en pause.
Remarque : Utilisez uniquement le compte de participant pour cet atelier. Si vous utilisez un autre compte Google Cloud, des frais peuvent être facturés à ce compte.
Démarrer l'atelier et se connecter à la console Google Cloud
-
Cliquez sur le bouton Démarrer l'atelier. Si l'atelier est payant, une boîte de dialogue s'affiche pour vous permettre de sélectionner un mode de paiement.
Sur la gauche, vous trouverez le panneau "Détails concernant l'atelier", qui contient les éléments suivants :
- Le bouton "Ouvrir la console Google Cloud"
- Le temps restant
- Les identifiants temporaires que vous devez utiliser pour cet atelier
- Des informations complémentaires vous permettant d'effectuer l'atelier
-
Cliquez sur Ouvrir la console Google Cloud (ou effectuez un clic droit et sélectionnez Ouvrir le lien dans la fenêtre de navigation privée si vous utilisez le navigateur Chrome).
L'atelier lance les ressources, puis ouvre la page "Se connecter" dans un nouvel onglet.
Conseil : Réorganisez les onglets dans des fenêtres distinctes, placées côte à côte.
Remarque : Si la boîte de dialogue Sélectionner un compte s'affiche, cliquez sur Utiliser un autre compte.
-
Si nécessaire, copiez le nom d'utilisateur ci-dessous et collez-le dans la boîte de dialogue Se connecter.
{{{user_0.username | "Username"}}}
Vous trouverez également le nom d'utilisateur dans le panneau "Détails concernant l'atelier".
-
Cliquez sur Suivant.
-
Copiez le mot de passe ci-dessous et collez-le dans la boîte de dialogue Bienvenue.
{{{user_0.password | "Password"}}}
Vous trouverez également le mot de passe dans le panneau "Détails concernant l'atelier".
-
Cliquez sur Suivant.
Important : Vous devez utiliser les identifiants fournis pour l'atelier. Ne saisissez pas ceux de votre compte Google Cloud.
Remarque : Si vous utilisez votre propre compte Google Cloud pour cet atelier, des frais supplémentaires peuvent vous être facturés.
-
Accédez aux pages suivantes :
- Acceptez les conditions d'utilisation.
- N'ajoutez pas d'options de récupération ni d'authentification à deux facteurs (ce compte est temporaire).
- Ne vous inscrivez pas à des essais sans frais.
Après quelques instants, la console Cloud s'ouvre dans cet onglet.
Remarque : Pour accéder aux produits et services Google Cloud, cliquez sur le menu de navigation ou saisissez le nom du service ou du produit dans le champ Recherche.

Tâche 1 : Activer la découverte pour la surveillance continue dans
Cloud Storage
Le service de découverte de Sensitive Data Protection vous permet d'identifier
où se trouvent les données sensibles et à haut risque au sein de votre
entreprise. Lorsque vous créez une configuration d'analyse de découverte,
Sensitive Data Protection analyse les ressources que vous sélectionnez et
génère des
profils de données. Il s'agit d'un ensemble d'informations sur les
infoTypes
(types de données sensibles) identifiés et de métadonnées sur le risque et le
niveau de sensibilité des données.
Dans cette tâche, vous allez créer une analyse de découverte pour profiler
automatiquement les données dans tous les buckets Cloud Storage du projet. La
génération des résultats complets de la découverte pouvant prendre un certain
temps, vous trouverez dans la dernière section de cette tâche des points clés
et des résumés des principaux résultats.
Créer et planifier une configuration d'analyse
-
Dans la console Google Cloud, cliquez sur le
menu de navigation ( ) > BigQuery.
) > BigQuery.
-
Sous Protection des données, cliquez sur
Sensitive Data Protection.
-
Cliquez sur l'onglet Découverte.
-
Sous Cloud Storage, cliquez sur Activer.
-
Pour Sélectionner un type de détection, laissez l'option
Cloud Storage activée, puis cliquez sur
Continuer.
-
Pour Sélectionner un champ d'application, laissez
l'option Analyser le projet sélectionné activée et
cliquez sur Continuer.
-
Pour Planifications gérées, conservez la valeur par
défaut et cliquez sur Continuer.
Dans cet atelier, vous allez planifier l'exécution de l'analyse de
découverte immédiatement après sa création. Cependant, de nombreuses
options permettent de programmer les analyses à exécuter de façon
périodique (par exemple, une fois par jour ou une fois par semaine) ou
après certains événements (par exemple, lorsqu'un modèle d'inspection est
mis à jour).
-
Pour Sélectionner un modèle d'inspection, laissez
l'option Créer un modèle d'inspection activée. Conservez
les autres valeurs par défaut, puis cliquez sur
Continuer.
Par défaut, le nouveau modèle d'inspection inclut environ 80 infoTypes
prédéfinis.
Pour Seuil de confiance, la
probabilité
minimale
par défaut est Possible. Cela signifie que vous n'obtenez
que les résultats évalués comme Possible,
Probable et Très probable.
Dans une tâche ultérieure, vous modifierez ce modèle d'inspection pour
explorer d'autres options concernant les infoTypes et le seuil de
confiance.
-
Pour Ajouter des actions, activez
Publier dans Security Command Center.
-
Pour Ajouter des actions, activez également
Enregistrer des copies des profils de données dans BigQuery
et indiquez l'ensemble de données et la table (qui ont été créés au
préalable dans cet atelier) pour enregistrer les résultats dans BigQuery.
| Propriété |
Valeur |
| ID du projet |
|
| ID de l'ensemble de données |
cloudstorage_discovery |
| ID de la table |
data_profiles |
-
Cliquez sur Continuer.
-
Pour
Définir des emplacements de secours pour le traitement,
conservez les valeurs par défaut et cliquez sur
Continuer.
-
Pour
Définir l'emplacement de stockage de la configuration,
laissez l'option activée pour
États-Unis (plusieurs régions aux États-Unis), puis
cliquez sur Continuer.
-
Indiquez un nom à afficher pour cette configuration :
Découverte Cloud Storage
-
Cliquez sur Créer, puis confirmez la création en cliquant
sur Créer une configuration.
-
Cliquez sur l'onglet Profils.
-
Pour Type d'emplacement, sélectionnez
Région >
pour afficher les profils.
-
Dans la table nommée
Profils de données pour
, cliquez sur l'onglet Magasins de fichiers.
Remarque : Une fois que l'onglet
Magasins de fichiers est affiché, consultez les captures
d'écran de la section suivante pour avoir un aperçu de ce que les résultats
de la découverte peuvent vous révéler sur vos données, puis passez à la
tâche 2.
Vous n'avez pas besoin d'attendre que l'analyse de découverte soit
terminée pour cliquer sur la vérification de la progression ci-dessous et
passer à la tâche 2.
Si vous décidez de laisser cette page ouverte pour suivre la progression dans
le temps, veillez à l'actualiser régulièrement pour voir les nouvelles
informations s'afficher.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Créer et planifier une configuration d'analyse
Ce que les résultats de la découverte peuvent vous révéler sur vos données
Remarque : Une fois l'analyse de la configuration lancée,
il peut s'écouler un certain temps avant que les résultats complets ne
soient disponibles.
Les images ci-dessous présentent les principaux résultats de l'activation de
la découverte pour Cloud Storage dans cet environnement d'atelier.
Pour les données Cloud Storage incluses dans cet environnement d'atelier, les
résultats ont signalé la présence potentielle de plusieurs infoTypes, y
compris des numéros de sécurité sociale américains, qui sont des données très
sensibles.
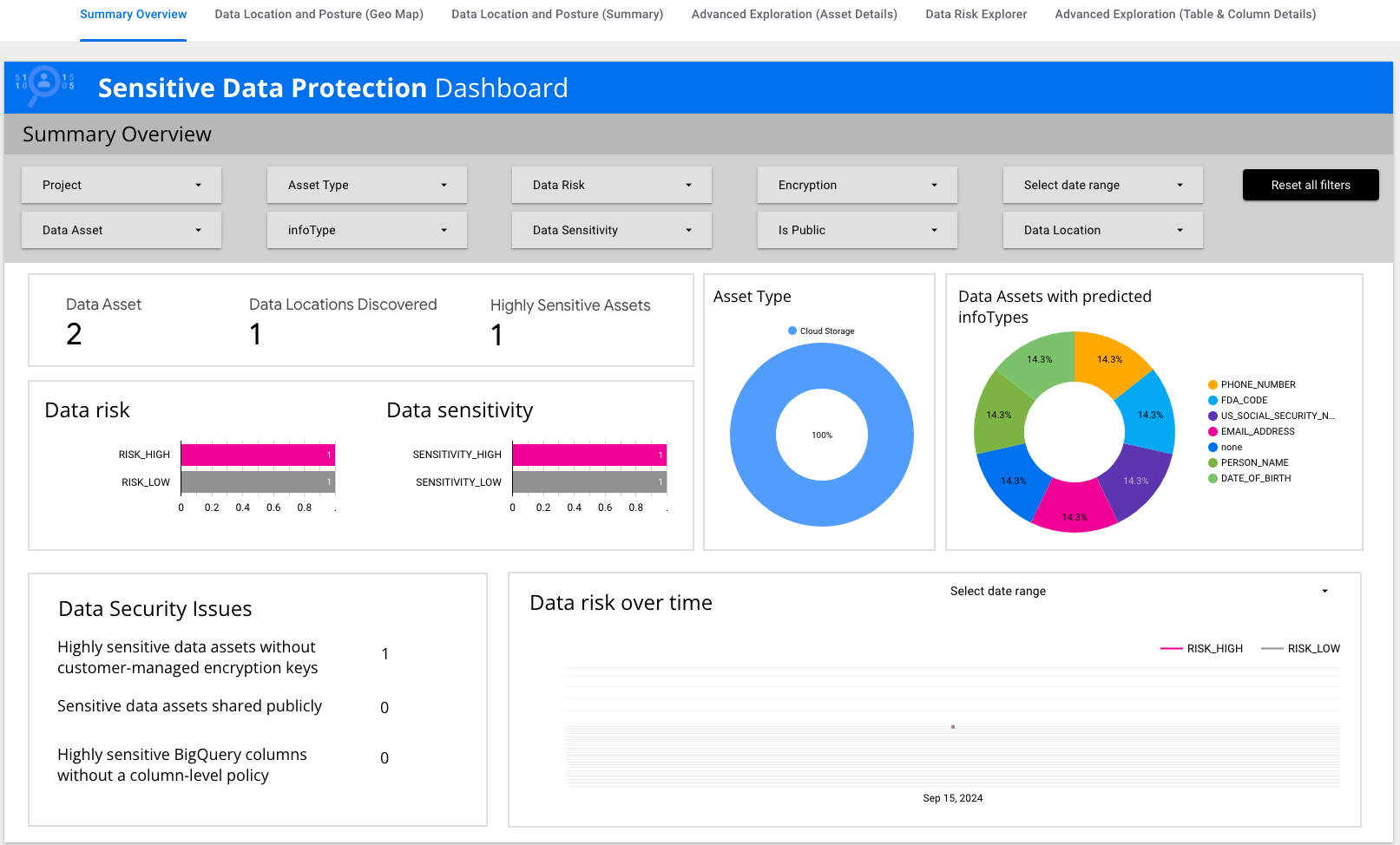
Image 1. Onglet "Profils" des résultats de la découverte
L'onglet Profils identifie les niveaux de sensibilité et de
risque pour chaque nom de bucket Cloud Storage : un bucket à faible
sensibilité (bucket vide destiné à recevoir les résultats des jobs) et un
bucket à sensibilité élevée (bucket contenant des données brutes, y compris
des numéros de sécurité sociale).
Dans cet environnement d'atelier, veillez à sélectionner
Région >
comme Type d'emplacement pour afficher les profils.
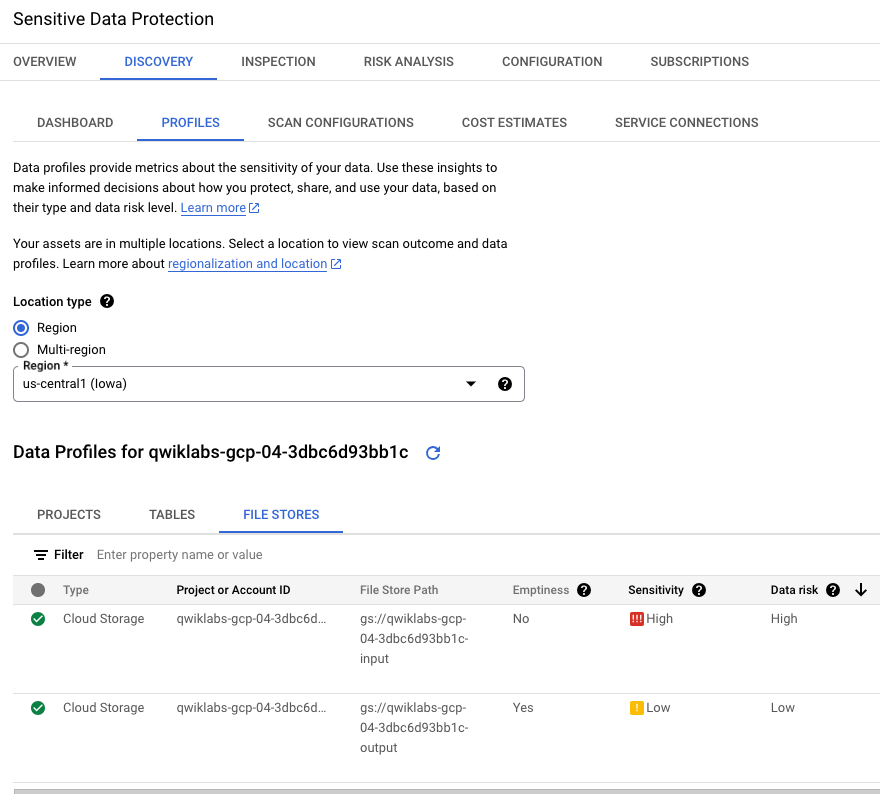
Image 2. Découverte pour Cloud Storage activée dans l'UI
Deux profils ont été identifiés pour Cloud Storage : un profil à faible
sensibilité (bucket vide destiné à recevoir les résultats des jobs) et un
profil à sensibilité élevée (bucket contenant des données brutes).
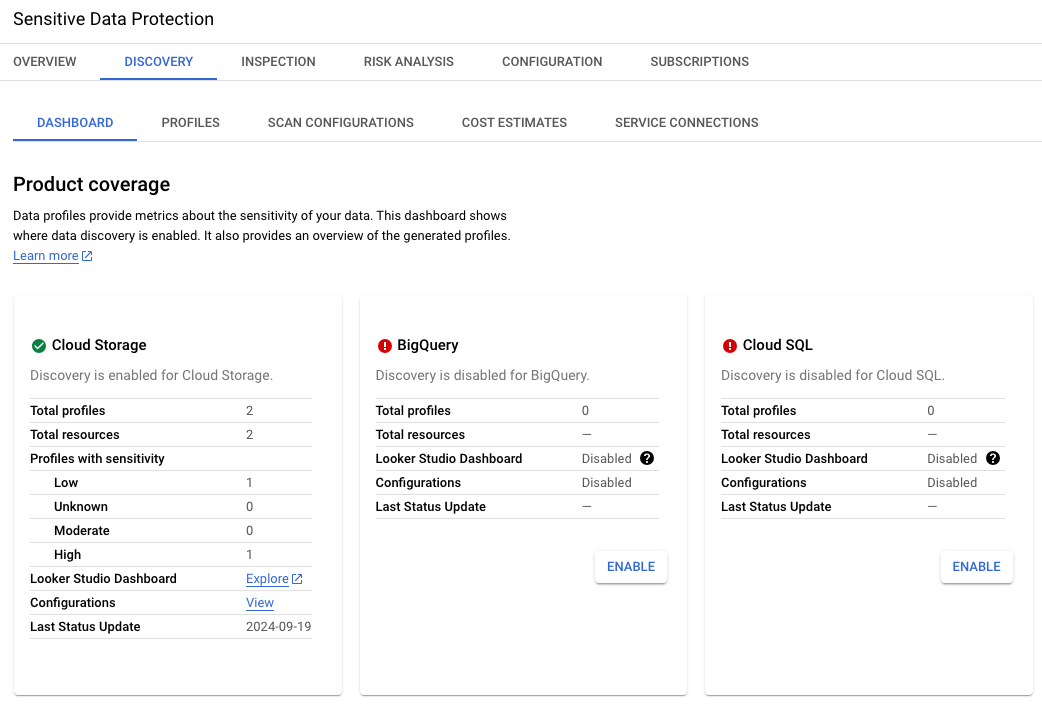
Image 3. Détails de l'inventaire des données sensibles
Cette section des résultats indique l'emplacement des deux profils de données.
Dans cet exemple, les deux se trouvent dans la région
us-central1.
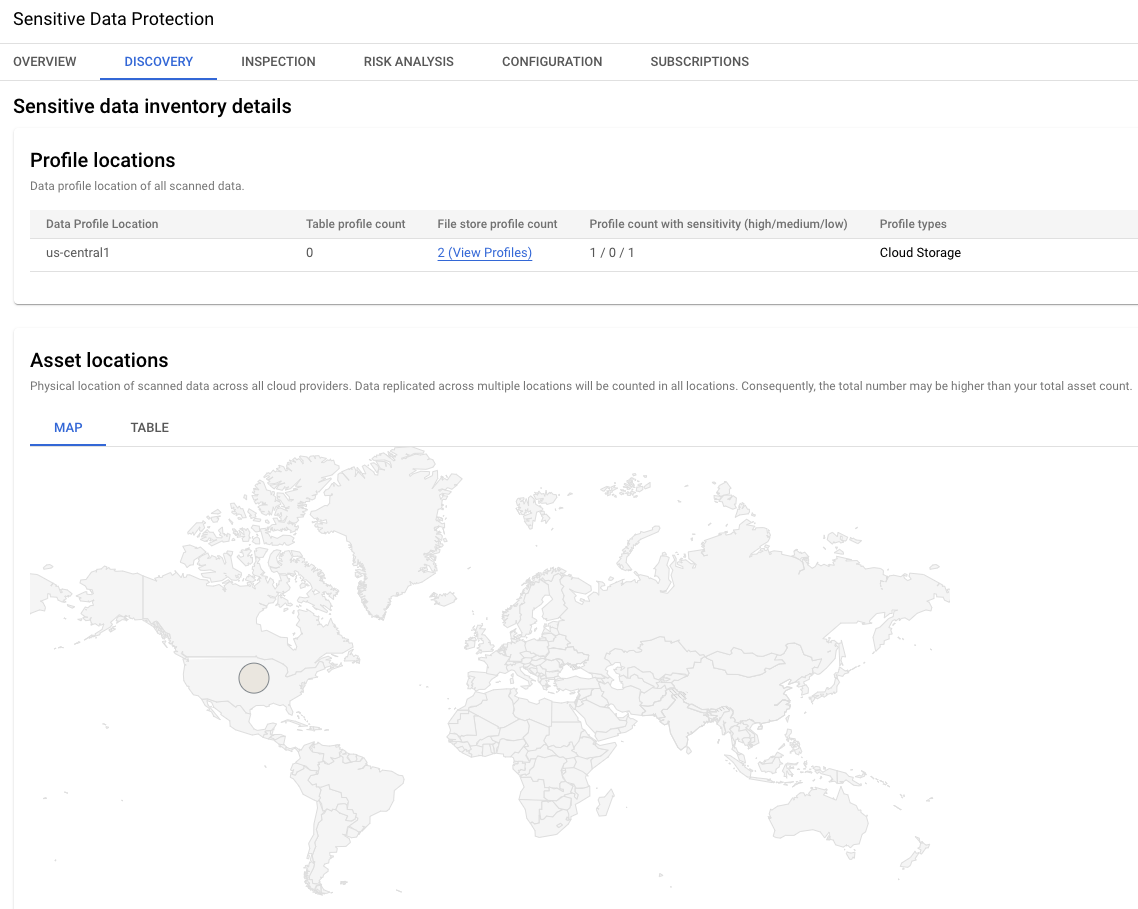
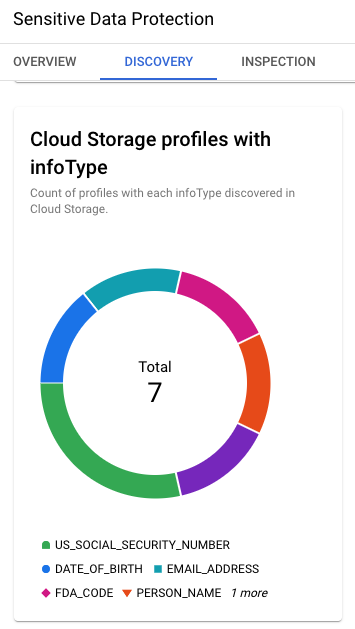
Image 4. Profils Cloud Storage avec infoTypes
Les résultats de la découverte fournissent également les infoTypes clés
identifiés dans Cloud Storage : numéro de sécurité sociale américain, date de
naissance, adresse e-mail, nom, etc.
Tâche 2 : Créer et modifier des modèles réutilisables pour inspecter et
masquer des infoTypes spécifiques
Maintenant que vous savez que des numéros de sécurité sociale américains ont
été identifiés dans vos fichiers Cloud Storage, vous pouvez commencer à
planifier l'inspection et le masquage de ces données sensibles avant que les
fichiers ne soient utilisés pour entraîner des modèles de machine learning.
Dans cette tâche, vous allez configurer deux
modèles :
-
Un modèle d'inspection existant que vous modifierez pour identifier toutes
les instances de numéros de sécurité sociale américains dans vos fichiers
Cloud Storage
-
Un modèle d'anonymisation pour masquer les numéros de sécurité sociale
américains dans des fichiers de données structurées (comme des fichiers
texte et CSV)
Plus tard dans l'atelier, vous utiliserez ces modèles pour inspecter et
masquer les numéros de sécurité sociale américains en lançant des jobs
d'inspection et d'anonymisation.
Modifier un modèle d'inspection existant
Rappelez-vous que lorsque vous avez activé la découverte pour Cloud Storage,
un modèle d'inspection a été créé avec plusieurs valeurs par défaut, y compris
celles des infoTypes et du seuil de confiance.
Dans cette section, imaginez que vous avez déjà examiné tous les résultats de
la découverte et que vous souhaitez maintenant modifier ce modèle d'inspection
pour vous concentrer sur les numéros de sécurité sociale américains.
-
Revenez à la page de présentation de
Sensitive Data Protection
en cliquant sur le menu de navigation () > Sécurité >
Sensitive Data Protection (sous
Protection des données).
-
Cliquez sur l'onglet Configuration.
-
Dans l'onglet Modèles, recherchez la ligne correspondant
au modèle généré par la découverte (par exemple, l'ID de modèle
7216194786087173213).
Notez cet ID de modèle, car vous en aurez besoin lors de la tâche 4.
-
Sous Actions pour cet ID de modèle, cliquez sur les trois
points verticaux, puis sélectionnez Modifier.
-
Modifiez le Nom à afficher en
Modèle d'inspection pour les numéros de sécurité sociale
américains.
-
Modifiez le champ Description et saisissez
Ce modèle a été créé dans le cadre d'une configuration de profileur
Sensitive Data Protection et a été modifié pour permettre une inspection
plus approfondie des numéros de sécurité sociale américains.
-
Pour InfoTypes, cliquez sur
Gérer les infoTypes.
-
Cochez la case US_SOCIAL_SECURITY_NUMBER et décochez
toutes les autres options.
Vous pouvez facilement désélectionner toutes les autres options en
cliquant sur Sélectionner toutes les lignes (sous l'icône
de filtre), puis en cliquant à nouveau dessus pour désélectionner toutes
les valeurs.
-
Cliquez sur OK pour revenir au modèle d'inspection.
-
Pour Seuil de confiance ("probabilité minimale"),
sélectionnez Improbable.
En plus des résultats évalués comme Possible,
Probable et Très probable, les résultats
incluront désormais Improbable afin de faciliter un
examen complémentaire des occurrences potentielles de numéros de sécurité
sociale américains.
-
Conservez les autres valeurs par défaut, puis cliquez sur
Enregistrer.
-
Cliquez sur Confirmer l'enregistrement.
Créer un modèle d'anonymisation pour des données structurées
-
Revenez à la page de présentation de
Sensitive Data Protection.
-
Cliquez sur l'onglet Configuration.
-
Dans l'onglet Modèles, cliquez sur
Créer un modèle.
-
Indiquez les valeurs suivantes pour créer le modèle d'anonymisation :
| Propriété |
Valeur |
| Type de modèle |
Anonymiser (supprimer les données sensibles)
|
| Type de transformation de données |
Enregistrer |
| ID du modèle |
us_ssn_deidentify |
| Nom à afficher |
Modèle d'anonymisation pour les numéros de sécurité sociale
américains
|
| Type d'emplacement |
Multirégional > Mondial |
-
Conservez les autres valeurs par défaut et cliquez sur
Continuer.
-
Pour Configurer l'anonymisation >
Règle de transformation, saisissez les noms de champs
numéro de sécurité sociale et
adresse e-mail, puis appuyez sur la touche
Entrée.
-
Pour Type de transformation, sélectionnez
Transformation des champs primitifs.
-
Pour Méthode de transformation >
Transformation, sélectionnez Remplacer.
Cette option remplace le contenu de chaque instance pour les champs que
vous avez fournis à l'étape 6 (numéro de sécurité sociale et adresse
e-mail).
-
Pour Méthode de transformation >
Type de remplacement, sélectionnez
Chaîne.
-
Pour Méthode de transformation >
Valeur de chaîne, conservez la valeur par défaut
[redacted].
-
Cliquez sur + Ajouter une règle de transformation pour
ajouter une deuxième règle.
-
Pour cette deuxième règle de transformation, saisissez le
nom de champ message, puis appuyez sur la touche
Entrée.
Dans cet environnement d'atelier, des fichiers CSV dans Cloud Storage
contiennent une colonne (ou un champ) nommée message, qui
stocke les exemples de messages de chat entre les clients et les agents de
service.
-
Pour Type de transformation, sélectionnez
Correspondance par infoType, puis cliquez sur
Ajouter une transformation.
-
Pour Méthode de transformation, sélectionnez
Remplacer par un nom d'infoType.
-
Pour InfoTypes à transformer, sélectionnez
Tous les infoTypes détectés définis dans un modèle d'inspection ou une
configuration d'inspection, et non spécifiés dans d'autres
règles.
Cette option applique l'inspection et le masquage des infoTypes à tous les
fichiers contenant un champ nommé message lorsque ce
modèle est utilisé pour exécuter un job.
-
Cliquez sur Créer.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Modifier le modèle d'inspection existant et créer un modèle d'anonymisation
pour des données structurées
Tâche 3 : Examiner les résultats de la découverte initiale
Remarque : Comme indiqué précédemment, une fois l'analyse
de la configuration lancée, il peut s'écouler un certain temps avant que les
résultats complets ne soient disponibles.
Maintenant que vous avez créé les modèles, des résultats sont disponibles dans
le tableau de bord Looker généré par l'analyse de découverte.
Dans cette tâche, vous allez examiner les résultats de la découverte initiale
fournis dans un tableau de bord Looker, qui s'appuie sur les informations de
profilage des données enregistrées dans BigQuery lors de la tâche 1.
Afficher un résumé des résultats dans un tableau de bord Looker
-
Revenez à la page de présentation de
Sensitive Data Protection.
-
Sous l'onglet Découverte >
Configurations d'analyse, recherchez la ligne nommée
Découverte Cloud Storage. Sous
Data Studio, cliquez sur Looker pour
cette ligne.
-
Pour Demande d'autorisation, cliquez sur
Autoriser.
-
Dans la boîte de dialogue
Sélectionnez un compte sur qwiklabs.net, sélectionnez
.
-
Pour Examiner l'accès aux données, cliquez sur
Confirmer.
-
Pour Accorder l'autorisation, cliquez sur
Autoriser.
-
Passez en revue la page Présentation du résumé.
Notez que des vignettes de données résument des informations clés telles
que le risque lié aux données, leur sensibilité et les types d'assets.
-
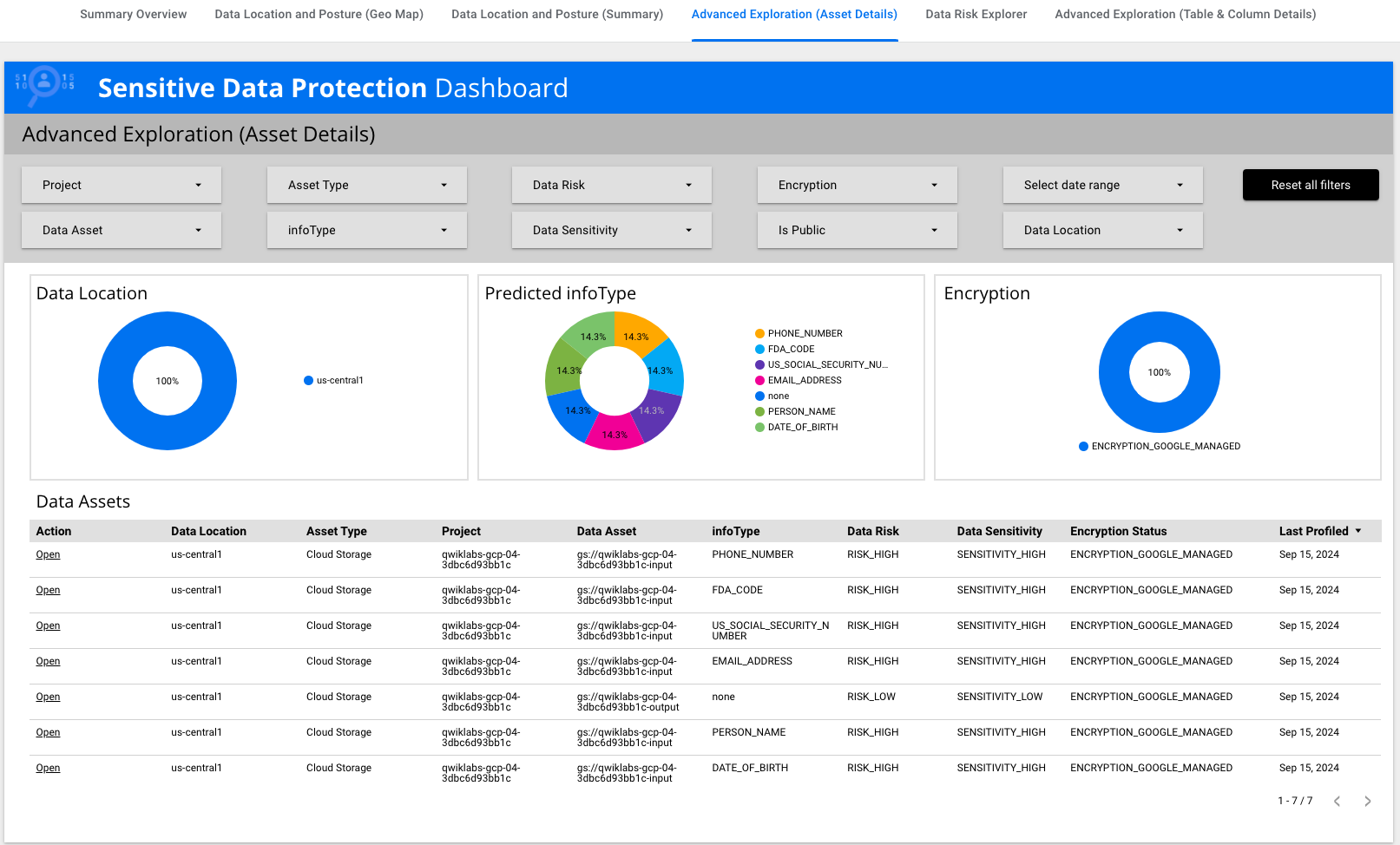
Cliquez sur Exploration avancée (détails des assets) et
examinez la table.
Notez qu'il existe un infoType US_SOCIAL_SECURITY_NUMBER.
-
Cliquez sur Modifier et partager.
-
Dans Saisissez vos informations générales, sélectionnez
un pays et indiquez un nom d'entreprise, par exemple "N/A".
-
Acceptez les conditions d'utilisation en cochant la case, puis cliquez sur
Continuer.
-
Sélectionnez Non pour toutes les préférences relatives
aux e-mails, puis cliquez sur Continuer.
-
Pour Examiner l'accès aux données avant d'enregistrer,
cliquez sur Confirmer et enregistrer.
-
Dans Data Studio, cliquez sur Afficher pour consulter le
rapport.
-
Repérez la ligne dont l'infoType est
US_SOCIAL_SECURITY_NUMBER, puis cliquez sur
Ouvrir dans la première colonne de cette ligne.
Afficher les résultats détaillés dans Sensitive Data Protection
-
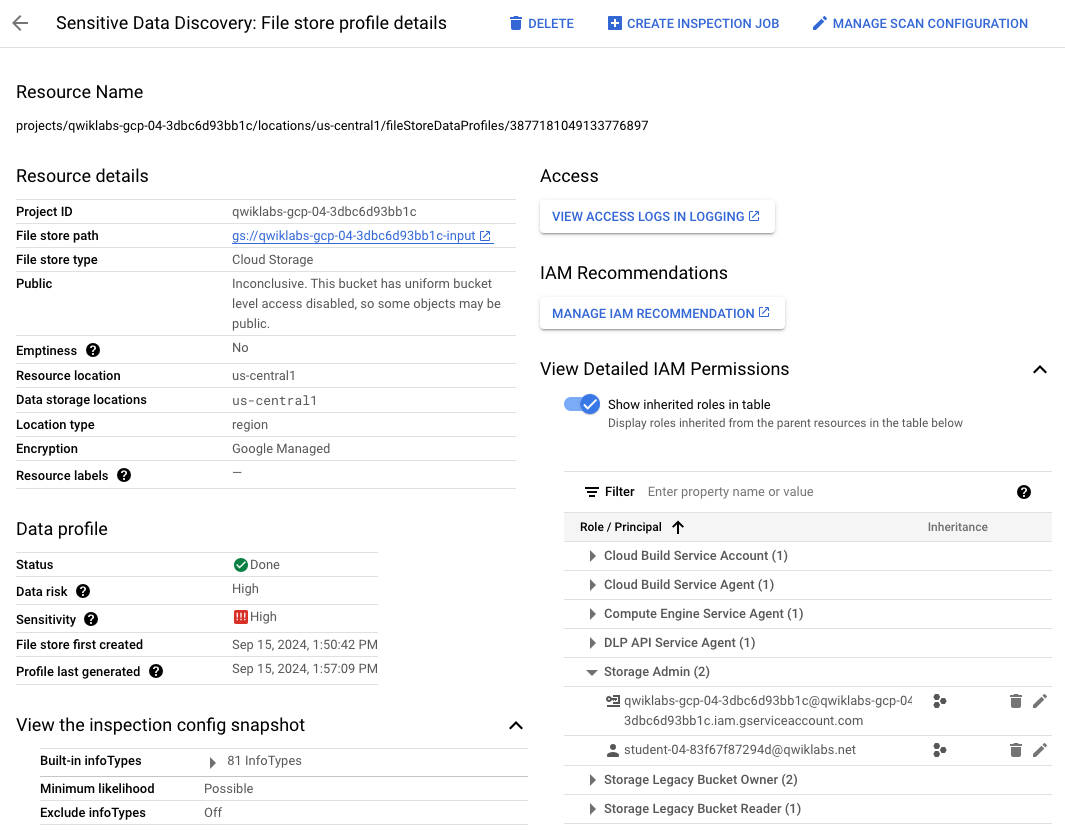
Sur la page
Découverte des données sensibles : détails du profil du magasin de
fichiers Cloud Storage, vérifiez que Sélectionner un projet (barre de menu
supérieure) est défini sur l'ID de projet
, puis passez en revue la page.
Notez que de nombreux détails sont fournis sur les ressources analysées, y
compris les autorisations IAM.
-
Cliquez sur la flèche à côté de
Afficher les autorisations IAM détaillées.
-
Cliquez sur la flèche à côté de Administrateur Storage.
Vous pouvez voir qu'un autre utilisateur () est listé en tant qu'administrateur Cloud Storage et dispose donc d'un
accès complet aux données.
Tâche 4 : Créer et exécuter un job d'inspection
Pour Sensitive Data Protection, un workflow typique après une analyse de
découverte consiste à exécuter un
job d'inspection
plus détaillé pour examiner de plus près des infoTypes spécifiques.
Rappelez-vous que lors de la tâche 2, vous avez créé un modèle pour une
inspection plus approfondie des numéros de sécurité sociale américains. Vous
allez maintenant utiliser ce modèle pour créer et exécuter le job
d'inspection.
Créer et exécuter un job d'inspection
-
Revenez à la page de présentation de
Sensitive Data Protection.
-
Cliquez sur l'onglet Inspection, puis sur
Créer un job et des déclencheurs de jobs.
-
Pour Choisir les données d'entrée, saisissez les valeurs
suivantes :
| Propriété |
Valeur |
| ID du job |
us_ssn_inspection |
| Type d'emplacement |
Multirégional > États-Unis (plusieurs régions aux États-Unis)
|
| Type de stockage |
Google Cloud Storage |
| Type d'emplacement |
Analyser un seul fichier ou le chemin d'accès au dossier
|
| URL |
gs://-input/
(ne pas oublier d'ajouter le caractère / à la fin de l'URL)
|
| Analyse récurrente |
Activer cette option (ne pas oublier d'ajouter une barre oblique
/ à la fin de l'URL ci-dessus)
|
| Échantillonnage |
Augmenter la valeur à 100 %
|
| Méthode d'échantillonnage |
Aucun échantillonnage |
| Fichiers |
Sélectionner TEXTE et CSV (et
désélectionner toutes les autres options), puis cliquer sur
OK
|
-
Cliquez sur Continuer.
-
Pour Modèle d'inspection >
Nom du modèle, ajoutez le chemin d'accès au modèle
d'inspection fourni ci-dessous, en remplaçant TEMPLATE_ID par
l'ID du modèle d'inspection que vous avez modifié à la tâche 2 (par
exemple, 7216194786087173213) :
projects//locations/global/inspectTemplates/TEMPLATE_ID
Pour afficher à nouveau l'ID du modèle, accédez à l'onglet
Configuration de la page de présentation de
Sensitive Data Protection.
Remarque : Assurez-vous que le chemin d'accès au modèle d'inspection ne
contient pas d'espaces lorsque vous l'ajoutez au Nom du modèle.
-
Conservez les autres valeurs par défaut, puis cliquez sur
Continuer.
-
Pour Ajouter des actions, activez l'option
Enregistrer dans BigQuery et cochez la case
Inclure le devis.
Cette option permet au job de copier l'emplacement et le contenu des
données potentiellement sensibles dans BigQuery.
-
Indiquez l'ensemble de données et la table (qui ont été préalablement
créés dans cet atelier) dans lesquels enregistrer les résultats dans
BigQuery :
| Propriété |
Valeur |
| ID du projet |
|
| ID de l'ensemble de données |
cloudstorage_inspection |
| ID de la table |
us_ssn |
-
Pour Ajouter des actions, activez également
Publier dans Security Command Center.
-
Cliquez sur Continuer.
-
Pour Planification, conservez la valeur par défaut
Aucun (exécuter le job ponctuel immédiatement après sa
création)
afin d'exécuter le job immédiatement, puis cliquez sur
Continuer.
Comme pour les analyses de découverte, vous pouvez planifier l'exécution des
jobs d'inspection selon un calendrier spécifique. Dans le cas présent, le job
sera exécuté immédiatement après sa création.
-
Cliquez sur Créer puis sur
Confirmer la création.
Restez sur cette page et attendez que le job soit terminé.
Lorsque l'état du job est Terminé, passez à la section
suivante.
Afficher les résultats du job d'inspection dans BigQuery
Dans la section précédente, vous avez choisi d'enregistrer les résultats de
l'inspection dans la table BigQuery nommée us_ssn. D'un
simple clic ci-dessous, vous pouvez facilement accéder à BigQuery pour
examiner les résultats.
-
Cliquez sur Afficher les résultats dans BigQuery.
-
Dans BigQuery, cliquez sur Aperçu pour afficher le
contenu de la table.
Observez la colonne nommée quote, qui contient une copie
de la valeur exacte qui a été signalée par le job d'inspection pour un
examen complémentaire. Vous pouvez également faire défiler la table vers
la droite et examiner la colonne container name pour voir
l'emplacement (plus précisément le nom de fichier) de la valeur.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Créer et exécuter un job d'inspection
Tâche 5 : Créer et exécuter un job d'anonymisation
En plus de la découverte, vous pouvez exploiter un autre service Sensitive
Data Protection nommé
anonymisation. Ce service vous permet de réduire les risques liés aux données sensibles
dans Cloud Storage en exécutant un job d'anonymisation pour créer des copies
des fichiers Cloud Storage dans lesquels les données sensibles sont masquées.
Ces nouvelles copies peuvent être partagées avec les workflows en aval, au
lieu des versions d'origine qui contiennent les données sensibles.
Dans cette tâche, vous allez créer et exécuter un job d'anonymisation à l'aide
du modèle d'anonymisation que vous avez créé dans la tâche 2.
-
Revenez à la page de présentation de
Sensitive Data Protection.
-
Cliquez sur l'onglet Inspection, puis sur
Créer un job et des déclencheurs de jobs.
-
Pour Choisir les données d'entrée, saisissez les valeurs
suivantes :
| Propriété |
Valeur |
| ID du job |
us_ssn_deidentify |
| Type d'emplacement |
Multirégional > États-Unis (plusieurs régions aux États-Unis)
|
| Type de stockage |
Google Cloud Storage |
| Type d'emplacement |
Analyser un bucket comportant des règles Inclure/Exclure
|
| Nom du bucket |
-input
|
| Échantillonnage |
Augmenter la valeur à 100 %
|
| Méthode d'échantillonnage |
Aucun échantillonnage |
| Fichiers |
Sélectionner TEXTE et CSV (et
désélectionner toutes les autres options), puis cliquer sur
OK
|
Remarque : Assurez-vous que le nom du bucket ne contient pas d'espaces.
-
Pour Exclure des chemins d'accès, cliquez sur
Ajouter une expression régulière d'exclusion. Dans
Exclure des chemins d'accès, saisissez
ignore.
La valeur de Exclure des chemins d'accès 1 est désormais la
suivante :
gs://-input/ignore
Cette option permet d'indiquer au job d'anonymisation d'ignorer les fichiers
du sous-répertoire nommé ignore.
-
Conservez les autres valeurs par défaut et cliquez sur
Continuer.
Notez que vous n'ajoutez pas de valeur pour le modèle d'inspection. Vous
définirez la valeur du modèle d'anonymisation à une étape ultérieure.
-
Sous Configurer la détection, conservez les valeurs par
défaut pour tous les champs, puis cliquez sur Continuer.
-
Dans Ajouter des actions, faites défiler la page vers le
bas pour trouver et activer Créer une copie anonymisée.
-
Pour Modèle d'anonymisation de données structurées,
saisissez le modèle d'anonymisation que vous avez créé précédemment pour
les fichiers structurés (tels que les fichiers CSV et texte) :
projects//locations/global/deidentifyTemplates/us_ssn_deidentify
Remarque : Assurez-vous que le chemin d'accès au modèle d'anonymisation
ne contient pas d'espaces.
-
Activez l'option
Exporter les détails de la transformation vers BigQuery et
indiquez l'ensemble de données et la table (qui ont été créés au préalable
dans cet atelier) pour enregistrer les résultats dans BigQuery.
| Propriété |
Valeur |
| ID du projet |
|
| ID de l'ensemble de données |
cloudstorage_transformations |
| ID de la table |
deidentify_ssn_csv |
-
Pour l'emplacement de sortie Cloud Storage, spécifiez :
gs://-output
Cette valeur indique au job d'écrire la sortie masquée dans le deuxième bucket
qui a été créé au préalable dans cet atelier pour les fichiers de sortie.
-
Pour Fichiers, sélectionnez TEXTE et
CSV (et désélectionnez toutes les autres options), puis
cliquez sur OK.
-
Cliquez sur Continuer.
-
Conservez la valeur par défaut Aucun pour
Planification afin d'exécuter le job immédiatement, puis
cliquez sur Continuer.
Comme pour les jobs d'inspection, vous pouvez planifier l'exécution du job
d'anonymisation à intervalles réguliers (par exemple, chaque semaine).
-
Cliquez sur Créer puis sur
Confirmer la création.
Restez sur cette page et attendez que le job soit terminé.
Lorsque l'état du job est Terminé, laissez cet onglet de
navigateur ouvert et passez à la section suivante.
Afficher les détails de la transformation anonymisée dans BigQuery
Dans la section précédente, vous avez choisi d'enregistrer les détails de
l'anonymisation dans la table BigQuery nommée
deidentify_ssn_csv. Dans cette section, vous allez accéder à
BigQuery pour afficher les détails de la transformation.
-
Dans la console Google Cloud, cliquez sur le
menu de navigation () > BigQuery.
-
Dans le volet Explorateur, développez
> cloudstorage_transformations
puis cliquez sur la table deidentify_ssn_csv.
-
Cliquez sur Aperçu pour afficher les résultats.
Observez les colonnes container_name et
transformation.type, qui fournissent des informations sur
les fichiers anonymisés à l'aide de règles de transformation spécifiques.
Afficher la sortie anonymisée
-
Revenez à la page des résultats du job d'inspection et cliquez sur
Configuration.
-
Faites défiler la page jusqu'à Actions >
Bucket de sortie pour les données Cloud Storage anonymisées.
-
Cliquez sur le lien du bucket (gs://-output) pour accéder à ce bucket Cloud Storage et examiner les fichiers
anonymisés.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Créer et exécuter un job d'anonymisation
Félicitations !
Dans cet atelier, vous avez activé la découverte pour la surveillance continue
des données sensibles dans les fichiers Cloud Storage. Vous avez également
créé et modifié des modèles réutilisables pour l'inspection et
l'anonymisation, et exécuté des jobs d'inspection et d'anonymisation avec
l'option permettant d'écrire les résultats des jobs dans BigQuery pour une
analyse complémentaire.
Étapes suivantes et informations supplémentaires
Consultez les ressources suivantes pour en savoir plus sur Sensitive
Data Protection pour Cloud Storage :
Formations et certifications Google Cloud
Les formations et certifications Google Cloud vous aident à tirer pleinement parti des technologies Google Cloud. Nos cours portent sur les compétences techniques et les bonnes pratiques à suivre pour être rapidement opérationnel et poursuivre votre apprentissage. Nous proposons des formations pour tous les niveaux, à la demande, en salle et à distance, pour nous adapter aux emplois du temps de chacun. Les certifications vous permettent de valider et de démontrer vos compétences et votre expérience en matière de technologies Google Cloud.
Dernière mise à jour du manuel : 10 mars 2026
Dernier test de l'atelier : 10 mars 2026
Copyright 2026 Google LLC. Tous droits réservés. Google et le logo Google sont des marques de Google LLC. Tous les autres noms d'entreprises et de produits peuvent être des marques des entreprises auxquelles ils sont associés.





